海量文本语料的预训练 及后续的监督微调奠定了LLM核心能力,但强化学习(RL)已逐渐成为优化LLMs不可或缺的范式,尤其在使其与人类价值观对齐、学习推理与遵循复杂指令方面发挥着关键作用。aligning them with human values, and teaching them to reason and follow complex instructions.
在本综述中,我们从三个关键维度追溯了 rl4llm 的发展脉络。
-
由LLMs离散、高维 特性带来的独特算法挑战,以及为解决这些挑战而发展的专门方法。
-
使大规模强化学习训练成为可行的计算框架,这些框架推动了相关技术从概念验证迈向实际生产系统。
-
关于大语言模型后训练阶段能力本质的核心争论:强化学习究竟是在传授新知识 ,还是在优化现有知识的表达方式?这一认知又如何塑造我们发展模型能力的方法路径。
目录
[1. Introduction](#1. Introduction)
[2. 强化学习核心概念与建模范式](#2. 强化学习核心概念与建模范式)
[2.1 大模型](#2.1 大模型)
[1. 预训练 pre-training](#1. 预训练 pre-training)
[2. 有监督微调 SFT](#2. 有监督微调 SFT)
[3. 后训练 post-training](#3. 后训练 post-training)
[2.2 传统 RL形式 与 适配LLM的RL](#2.2 传统 RL形式 与 适配LLM的RL)
[2.3 RL in LLMs 的挑战(参数量与内存 + 数据异质性)](#2.3 RL in LLMs 的挑战(参数量与内存 + 数据异质性))
[3. 强化学习算法](#3. 强化学习算法)
[3.1 PPO](#3.1 PPO)
[3.2 From PPO to REINFORCE(价值网络必要吗?)](#3.2 From PPO to REINFORCE(价值网络必要吗?))
[3.3 Variants of REINFORCE](#3.3 Variants of REINFORCE)
[3.4 offline 离线算法 - DPO](#3.4 offline 离线算法 - DPO)
[3.5 在线与离线的对比](#3.5 在线与离线的对比)
[4. 大规模强化学习框架](#4. 大规模强化学习框架)
[4.1 Model Updating 模型更新](#4.1 Model Updating 模型更新)
[4.2 Response Sampling 响应采样(推理)](#4.2 Response Sampling 响应采样(推理))
[4.3 System Integration 系统集成 - 上两步推理与更新的融合](#4.3 System Integration 系统集成 - 上两步推理与更新的融合)
[5. Discussion and Future Directions](#5. Discussion and Future Directions)
[1. 浅层对齐假说(RL后训练有没有提高模型能力?)](#1. 浅层对齐假说(RL后训练有没有提高模型能力?))
[2. 未来发展的算法特性](#2. 未来发展的算法特性)
[3. 面向实际应用的研究方向](#3. 面向实际应用的研究方向)
1. Introduction
RL4LLM 的领域目标:
-
价值对齐任务,确保模型行为符合人类偏好
-
安全性增强任务,减少模型的有害输出
-
专业领域优化任务,例如数学推理与代码生成
-
新兴智能体 能力培育任务,使模型能够完成复杂的多步骤任务
多维度的研究方向:
-
提出更贴合语言类任务 特点的全新问题建模范式 new problem formulations that better capture the nuances of language-based tasks;
-
研发能够应对高维空间 强化学习独特挑战的算法algorithmic advances that address the unique challenges of RL in high-dimensional spaces;
-
搭建可支撑大规模 强化学习训练算力需求的先进训练基础设施 sophisticated training infrastructures capable of handling the computational demands of large-scale RL training
综述的四部分:

- 强化学习核心概念与建模范式 :介绍强化学习的核心概念 ,分析这些概念如何适配大语言模型的训练流程 。特别关注强化学习在 LLM 场景中的独特属性,包括文本环境中的奖励建模、梯度估计 挑战,以及高维空间中的梯度更新策略。
- 主流强化学习训练算法 :PPO、ReMax、GRPO。重点阐述这些算法与传统 强化学习方法的关联与差异、针对大语言模型特性的适配方案,以及计算效率 与学习效果之间的权衡关系。
- 分布式强化学习训练框架 :现代LLM规模强化学习训练的现有基础设施与方法 ,探讨内存高 效训练技术、生成加速 技术、分布式 训练与优化策略,以及应对大规模强化学习部署计算挑战的解决方案。
- 未来研究方向与开放问题 :RL-LLM交叉领域的潜在研究方向,包括现有方法的必要改进方案、样本高效 学习的新兴技术、解决当前可扩展性与稳定性 瓶颈的策略,以及通过多模态 融合和智能体化大语言模型系统构建提升模型能力的路径。
2. 强化学习核心概念与建模范式
2.1 大模型
推动 LLM 发展加速的三大核心因素:
-
Transformer 的架构创新
-
训练数据集规模的持续扩大与多样性的不断提升
-
模型训练专用计算资源的显著进步
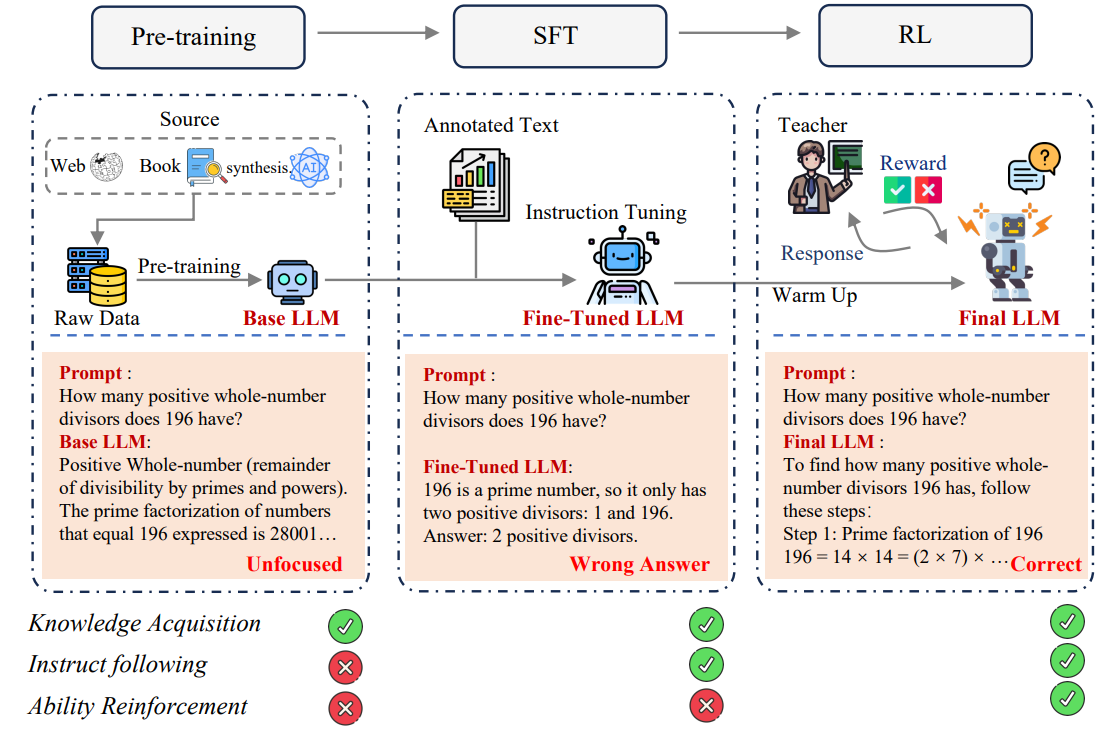
LLM 训练三大步骤:
1. 预训练 pre-training
(foundational knowledge and linguistic understanding 基础知识储备与语言理解能力)
预训练 阶段 互联网 级别的多样化数据集,"下一词预测 " 任务的自监督 特性,让模型从原始文本中学习到丰富的特征表示。
多任务学习 模型需要学会在各类多样的上下文场景中预测标记 ,跨领域的训练方式,能够促使模型形成可迁移至不同任务 的通用能力。
预训练阶段的核心目标是通用语言 建模与理解,而下游任务则要求模型整合自身的知识与语言能力,生成结构清晰、目标导向的回应 。预训练大语言模型在下游任务中表现不佳的根源:
生成虚构 事实、产生带有偏见 或有害的内容,以及无法准确遵循用户指令。
预训练的"下一词预测",这与 "安全、有效地遵循用户指令" 的理想目标相去甚远。
2. 有监督微调 SFT
(instruction following and appropriate response formatting 遵循指令,并输出格式规范的回应)
监督微调则通过数据分布迁移( 与人类需求对齐**)** 的方式解决了这一错配问题 ------ 它在保持 "下一词预测" 这一技术目标不变的前提下,将训练数据的分布 从通用文本语料库,转变为经过精心筛选 的**"指令 - 回应" 配对数据** 与任务专属数据集。
此外,SFT 还将模型的输出格式转化为人类评估者或奖励模型 能够有效理解和评判的形式,
从而为后续的强化学习训练提供有意义的奖励信号。
监督微调 SFT 最大似然估计的目标函数:
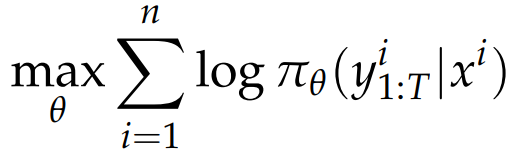
监督微调与经典监督学习存在本质区别。
- 充分利用了模型在预训练阶段已经习得的海量知识 ,因此仅需少量样本即可实现高效的适配。
属于迁移学习与持续学习的范式范畴。
- 过参数化状态 ,因此需要重点关注过拟合 风险。可能会导致模型生成回应的多样性下降 ,并提出了隐式熵正则化 方案来解决这一问题。对齐代价 现象 ------ 模型在完成对齐的过程中 ,会遗忘一部分在预训练阶段习得的知识与能力。
3. 后训练 post-training
(boost alignment, safety, and complex reasoning abilities 提升模型对齐度、安全性与复杂推理能力)RLHF / 推理时优化(思维链等)
RLHF基于人类反馈的强化学习
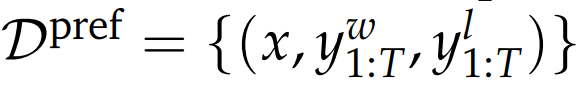 数据集 偏好回答(win)不偏好回答(loss)
数据集 偏好回答(win)不偏好回答(loss)

可得:奖励模型学习的最基础形式化表达:
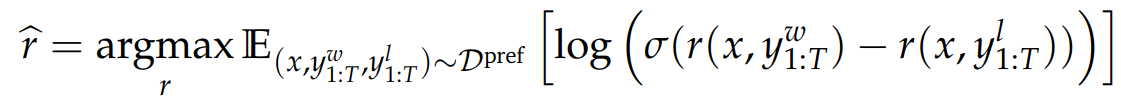
基于奖励模型的策略优化:最大化奖励 + KL 散度约束
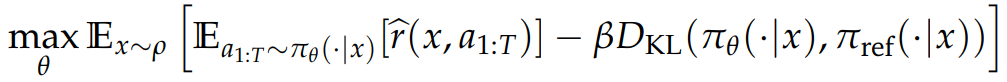
KL散度约束 的作用 缓解奖励劫持/奖励过优化 问题:
由于偏好数据集的规模与覆盖范围有限,训练得到的奖励模型可能会偏离真实奖励函数。
后续策略学习可能会过度利用这个不够完善的奖励模型,最终导致模型在真实场景下的性能达不到最优。
RLHF 分为:基于奖励模型的方法 与无奖励模型的方法 。基于奖励模型的方法能够利用学到的奖励模型 ,对偏好数据集之外的数据计算奖励值,与偏好数据结合,共同用于策略学习。
RLVR 基于可验证奖励的强化学习 提升大模型推理能力。
把策略学习式子中的 r 替换为 -> 规则奖励函数 r_rule 判定模型最终输出结果的正确性。
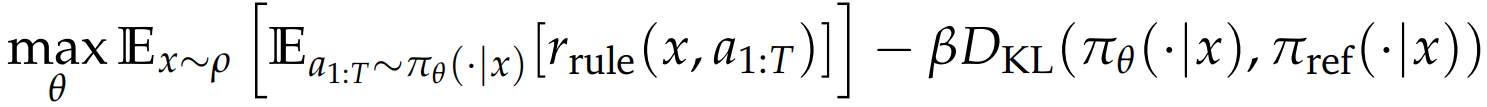
(结果奖励如数学题 与正确答案对比;程序题 单元测试)
2.2 传统 RL形式 与 适配LLM的RL
传统 RL 策略π 的目标函数:
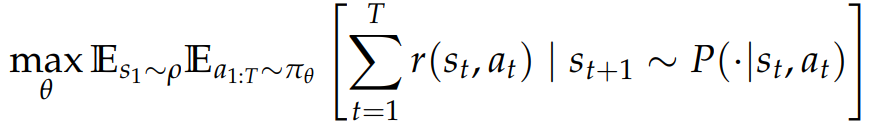
MDP 各组件与 LLM 生成过程的直接对应关系: 状态 st 包含截至当前时刻已生成的所有标记,st=(x,a1,...,at−1),其中 x 表示输入的初始提示词 。动作 at 对应从词表集合 V 中选择一个标记。初始状态 s1 即为提示词 x,初始状态分布 ρ 对应提示词的分布。
但在该形式化定义中,动作空间 的规模极大(例如 Llama-3 模型的词表大小达 12.8 万),目前已有相关研究致力于探索更紧凑的动作空间表示。
传统 RL :环境的不确定性通常会导致状态转移具有随机性, 极难求解,因为这种随机性 不受智能体控制,通常需要借助价值网络等先进技术来降低方差。
LLM **确定性状态转移:**将状态 st 与动作 at 进行拼接,更高效的、专门适配语言模型微调的 RL。
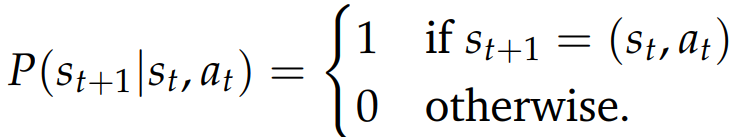
奖励函数设置
RL4LLM 通常采用稀疏奖励函数(整体评估) ,即仅在完整的回应序列生成完毕后才会赋予奖励(例如 r=1 或 r=−1),中间的标记生成步骤均无奖励(奖励值为 0)。
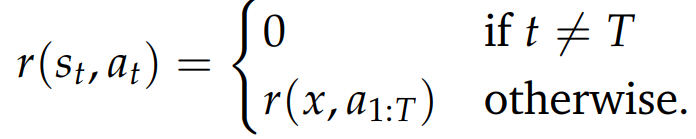
目标函数 奖励最大化
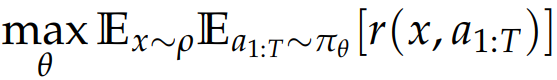
上文的固定长度序列 (T)末尾赋予单一奖励 的设定 -> 适用于单轮回应生成任务;
实际情形:更复杂的序贯交互,如多轮对话 or 复杂智能体。
状态空间|S| 大幅扩充 ,不仅是当前的提示词 x + 生成部分 a,还要历史对话。
对于动作 a;选单个动作 -> 微 动作;单轮对话 -> 宏动作
奖励信号 r 不再局限于序列末尾 ,而是可能在每轮对话结束后赋予,
甚至在多轮对话后才稀疏赋予,具体取决于对话任务的目标。
2.3 RL in LLMs 的挑战(参数量与内存 + 数据异质性)
缩放定律 :模型性能会随参数量的增加而稳定提升
参数量指数级增长,带来了独特的计算需求,也使得大语言模型的强化学习训练与传统强化学习应用截然不同。
并且参数量 增长速度远快于 GPU 显存增长速度。
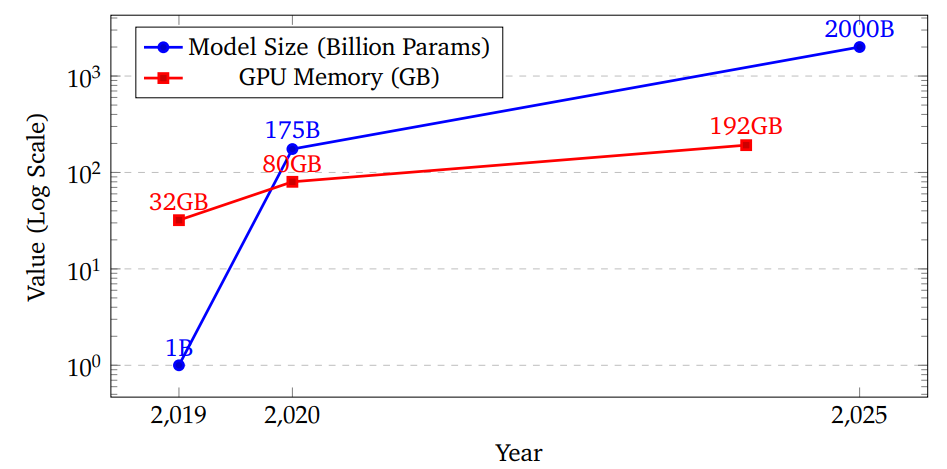
内存需求:
监督学习仅需维护一个模型实例 ;单次前向传播。
但常用强化学习 通常需要同时维护多个模型副本 ------ 包括策略网络、价值网络,以及用于 KL 散度正则化的参考模型,内存需求增加约 2-3 倍。每个训练步骤中需要执行多次前向与反向传播。
大规模强化学习优化需要:内存高效 型算法+ 新型分布式训练。
Data Heterogeneity 数据异质性:
一模型多任务,不同任务的数据往往具有截然不同的奖励特征。
不同类型提示词对应的奖励分布差异巨大:
开放式创意类 提示词的奖励分布通常较为平缓且呈多峰分布;
而像 "新西兰的首都是什么?" 这类事实性封闭式 提示词,由于其答案具有非对即错的二元特性 ,往往会产生极端的奖励值。
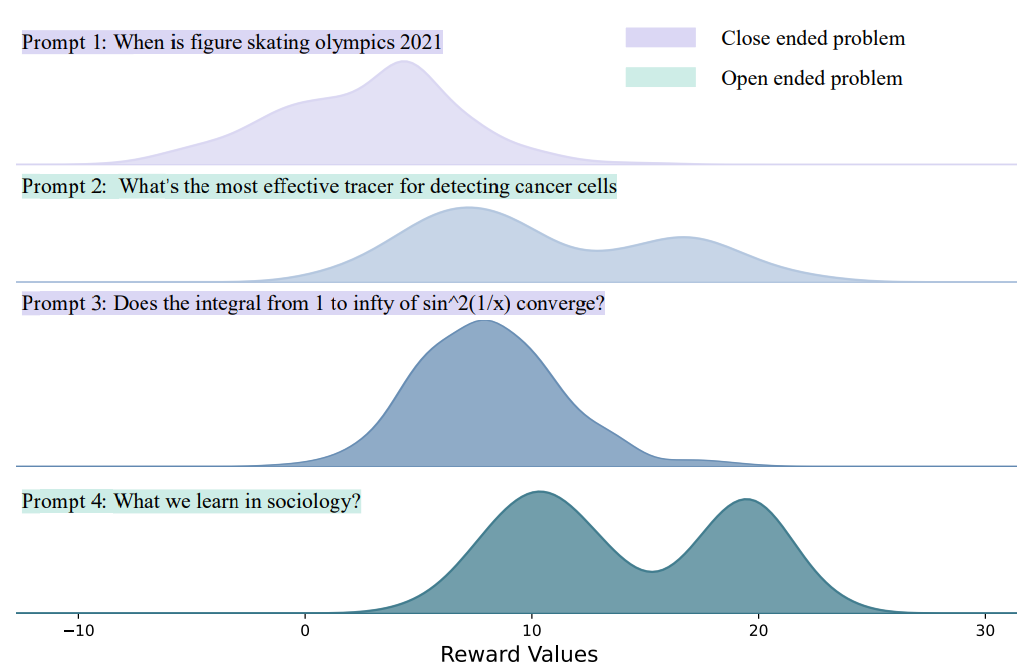
类似地,在面向推理任务的 RLVR 方法中,不同难度级别的数学题,
其解题成功率与对应的奖励分布也存在天壤之别。
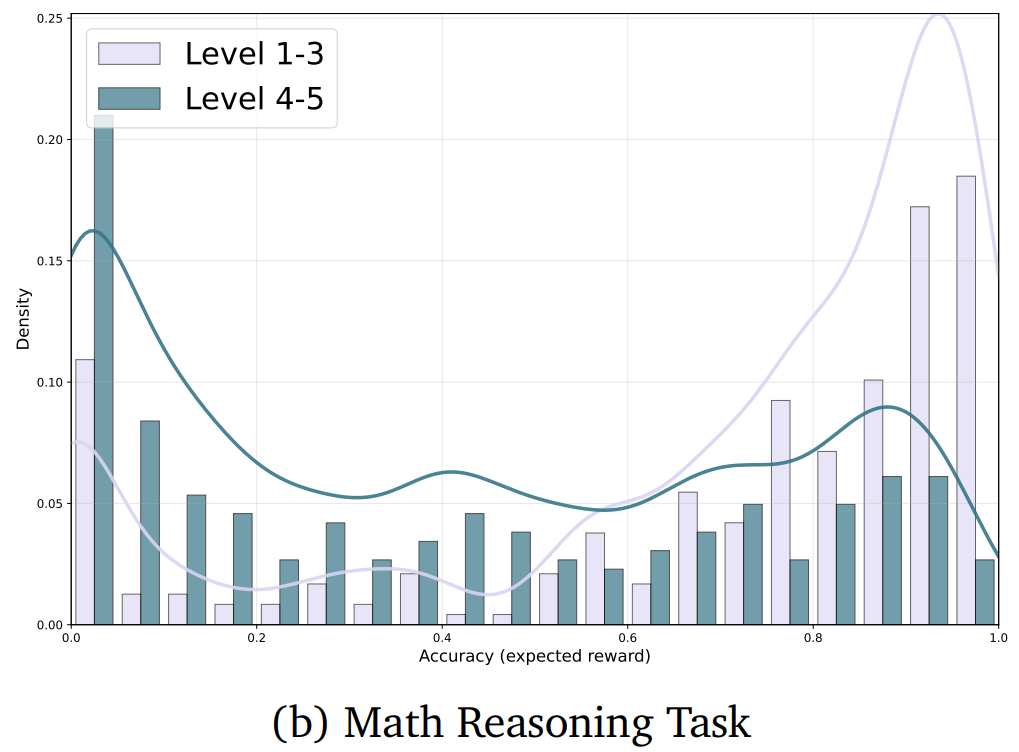
梯度失衡效应 ------ 1. 奖励方差较大 的任务会主导梯度更新过程,进而可能导致模型在其他领域发生灾难性遗忘;
-
奖励值极端的任务可能会获得过多关注
-
不同任务类型产生的梯度信号可能相互冲突,导致训练过程出现震荡
需要:多任务梯度重平衡 ,并确保模型在异质性奖励空间中能够稳定优化。
还有难点:稀疏、延迟 的奖励结构(如何奖励分配)词表维度 高(超高维 离散动作空间)难以精准拟合价值函数
3. 强化学习算法
分为两大类
online 在线强化学习算法 ,通过与环境的迭代交互实现策略优化;
offline 离线强化学习算法 ,基于固定数据集完成模型训练。
在线算法:探索 + 利用(推理 + 更新)

利用:策略梯度更新

策略梯度估计量的设计:稳定性 + (熵)正则化(多样性 探索能力)

(是否需要价值网络呢?REINFORCE -> actor critic -> LLM-specific actor only)
REINFORCE 实现简洁,无需 额外训练一个独立的价值函数 (但方差高)
Actor Critic 引入价值模型 降低 随机梯度的不确定性与方差。
降低方差的核心逻辑 ------ 即应对外部环境的认知不确定性 ------
并不能完全适用于大语言模型,因为大语言模型的训练场景并不存在同类的认知不确定性。
这一观点推动了一批 LLM专用强化学习算法的研发。(省略价值网络)
3.1 PPO
策略梯度定理指出,当我们想要更新策略 πθ 时,数据应遵循 πθ 的分布。
直接使用来自 πθ_old 的数据进行更新会引入偏差。为了消除这种偏差,PPO采用了重要性采样,通过比率 ψ(s_t, a_t) 来调整数据权重,以确保其在期望上是无偏的。
裁剪 + 重要性采样 ,实现异策略off-policy训练。
好处:数据复用 data reuse 即使在将策略更新为 πθ (不同于 πθ_old)之后,我们仍可以继续使用来自 πθ_old 的数据,而不是立即从 πθ 收集新数据。
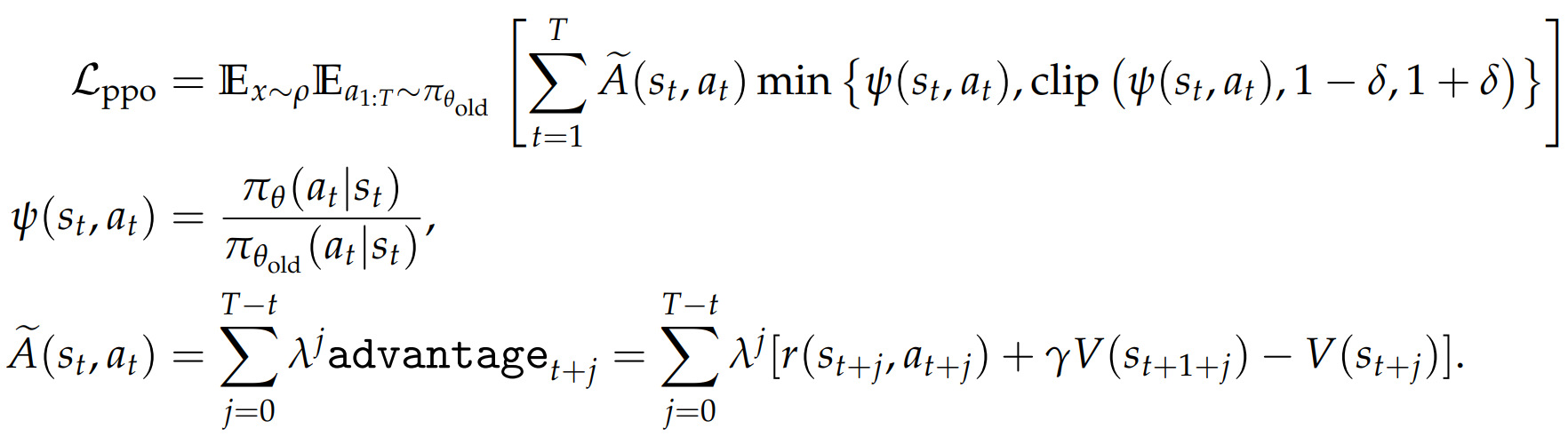
传统深度强化学习方法推崇多轮训练 ,以最大化数据利用率,
将数据集划分为多个小批次,以及对数据进行多轮训练。
但在语言模型微调任务中,由于重复更新 存在训练不稳定的风险,
单轮训练 反而更受青睐。即便是单轮训练,将数据划分为小批次的有效性仍存在争议。
这些设计选择本质上与数据的内在特性 相关,在步长固定的前提下,当数据具有同质性 时,(SGD)的收敛速度快于(GD)。
同样适用于强化学习优化:若数据具有同质性 ,在保持学习率一致 的情况下,离策略学习 的优势会更显著;反之,面对异质性数据时,离策略学习的优势将大幅减弱。
Clipping-based Regularization 基于裁剪的正则化
单边且逐点的正则化机制,A>0 概率不能过高,A<0概率不能过低。

PPO 的正则化是事后校正 的 ------ 只有当策略概率比超出阈值后才会生效;
而 TRPO 的 KL 散度正则化是事前预防 的 ------ 从一开始就确保更新后的策略不会超出边界。
相对裁剪的进一步改进:
- 部分潜在有益的动作初始概率较低 ,更优选择是大幅提升 该动作概率。非对称正则化系数 ,为正向优势场景设置更大的 δ 值,允许在必要时对概率进行更激进的提升。
- 初始概率已经很高 & A>0 过度利用 会削弱 对其他潜在有益动作的探索。基于排序的概率流正则化 方法:只需维持动作概率在分布中的相对排序 ,而非 将其推向极端值 ,即可在保证动作多样性的同时实现有效学习。
GAE 的 A 优势值可视为 "中心化 "形式。与随机采样 结合时,就能有效降低梯度估计的方差。
3.2 From PPO to REINFORCE(价值网络必要吗?)
传统 强化学习中 价值网络的作用:
In traditional RL environments, stochastic transitions create uncertainty beyond the agent's control, resulting in noisy return estimations.
随机的状态转移 会带来智能体不可控的不确定性 ,进而导致回报估计结果存在较大噪声。
To address this challenge, the RL community developed value networks that could be iteratively trained on historical data to provide more accurate return estimates.
为解决这一问题,强化学习领域用价值网络 ------ 通过在历史数据上迭代训练 ,实现更精准的回报估计。
但 LLM 不存在这样的随机性:
Token generation in language models is a deterministic process once the prompt and model parameters are fixed. 而语言模型的标记生成过程是确定性的 :只要给定提示词与模型参数,生成的标记序列就是固定的 。(不存在 随机状态转移 不可控的不确定性)
基于结构更简洁的 REINFORCE 算法,即使不引入价值网络,也能实现与 PPO 相当的性能。
核心结论 :PPO 退化为带标记级基准值的 REINFORCE
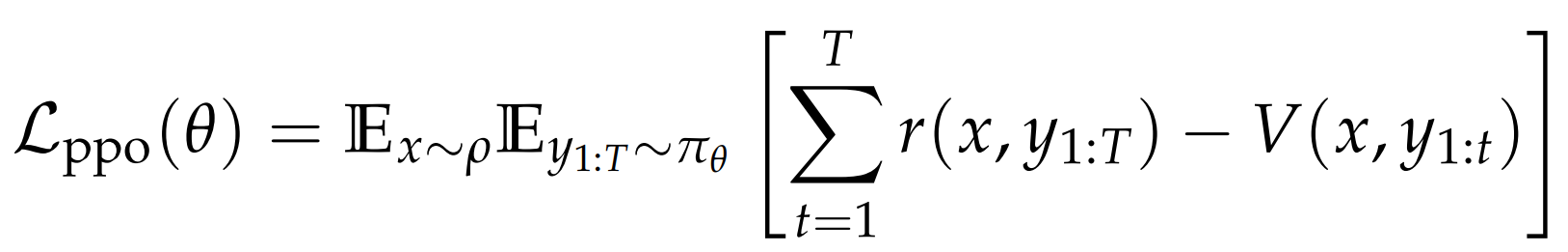
- PPO 需要并行训练两个独立网络:语言模型(策略 网络)与价值网络,这会使计算资源消耗与训练时间都翻倍。
- 当采用轨迹级或结果导向型 奖励训练大语言模型时,价值网络的核心作用仅是为优势估计提供基准值(算 A) ;传统强化学习的核心技术(GAE 与 TD 学习)在此场景下不再必要。
优化 REINFORCE with-baseline :减去基准值 b
后面几种方法 不同的优势函数,区别只是 b 的选取不同。
把梯度估计的式子 r ->(r - b) 又被称为优势值 估计量无偏 性 方差显著降低。
每个提示词设置自适应的基准值 :奖励幅度归一化 -> 应对数据异质性挑战,
通式 写成蒙特卡洛估计:
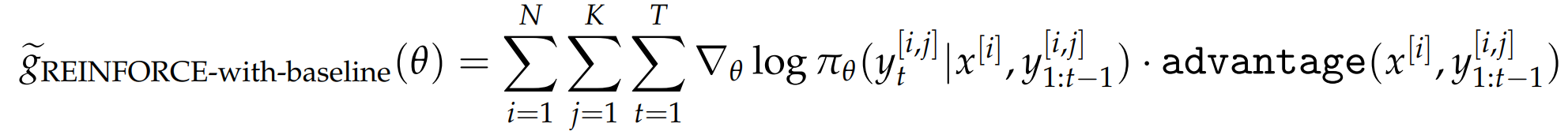
advantage 和 b 的取法
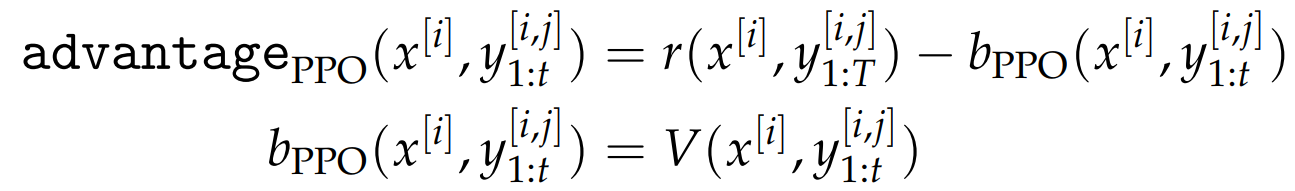
3.3 Variants of REINFORCE
引入的随机变量 与原奖励随机变量正相关,故可以降低梯度的二阶矩,进而降低方差。
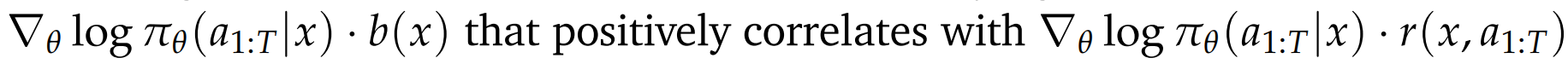
- ReMax :基准值设定为贪心解码回应 **(概率最高的动作)**的奖励值
优势:高度凝练的参考信息 + 极高的计算效率

- GRPO:摒弃了价值网络估计,直接采用奖励值的统计量构建基准值;(优势值归一化)
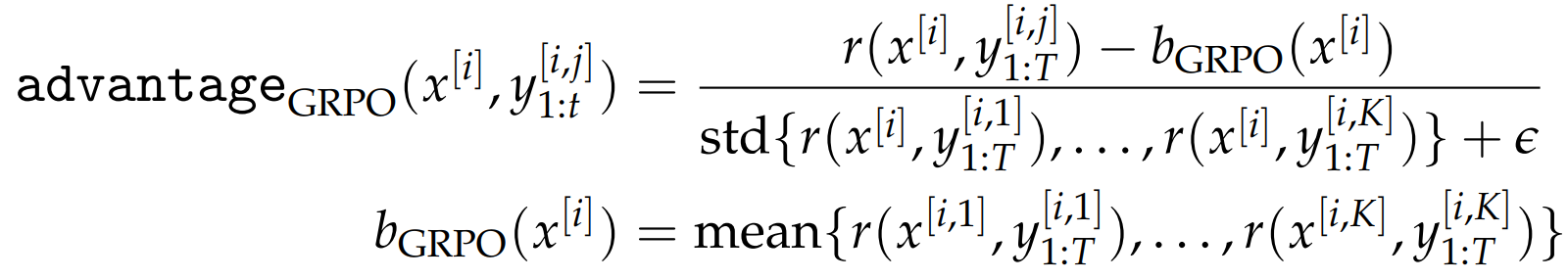
- RLOO :留一法 这个位置其余位置的均值
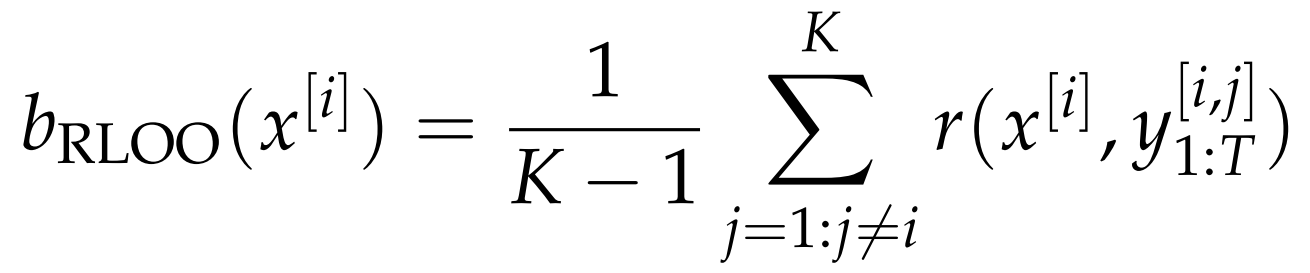
ReMax 仅利用单个回应 (贪心解码结果)构建b,而 GRPO 与 RLOO 则依赖多个回应的统计信息。
GRPO的梯度估计量 在标准差计算与均值估计引入固有偏差。
但偏差的存在并不意味着算法无法收敛,只要梯度更新方向与真实梯度方向 的夹角小于 90 度,算法就有望实现渐近收敛。并且 GRPO 中的标准差校正项可被视为一种自适应学习率机制。
3.4 offline 离线算法 - DPO
基于固定数据集更新。
在经典RL中:随机初始化的网络展开,主要解决分布偏移与过估计等问题。
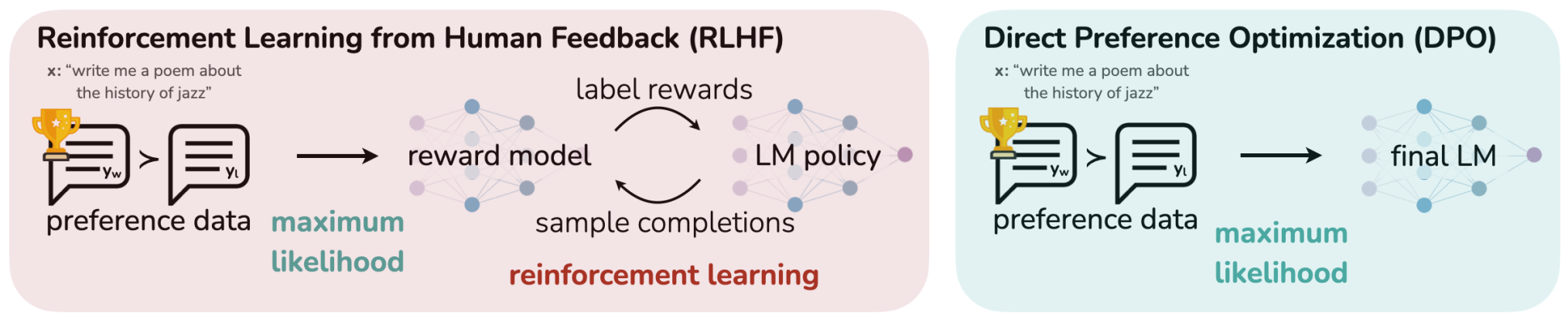
DPO 简化了训练流程,无需显式训练奖励模型。
核心创新点在于:将大语言模型本身视为一个隐式的奖励模型。
对于偏好数据而言,模型自身输出的对数概率 可被解读为一种指标,用于衡量一个回应相较于另一个回应的偏好程度。
在策略优化过程中,DPO 直接调整模型输出的对数似然 ,以此提升受偏好回应 相对于不受偏好回应的概率。
DPO(Direct Preference Optimization)
解带 KL 散度正则化的奖励最大化问题:
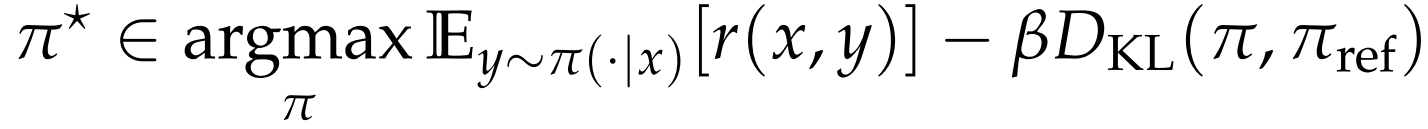
有闭式解:
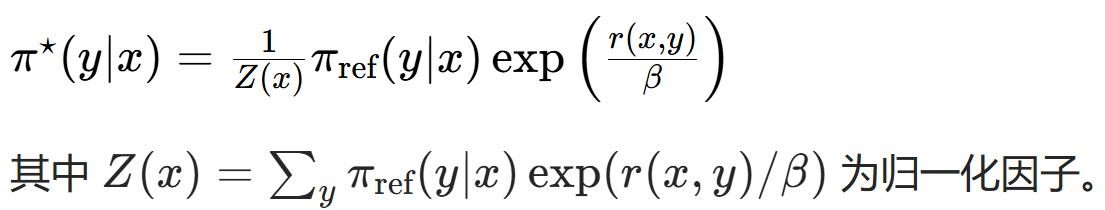
所以参数化奖励函数 -> 参数化最优策略 π*,目标函数可写作:
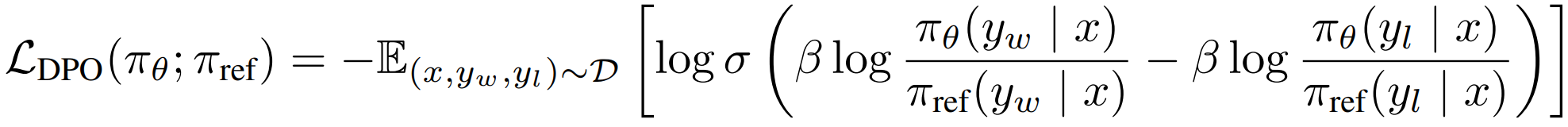
3.5 在线与离线的对比
在线RL的核心优势在于其 "在线优化 " 特性:模型能够生成全新的回应 ,并基于当前策略产生的新数据开展学习 。这与 DPO 算法形成鲜明对比 ------ 后者依赖人工构建的静态数据集。
离线算法的性能可以通过引入某种形式的 "在线" 数据采集与利用机制 得到增强,
例如,迭代式 DPO :利用当前模型生成新的回应样本 ,再借助已训练的奖励模型 为这些新数据标注偏好标签 ,最后将标注后的数据用于下一轮 DPO 训练 。这一流程引入了类在线学习的元素,使模型能够从自身(或更新后的)策略生成的数据中学习,从而在纯离线学习与在线学习的动态特性之间搭建起桥梁。
4. 大规模强化学习框架
探索 - 响应采样(推理);利用(训练) - 梯度下降模型更新。
GPU 上同时支持模型训练 与响应采样(推理) ,可能引发GPU 资源管理的矛盾。
如 kv-cache 等推理技术,可能与训练需求冲突。
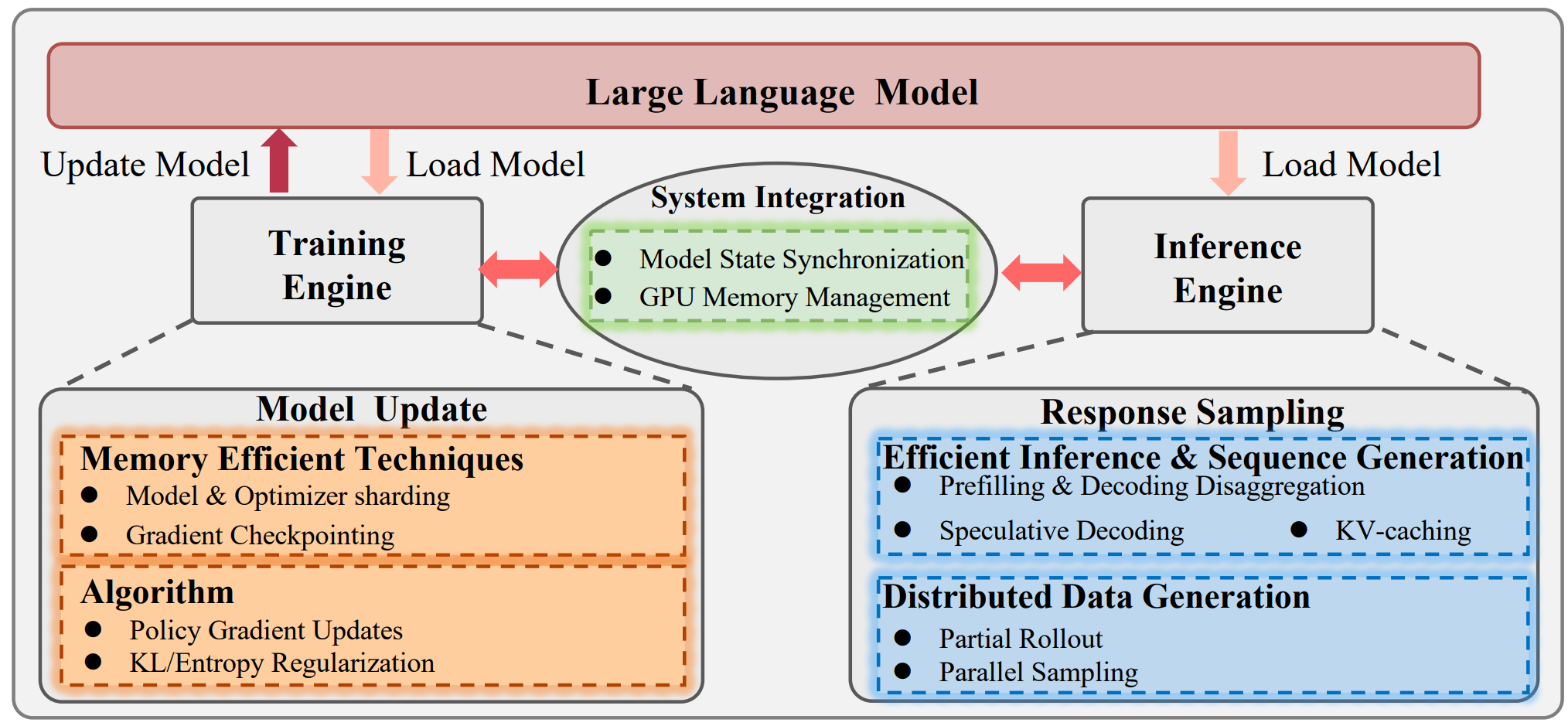
- 由训练 引擎执行的模型更新流程 ,会采用显存优化 技术(如模型和优化器分片、梯度检查点)与强化学习算法(如策略梯度更新、KL 散度 / 熵正则化)完成模型参数的迭代优化。
- 与之并行的是,由推理 引擎执行的响应采样流程,会通过prefilling与decoding解耦、投机性解码、KV-cache、partial rollout、并行采样等技术,高效完成新数据的生成。
- 系统集成模块 负责同步 训练与推理循环间的模型状态,并统筹管理GPU 显存 资源,从而实现低延迟的持续数据生成与模型优化。
4.1 Model Updating 模型更新
FSDP,DeepSpeed and Megatron 等架构分布式训练系统,通过并行 加快训练速度,缓解 GPU 显存受限。
大数据集 -> 数据并行 分配至多个节点。
模型过大 -> 模型并行(张量并行 or 流水线并行)将模型的不同组件拆分。
超参数调优 高效配置(学习率、迭代次数、模型更新步数)利用超参数缩放定律、μ 参数迁移。
4.2 Response Sampling 响应采样(推理)
响应采样收集高质量数据,要求训练全程都低延迟 的相应生成,需要GPU显存和加速技术。
自回归串行 前向传播:生成 T 个 token 需要执行 T 次独立的前向传播,
而模型更新阶段,仅需一次前向传播 即可并行计算出所有 T 个 token 对应的梯度。
1. Caching and Memory Management 高效的缓存管理
目前主流的推理框架(如 vLLM、SGLang)均采用分页注意力(Paged Attention) 等技术,优化缓存调度机制与显存利用率。
将预填充prefilling 与解码decoding这两个环节分配至不同的计算实例中执行,从而提升整体吞吐量。
2. Algorithmic Acceleration 算法层面加速
随着上下文长度 的不断增加,针对 Transformer 推理过程的算法优化变得至关重要。
投机性解码 speculative decoding------ 借助小模型(或辅助预测头)生成候选 token ,再由大模型完成验证;
前瞻解码 Lookahead Decoding ------ 将生成过程重构为一个非线性系统 ,通过雅可比迭代法求解,实现多个 token 的并行解码。
3. Improved Architectures 架构优化
为缓解自回归生成的串行 瓶颈,研究人员借鉴扩散模型的设计思路,探索并行采样技术方案。
在 Transformer 的内部组件中,注意力机制 始终是长上下文 场景下的主要计算瓶颈,这也推动了一系列高效注意力设计的诞生,具体包括:
基于参数共享的方法(如分组查询注意力(Grouped Query Attention);
基于降维的技术(如多头隐式注意力(Multi-Head Latent Attention) 、线性注意力;
以及利用注意力权重固有结构的稀疏感知方法。
FlashAttention 为代表的算法 - 硬件协同设计 方案,充分利用硬件的存储层次结构 等特性实现显著的加速效果,也为更广泛的硬件感知优化策略提供了思路。
4.3 System Integration 系统集成 - 上两步推理与更新的融合
- 集中式调度
调度模型更新与响应采样任务 + 动态管理 GPU 显存分配 + 维护训练引擎与推理引擎之间的模型参数同步。
- 同步训练的局限性
不同提示词对应的采样耗时存在固有差异 ,会造成资源利用率低下与同步瓶颈问题。
对于代码生成这类复杂任务,该问题会表现得尤为突出 ------ 这类任务的奖励计算往往需要执行多个单元测试 ,导致反馈循环大幅延长,进而加剧 GPU 的闲置时长。
- 异步训练范式
(对于同步训练的问题)支持部分轨迹生成 ,并允许响应采样 与奖励计算 任务并行执行。
缺陷:异步训练天然会构建异策略学习场景 ,即生成训练数据 的策略与待更新 的策略并非同一策略 ,这可能导致训练过程不稳定、模型难以收敛。
要解决这些挑战,需要借鉴传统强化学习领域的成熟技术,包括:异策略学习方法、限制 与参考策略偏差 的安全策略更新机制、以及防止策略性能断崖式下降的分布偏移控制手段。
取得计算效率与算法稳定性之间的平衡。
5. Discussion and Future Directions
强化学习究竟能为预训练语言模型赋予什么? 基于性能优异的预训练大语言模型,我们已知强化学习能够通过微调(消耗极低的计算资源 )进一步增强模型的多项认知能力 ,例如思维链推理 、工具调用能力 ,以及在测试阶段可扩展的自我反思能力。
由此引申出两个核心问题:我们能否进一步扩大这种训后优化的计算规模 ?强化学习能否赋予模型一些仅凭预训练无法获得的全新行为模式?
1. 浅层对齐假说(RL后训练有没有提高模型能力?)
"模型的知识储备与核心能力 几乎完全是在预训练阶段习得 的,而对齐 过程的作用,只是教会模型在与人类交互时,应当采用哪一子集的格式规范进行输出。"
佐证在于:研究人员发现,仅使用约 1000 条精心构造的样本开展有监督微调(SFT),训练后的模型就能生成接近人类表达习惯的文本响应。这表明模型能够快速掌握文本风格 层面的规则,而其输出内容所蕴含的实质知识 ,则全部来源于预训练阶段。
这一假说在数学推理领域得到了更多实证支持。以 DeepSeekMath为代表的研究揭示了一个有趣的规律:强化学习训练并未提升模型的 "上限性能 "(以 pass@K 指标衡量);但却能大幅提升模型的 pass@1 指标,在首次尝试作答时,选择最优解法的能力得到了显著增强。
这一现象说明,强化学习并非在拓展模型原始的问题求解能力,而是扮演了 精密置信度校准器 的角色 ------ 它教会模型将自身最优的推理路径 凝练为默认输出,从而让贪心解码生成的结果变得更加可靠。
上述说法的局限性:
首先,将基于最终答案正确率的 pass@K 指标作为衡量模型 "上限性能" 的唯一标准,本身就存在固有缺陷。因为模型生成的响应可能存在过程错误 ,或是仅凭运气 得出正确答案。因此,若用 pass@K 来衡量 "上限性能 ",很容易出现数值高估的情况。
一项有趣研究表明,强化学习实际上具备提升模型基础能力的潜力。例如,即便强化学习仅基于最终结果给予模型奖励信号 ,模型不仅能提高答案的正确率,还能有效减少推理过程中的错误。
其次,现有得出 "负面结论" 的研究,往往局限于小计算量训练范式 。训练数据量有限 (通常在 1 万至 10 万样本之间)、探索空间受限 (每条提示词仅采样 8、16 或 32 条响应)、训练迭代次数稀少(通常仅为数个训练轮次)。
综合来看,这些因素意味着当前主流的强化学习训练范式仍存在明显的不足 。近期已有多项研究大幅扩充了强化学习的计算资源投入,并取得好成果。
现有强化学习算法在探索机制 上同样存在局限,面对一些高难度任务 (如在围棋对弈中取胜、撰写具备竞赛水准的数学解题过程、攻克某一科学领域的开放性问题),模型往往需要经过数百甚至数千次的试错 ,才能找到正确的解决方案。如果采样次数受限 ,模型接收到的奖励信号很可能全部为负值 ,最终导致训练梯度归零 ,无法实现有效优化。此外,当前的训练基础设施 也难以充分支撑如此大规模的探索过程,这也限制了强化学习赋能模型的能力边界。
2. 未来发展的算法特性
-
高效且有效的探索机制 对由 token 序列构成的海量动作空间 进行探索时,普遍存在效率低下 的问题,导致模型尝试生成的候选结果,可能全部得到负面反馈 ,最终无法实现任何有效学习。要解决这一问题,大范围探索策略 至关重要。未来的算法必须研发更先进的探索技术 ,使其能够在语言生成的高维离散空间中高效搜索 ,同时维持训练过程的稳定性。
-
具体实现路径可包括:构建精简的状态 / 动作空间表征、优化探索资源的分配方案、采用结构化更强 的探索空间(例如基于树结构的方法),或是结合LLM的独特属性 ,设计基于提示引导的探索技术。
-
基于离线数据的学习模式 在线强化学习由于模型规模庞大、仿真速度缓慢,在线探索 过程需要付出高昂的计算与资金成本 ,这使其在实际应用中难以落地。并且无法充分利用已收集的数据 ,例如 PPO、GRPO 这类算法,通常仅对样本进行一次训练就将其丢弃 。事实上,在线强化学习的过程本身可被视作一个数据收集 过程,在此过程中会积累大量质量参差不齐的数据 。因此,从这类经验数据中学习具有极高的价值。主流方案仍以有监督微调(SFT)为主 ------依赖人工筛选的高质量数据进行模仿学习。
-
异策略学习方法 当前大语言模型强化学习方案主要采用同策略学习 范式,即训练数据直接由当前策略生成。打破这一限制将带来多项显著优势:
- 利用离线数据 ,需要异策略学习 能力,从而最大化挖掘过往经验数据的价值。
- 从训练系统的角度来看,我们此前提及的异步训练模式 (可提升 GPU 利用率 ),天然会产生异策略数据 。尽管异策略学习在历史实践中常引发训练不稳定 的问题,但结合大语言模型的独特属性,这些挑战有望得到缓解。
3. 面向实际应用的研究方向
预训练大语言模型的训练数据主要来源于网络文本语料库 ,因此其无法覆盖现实物理环境与交互场景中的全部情形 ,而预训练阶段对此类场景的覆盖度本就十分有限。这就要求大语言模型必须借助外部工具,并接收更多的外部反馈信号,强化学习的重要性也由此愈发凸显。下文将重点介绍几个相关研究方向:
1. 工具调用与外部系统集成
对于修复代码仓库漏洞这类复杂任务,大语言模型若仅在 token 空间内完成问题求解,不仅难度极大,还会产生难以承受的计算开销 。一种极具潜力的解决方案是,将特定子任务卸载至外部工具 完成,把底层的推理步骤抽象为工具调用指令。
优势:简化训练流程,减少模型幻觉现象、提升输出结果的可靠性,进而增强任务表现。
LLM 无法仅通过预训练 就天然掌握高效的工具调用策略。训后优化技术 ,尤其是强化学习,为模型习得高效工具使用方法提供了可行路径,能够让模型学会判断调用时机与合理分配子任务 的能力。这就要求大语言模型不仅要认清自身能力边界,还要能策略性地将子任务委托给适配的外部工具或资源。
近期已有相关研究聚焦于通过强化学习,依托长思维链框架 训练大语言模型实现工具交互 ,这类方法有助于在复杂问题求解过程中,减少无效或低效的工具调用 行为。不过当前相关探索仍处于早期阶段,大多仅在单一工具的孤立场景 中验证技术有效性。如何利用多样化的工具生态系统解决更具普适性的复杂问题,仍是一个兼具开放性与重要性的研究课题。
2. 多智能体协同与协作
经强化学习增强的大语言模型,其发展前景不仅局限于提升单个智能体 的能力,更在于拓展多智能体协同 的维度。当多个人工智能体开始协作完成复杂任务时,强化学习就成为智能体习得高效通信协议、任务分解策略与协同机制 的关键技术。这包括让智能体学会协商谈判、责任分配、冲突解决 ,以及在多智能体交互过程中始终保持一致的联合目标。
面向大语言模型的多智能体强化学习 面临诸多独特挑战,例如需要让智能体建立共享的通信语言、理解其他智能体的能力与局限 ,以及根据智能体群体的动态变化调整自身行为 模式。这些能力对于大语言模型系统在现实场景的落地至关重要 ------ 在这些场景中,往往需要多个agent协同工作,或是在协作环境中与人类用户交互。
3. 多模态强化学习与物理世界交互
多模态 能力的融合,是经强化学习增强的大语言模型发展的关键前沿方向。图像与视频理解 能力,能让模型以纯文本系统无法实现 的方式感知并交互物理世界;音频与语音 处理能力则进一步提升大语言模型与人类自然交互的能力,助力打造更自然、更具响应性的交互界面。
通过在多模态任务 上开展强化学习 训练,大语言模型能够将语言理解能力锚定在视觉与空间语境 中,形成更稳健的现实世界推理能力 。多模态强化学习在动作空间设计、奖励函数定义、跨模态表征学习等方面均存在独特挑战,拓展了具身智能的能力边界。