1. 大模型调用
1.1. 常见参数
使用大模型需要传递的参数,在访问大模型时都需要在请求体中以 json 的形式进行传递。

1.2. 响应数据
在与大模型交互的过程中,大模型响应的数据是 json 格式的数据。

2. LangChain4j 会话功能
2.1. 快速入门
引入依赖
xml
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai</artifactId>
<version>1.8.0</version>
</dependency>构建 OpenAiChatModel 对象,调用 chat 方法与大模型交互
java
// 构建OpenAiChatModel对象
OpenAiChatModel model = OpenAiChatModel.builder()
.baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1")
.apiKey(System.getenv("API-KEY"))
.modelName("qwen-plus")
.logRequests(true)
.logResponses(true)
.build();
// 调用chat方法,交互
String result = model.chat("你是谁?");
System.out.println(result);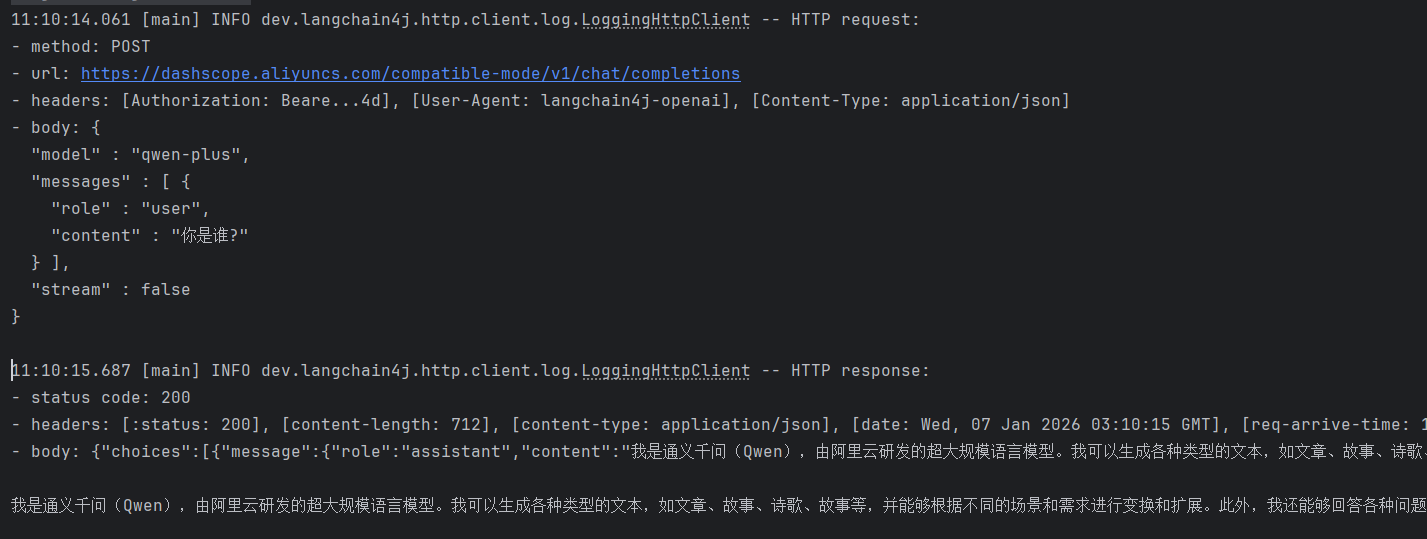
2.2. 集成SpringBoot
引入依赖
xml
<!--langchain4j起步依赖-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai-spring-boot-starter</artifactId>
<version>1.10.0-beta18</version>
</dependency>配置大模型所需参数
yaml
langchain4j:
open-ai:
chat-model:
base-url: https://dashscope.aliyuncs.com/compatible-mode/v1
api-key: ${API-KEY}
model-name: qwen-plus
log-requests: true
log-responses: true
logging:
level:
dev.langchain4j: debug写个接口
java
package com.itheima.consultant.controller;
import dev.langchain4j.model.openai.OpenAiChatModel;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class ChatController {
@Autowired
private OpenAiChatModel chatModel;
@RequestMapping("/chat")
public String chat(String message) {
return chatModel.chat(message);
}
}
2.3. AiServices 工具类
引入依赖
xml
<!--AiServices相关的依赖-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-spring-boot-starter</artifactId>
<version>1.10.0-beta18</version>
</dependency>接口类
java
package com.itheima.consultant.aiservice;
public interface ConsultantService {
// 聊天
public String chat(String message);
}配置类
java
package com.itheima.consultant.config;
import com.itheima.consultant.aiservice.ConsultantService;
import dev.langchain4j.model.openai.OpenAiChatModel;
import dev.langchain4j.service.AiServices;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class CommonConfig {
@Autowired
private OpenAiChatModel chatModel;
@Bean
public ConsultantService consultantService() {
return AiServices.builder(ConsultantService.class)
.chatModel(chatModel)
.build();
}
}
java
package com.itheima.consultant.controller;
import com.itheima.consultant.aiservice.ConsultantService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class ChatController {
@Autowired
private ConsultantService consultantService;
@RequestMapping("/chat")
public String chat(String message) {
return consultantService.chat(message);
}
}上面是通过配置类构建代理类,接下来还有声明式使用。将配置类里的Bean注释掉,在接口类添加@AiService注解。
java
package com.itheima.consultant.aiservice;
import dev.langchain4j.service.spring.AiService;
import dev.langchain4j.service.spring.AiServiceWiringMode;
@AiService(
wiringMode = AiServiceWiringMode.EXPLICIT, // 手动装配
chatModel = "openAiChatModel"
)
//@AiService
public interface ConsultantService {
// 聊天
public String chat(String message);
}2.4. 流式调用
上述模型使用的是阻塞式调用,等待总结果返回;流式调用是一边算一边回答。
引入依赖
xml
<!--引入流式调用相关的依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-reactor</artifactId>
<version>1.10.0-beta18</version>
</dependency>配置
yaml
streaming-chat-model:
base-url: https://dashscope.aliyuncs.com/compatible-mode/v1
api-key: ${API-KEY}
model-name: qwen-plus
log-requests: true
log-responses: true接口类
java
@AiService(
wiringMode = AiServiceWiringMode.EXPLICIT, // 手动装配
chatModel = "openAiChatModel",
streamingChatModel = "openAiStreamingChatModel"
)
public interface ConsultantService {
public Flux<String> chat(String message);
}Controller类
java
@RequestMapping(value = "/chat", produces = "text/html;charset=utf-8")
public Flux<String> chat(String message) {
return consultantService.chat(message);
}
2.5. 消息注解
| 注解 | 概念 | 用法 | 小例子 |
|---|---|---|---|
@SystemMessage |
系统级指令,定义模型身份、行为规范和回答风格 | 放规则、角色设定、输出格式约束、能力边界 | "你是一名医学影像AI,只能基于循证医学回答,输出为结构化要点" |
@UserMessage |
用户级消息,提供本轮具体任务或输入 | 放问题、业务请求、参数、上下文数据 | "分析这张甲状腺超声图像的可疑特征" |
java
@SystemMessage(fromResource = "system.txt")
public Flux<String> chat(String message);2.6. 会话记忆
配置类添加
java
@Configuration
public class CommonConfig {
@Autowired
private OpenAiChatModel chatModel;
@Bean
public ChatMemory chatMemory() {
return MessageWindowChatMemory.builder()
.maxMessages(10)
.build();
}
}
java
@AiService(
wiringMode = AiServiceWiringMode.EXPLICIT, // 手动装配
chatModel = "openAiChatModel",
streamingChatModel = "openAiStreamingChatModel",
chatMemory = "chatMemory" // 配置会话记忆功能
)
public interface ConsultantService {
@SystemMessage(fromResource = "system.txt")
public Flux<String> chat(String message);
}2.6.1. 会话记忆隔离
在配置类中加入Bean
java
@Bean
public ChatMemoryProvider chatMemoryProvider() {
return new ChatMemoryProvider() {
@Override
public ChatMemory get(Object memoryId) {
return MessageWindowChatMemory.builder()
.id(memoryId)
.maxMessages(20)
.build();
}
};
}
java
@AiService(
wiringMode = AiServiceWiringMode.EXPLICIT, // 手动装配
chatModel = "openAiChatModel",
streamingChatModel = "openAiStreamingChatModel",
chatMemoryProvider = "chatMemoryProvider"
)
public interface ConsultantService {}
java
@RequestMapping(value = "/chat", produces = "text/html;charset=utf-8")
public Flux<String> chat(String memoryId, String message) {
return consultantService.chat(memoryId, message);
}2.6.2. 会话记忆持久化
使用docker启动redis
shell
docker run --name redis -d -p 6379:6379 redis引入依赖
xml
<!--redis依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>配置redis连接
yaml
spring:
data:
redis:
host: 127.0.0.1
port: 6379创建一个类用于存储持久化redis数据
java
package com.itheima.consultant.repository;
import dev.langchain4j.data.message.ChatMessage;
import dev.langchain4j.data.message.ChatMessageDeserializer;
import dev.langchain4j.data.message.ChatMessageSerializer;
import dev.langchain4j.store.memory.chat.ChatMemoryStore;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Repository;
import java.util.List;
import java.util.concurrent.TimeUnit;
@Repository
public class RedisChatMemoryStore implements ChatMemoryStore {
private static final Logger log = LoggerFactory.getLogger(RedisChatMemoryStore.class);
// 注入RedisTemplate
@Autowired
private StringRedisTemplate redisTemplate;
/**
* 获取会话消息
*
* @param memoryId
* @return
*/
@Override
public List<ChatMessage> getMessages(Object memoryId) {
// 从Redis中获取json数据
String json = redisTemplate.opsForValue().get(memoryId.toString());
if (json == null) {
return List.of();
}
// 把json数据转换成List<ChatMessage>
try {
return ChatMessageDeserializer.messagesFromJson(json);
} catch (Exception e) {
log.error("Failed to deserialize chat messages from Redis: {}", e.getMessage());
return List.of();
}
}
/**
* 更新会话消息
*
* @param memoryId
* @param list
*/
@Override
public void updateMessages(Object memoryId, List<ChatMessage> list) {
// 把List转换成json数据
String json = ChatMessageSerializer.messagesToJson(list);
// 存储到Redis中
redisTemplate.opsForValue().set(memoryId.toString(), json, 1, TimeUnit.DAYS);
}
/**
* 删除会话消息
*
* @param memoryId
*/
@Override
public void deleteMessages(Object memoryId) {
redisTemplate.delete(memoryId.toString());
}
}注入Bean
java
@Autowired
private ChatMemoryStore redisChatMemoryStore;
@Bean
public ChatMemoryProvider chatMemoryProvider() {
return new ChatMemoryProvider() {
@Override
public ChatMemory get(Object memoryId) {
return MessageWindowChatMemory.builder()
.id(memoryId)
.maxMessages(20)
.chatMemoryStore(redisChatMemoryStore)
.build();
}
};
}
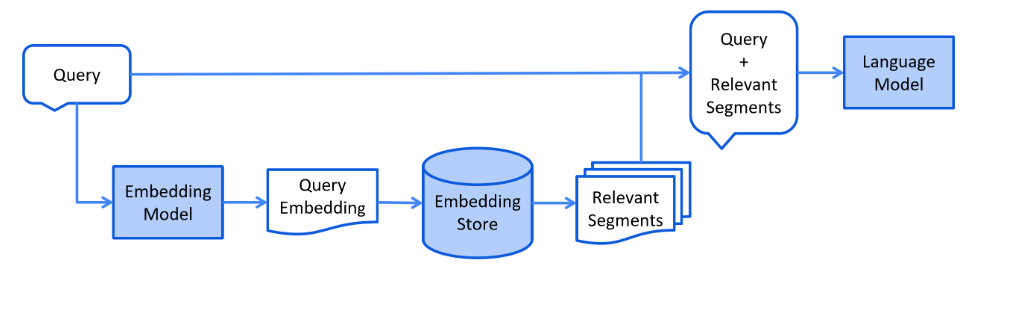
3. LangChain4j RAG
RAG(Retrieval Augmented Generation)检索增强生成,通过检索外部知识库的方式增强大模型的生成能力。
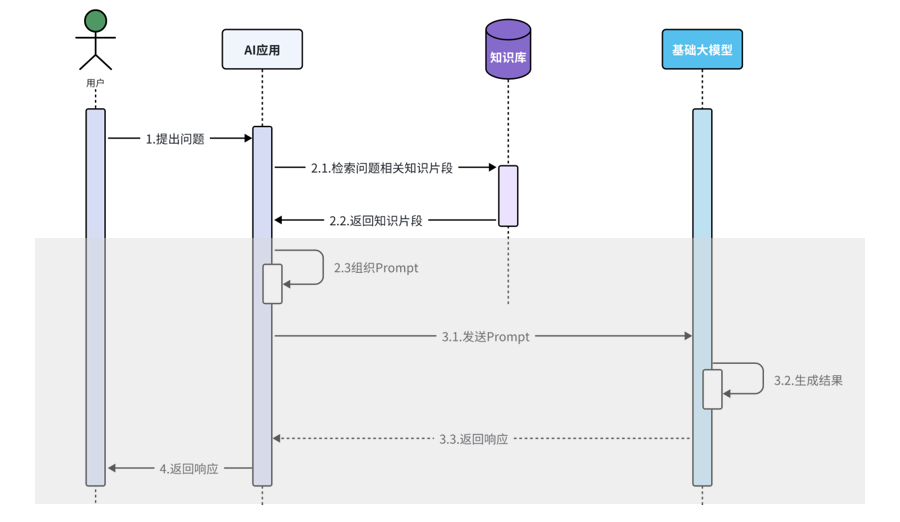
知识库:向量数据库,包括 Milvus、Chroma、Pinecone、RedisSearch(Redis)、pgvector(PostgreSQL)。
3.1. RAG 知识库原理

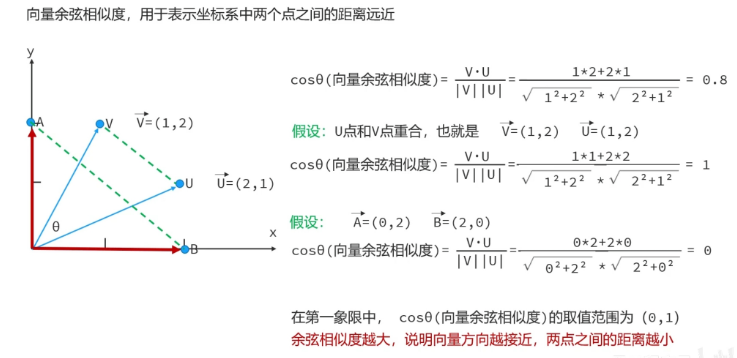

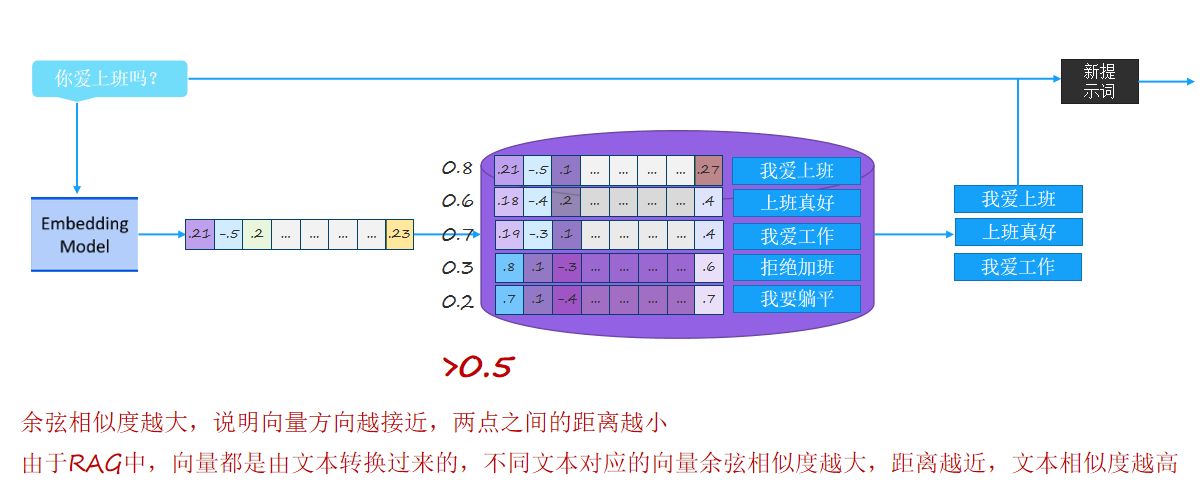
RAG核心原理是通过"语义向量化管理外部知识 + 相似检索结合大模型生成",解决大模型知识过时、回答不可靠的问题。首先在知识预处理阶段,为了适配嵌入模型的处理能力并保留文本语义完整性,将"我爱上班、上班真好"这类原始文档拆分为独立短句片段;再通过嵌入模型将每个片段转换为能表征语义的数值向量,其原理是利用模型将文本的语义信息映射到统一的向量空间,使语义相近的文本对应向量的"方向"更一致;随后将"片段 - 向量"对存入向量库,利用向量库的高效相似检索能力存储这些语义化的知识。当用户发起"你爱上班吗"的查询时,先通过同一嵌入模型将问题转化为同向量空间的查询向量(Query)(保证语义计算的一致性),再基于余弦相似度原理(向量夹角越小,相似度数值越高,对应文本语义越接近),从向量库中筛选出相似度达标的相关片段(如图中筛选出 > 0.5 的"我爱上班"等内容);最后将"用户查询 + 检索到的相关外部片段"组合为提示词输入大语言模型,让模型基于这些精准匹配的外部知识生成回答,以此实现"用外部知识库增强大模型生成能力"的核心目标。
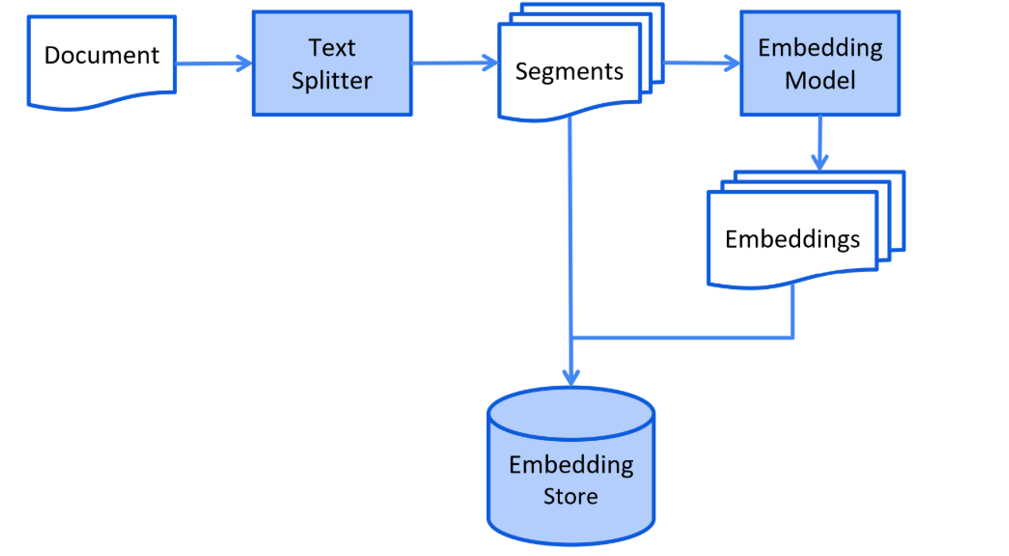
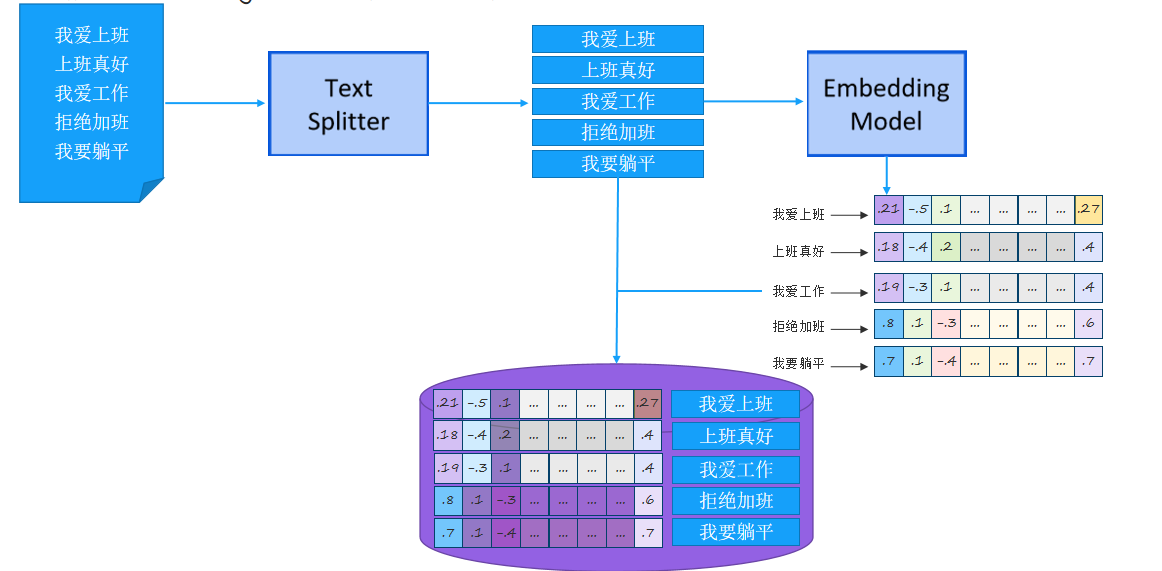
3.2. RAG 快速入门
引入向量数据库依赖
xml
<!--rag-easy依赖-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-easy-rag</artifactId>
<version>1.10.0-beta18</version>
</dependency>配置类添加Bean
java
// 构建向量数据库操作对象
@Bean
public EmbeddingStore store() {
// 加载文档进内存
List<Document> documents = ClassPathDocumentLoader.loadDocuments("content");
// 构建向量数据库操作对象
InMemoryEmbeddingStore<TextSegment> store = new InMemoryEmbeddingStore<>();
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
.embeddingStore(store)
.build();
ingestor.ingest(documents);
return store;
}
// 构建向量数据库检索对象
@Bean
public ContentRetriever contentRetriever(EmbeddingStore store) {
return EmbeddingStoreContentRetriever.builder()
.embeddingStore(store)
.maxResults(3)
.minScore(0.6)
.build();
}
3.3. 核心 API
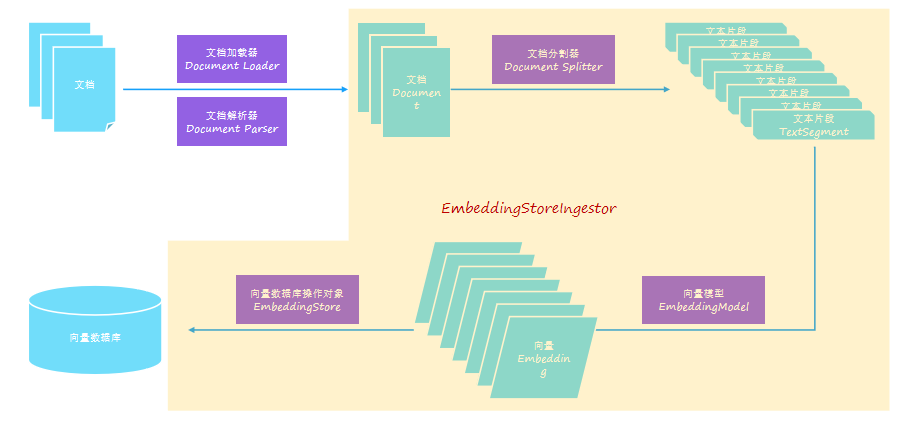
3.3.1. 文档加载器
用于把磁盘或网络中的数据加载进程序。
- FileSystemDocumentLoader:根据本地磁盘绝对路径加载
- ClassPathDocumentLoader:相对于类路径加载
- UrlDocumentLoader:根据url路径加载
3.3.2. 文档解析器
用于解析使用文档加载器加载进内存的内容,把非纯文本数据转化成纯文本。
- TextDocumentParser:解析纯文本格式的文件
- ApachePdfBoxDocumentParser:解析pdf格式文件
- ApachePoiDocumentParser:解析微软的office文件,例如DOC、PPT、XLS
- ApacheTikaDocumentParser(默认):几乎可以解析所有格式的文件
引入pdf解析器依赖
xml
<!--pdf解析器依赖-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-document-parser-apache-pdfbox</artifactId>
<version>1.10.0-beta18</version>
</dependency>
3.3.3. 文档分割器
用于把一个大的文档,切割成一个一个的小片段。
- DocumentByParagraphSplitter:按照段落分割文本
- DocumentByLineSplitter:按照行分割文本
- DocumentBySentenceSplitter:按照句子分割文本
- DocumentByWordSplitter:按照固定数量的字符分割文本
- DocumentByRegexSplitter:按照正则表达式分割文本
- DocumentSplitters.recursive(...)(默认):递归分割器,优先段落分割,再按照行分割,再按照句子分割,再按照词分割
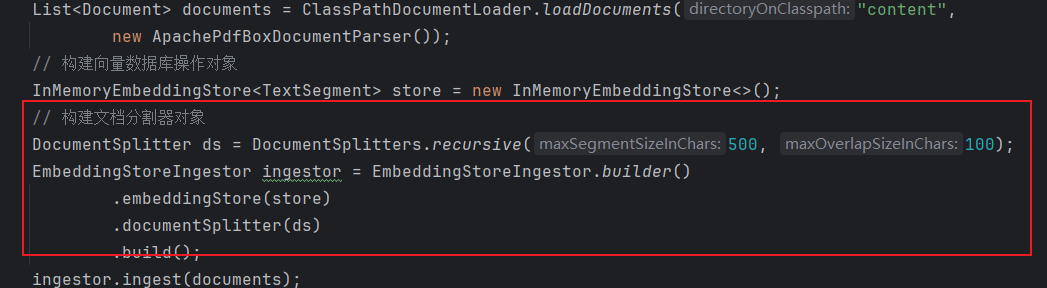
3.3.4. 向量模型
用于把文档分割后的片段向量化或者查询时把用户输入的内容向量化。
配置向量模型
yaml
embedding-model:
base-url: https://dashscope.aliyuncs.com/compatible-mode/v1
api-key: ${API-KEY}
model-name: text-embedding-v3
log-requests: true
log-responses: true
max-segments-per-batch: 10注入向量模型
java
@Autowired
private EmbeddingModel embeddingModel;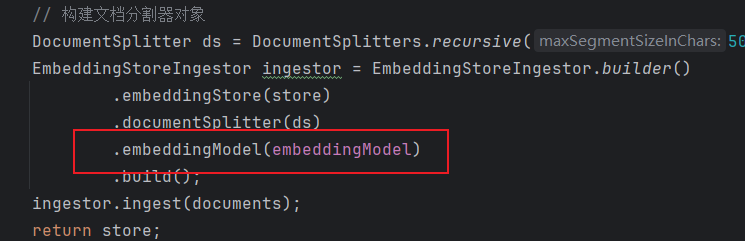
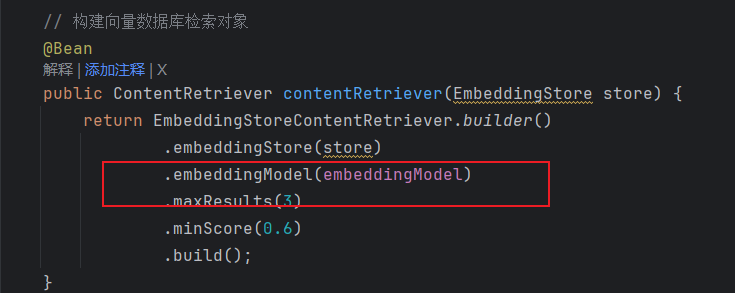
3.3.5. EmbeddingStore
用于操作向量数据库(添加、检索)。
准备向量数据库
shell
docker run --name redis-vector -d -p 6379:6379 redislabs/redisearch引入依赖
xml
<!--引入langchain4j对于redis向量数据库的支持-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-redis-spring-boot-starter</artifactId>
<version>1.0.1-beta6</version>
</dependency>配置信息
yaml
langchain4j:
community:
redis:
host: 127.0.0.1
port: 6379注入
java
@Autowired
private RedisEmbeddingStore redisEmbeddingStore;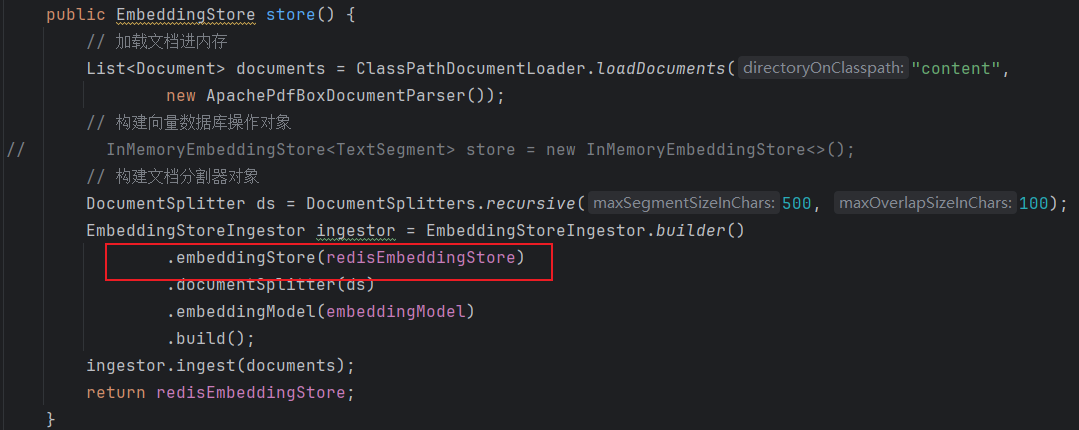

4. Tools 工具
4.1. 准备工作
先启动mysql,创建数据库
sql
create database if not exists volunteer;
use volunteer;
create table if not exists reserevation
(
id bigint primary key auto_increment not null comment '主键ID',
name varchar(50) not null comment '考生姓名',
gender varchar(2) not null comment '性别',
phone varchar(20) not null comment '手机号',
communication_time datetime not null comment '沟通时间',
province varchar(32) not null comment '考生所处的省份',
estimated_score int not null comment '考生预估分数'
)引入依赖
xml
<!--lombok-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<!--mybatis-->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>3.0.3</version>
</dependency>
<!--mysql-->
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
</dependency>配置信息
yaml
spring:
datasource:
url: jdbc:mysql://localhost:3306/volunteer?useUnicode=true&characterEncoding=uft-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
username: root
password: 123456
driver-class-name: com.mysql.cj.jdbc.Driver
mybatis:
configuration:
map-underscore-to-camel-case: true新建实体类:
java
package com.itheima.consultant.pojo;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.time.LocalDateTime;
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Reservation {
private Long id;
private String name;
private String gender;
private String phone;
private LocalDateTime communicationTime;
private String province;
private Integer estimatedScore;
}Mapper
java
package com.itheima.consultant.mapper;
import com.itheima.consultant.pojo.Reservation;
import org.apache.ibatis.annotations.Insert;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Select;
@Mapper
public interface ReservationMapper {
@Insert("insert into reservation(name, gender, phone, communication_time, province, estimated_score) " +
"values (#{name}, #{gender}, #{phone}, #{communicationTime}, #{province}, #{estimatedScore})")
void insert(Reservation reservation);
@Select("select * from reservation where phone = #{phone}")
Reservation findByPhone(String phone);
}Service
java
package com.itheima.consultant.service;
import com.itheima.consultant.mapper.ReservationMapper;
import com.itheima.consultant.pojo.Reservation;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
@Service
public class ReservationService {
@Autowired
private ReservationMapper reservationMapper;
public void insert(Reservation reservation) {
reservationMapper.insert(reservation);
}
public Reservation findByPhone(String phone) {
return reservationMapper.findByPhone(phone);
}
}4.2. 原理
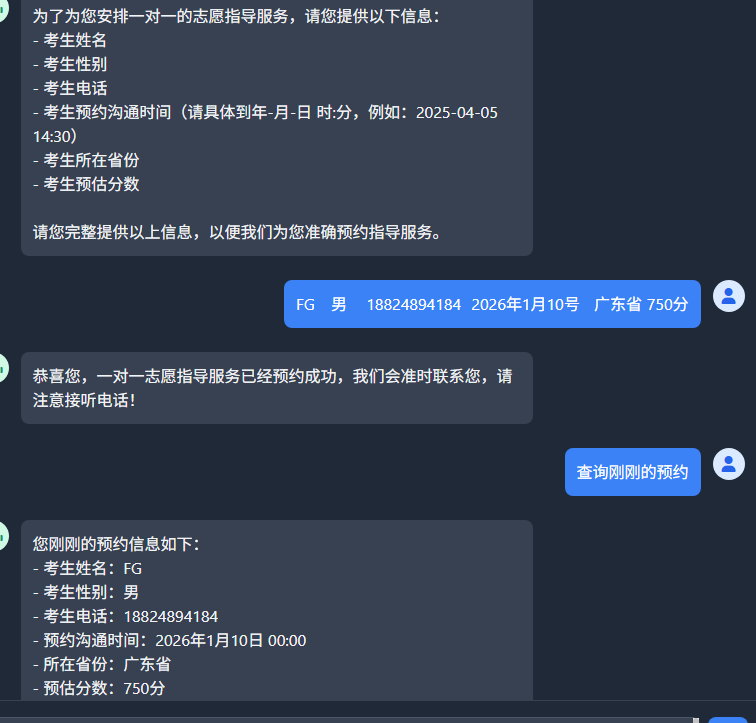
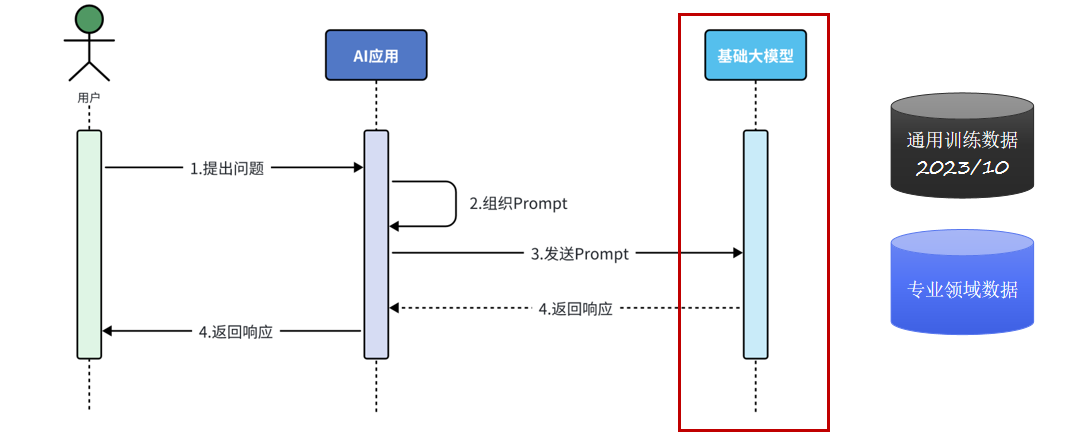
用户向AI应用提交自然语言查询后,AI应用会将查询与工具元信息(含Function名称、功能描述、入参schema)组装为包含工具定义的Prompt,提交至基础大语言模型(LLM);大模型执行任务规划与工具匹配,判定需触发函数调用(Function Call)后,向AI应用返回结构化的函数调用指令(含目标工具标识、参数键值对);AI应用解析指令并触发对应的工具函数(Tool Function)执行,获取工具返回的结构化结果,再将该结果封装为上下文补充至Prompt,发起新一轮Prompt请求;这一"大模型决策调用 → AI应用执行工具 → 结果回传拼接"的多轮交互循环会重复执行,直至大模型判定任务完成;最终大模型结合工具执行结果与自然语言生成能力构造最终回答,通过AI应用回馈给用户。

工具类
java
package com.itheima.consultant.tools;
import com.itheima.consultant.pojo.Reservation;
import com.itheima.consultant.service.ReservationService;
import dev.langchain4j.agent.tool.P;
import dev.langchain4j.agent.tool.Tool;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import java.time.LocalDateTime;
@Component
public class ReservationTool {
@Autowired
private ReservationService reservationService;
// 添加预约信息
@Tool(name = "添加志愿指导服务预约")
public void addReservation(
@P("考生姓名") String name,
@P("考生性别") String gender,
@P("考生手机号") String phone,
@P("沟通时间,格式为:yyyy-MM-dd HH:mm") LocalDateTime communicationTime,
@P("考生所在省份") String province,
@P("考生预估分数") Integer estimatedScore
) {
reservationService.insert(new Reservation(null, name, gender, phone, communicationTime, province, estimatedScore));
}
// 根据手机号查询预约信息
@Tool(name = "根据手机号查询志愿指导服务预约")
public Reservation getReservationByPhone(@P("考生手机号") String phone) {
return reservationService.findByPhone(phone);
}
}