简介
查询的本质,是在一堆数据中,找出自己想要的数据,几乎是所有信息化系统都具备的功能。
本文介绍在程序设计中,或者在系统开发中,几种常见的查询方式及特点。
(1)顺序查询
顺序查询,即遍历所有元素,判断当前元素是否为自己想要的。
在程序设计语言中,通过循环语句加判断语句,如 Java
java
List<Integer> data = List.of(1,2,3,4);
for (Integer datum : data) {
if (datum == 2) {
System.out.println("这是我想要的元素 = " + data);
}
}顺序查询的优点是能随机访问,就是能通过下标或者说序号访问元素。
这也是它底层实现的特点使其具备的优点,顺序存储可以使其在内存中占有一段连续的空间,如上面的"1,2,3,4",一个数占 4 个字节,那么想要访问第 3 个元素,只需访问起始位置的内存地址 + 3个元素的偏移量,就能直接访问到第 3 个元素。
在 Java 中,实现 RandomAccess 接口的容器具备了这个特点。
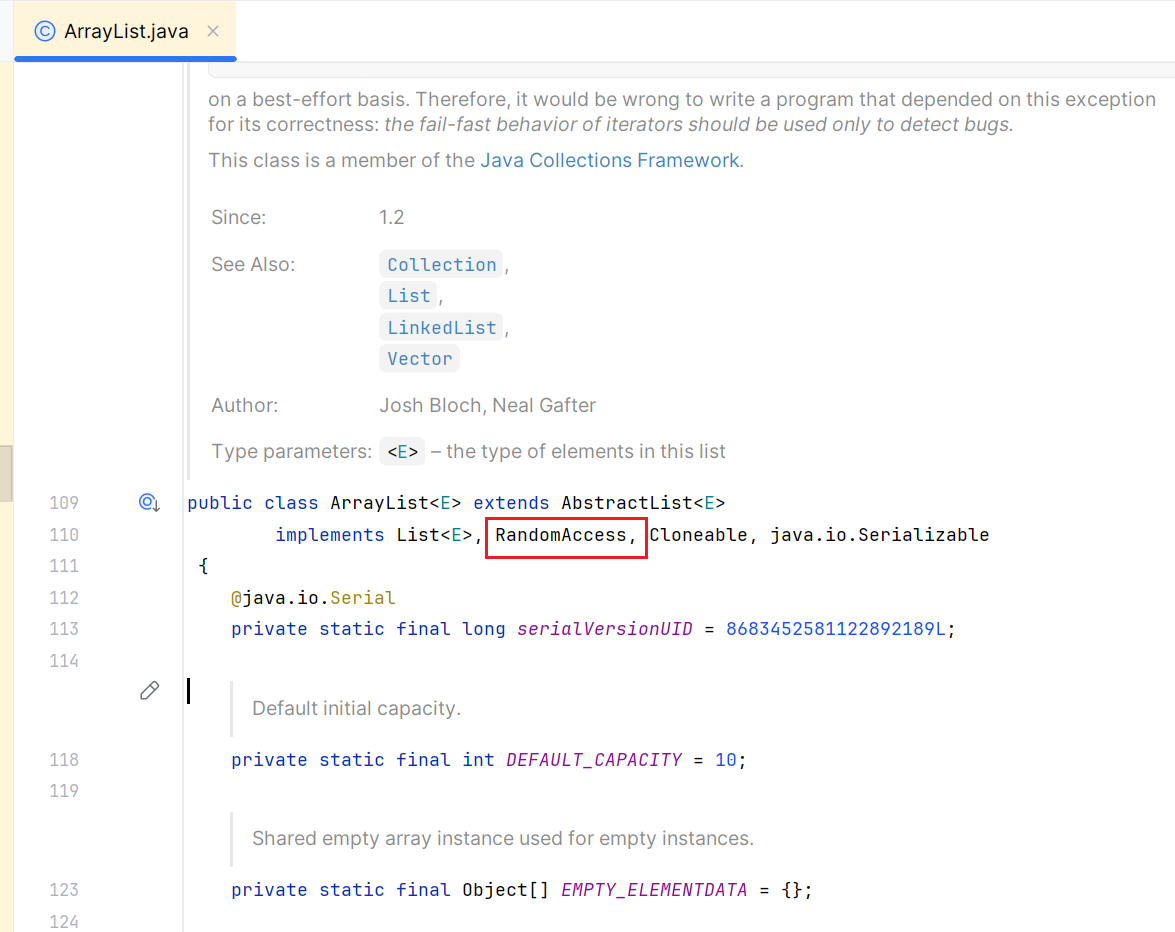
当然,随机访问需要容器占有一段连续的内存空间,这肯定会造成内存使用率不高,会有碎片的内存空间,相对的,就有了链表的数据结构,通过给单个元素增加引用节点,可以将多个碎片化的内存空间使用起来,可以提高内存使用率,但同时单个元素除了要存数据,还要存引用,单个元素就会占用更高的内存。
集合和链表,也是一种平衡和取舍。
(2)哈希查询
哈希查询,在存储元素时,使用元素的值给每一个元素生成一个唯一 ID,查询时,通过 ID,直接查询。
比如元素"张三的信息,李四的信息,王五的信息,赵六的信息",我们写一个"哈希算法",这个算法的作用是,**传入的值相同,会得到一个一模一样的返回值。**存入时,用"张三"为哈希算法入参,得到一个返回值,将张三的信息存入到这个返回值的地址上,查询时,同理,用"张三"为入参,得到返回值,获取这个返回值地址上的值。
这个查询的效率也是杠杠的,在 Java 中,HashMap 时哈希查询的一种实现,在开发中,我们为了避免循环查询数据库,降低接口耗时,常常将所需要的数据库数据一次性查出来,再使用 HashMap 组装起来,通过 .get(key) 的方式直接获取指定元素。
(循环查询)
java
List<String> data = List.of("张三", "李四", "王五", "赵六");
for (String datum : data) {
// 查询数据库
UserInfo userInfo = dataMapper.selectByUsername(data);
// 继续其他的业务
.......
}(哈希查询)
java
List<String> data = List.of("张三", "李四", "王五", "赵六");
// 一次性查出所有
List<UserInfo> userInfoList = dataMapper.selectAll(data);
// 组装 HashMap
Map<String, UserInfo> userInfoMap = new HashMap<>();
for (UserInfo userInfo : userInfoList) {
userInfoMap.put(userInfo.getUsername(), userInfo);
}
for (String datum : data) {
// 取元素时,直接 get(datum) 即可
UserInfo userInfo = userInfoMap.get(datum);
// 继续其他的业务
.......
}哈希查询的缺点时,它无法做到范围查询,比如查询 id > 2 的元素,就只能循环查询,挨个判断。所以数据库就不能采用这种设计(当然还有众多因素的考虑),数据库需要支持多种数据类型的存储和查询,范围查询很常见。
(3)二叉树查询
二叉树查询,通过树状结构,将元素按照一定的算法逻辑存储,查询时按照树的存储逻辑查询。
以平衡二叉树为例(AVL),将一堆元素按照"左小右大"的特点存储,如下图,80 > 40,存在右边,8 < 40,存在左边,每个元素都是如此,此时再存入一个元素,如 4,
-
4 < 40,存左边
-
4 < 8,存左边
-
4 > 3,存右边
-
4 < 5,存左边,最后元素 4,就存在了
如下:

查询逻辑也是一样的,因为整个结构都是有序的,就是二分查询。
(4)分词查询
分词查询,最典型的技术是 Elasticsearch,存入时将数据拆分成多个小的片段,查询时,将查询的内容也进行拆分,用拆分后的片段进行匹配,找到所需要的记录。
如,这是一段关于查询的文章,被拆分成"这是","一段","关于","查询","的","文章"片段,当用关键词"查询的文章"检索时,"查询的文章",也被被拆分成,"查询","的","文章",最终查询的结果,也就是片段的匹配结果,某条记录片段匹配的数量越多,说明查询结果的匹配度越高,也就最符合查询结果。
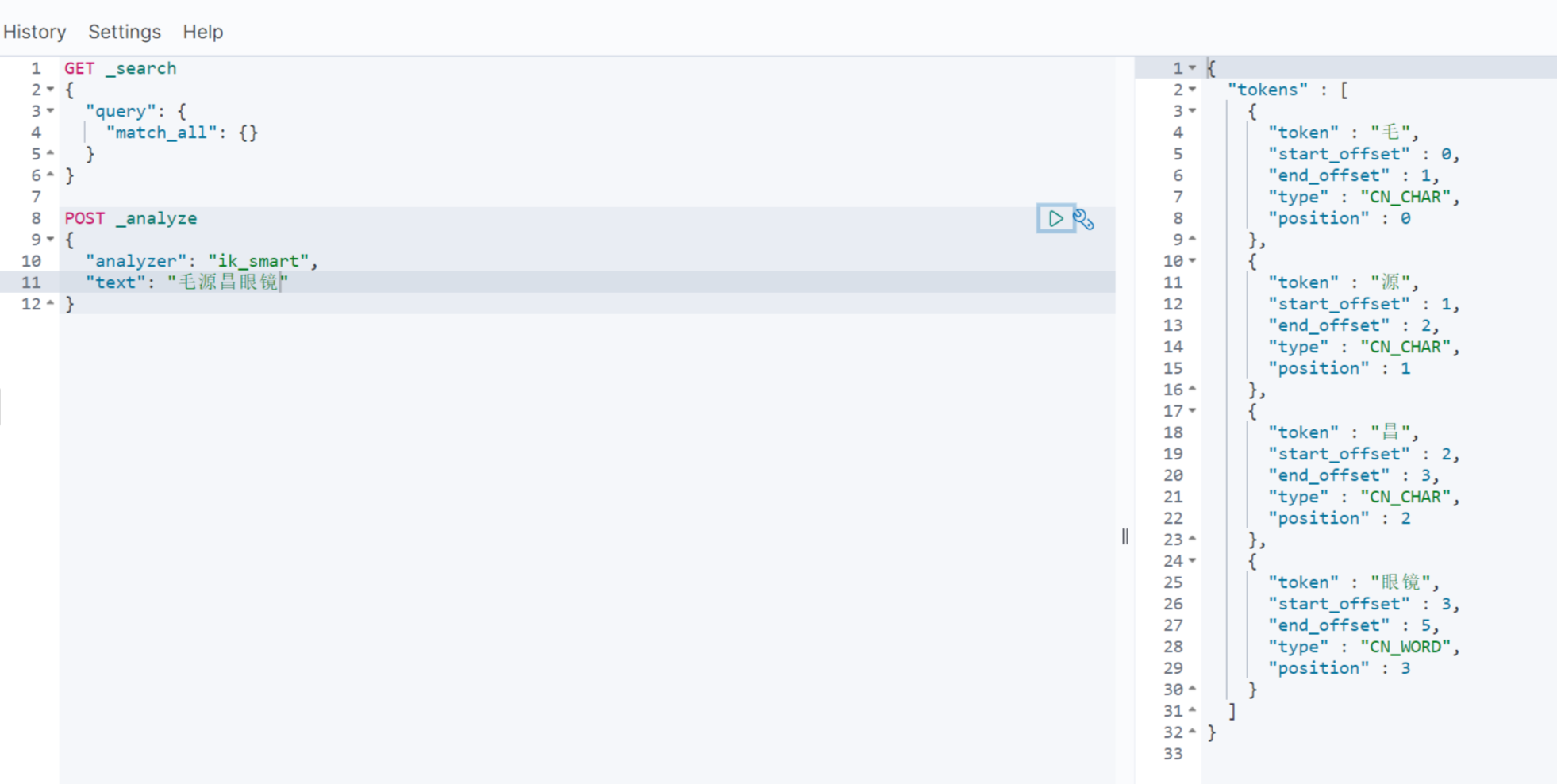
这就是分词查询的实现思想,当然还有细节,如分词算法,某些名牌名称不应该被分词,如 "毛源昌眼镜","毛源昌"不应该被分为"毛","源","昌";还有分词后的匹配算法,也有相关的权重计算,最终查询结果是片段匹配 + 权重的结果。
(5)写入查询
写入查询,是查询思想的一个转变,当要查询某条记录是否存在时,不去直接查询这条记录,而是通过写入的方式来查询。
举个例子,某数据库表中,要查符合某些条件的记录是否存在,可以直接拼接条件查询,判断查询结果。也可以将这些条件设置成一个组合唯一约束,如果能成功写入,说明记录不存在,不能说明记录已存在。实际开发中,MySQL 有快照读和本地读的机制,高并发读写可能会出现读到的不是最新的记录,而通过写入查询就能避免这问题。(在避免 MQ 重复消费消息时会用得上,记录消费记录,每次消费前写入一条记录,能成功写入表示未被消费)
除此之外,分布式锁也是一种体现,能不能获取锁,通过写入来判断。这个写入操作可以是 Redis、MySQL、Zookeeper,甚至是文件操作------能不能生成某个文件,能生成就获取锁。
总结
顺序查询:最常用,最符合人脑思考。
哈希查询:非常高效,要善于使用。
二叉树查询:可以范围查询,设计得好,用起来就好,如 MySQL 底层实现。
分词查询:海量数据的模糊查询场景,如社交、电商平台。
写入查询:高并发读场景,考虑使用改读为写。