在传统数据分析流程中,我们通常需要手动编写 SQL 或 Pandas 代码来回答业务问题。这不仅对非技术人员不友好,而且每次分析过程都难以复用。随着大模型能力的增强,我们终于可以构建一种全新的范式:让 AI 像分析师一样思考,让代码像工程师一样执行。
本教程将带你使用 DeepSeek V3.2 Speciale 构建一个真正可落地的 AI 数据分析代理(Data Analysis Agent)。它可以挂载在任意 CSV 数据之上,让用户直接用自然语言提问,并自动完成分析、可视化与洞察总结。
🧠 一、什么是 DeepSeek V3.2 Speciale?
DeepSeek V3.2 Speciale 是 DeepSeek V3.2 家族中面向高计算推理场景的强化版本。它并不是为闲聊设计,而是专门用于复杂规划、工具调用和多步骤推理任务。
该模型通过增强强化学习训练,在复杂推理基准上表现突出,整体能力可以对标 Gemini 3 Pro 等高端模型,并在 IMO、CMO、ICPC World Finals、IOI 2025 等权威算法竞赛任务中取得金牌级成绩。这使得它天然适合构建:
-
多步骤 Agent 系统
-
复杂工具编排工作流
-
自动化分析与决策系统
你可以把它理解为:一个会"先想清楚再动手"的工程型模型。
🚀 二、项目目标与整体架构
在本项目中,我们希望构建一个真正工程化的 AI 分析系统,整体流程如下:
用户上传 CSV 文件,并用自然语言提出问题;规划代理读取数据结构和问题,将其转化为结构化 JSON 分析计划;Python 工具根据计划执行真实的数据计算与可视化;最后,解释代理将结果转化为业务洞察总结。最终,我们将得到一个:可复现 + 可解释 + 可扩展 的 Streamlit AI 数据分析应用。
这种架构遵循经典的 Tool-Augmented Agent 设计范式:模型负责"思考",工具负责"执行",前端负责"呈现"。
🏗️ 三**、**环境准备
1.构建独立运行环境
在正式编写代码之前,我们首先需要为项目创建一个独立的 Python 虚拟环境并安装依赖,避免不同项目之间的依赖冲突。在终端中执行以下命令:
python3 -m venv my_env
source my_env/bin/activate
pip install streamlit pandas matplotlib seaborn python-dotenv openai2.获取 DeepSeek API 密钥
要开始使用 DeepSeek v3.2 Speciale,你首先需要获取 API 密钥。请按照以下步骤操作:
-
访问平台:在浏览器中打开 platform.deepseek.com
-
注册账户:如果你还没有 DeepSeek 账户,点击"注册"按钮创建新账户。你可以使用电子邮箱或第三方平台账号进行注册。
-
完成验证:按照页面提示完成邮箱验证或手机验证流程。
-
进入 API 管理:登录成功后,在控制台界面中找到"API 密钥"或"API Keys"管理页面。
-
创建新密钥 :点击"创建新的 API 密钥"按钮,系统会生成一个以
sk-开头的密钥字符串。 -
安全保存 :重要提示:立即将 API 密钥复制并保存到安全的地方,因为这个密钥只会在创建时显示一次。
3.配置 API 密钥到环境文件
现在我们需要将刚才获取的 DeepSeek API 密钥安全地存储到项目的环境配置文件中。请按照以下步骤操作:
-
创建或编辑环境文件 :在项目根目录下,使用终端命令创建或编辑
.env文件:vi .env -
进入编辑模式 :按
i键切换到输入模式(你会看到左下角显示-- INSERT --提示) -
输入 API 密钥 :在文件中添加以下内容(将
your_api_key_here替换为你实际获取的密钥):DEEPSEEK_API_KEY=your_api_key_here -
保存并退出:
-
按
Esc键退出输入模式 -
输入
:wq并按回车键执行保存并退出
-
现在你已经准备好了访问 DeepSeek v3.2-Speciale 模型的通行证!
⚡ 四**、**基础配置
在代码开始部分,我们首先完成可视化风格、中文字体处理以及 API 初始化。我们统一使用 Seaborn + Matplotlib 的暗色网格风格,让图表更具可读性。同时显式指定中文字体,防止在图表标题、坐标轴中出现乱码问题。这一步在中文数据场景中非常关键,否则可视化结果将无法直接用于业务汇报。
接着通过 dotenv 加载 .env 文件中的 API Key,并初始化 DeepSeek 客户端。这样做的好处是避免将密钥硬编码进代码中,更符合工程安全规范。到这里,我们已经拥有了一个可以随时调用 DeepSeek V3.2 Speciale 的客户端对象,为后续构建 Agent 做好准备。
import io
import json
import os
import re
from datetime import datetime
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
import streamlit as st
from dotenv import load_dotenv
from openai import OpenAI
plt.style.use('seaborn-v0_8-darkgrid')
sns.set_palette("husl")
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei', 'Arial Unicode MS', 'sans-serif']
plt.rcParams['axes.unicode_minus'] = False
load_dotenv()
DEEPSEEK_API_KEY = os.getenv("DEEPSEEK_API_KEY")
DEEPSEEK_BASE_URL = os.getenv("DEEPSEEK_BASE_URL", "https://api.deepseek.com")
ifnot DEEPSEEK_API_KEY:
st.warning("⚠️ 未检测到 DEEPSEEK_API_KEY 环境变量,请在 .env 文件中配置。")
client = OpenAI(
api_key=DEEPSEEK_API_KEY,
base_url=DEEPSEEK_BASE_URL,
)📊 五、构建规划代理(Planner Agent)
有了客户端之后,我们首先构建规划代理(Planner Agent)。它的核心职责非常明确:决定"对数据做什么分析"。
这里我们采用一个非常重要的设计原则:
❌ 不允许模型直接操作 DataFrame
✅ 只允许模型输出结构化 JSON 计划
这样做的意义在于:
模型负责"想方案",而不是"动数据"。所有真实的数据操作都由 Python 执行,既安全又可控,同时让整个分析流程完全可复现。在实现上,我们为模型设计了一个严格约束的系统提示词,明确规定输出格式。
defcall_planner_llm(schema_text: str, question: str) -> tuple[dict, str]:
system_prompt = """
你是一个数据分析规划器。请将用户的问题转换为 JSON 格式的执行计划。
JSON 结构要求(必须严格遵守):
{
"operation": "group_by_summary",
"group_by": ["列名"],
"filters": [],
"target_column": "要分析的列名",
"metric": "sum",
"need_chart": true,
"chart_type": "bar"
}
字段说明:
- operation: 固定使用 "group_by_summary"
- group_by: 分组列名列表(例如 ["产品名称"] 或 ["分类", "地区"])
- filters: 可选过滤器,例如 [{"column": "年份", "op": "==", "value": "2023"}]
- target_column: 要聚合计算的数值列(必须存在于数据集中)
- metric: 聚合方式,可选:sum (求和), mean (平均值), count (计数), max (最大值), min (最小值)
- need_chart: 是否需要图表 (true/false)
- chart_type: 图表类型:bar (柱状图), line (折线图), pie (饼图)
规则:
1. 只能使用数据集中存在的列。
2. 如果提到"今年"或"去年",请参考数据集中的时间列。
3. 简要思考后,仅输出完整的 JSON。
""".strip()
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": f"数据概览:\n{schema_text}\n\n用户问题:\n{question}\n\n请输出 JSON 计划:"},
]
resp = client.chat.completions.create(
model="deepseek-reasoner",
messages=messages,
)
message = resp.choices[0].message
content = message.content or""
reasoning_content = getattr(message, 'reasoning_content', None) or""
defextract_json(text: str) -> dict | None:
try:
return json.loads(text)
except:
match = re.search(r'\{.*\}', text, re.DOTALL)
if match:
try: return json.loads(match.group())
except: returnNone
returnNone
plan = extract_json(reasoning_content) or extract_json(content)
if plan:
return plan, reasoning_content
raise ValueError(f"无法从模型响应中提取 JSON 计划。响应内容:{content[:200]}")当用户提问时,规划器会同时看到两部分信息: 一是数据集的结构描述(列名、类型、样例值),二是用户的自然语言问题。基于这两部分上下文,模型并不会直接给出答案,而是返回一个完整的分析计划,描述:
-
要做什么操作
-
按哪些字段分组
-
是否需要筛选条件
-
统计哪一列
-
使用什么指标
-
是否生成图表以及图表类型
这样一来,我们就成功把"自然语言"转换成了机器可执行的分析指令。
⚖️ 六、数据执行引擎:让 Python 真正干活
拿到 JSON 计划之后,接下来就进入真正的执行阶段。此时模型已经"退居幕后",所有计算都由 Python 完成。
我们首先对数据做一层智能预处理,自动识别包含"日期 / 时间"关键词的字段,将其转换为 datetime 类型,并自动派生出"年份""月份"字段。这样一来,当用户问"去年""按月统计"时,系统可以直接利用这些衍生字段完成分析。
随后我们实现一个通用过滤器执行器,它可以解析 JSON 中的筛选条件,支持等于、大于、小于、包含等常见操作。这一步让模型生成的过滤规则真正落地执行。
当过滤完成后,系统会根据计划中的 group_by 和 metric 参数,动态调用 Pandas 的 groupby + agg 完成统计计算,并自动排序输出结果。这一层相当于一个通用数据执行引擎,完全由结构化指令驱动。
整个过程中,模型不会触碰任何真实数据,只负责给"策略",而 Python 负责"落地执行"。
defget_schema_description(df: pd.DataFrame) -> str:
lines = ["数据集列信息:"]
for col, dtype in df.dtypes.items():
if dtype == 'object'and df[col].nunique() < 15:
samples = df[col].dropna().unique()[:5]
lines.append(f"- {col} ({dtype}) | 样例值: {', '.join(map(str, samples))}")
else:
lines.append(f"- {col} ({dtype})")
return"\n".join(lines)
defpreprocess_dates(df: pd.DataFrame) -> pd.DataFrame:
df = df.copy()
for col in df.columns:
ifany(x in col.lower() for x in ['date', 'time', '日期', '时间']):
try:
df[col] = pd.to_datetime(df[col], errors='coerce')
if df[col].notna().sum() > 0:
df[f'{col}_年份'] = df[col].dt.year
df[f'{col}_月份'] = df[col].dt.month
except: pass
return df
defapply_filters(df: pd.DataFrame, filters: list) -> pd.DataFrame:
ifnot filters: return df
for f in filters:
col, op, val = f.get("column"), f.get("op"), f.get("value")
if col notin df.columns: continue
try: val = pd.to_numeric(val)
except: pass
if op == "==": df = df[df[col] == val]
elif op == ">": df = df[df[col] > val]
elif op == "<": df = df[df[col] < val]
elif op == "contains": df = df[df[col].astype(str).str.contains(str(val), case=False)]
return df
defrun_analysis_plan(df: pd.DataFrame, plan: dict) -> pd.DataFrame:
target_col = plan.get("target_column")
group_by = plan.get("group_by") or []
metric = plan.get("metric", "sum")
df = apply_filters(df, plan.get("filters", []))
ifnot group_by:
return pd.DataFrame({f"{metric}_{target_col}": [getattr(df[target_col], metric)()]})
res = df.groupby(group_by)[target_col].agg(metric).reset_index()
return res.sort_values(by=target_col, ascending=False)如果 JSON 计划中指定需要图表,我们会自动进入可视化模块。此时系统会根据 chart_type 参数,动态选择柱状图、折线图或饼图。
为了保证展示效果,我们会对数据取 Top N 进行可视化,防止类别过多导致图表不可读。最终生成的图表不会直接保存为文件,而是写入内存缓冲区 BytesIO,再交由 Streamlit 前端展示。
这样设计的好处是:
-
不产生临时文件
-
性能更高
-
更适合 Web 应用部署
def generate_chart(df: pd.DataFrame, plan: dict):
ifnot plan.get("need_chart")or df.empty ornot plan.get("group_by"): return Nonechart_type = plan.get("chart_type", "bar") x_col, y_col = plan["group_by"][0], plan["target_column"] fig, ax = plt.subplots(figsize=(10, 5)) plot_df = df.head(15) if chart_type == "bar": sns.barplot(data=plot_df, x=x_col, y=y_col, ax=ax) elif chart_type == "line": sns.lineplot(data=plot_df, x=x_col, y=y_col, marker='o', ax=ax) elif chart_type == "pie": ax.pie(plot_df[y_col], labels=plot_df[x_col], autopct='%1.1f%%') ax.set_title(f"{y_col} 按 {x_col} 分析") plt.xticks(rotation=45) buf = io.BytesIO() fig.savefig(buf, format="png", bbox_inches='tight') plt.close(fig) return buf
🚄 七、构建解释代理(Explainer Agent)
当表格和图表都生成后,我们进入最后一个智能环节:解释代理(Explainer Agent)。此时模型不再负责规划,而是扮演"资深数据分析师"的角色。我们会把:
-
用户原始问题
-
执行计划
-
真实计算结果
一并传给模型,并要求它输出一段业务级解读,包括:
-
先用 1-2 句话直接回答问题
-
再用自然语言总结关键趋势
-
必须包含具体数值和比例
-
最后给出一个行动建议
最终输出的内容不再是"技术报告",而是可以听得懂的业务结论。这一步非常关键,它让整个系统从"算得对"升级为"说得清"。
defcall_explainer_llm(question: str, plan: dict, result_summary: list) -> tuple[str, str]:
system_prompt = """
你是一位资深数据分析师。你需要向业务人员解释 Python 执行后的分析结果。
要求:
1. 首先用 1-2 句话直接回答用户的问题。
2. 使用项目符号(3-5点)列出核心洞察、趋势或异常发现。
3. 必须包含具体的数值和百分比,让结论更有说服力。
4. 使用通俗易懂的商业语言,避免提及"聚合"、"分组"等技术术语。
5. 最后给出一个简短的行动建议。
""".strip()
user_content = f"问题:{question}\n执行计划:{json.dumps(plan)}\n分析结果:{json.dumps(result_summary[:20])}"
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_content},
]
resp = client.chat.completions.create(
model="deepseek-reasoner",
messages=messages,
)
return (resp.choices[0].message.content, getattr(resp.choices[0].message, 'reasoning_content', ""))🌐 八、Streamlit 前端整合
在前端部分,我们使用 Streamlit 构建一个完整的交互界面。用户可以上传 CSV 文件,实时预览数据结构,并直接输入自然语言问题。当点击"开始分析"后,系统会自动串联完整工作流:
用户问题 → 规划代理 → JSON 计划 → Python 执行 → 图表 → 洞察总结
st.set_page_config(page_title="AI 数据分析助手", layout="wide")
st.markdown("""
<style>
.reportview-container .main .block-container { padding-top: 2rem; }
.insight-box { background-color: #f8f9fa; padding: 20px; border-left: 5px solid #28a745; border-radius: 5px; margin: 10px 0; }
</style>
""", unsafe_allow_html=True)
st.title("📊 AI 数据分析助手")
st.caption("上传 CSV 文件,直接用自然语言提问,AI 自动完成数据处理与可视化。")
uploaded_file = st.file_uploader("选择 CSV 文件", type="csv")
if uploaded_file:
df_raw = pd.read_csv(uploaded_file)
df = preprocess_dates(df_raw)
with st.expander("🔍 数据预览"):
c1, c2, c3 = st.columns(3)
c1.metric("总行数", f"{len(df):,}")
c2.metric("列数", len(df.columns))
c3.metric("内存占用", f"{df.memory_usage().sum()/1024**2:.1f} MB")
st.dataframe(df.head(10))
st.divider()
query = st.text_input("💬 请输入您想了解的问题:", placeholder="例如:去年销售额最高的三个地区是哪里?")
if st.button("开始分析", type="primary") and query:
with st.spinner("AI 正在思考并提取数据..."):
schema = get_schema_description(df)
try:
plan, p_reason = call_planner_llm(schema, query)
with st.expander("🛠️ 查看 AI 分析计划"):
st.write("**推理过程:**")
st.write(p_reason)
st.write("**执行 JSON:**")
st.json(plan)
res_df = run_analysis_plan(df, plan)
st.subheader("📈 分析结果")
col_left, col_right = st.columns([3, 2])
with col_left:
chart_buf = generate_chart(res_df, plan)
if chart_buf: st.image(chart_buf)
else: st.info("该查询不适用图表展示。")
with col_right:
st.dataframe(res_df, use_container_width=True)
with st.spinner("正在生成深度洞察..."):
res_dict = res_df.head(20).to_dict(orient="records")
insight, e_reason = call_explainer_llm(query, plan, res_dict)
st.subheader("💡 AI 深度洞察")
st.markdown(f'<div class="insight-box">{insight}</div>', unsafe_allow_html=True)
with st.expander("查看洞察生成逻辑"):
st.write(e_reason)
except Exception as e:
st.error(f"分析出错:{str(e)}")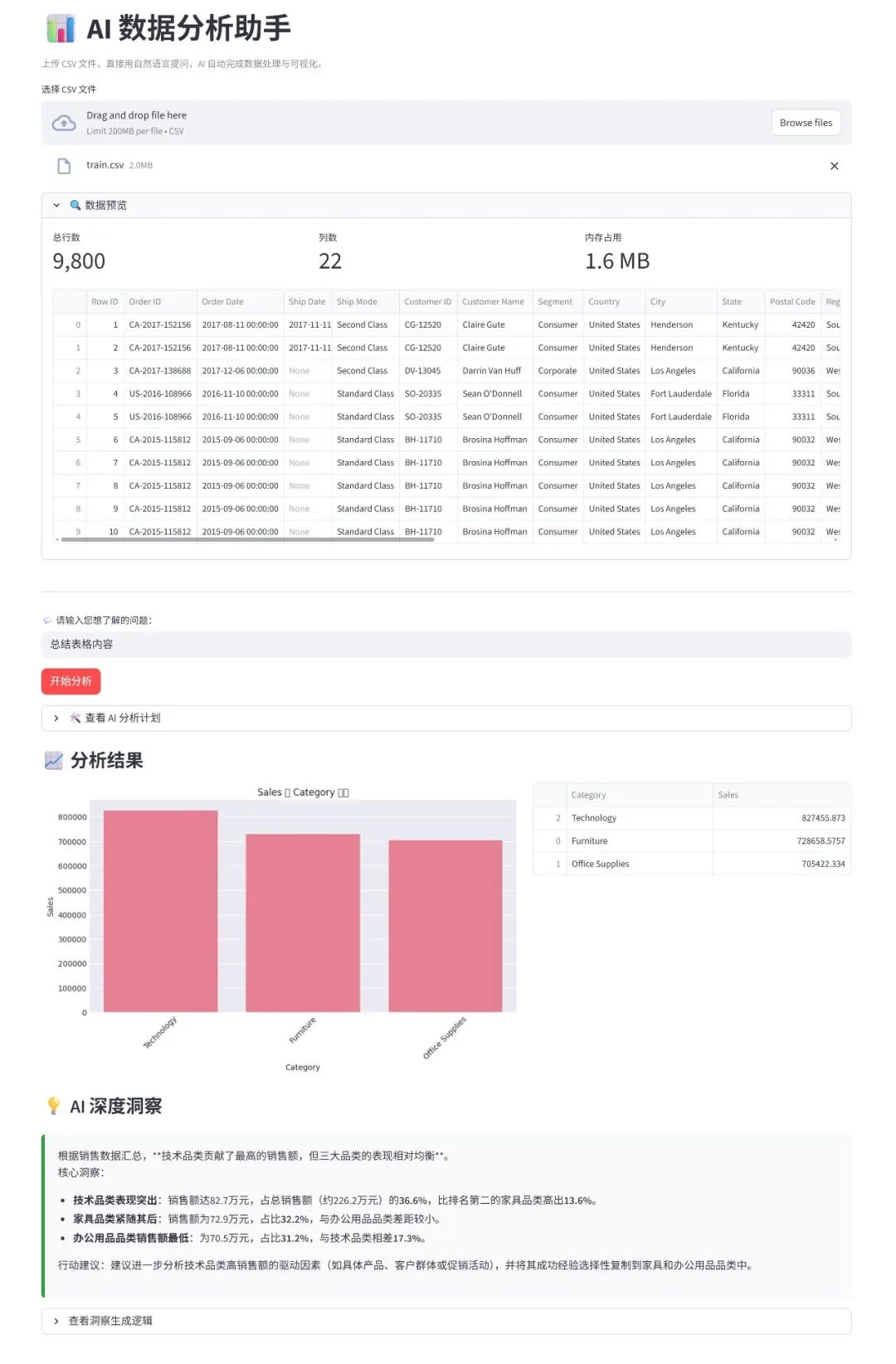
💡 结语
至此,我们已经完整构建了一个基于 DeepSeek V3.2 Speciale 的 AI 数据分析代理。从环境搭建开始,到规划代理将自然语言问题转化为结构化分析计划,再到 Python 工具安全执行分析流程,最终由解释代理输出业务级洞察,我们实现了一套真正可落地的智能分析系统。
这不仅仅是一个"会画图的问答工具",而是一种全新的数据分析范式:让模型负责思考,让程序负责执行,让人专注决策。通过这一项目,你已经掌握了构建 AI Agent 的核心方法论:
-
如何用结构化指令约束大模型
-
如何让工具成为模型的"手"和"脚"
-
如何构建可解释、可复现的智能工作流
-
如何将技术能力产品化落地
更重要的是,这套架构具备极强的扩展性。你可以继续接入数据库、引入多表分析、构建多 Agent 协作系统,甚至打造企业级智能 BI 平台。这些能力,正是未来 AI 应用的核心竞争力。
如果你想进一步深入 AI Agent 体系化建设,欢迎继续探索人工智能代理基础技能轨。本教程只是起点,更精彩的智能系统,正等待你亲手构建。同时,你也可以关注 BitaHub 平台,这里持续汇聚前沿模型实践、工程化教程与真实应用案例,帮助你更高效地落地 AI 项目。