一句话说清楚
MVCC = 多版本并发控制 = 每个事务看到的是数据库在某个时间点的"快照",而不是实时数据。
用一个生活中的例子理解
场景:银行账户余额查询
想象你在银行查询余额:
没有 MVCC 的情况(加锁)
markdown
1. 你开始查询余额:1000元
2. 同时,你老婆在转账:-500元
3. 银行说:"等等!你老婆正在操作,你等会儿再查"
4. 你被阻塞,直到转账完成问题:读操作被写操作阻塞
有 MVCC 的情况
markdown
1. 你开始查询余额:1000元
2. 同时,你老婆在转账:-500元
3. 银行说:"你查你的,她转她的,互不影响"
4. 你看到的是查询开始时的余额:1000元
5. 你老婆转账完成后,余额变成500元
6. 你下次查询才会看到500元优点:读写不冲突,读操作看到的是一致性快照
技术原理(核心概念)
MVCC 主要依赖以下三个关键技术来实现:
1. 数据的三个隐藏字段
InnoDB 引擎会为每一行数据自动添加三个我们看不见的隐藏字段:
- DB_TRX_ID(6字节):最近修改/创建本行数据的事务ID。记录是哪个事务生成了这个数据版本。
- DB_ROLL_PTR(7字节):回滚指针。指向这条数据的上一个版本的地址(存储在 Undo Log 中)。它就像一条链表的指针,把同一个数据的多个版本串联起来。
- DB_ROW_ID(6字节):行ID。如果表没有主键,InnoDB 会用它生成聚簇索引。
2. Undo Log(回滚日志)
- 作用:存储数据旧版本的"档案馆"。
- 当一行数据被更新时,旧版本的数据不会立刻删除,而是会被拷贝到 Undo Log 中,并通过 DB_ROLL_PTR 指针形成一个版本链。
- 这个版本链使得事务可以根据需要找到任何历史版本的数据。
3. Read View(读视图)
- 作用:决定当前事务应该看到哪个版本数据的"筛选规则"。
- 当一个事务执行快照读(普通的 SELECT 语句)时,会生成一个 Read View。这个 Read View 主要包含:
-
- m_ids:生成 Read View 时,系统中活跃的(未提交的)事务ID列表。
- min_trx_id:m_ids 中的最小值。
- max_trx_id:生成 Read View 时,系统应该分配给下一个事务的 ID。
- creator_trx_id:创建这个 Read View 的事务自己的 ID。
MVCC 版本链的形成过程
示例:三次更新操作
ini
-- 初始状态
INSERT INTO users (id, name) VALUES (1, '张三');
-- 版本V1: name='张三', trx_id=100, roll_ptr=NULL
-- 事务200更新
BEGIN;
UPDATE users SET name = '李四' WHERE id = 1;
-- 版本V2: name='李四', trx_id=200, roll_ptr→V1
COMMIT;
-- 事务300更新
BEGIN;
UPDATE users SET name = '王五' WHERE id = 1;
-- 版本V3: name='王五', trx_id=300, roll_ptr→V2
COMMIT;形成的版本链:
ini
最新版本 ← 当前查询从这里开始
↓
V3: name='王五', trx_id=300, roll_ptr → V2
↓
V2: name='李四', trx_id=200, roll_ptr → V1
↓
V1: name='张三', trx_id=100, roll_ptr = NULLMVCC 如何工作(四步判断)
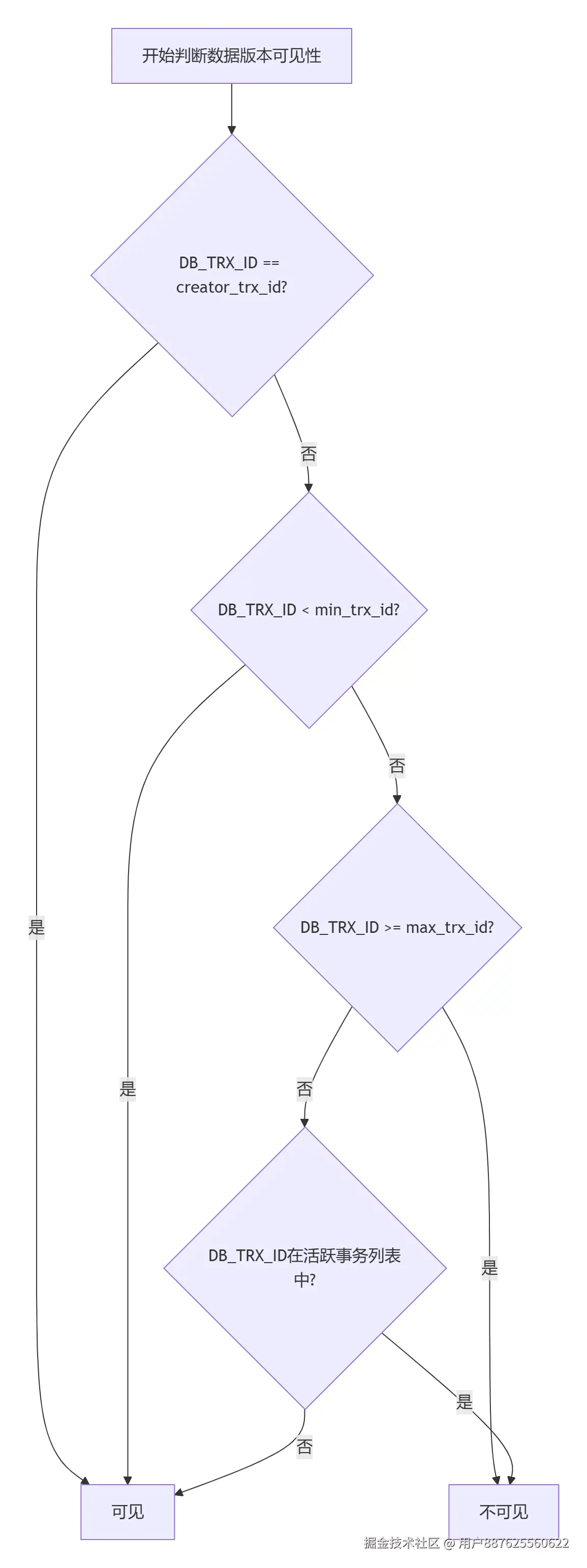
当事务要读取一行数据时,会沿着版本链,从最新版本开始往回找,判断哪个版本对当前事务可见:
判断规则(核心!)
对于版本链中的每个版本,检查其事务ID(DB_TRX_ID):
- 如果 DB_TRX_ID = creator_trx_id:
- 说明这个版本是当前事务自己修改的 ✅ 可见
- 如果 DB_TRX_ID < min_trx_id:
- 说明这个版本在 ReadView 创建前已提交 ✅ 可见
- 如果 DB_TRX_ID > max_trx_id:
- 说明这个版本在 ReadView 创建后才开始 ❌ 不可见
- 如果 min_trx_id < DB_TRX_ID < max_trx_id
- 不在 m_ids 中:说明这个版本的事务已提交 ✅ 可见
- 在 m_ids 中:说明这个版本的事务还在活跃(未提交) ❌ 不可见
如果当前版本不可见,就沿着回滚指针找上一个版本,直到找到可见的版本或版本链结束。
实战例子演示
场景:两个事务并发操作
初始数据:
ini
id=1, name='张三', age=20, DB_TRX_ID=50, DB_ROLL_PTR=NULL事务时间线:
ini
时间点1:事务100开始,修改 age=21
时间点2:事务200开始,创建 ReadView
时间点3:事务100提交
时间点4:事务200查询数据版本链形成
ini
当前版本:age=21, DB_TRX_ID=100, DB_ROLL_PTR→
↓
旧版本:age=20, DB_TRX_ID=50, DB_ROLL_PTR=NULL事务200的 ReadView
ini
m_ids = [100, 200] // 活跃事务列表
min_trx_id = 100 // 最小活跃事务ID
max_trx_id = 201 // 下一个事务ID
creator_trx_id = 200 // 当前事务ID事务200查询过程
- 找到当前版本:age=21, DB_TRX_ID=100
- 判断:DB_TRX_ID=100 在 m_ids 中(事务100还在活跃)
- ❌ 不可见,继续找上一个版本
- 找到旧版本:age=20, DB_TRX_ID=50
- 判断:DB_TRX_ID=50 < min_trx_id(100)
- ✅ 可见,返回 age=20
结果:事务200看到的是 age=20,而不是最新的 age=21
隔离级别与 MVCC
| 隔离级别 | MVCC 行为 | 说明 |
|---|---|---|
| 读未提交 | 不使用 MVCC | 直接读最新数据,可能读到脏数据 |
| 读已提交 | 每次读时都创建新 ReadView | 每次查询看到已提交的最新数据 |
| 可重复读 | 第一次读时创建 ReadView | 整个事务看到同一个快照 |
| 串行化 | 不使用 MVCC | 加锁,完全串行执行 |
底层实现细节
1. Undo Log(回滚日志)
- 记录数据修改前的旧值
- 用于回滚事务和构建版本链
- 当事务提交后,undo log 不会立即删除,因为可能还有其他事务需要读旧版本
2. 版本链清理
- 当没有事务需要读旧版本时,undo log 会被清理
- 通过 purge 线程定期清理
- 清理条件:所有 ReadView 的 min_trx_id 都大于某个版本的事务ID
3. 当前读 vs 快照读
sql
-- 快照读(使用MVCC)
SELECT * FROM users WHERE id=1; -- 看到快照
-- 当前读(加锁,读最新)
SELECT * FROM users WHERE id=1 FOR UPDATE; -- 加写锁
SELECT * FROM users WHERE id=1 LOCK IN SHARE MODE; -- 加读锁一句话总结
MVCC 就是:每个事务看到的是数据库在某个时间点的"快照",而不是实时数据。通过版本链和 ReadView 机制,实现读写不冲突和高并发。
记住这个核心:
- 版本链:每次修改都记录旧版本,形成链表
- ReadView:事务开始时创建,决定哪些版本可见
- 判断规则:沿着版本链找,找到第一个对当前事务可见的版本
- 隔离级别:读已提交 vs 可重复读的区别在于 ReadView 的创建时机