在处理复杂的数据关系时,单层 SQL 查询往往显得力不从心,子查询(Subquery) 能够让你在查询中嵌套查询,像剥洋葱一样逐层解决复杂的业务逻辑。
文章目录
- [一、 子查询基础](#一、 子查询基础)
-
- [1.1 什么是子查询?](#1.1 什么是子查询?)
- [二、 按出现位置划分:过滤器/动态列/衍生表](#二、 按出现位置划分:过滤器/动态列/衍生表)
-
- [2.1 在 WHERE 子句中:过滤器](#2.1 在 WHERE 子句中:过滤器)
- [2.2 在 SELECT 子句中:动态列](#2.2 在 SELECT 子句中:动态列)
- [2.3 在 FROM 子句中:派生表](#2.3 在 FROM 子句中:派生表)
- [三、 按相关性划分:独立子查询 vs. 关联子查询](#三、 按相关性划分:独立子查询 vs. 关联子查询)
-
- [3.1 独立子查询](#3.1 独立子查询)
- [3.2 关联子查询](#3.2 关联子查询)
一、 子查询基础
1.1 什么是子查询?
子查询是嵌套在另一个 SQL 语内部的查询,它极大地提高了代码的解耦性,使复杂的业务逻辑可以分步表达。
- 外层查询:被称为主查询。
- 内层查询:被称为子查询,它为外层查询提供临时数据源或过滤条件。
子查询通常遵循由内向外的原则:MySQL 首先执行括号内的子查询,将其结果作为外部查询的输入。
二、 按出现位置划分:过滤器/动态列/衍生表
2.1 在 WHERE 子句中:过滤器
这是最常见的用法,将子查询的结果作为 WHERE 后的常量或集合。
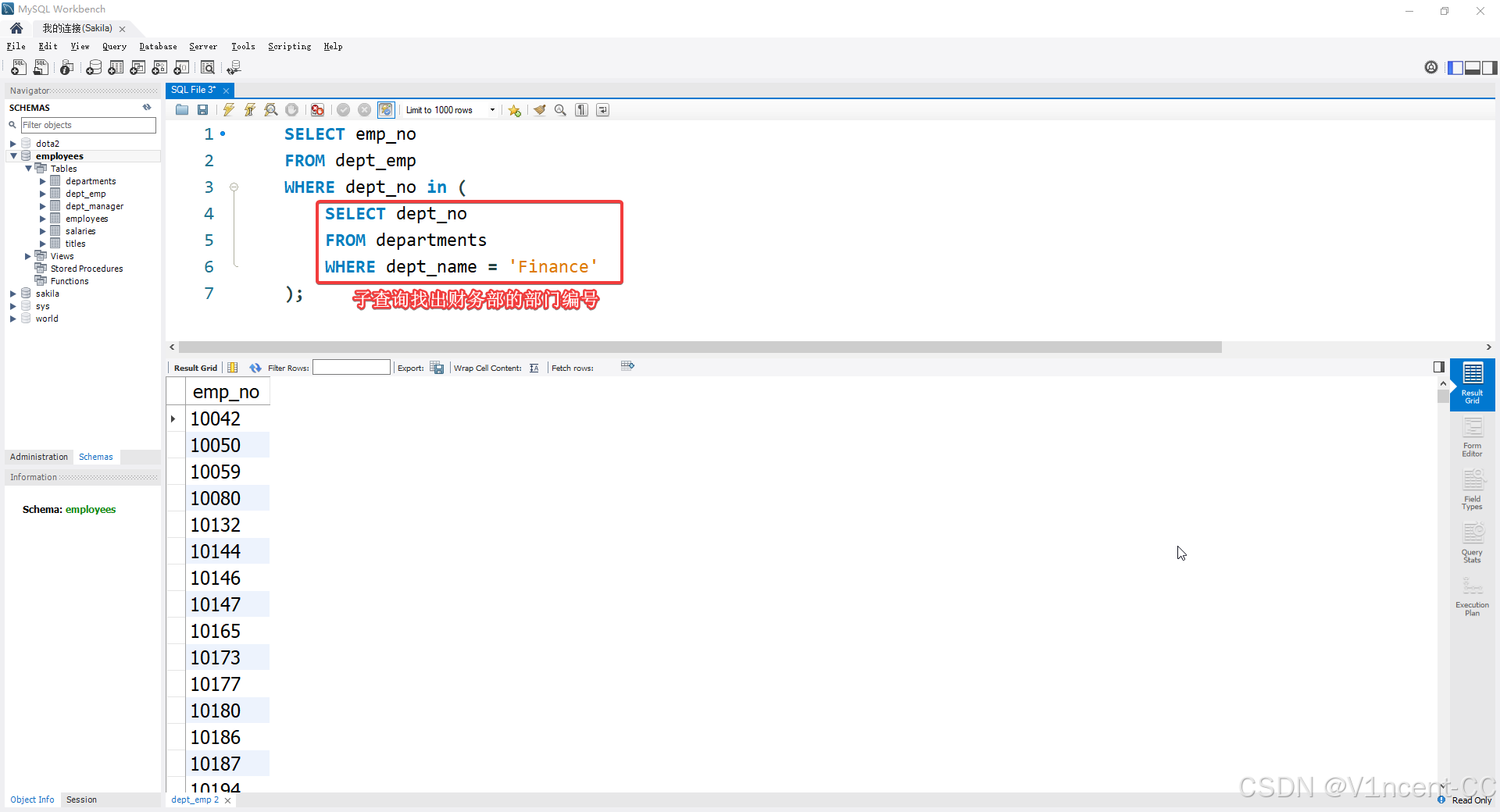
案例: 找出所有在 "Finance"(财务部)工作的员工工号
正常的处理流程如下:
- 先从
departments表找到部门编号dept_no。 - 在
dept_emp表中根据该编号找到对应的emp_no。
下面的SQL通过子查询先找出财务部对应的部门编号,然后将其作为where条件,过滤出员工号。
sql
SELECT emp_no
FROM dept_emp
WHERE dept_no in (
SELECT dept_no
FROM departments
WHERE dept_name = 'Finance'
);
2.2 在 SELECT 子句中:动态列
这种子查询必须返回标量值(单行单列),通常用于在主表结果旁增加统计信息。
案例: 列出所有部门的名称,并统计该部门的员工总数。
sql
SELECT
d.dept_name,
(SELECT COUNT(*) FROM dept_emp de WHERE de.dept_no = d.dept_no) AS total_employees
FROM departments d;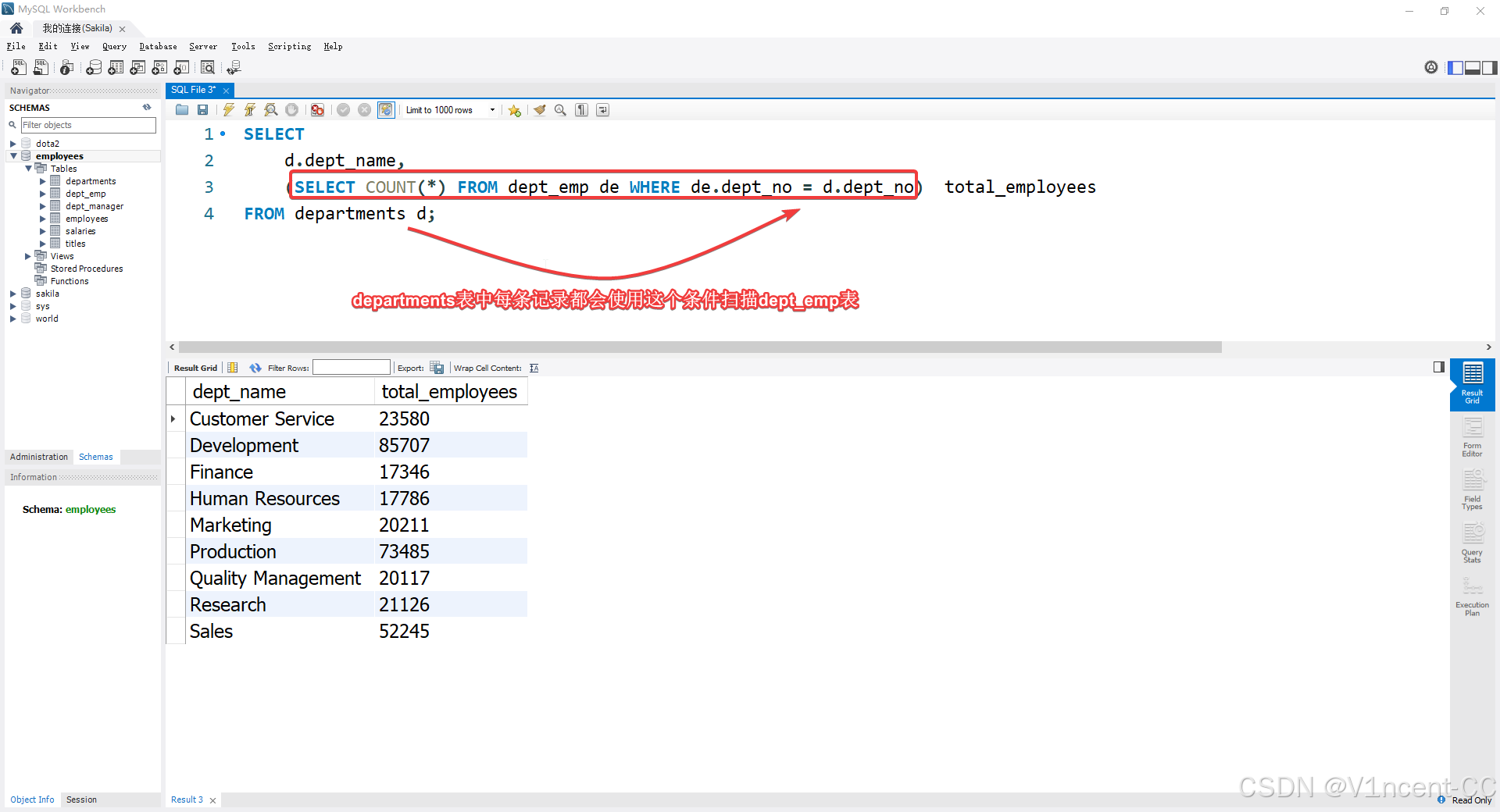
警告: 此类查询属于关联子查询,主查询每输出一行,子查询都会扫描一次
dept_emp表,在海量数据下性能极差。
2.3 在 FROM 子句中:派生表
当复杂的聚合计算无法通过一次 GROUP BY 完成时,可以将子查询结果当作一张"临时表"。
案例:统计每个部门的最高工资员工。
- 统计每个部门的最高工资额,作为衍生表dept_max。
- 再次与员工和部门表连接,定位工资最高的员工。
sql
SELECT
d.dept_no 部门编号,
concat(e.first_name, ' ',e.last_name) 姓名,
s.salary 工资
FROM employees e
JOIN salaries s ON s.emp_no = e.emp_no
JOIN dept_emp d ON d.emp_no = e.emp_no
JOIN (
SELECT de.dept_no, MAX(salary) max_sal
FROM salaries s
JOIN dept_emp de ON s.emp_no = de.emp_no
GROUP BY de.dept_no
) dept_max ON dept_max.max_sal = s.salary and dept_max.dept_no = d.dept_no
where s.to_date='9999-01-01' -- 只查当前在职员工
order by d.dept_no;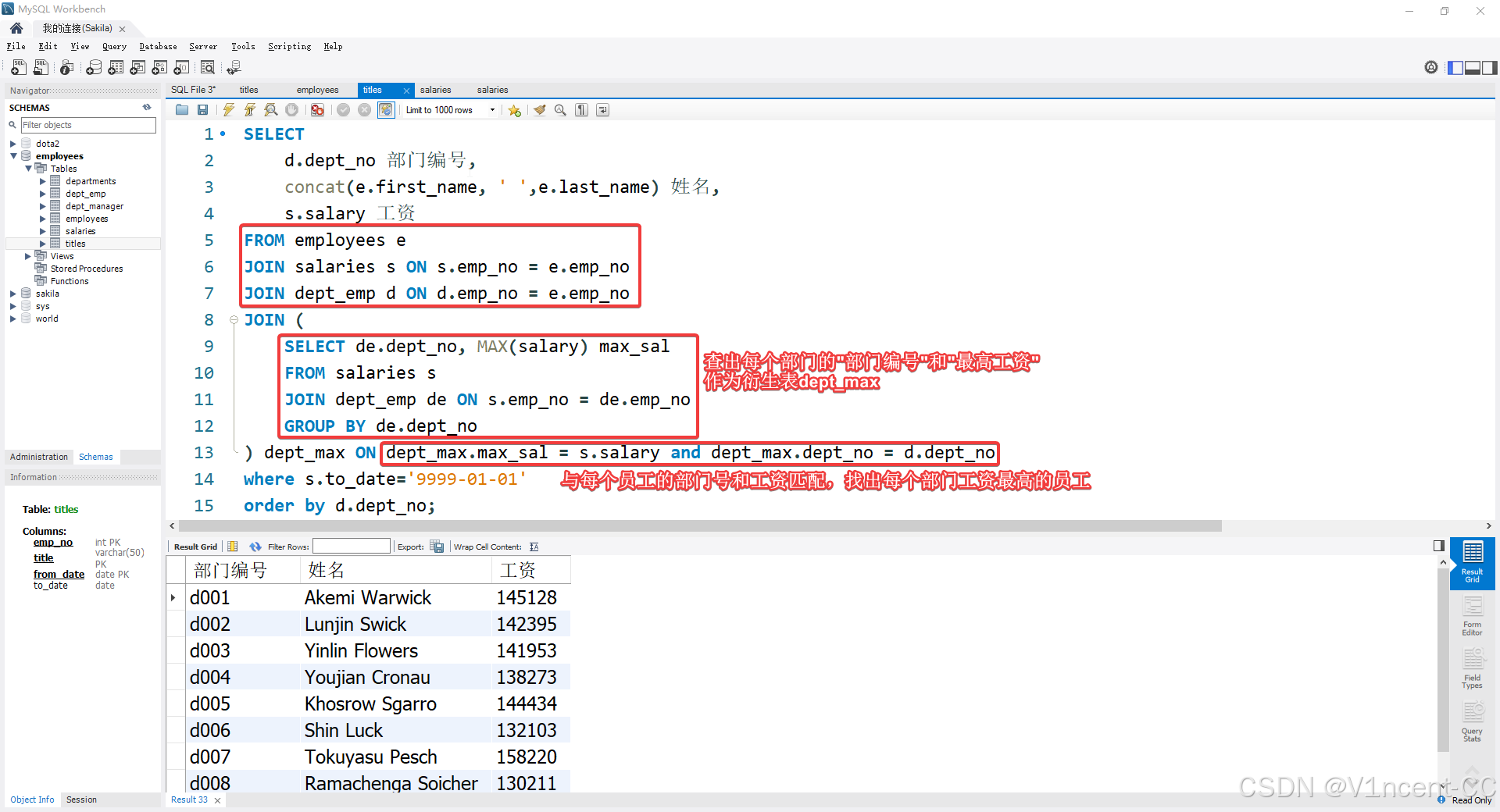
三、 按相关性划分:独立子查询 vs. 关联子查询
3.1 独立子查询
独立子查询不依赖外部查询的任何字段,可以单独运行。MySQL 会先算完子查询得到一个结果(如一个数值或一个列表),再将其作为常量交给外部查询,独立子查询的优点是结构简单,逻辑清晰,性能通常也较好。
WHERE 条件中的独立过滤条件或者衍生表都是典型的独立子查询。
3.2 关联子查询
关联子查询的内部引用了外部查询的字段(通常在 WHERE 子句中),这意味着它无法脱离外部环境独立运行,外部查询每处理一行,子查询通常都要重新执行一次,在百万级数据的表上,关联子查询可能导致严重的性能瓶颈(逐行扫描计算),在使用关联子查询时,可以思考一下是否能转换成独立子查询。
| 特性 | 独立子查询 | 关联子查询 |
|---|---|---|
| 依赖关系 | 不依赖外部查询字段,可独立执行 | 必须引用外部查询字段,不可独立执行 |
| 执行次数 | 通常只执行 1 次 | 根据外部查询每行执行1次 |
| 场景场景 | 派生表、独立过滤条件 | 动态列、存在性检查 (EXISTS) |
子查询是处理复杂业务的核心工具,但不恰当的使用也可能带来严重的性能问题。子查询的优势是逻辑层次较清晰,但有时也有更好的替代方案,比如"用join代替子查询"或考虑使用CTE(公用表表达式)。