一. 强化学习
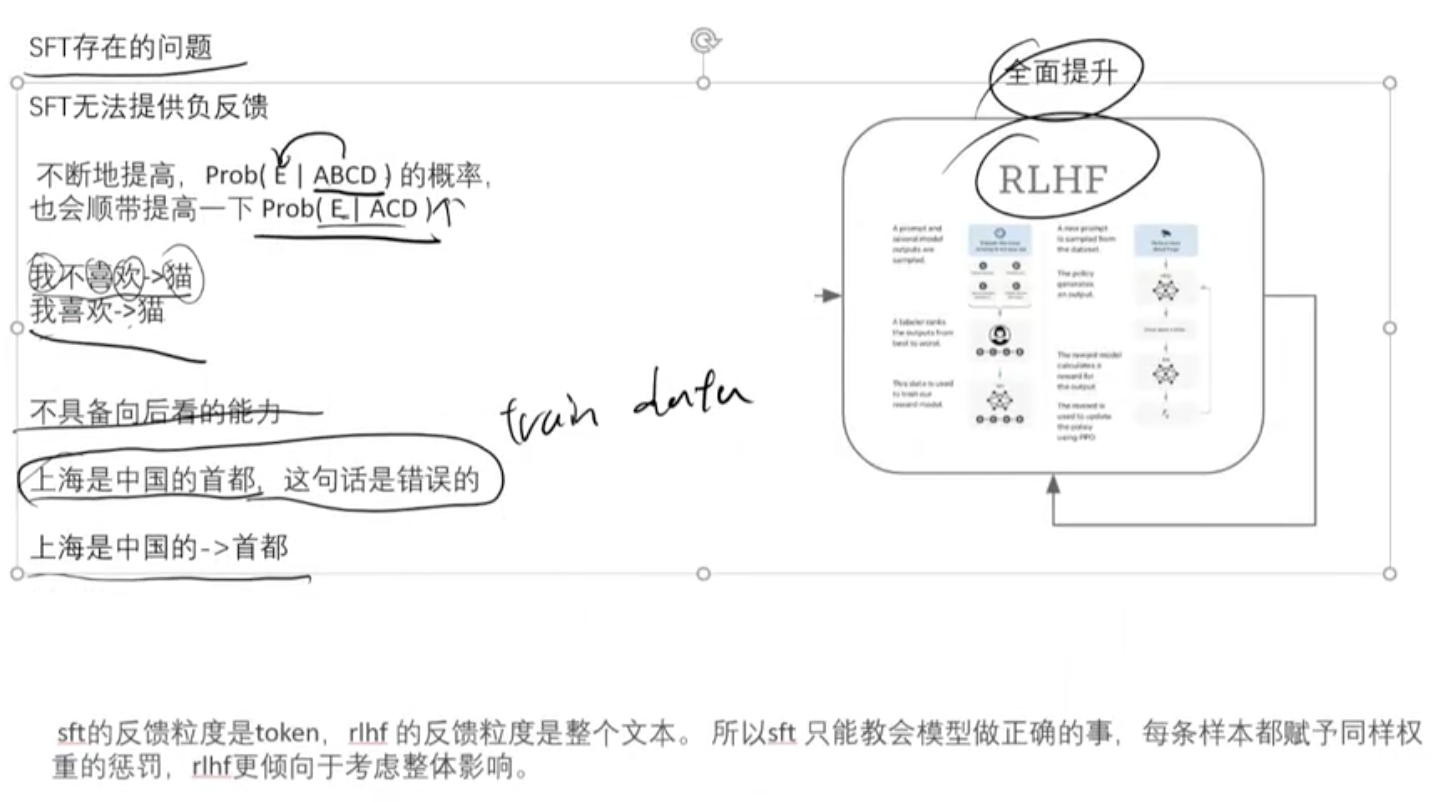
1.SFT与强化学习
2.RM(奖励模型)
ORM(结果奖励):标注困难,成本高
PRM(过程奖励): 简单, 但存在结果对, 过程错的情况。
- 奖励方法:
基于规则 (Rule-based Rewards)的奖励, deepseek
基于模型(Reward Model)的奖励, openai
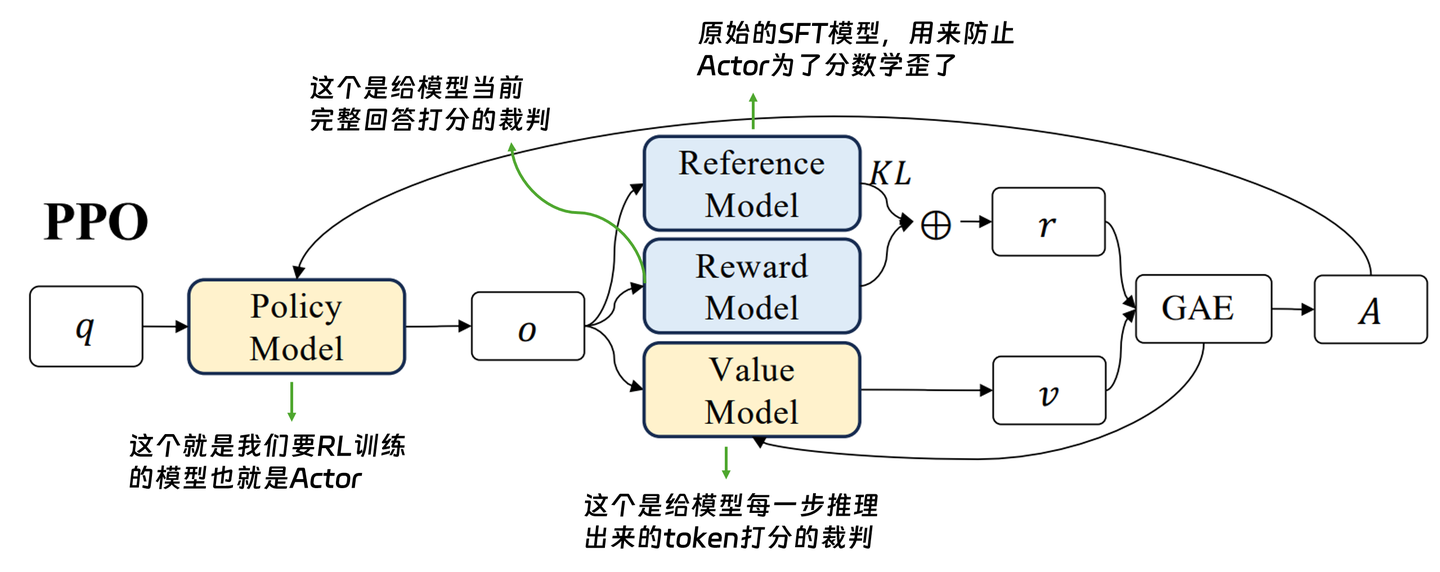
- PPO:有value Model
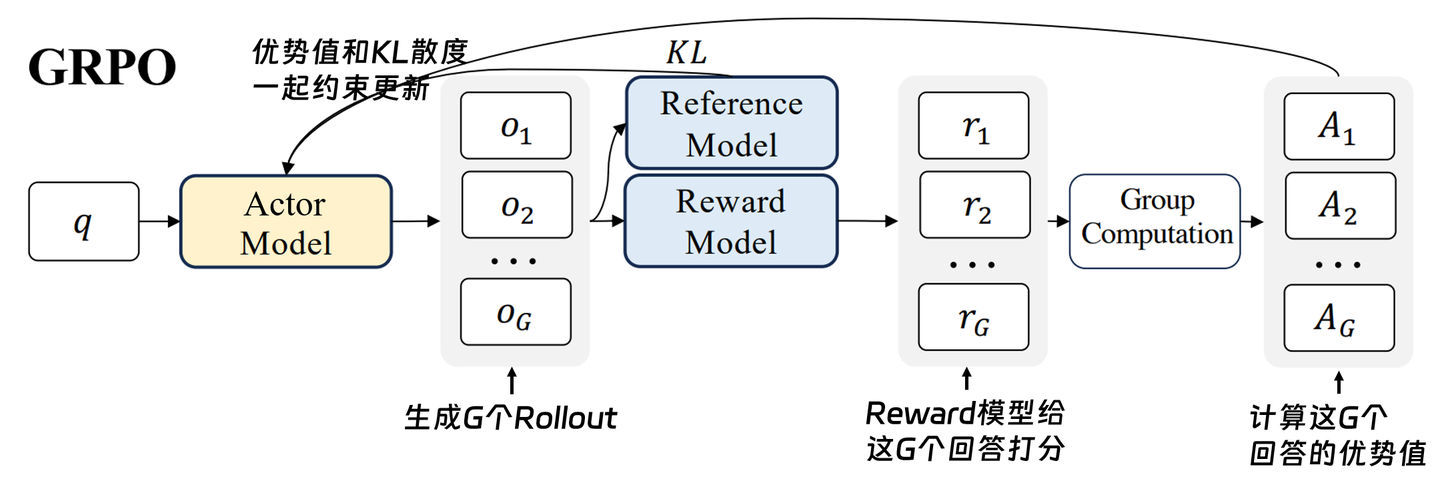
- GPO: 没有Value Model, 让结果内卷
二. 思维链技术
- 增强模型推理技术的手段
1)提高token数,2)生成更多个的输出
- 思维链方法
(1)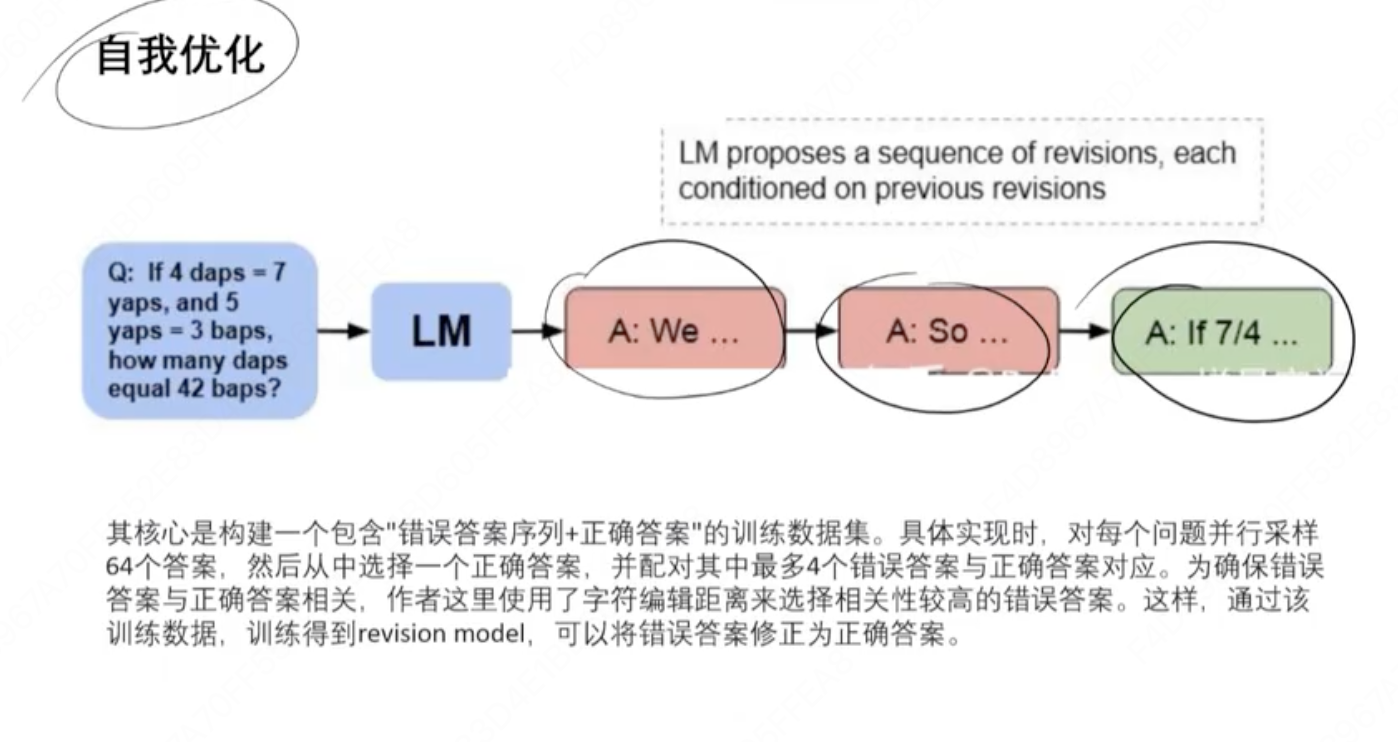
iput: prompt
output: W1,W2, W3, R1
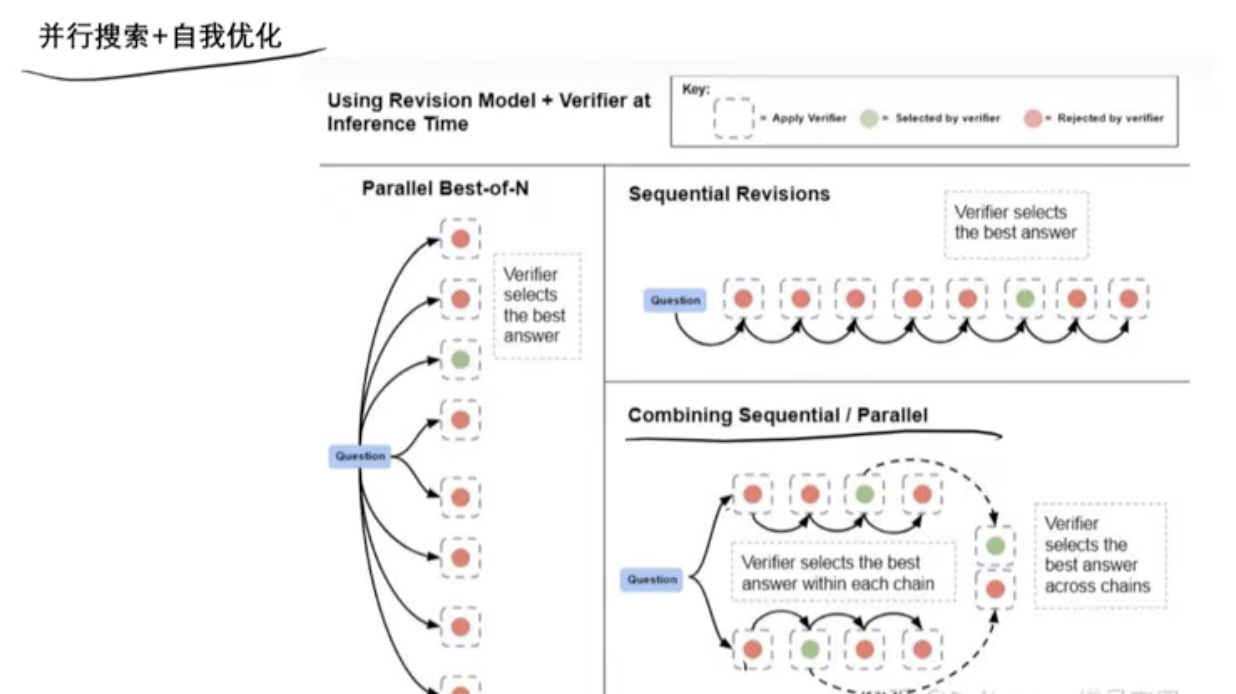
(2)并行搜索+自我优化
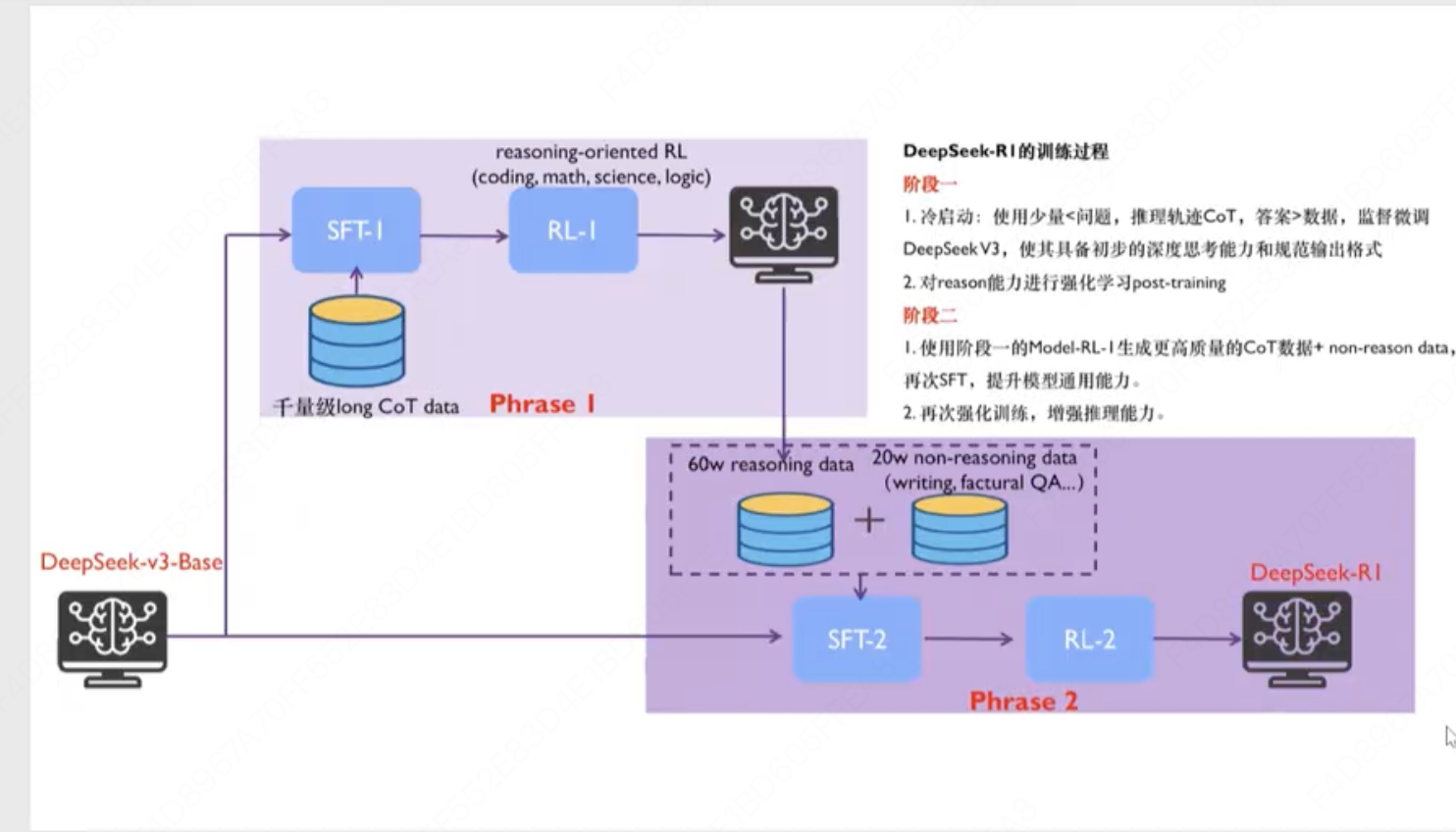
- DeepSeek-R1训练过程
- 强化学习与蒸馏技术

5.推理模型的未来趋势
