推荐直接网站在线阅读:aicoting AI算法面试学习在线网站
特征工程(Feature Engineering) 是机器学习流程中将原始数据转换为适合模型学习的特征的关键步骤。它直接决定了模型能否高效捕捉数据中的规律。好的特征可以显著提升模型性能,而差的特征即使模型再复杂也难以取得好效果。
特征工程的核心目标是:
- 提取有效信息:将原始数据中有价值的信号转化为模型可以理解的特征;
- 减少冗余与噪声:去掉无关或多余的特征,使模型更简洁、更泛化;
- 增强表达能力:通过构造、组合或降维生成新的特征,使模型能够更好地捕捉数据的复杂关系;
- 提高训练效率:减少特征维度、统一尺度,使模型训练更快、收敛更稳定。
特征工程通常包括三个主要环节:
- 特征选择:识别并保留对预测任务最有贡献的特征;
- 特征构造:基于现有特征生成新的、更具信息量的特征,例如多项式特征、交互特征;
- 特征降维:通过方法如 PCA、LDA、ICA,将高维特征压缩到低维空间,同时保留主要信息。
特征工程在机器学习中与算法本身同等重要。这也是机器学习和深度学习的最大区别所在,通过合理的特征处理,可以让简单的模型也取得出色的效果,为后续模型训练和优化打下坚实基础。下面我们来看一下特征选择。
什么是特征选择?
特征选择是指从原始特征集合中挑选出对模型预测任务最有价值的特征,同时去掉无关或冗余特征的过程。
- 目标:提高模型性能、减少过拟合、降低计算成本、提升可解释性。
- 问题背景:在大数据时代,数据集可能包含成百上千个特征,很多特征对预测没有帮助甚至有害。
特征选择的原则
特征选择通常遵循以下原则:
- 相关性原则:保留与目标变量相关性高的特征。
- 冗余最小化:去掉高度相关或重复的特征。
- 可解释性:保留对业务有意义的特征。
- 泛化能力:选择能够提高模型在新数据上表现的特征。
特征选择的方法分类
1. 过滤法(Filter Method)
核心思想:通过统计指标对特征进行排序和筛选,独立于具体模型。
常用指标
- 相关系数(Correlation):Pearson、Spearman。
- 卡方检验(Chi-Square):用于分类问题的离散特征。
- 互信息(Mutual Information):衡量特征与目标的依赖关系。
python
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.feature_selection import SelectKBest, chi2, f_classif
# 加载数据
iris = load_iris()
X, y = iris.data, iris.target
# 卡方检验选择前2个特征
chi2_selector = SelectKBest(score_func=chi2, k=2)
X_chi2 = chi2_selector.fit_transform(X, y)
print(X_chi2)
# 方差分析选择前2个特征
f_selector = SelectKBest(score_func=f_classif, k=2)
X_f = f_selector.fit_transform(X, y)
# print(X_f)输出如下:
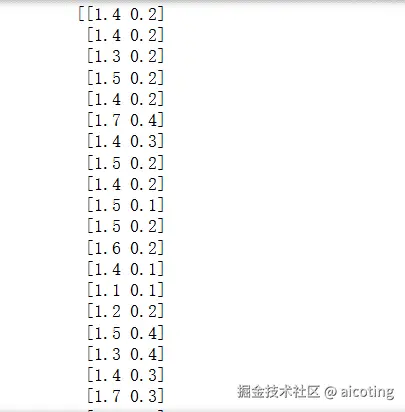
过滤法的优点是简单快速、与模型无关并且可处理高维数据;缺点是忽略特征间的关联、可能丢失非线性关系信息。
2.包裹法(Wrapper Method)
核心思想:通过模型性能作为评价标准,使用搜索策略挑选特征。 常用策略
- 递归特征消除(RFE, Recursive Feature Elimination):反复训练模型,每次剔除最不重要的特征。
- 前向选择(Forward Selection):从空特征集开始,逐步加入最优特征。
- 后向消除(Backward Elimination):从完整特征集开始,逐步删除最差特征。
python
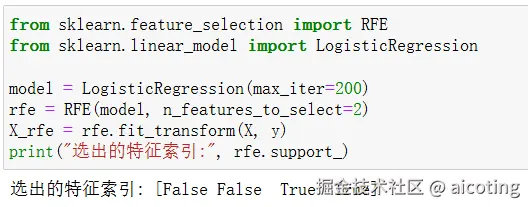
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(max_iter=200)
rfe = RFE(model, n_features_to_select=2)
X_rfe = rfe.fit_transform(X, y)
print("选出的特征索引:", rfe.support_)运行的结果如下:
包裹法的优点是考虑特征间交互作用,并且可提升模型性能;但是缺点是计算成本高,尤其在高维数据中,同时对模型依赖强,不同模型结果不同。
3.嵌入法(Embedded Method)
核心思想:在模型训练过程中自动选择特征。模型本身带有特征选择能力。 常用方法
- 正则化回归(Lasso/L1):对不重要的特征权重压缩为零。
- 决策树 / 随机森林特征重要性:根据信息增益或 Gini 指数衡量特征贡献。 示例代码(Python + Lasso)
python
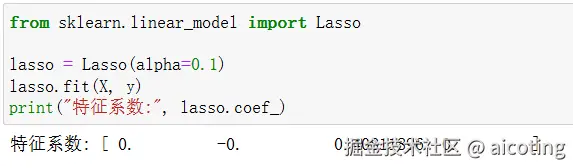
from sklearn.linear_model import Lasso
lasso = Lasso(alpha=0.1)
lasso.fit(X, y)
print("特征系数:", lasso.coef_)输出结果为:
嵌入法的优点是将特征选择融入训练过程,相比包裹法更高效,适合高维稀疏数据。但是缺点是对模型类型依赖,可能错过非线性关系。
最新的文章都在公众号aicoting更新,别忘记关注哦!!!