平常我们编写 C/C++ 代码时,使用的都是 C/C++ 中标准库,编译的都是 C/C++ 的标准库。那么库是什么,我们在使用库的时候底层又是如何的呢?
1. 库的认识
1.库的初步认识
如何确认我们编写的C语言代码使用到C标准库呢?使用指令:ldd 可执行程序名,查看可执行程序所依赖的库:
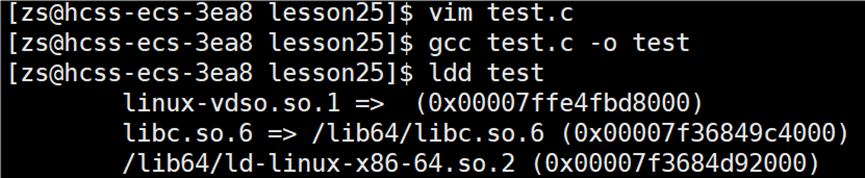
可以看到 libc.so.6 => /lib64/libc.so.6,libc.so.6 指的是 lib64 目录下的 libc.so.6 文件。/lib64 是linux 系统下查找库时的默认路径,linux 系统在搜索库时一般都会在 lib64 目录下搜索。
/lib64/libc.so.6 实际上是软链接,它指向的是 libc-2.17.so:

libc-2.17.so 也在 lib64 目录下:

libc-2.17.so 就是C语言代码所用到的C标准库。
lib64 是 usr/lib64 的软链接:

直接访问 /lib64 就是在访问 usr/lib64。
可以查看系统安装的C语言动态库和我们安装的静态库:

之前曾说过,在系统中,翻译程序,链接库时,存在两个链接方式:静态链接和动态链接。要实现静态链接,需要有静态链接库;要实现动态链接,需要有动态链接库。之前讲的很浅,静态链接就是将库拷贝到可执行程序中,动态链接就是所有可执行程序共享库。
在 linux 系统当中,若库文件以 .so 结尾,那么该库文件是动态库文件;若库文件以 .a 结尾,那么该库文件是静态库文件。
在 windows 系统当中,若库文件以 .dll 结尾,那么该库文件是动态库文件;在windows系统当作,若库文件以 .lib 结尾,那么该库文件是静态库文件。
test 可执行程序链接的库是 libc-2.17.so,以.so结尾,所以它链接的是动态库文件。
库文件的命名:以 lib 开头,以 .a/.so 作为结尾,其余部分就是库的文件名。即一个库文件的文件名是去掉 lib 开头的前缀,.a/.so 结尾的后缀,剩下的就是库文件名。例:libc.so.6 去掉 lib,.so.6,剩下的部分就是该库文件的文件名,即 c,这就是C标准库。
进一步的确定 test 可执行程序链接的就是动态库,使用指令:file 可执行程序名:

dynamically linked 说明该程序使用的就是动态链接。
C/C++ 程序使用 gcc/g++ 编译链接时,默认使用的就是动态链接。如果想要强制程序使用静态链接,需要在指令的后面加上 -static。
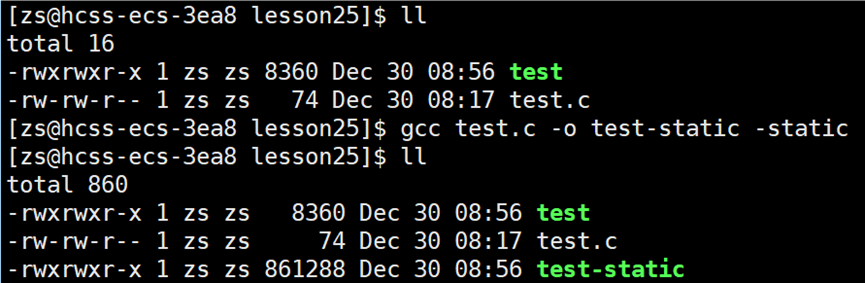
test-static 就是静态链接编译的可执行程序。test-static 是一个可以正常运行的程序:

使用 ldd 和 file 指令查看 test-static 程序:

如果发现自己的系统中静态链接链接不上,这是因为你的系统中没有安装C/C++的静态库。
安装C和C++静态库的指令:
CentOS版本:yum install glibc-static libstdc++-static -y
Ubuntu版本:apt install libc6-dev libstdc++-11-dev g++ -y
2. 制作和使用库
1. 引言
在讲解 gcc/g++ 编译器时,曾深入探讨了代码翻译的过程,在 .c 文件经过预处理和汇编,编译之后,生成 .o 文件,最后将所有的 .o 文件链接在一起,从而生成可执行程序。
之前我们曾自己封装实现了部分文件操作函数:fopen,file结构体,fputs函数,fflush函数,fclose函数。为了展示库的制作,新建文件mystring.h,mystring.c,main.c。
main.c文件中的内容如下所示:
cpp
#include "mystdio.h"
#include "mystring.h"
int main()
{
mystrlen();
return 0;
}将 main.c,mystdio.c,mystring.c 全部编译链接形成一个可执行程序:
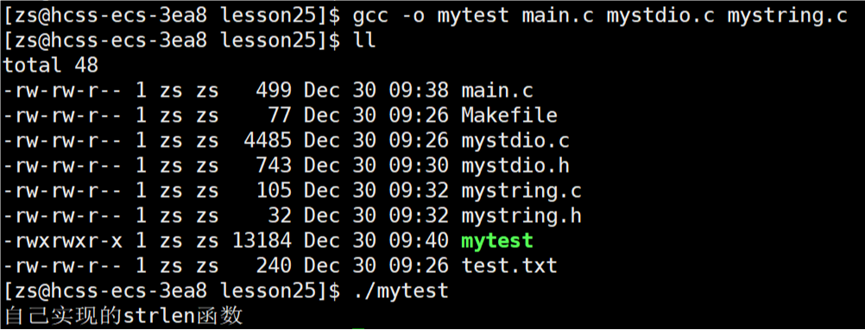
上述操作是将所有的 .c 文件一次性的直接编译链接形成可执行程序,接下来演示将所有的 .c 文件经过编译后形成 .o 文件,再将所有的 .o 文件链接形成可执行程序。推荐使用这种方式形成可执行程序。
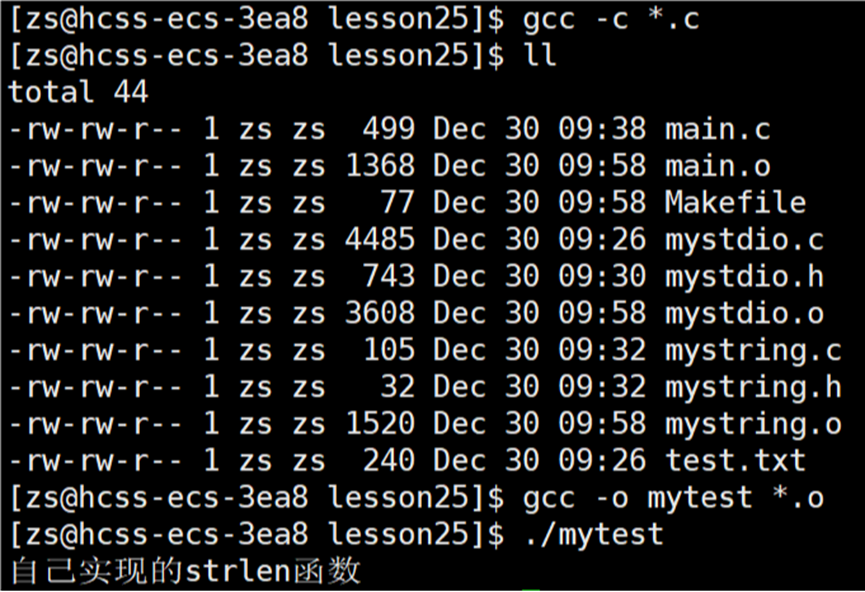
将 .c 源文件编译成 .o 文件与其它的 .c 源文件没有任何关系,链接时多个 .o 文件才产生关联。
在 main.c 文件中声明一个变量 num,并在 main.c 文件中使用 num 变量,在其它的 .c 文件中是找不到变量 num,但是 main.c 却可以编译形成 .o 文件。
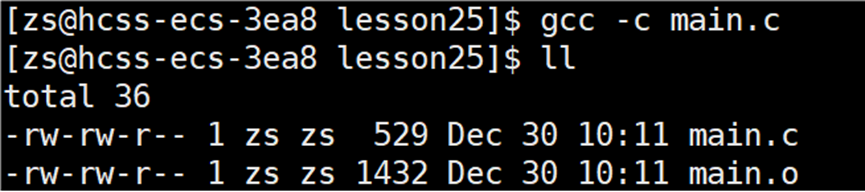
在将所有的 .o 文件链接形成可执行程序时,会报错。
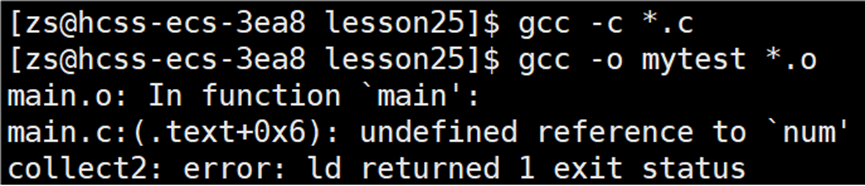
找不到变量num,由此可以知道上述的错误是在链接时发现的。
为了后续的演示,编写一个 Makefile 自动化编译文件,文件内容如下所示:
bash
mytest:mystring.o mystdio.o
gcc -o $@ $^
%.o:%.c
gcc -c $<
.PHONY:clean
clean:
rm -f *.o mytest既然所有的 .c 源代码都需要经过编译形成 .o 文件,那么向他人提供代码就不需要提供 .c 源码,而是源码编译好的 .o 文件,再提供源代码中使用的函数的声明,即相关头文件,因为即便提供 .c 源代码在翻译时也会编译成 .o 文件,反正最终都要变成 .o 文件,不如直接提供 .o 文件。
将自己实现的 .c 源文件,经过编译后形成的 .o 文件供他人使用,我们提供的 .o 文件不就是所谓的库文件的功能吗?静态库文件的本质就是 .o 文件,这也是为什么在链接时才会将库文件与 .c 源文件形成的 .o 文件链接在一起,链接就是将所有的 .o 文件链接在一起,在链接时库文件会一同被链接。
如果自己实现了1000多个 .c 源文件,向他人提供这些文件时,岂不是要提供1000多个 .o 文件?如果中途丢失了几个 .o 文件,那不是很容易出现问题?在实现工程项目时,.c 源文件很多,那就注定了 .o 文件也会很多,所以我们需要将多个 .o 文件想办法打包形成一个文件,它就是真正意义上的 .a/.so 文件,所以库本质上就是.o文件的集合!!
自己制作和使用自己的库,使用两个视角一个是"我"(mylibc),一个是"他人"(other),"他人"就是使用我们制作的库。
2. 制作和使用静态库
将 mystring.c 和 mystdio.c 文件编译形成 .o 文件:
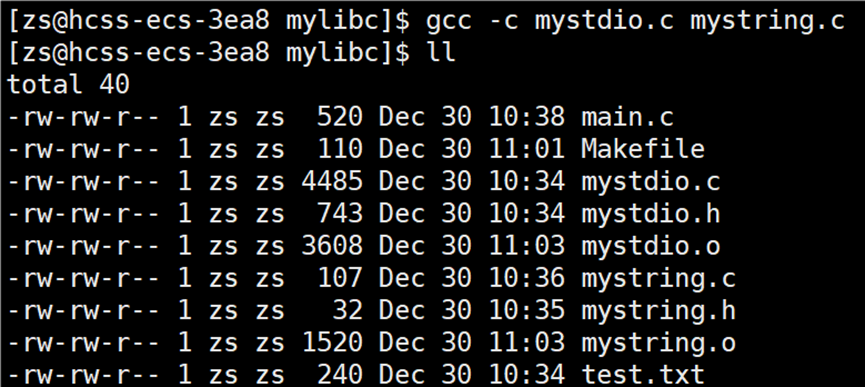
将生成的 .o 文件打包形成静态库,使用指令:ar -rc lib库文件名.a 要打包的.o文件。

ar 是 gnu 归档工具,rc 表示替换并创建(replace and create)。
使用指令:ar -tv lib库文件名.a,列出静态库所包含的文件的详细信息。

t 选项:列出静态库中的文件;v 选项:显示文件的详细信息。
将我们打包好的静态库供他人使用,并且还需要提供相关头文件。库中只有函数的实现,函数的声明在 .h 头文件中。
other 将自己实现的 main.c 编译成 main.o 文件,接着便开始链接形成可执行程序:
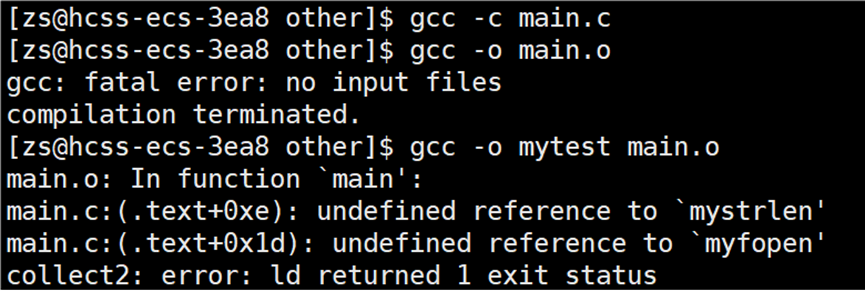
编译报错显示找不到mystrlen和myfopen函数,我们需要告知编译器链接的库文件是谁,使用选项:-l库文件名(-l 与 库文件名之间可以有空格,但是建议写在一起)

报错显示在 /usr/bin/ld 路径下找不到 mystdio 库文件,这是因为 OS 默认查找库时,只会在 lib64 目录下查找,如果想要链接我们实现的静态库,需要告知编译器我们实现的静态库的位置,使用选项:-L库所在的路径(-L 与 库所在的路径之间可以有空格,但是建议写在一起)
这样 gcc 编译器就可以找到静态库,并链接使用静态库。
要让自己的可执行程序与静态库链接,本质是将 main.o 与静态库中的 .o 文件统一链接在一起。要理解库,就需要淡化库的概念,将库理解成 .o 文件的集合,不要看库就是库,要看库就是 .o 文件。
补充说明 -l 和 -L 选项的相关知识:
-l 选项:告知编译器要链接的库的名称
在上述要链接静态库时,需要 -l选项,但是在我们编写的 C/C++ 代码时,并没有告知编译器要链接的库的名称呀?gcc/g++ 是专门用来编译 C/C++ 的,它们默认就是认识 C/C++ 标准库
-L选项:告知编译器要链接的库的路径,告知编译器库在哪里
在上述要链接静态库时,需要-L选项,但是在我们编写的 C/C++ 代码时,并没有告知要链接的库在哪里呀?链接器是怎么找到的?链接器在查找链接的库时,默认在默认系统路径下查找,如 /lib64 路径下。使用的是语言级别的库,编译器自动能够找到对应的库;使用的是自己实现/外部链接的库,需要告知编译器要链接的库的路径
发布的库中绝对不能包含 main 函数,因为库之后是需要供他人使用的,提供给他人使用的库中包含了 main 函数,别人在使用时,自己写的 main 函数和库中的 main 函数会发生冲突。如果想将自己实现的库给他人使用,需要提供库文件和 .h 头文件(类似于库的使用手册)。
Makefile 文件的内容如下所示:
bash
libmystdio.a:mystring.o mystdio.o
ar -rc $@ $^
%.o:%.c
gcc -c $<
.PHONY:clean
clean:
rm -rf *.o *.a mylib
.PHONY:output
output:
mkdir -p mylib
mkdir -p mylib/include
mkdir -p mylib/lib
cp *.h mylib/include
cp *.a mylib/lib在当前路径下生成 mylib/include 和 mylib/lib 目录,将 .h 和 .a 分别拷贝到 include 和 lib 目录下。
使用 make 指令,生成静态库:
在当前路径下生成 mylib 目录,目录包含着头文件+库文件:
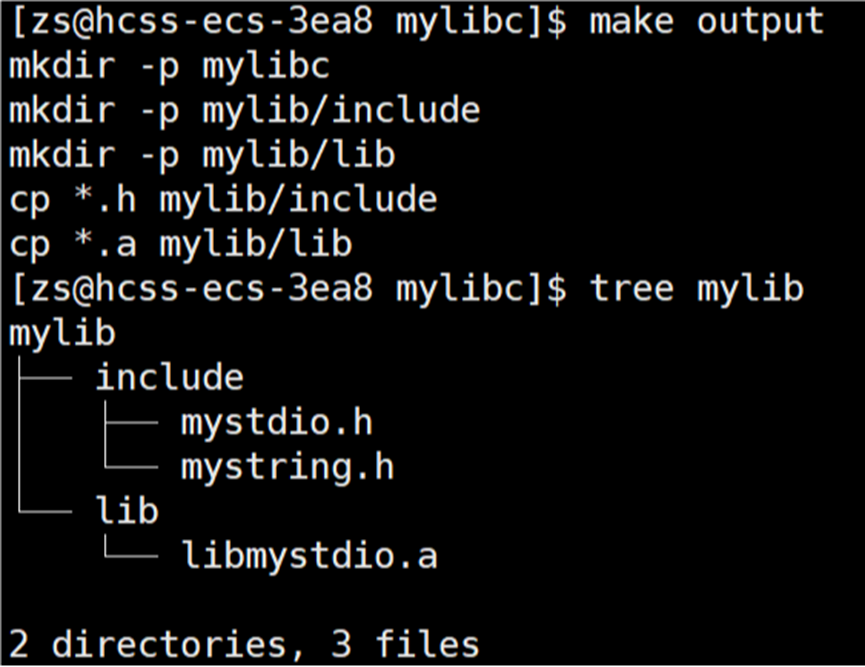
之后便将 mylib 供他人使用即可。
别人怎么使用我们提供的库?
● 将库使用的头文件和库文件拷贝到当前系统的指定的目录下


如此就将他人提供的库安装到自己的系统上了,接下来只需使用即可。
将库删除后,链接就会失败。
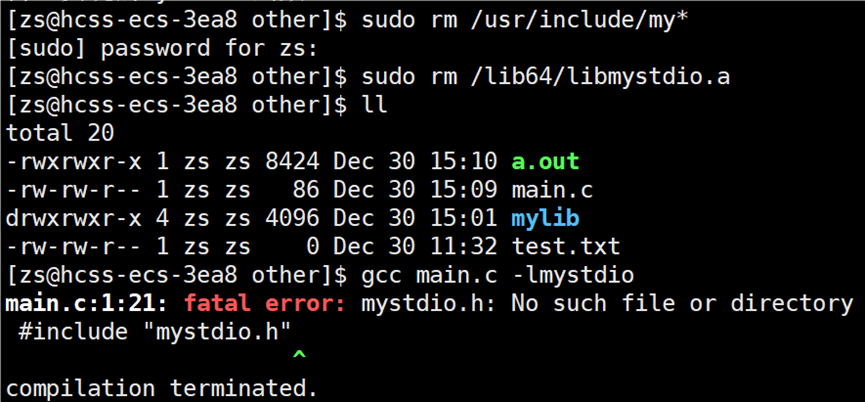
**●**如果不想将库中的文件拷贝到当前系统的指定目录下,应该怎么办?
目前遇到的问题就是找不到 main.c 引用的头文件 mystdio.h 和 mystring.h,这两个头文件不在当前目录下,在 mylib 目录中。所以要告知编译器在编译 main.c 文件时,头文件在哪里找,使用指令:gcc -c main.c -I(大写i) ./mylib/include/,-I 选项:告知编译器除了当前和系统目录,-I指定的路径下也有头文件需要搜索。
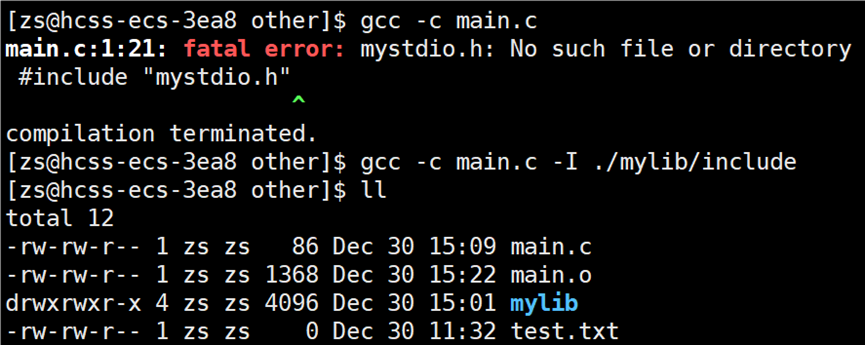
头文件找到了,但是要链接的静态库找不到呀?链接的静态库在 mylib 目录下。所以要告知编译器链接时,库文件在哪里找,使用指令:gcc main.o -o main -lmystdio -L ./mylib/include。
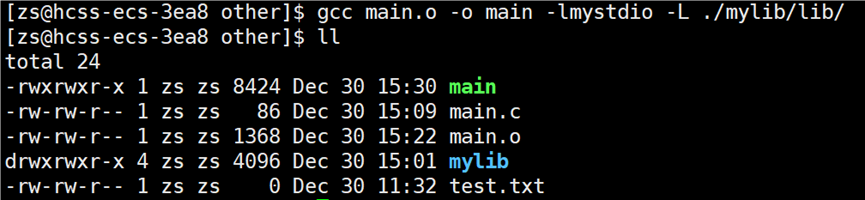
从 .c 源文件编译链接形成可执行程序的指令为:gcc main.c -o main -I ./mylib/include/ -lmystdio -L ./mylib/lib/。

第二种使用库的方法:使用-I(大写i) -l -L选项 。使用这三个选项可以链接任意的库。
● 对库文件建立软链接

再将库中的头文件拷贝到当前系统的指定路径下:
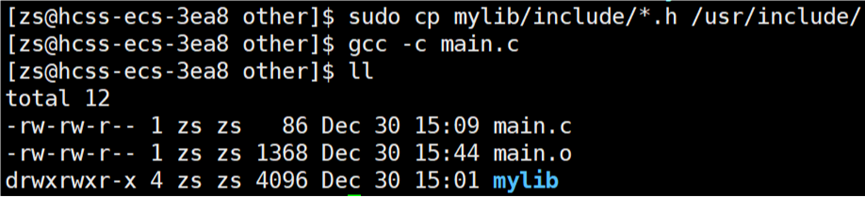
链接时仍然找不到静态库在哪。

只要库是第三方的,就需要使用 l 选项告知编译器库文件在哪里找
3. 制作和使用动态库
将 .c 源文件形成 .o 文件,使用指令:gcc -fPIC -c *.c,-fPIC 的意思形成与位置无关码,-fPIC 也可以将 .c 源文件形成 .o 文件:
将所有的 .o 文件链接形成动态库:
shared 选项:表示生成动态库格式。动态库的名字去掉 lib 前缀,.so 后缀,剩下的就是库名,所以 libmystdio.so 库的名字为 mystdio。
使用 Makefile 文件,自动化创建动态库,Makefile的内容如下所示:
bash
libmystdio.so:mystring.o mystdio.o
gcc -shared -o $@ $^
%.o:%.c
gcc -fPIC -c $<
.PHONY:clean
clean:
rm -rf *.o *.so mylib
.PHONY:output
output:
mkdir -p mylib
mkdir -p mylib/include
mkdir -p mylib/lib
cp *.h mylib/include
cp *.so mylib/lib使用 make 指令,将 .c 源文件编译形成 .o 文件,将所有的 .o 文件链接形成动态库。
在当前路径下生成 mylib 目录,目录包含着头文件+库文件:
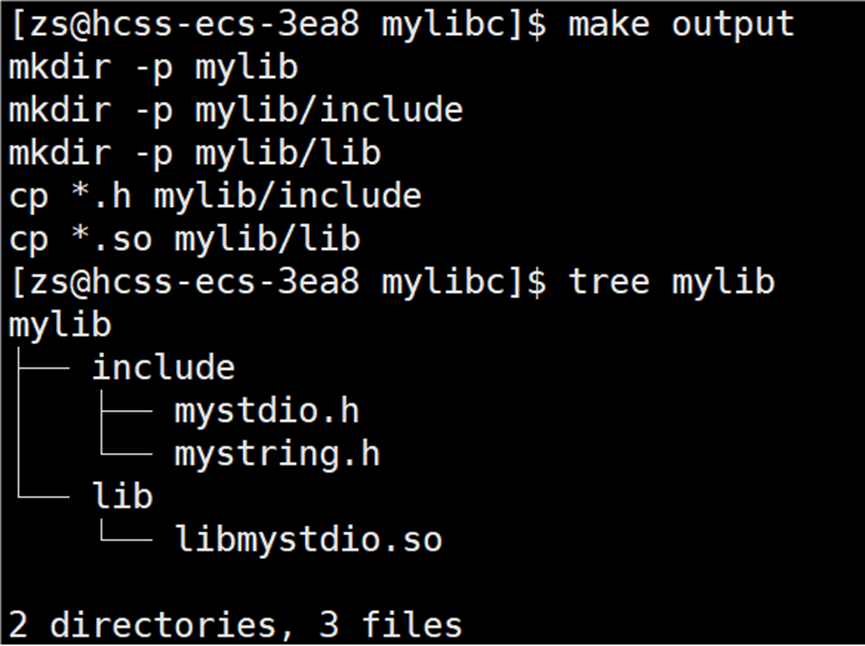
在形成动态库时,并没有使用 ar,而是继续使用 gcc/g++,这表明了什么?静态库通过归档工具 ar 构建,而动态库通过链接器构建,使用库最常见的场景是动态库,常见到什么程度?一款合格的编译器本身默认就能形成动态库。
将生成的动态库提供他人使用。将 main.c 文件形成 main.o 文件:

显示头文件找不到,使用指令:gcc -c main.c -I mylib/include,告知编译器头文件在指定路径下查找:
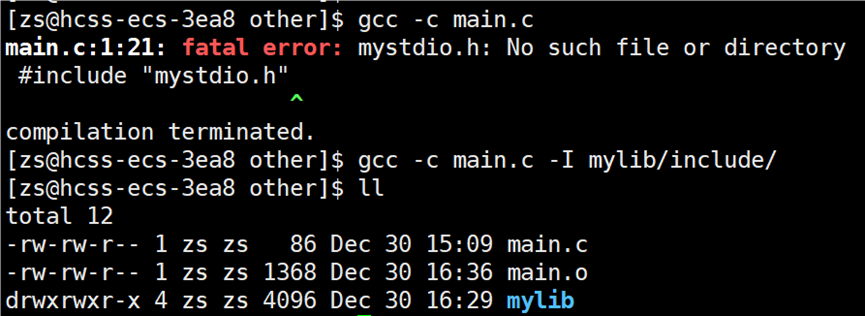
头文件找到了,但是库文件没有找到,需要告知编译器库在哪里去找,使用指令:gcc main.o -o main -lmystdio -L ./mylib/lib/:
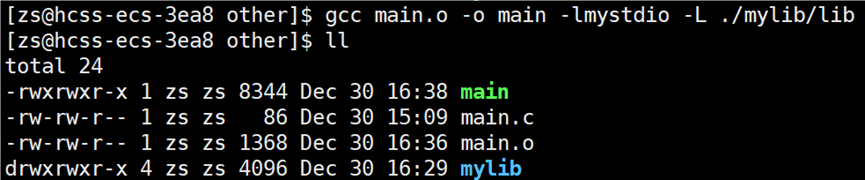
从.c源文件形成的可执行程序的指令为:gcc main.c -o main -I mylib/include/ -lmystdio -L ./mylib/lib/。
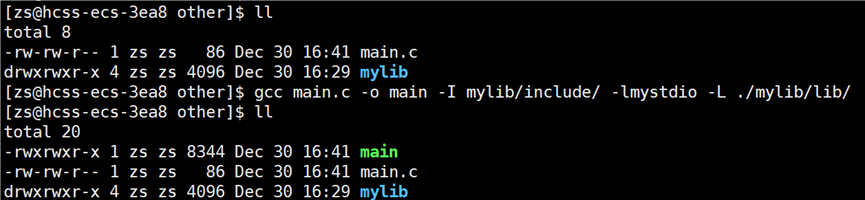
从目前来看,静态库和动态库的使用没有区别,不管使用静态库还是动态库在编译的选项上看起来都是一样的。
接下来运行 main 可执行程序会发现:

程序直接报错了,报错信息显示:libmystdio.so 找不到,因为不存在这个文件。
使用 ldd 指令查看 main 程序链接的库:

libmystdio.so => not found,所以程序运行不起来,为什么找不到动态库呢?我不是在编译的时候告诉过编译器,库文件在哪里找了吗?为什么在运行程序的时候却报错显示找不到库呢?这里的找不到,是谁找不到?是OS操作系统 。但是我们将库的信息告诉的是谁?是编译器!!
编译器知道库的信息,但是OS/加载器不知道 呀?为什么编译器要知道库的信息?一旦形成可执行程序,编译器的工作就已经做完了,./ 运行可执行程序是OS完成的,在运行程序时,加载器不仅需要加载程序,还需要加载程序所依赖的库文件,加载器找不到对应的库文件,所以运行程序时会报错。
为什么使用静态库时,没有出现这个问题?静态库中的方法拷贝到了程序的内部,程序运行时,就不需要库了。动态链接,程序运行时,仍然需要库 。动态库不仅需要在链接时能够被找到,在加载时也能被找到。
如何让系统在程序运行时找到动态库?
● 将动态库拷贝到程序中
● 建立软链接
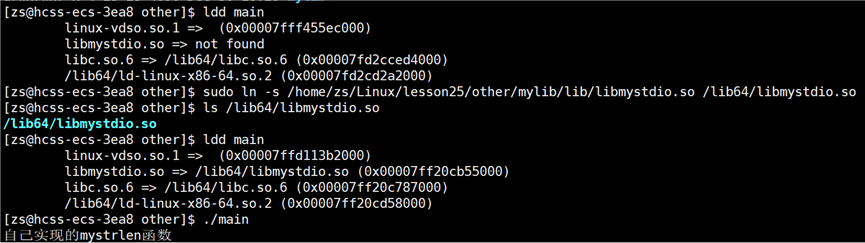
● 通过环境变量,更改环境变量LD_LIBRARY_PATH
OS 存在着环境变量 LD_LIBRARY_PATH(加载库路径)

LD_LIBRARY_PATH 环境变量是 OS 运行程序时,动态搜索的路径,除了在 lib64 路径下搜索之外的另一条路径。
export导出 LD_LIBRARY_PATH,添加新的路径:
4. 使用外部库
之前我们使用的库都是自己实现的,接下来使用别人实现的库。那么我们应该使用别人的什么库?根据具体的应用场景使用对应的库。下面使用图形库:ncurse。
CentOS安装指令:sudo yum install -y ncurses-devel
Ubuntu安装指令:sudo apt install -y libncurses-dev
既然是库,那么一定会为用户提供动态库文件和头文件:


使用 ncurses 库,打印一个心行曲线,代码为:
cpp
#include <ncurses.h>
#include <math.h>
#define PI 3.14159265358979323846
int main() {
initscr();
clear();
noecho();
curs_set(FALSE);
int width = COLS, height = LINES;
double scale_x = 20; // 增大横向缩放
double scale_y = 8; // 减小纵向缩放
double t = 0;
for (t = 0; t <= 2 * PI; t += 0.05)
{
// 心形参数方程(经典心脏线变种)
double x = scale_x * sin(t) * sin(t) * sin(t);
double y = scale_y * (cos(t) - 0.5 * cos(2*t) - 0.2 * cos(3*t) - 0.1 * cos(4*t));
int cx = width / 2 + (int)x;
int cy = height / 2 - (int)y; // y 轴反向(因为终端从上到下)
if (cx >= 0 && cx < width && cy >= 0 && cy < height)
{
mvaddch(cy, cx, '*');
}
}
refresh();
getch();
endwin();
return 0;
}链接 ncurses 库和 math 库,生成可执行程序:
为什么这里不需要告诉编译器库在哪里去找?因为 ncurses库已经被安装到当前系统中了。运行生成的可执行程序:

如此我们就链接并使用了一个外部库了,其它库的使用也是如此。知道了怎么链接和使用自己实现的库,也就可以更快的掌握链接和使用其它的库。
5. 静态库和动态库
静态库和动态库是可以同时存在的:
如果动静态库中的内容是一样,那么在程序链接时,链接的是动态库还是静态库呢?

很明显链接的是动态库,所以若动静态库同时存在,程序链接的是动态库。
如果想要链接静态库,需要在指令的后面加上 -static:

如果只提供动态库,那么在程序链接时,链接的是什么?很明显链接的动态库

因此我们也可以知道,我们使用 -static,前提是必须存在对应静态库,这样才可以链接。
如果只提供静态库,那么在程序链接时,链接的是什么?
使用 ldd 查看可执行程序所依赖的库:

可以看出,只有 C 标准库(libc.so.6)是动态链接的,而 libmystdio 未出现在列表中------说明它已被静态链接进程序中。
查看链接库后生成的可执行程序的大小:
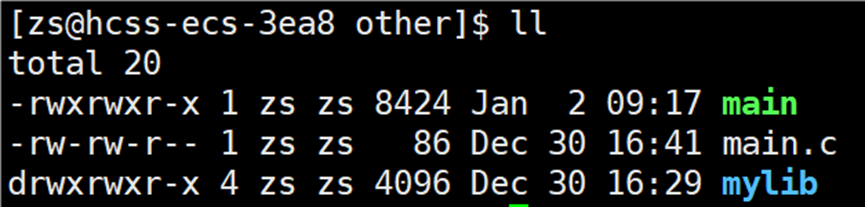
与之前链接提供的动态库生成的可执行程序的大小进行比对:
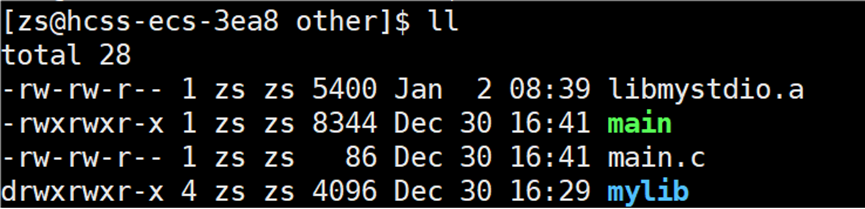
这是因为:当使用静态库时,链接器会将静态库中用到的函数代码和数据直接复制到可执行文件中 ,从而增加了程序体积。而 C 标准库之所以仍然是动态链接,是因为系统默认提供了 libc.so.6,且链接器优先选择动态版本(除非明确指定 -static)。
因此,可以得出结论:
- 即使只提供静态库,程序仍然可能默认采用动态链接(尤其是对标准库)
- 但对于那些没有动态版本或无法找到动态版本的库,链接器会自动回退为静态链接
- 最终结果是:该库(静态库)的内容被嵌入到可执行文件中,导致其体积增大
使用 -static选项,就会链接静态库:

由此我们可以得出, -static的作用是在有对应的静态库的前提下,强制将静态库全部静态链接到可执行程序中。
总结:
● 如果只提供了某个库的动态版本,而没有提供静态版本,那么对该库只能进行动态链接;
● 如果只提供了某个库的静态版本,而没有提供动态版本,那么即使程序整体默认采用动态链接方式,对该特定库也只能进行静态链接
3. ELF 格式
在编译之后会生成名为 .o 的文件,它们被称作目标文件,全称为可重定位目标文件。要注意的是如果我们修改了一个原文件,那么只需要单独编译它这一个,而不需要浪费时间重新编译整个工程。可执行程序是一个二进制的文件,文件的格式是 ELF ,ELF 是一种标准化的文件结构,ELF格式是对二进制代码的一种封装。
一旦提到二进制文件,我们的脑海可能会浮现出以下类似的内容:
这么理解二进制文件也没有问题,需要注意的是,可执行程序并不是随意拼接的二进制数据,而是具有严格定义的内部结构 。在 Linux 系统中,这种结构遵循 ELF(Executable and Linkable Format)格式标准。
在 Linux 系统中,ELF 是一种通用的二进制文件格式,用于可执行文件、可重定位目标文件(.o)和动态共享库(.so)。而静态库(.a)虽然包含多个 ELF 格式的 .o 文件,但其本身是一个 ar 归档文件,并非 ELF 格式。ELF格式是类Unix系统下标准的二进制格式,ELF 格式大概是怎个模样呢?如下图所示:

编译过程的是将 .c 源文件变成 .o 文件,而 .o 文件,可执行程序,动态库都是ELF格式,所以可以将多份 .c 源代码编译形成 .o 文件,将多份 .o 文件与库文件链接在一起形成可执行程序。在 Linux 下,无论是源代码编译出的目标文件(.o),还是动态库(.so)和最终的可执行程序,都采用同一种二进制格式 ------ ELF。正因如此,编译器可以把多个 .o 文件'组装'起来,合并它们的代码段、数据段等,最终形成一个完整的可执行程序。如下图所示:
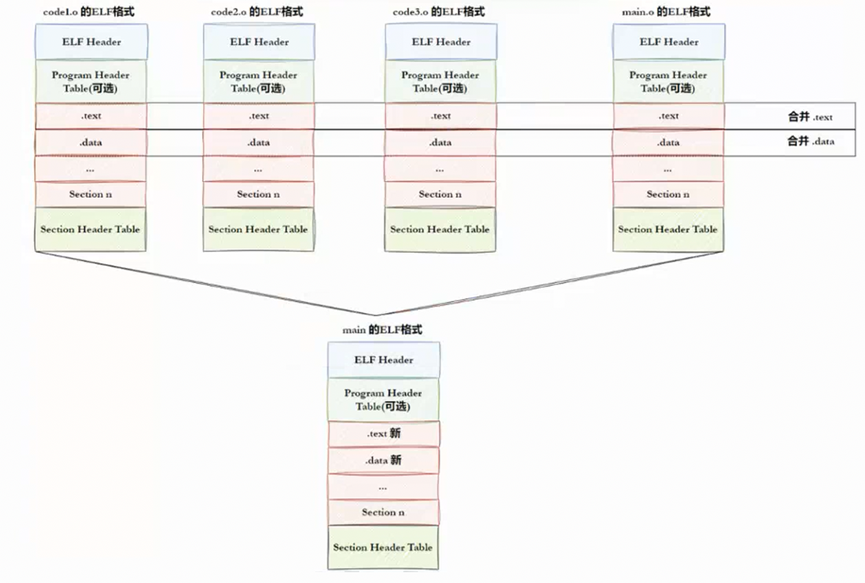
ELF格式由以下四部分构成:
● ELF头 (ELF header) :描述文件的主要特性。其位于文件的开始位置,它的主要目的是定位文件的其他部分
**●**程序头表 (Program header table) :列举了所有有效的段(segments)和它们的属性。表里记着每个段的开始的位置和偏移量(offset)、长度,毕竟这些段,都是紧密的放在二进制文件中,需要段表的描述信息,才能把它们每个段分割开
**●**节头表 (Section header table) :包含对节(sections)的描述
**●**节(Section):ELF文件中的基本组成单位,包含了特定类型的数据。ELF文件的各种信息和数据都存储在不同的节中,如代码节存储了可执行代码,数据节存储了全局变量和静态数据等
使用指令:size 可执行程序文件名,可以看到可执行程序中有多少个数据节:
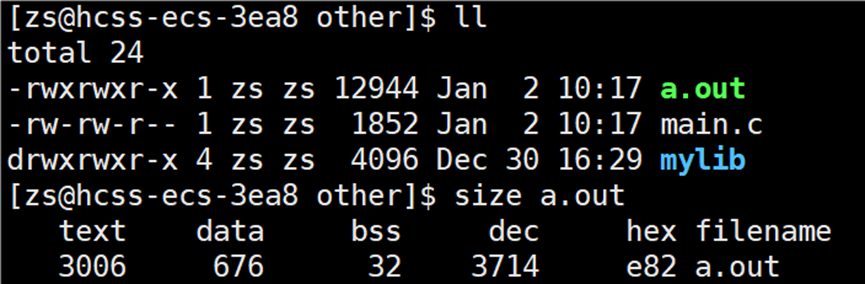
我们可以知道在生成可执行程序时,就已经将代码和数据分开了。
ELF文件中不同节中保存的内容不一样。
最常见的节是:(使用 size 指令可以看到一个可执行程序的代码节和数据节的大小)
代码节(.text):用于保存机器指令,是程序的主要执行部分
数据节(.data):保存已初始化的全局变量和局部静态变量
既然 ELF 格式中存在着这么多的节,免不了对这些进行管理,Section Header Table 就是管理节的,文件中一共有多少个节,每个节的内容是什么等等。
既然 ELF 格式由那四部分构成,那么我们是否可以直观的看到这些结构呢?
查看 ELF header 信息,使用指令:readelf -h 可执行程序名,显示 ELF 格式文件的 ELF header 文件头信息。文件头包含了 ELF 文件的基本信息,比如文件类型、机器类型、版本、入口点地址、程序头表和节头表的位置和大小等。
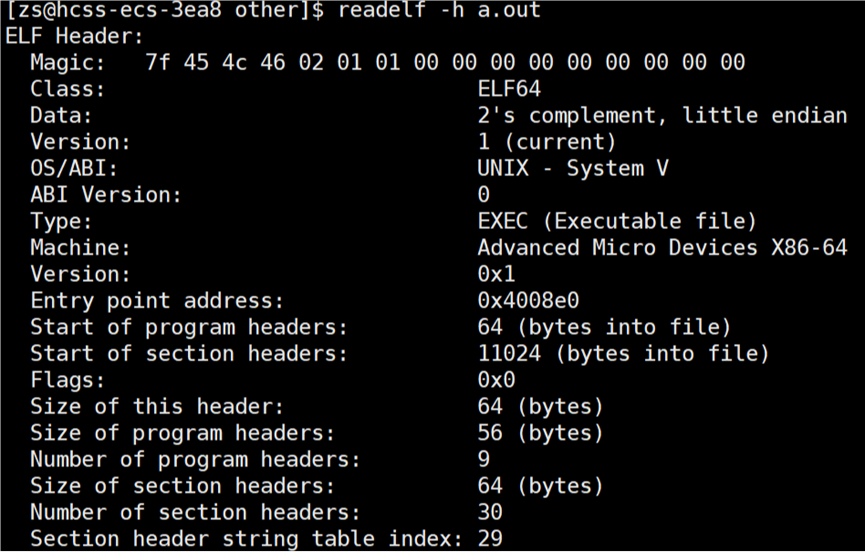
这和磁盘文件的 ext2_inode 结构体一样,结构体中不是只是包含 i_block 数组,也会包含文件的相关所有属性(除了文件名)。在 linux 系统中一切皆文件,ELF 文件都是文件,文件=文件内容+文件属性,上图显示的 ELF Header 的信息很明显是文件的内容,可执行程序 a.out 的内容被划分成了多层结构。我们将文件当作数组,此时再来看 ELF 格式,program header 的起始地址在 64,说明数组前 64 个字节保存的是 ELF Header 的信息。注意看字段 ------ Entry point address:0x4008e0,它代表着可执行程序的入口地址。
使用指令:readelf -S 可执行程序名,查看 ELF 格式中节的信息,也就是查看 Section Header Table 中的信息。

一共30个节。
13 .text PROGBITS 00000000004008e0 000008e0
00000000000003b2 0000000000000000 AX 0 0 16
text就是代码段,AX中的X表示该节是可执行的,000008e0(0x8e0)表示的是偏移量
24 .data PROGBITS 0000000000602080 00002080
0000000000000004 0000000000000000 WA 0 0 1
该节存储的是程序中已初始化的全局变量和静态变量
27 .symtab SYMTAB 0000000000000000 000020b8
0000000000000720 0000000000000018 28 46 8
该节保存的就是符号表
Section Header Table 是一个由 Section Header 组成的数组,每个 Section Header 描述了一个节。读取 ELF 文件开头的 ELF Header(64 字节),从 ELF Header 中提取:e_shoff ------ Section Header Table 在文件中的偏移,e_shnum ------ 节头数量,e_shentsize ------ 每个节头的大小。根据 e_shoff 定位到 Section Header Table,遍历每个 Section Header,从中读取:sh_offset ------ 该节在文件中的起始偏移,sh_size ------ 节的大小,sh_addr ------ 该节在内存中的虚拟地址。由此可定位并读取任意节的内容。
使用指令:readelf -l 可执行程序名,查看 Program Header Table 的信息。
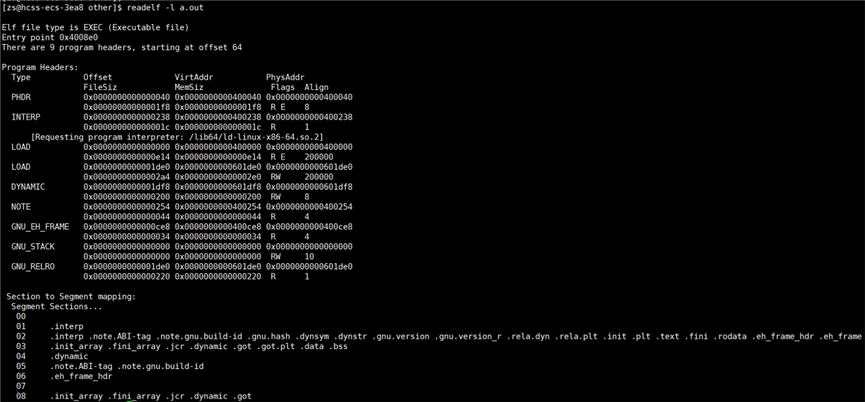
一共有9个 program Header,从文件的偏移量64开始。
Program Header Table 描述的是可执行程序中的段信息,段信息就是地址空间中的代码区,初始化数据区,未初始化数据区,共享区。段信息并不直接存在 ELF 格式中,即 ELF 格式中没有一个一个的段,但是 ELF 中存在一个一个的数据节。
不同的数据节,大小不一样,权限可能有相同的。ELF 是文件,文件有自己的文件内容,OS 读取磁盘文件内容是以 4KB 为单位导入到内存中的,一个可执行程序要加载到内存,可执行程序在磁盘上存储时内容可以随便放,因为磁盘的空间很大,但是可执行程序加载到内存中时,就不一样了,内存比磁盘宝贵,不同数据节大小不一,如果每个节都单独使用一个4KB,可执行程序中有30个节,岂不是要耗费30个4KB大小的空间,并且这30个4KB大小的空间可能还没有使用完。
为了更好的实现内存加载和节省空间,我们可以将多个具有相同权限的节在加载时,由加载器帮助我们对这些节进行合并,压缩形成一个一个的段。ELF 文件中没有名为'段'的数据节,但通过 Program Header Table 明确定义了若干个可加载段,段在文件生成时就已确定。
直接看 Section to Sgment mapping 部分的信息:

Sections to Segment mapping 的含义就是规定哪些数据可以合并到一个数据段:
02 .interp .note.ABI-tag .note.gnu.build-id .gnu.hash .dynsym .dynstr .gnu.version .gnu.version_r .rela.dyn .rela.plt .init .plt .text .fini .rodata .eh_frame_hdr .eh_frame
03 .init_array .fini_array .jcr .dynamic .got .got.plt .data .bss
这些节被组织到同一个可加载段中,共享相同的内存映射和权限。这样,操作系统在加载程序时,只需处理少数几个段,而非数十个独立的节,从而提高了加载效率和内存管理的简洁性
所以我们加载运行可执行程序时,应该优先看 program Header table,因为该区域可以告诉我们有几个段需要被加载。program Header Table 虽然服务于"加载",但它是由链接器在构建可执行文件时生成的。
如何查看一个一个的节的信息?我们主要看 text 节的信息,使用指令:objdump -S 可执行程序名,作用是反汇编可执行节。
部分信息如下所示:
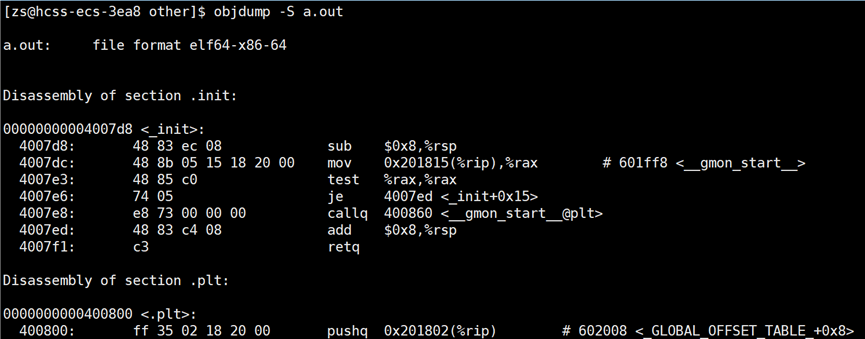
程序反汇编的信息有点多,不好观察,我们可以将反汇编信息写入到一个文件中:

查看 text 节的信息:

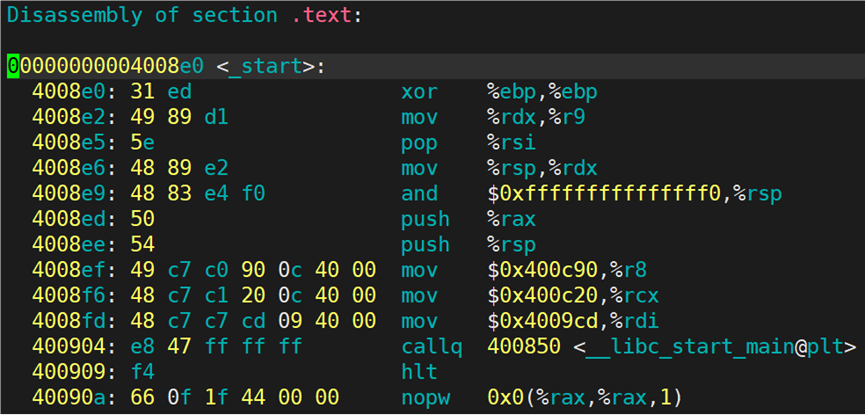
text 节的起始地址是:0x4008e0。
4. 可执行程序加载
创建进程,先创建内核进程相关的数据结构,还是先加载 ELF 格式的二进制文件?先创建内核进程相关的数据结构,再将 ELF 格式的二进制文件加载到创建的内核数据结构中。
磁盘形成可执行程序时,采用的是平坦模式 。在链接阶段,链接器会为代码和数据分配虚拟地址 ,这些地址作为元数据写入可执行文件(如 ELF 格式)中。因此,在磁盘上的可执行文件中,每条指令和数据项都已经关联了一个确定的虚拟地址。这些地址在数值上可以看作是"起始虚拟地址 + 偏移量"的形式。磁盘上可执行文件所记录的地址就是虚拟地址。这些虚拟地址在程序加载前就已存在,并在加载后由操作系统映射到进程的虚拟地址空间中。
程序在未被加载到内存时,其可执行文件(如 ELF 文件)中已经记录了每条指令和数据的虚拟地址。这些地址是由链接器在生成可执行文件时分配的,称为"预设虚拟地址"。虽然此时程序尚未运行,也没有占用任何物理内存,但这些地址作为元数据 已写入 ELF 的 Program Header 和 Section Header 中。因此,当我们使用 objdump -S 查看反汇编代码时,看到的地址(例如 0x4008e0)正是这些预设的虚拟地址。它们不是随意标注的,而是程序未来在内存中期望被加载的位置。需要注意的是:这些地址在加载前只是"蓝图",只有当操作系统将程序加载到进程的虚拟地址空间后,它们才成为真正可访问的虚拟地址。
生成可执行程序时,链接器 会为代码和数据分配预设的虚拟地址。这些虚拟地址在链接阶段就被写入可执行文件(如 ELF 格式)的 Program Header 和 Section Header 中,因此在程序加载到内存之前就已经存在。objdump 正是读取这些地址来标注每条指令的位置。
虚拟地址是现代操作系统内存管理的核心:它构成了每个进程私有的、连续的线性地址空间,由 CPU 的 MMU 通过页表动态映射到物理内存。因此,编译器和操作系统必须共同遵守同一套虚拟地址空间模型。
这是对虚拟地址空间的进一步的理解,有了虚拟地址的了解之后,接下来理解可执行程序的加载。
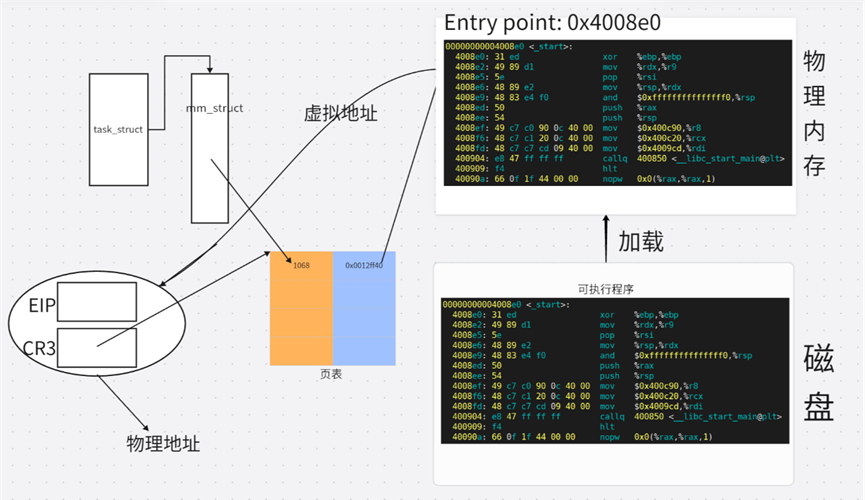
在创建进程时,操作系统首先初始化内核中的进程控制结构(如 task_struct 和 mm_struct),并为其建立独立的虚拟地址空间。接着,内核解析可执行程序的 ELF 文件。ELF 中的 Program Header 记录了每个可加载段的预设虚拟地址 。这些虚拟地址是由链接器在生成可执行文件时分配的 。操作系统并不会立即将整个程序从磁盘复制到物理内存,而是通过内存映射 机制,将 ELF 文件的各个段映射到进程的虚拟地址空间 中。此时,物理内存尚未分配。当 CPU 首次访问某条指令或数据时,会触发缺页异常,内核才从磁盘读取对应的页面到物理内存,并在页表中建立该虚拟地址到物理地址的映射。
在mm_struct结构体存储着地址空间的分布界线,从哪里哪里开始,到哪里哪里结束:
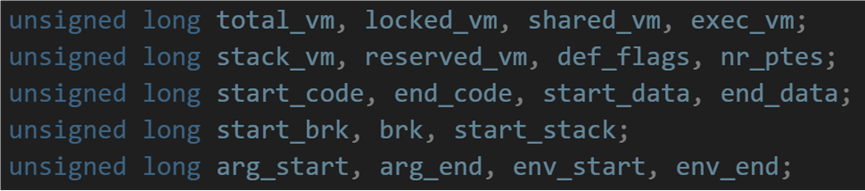
mm_strcut 结构体由谁初始化?初始化数据从哪来?mm_struct 结构体用于描述进程的虚拟地址空间布局,其中的 start_code, end_code, start_data, end_data, start_brk, brk, start_stack 等字段记录了代码段、数据段、堆、栈等关键区域的起始和结束地址。这些字段由操作系统在调用 execve() 加载可执行程序时进行初始化。具体来说,内核会解析可执行文件(如 ELF)的 Program Header Table ,根据 Program Header Table 中的数据计算出各区域的边界。因此,mm_struct 的初始化数据主要来源于 ELF 文件的 Program Header Table,并通过内核的解析逻辑映射为进程的虚拟地址空间布局。
在加载可执行程序时,操作系统会将虚拟地址到物理地址的映射关系(按需)填充到页表中。CPU 从哪行代码处开始执行呢?从可执行程序的 ELF 格式中的 ELF Header 中获取到 Entry point address,如此 CPU 就知道从哪里开始执行程序。CPU 是怎么知道它要执行哪一行代码的?由 PC 指针决定,它是 CPU 中指向下一条要执行指令的指针,程序运行到哪,PC 指针就指到哪。在程序内部进行函数调用(call 函数名)时,调用的是什么地址?虚拟地址。CPU 读取到的地址都是虚拟地址。CPU 中存在一个寄存器叫做 CR3,它保存了当前进程页表的物理地址。程序已经加载到内存,包括其中的代码和调用的函数。当 CPU 需要访问某个虚拟地址对应的数据(或指令)时,它会将该虚拟地址交给 MMU(内存管理单元),MMU 利用 CR3 找到页表,并根据虚拟地址逐级查找,最终找到对应的物理地址,从而通过物理地址从内存中读取所需的数据。这一整套虚拟地址到物理地址的转换工作,是在 CPU 内部由 MMU 自动完成的,对程序完全透明。
查看 a.out 可执行程序的 ELF Header 信息:
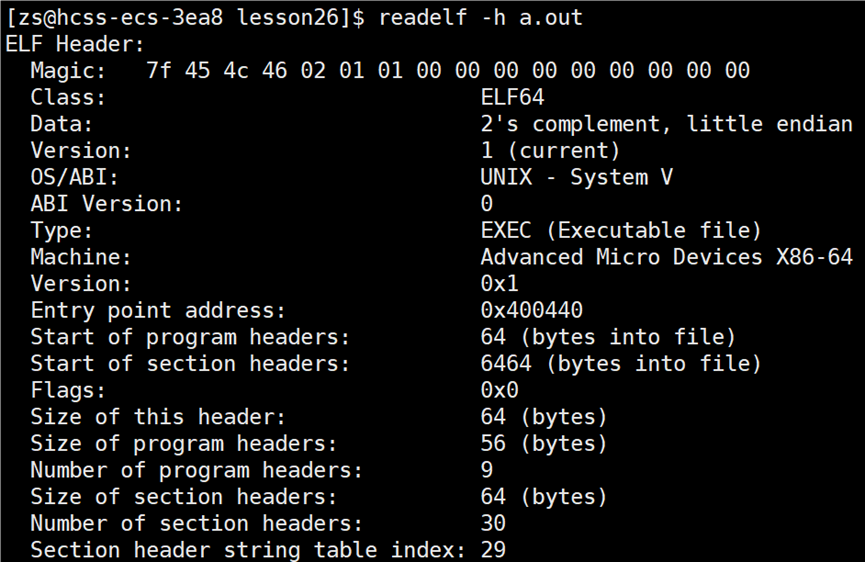
程序运行的起始地址为:0x400440。
查看 a.out 的 text 节的反汇编信息:
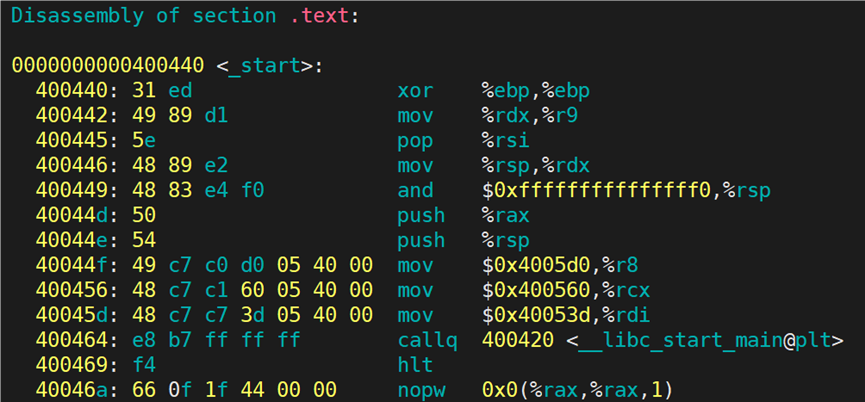
在 Linux 中,可执行程序的实际入口点是 _start 函数,而不是用户编写的 main 函数。
从上图可以看出,_start 函数会调用<libc_start_main> 函数:

<libc_start_main>经过一系列的跳转,最终会跳转到 main 函数处:

代码经过编译和汇编后,最终会转换为机器指令的二进制形式。从反汇编结果可以看出,每条指令在虚拟地址空间中都有一个确定的地址。严格来说,这些地址本身并不是程序运行所必需的------它们主要是为了调试、链接和定位而存在的元数据。真正的可执行文件本质上是一串连续的二进制字节流 。每一行指令都有它最基本的要素:指令的长度,操作码(读/写),数据等等,代码变成二进制后,有些01表示指令的长度,有些01表示数据。CPU 在执行可执行程序时,并不需要"看到"地址,它只需要从入口点开始顺序读取字节,并根据当前指令的编码解析出其长度和操作码。当 CPU 完成当前指令的读取和译码后,会将 PC 指针向前移动该指令的字节数,从而自然地指向下一条指令的起始位置 。因此,只要知道程序的入口地址,CPU 就能从那里开始,通过不断"读取 → 译码 → 推进 PC" 的循环,依次执行后续所有指令------无需预先知道每条指令的地址。
CPU 本身无法理解"磁盘""网卡""文件"等高层概念,它只能执行一些最基本的运算和控制操作 ,比如加法、减法、逻辑运算、数据移动、条件跳转等。为什么 CPU 能理解这些基本操作?因为每款 CPU 在设计时都定义了一套指令集 。CPU 刚被制造出来时,"什么都不懂"------它的行为完全由硬件电路实现的指令集决定。我们可以把指令集看作是 CPU 能够识别和执行的基本"动作"集合 。所有复杂的程序行为,最终都是通过组合这些基本指令来完成的。因此,当我们编写高级语言程序并进行编译时,本质上是将这些高级逻辑翻译成目标 CPU 指令集所对应的二进制机器码 。这也是为什么程序最终必须以二进制形式存在:因为 CPU 的指令本身就是用二进制编码的,只有这样才能被硬件直接识别和执行。
那么,为什么会有汇编语言?汇编语言其实就是机器指令的符号化表示。我们反汇编看到的 mov, add, call 等指令,就是与 CPU 指令集一一对应的文本形式。汇编器的作用,就是把这些助记符转换为对应的二进制机器码,从而让 CPU 能够执行。
为什么我们在 Windows 或 macOS(运行在 PC 或服务器上)编译的程序不能直接在安卓或 iPhone 手机上运行?虽然程序最终都是以二进制形式 存在的,但关键在于:不同平台的 CPU 使用不同的指令集 。在传统的 PC 和服务器上,通常使用的是 Intel 的 x86/x86-64 架构 CPU ,其指令集是 x86。而绝大多数安卓手机和苹果 iPhone/iPad 使用的是 ARM 架构的 CPU ,其指令集是 ARM。因此,即使两个程序看起来都是"01 组成的二进制",但它们所包含的机器指令对彼此的 CPU 来说是无法识别甚至非法的。
不同的编译器可以将同一份源代码编译成适用于不同平台的可执行程序,这体现了软件在源码层面的可移植性 。然而,编译后的二进制程序通常不具备跨平台性 。其根本原因有两个:在硬件层面,不同 CPU 架构使用不同的指令集;在软件层面,不同操作系统提供了不同的系统调用接口和运行时环境。即使指令集相同,程序也可能因为调用了某个 OS 特有的系统调用而无法在另一个 OS 上运行。因此,我们说一个二进制程序不具备跨平台性,本质上是因为:硬件差异体现在指令集上;软件差异体现在操作系统及其系统调用上。
5. 理解链接
1. 静态链接
我们可以清晰地观察到静态库参与静态链接的过程,而动态库无法参与静态链接(它只能在运行时被动态加载或链接)。程序与静态库进行静态链接时,链接器会从静态库提取程序实际用到的目标文件,并将这些 .o 中的代码和数据合并到最终的可执行文件中 。正因为如此,静态链接生成的可执行程序通常体积较大。
无论是自己的 .o ,还是静态库中的 .o ,本质都是把 .o 文件进行链接的过程,所以研究静态链接本质就是研究 .o 是如何链接的。
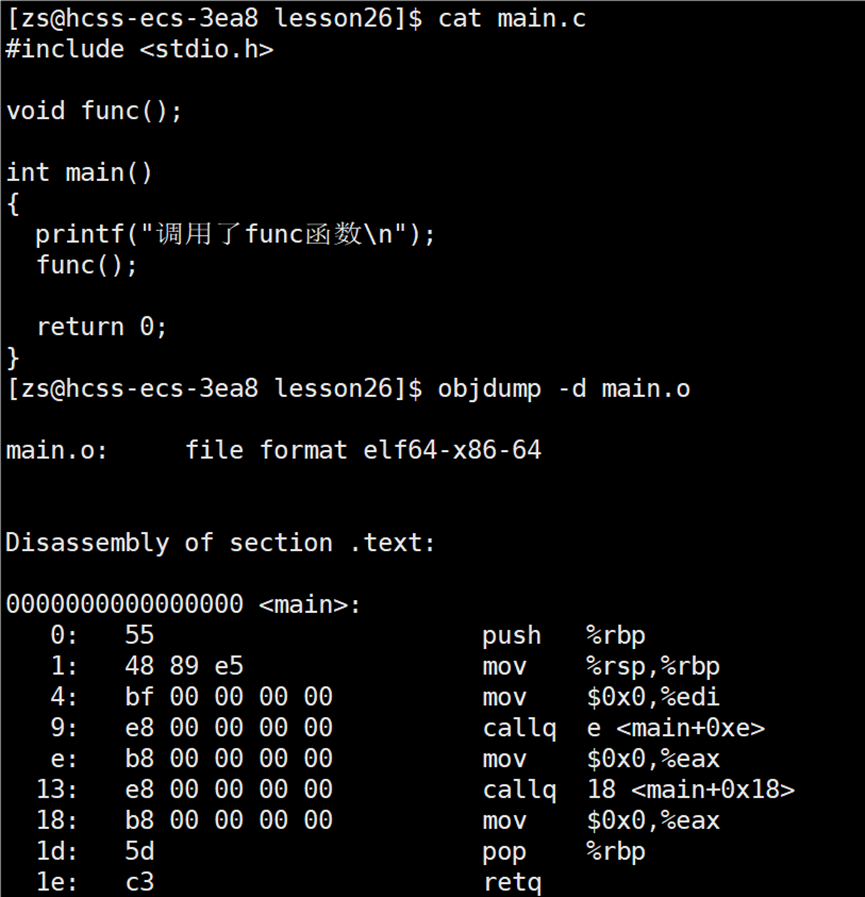
创建两个文件:main.c 和 func.c,main.c 文件中调用了 func.c 中的内容。
main.c 的内容如下所示:
cpp
#include <stdio.h>
void func();
int main()
{
printf("调用了func函数\n");
func();
return 0;
}func.c 的内容如下所示:
cpp
#include <stdio.h>
void func()
{
printf("hello linux\n");
}将 main.c 和 func.c 文件编译成 .o 文件,将所有 .o 文件链接形成可执行程序:
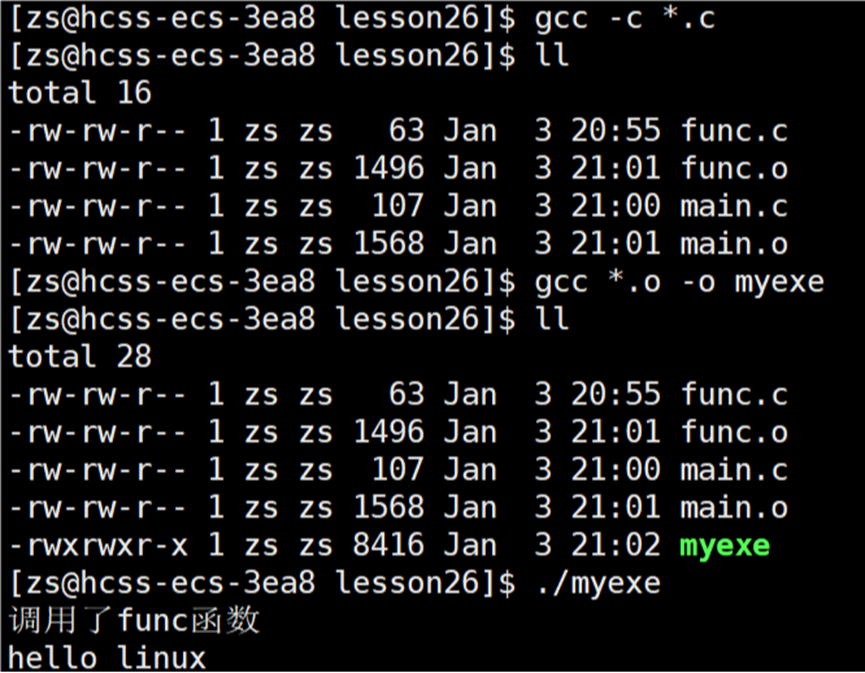
使用指令:objdump -d *.o,查看 .o 文件的 .text代码节的反汇编信息。
main.o 文件的 text节 反汇编信息:
func.o 文件的 text节 反汇编信息:
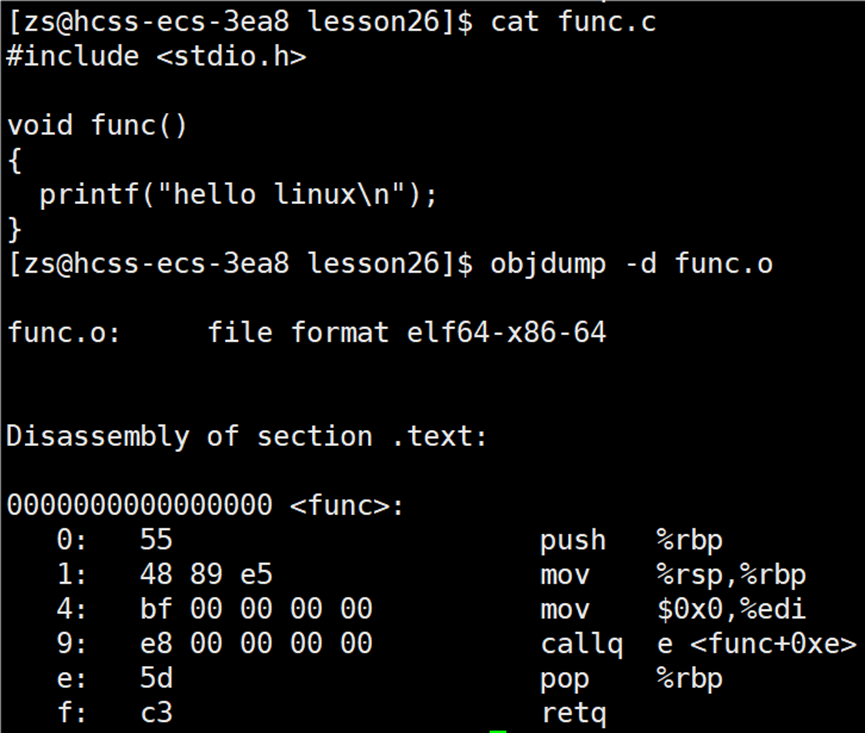
在 main.o 文件的反汇编信息中,可以看到 main 函数确实存在。其中有一条 callq 指令,其机器码为 e8 00 00 00 00,这表示调用了一个函数,但目标地址目前是全零 。同样,在 func.o 的反汇编中,func 函数也包含一条 callq 指令,其机器码同样是 e8 00 00 00 00,调用的是 printf 函数。e8 后面跟着的是全0,说明该函数调用的目标地址尚未确定。 此外,main.o 中还有一条 callq 指向 <main+0x18>,这是对 func() 的调用。虽然 func 定义在另一个 .o 文件中,但在链接前,其地址也未知,因此同样用 0x0 占位。所以,在 .o 文件中,只要调用了其他文件中定义的函数,即使有声明,其调用地址也会在反汇编中显示为全 0,表示"待链接时解析"。
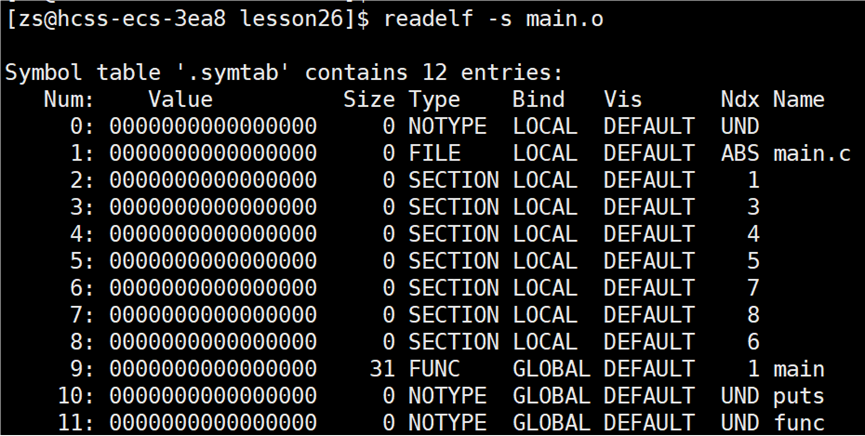
使用指令:readelf -s *.o,读取 .o 文件中的符号表信息。
main.o 文件中符号表的信息:
func.o 文件中符号表的信息:
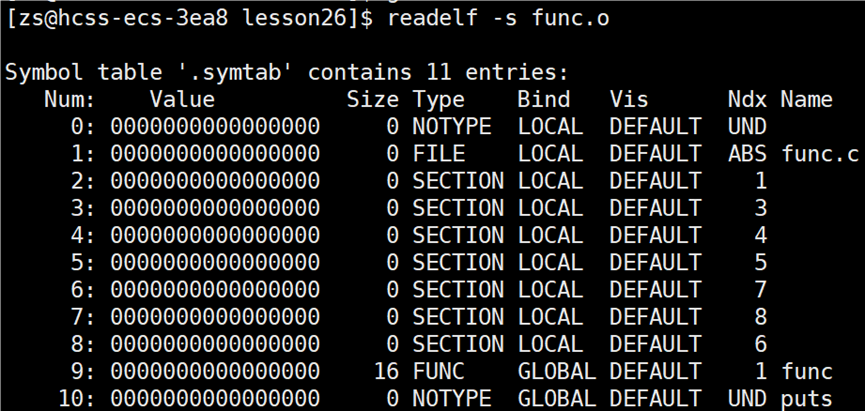
puts 是 printf 函数底层调用的 puts 函数,前面的 UND 表示 undefine未定义 的意思。
将两个 .o 文件链接形成可执行程序:

读取可执行程序的符号表,看看 func,puts 函数是否不是 UND。
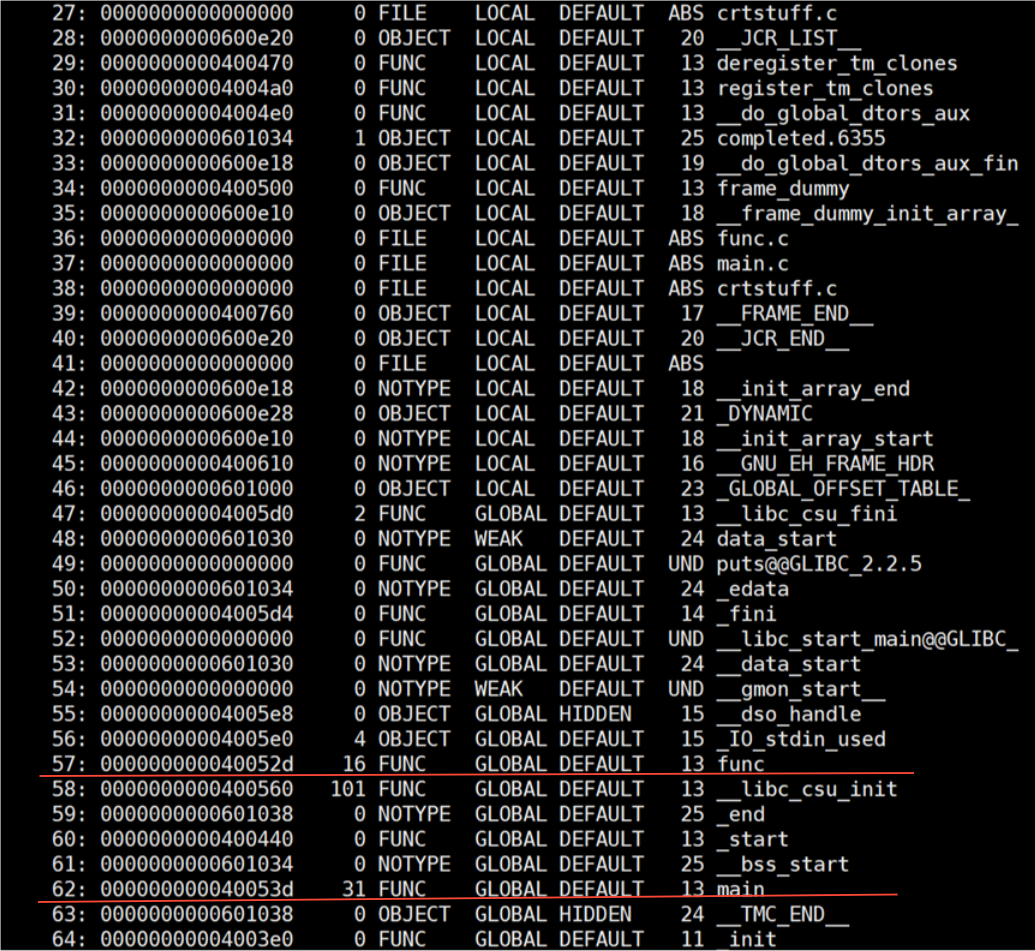
一旦形成可执行程序,符号表中不能存在未定义符号(UND)------ 因为链接器的任务就是解析所有外部引用。在我们调试代码时出现xxx undefined,这个错误就是在链接时发现的。在 func.o 中,func 函数是本地定义的,因此它是"已定义"的;而 printf 或 puts 是外部函数,不在本文件中,所以在 func.o 的符号表中,它们的状态为 UND 。当链接器处理 main.o 时,它发现其中调用了 func(),但该函数在 main.o 中没有定义,因此标记为 UND。随后,链接器扫描 func.o,发现其中正有 func() 的定义,于是将 main.o 中的 func 引用与 func.o 中的定义进行匹配,这一过程称为符号对照。
再读取 main.exe 可执行程序的节表,只看 text节 的信息。

对照 main.exe 的符号表的 main 函数和 func 函数所在的节。

func和main符号再哪个节中呢?在13号节中,而13号节就是代码节,这说明:我们编写的 C 函数代码,在经过编译和链接后,最终被放置在可执行文件的 .text 节中,这也是程序运行时 CPU 执行指令的地方。
查看可执行程序 main.exe 的 text节 的反汇编信息:
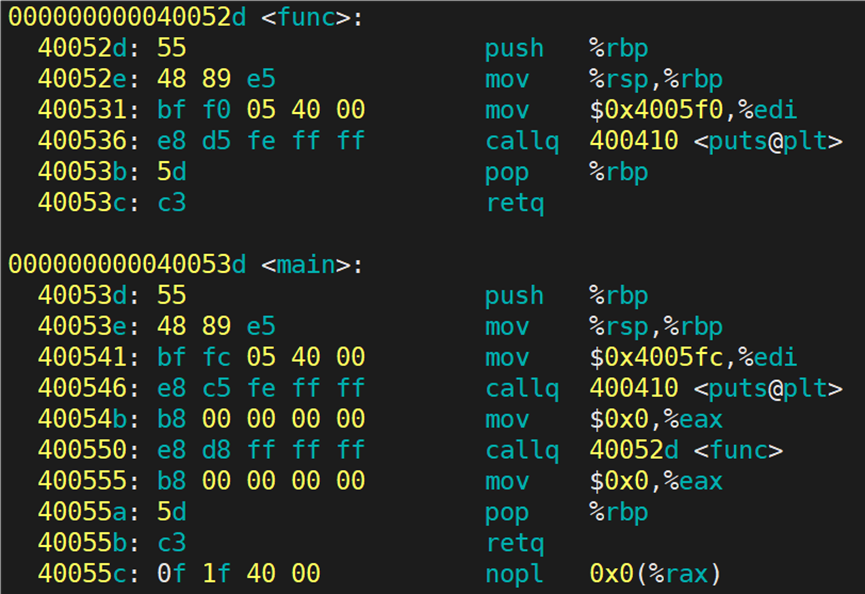
我们能够在可执行程序的反汇编信息看到 main 函数和 func 函数,这说明:在链接阶段,链接器将 main.o 和 func.o 中的代码段(.text)合并到了最终的可执行文件中。
前文提到可执行程序是以平坦模式将自己的代码从全0到全F编址的,在这个地址空间中,main 函数和 func 函数都被分配了确定的虚拟地址 。func 函数位于 0x40052d,main 函数位于 0x40053d 。在 main.exe 的反汇编中可以看到,main 函数调用 puts 和 func 时,call 指令的操作码 e8 后面不再是全 0,而是具体的 4 字节偏移值。
在静态链接过程中,链接器会:
- 将 main.o 和 func.o 中用到的代码段(.text)合并到同一个可执行文件中
- 为每个函数分配唯一的虚拟地址,即平坦模式编址
- 查找主文件(如 main.o)中的未定义符号引用(如对 func 的调用)
- 找到这些符号在其他 .o 文件中的定义(如 func.o 中的 func)
- 计算出 call 指令所需的相对偏移量
- 将原来占位的 e8 00 00 00 00 中的 00 00 00 00 替换为实际偏移值
将占位地址(0x00)替换为真实地址(或偏移量)的过程,就叫做地址重定位。
总结:
两个 .o 的代码段合并到了一起,合并方法实现到一个可执行文件,并进行了统一的编址
链接的时候,会修改 .o 中没有确定的函数地址,在合并完成之后,进行相关 call 地址,完成代码调用
静态链接的过程,本质上就是将程序自身的 .o 文件与所依赖的静态库 中的 .o 文件进行合并 ------ 这与前面将 main.o 和 func.o 链接的过程完全一致。因此,链接就是将编译后生成的所有目标文件 ,连同用到的静态库 ,组合并拼装成一个独立的可执行文件 。在这个过程中,最关键的一环是地址重定位 (relocation):当所有模块被合并到同一个地址空间后,链接器会扫描每个 .o 文件中的重定位表(Relocation Table),该表记录了哪些指令或数据位置引用了外部符号(如函数、全局变量)。链接器根据这些信息,结合最终分配的虚拟地址,计算出正确的偏移量或绝对地址,并将原来占位的值(如 call 指令中的 e8 00 00 00 00)重写为实际的目标地址或相对偏移。所以,静态链接的本质,就是在生成可执行文件的过程中,对内部所有跨模块的引用。这一过程完成后,就得到了一个自包含、无需外部依赖的可执行程序。
从上述静态链接的过程,我们可以知道静态库没有运行时加载过程;静态链接是在编译后的链接阶段完成的,远早于程序被操作系统加载到内存执行的时刻。
2. 动态库加载
这里谈的是动态库的加载,因为静态库不需要加载,在动态库的加载中又附加了动态链接的过程。
进程创建时,操作系统首先为进程分配内核数据结构(如进程控制块 PCB、内存描述符、文件描述符表等),然后才加载用户程序到内存中。如果这个程序是动态链接的可执行文件 (即依赖 .so 等共享库),那么在它真正开始执行之前,必须完成动态链接过程 。动态链接的第一步,就是由动态链接器加载程序所依赖的所有共享库 。因此,加载程序的过程中,实际上是先加载其依赖的动态库 。如果系统找不到某个必需的动态库,动态链接器会报错,整个程序加载过程就会失败,进程无法启动。
将 main.o 与 func.o 文件链接形成可执行程序,由于链接了 C 标准库,所以可执行程序 main.exe 是动态链接的:

因为 main.exe 可执行程序是动态链接的,用到了C标准库,所以在程序还未加载之前,该程序就已经知道它所依赖的库有哪些。
使用指令查看 main.exe 程序的符号表中 printf 函数所调用的 puts 函数:

puts 方法是 glibc 库中的方法,但是这两个 puts 方法是 UND 的,这表明:虽然 puts 被调用,但其定义不在 main.exe 中,而是来自外部共享库(即 glibc)。尽管 main.exe 是一个完整的可执行文件,但由于它是动态链接的 ,其中一些函数在编译链接阶段并未被"真正绑定"到具体地址,因此它们在符号表中仍然标记为 UND 。这意味着:这些函数的地址在程序运行前是不确定的 ,需要等到运行时由动态链接器从对应的共享库中查找并解析。所以我们可以得出结论:对于动态链接的程序,必须先加载其所依赖的共享库,再执行程序本身。
要想加载程序所依赖的库,首先需要找到这些库,而一个一个的库本质就是磁盘文件,所以要找库本质上就是找磁盘文件!!因此要找到库,就需要知道库的路径,如此才能进行路径解析。正因如此才有了前面提到的3种给系统确定动态库路径的方法。
在运行程序之前,将程序所依赖的库加载到内存中,再将程序自身的代码和数据加载到内存里,并创建进程相关的内核数据结构。进程中需要调用方法,但是这些方法是 UND 呀?不认识这些方法呀?因此进程不仅需要知道程序的代码,还需要知道所依赖的库的代码 。怎样才能知道库的代码呢?动态库本质上是由多个 .o 文件打包而成的共享对象,其中每个函数在库内部都有其相对偏移地址。 当库被加载时,动态链接器会为动态库分配一个起始虚拟地址 ,从而确定每个函数的虚拟地址(函数虚拟地址=起始虚拟地址 + 函数在库中的偏移量) 。这些库代码会被映射到当前进程的虚拟地址空间中 ,映射到进程虚拟地址空间的共享区处。操作系统通过页表 建立虚拟地址到物理内存的映射关系,并将动态库的代码段映射到进程地址空间。最终,当程序调用 puts 等库函数时,实际上是在本进程的虚拟地址空间内进行函数跳转,就像调用本地函数一样------只是目标地址位于共享库的映射区域。
一个动态库在系统中只需要被加载到物理内存一次 。当某个进程需要使用该库时,操作系统并不会重新加载,而是将已加载的动态库映射到该进程自己的虚拟地址空间中 。库本身也有代码和数据。不同的程序可能包含了相同的功能和代码,显然会浪费⼤量的硬盘空间,共享库的本质就是将多个进程需要用到的资源,只需要在内存中形成一份,有效的处理相同资源占用空间的情况。动态库被使用的本质是库被映射到进程的虚拟地址空间中。
前面提到:当某个动态库已经被加载到物理内存中,若后续有另一个程序也依赖该库,则无需重新从磁盘加载 ,而是直接将其映射到新进程的虚拟地址空间中 。但这就引出一个问题:操作系统如何知道哪些动态库当前已被加载?哪些还在被使用? 系统中会同时存在多个库,有的库是新加载到内存中的,有的库已经没有进程再映射它了,若没有进程与该库相关联,那么该库会被释放掉,既然OS中存在这么多的库,OS自然需要管理这些加载到内存中的库,怎么管理?先描述,再组织。
动态链接到底是如何工作的??动态链接实际上将链接的整个过程推迟到了程序加载的时候。当动态库被加载到内存以后,一旦它的内存地址被确定,我们就可以去修正动态库中的那些函数跳转地址了。在 C/C++ 程序中,当程序开始执行时,它首先并不会直接跳转到 main 函数。实际上,程序的入口点 _start ,这是一个由C运行时库(通常是glibc)或链接器(如ld)提供的特殊函数。 在 _start 函数中,会执行一系列初始化操作,这些操作包括:
设置堆栈:为程序创建一个初始的堆栈环境
初始化数据段:将程序的数据段(如全局变量和静态变量)从初始化数据段复制到相应的内存位置,并清零未初始化的数据段
动态链接:这是关键的一步,_start 函数会调用动态链接器的代码来解析和加载程序所依赖的动态库。动态链接器会处理所有的符号解析和重定位,确保程序中的函数调用和变量访问能够正确地映射到动态库中的实际地
动态链接器:动态链接器(如ld-linux.so)负责在程序运行时加载动态库。当程序启动时,动态链接器会解析程序中的动态库依赖,并加载这些库到内存中。环境变量和配置文件:Linux 系统通过环境变量(如LD_LIBRARY_PATH)和配置文件(如/etc/ld.so.conf及其子配置文件)来指定动态库的搜索路径。这些路径会被动态链接器在加载动态库时搜索。
动态库自身没有 main 函数 ,它只包含一组可供其他程序调用的函数和数据。在动态库内部,每个函数在链接时都会被分配一个地址 。但这个地址并不是绝对的虚拟地址 ,而是相对于库文件起始位置的偏移量 。换句话说,动态库在构建时采用以 0 为基地址的平坦地址空间模型 进行编址。例如:函数 A 的地址记为 0x100,函数 B 为 0x200。在动态库内部定位某个函数时,不能直接使用 0x100 作为运行时地址 ,而必须在运行时由动态链接器将该偏移加上库实际加载的基地址,才能得到真正的虚拟地址。
综上,动态链接的整体过程为:
进程创建完毕后,若该程序是动态链接的,则需要将其所依赖的动态库加载到进程中。
第一步是找到动态库文件:要将库加载到内存中需要在磁盘上找到库的位置,进程并不直接知道库的路径,而是由动态链接器(如 ld-linux.so)根据可通过环境变量(如LD_LIBRARY_PATH)和配置文件(如/etc/ld.so.conf及其子配置文件)来指定动态库的搜索路径,一旦确定库的完整路径,进行路径解析,操作系统就通过文件系统查找该文件:定位其所在磁盘块,获取其 inode,读取文件内容。
第二步是将库加载并映射到进程的虚拟地址空间:内核为当前进程的 mm_struct 创建新的 vm_area_struct,通过系统调用,将动态库的代码段(.text)和数据段(.data)映射到进程的虚拟地址空间中,此时,动态库获得一个起始虚拟地址。
第三步是建立虚拟地址到物理地址的映射:库的内容被加载到物理内存,进程的页表建立从进程虚拟地址 → 物理页帧的映射关系;因此,库不仅有了虚拟地址,也关联了对应的物理地址。动态库在构建时,每个函数的地址是以 0为起始虚拟地址的偏移量记录的;运行时,函数的虚拟地址 = 库的加载起始虚拟地址 + 函数偏移量;而由于虚拟地址已通过页表映射到物理内存,其函数对应的物理地址也随之确定。
因此,只要知道动态库的起始虚拟地址(和底层页表映射),就能动态计算出库中任意函数的虚拟地址和物理地址。
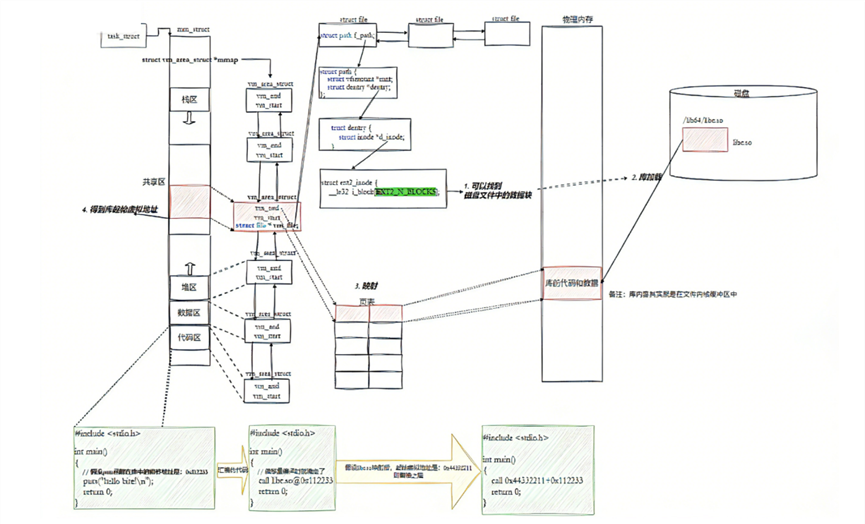
尽管库可能被加载到不同于其他进程的地址 ,但库内部各段在虚拟地址空间中仍然是连续的 ,并非"分散"成碎片 。因此,只要知道库的加载基地址和函数的偏移量,就能动态计算出该函数在当前进程中的虚拟地址 。而由于该虚拟地址已通过进程页表 映射到物理内存,其对应的物理地址也可由 MMU 自动转换得出。所以,无论库被加载到哪个虚拟地址,只要偏移量不变,所有函数的运行时地址都能正确计算出来。
静态链接和动态链接的对比:
静态链接在构建时完成地址绑定,而动态链接在程序运行时由动态链接器加载库并重定位调用地址,库的虚拟地址范围由进程的 vm_area_struct 结构中的 vm_start 记录,只有运行时程序才与动态库真正关联
在动态链接中,函数调用的目标地址确实需要在运行时确定。但代码段 (.text)是只读的,因此我们不能直接修改 call 指令的后面的内容。针对这种情况:动态链接采用的做法是 .data (可执行程序或者库自己)中专门预留一片区域用来存放函数的跳转地址,它也被叫做全局偏移表GOT,表中每一项都是本运行模块要引用的一个全局变量或函数的地址。因为 .data 区域是可读写的,所以可以支持动态进行修改。由于代码段只读,我们不能直接修改代码段,但有了GOT表,代码便可以被所有进程共享。
然而,由于不同进程加载动态库的起始虚拟地址不同 ,GOT 中存储的绝对地址也各不相同 ,因此每个进程必须拥有自己独立的 GOT 表副本 ,即 GOT 不能在进程间共享 。在单个.so下,由于GOT表与 .text 的相对位置是固定的,我们完全可以利用 CPU 的相对寻址来找到 GOT 表。函数调用时,程序先通过 PLT (Procedure Linkage Table),再从 GOT 中取出目标函数的真实地址进行跳转 。这种机制使得动态库无需在加载时修改任何代码段内容 ,无论被加载到哪个虚拟地址,都能正确运行------这就是 PIC (Position-Independent Code,位置无关代码)。正因如此,我们在编译动态库时必须加上 -fPIC 参数,告诉编译器生成基于相对地址和 GOT/PLT 的代码,而不是依赖固定地址的绝对跳转。
在 ELF 格式中除了 .text 节,还存在着 .got 节:

.got 节通常与 .data 节合并在一起,作为可读写的数据段,在程序加载时被映射到进程的虚拟地址空间中。

got 中记录进程使用的库方法的偏移地址和库地址, 当程序调用某个库函数时,并不是直接使用 call <绝对地址>,而是:先跳转到 PLT(Procedure Linkage Table)中的对应条目,PLT 通过相对寻址访问 .got.表,从 .got中取出目标函数的真实虚拟地址,然后跳转到该地址执行函数。因此,函数调用的本质是:通过 GOT 表进行间接跳转 。由于 .got 位于可读写的数据段,可以在运行时安全地修改其中的地址值 ,而无需改动只读的 .text 代码段。这种机制实现了地址重定向 ------ 即在不修改代码的前提下,将函数调用指向正确的运行时地址,从而支持动态链接。