目录
1.什么是库
库是写好的现有的,成熟的,可以复⽤的代码。现实中每个程序都要依赖很多基础的底层库,不可能每个⼈的代码都从零开始,因此库的存在意义⾮同寻常。
本质上来说库是⼀种可执⾏代码的⼆进制形式,可以被操作系统载⼊内存执⾏。库有两种:
静态库 .aLinux 、 .libwindows
动态库 .soLinux 、 .dllwindows
ubuntu环境下的C语言动静态库:
ubuntu环境下的C++动静态库:


2.静态库
静态库(.a):程序在编译链接的时候把库的代码链接到可执⾏⽂件中,程序运⾏的时候将不再需要静态库。
⼀个可执⾏程序可能⽤到许多的库,这些库运⾏有的是静态库,有的是动态库,⽽我们的编译默认为动态链接库,只有在该库下找不到动态.so的时候才会采⽤同名静态库。我们也可以使⽤ gcc的 -static 强转设置链接静态库。
注:动静态库中,不需要包含main函数,所有的库,本质都是源文件对应的 .o
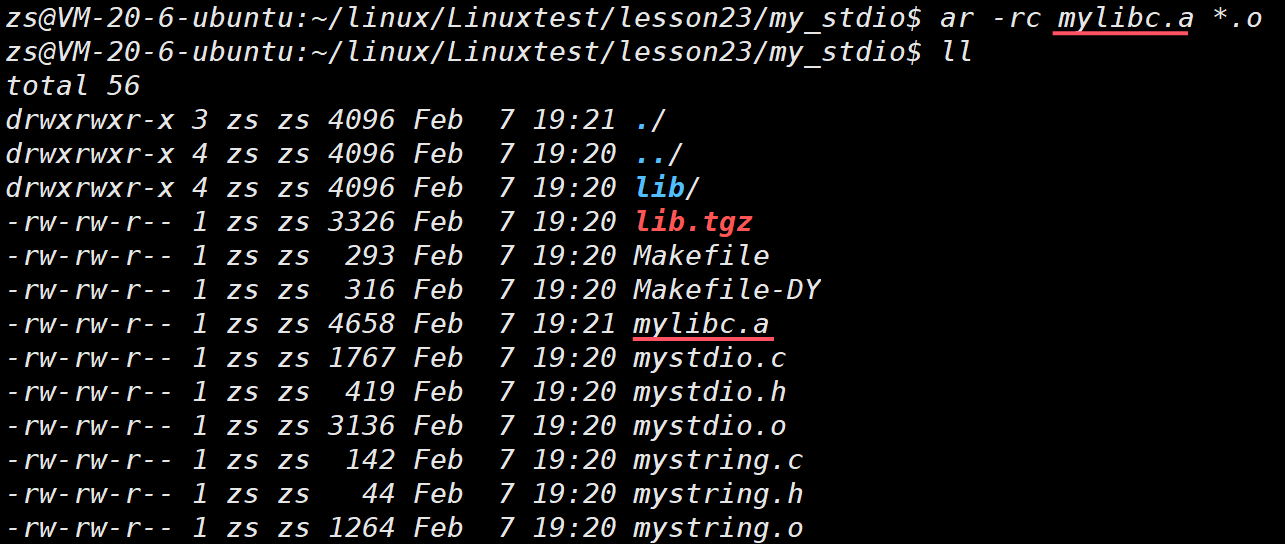
2.1静态库生成
ar 是 gnu 归档⼯具, rc 表⽰ (replace and create)
-t: 列出静态库中的⽂件
-v:verbose 详细信息
普通方法:
.a静态库,本质是一种归档文件,不需要使用者解包,而是用gcc/g++直接链接使用
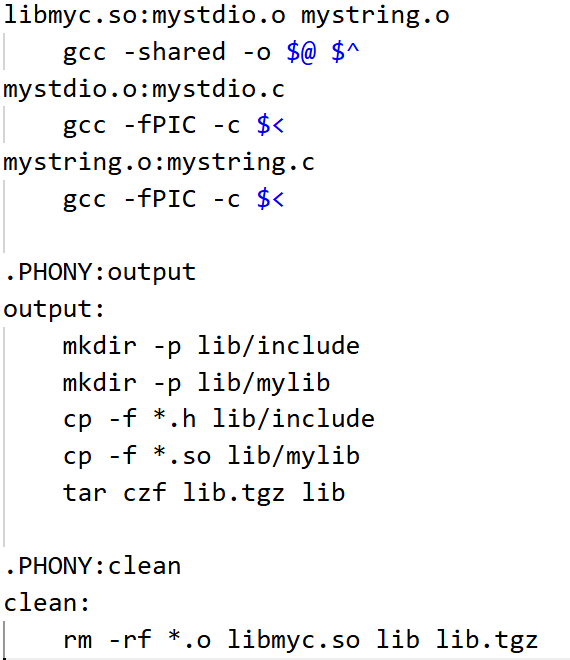
Makefile脚本

2.2静态库使用
库应用的三个场景:
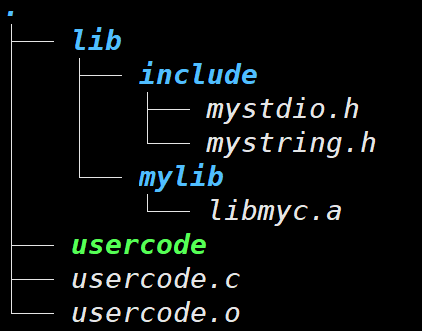
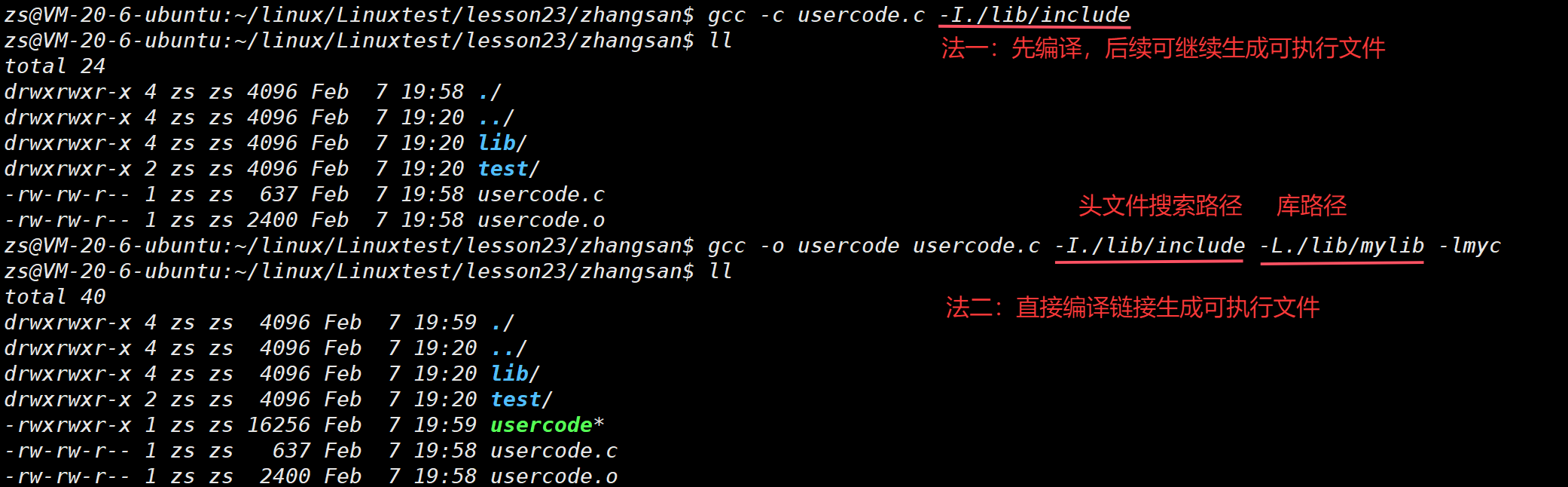
(-L): 指定库路径,去哪里找库
(-I): 指定头⽂件搜索路径
(-l): 指定库名,找什么库
-测试⽬标⽂件⽣成后,静态库删掉,程序照样可以运⾏
-关于 -static 选项,稍后介绍
-库⽂件名称和引⼊库的名称:去掉前缀 lib ,去掉后缀 .so , .a ,如: libc.so -> c
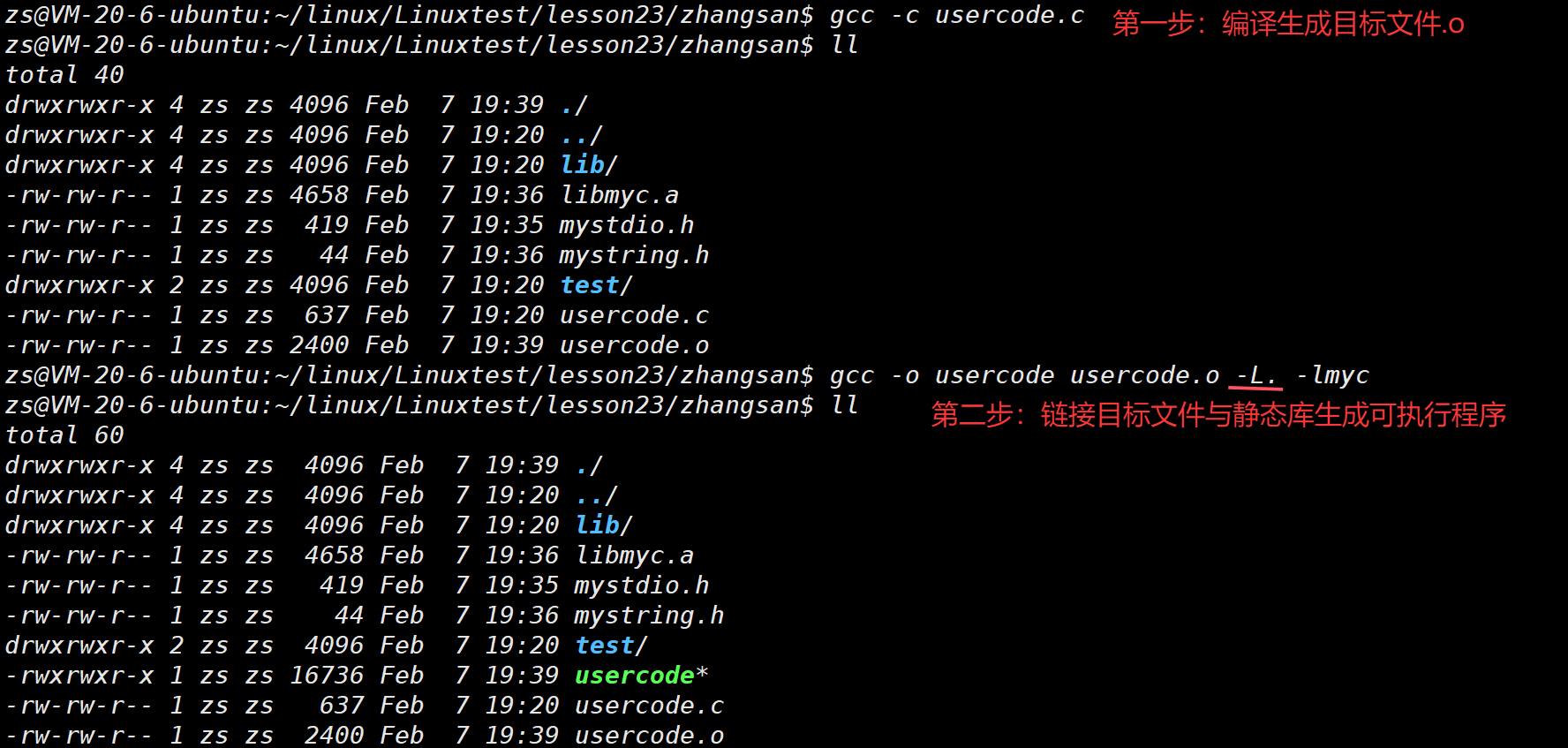
场景一:头⽂件和库⽂件和我们⾃⼰的源⽂件在同⼀个路径下
如果要链接任何非C/C++的库,都要指明-L
场景2:头⽂件和库⽂件有⾃⼰的独⽴路径
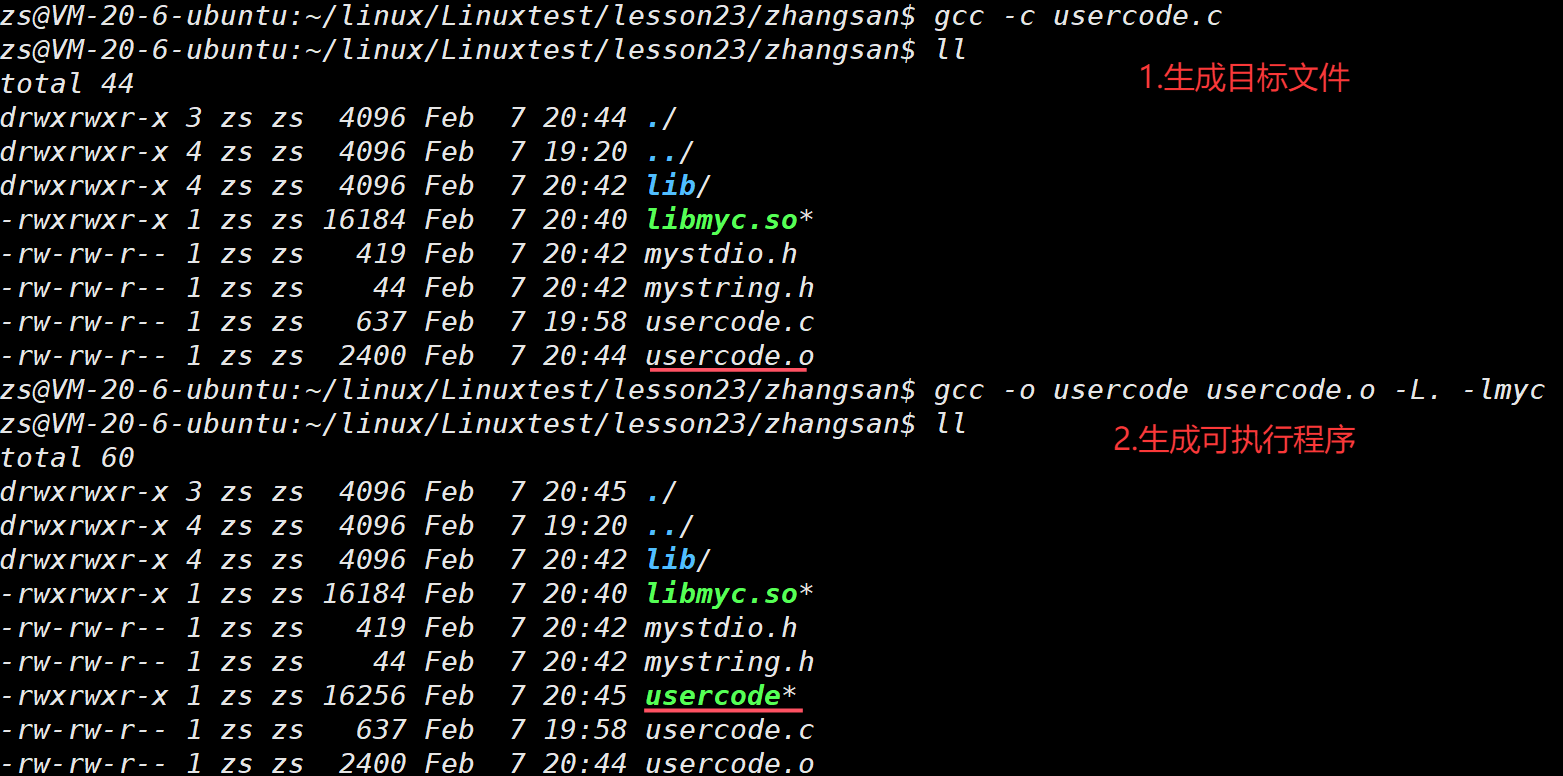
场景三:库也可以被安装到系统中的,这时编译链接不需要指定路径。若已经安装到系统,使用:gcc usercode.c -lmyc
3.动态库
动态库(.so):程序在运⾏的时候才去链接动态库的代码,多个程序共享使⽤库的代码。
⼀个与动态库链接的可执⾏⽂件仅仅包含它⽤到的函数⼊⼝地址的⼀个表,⽽不是外部函数所在⽬标⽂件的整个机器码
在可执⾏⽂件开始运⾏以前,外部函数的机器码由操作系统从磁盘上的该动态库中复制到内存中,这个过程称为动态链接(dynamic linking)
动态库可以在多个程序间共享,所以动态链接使得可执⾏⽂件更⼩,节省了磁盘空间。操作系统采⽤虚拟内存机制允许物理内存中的⼀份动态库被要⽤到该库的所有进程共⽤,节省了内存和磁盘空间。
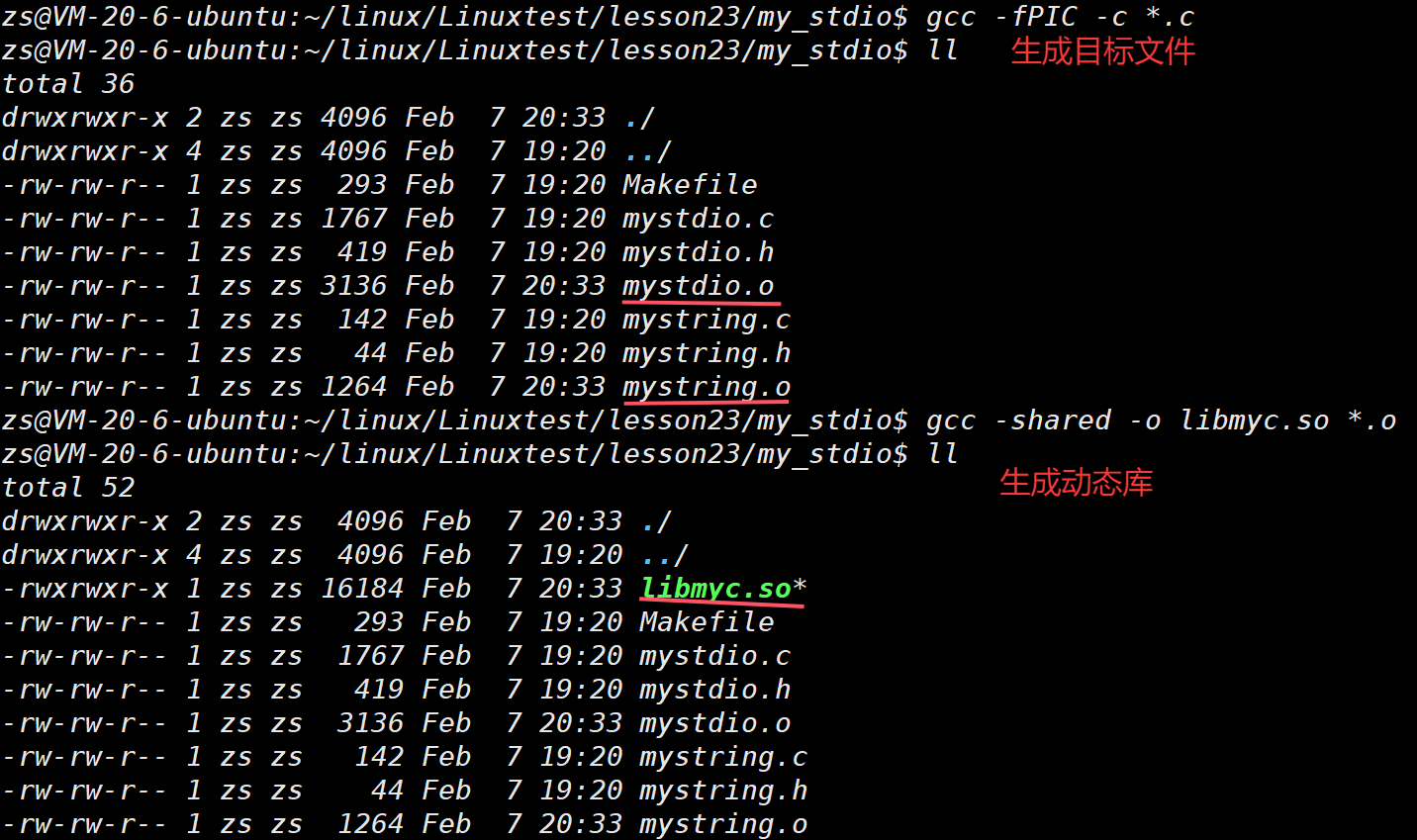
3.1动态库生成
shared: 表⽰⽣成共享库格式
fPIC:产⽣位置⽆关码(position independent code)
库名规则:libxxx.so
普通方法:
Makefile脚本:
结论1:gcc/g++默认使用动态库非得静态链接带-static前提得有静态库结论2:在linux系统下,默认情况安装大部分库,优先安装动态库
结论3:库:应用程序 = 1:n
结论4:vs不仅能形成可执行程序,也能形成动静态库
3.2动态库使用
场景一:头⽂件和库⽂件和我们⾃⼰的源⽂件在同⼀个路径下
如果要链接任何非C/C++的库,都要指明-L
场景2:头⽂件和库⽂件有⾃⼰的独⽴路径


3.3库运行搜索路径
3.3.1问题
上面我们已经形成了可执行文件,但是无法运行。为什么会这样?
Linux 动态链接器在运行时会按以下顺序搜索动态库:
- 可执行文件内部记录的
rpath(编译时用-Wl,-rpath=选项指定)- 环境变量
LD_LIBRARY_PATH- 系统配置文件
/etc/ld.so.conf里的路径- 系统默认路径
/lib、/usr/lib你的问题就是
libmyc.so不在上述任何一个搜索路径里。

3.3.2解决方案
拷⻉ .so ⽂件到系统共享库路径下, ⼀般指 /usr/lib 、 /usr/local/lib 、 /lib64 或者开篇指明的库路径等
向系统共享库路径下建⽴同名软连接
更改环境变量: LD_LIBRARY_PATH
这个环境变量是内存级的,关闭xshell后就失效
ldconfig⽅案:配置/ etc/ld.so.conf.d/ ,ldconfig更新
总结:
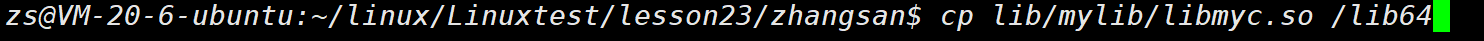



4.使用外部库
我们现在没接触过太多的库,唯⼀接触过的就是C、C++标准库,这⾥我们可以推荐⼀个好玩的图形库:ncurses
// 安装
// Centos
sudo yum install -y ncurses-devel *// ubuntu* sudo apt install -y libncurses-dev
5.目标文件
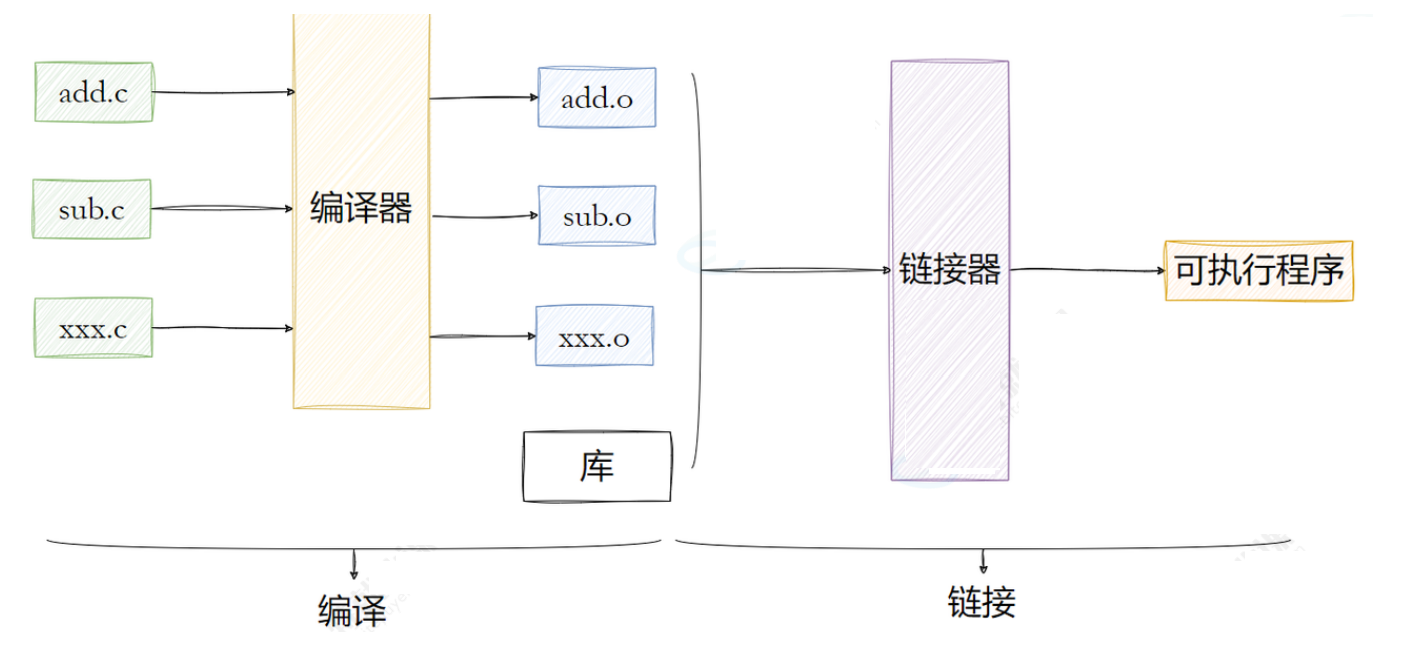
编译和链接这两个步骤,在Windows下被我们的IDE封装的很完美,我们⼀般都是⼀键构建⾮常⽅便,但⼀旦遇到错误的时候呢,尤其是链接相关的错误,很多⼈就束⼿⽆策了。在Linux下,我们之前也学习过如何通过gcc编译器来完成这⼀系列操作。
接下来我们深⼊探讨⼀下编译和链接的整个过程,来更好的理解动静态库的使⽤原理。
先来回顾下什么是编译呢?编译的过程其实就是将我们程序的源代码翻译成CPU能够直接运⾏的机器代码。
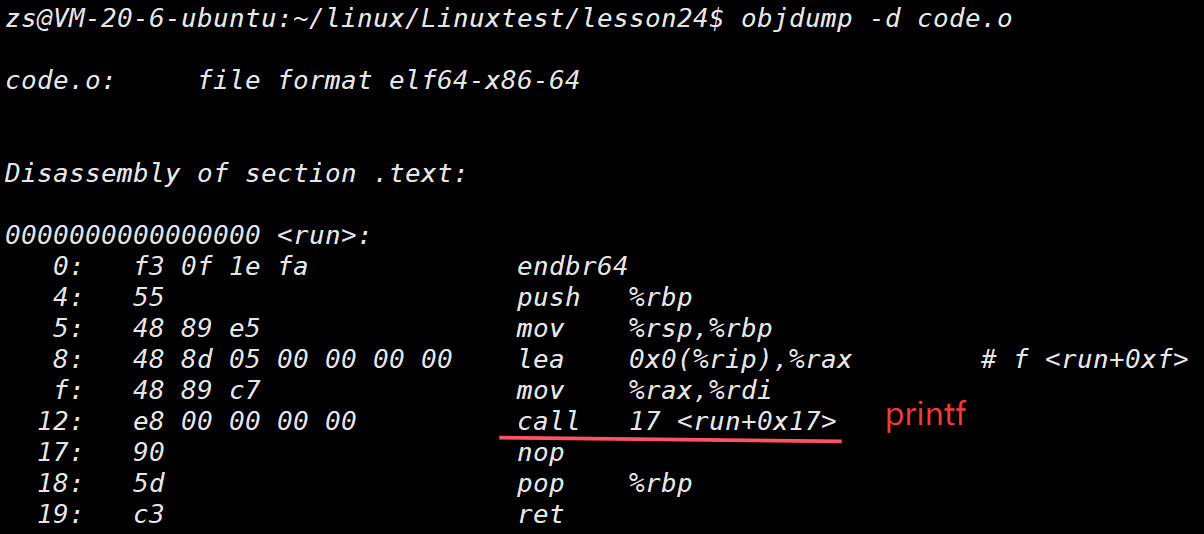
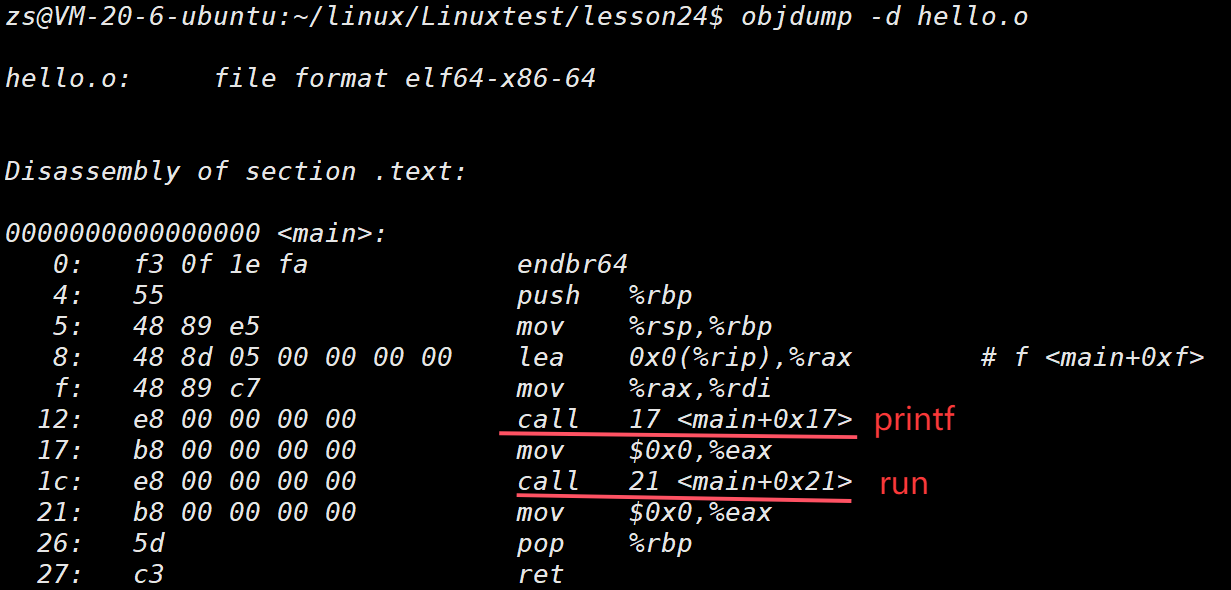
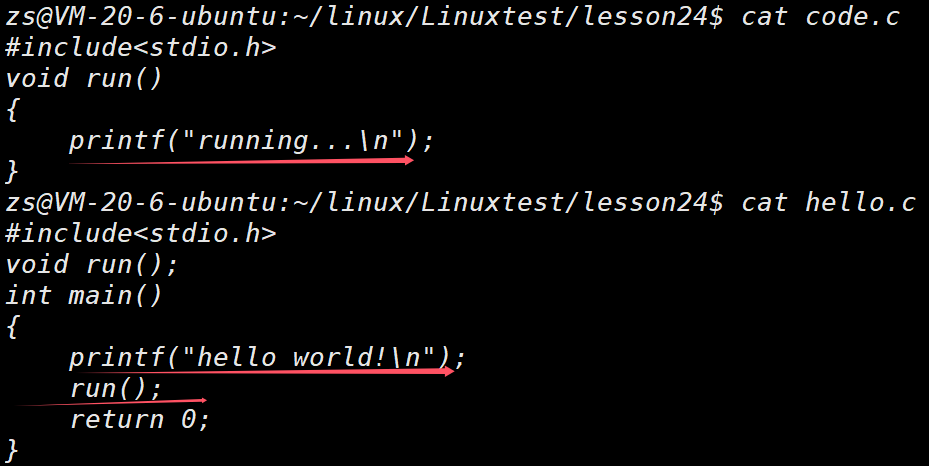
⽐如:在⼀个源⽂件 hello.c ⾥便简单输出"hello world!",并且调⽤⼀个run函数,⽽这个函数被定义在另⼀个原⽂件 code.c 中。这⾥我们就可以调⽤ gcc -c 来分别编译这两个原⽂件。
// hello.cinclude <stdio.h>
void run ();
int main () {
printf ( "hello world!\n" );
run();
return 0 ;
}
// code.cinclude <stdio.h>
void run () {
printf ( "running...\n" );
}
// 编译两个源⽂件
gcc -c hello.c gcc -c code.c
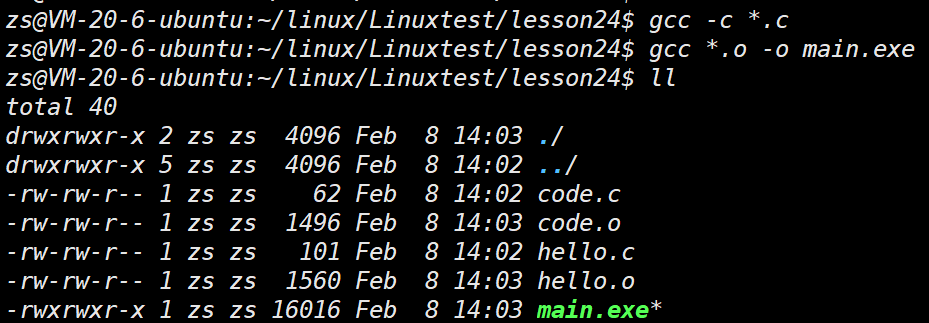
ls code.c code.o hello.c hello.o 可以看到,在编译之后会 ⽣成两个扩展名为 .o 的⽂件 ,它们 被称作⽬标⽂件 。要注意的是 如果我们修改了⼀个原⽂件,那么只需要单独编译它这⼀个,⽽不需要浪费时间重新编译整个⼯程 。⽬标⽂件是⼀个⼆进制的⽂件,⽂件的格式是 ELF ,是对⼆进制代码的⼀种封装。 file hello.o
hello.o: ELF 64-bit LSB relocatable, x86-64, version 1 (SYSV), not stripped
## file 命令⽤于辨识⽂件类型。
6.ELF文件
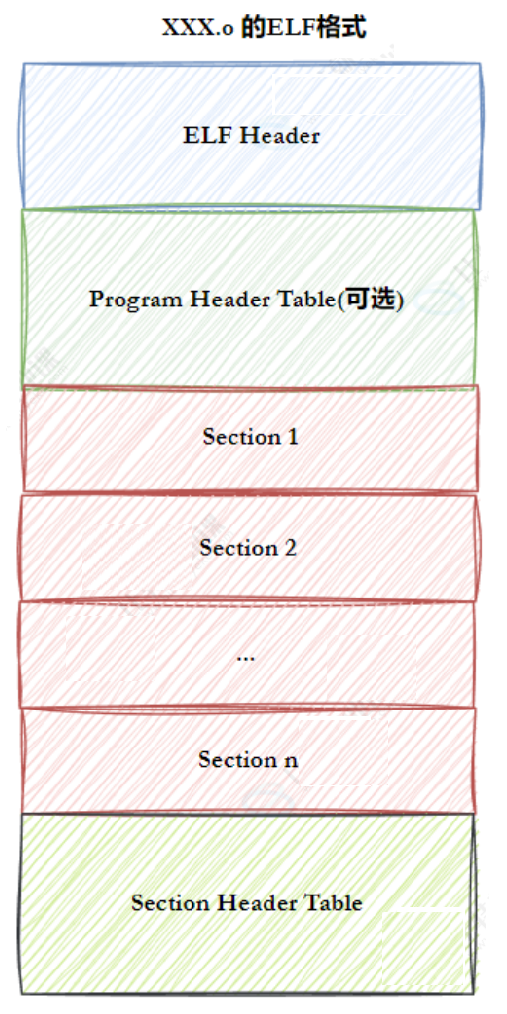
要理解编译链链接的细节,我们不得不了解⼀下ELF⽂件。其实有以下四种⽂件其实都是ELF⽂件:
-可重定位⽂件(Relocatable File ) :即 xxx.o ⽂件。包含适合于与其他⽬标⽂件链接来创建可执⾏⽂件或者共享⽬标⽂件的代码和数据。
-可执⾏⽂件(Executable File ) :即可执⾏程序。
-共享⽬标⽂件(Shared Object File ) :即 xxx.so⽂件。
-内核转储(core dumps) ,存放当前进程的执⾏上下⽂,⽤于dump信号触发。
⼀个ELF⽂件由以下四部分组成:
-ELF头 (ELF header) :描述⽂件的主要特性。其位于⽂件的开始位置,它的主要⽬的是定位⽂件的其他部分。
-程序头表(Program header table) :列举了所有有效的段(segments)和他们的属性。表⾥记着每个段的开始的位置和位移(offset)、⻓度,毕竟这些段,都是紧密的放在⼆进制⽂件中,需要段表的描述信息,才能把他们每个段分割开。
-节头表(Section header table) :包含对节(sections)的描述。
-节(Section ):ELF⽂件中的基本组成单位,包含了特定类型的数据。ELF⽂件的各种信息和数据都存储在不同的节中,如代码节存储了可执⾏代码,数据节存储了全局变量和静态数据等。
最常⻅的节:
-代码节(.text):⽤于保存机器指令,是程序的主要执⾏部分。
-数据节(.data):保存已初始化的全局变量和局部静态变量。
size:它用来展示二进制可执行文件(这里是名为code的程序)在内存中各段的大小信息。

7.ELF从形成到加载轮廓
- 编译 / 汇编阶段:生成带 section 的基础文件(.o + 静态库 / 动态库)
- 处理对象:C/C++ 源代码(.c/.cpp)
- 执行工具:编译器(gcc)+ 汇编器(as)
- 核心操作 :
- 编译器把源码编译为汇编代码,汇编器再转为机器指令;
- 按功能划分出
.text/.data/.bss等section(节)(仅 section,无 segment);- 产出物 :
- 单个
.o可重定位目标文件(只有 section + 节头表,无 segment、无程序头表);- 若制作库文件:
- 静态库(.a):本质是多个
.o文件的归档包(仍只有 section);- 动态库(.so):需额外经过链接步骤,因此包含 section + segment(后续链接可执行文件时,链接器仅读取其依赖信息,不重新生成它的 segment)。
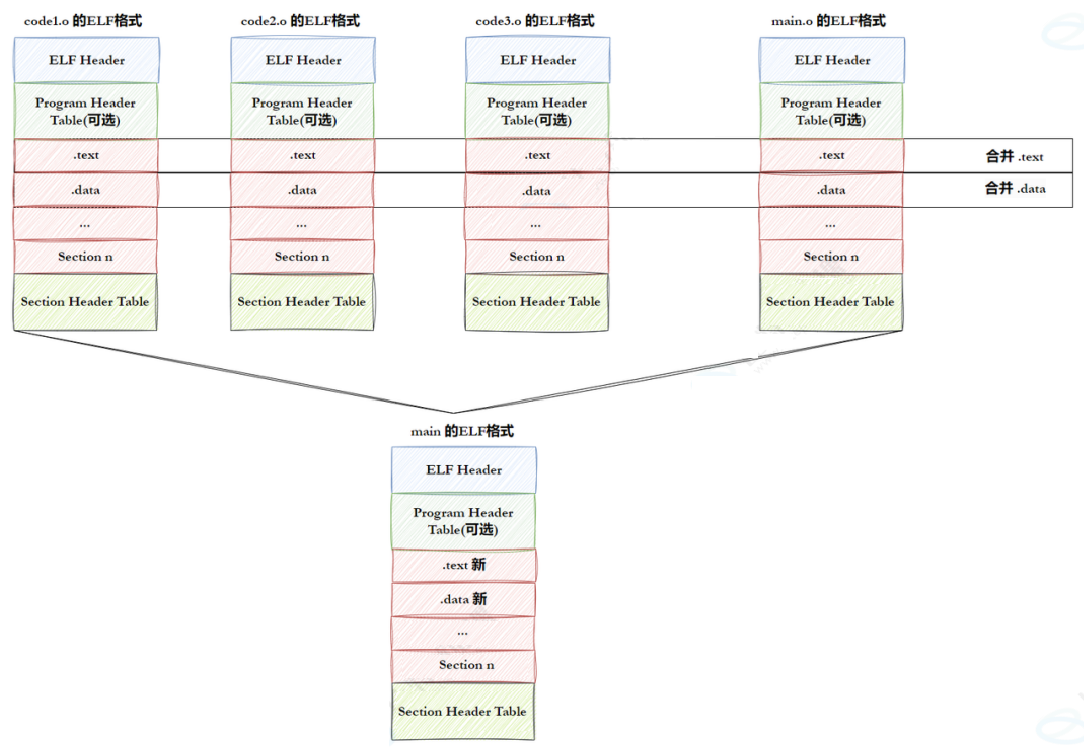
- 链接阶段:合并 section → 生成 segment → 产出可执行文件
- 处理对象 :多个
.o文件 + 静态库(.a)/ 动态库(.so)依赖- 执行工具:链接器(ld,gcc 会调用 ld)
- 核心操作 :① 符号解析:解决不同文件间的函数 / 变量引用(比如
.o里调用的printf,找到对应库的符号);② 地址重定位:为所有 section 分配统一的虚拟地址;③ 合并 section:将内存属性相同的 section(如.text+.init)合并为整体;④ 生成 segment:把合并后的 section 封装成segment,标记权限(R/X/RW)、虚拟地址等属性;⑤ 写入程序头表:将所有 segment 的信息记录到程序头表,并关联到 ELF 头部;- 产出物:ELF 可执行文件(同时包含 section + segment,section 供调试,segment 供加载)。
- 加载阶段:映射 segment 到内存(无新 segment 生成)
- 处理对象:ELF 可执行文件 + 依赖的动态库(.so)
- 执行工具:加载器(ld-linux.so)+ 内核
- 核心操作:读取可执行文件的程序头表,直接将已存在的 segment 映射到进程虚拟内存,设置内存权限,完成动态链接绑定;
- 产出物:运行中的进程(segment 从磁盘文件映射到内存,无创建 / 修改)。
总结
- segment 的 "诞生" 唯一时机是链接阶段,由链接器基于合并后的 section 创建,并非加载阶段;
.o和静态库(.a)只有 section,动态库(.so)因需被加载,生成时已包含 segment;- 链接器是 segment 的 "创建者",加载器只是 segment 的 "使用者"(仅内存映射)。
7.1ELF形成可执行
本质:这是一个静态的、文件层面的构建过程 ,由链接器(ld)完成。目标是把多个 .o 目标文件、库文件打包成一个完整的、可被加载器识别的 ELF 可执行文件
step-1: 编译 :将多份 C/C++ 源代码,翻译成为⽬标 .o ⽂件 + 动静态库(ELF)
step-2: 链接 :将多份 .o ⽂件section进⾏合并形成segment (实际合并是链接时的)
7.2ELF可执行文件加载
本质:这是一个动态的、内存层面的映射过程 ,由加载器(ld-linux.so)完成。目标是把可执行文件的内容从磁盘映射到进程的虚拟内存中,并准备好运行环境。核心是建立虚拟地址到物理地址的映射,以及完成动态链接的最终绑定。
-⼀个ELF会有多种不同的Section,在加载到内存的时候,也会进⾏Section合并,形成segment
-合并原则:相同属性,⽐如:可读,可写,可执⾏,需要加载时申请空间等.
-这样,即便是不同的Section,在加载到内存中,可能会以segment的形式,加载到⼀起
-很显然,这个合并⼯作也已经在 形成 可执行程序(ELF) 的时候, 合并⽅式已经确定了 ,具体合并原则 被记录在了 ELF 的 程序头表 (Program header table) 中
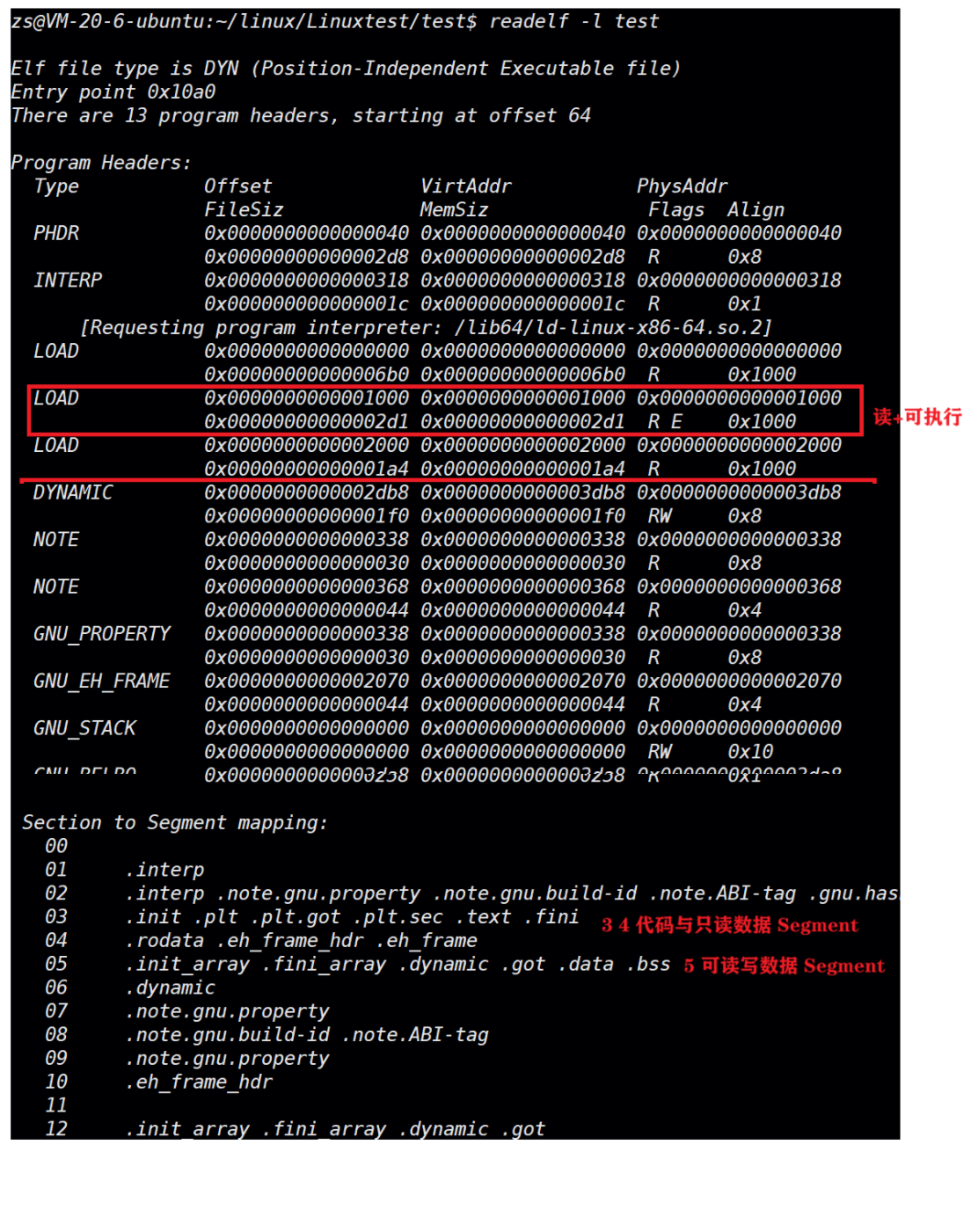
查看可执行程序的section:
查看section合并的segment:也就是查看程序头表 Program header table
📌 为什么要将section合并成为segment
Section合并的主要原因是为了减少⻚⾯碎⽚,提⾼内存使⽤效率。如果不进⾏合并,
假设⻚⾯⼤⼩为4096字节(内存块基本⼤⼩,加载,管理的基本单位),如果.text部分
为4097字节,.init部分为512字节,那么它们将占⽤3个⻚⾯,⽽合并后,它们只需2个
⻚⾯。
此外,操作系统在加载程序时,会将具有相同属性的section合并成⼀个⼤的
segment,这样就可以实现不同的访问权限,从⽽优化内存管理和权限访问控制。
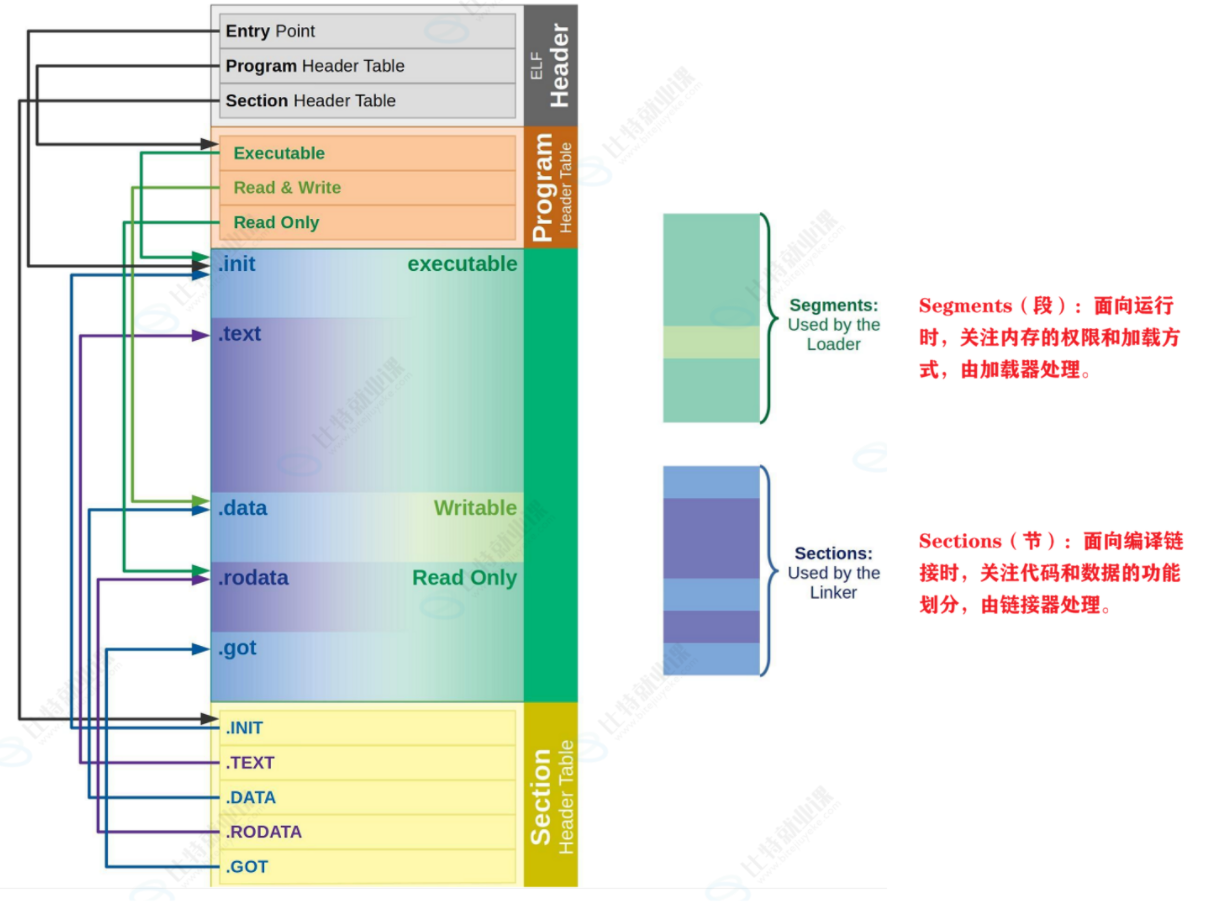
对于 程序头表 和 节头表 ⼜有什么⽤呢,其实 ELF ⽂件提供 2 个不同的视图/视⻆来让我们理解这两个部分:
- 节头表 → 编译链接时用 → 关注逻辑上的 section
- 程序头表 → 运行加载时用 → 关注内存中的 segment
- 链接视图 (Linking view) - 对应 节头表 Section header table
-⽂件结构的粒度更细,将⽂件按功能模块的差异进⾏划分,静态链接分析的时候⼀般关注的是链接视图,能够理解 ELF ⽂件中包含的各个部分的信息。
-为了空间布局上的效率,将来在链接⽬标⽂件时,链接器会把很多节(section)合并,规整成可执⾏的段(segment)、可读写的段、只读段等。合并了后,空间利⽤率就⾼了,否则,很⼩的很⼩的⼀段,未来物理内存⻚浪费太⼤(物理内存⻚分配⼀般都是整数倍⼀块给你,⽐如4k),所以,链接器趁着链接就把⼩块们都合并了。- 执⾏视图 (execution view) - 对应 程序头表 Program header table◦
-告诉操作系统,如何加载可执⾏⽂件,完成进程内存的初始化。⼀个可执⾏程序的格式中,⼀定有 program header table 。
-说⽩了就是:⼀个在链接时作⽤,⼀个在运⾏加载时作⽤
下面我们来看ELF(Executable and Linkable Format)文件结构示意图,它清晰展示了 ELF 文件在编译、链接和运行时的组织方式,以及 "段(Segment)" 和 "节(Section)" 的对应关系:
从 链接视图 来看:
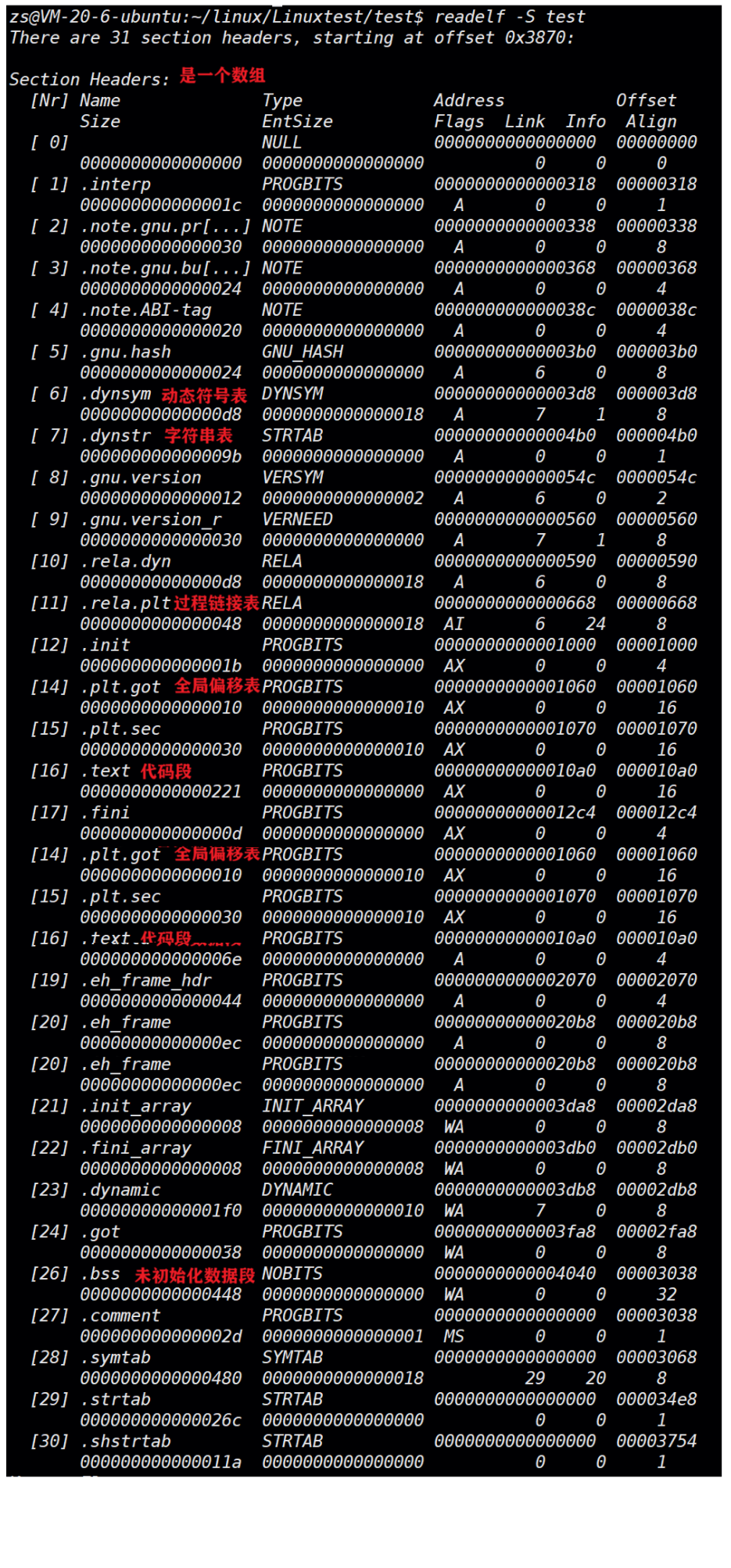
命令 readelf -S hello.o 可以帮助查看ELF⽂件的 节头表。
.text节 :是保存了程序代码指令的代码节。
.data节 :保存了初始化的全局变量和局部静态变量等数据。
.rodata节 :保存了只读的数据,如⼀⾏C语⾔代码中的字符串。由于.rodata节是只读的,所以只能存在于⼀个可执⾏⽂件的只读段中。因此,只能是在text段(不是data段)中找到.rodata节。
.BSS节 :为未初始化的全局变量和局部静态变量预留位置
.symtab节 : Symbol Table 符号表,就是源码⾥⾯那些函数名、变量名和代码的对应关系。
.got.plt节 (全局偏移表-过程链接表):.got节保存了全局偏移表。.got节和.plt节⼀起提供了对导⼊的共享库函数的访问⼊⼝,由动态链接器在运⾏时进⾏修改。对于GOT的理解,我们后⾯会说。
使⽤ readelf 命令查看 .so ⽂件可以看到该节。
从 执⾏视图 来看:
告诉操作系统哪些模块可以被加载进内存。
加载进内存之后哪些分段是可读可写,哪些分段是只读,哪些分段是可执⾏的
我们可以在 ELF 头 中找到⽂件的基本信息,以及可以看到ELF头是如何定位程序头表和节头表的。例如我们查看下hello.o这个可重定位⽂件的主要信息:
// 查看⽬标⽂件-ELF HEADER
readelf -h hello.o ELF Header: Magic: 7f 45 4 c 46 02 01 01 00 00 00 00 00 00 00 00 00 # ELF ⽂件标识符(魔 数) Class: ELF64 # ⽂件类: 64 位架构 Data: 2' s complement, little endian # 数据编码:⼩端序⼆进制补码 Version: 1 (current) # ELF 版本:当前版本 ( 1 ) OS/ABI: UNIX - System V # 操作系统 ABI : System V UNIX ABI Version: 0 # ABI 扩展版本:未扩展( 0 ) Type: REL (Relocatable file) # ⽂件类型:可重定位⽂件(⽬标⽂件) Machine: Advanced Micro Devices X86 -64 # ⽬标平台: x86 -64 架构 Version: 0x1 # 对象⽂件版本: 1 Entry point address: 0x0 # ⼊⼝点地址:⽆ (⽬标⽂件为 0 ) Start of program headers: 0 (bytes into file) # 程序头表起始偏移:⽆(⽬标⽂件为 0 ) Start of section headers: 728 (bytes into file) # 节头表起始偏移: 728 字节处 Flags: 0x0 # 处理器特定标志:⽆标志( 0 ) Size of this header: 64 (bytes) # ELF 头⼤⼩: 64 字 节 Size of program headers: 0 (bytes) # 程序头表条⽬⼤⼩:⽆(⽬标⽂件为 0 ) Number of program headers: 0 # 程序头表条⽬数:⽆(⽬标⽂件为 0 ) Size of section headers: 64 (bytes) # 节头表条⽬⼤⼩: 64 字节 Number of section headers: 13 # 节头表条⽬数: 13 个节 Section header string table index: 12 # 节名称字符串表索引:第 12 节 (.shstrtab) #查看可执行程序-ELF HEADER gcc *.o
$ readelf -h a.out
Magic: 7f 45 4 c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64 # 64 位架构
Data: 2' s complement, little endian # ⼩端序⼆进制补码
Version: 1 (current) # ELF 版本: 1 (当前标准)
OS/ABI: UNIX - System V # 操作系统 ABI :
System V UNIX
ABI Version: 0 # ⽆扩展 ABI
Type: DYN (Shared object file) # ⽂件类型:动态共享库(.so )
Machine: Advanced Micro Devices X86 -64 # ⽬标平台: x86 -64
Version: 0x1 # 对象⽂件版本: 1
Entry point: 0x1060 # 程序⼊⼝点虚拟地址(动态链接后解析)
Start of program headers: 64 (bytes into file) # 程序头表起始偏移: 64 字节
Start of section headers: 14768 (bytes into file) # 节头表起始偏移: 14768 字节
Flags: 0x0 # ⽆处理器特定标志
Size of this header: 64 (bytes) # ELF 头⼤⼩: 64 字节
Size of program headers: 56 (bytes) # 程序头表每个条⽬⼤⼩: 56 字节
Number of program headers: 13 # 程序头表条⽬数: 13 (如LOAD 、 DYNAMIC 等段)
Size of section headers: 64 (bytes) # 节头表每个条⽬⼤⼩: 64 字节
Number of section headers: 31 # 节头表条⽬数: 31 个节(如.text 、 .data 等)
Section header string table index: 30 # 节名称字符串表索引:第 30 节( .shstrtab )
总结:链接时参考节头表(Section Header Table) ,节头表定义了所有 section(节)的属性;链接器将属性相同的 section 合并成 segment(段),并把这些 segment 的加载规则(地址、权限、大小等)写入程序头表(Program Header Table) );最终加载器(操作系统)在运行程序时,只需读取程序头表,就能按规则把 segment 映射到内存。
8.理解连接与加载
8.1静态链接
⽆论是⾃⼰的 .o , 还是静态库中的 .o ,本质都是把.o⽂件进⾏连接的过程
所以:研究静态链接,本质就是研究 .o 是如何链接的
查看编译后的.o⽬标⽂件
objdump -d 命令:将代码段(.text)进⾏反汇编查看。
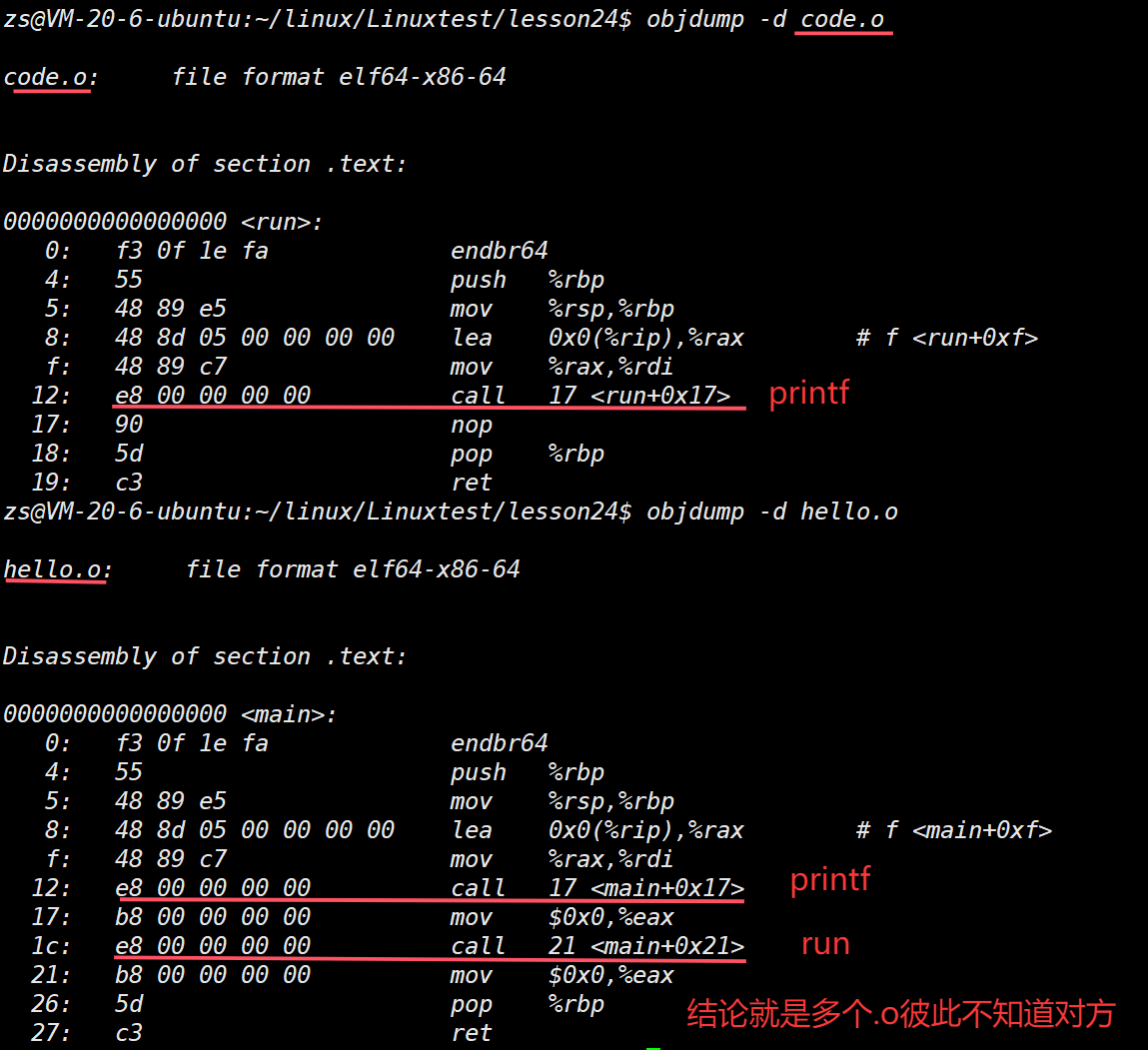
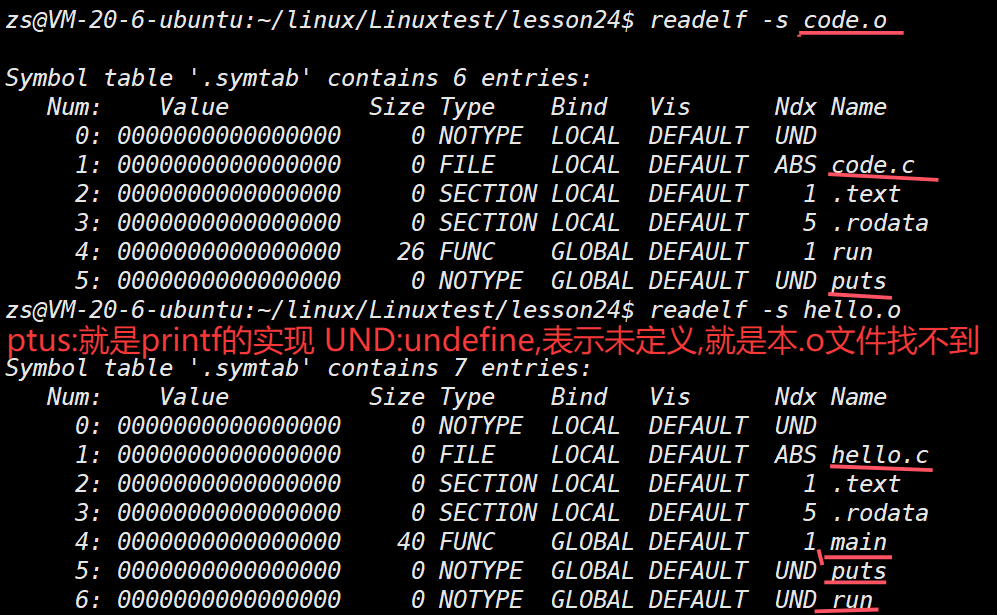
hello.o 中的 main 函数不认识 printf 和 run 函数
code.o 不认识 printf 函数
我们可以看到这⾥的call指令,它们分别对应之前调⽤的printf和run函数,但是你会发现他们的跳转地址都被设成了0。那这是为什么呢?
其实就是在编译 hello.c 的时候,编译器是完全不知道 printf 和 run 函数的存在的 ,⽐如他们
位于内存的哪个区块,代码⻓什么样都是不知道的。因此,编译器只能将这两个函数的跳转地址先暂时设为0。
这个地址会在哪个时候被修正? 链接的时候! 为了让链接器将来在链接时能够正确定位到这些被修正的地址,在代码块(.data)中还存在⼀个 重定位表 ,这张表将来在链接的时候,就会根据表⾥记录的地址将其修正。
下面演示整个过程:
第一步:查看code.o和hello.o的代码段----只编译未链接
第二步:读取code.o和hello.o符号表----只编译未链接
第三步:读取链接后的可执行程序的符号表---只截取部分重要地方
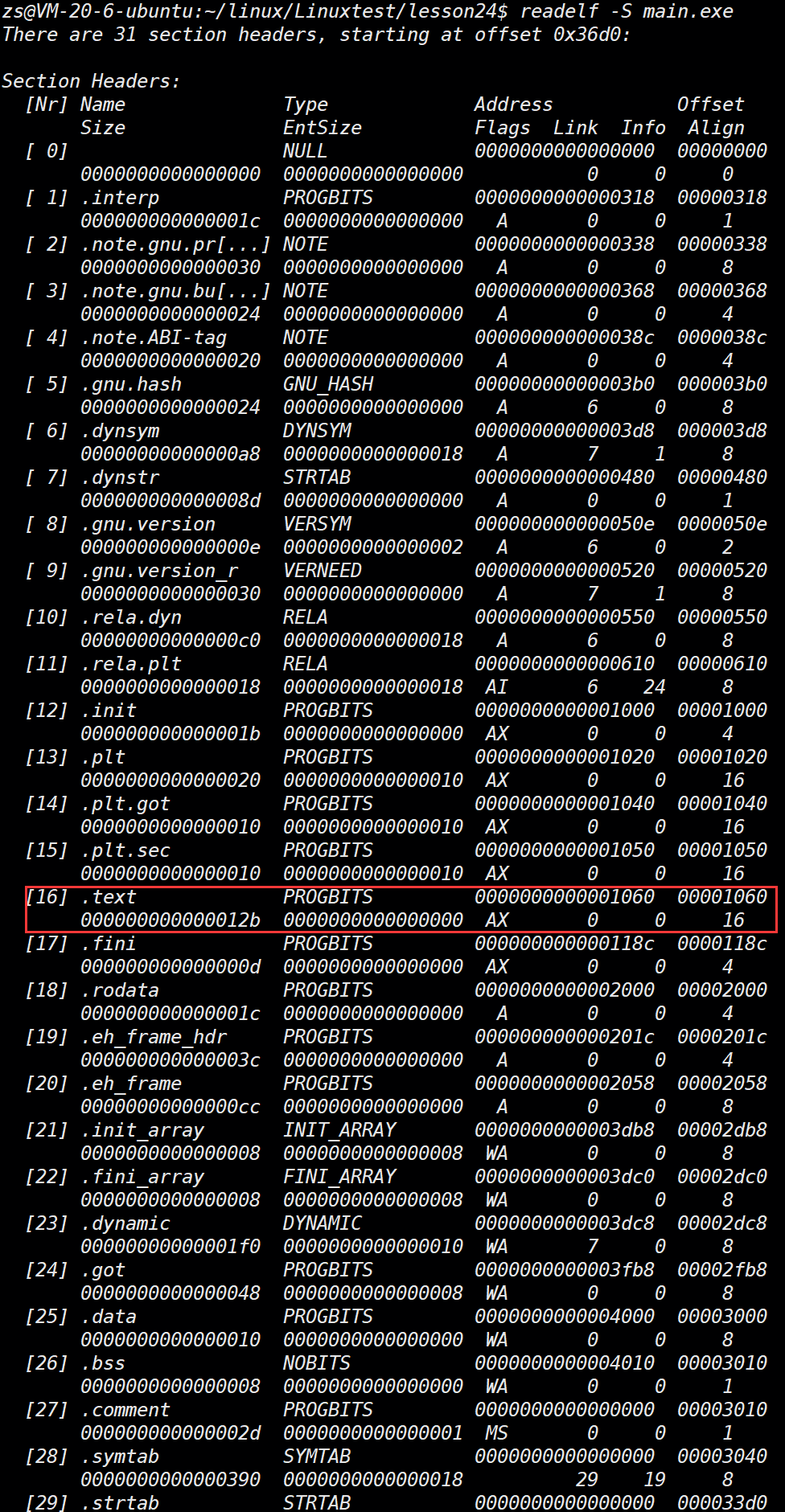
readelf -S main.exe
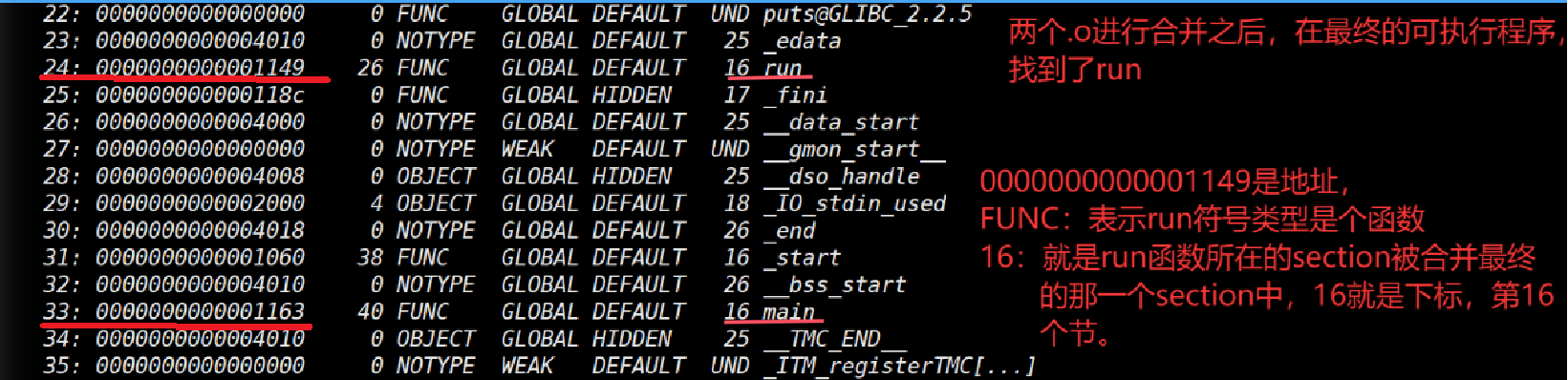
验证16: 读取可执行程序最终的所有的section清单
# hello.o 和 code.o 的 .text 被合并了,是 main.exe 的第 16 个 section
# 怎么证明上⾯的说法?
# 关于 hello.o 或者 code.o call 后⾯的 00 00 00 00 有没有被修改成为具体的最终函数地址呢?
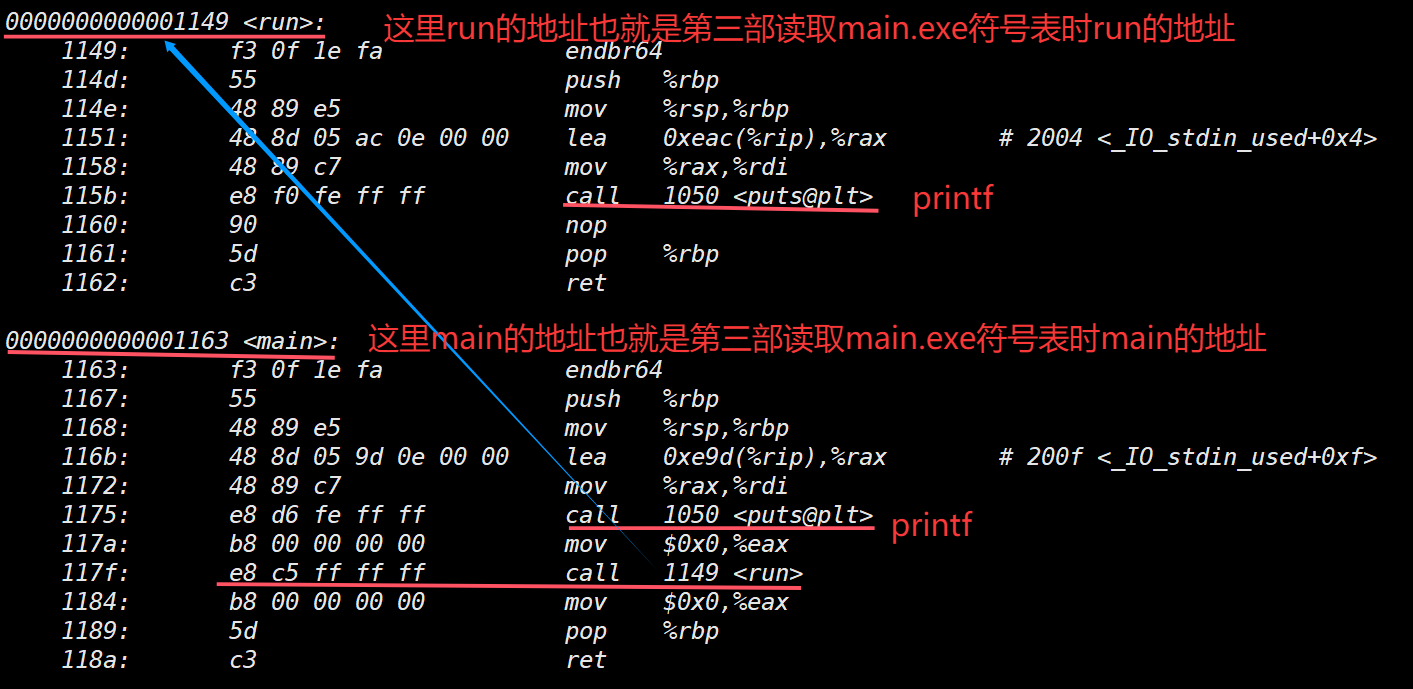
查看main.exe的代码段:objdump -d main.exe
最终:
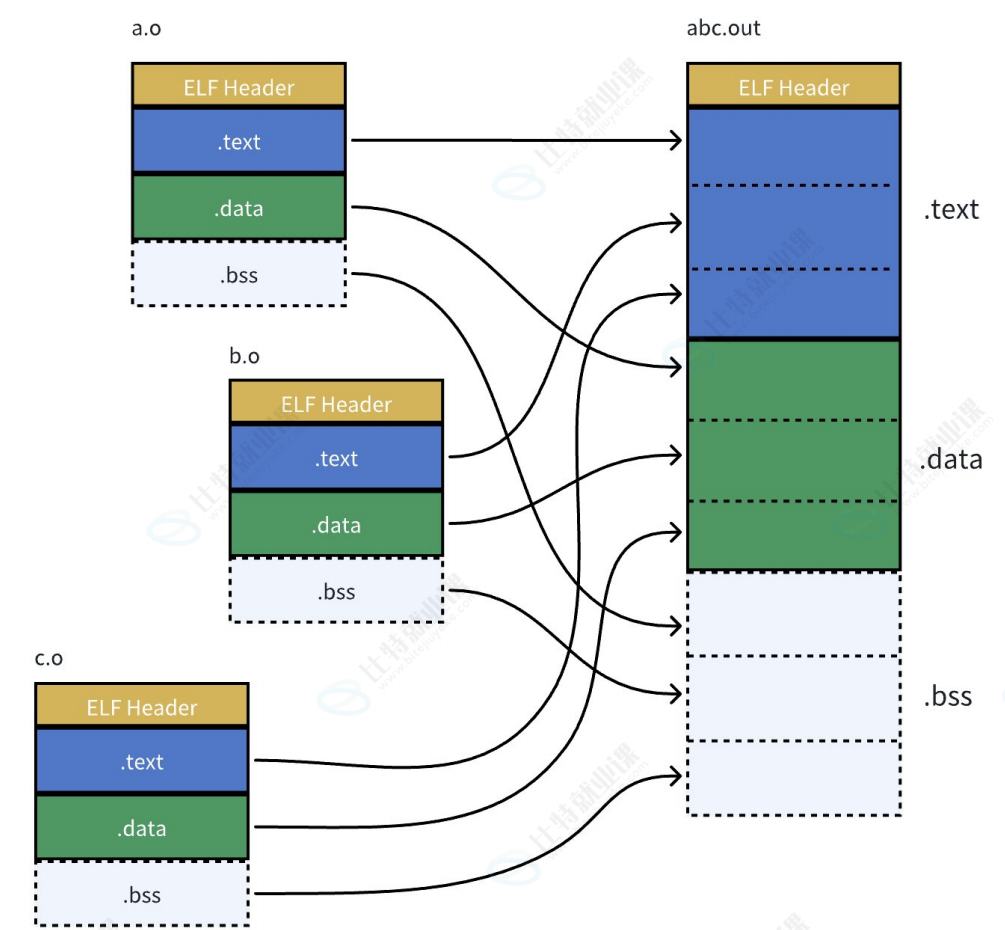
- 两个 .o 的代码段合并到了⼀起,并进⾏了统⼀的编址
- 链接的时候,会修改 .o 中没有确定的函数地址,在合并完成之后,进⾏相关 call 地址,完成代码调⽤
静态链接就是把库中的.o进⾏合并,和上述过程⼀样所以链接其实就是将编译之后的所有⽬标⽂件连同⽤到的⼀些静态库运⾏时库组合,拼装成⼀个独⽴的可执⾏⽂件。其中就包括我们之前提到的地址修正,当所有模块组合在⼀起之后,链接器会根据我们的.o⽂件或者静态库中的 重定位表 找到那些需要 被重定位的函数全局变量 ,从⽽修正它们的地址。 这其实就是静态链接的过程.
所以,链接过程中会涉及到对.o中外部符号进⾏地址重定位。
8.2ELF加载与进程地址空间
8.2.1虚拟地址/逻辑地址
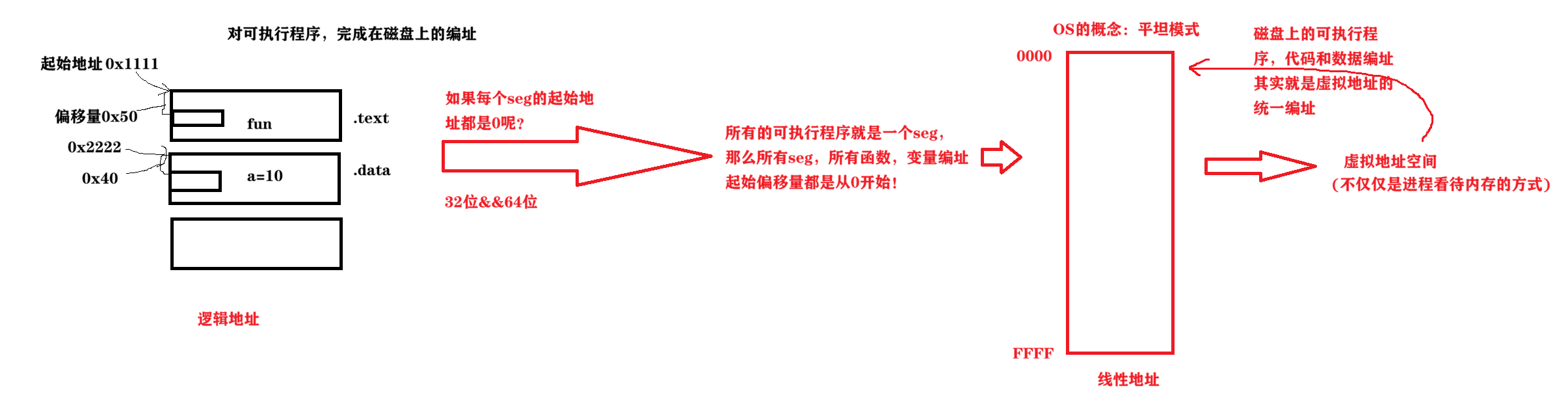
一个可执行程序没有被加载到内存中,该可执行程序也有地址!!!
编译 vs 链接的地址处理分工
阶段 主体 处理的地址类型 核心行为 编译(Compile) 编译器(gcc -c) 逻辑地址 对单个源文件(如 main.c)编译,生成目标文件(.o),为每个段(.text/.data)生成相对逻辑地址(段内偏移) 链接(Link) 链接器(ld) 虚拟地址 合并所有.o 文件的段,将逻辑地址转换为全局虚拟地址,写入 ELF 可执行文件
- 逻辑地址(图中左侧)
- 定义 :这是编译 / 链接阶段生成的地址,由 "段基地址 + 段内偏移量" 组成。
- 编译阶段 :编译器处理单个源文件(如
main.c)时,会生成目标文件(.o)。此时,它为每个段(.text/.data)内的指令和变量生成节内偏移量,这是逻辑地址的一部分。- 链接阶段 :链接器合并多个目标文件的段时,会为每个段分配一个全局的 "段基地址"。最终的逻辑地址是由 "段基地址 + 段(节)内偏移量 " 组成的,所以完整的逻辑地址其实是在链接阶段才最终确定的。
- 特点 :
- 它是程序在磁盘上的编址方式,只和可执行文件的段结构相关。
- 例如图中
.text段基址是0x1111,fun函数的偏移是0x50,它的逻辑地址就是0x1111 + 0x50。- 每个段(
.text、.data等)都有独立的基地址,不同段的偏移量是各自独立计数的。- 本质:逻辑地址是分段模型下的产物,是程序 "编译时" 的地址。
最右侧的Offset就是逻辑偏移量
- 虚拟地址(图中右侧)
- 定义:这是现代 32 位 / 64 位操作系统中,程序运行时看到的地址,是 "平坦模型" 下的全局偏移量。
- 特点 :
- 它是整个程序统一编址的地址,所有段的基地址都被设为
0,因此虚拟地址 = 全局偏移量。- 例如图中提到 "所有函数、变量的起始偏移量都从 0 开始",这个全局偏移量就是虚拟地址。
- 它不仅是进程看待内存的方式,也是磁盘上可执行文件的编址方式(编译时已确定)。
- 本质:虚拟地址是平坦模型下的产物,是程序 "运行时" 的地址,由 MMU(内存管理单元)映射到物理地址。
这里的地址就是虚拟地址,已链接后的
编译 vs 链接的地址处理分工
阶段 主体 处理的地址类型 核心行为 编译(Compile) 编译器(gcc -c) 逻辑地址 对单个源文件(如 main.c)编译,生成目标文件(.o),为每个段(.text/.data)生成相对逻辑地址(段内偏移) 链接(Link) 链接器(ld) 虚拟地址 合并所有.o 文件的段,将逻辑地址转换为全局虚拟地址,写入 ELF 可执行文件 完整过程:从逻辑地址到虚拟地址的生成步骤
- 编译阶段:生成 "分段的逻辑地址"(每个.o 文件独立)
当你执行
gcc -c main.c -o main.o时,编译器做的事:
- 把 main.c 的代码、数据拆分为
.text(代码)、.data(已初始化数据)、.bss(未初始化数据)等段;- 为每个段内的符号(函数 / 变量)分配节内偏移量(这就是最原始的逻辑地址);
- 此时的逻辑地址是 "相对的":比如 main.o 中
.text段的fun函数偏移是0x50,.data段的a变量偏移是0x40,但每个.o 文件的段基址都默认从0开始(还没合并)。⚠️ 注意:此时的逻辑地址是 "局部的"(仅对当前.o 文件有效),还不是最终的虚拟地址。
- 链接阶段:将逻辑地址转换为 "全局虚拟地址"
当你执行
gcc main.o test.o -o main时,链接器做的核心事:
- 合并节 :把所有.o 文件的
.text节合并成一个大的.text段,.data段同理;- 分配虚拟地址空间 :
- 链接器会遵循 ELF 规范(如 Linux x86_64 的代码段默认从
0x400000开始),为合并后的每个段分配全局基地址(现代系统中这个基地址就是虚拟地址的起始);- 例如:合并后的
.text段基地址设为0x400000,原来 main.o 中fun函数的段内偏移0x50,就会被转换为虚拟地址0x400050;- 修正地址引用 :把代码中所有对符号的引用(如调用
fun函数),从 "段内逻辑偏移" 修正为 "全局虚拟地址";- 写入 ELF 文件 :将最终的虚拟地址写入 ELF 可执行文件的程序头表(Program Header Table) (对应 Segment 的
p_vaddr)和符号表,这就是你之前看到的 "编译好的可执行文件里已经是虚拟地址"。
关键补充:为什么链接器能直接生成虚拟地址?
链接器不是 "凭空" 造虚拟地址,而是遵循操作系统的ELF 链接脚本(Linker Script):
- 链接脚本定义了各个段的虚拟地址起始位置(如
SECTIONS { .text 0x400000 : { *(.text) } });- 链接器根据这个脚本,把编译器生成的 "段内逻辑偏移" 叠加到 "全局基地址" 上,最终得到虚拟地址;
- 这个虚拟地址会直接作为 ELF Segment 的
p_vaddr,后续内核加载时,就用这个p_vaddr初始化vm_area_struct的vm_start。
总结
逻辑地址是链接器在编译后给程序 "预分配" 的虚拟地址,它由段的虚拟基地址和节内偏移量拼接而成,程序运行时会直接使用这个地址作为虚拟地址。
- 逻辑地址是编译器为单个.o 文件生成的 "段内偏移",是局部的、分段的;
- 虚拟地址是链接器合并所有.o 文件的节后,基于 ELF 规范分配的 "全局地址",是平坦的;
- 整个过程是:编译器生成节内偏移量 → 链接器合并节 + 分配全局基地址 → 逻辑地址 = 所属段的虚拟基地址 + 节内偏移量 (此时的逻辑地址本质就是链接阶段预定的虚拟地址)-> 生成最终的虚拟地址,而非单一 "编译" 步骤直接生成虚拟地址。
8.2.2重新理解进程虚拟地址空间
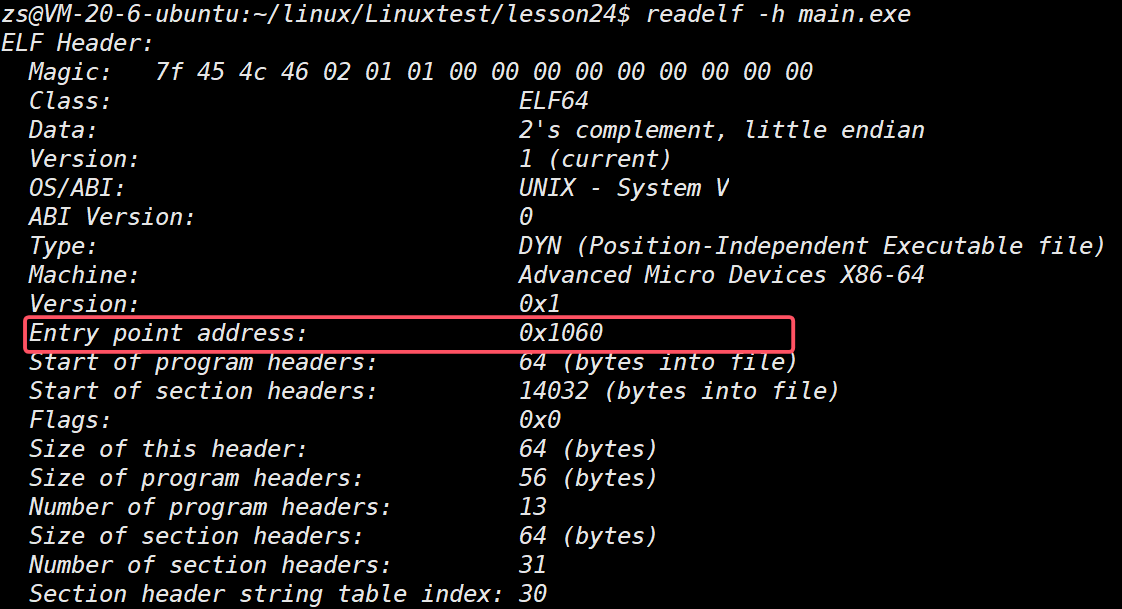
ELF 在被编译好之后,会把⾃⼰未来程序的⼊⼝地址记录在ELF header的Entry字段中:
虚拟入口地址也就是操作系统加载程序后,CPU 开始执行的第一条指令的虚拟地址。
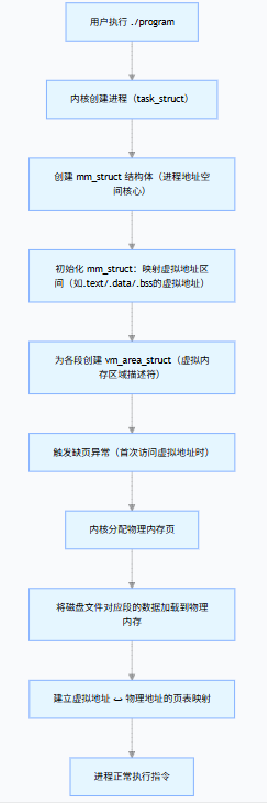
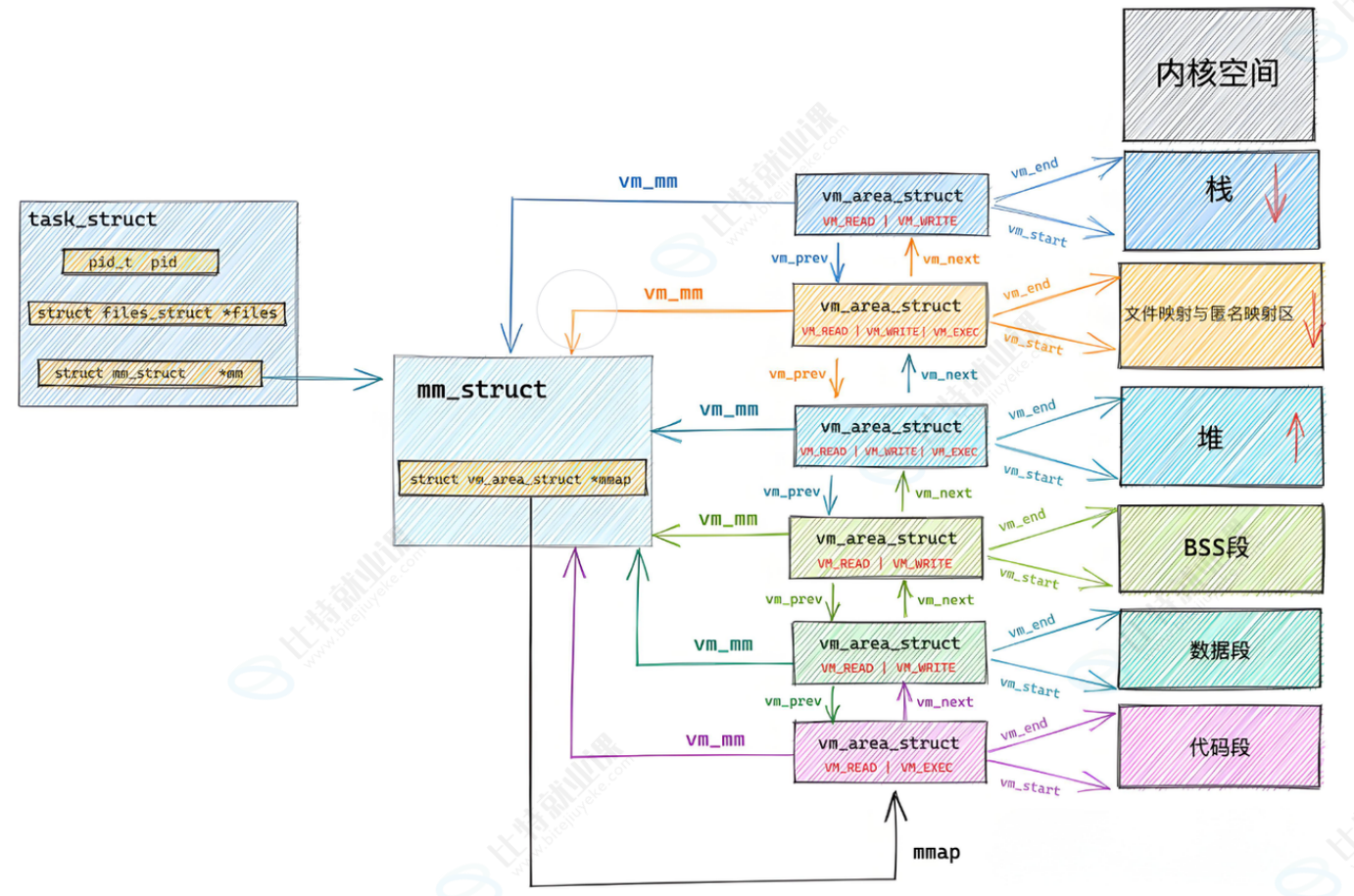
进程mm_struct、vm_area_struct在进程刚刚创建的时候,初始化数据从哪⾥来的?从ELF各个segment来,每个segment有⾃⼰的起始地址和⾃⼰的⻓度,⽤来初始化内核结构中的start, end等范围数据,另外在⽤详细地址,填充⻚表,⼀张图说清楚:
这里的BSS用来接收ELF的描述信息
- BSS 段的核心特征:ELF 中只存「描述信息」(地址、大小、权限),无实际数据。
- 初始化逻辑:加载器根据这些描述信息,在进程虚拟地址空间分配内存并清零。

8.3动态链接与动态库加载
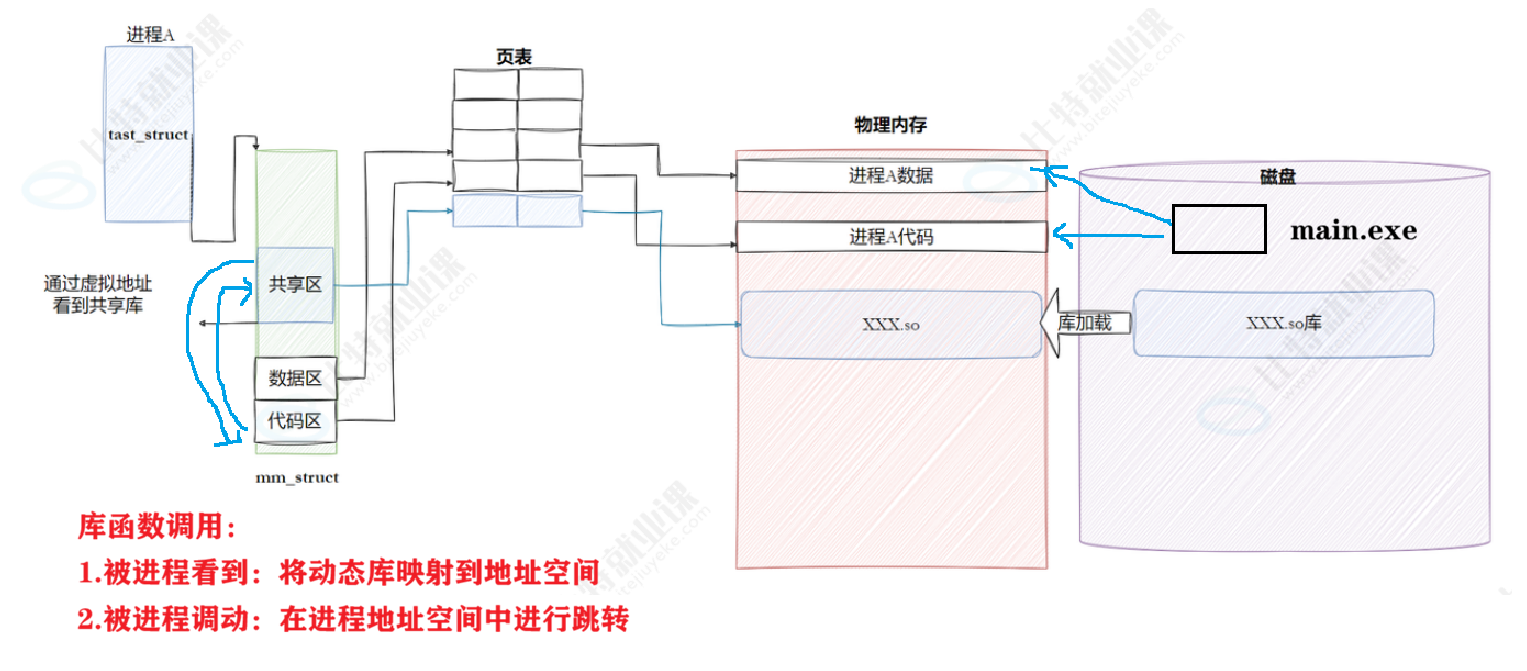
8.3.1进程如何看到动态库
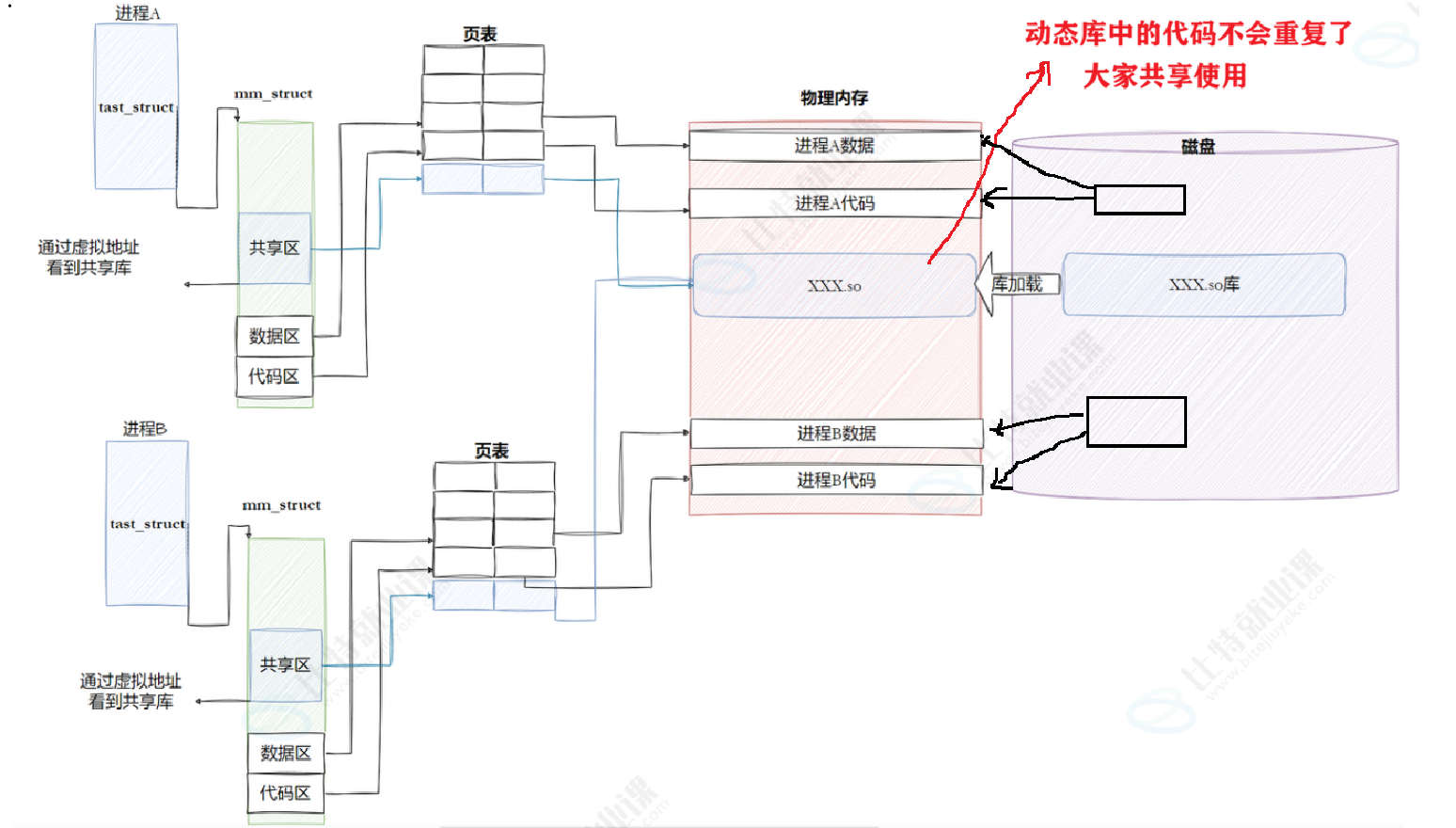
8.3.2进程间如何共享库
8.3.3动态链接
8.3.3.1概要
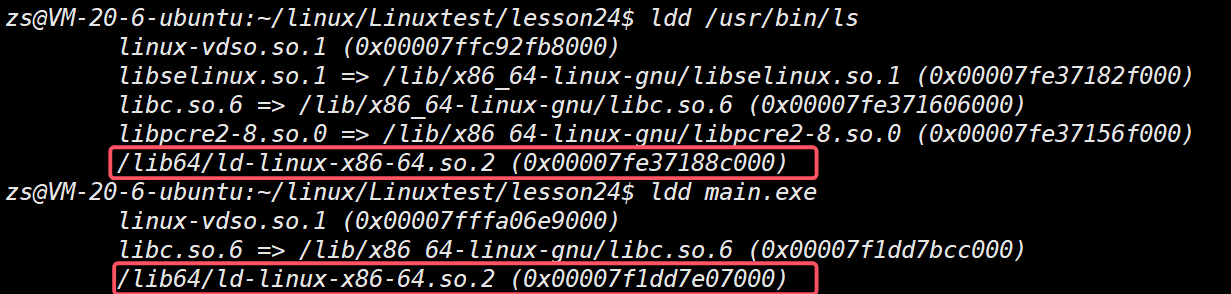
动态链接其实远⽐静态链接要常⽤得多。⽐如我们查看下 hello 这个可执⾏程序依赖的动态库,会发现它就⽤到了⼀个c动态链接库:
这⾥的 libc.so 是C语⾔的运⾏时库,⾥⾯提供了常⽤的标准输⼊输出⽂件字符串处理等等这些功能。
那为什么编译器默认不使⽤静态链接呢?静态链接会将编译产⽣的所有⽬标⽂件,连同⽤到的各种库,合并形成⼀个独⽴的可执⾏⽂件,它不需要额外的依赖就可以运⾏。照理来说应该更加⽅便才对是吧?
静态链接最⼤的问题在于⽣成的⽂件体积⼤,并且相当耗费内存资源。随着软件复杂度的提升,我们的操作系统也越来越臃肿,不同的软件就有可能都包含了相同的功能和代码,显然会浪费⼤量的硬盘空间。这个时候, 动态链接的优势就体现出来了,我们可以将需要共享的代码单独提取出来,保存成⼀个独⽴的动态链接库,等到程序运⾏的时候再将它们加载到内存,这样不但可以节省空间,因为同⼀个模块在内存中只需要保留⼀份副本,可以被不同的进程所共享。
动态链接到底是如何⼯作的??
-⾸先要交代⼀个结论, 动态链接实际上将链接的整个过程推迟到了程序加载的时候 。⽐如我们去运⾏⼀个程序,操作系统会⾸先将程序的数据代码连同它⽤到的⼀系列动态库先加载到内存,其中每个动态库的加载地址都是不固定的,操作系统会根据当前地址空间的使⽤情况为它们动态分配⼀段内存。
-当动态库被加载到内存以后,⼀旦它的内存地址被确定,我们就可以去修正动态库中的那些函数跳转地址了。

8.3.3.2我们可执行程序被编译器动了手脚
在C/C++程序中,当程序开始执⾏时,它⾸先并不会直接跳转到 main 函数。实际上,程序的⼊⼝点是 _start ,这是⼀个由C运⾏时库(通常是glibc)或链接器(如ld)提供的特殊函数。
在 _start 函数中,会执⾏⼀系列初始化操作,这些操作包括:
- 设置堆栈:为程序创建⼀个初始的堆栈环境。
- 初始化数据段:将程序的数据段(如全局变量和静态变量)从初始化数据段复制到相应的内存位置,并清零未初始化的数据段。
- 动态链接:这是关键的⼀步, _start 函数会调⽤动态链接器的代码来解析和加载程序所依赖的动态库(shared libraries)。动态链接器会处理所有的符号解析和重定位,确保程序中的函数调⽤和变量访问能够正确地映射到动态库中的实际地址。
动态链接器:
-动态链接器(如ld-linux.so)负责在程序运⾏时加载动态库。
-当程序启动时,动态链接器会解析程序中的动态库依赖,并加载这些库到内存中。
环境变量和配置⽂件:
-Linux系统通过环境变量(如LD_LIBRARY_PATH)和配置⽂件(如/etc/ld.so.conf及其⼦配置⽂件)来指定动态库的搜索路径。
-这些路径会被动态链接器在加载动态库时搜索。
缓存⽂件:
为了提⾼动态库的加载效率,Linux系统会维护⼀个名为/etc/ld.so.cache的缓存⽂件。
该⽂件包含了系统中所有已知动态库的路径和相关信息,动态链接器在加载动态库时会⾸先搜索这个缓存⽂件。- 调⽤ __libc_start_main :⼀旦动态链接完成, _start 函数会调⽤
__libc_start_main (这是glibc提供的⼀个函数)。 __libc_start_main 函数负责执⾏
⼀些额外的初始化⼯作,⽐如设置信号处理函数、初始化线程库(如果使⽤了线程)等。- 调⽤ main 函数:最后, __libc_start_main 函数会 调⽤程序的 main 函数 ,此时程序的执
⾏控制权才正式交给⽤⼾编写的代码。- 处理 main 函数的返回值: 当 main 函数返回时 , __libc_start_main 会负责处 理这个返回
值,并最终调⽤ _exit 函数来终⽌程序 。
上述过程描述了C/C++程序在 main 函数之前执⾏的⼀系列操作,但这些操作对于⼤多数程序员来说是透明的。程序员通常只需要关注 main 函数中的代码,⽽不需要关⼼底层的初始化过程。然⽽,了解这些底层细节有助于更好地理解程序的执⾏流程和调试问题。
8.3.3.3动态库中的相对地址
动态库为了随时进⾏加载,为了⽀持并映射到任意进程的任意位置,对动态库中的⽅法,统⼀编址,采⽤相对编址的⽅案进⾏编制的(其实可执⾏程序也⼀样,都要遵守平坦模式,只不过exe是直接加载的)。 动态库也是ELF,我们也可以理解为起始地址(0)+偏移量
8.3.3.4我们的程序怎么和库映射起来
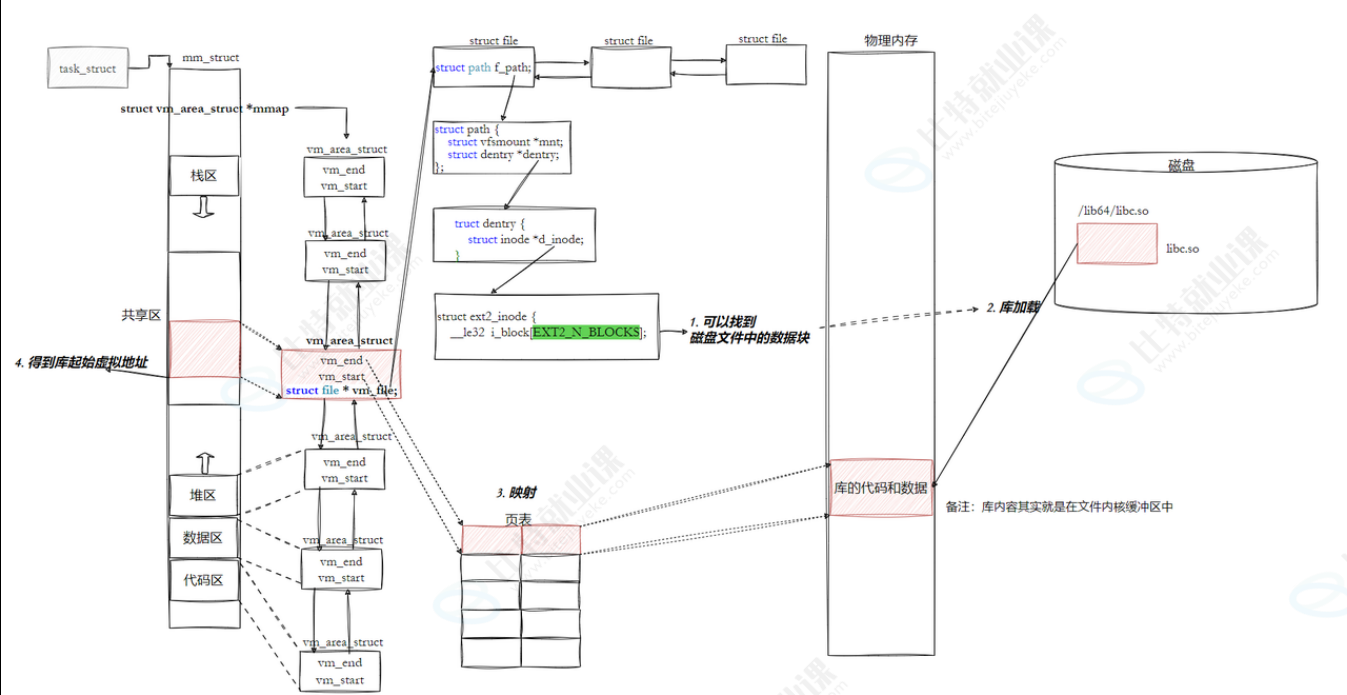
📌 注意:
动态库也是⼀个⽂件,要访问也是要被先加载,要加载也是要被打开的 让我们的进程找到动态库的本质:也是⽂件操作,不过我们访问库函数,通过虚拟地址进⾏跳转访问的,所以需要把动态库映射到进程的地址空间中
- 核心逻辑
动态库的映射并不是 "先一次性加载到物理内存,再映射到进程",而是:
- 先建立虚拟地址映射 :动态链接器先在进程的虚拟地址空间里,为动态库创建对应的
vm_area_struct虚拟内存区域,这一步只是在mm_struct中定义了虚拟地址范围,还没有分配物理内存。- 缺页异常触发加载:当进程首次调用动态库的函数时,会触发缺页异常,内核才会把磁盘上的动态库数据加载到物理内存(或文件内核缓冲区),然后再通过页表建立虚拟地址到物理地址的映射。
完整流程拆解
打开动态库文件 动态链接器先通过文件路径(如
/lib64/libc.so)找到磁盘上的动态库,打开文件并获取struct file和inode等文件描述信息。创建虚拟内存区域 在进程的虚拟地址空间中,为动态库分配一段虚拟地址范围,并创建对应的
vm_area_struct,挂到进程的mm_struct中。首次访问触发缺页 当进程调用库函数(如
puts)时,CPU 访问对应的虚拟地址,发现页表中没有映射,触发缺页异常。加载到物理内存并映射内核分配物理内存页,将动态库的对应数据从磁盘加载到物理内存(或复用文件内核缓冲区中的缓存),然后更新页表,完成虚拟地址到物理地址的映射。
后续访问直接使用之后再访问该库函数时,就可以通过页表直接找到物理内存中的代码,无需再次加载。
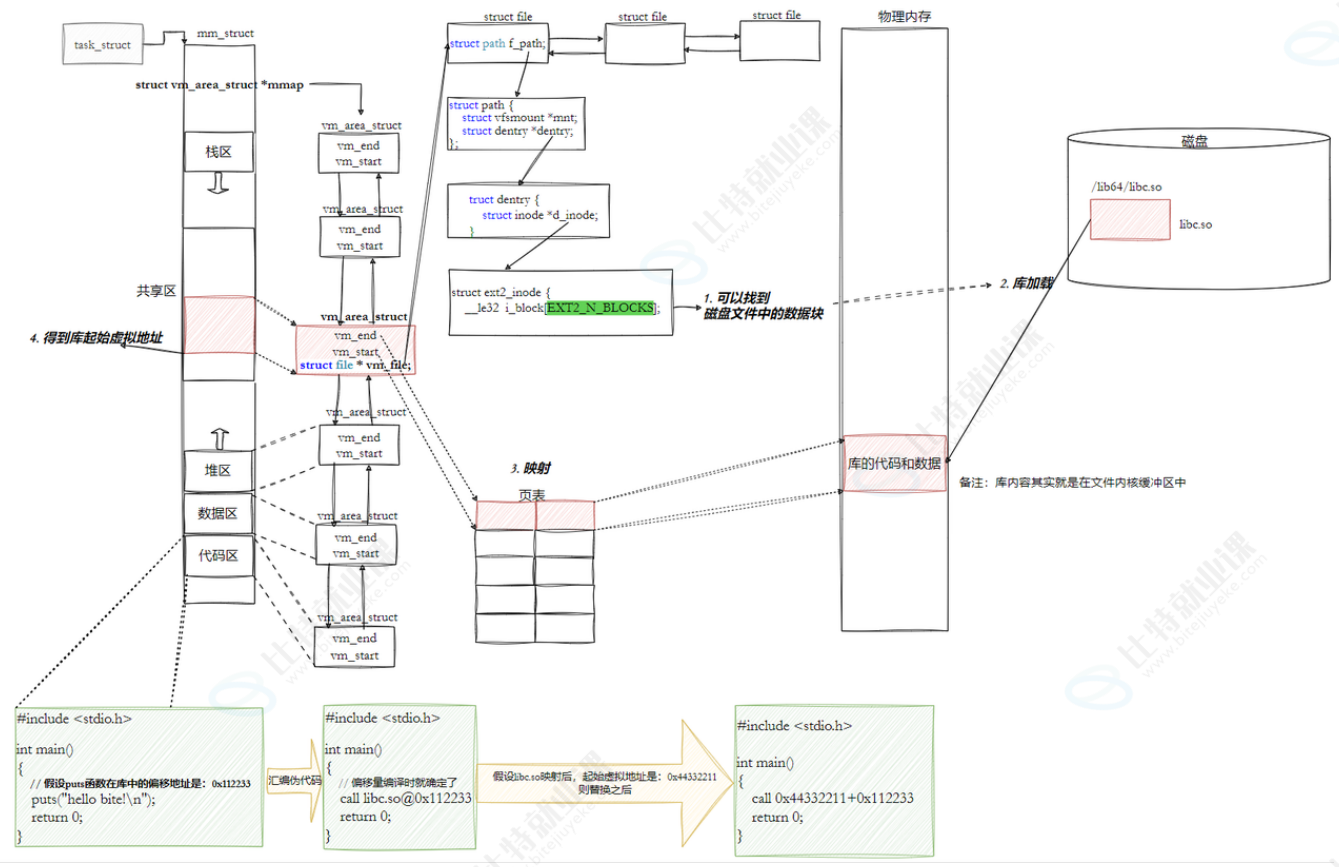
8.3.3.5我们的程序怎么进行库函数调用
📌 注意:
库已经被我们映射到了当前进程的地址空间中
库的虚拟起始地址我们也已经知道了
库中每⼀个⽅法的偏移量地址我们也知道
所有:访问库中任意⽅法,只需要知道库的起始虚拟地址+⽅法偏移量即可定位库中的⽅
法
⽽且:整个调⽤过程,是从代码区跳转到共享区,调⽤完毕在返回到代码区,整个过程完
全在进程地址空间中进⾏的.
- 编译时:生成偏移占位
- 编译器识别库函数(如
puts)调用,仅记录该函数在动态库内的相对偏移地址 (例如图中的0x112233)。- 生成的调用指令为占位形式:
call libc.so@0x112233,此时无实际虚拟地址。
- 加载时:确定库的虚拟基地址
- 动态链接器加载
libc.so,内核为其在进程虚拟地址空间的 "共享区" 分配起始虚拟地址 (例如图中的0x44332211)。- 内核通过页表将库的代码数据映射到该虚拟地址范围,完成库的虚拟地址空间分配。
- 重定位:计算最终虚拟地址
- 动态链接器将库的起始虚拟地址与函数的相对偏移相加:
0x44332211 + 0x112233 = 0x44444444- 修改原调用指令,将占位地址替换为计算出的最终虚拟地址:
call 0x44444444。
- 运行时:虚拟地址→物理地址映射
- CPU 执行
call 0x44444444时,MMU(内存管理单元)查询页表。- 将虚拟地址
0x44444444转换为对应的物理内存地址。- CPU 跳转到该物理地址,执行库函数的机器指令。
总结
- 核心逻辑:反汇编得库函数内偏移 → 加载后得库虚拟基地址 → 相加得函数虚拟地址 → 页表映射得物理地址 → CPU 执行。
- 关键前提:动态库的位置无关代码(PIC)保证了偏移量的固定性,是地址计算的基础。
- 页表映射是虚拟地址到物理地址的 "桥梁",是所有内存访问的必经步骤,而非库函数特有。
这个方法致命的缺点是代码段数据不可以修改
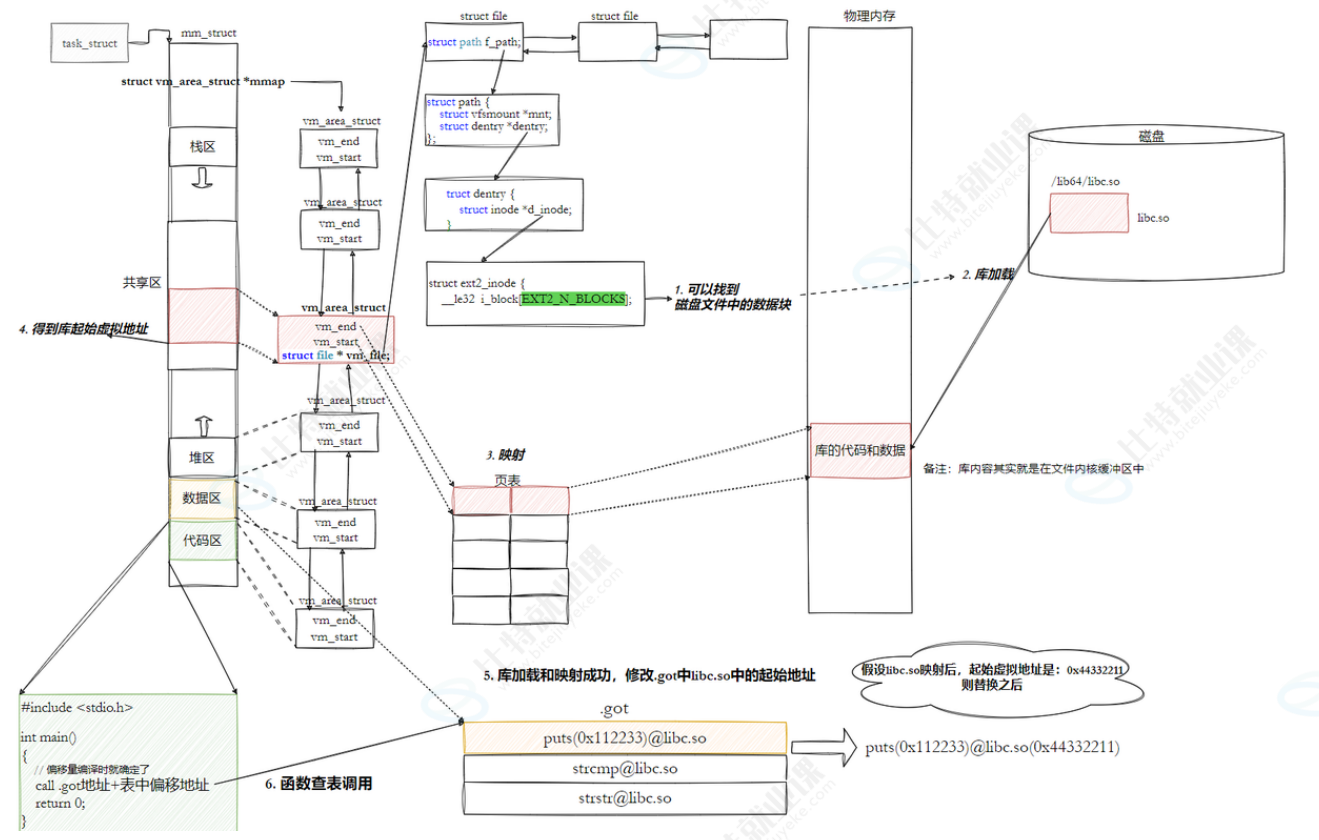
8.3.3.6全局偏移量表GOT(global offset table)
注意:
-也就是说,我们的程序运⾏之前,先把所有库加载并映射,所有库的起始虚拟地址都应该
提前知道
-然后对我们加载到内存中的程序的库函数调⽤进⾏地址修改,在内存中⼆次完成地址设置
(这个叫做加载地址重定位)
-等等,修改的是代码区?不是说代码区在进程中是只读的吗?怎么修改?能修改吗?
所以:动态链接采⽤的做法是在 .data (可执⾏程序或者库⾃⼰)中专⻔预留⼀⽚区域⽤来存放函数的跳转地址, 它也被叫做全局偏移表GOT ,表中每⼀项都是本运⾏模块要引⽤的⼀个全局变量或函数的地址。
因为.data区域是可读写的,所以可以⽀持动态进⾏修改
- 编译阶段:分配 GOT 表偏移
在代码里写
call .got地址+表中偏移地址时,编译器做了两件事:
- 固定偏移 :编译器会为每个动态符号(如
puts)在 GOT 表中分配一个唯一的偏移位置,比如puts对应的偏移是0x10。- 生成指令 :把代码里的
call puts转换成call [GOT_BASE + 0x10],这里的GOT_BASE是 GOT 表的起始地址,0x10就是编译时分配好的固定偏移量。这个阶段,程序并不知道
puts的真实地址,只知道它在 GOT 表中的偏移位置。
- 加载阶段:填充 GOT 表项
当程序加载时,动态链接器会:
- 找到
libc.so中puts函数的实际内存地址,比如0x7f89002a1230。- 把这个地址写入 GOT 表中
0x10偏移对应的表项里。此时,
GOT_BASE + 0x10这个地址里就存着puts的真实执行地址了。
- 运行阶段:通过偏移调用函数
程序执行到
call [GOT_BASE + 0x10]时,会:
- 先从
GOT_BASE + 0x10这个地址中读取存储的puts真实地址0x7f89002a1230。- 然后跳转到这个地址执行
puts函数。
- 由于代码段只读,我们不能直接修改代码段。但有了GOT表,代码便可以被所有进程共享。但在不同进程的地址空间中,各动态库的绝对地址、相对位置都不同。反映到GOT表上,就是每个进程的每个动态库都有独⽴的GOT表,所以进程间不能共享GOT表。
- 在单个.so下,由于GOT表与 .text 的相对位置是固定的,我们完全可以利⽤CPU的相对寻址来找到GOT表。
- 在调⽤函数的时候会⾸先查表,然后根据表中的地址来进⾏跳转,这些地址在动态库加载的时候会被修改为真正的地址。
- 这种⽅式实现的动态链接就被叫做 PIC 地址⽆关代码 。换句话说,我们的动态库不需要做任何修改,被加载到任意内存地址都能够正常运⾏,并且能够被所有进程共享,这也是为什么之前我们给编译器指定-fPIC参数的原因,PIC=相对编址+GOT。


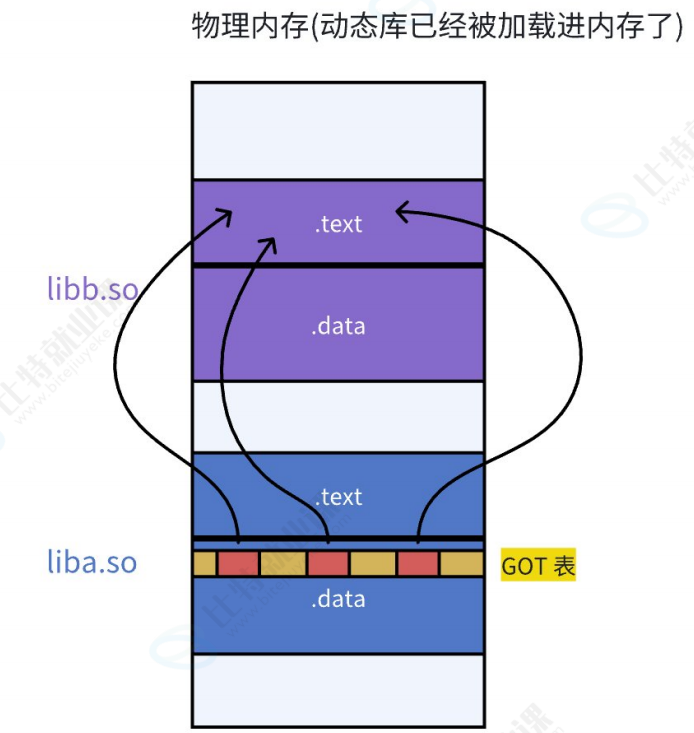
8.3.3.7库间依赖
注意:
-不仅仅有可执⾏程序调⽤库
-库也会调⽤其他库!!库之间是有依赖的,如何做到库和库之间互相调⽤也是与地址⽆关的呢?
-库中也有.GOT,和可执⾏⼀样!这也就是为什么⼤家为什么都是ELF的格式!
由于GOT表中的映射地址会在运⾏时去修改,我们可以通过gdb调试去观察GOT表的地址变化。在这⾥我们只⽤知道原理即可.
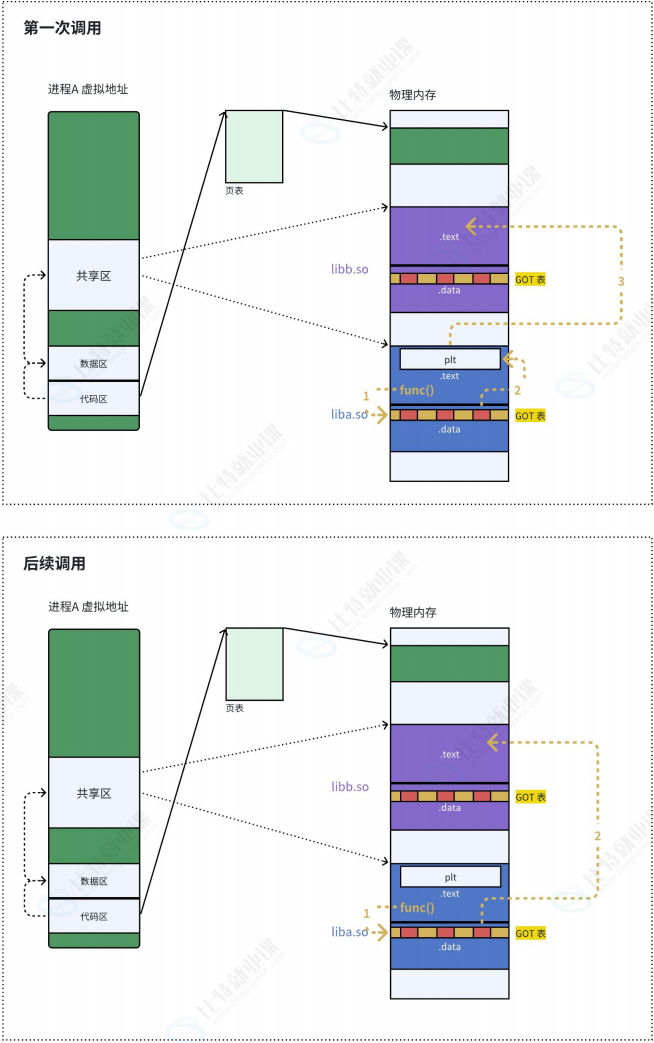
由于动态链接在程序加载的时候需要对⼤量函数进⾏重定位,这⼀步显然是⾮常耗时的。为了进⼀步降低开销,我们的操作系统还做了⼀些其他的优化,⽐如延迟绑定, 或者也叫PLT (过程连接表(Procedure Linkage Table))。与其在程序⼀开始就对所有函数进⾏重定位,不如将这个过程推迟到函数第⼀次被调⽤的时候,因为绝⼤多数动态库中的函数可能在程序运⾏期间⼀次都不会被使⽤到。
📋 GOT 与 PLT 协同工作关键步骤清单
- 编译阶段
- 编译器生成可执行文件时,会为每个动态库函数调用生成 PLT 条目 和对应的 GOT 表项。
- PLT 条目里存放的是跳转指令,初始指向动态链接器的解析入口(PLT 0)。
- GOT 表项初始时只保存符号占位符或偏移量(如
puts@libc.so),而非真实地址。
- 程序启动与动态库加载
- 动态链接器加载
libc.so并映射到进程虚拟地址空间,得到库的起始虚拟地址(如0x44332211)。- 此时 GOT 表项仍未被填充真实地址,处于 "待解析" 状态。
首次调用
puts程序执行
call puts@plt,跳转到 PLT 中puts对应的条目。PLT 条目执行
jmp *puts@GOT,尝试跳转到 GOT 表中puts的地址。因为是首次调用,GOT 表中的地址并未解析,会跳回 PLT 条目后续的指令。
PLT 条目将
puts的符号信息压栈,然后跳转到 PLT 0(公共解析入口)。PLT 0 跳转到动态链接器的解析函数
_dl_runtime_resolve。动态链接器计算
puts的真实地址:plaintext
真实地址 = 0x44332211(库起始地址) + 0x112233(函数偏移)动态链接器将计算出的真实地址写入 GOT 表对应的
puts条目。最后跳转到
puts的真实地址执行函数。后续调用
puts程序再次执行
call puts@plt,跳转到 PLT 条目。PLT 条目执行
jmp *puts@GOT,直接跳转到 GOT 表中已缓存的puts真实地址。无需再触发动态链接器解析,直接执行函数,效率更高。
8.3.4总结
-静态链接的出现,提⾼了程序的模块化⽔平。对于⼀个⼤的项⽬,不同的⼈可以独⽴地测试和开发⾃⼰的模块。通过静态链接,⽣成最终的可执⾏⽂件。
-我们知道静态链接会将编译产⽣的所有⽬标⽂件,和⽤到的各种库合并成⼀个独⽴的可执⾏⽂件,其中我们会去修正模块间函数的跳转地址,也被叫做编译重定位(也叫做静态重定位)。
-⽽动态链接实际上 将链接的整个过程推迟到了程序加载的时候 。⽐如我们去运⾏⼀个程序,操作系统会⾸先将程序的数据代码连同它⽤到的⼀系列动态库先加载到内存,其中每个动态库的加载地址都是不固定的,但是⽆论加载到什么地⽅,都要映射到进程对应的地址空间,然后通过.GOT⽅式进⾏调⽤(运⾏重定位,也叫做动态地址重定位)。