【深度学习Day5】决战 CIFAR-10:手把手教你搭建第一个"正经"的卷积神经网络 (附调参心法)
摘要:维度计算通关了,卷积、池化这些"乐高积木"也摸熟了------恭喜你,终于可以告别 MNIST 这个黑白两色的"新手村"了!今天,咱们要冲的是计算机视觉界的经典副本------CIFAR-10。这不仅是从"黑白素描"到"彩色照片"的跨越,更是检验你是否真懂 CNN 的"毕业考试"。本文全程保姆级教学,从数据流水线搭建到 Mini-VGG 网络手搓,从数据增强防过拟合到 Dropout 实战,每一步都拆解得明明白白。文末还藏了一份"炼丹(调参)心法",新手直接抄作业就能把准确率拉满!
关键词:PyTorch, CNN, CIFAR-10, 过拟合, Dropout, 调参技巧, 新手入门
一、 灵魂拷问:为啥 MNIST 是新手村,CIFAR-10 才是真战场?
咱先摸着良心说:MNIST 那玩意儿,真的太"照顾"新手了。就像你学画画,先练画火柴人------背景纯黑,数字纯白,边缘清晰,特征单一到离谱。别说 CNN 了,随便整个 MLP(全连接网络),稍微调调参都能干到 97% 准确率,纯属"新手福利局"。
但 CIFAR-10 不一样,它是个实打实的"硬核战场"------里面全是 32×32 的彩色图片,10 个类别(飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船、卡车),每一张都充满了"陷阱":
- 维度暴增:从"单身狗"到"三人行" :MNIST 是单通道灰度图,shape 是 (1,28,28);CIFAR-10 是 RGB 三通道彩色图,shape 直接变成 (3,32,32)。信息量大了不止一点,网络处理起来的难度直接翻倍------就像从读拼音儿歌,变成读文言文。
- 背景混乱:主角藏在"杂物堆"里:MNIST 里的数字永远在正中间,背景干净得像新铺的床单;但 CIFAR-10 里的物体,那是真·随心所欲------鸟可能站在树上,也可能飞在云里;猫可能趴在沙发上,也可能躲在草丛里。网络得学会"自动忽略无关背景,精准锁定主角",这才是计算机视觉的核心能力。
- 类间相似性拉满:逼死"脸盲"网络:MNIST 里的 0 和 1 有着云泥之别,但 CIFAR-10 里的猫和狗、汽车和卡车,长得那叫一个像!别说网络了,有时候我自己都得瞅半天才能分清。这就要求网络能学到物体的"本质特征",而不是表面的皮毛。
这里给大家放个真实战报:用跑 MNIST 稳拿 97% 准确率的 MLP 去跑 CIFAR-10,准确率通常只有 40%-50%------比瞎猜(10%)强点,但纯属"送人头"。而咱们今天用 CNN 搭建的简单网络,就能轻松干到 74%+,优化一下甚至能冲 85%!这就是卷积提取空间特征的魔力~
二、 数据流水线:PyTorch 版"图像处理工厂"(比 MATLAB 香多了)
做深度学习,数据处理是第一步,也是最容易踩坑的一步。MATLAB 里的 imageDatastore 虽然好用,但灵活性差;PyTorch 里的 transforms 就不一样了,相当于给你一套"定制化流水线",从图片读取、预处理到加载进 GPU,一条龙服务,还能自由加"工序"。
核心原则:训练集要"折腾",测试集要"老实" 。训练集越折腾,网络学得越鲁棒;测试集要是乱折腾,就相当于考试时改题目,测出来的准确率全是假的!
关键工序解读
-
数据增强(防过拟合神器) :相当于给训练集"换衣服",让网络认不出原图,只能学本质特征。咱们加了两个最实用的操作:
RandomHorizontalFlip():随机水平翻转。比如把飞机的机头从左翻到右,逼网络明白"不管机头朝哪,这都是飞机"。RandomCrop(32, padding=4):随机裁剪+填充。先给图片四周补 4 个像素的黑边,再随机裁成 32×32。这招能模拟"物体不在画面正中间"的真实场景------总不能让现实中的猫都站在镜头正中间拍照吧?
-
标准化(加速收敛的关键) :把像素值从 0,1 映射到 -1,1。这里用的
mean=[0.5,0.5,0.5]、std=[0.5,0.5,0.5]是 RGB 图片的"通用配方",记住就行!作用是让所有像素值都处于同一个"舒适区",梯度下降跑起来不跑偏、不卡顿------就像跑步前先热身,能少走很多弯路。
完整代码(可直接复制运行)
python
import torch
import torchvision
import torchvision.transforms as transforms
# 定义数据预处理流水线:训练集折腾,测试集躺平
train_transform = transforms.Compose([
transforms.RandomHorizontalFlip(), # 随机水平翻转(给图片"翻个身")
transforms.RandomCrop(32, padding=4), # 随机裁剪+填充(模拟物体偏移)
transforms.ToTensor(), # 转成Tensor格式(PyTorch专属"数据格式")
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 标准化到[-1,1]
])
test_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
# 测试集啥也不加,老实读图就行
])
# 加载数据(自动下载,第一次慢,后续直接用缓存)
trainset = torchvision.datasets.CIFAR10(
root='./data', # 数据存放在当前目录的data文件夹
train=True, # 加载训练集
download=True, # 没有就自动下载
transform=train_transform
)
# 数据加载器:批量喂数据,还能多线程加速
trainloader = torch.utils.data.DataLoader(
trainset,
batch_size=64, # 每次喂64张图
shuffle=True, # 打乱训练集顺序(避免网络"死记硬背")
)
testset = torchvision.datasets.CIFAR10(
root='./data',
train=False, # 加载测试集
download=True,
transform=test_transform
)
testloader = torch.utils.data.DataLoader(
testset,
batch_size=100, # 测试集批量可以大一点,速度更快
shuffle=False, # 测试集不用打乱,按顺序测就行
)
# 类别标签:记下来,后续看预测结果能用
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')MATLAB 老鸟专属笔记:这里的 DataLoader 比 imageDatastore 灵活太多------不仅能自动批量处理,还能和后续的 GPU 训练无缝衔接。
三、 网络搭建:手搓 Mini-VGG,拒绝"调包侠"
很多新手学 CNN 喜欢直接调 torchvision 里的现成模型,看似快,实则学不到精髓。咱们今天用 【深度学习Day4】 学的"卷积、池化、全连接"积木,手搓一个简化版 VGG------VGG 是 ImageNet 竞赛的经典模型,核心思路就是"堆叠卷积块+池化下采样",简单又高效。
设计思路
核心逻辑:先提取特征,再分类。用卷积块提取图片的边缘、纹理、形状等特征,再用全连接层把这些特征映射到 10 个类别上。
- 特征提取部分:2 个卷积块。每个卷积块 = 卷积层(Conv)→ 激活函数(ReLU)→ 池化层(MaxPool)。卷积层负责提特征,ReLU 负责加非线性(让网络能学复杂关系),池化层负责"浓缩精华"(减少参数,防过拟合)。
- 分类层部分:全连接层(Linear)+ Dropout。把卷积提取的 2D 特征拉平成 1D 向量,再通过全连接层映射到 10 个类别;Dropout 负责"随机让一半神经元摸鱼",防止网络死记硬背。
硬核维度计算(必懂!不然网络会报错)
新手最容易踩的坑就是"维度不匹配"------输入和输出的 shape 对不上,程序直接崩。咱们一步一步算,保证明明白白:
- 输入:Batch, 3, 32, 32 → Batch 是批量大小(比如 128),3 是 RGB 通道,32×32 是图片尺寸。
- 卷积块 1:Conv2d(3, 32, 3, padding=1) → 输入通道 3,输出通道 32,卷积核 3×3,padding=1(填充 1 个像素)。 为什么加 padding?因为卷积核是 3×3,不加 padding 的话,图片尺寸会变小(32→30),加了 padding 能保持尺寸不变(还是 32×32)。 经过 ReLU 激活后,shape 不变 → Batch, 32, 32, 32。 再经过 MaxPool2d(2,2)(2×2 池化,步幅 2)→ 尺寸减半(32→16)→ Batch, 32, 16, 16。
- 卷积块 2:Conv2d(32, 64, 3, padding=1) → 输入通道 32,输出通道 64,其他参数和上一层一样。 经过 ReLU 后 shape 不变 → Batch, 64, 16, 16。 再经过 MaxPool2d(2,2) → 尺寸再减半(16→8)→ Batch, 64, 8, 8。
- 拉平(Flatten):把 Batch, 64, 8, 8 变成 1D 向量。计算方法:64×8×8=4096 → 拉平后 shape 是 Batch, 4096。
- 全连接层:Linear(4096, 512) → 从 4096 维降到 512 维;再经过 Linear(512, 64) → 降到 64 维;最后 Linear(64, 10) → 降到 10 维(对应 10 个类别)。
完整网络代码(带详细注释)
python
import torch.nn as nn
import torch.nn.functional as F
# 定义设备:有GPU用GPU,没GPU用CPU(GPU训练快10倍!)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
# 卷积块 1:3通道输入→32通道输出
self.conv1 = nn.Conv2d(3, 32, 3, padding=1) # 卷积层
self.pool = nn.MaxPool2d(2, 2) # 池化层(共用)
# 卷积块 2:32通道输入→64通道输出
self.conv2 = nn.Conv2d(32, 64, 3, padding=1) # 卷积层
# 全连接层:特征映射到类别
self.fc1 = nn.Linear(64 * 8 * 8, 512) # 输入4096维→输出512维
self.fc2 = nn.Linear(512, 64) # 512维→64维
self.fc3 = nn.Linear(64, 10) # 64维→10维(10分类)
# Dropout:随机丢弃50%神经元(防过拟合核心)
self.dropout = nn.Dropout(0.25)
def forward(self, x):
# 前向传播:数据在网络里的流动路径
x = self.pool(F.relu(self.conv1(x))) # 卷积1→ReLU→池化 → [B,32,16,16]
x = self.pool(F.relu(self.conv2(x))) # 卷积2→ReLU→池化 → [B,64,8,8]
x = x.view(-1, 64 * 8 * 8) # 拉平:[B,64,8,8]→[B,4096]
# 这里的-1表示"自动计算Batch大小",不用手动改,超方便!
x = F.relu(self.fc1(x)) # 全连接1→ReLU
x = self.dropout(x) # 加Dropout防过拟合
x = F.relu(self.fc2(x)) # 全连接2→ReLU
x = self.fc3(x) # 输出层:不用激活(CrossEntropyLoss自带Softmax)
return x
# 初始化模型并移到设备上
model = SimpleCNN().to(device)关键提醒 :Dropout 只在训练时生效!训练时调用 model.train(),Dropout 会随机丢弃神经元;测试时一定要调用 model.eval(),Dropout 会自动"下班",所有神经元都工作------不然测试准确率会低得离谱!
四、 训练实录:10轮"炼丹",见证 CNN 逆袭
训练代码的核心结构和 【深度学习Day3】 跑 MNIST 时差不多,这里直接复用之前的 train 和 test 函数,不用再写一遍,省时省力~ 下面直接给出完整可运行的训练+评估代码,不用再找旧代码拼接!
核心训练参数+完整训练/评估代码
python
import torch.optim as optim
import time
# 1. 核心参数
criterion = nn.CrossEntropyLoss() # 多分类损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001, weight_decay=1e-4) # 加权重衰减防过拟合
epochs = 10 # 训练10轮
batch_size = 64
# 2. 评估函数(计算测试集准确率)
def test(model, testloader, criterion):
model.eval() # 切换到评估模式,Dropout失效
test_loss = 0.0
correct = 0
total = 0
with torch.no_grad(): # 关闭梯度计算,节省显存和时间
for X, y in testloader:
X, y = X.to(device), y.to(device)
outputs = model(X)
loss = criterion(outputs, y)
test_loss += loss.item() * X.size(0)
_, predicted = torch.max(outputs.data, 1)
total += y.size(0)
correct += (predicted == y).sum().item()
# 计算平均损失和准确率
avg_loss = test_loss / total
accuracy = 100 * correct / total
return avg_loss, accuracy
# 3. 完整训练循环
def train(model, trainloader, testloader, criterion, optimizer, epochs):
print(f"共{epochs}轮,batch_size={batch_size}")
print("----------------------------------------")
best_acc = 0.0 # 记录最佳测试准确率
for epoch in range(epochs):
start_time = time.time()
model.train() # 切换到训练模式,Dropout生效
running_loss = 0.0
for X, y in trainloader:
X, y = X.to(device), y.to(device)
# 梯度清零
optimizer.zero_grad()
# 前向传播+反向传播+优化
outputs = model(X)
loss = criterion(outputs, y)
loss.backward()
optimizer.step()
# 统计训练损失
running_loss += loss.item() * X.size(0)
# 每轮结束后评估测试集
avg_train_loss = running_loss / len(trainloader.dataset)
test_loss, test_acc = test(model, testloader, criterion)
# 记录最佳准确率
if test_acc > best_acc:
best_acc = test_acc
# 可选:保存最佳模型
torch.save(model.state_dict(), "cifar10_best_model.pth")
# 打印每轮训练信息
end_time = time.time()
epoch_time = end_time - start_time
print(f"Epoch [{epoch+1}/{epochs}]")
print(f"训练损失: {avg_train_loss:.4f}, 测试损失: {test_loss:.4f}")
print(f"测试准确率: {test_acc:.2f}%, 最佳准确率: {best_acc:.2f}%")
print(f"本轮耗时: {epoch_time:.2f}秒")
print("----------------------------------------")
print("训练结束!最佳模型已保存为 cifar10_best_model.pth")
# 4. 启动训练(直接调用函数即可)
train(model, trainloader, testloader, criterion, optimizer, epochs)训练战报
用 GPU 训练(batch_size=64),10 轮训练总耗时不到 8 分钟,每轮耗时 40 秒左右内,准确率表现如下(这里给出部分我的结果):
text
共10轮,batch_size=64
----------------------------------------
Epoch [1/10]
训练损失: 1.5999, 测试损失: 1.3044
测试准确率: 51.61%, 最佳准确率: 51.61%
本轮耗时: 41.32秒
...
Epoch [5/10]
训练损失: 0.9686, 测试损失: 0.8486
测试准确率: 69.91%, 最佳准确率: 69.91%
本轮耗时: 40.09秒
...
Epoch [10/10]
训练损失: 0.8114, 测试损失: 0.7328
测试准确率: 74.72%, 最佳准确率: 74.72%
本轮耗时: 40.31秒
----------------------------------------
训练结束!最佳模型已保存为 cifar10_best_model.pth五、 核心干货:CNN 调参心法(面试必背!)
跑通模型只是第一步,真正的"炼丹大师"都懂调参。面试官最爱问:"如果你的模型准确率上不去,你会怎么办?" 直接甩下面这套心法,保证让面试官眼前一亮!
5.1 遇到过拟合(训练集99%,测试集70%):这是最常见的坑
过拟合就是网络"死记硬背"了训练集,遇到新数据(测试集)就歇菜------相当于考试前背题,换一套题就考砸。对策按优先级排序:
- 数据增强(首选!零成本见效) :除了我们加的翻转和裁剪,还能加
RandomRotation(随机旋转)、ColorJitter(随机调整亮度/对比度)------越折腾,网络越难背图。 - 加大 Dropout 力度:如果用了 0.25 的 Dropout 还过拟合,就调到 0.4 或 0.5(别太高,不然网络学不到东西)。
- 加权重衰减(L2正则化) :在优化器里加
weight_decay=1e-4,相当于给权重戴个"紧箍咒",不让它长得太大------权重太大容易过拟合。 - 早停(Early Stopping) :训练时盯着测试集准确率,一旦连续几轮不涨甚至下降,就立刻停------别让网络在训练集上"瞎琢磨"。
5.2 遇到欠拟合(训练集都不到70%):网络太"笨",学不会
欠拟合就是网络的"学习能力"不够,连训练集的规律都没摸透------相当于小学生学微积分,根本跟不上。对策:
- 加深/加宽网络:比如把卷积层从 2 层加到 4 层,或者把输出通道从 32/64 改成 64/128------给网络"加脑子"。
- 调低学习率:学习率太高,梯度下降会"跳来跳去",永远踩不到最优解;调低到 0.0001,让它慢慢学。
- 减少正则化力度:如果加了 Dropout 或权重衰减,就适当降低(比如 Dropout 从 0.5 降到 0.3)------别把网络"管太严",让它放开了学。
六、 趣味环节:看看 CNN 到底在"看"什么?
咱们花了这么多时间搭网络,你不好奇它是怎么"看"图片的吗?其实可以用代码提取卷积层的特征图,可视化之后就一目了然了:
- 第一层卷积核:主要提取边缘、颜色、纹理这些简单特征------就像我们看东西先看轮廓。
- 深层卷积核:主要提取眼睛、车轮、翅膀这些复杂特征------网络会把简单特征组合成复杂特征,最后判断"这是什么"。
这里给大家放一段简单的可视化代码(直接跑):
python
import matplotlib.pyplot as plt
import numpy as np
# 取一张测试图
dataiter = iter(testloader)
images, labels = next(dataiter)
img = images[0].unsqueeze(0).to(device) # 取第一张图,加Batch维度
# 提取conv1层的特征图
model.eval()
with torch.no_grad():
# 手动前向传播到conv1
x = F.relu(model.conv1(img))
# 可视化特征图(取前16个通道)
x = x.squeeze(0).cpu().numpy() # 去掉Batch维度,转成numpy
fig, axes = plt.subplots(4, 4, figsize=(10, 10))
for i, ax in enumerate(axes.flat):
ax.imshow(x[i], cmap='gray')
ax.axis('off')
plt.savefig('conv1_features.png')
plt.show()运行后会生成一张 4×4 的特征图,每一张小图都是 CNN 看到的"世界"------是不是很神奇?这完美印证了 CNN "由简入繁"的特征提取逻辑。 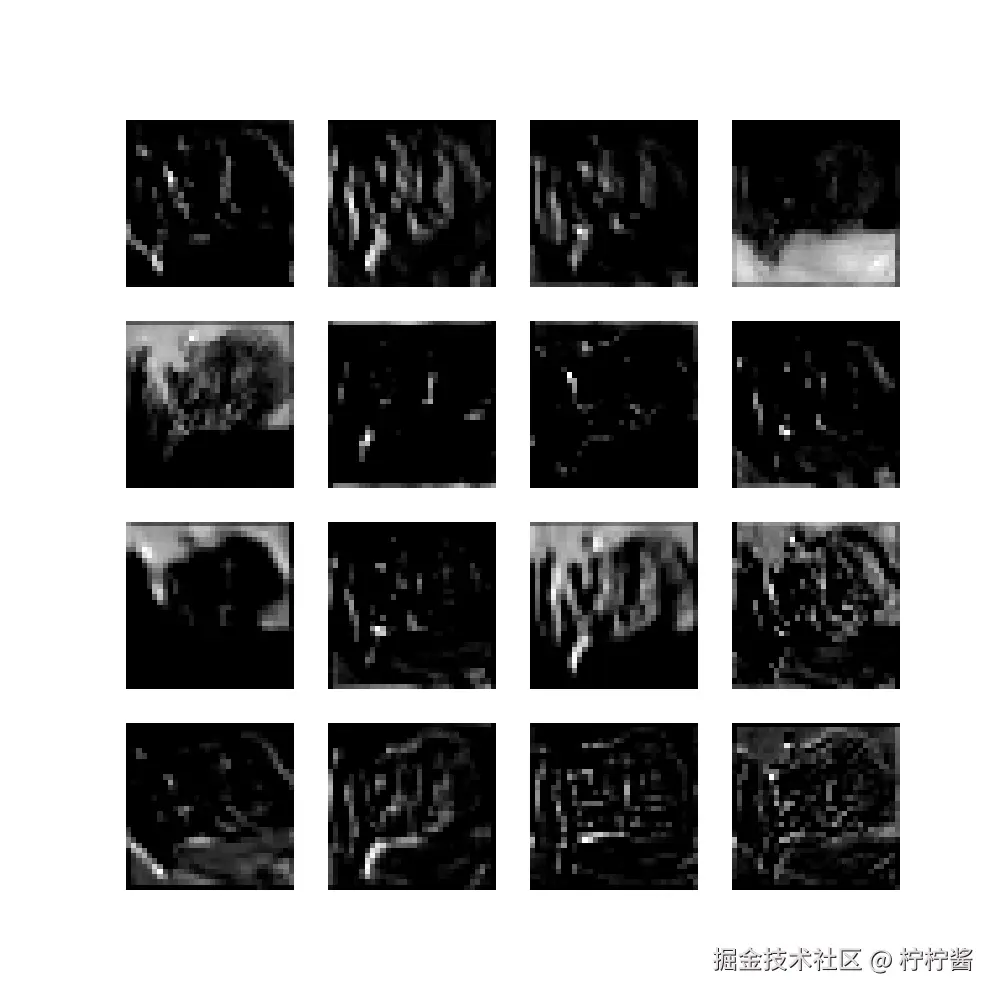
📌 下期预告:ResNet + 迁移学习,准确率冲 90%+!
通过今天的实战,咱们也算看明白了:CNN虽然比MLP能打,但架不住它会"作弊"------偷偷把训练集的"标准答案"背下来了(训练集准确率飙高,测试集拉胯,过拟合实锤!)。
所以下一篇,咱先不急着换"新装备"(ResNet先委屈一下,放仓库积灰),专门开一期"反作弊特训营"------死磕数据增强(Data Augmentation)! 我会带你扒明白PyTorch transforms的"基础操作",手把手教你玩明白高级增强技巧。核心思路就一个:不增加模型半点复杂度,纯靠"压榨"数据的每一滴价值,把准确率再往上猛提一截! 让模型从"死记硬背"变成"真正理解"。
最后留个小作业:把今天的网络改成 3 个卷积块,看看准确率能不能冲到 80%?评论区晒出你的战报!
欢迎关注我的专栏,见证 MATLAB 老鸟到算法工程师的进阶之路!