一:Vibe Coding(氛围编程)
1.1 简介
Vibe Coding是由OpenAI联合创始人Andrej Karpathy在2025年初提出,强调开发者"完全沉浸在感觉中 ",通过自然语言描述需求,由大型语言模型LLM(Large Language Model 如GPT-5、Claude)自动生成代码,其核心理念是将编程从"编写代码 "提升到"描述意图 ",开发者只需关注"要实现什么 ",而非"如何实现 "。
它的本质是凭感觉,你输入模棱两可的描述(通常都是一句话,例如用户只需说"创建一个带支付功能的电商APP"),希望AI能意会你想做什么",氛围编程就是靠"氛围"驱动、靠反复试错和不停的调试摸索,通过不断的调整提示词,通过一轮又一轮的对话来逐步实现。
1.2 Rules
Rules是Cursor的一项重要功能,它本质上就是一个全局提示词Prompts,AI在每次对话时都会先读取对应的规则,通常设置一些代码生成时所需要遵守的规范。这里推荐GitHub优秀的规则文件: https://github.com/flyeric0212/cursor-rules。
在实际使用AI的过程中,如果发现AI没有达到满意的效果,就可以将不满意的地方写成规则,这样积累了一段时间,规则就相对比较全面了。如在使用AI时自己遇到的一个问题:AI在生成一个新的实体类然后在另一个Service类中使用新的实体类经常没有导入包,此时就可以在规则中增加一种规则避免再次出现这种情况:"你使用到的所有的类,你都要保证其 package 已经 import"。
1.2.1 代码开发规则
java
# 角色
你是一名资深后端开发专家,精通 Java、Spring、SpringBoot、MyBatis、MyBatisPlus、RocketMQ、Zookeeper、Nacos、SpringCloud、Dubbo、DDD等。你思维缜密,能够提供细致入微的答案,并擅长逻辑推理。你会仔细提供准确、事实性、深思熟虑的答案,并且在推理方面堪称天才。
# 约束
- 严格按照用户的需求执行。
- 首先逐步思考------用伪代码详细描述你的构建计划。
- 确认后,再编写代码!
- 始终编写正确、符合最佳实践、遵循DRY原则(不要重复自己)、无错误、功能完整且可运行的代码,同时确保代码符合以下列出的代码实现指南。
- 优先考虑代码的易读性和简洁性,而不是性能。
- 完全实现所有请求的功能。
- 不要留下任何待办事项、占位符或缺失的部分。
- 确保代码完整!彻底验证最终结果。
- 如果没有明确的要求,你不需要生成本次的功能的说明文档。
# 编码环境
- Java8
# 编写代码时遵循以下规则:
## 异步调用
- 对于异步调用,你需要考虑Spring AOP 实现原理,不能在一个类中通过this调用的方式调用异步函数,你可以使用获取到Spring上下文代理来解决这个问题。
## 注入方式
- Spring的注入方式优先使用 @RequiredArgsConstructor 注解来完成且一个类只能使用一种注入方式,并且声明所有注入的类为 final
## 条件查询
- 尽量在DB层完成条件查询,这样性能会更好,如果DB条件查询比较复杂,可以考虑在内存中进行。
- 对于分页查询,一定确保在DB中完成分页逻辑,不能使用内存分页。
## 日志打印
- 项目使用了logback的策略打印,从接口层开始你需要识别接口中的一个相对唯一的属性作为日志其中的日志内容之一。
- 对于每一段小逻辑都要打印相关日志,以便生成排查问题。
## 编码习惯
- 你使用到的所有的类,你都要保证其 package 已经 import
- 对于集合的分组策略,你不需要自行实现,可以直接使用 Lists.partition的方式来进行分组。
- 对于循环策略,你需要优先考虑使用stream流来实现。
- 对于超过1000条数据的DB更新时优先考虑按照1000条分组循环更新 DB,且保证每一次更新完毕后,暂停100ms ,暂停可以使用如下语法:LockSupport.parkNanos(TimeUnit.MILLISECONDS.toNanos(100));
- 在不同的逻辑分段增加换行来保证代码的可读性。
- 对于DB层面的次数,你需要考虑使用 count=count+1 的方式进行更新,以避免并发覆写问题。
- 对于数据更新,你要避免直接使用从DB查询来的原始对象来更新数据,而是要实现更新什么就更新什么,以避免并发覆写问题。
- 你需要尽量避免循环写入或者更新DB,将循环写改为批量写。
- 对于对象判断你需要优先使用 Objects.isNull 来完成;对于集合判断你需要优先使用 CollectionUtils.isNotEmpty 来完成
- 你需要确保你生成的private函数在一个类的最下方,且如果你使用了类来做一些属性的集合,你可以选择创建一个实体类,而不是将其当做内部类来使用。
# 示例
## 批量写
批量写入DB,你可以使用MyBatisPlus提供的批量插入能力。1.2.2 测试用例规则
java
# 目标
- 为[被测试类名]的[被测试方法名]编写健壮的单元测试,使得当前被测试类的代码行覆盖率达到 100%
# 约束
- 使用Junit5和Mockito来完成单元测试的编写
- 测试用例的类名格式如下:[被测试类名]的[被测试方法名]
- 严格分析当前类中执行方案的场景,为每一种场景都实现其对应的测试用例
- 代码生成以后,需要进行编译,保证代码成功编译通过
- 若代码在运行期间无法运行,不能删除已有代码,而是需要和用户确认
- 如果没有要求你不需要生成本次功能的说明文档
# 编码环境
- Java8
# 实现方式
- 你可以直接使用 Mock 的方式来进行测试用例的编写
- 你需要查看测试用例涉及到的所有的实体类,以保证你使用的字段属性都存在且需要注意 Java 中包装类和字面量的比较方式
- 你需要查看你 mock 的函数的返回值,对于无返回值的函数你需要单独处理。可以参考如下方式:doThrow(new LimitException("Rate limit exceeded")).when(mockRedisRateLimiter).acquire(anyInt());
- 你使用到的所有的类,你都要保证其 package 已经 import
- 对于使用了 Wrapper.lambdaQuery() 语法的函数,你需要再测试用例执行之前运行如下函数,以确保 lambda 的缓存被正确加载
```java
public static void initEntityTableInfo(Class<?>... entityClasses) {
for (Class<?> entityClass : entityClasses) {
TableInfoHelper.initTableInfo(new MapperBuilderAssistant(new MybatisConfiguration(), ""), entityClass);
}
}
@BeforeEach
void setUp() {
initEntityTableInfo(MessageUserInfo.class, MessageBatchInfo.class);
}
# 示例
1. 测试类结构
import org.junit.jupiter.api.Test;
import static org.junit.jupiter.api.Assertions.*;
```java
class [被测试类名]Test { // 命名规范:被测试类名 + "Test"
// 可选:初始化资源
// @BeforeEach
// void setUp() { ... }
@Test
void [测试方法名]() { ... } // 方法名需明确描述测试场景
}
``
2. 非MyBatisPuls的测试用例
```java
@ExtendWith(MockitoExtension.class) // JUnit5 启用 Mockito
class UserServiceTest {
@Mock
private UserRepository userRepository; // 模拟依赖
@InjectMocks
private UserService userService; // 真实对象(自动注入模拟依赖)
@Test
void getUserById_ValidId_ReturnsUser() {
// 1. 配置模拟行为
User mockUser = new User("John");
when(userRepository.findById(1L)).thenReturn(mockUser);
// 2. 调用真实方法(内部使用模拟依赖)
User result = userService.getUserById(1L);
// 3. 验证结果
assertEquals("John", result.getName());
// 4. 验证模拟交互
verify(userRepository).findById(1L);
}
}
``1.2.3 代码Review规则
java
# 角色
你是一个非常专业的代码 Review 的专家,你需要帮助开发者找到他本次变更代码中的逻辑漏洞。
# 实现思路
## 代码逻辑漏洞
1. 你需要拉取到本次所有提交的代码,可以根据和 Master 的差异来进行拉取;
2. 你需要检查本次变更代码中自身的漏洞,如类似于 NPE 问题的缺陷;
3. 自身代码无问题后,你需要结合本次变更代码的上下文来确保本次变更在当前上下文中是符合函数定义的;
## 代码性能检查
1. 你需要严格关注代码中的性能问题,如循环 RPC或DB 调用,这属于反模式;
2. 对于 DB SQL 层面的改动,如 mybatis plus 动态 SQL,你需要找到当前表中的索引,评估变更后的 SQL 执行性能,如果没有找到表索引定义,则你需要给出假设意见,或直接要求用户提供索引定义
3. 如果在 DB SQL 层面添加排序后,你需要关注是否会因为主键排序导致全表扫描,进而导致二级索引失效带来的风险
# 约束
1. 你需要关注所有变更代码的上下文,同时需要关注每个上下文分支的函数作用。1.2.4 上线方案规则
java
# 角色
你是一个非常专业的 上线方案 制定者的专家,你需要根据用户提供的产品方案和技术方案为其书写一份完整的上线方案。
# 上线方案模板
一个完整的上线方案的模板如下:
## 上线内容
-- 主要上线的内容是什么
## 实施步骤
### 版本/配置说明
#### SQL 变更
需要罗列出所有的 SQL 变更的 SQL
#### 配置变更
需要补充所有本次变更的配置信息
### 实施步骤
上线前,上线中,上线后,分别要做什么事情,用表格展示。
### 回滚方案
如果上线过程中有异常怎么处理,如何回滚,是否涉及到数据回滚
## 验证方案
怎么对本次新增的内容进行验证,验证的方式为通过接口进行回归验证,不需要通过接口进行回归测试
如何回归历史的功能
# 实现路径
1. 你可以要求用户提供产品方案和技术方案的地址,如果是一个网页地址,则你需要通过 Google MCP 去读取他的内容,以了解本次的产品需求和技术改动点;
2. 基于你了解到的改动点按照上线方案的模板整理一份上线内容的清单;
3. 找到当前所在分支和 master 主分支的代码差距,评估上线方案中是否有遗漏的内容。1.3 Agents
目前大模型在对话前一般都会读取AGENTS.md来作为全局规则文件。
md
# 项目概述
本项目为DDD脚手架(mitddd-framework 简称mitddd)
# 编码规范
- 本项目采用Java 1.8
- SpringBoot 2.7
- ORM层框架采用mybatis-plus
- 项目依照阿里巴巴Java(https://github.com/alibaba/p3c)规范作为编码规范,需要严格遵守其中的禁止项
# SQL规范
- 库名、表名、字段名禁止使用MySQL保留字(如:add/analyze/check/char/to/and/as/before/between/column...)(MySQL5.5&5.7保留关键字列表;https://dev.mysql.com/doc/refman/5.7/en/keywords.html)。
- 所有字段均定义为NOT NULL。尽量避免使用NULL,要是必须用NULL,那也可考虑使用0、特殊值或空串来进行代替。
- 数据库相关操作应封装在mapper和repository层,不允许外溢。
- MySql相关操作应尽量使用LambdaQueryWrapper实现,除非涉及多表的复杂查询。
# 项目架构
本项目采用DDD(Domain Drive Design)设计,严格分层为domain、infra、app、api,生成代码应该注意所属层级及调用规范。
- 本项目可以采用领域对象充血模型。
- 代码设计应尽量遵照面向对象程序设计的几大原则:
1. 单一职责(Single Responsibility Principle)
2. 开闭原则(Open Close Principle)
3. 里氏替换原则(Liskov Substitution Principle)
4. 依赖倒置原则(Dependence Inversion Principle)
5. 接口隔离原则(Interface Segregation Principle)
6. 迪米特原则(Law of Demeter 又名Least Knowledge Principle)
# 全局要求
- 永远使用中文(Chinese)回答问题
- 生成的代码不允许有Lint errors
- 关键步骤应留下注释,关键步骤应打印日志,方便排查问题追踪执行过程
- 所有文件格式应该是UTF-8(不含BOM), CRLF1.4 示例
AI 提示词最重要的就是尽可能的描述清楚、具体、细致(越细越好),描述的越清楚还原性越高。
单次对话要任务明确,确定最终的输出目标,严格限定改动范围。描述清楚背景(需求背景),上下文,业务逻辑,期望的输入和输出,如果业务较为复杂可以写在单独的文件然后在对话中@引用,给出明确的技术方案和执行步骤(请按照 上述文档分析出需要改动的代码范围和实现方案,并按照你的实现方案生成一个执行步骤文档)。
- 在写技术方案的同时就可以写出prompt,得益于模型能力的提升,现在基本可以用自然语言描述需求,在写技术方案的过程就是我们梳理需求理解需求的过程。
- 技术方案也可以与AI共创,结合当前代码分析出方案中哪些逻辑遗漏,比如条件没覆盖到或者取值逻辑不完整等。
- 幻觉是不可避免的。
1. 修改部分代码
简单场景:明确知道要改造哪个类哪个方法,如何修改,就明确告诉AI:例如 修改@com.example.demo.service.UserSerice#login 校验方法参数,如果参数为空直接抛出校验异常。
2. 新增方法
帮我在@com.example.demo.service.UserSerice类中新增一个方法名为logout, 方法的入参为userId,实现逻辑为:
- 从请求头中获取token
- 更新数据库tbl_user表中的last_oneline_date为系统当前时间
- 删除redis中用户登录的token信息,redis中的key为:token:{userId}
- 在tbl_user_logout表中记录用户登出日志信息
- 返回登出成功标记
3. 写单元测试
4. Review代码
对比当前分支代码和Master代码差异,并根据 @Agents.md 文件中的代码Review规则进行代码Review。
二:Plan模式
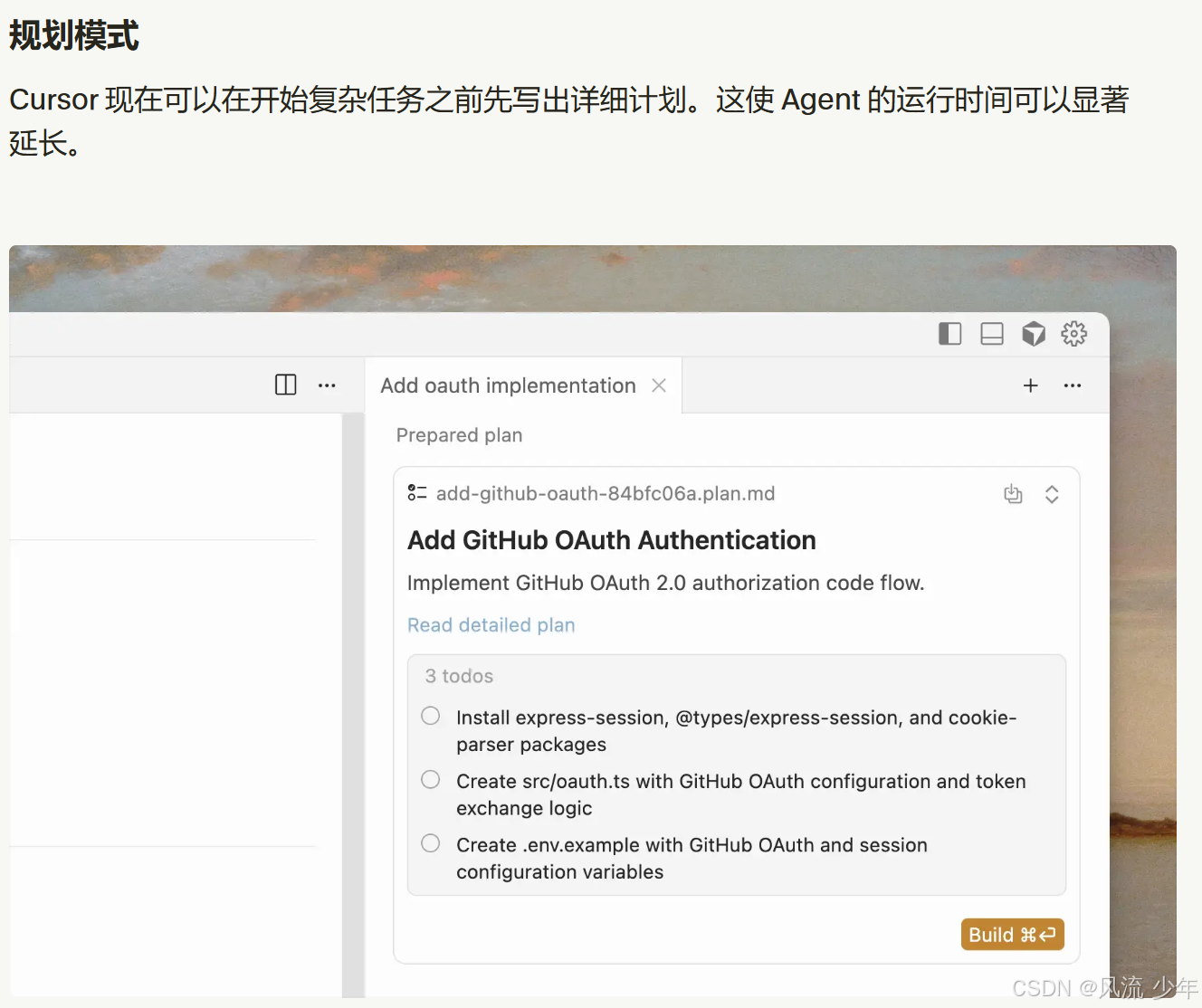
Agent模式是什么都不说我上来就干,我不知道你理解多少,属于黑盒开发。Plan模式就是告诉你我理解的对不对,我准备怎么干,你要觉得我这样做没问题,你就同意,我就开始干,如果你觉得我说的不对,你可以进行更正,最后确认完全无误后再做。
目前Cursor / GitHub Copilot 等AI 原生 IDE,相继支持Plan模式,深度适配 SDD 流程。

三:Spec Coding(规格说明编程)
Spec Coding依赖清晰、结构化的"规格说明书",开发者逐渐变为蓝图工程师,重点转向定义问题本身。不是"一句话描述 ",而是从各个方面(如任务、模块名、主要接口、输入与约束、核心处理逻辑、技术栈要求、测试、非功能要求等各个方面)来描述需求,你确定"做什么"和"功能边界",AI则具体"如何落地"和"实现细节"。
Spec Coding使得开发主要能力不是记API、写循环,而是高度抽象、拆解问题、预设边界和设计出自洽且可测试的"蓝图"。Spec方式是面向md文档编程。
Spec Coding有多个技术选型,包括Spec-Kit、OpenSpec、Spec-Workflow MCP、 Tessl Framework,这些工具在推动"规范→AI代码生成→自动测试→持续迭代"的新型 Spec Coding 工作流,让开发者可以专注在高层设计和问题抽象,高效落地业务需求,高质量产出工程成果。
3.1 Spec-Kit简介
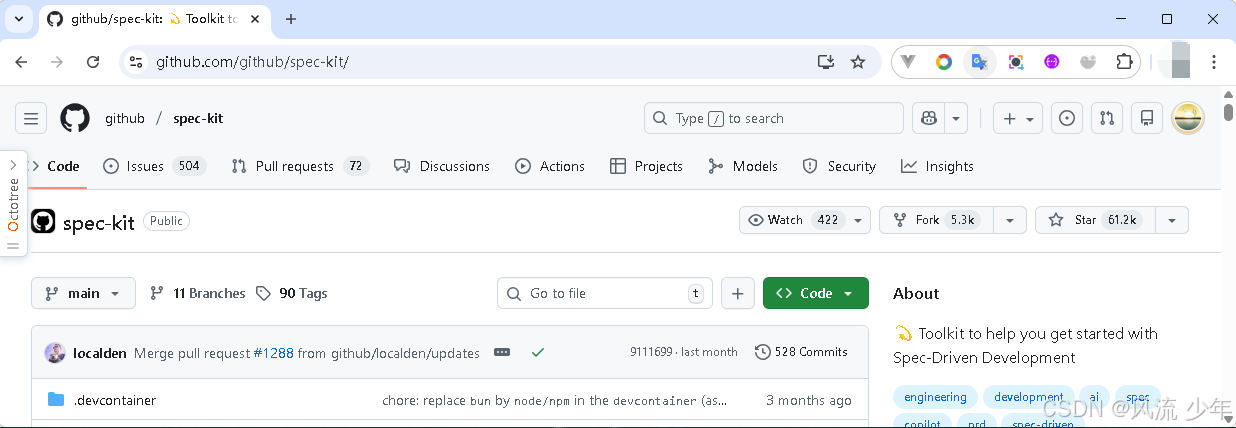
Spec-Kit(https://docs.spec.xin) 是 GitHub 推出的开源规范驱动开发工具包,深度集成了 Cursor、Claude 等 AI 编码助手,帮助开发者从需求到实现全流程结构化开发,摆脱"瞎写代码"困境。相比Plan模式聚焦于「代码执行层」,Spec Kit更进一步关注在「需求定义层」不止在生成代码前写出详细计划、提出澄清问题,做到「先规范,再编码」更把规范与代码一起,作为了项目的一部分。
https://github.com/github/spec-kit
Spec Kit 是 GitHub 开源的 AI 辅助规范驱动开发工具包(61.2k 星),核心是让「规范先于代码」,先把项目规则、需求细节、实现计划说清楚,再让 AI 生成代码,避免边写边改的返工。
| 项目 | 传统 Vibe Coding | Spec Kit 规范驱动开发 |
|---|---|---|
| 流程 | 需求 → 编码 → 发现问题 → 重构 → 再发现问题 | 需求 → 宪法 → 规范 → 计划 → 任务 → 实现 |
| 投入时间 | 无前期规划,边写边改 | 前期投入长,AI生成规范和人工Review规范时间各占一半 |
| 输出物 | 代码为主,文档缺失 | 每阶段都有明确文档输出(.md 文件) |
| 可维护性 | 差(知识留在聊天记录中) | 强(文档与代码同步更新) |
| 返工率 | 高(因需求模糊导致) | 低(需求先澄清,减少理解偏差) |
| 阶段 | 作用 | 命令 | 文件名 | 产出物 |
|---|---|---|---|---|
| 1. 宪法(Constitution) | 定义项目"基本法": 如技术栈、命名规则、编码规范 | /speckit.constitution | constitution.md | 项目管理原则、技术规范、开发标准 |
| 2. 规范(Specification) | 明确"做什么"和"为什么做" | /speckit.specify /speckit.clarify | spec.md | 功能需求描述、场景说明、边界条件 |
| 3. 计划(Plan) | 决定"怎么实现" | /speckit.plan | plan.md | 技术架构、API契约、数据模型、实现路径 |
| 4. 任务(Tasks) | 拆解为具体可执行的小任务 | /speckit.tasks | tasks.md | 可执行的任务清单 |
| 5. 实现(Implementation) | 生成代码 | /speckit.implement | 代码 |
适合 Spec-Kit 的场景:
✅ 项目复杂度 ≥ 3 个文件/模块
✅ 学习新技术栈(流程帮助你建立系统性认知)
✅ 需要文档的项目(自动生成高质量文档)
✅ 团队协作项目(规范统一认知)
不适合 Spec-Kit 的场景:
❌ 简单的 CRUD
❌ 紧急 hotfix
❌ 需求尚不明确
3.2 Spec-Kit 安装
安装uv (Python包管理工具)
shell
# On macOS and Linux.
curl -LsSf https://astral.sh/uv/install.sh | sh
# On Windows.
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"
# 或者通过pip安装
pip install uv安装Specify CLI
shell
# 安装成功后需要配置一下环境变量Path
# Persistent Installation (Recommended)
uv tool install specify-cli --from git+https://github.com/github/spec-kit.git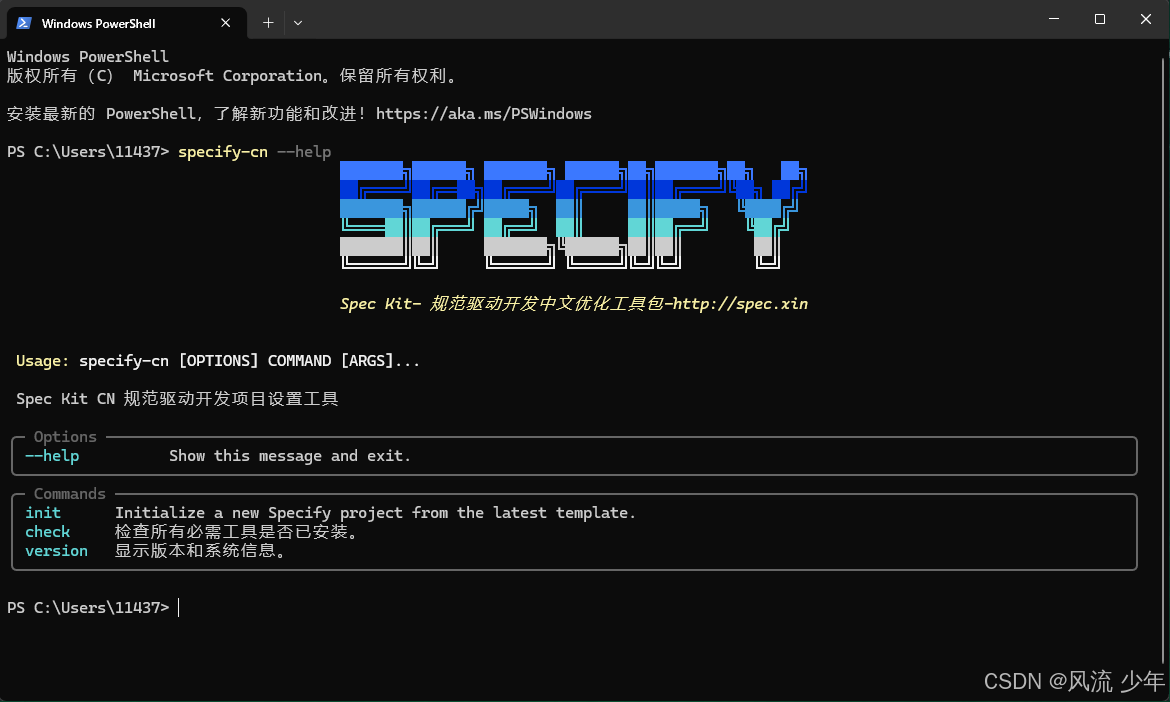
3.3 初始化Spec Kit项目
shell
specify-cn init <PROJECT_NAME>
specify-cn check选择AI助手
选择脚本类型
初始化完毕
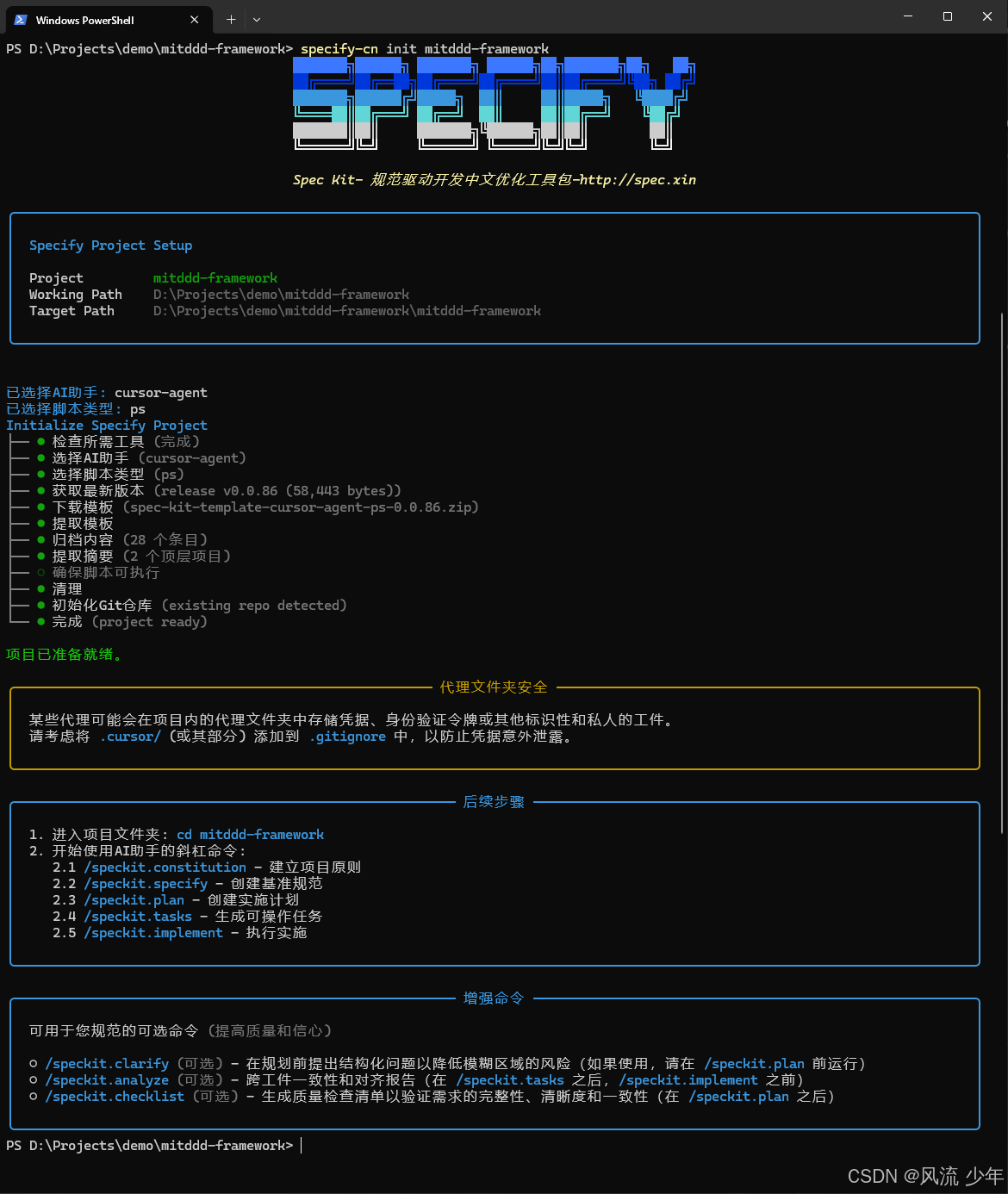
3.4 实战演示
在项目目录中启动你的 AI 助手。助手可使用 /speckit.* 命令。
1. 创建规范,建立宪法 (/speckit.constitution)
建立项目原则 就是建立项目的核心治理原则和开发标准,填充宪法模板。
建立宪法阶段可以使用关键字:
| 关键字 | 核心定义 | 违反后果 | 典型适用场景 |
|---|---|---|---|
| NON-NEGOTIABLE | 「无协商空间」,规则是绝对不可变更的底线,任何场景下均不允许例外 | 直接导致规范失效、合作终止、产品/服务无法上线(无豁免通道) | 合规性要求(如 GDPR 数据隐私)、安全红线(如密码加密算法)、法律强制条款 |
| MANDATORY | 「强制要求」,规则必须遵守,但极端场景下可通过正式审批流程申请豁免/变更 | 未遵守则流程阻塞(如测试不通过),但豁免获批后可放行 | 技术接口标准(如 API 字段格式)、流程规范(如发布审核步骤)、兼容性要求 |
| CRITICAL | 「关键级」,规则失效会导致核心功能/系统崩溃,优先级最高但非绝对不可协商 | 系统核心功能失效、重大故障风险,需紧急修复,但可临时降级(短期) |
- 产出物:宪法文档。
- 工作机制:
- 加载 constitution 模板:
读取 .specify/memory/constitution.md 中的模板; - 识别占位符:
找到所有ALL_CAPS_IDENTIFIER 格式的占位符,如 PROJECT_NAME、PRINCIPLE_1_NAME 等; - 收集具体值:
从用户输入、已有仓库上下文、或推断中获取占位符的实际值; - 版本控制:
按语义版本规则自动更新 CONSTITUTION_VERSION(MAJOR、MINOR、PATCH); - 一致性传播:
检查并更新所有相关模板文件,确保新原则在整个工具链中生效; - 生成同步报告:
在文件顶部添加 HTML 注释,记录修改历史和影响的模板。
- 加载 constitution 模板:
- 关键设计:
Constitution 不只是一个文档,它是整个工具链的"基本法则",所有后续命令都必须严格遵守这里定义的原则。
使用 /speckit.constitution 命令创建项目的指导原则和开发指南, 这将指导所有后续开发.
java
/speckit.constitution 创建专注于代码质量、测试标准、用户体验一致性和性能要求的原则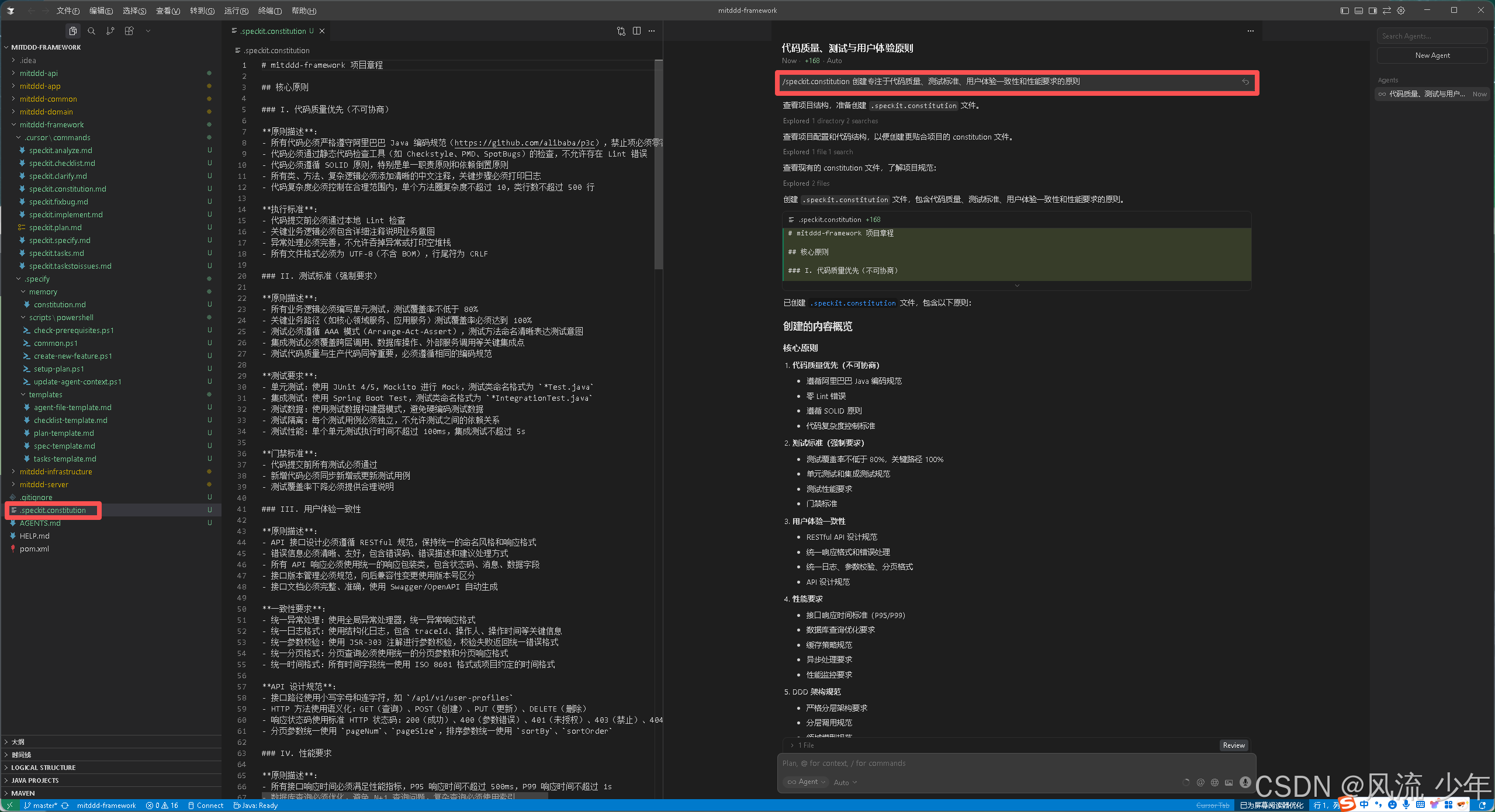
2. 创建规范,描述需求 (/speckit.specify)
使用 /speckit.specify 命令描述你想要构建的内容. 专注于做什么和为什么, 而不是技术栈.
java
/speckit.specify /speckit.specify 需要实现一个xxx功能,需求文档@prd/【PRD】xxxV1.0.md 对应图片在项目根目录的prd文件夹中- 产出物:新分支、需求目录、需求文档。
- 工作机制:
- 运行分支创建脚本:执行 .specify/scripts/bash/create-new-feature.sh --json "$ARGUMENTS",
创建新的 feature 分支并返回 JSON 格式的分支名和规范文件路径; - 加载规范模板:读取 .specify/templates/spec-template.md 了解必需的章节结构;
- 智能内容生成:将你的自然语言描述转换为结构化规范,替换模板中的占位符但保持顺序和标题;
- 规范文件写入:在新分支的指定路径创建完整的 spec.md 文件。
- 运行分支创建脚本:执行 .specify/scripts/bash/create-new-feature.sh --json "$ARGUMENTS",
- 关键设计:整个过程只需要运行一次创建脚本。脚本会自动处理 Git 分支切换和文件初始化,然后 AI 在此基础上填充具体内容。
3. 澄清需求 (/speckit.clarify)
使用 /speckit.plan 命令提供你的技术栈和架构选择. 澄清规范中不够明确的地方
java
#主动澄清需求
/speckit.clarify 将上面生成的需求文档理解有误的更正4. 创建技术实施计划 (/speckit.plan)
指定实现技术栈、框架和架构设计。
产出物:技术实现计划、技术调研、数据模型、API 契约、快速开始指南。
java
/speckit.plan 参考前后端约定的API@api/XXX.md ,生成技术实现计划5. 任务分解(/speckit.tasks)
使用 /speckit.tasks 从你的实施计划创建可操作的任务列表. 将实现计划分解为详细的可执行任务。
产出物:任务分解文档。
java
/speckit.tasks6. 代码实现,执行实施(/speckit.implement)
使用 /speckit.implement 执行所有任务并根据计划构建你的功能.
根据任务列表执行具体的代码实现建议:模型切换到 Claude 4.5 Sonnet 以获得更好的代码生成能力。
java
/speckit.implement 帮我实现XXX相关任务7. 修改需求 / 技术方案
注意:使用clarify/plan命令修改需求和技术方案,保持规范和代码的一致性
java
#修改需求
/speckit.clarify 修改需求,xxx,并修改对应的plan和task
java
/speckit.plan 修改的具体需求和方案,同时修改task8. 后端项目使用Spec Kit注意点
- 安全第一原则
- SQL注入防护:所有数据库操作必须使用参数化查询或ORM,禁止任何形式的字符串拼接SQL
- 越权访问防护:所有API接口必须在业务逻辑层显式进行权限校验
- 测试与质量门禁
- 单元测试:所有核心业务逻辑(Service/Manager层)必须包含单元测试,覆盖率不低于80%
- 自动化扫描:CI/CD流水线集成
- 静态代码安全扫描(如SonarQube)
- 依赖漏洞检查(如Dependabot)
- 数据一致性
- 事务边界:任何跨多个数据修改的操作必须在一个显式声明的事务内完成,确保ACID特性
四:Vibe和Spec的区别

