
前言
做 Web 自动化测试时,你是否遇到过这些崩溃瞬间:明明看到页面上的按钮,脚本却死活找不到;好不容易定位到元素,点击后却没反应;页面还没加载完成,代码就已经执行下一步导致报错;切换窗口后,脚本直接 "迷路" 找不到目标元素......
其实,自动化测试的核心就是 "和浏览器打交道",而 Selenium 提供的常用函数,就是你与浏览器沟通的 "语言"。就像学英语要先掌握核心词汇和句型,做自动化测试也必须吃透这些常用函数 ------ 它们是搭建自动化脚本的 "砖瓦",是解决实战问题的 "钥匙",更是从 "自动化新手" 进阶到 "测试高手" 的必经之路。
很多人之所以觉得自动化测试难,不是因为逻辑复杂,而是因为没理清常用函数的用法、场景和坑点。比如同样是 "等待",什么时候用强制等待,什么时候用显式等待?同样是 "获取文本",为什么有时候用
text方法拿不到值?同样是 "切换窗口",为什么切换后还是找不到元素?今天这篇文章,就带大家彻底吃透 Selenium 自动化测试的常用函数。我们以 Python 语言为基础,从元素定位、操作测试对象、窗口控制、弹窗处理、等待机制、浏览器导航、文件上传到浏览器参数设置,8 大核心模块逐一拆解,让你看完就能用,用了就见效!下面就让我们正式开始吧!
一、元素定位:自动化测试的 "找对象" 艺术
Web 自动化测试的第一步,也是最关键的一步,就是 "找到页面上的元素"------ 就像追求心仪的对象,首先得知道对方在哪里。Selenium 提供了多种元素定位方式,其中最常用、最稳定的就是**CSS Selector和XPath**。
1.1 核心定位方式:CSS Selector(推荐首选)
CSS Selector 是通过 CSS 选择器语法定位元素,优点是语法简洁、定位速度快、稳定性高,是企业实战中最常用的定位方式。
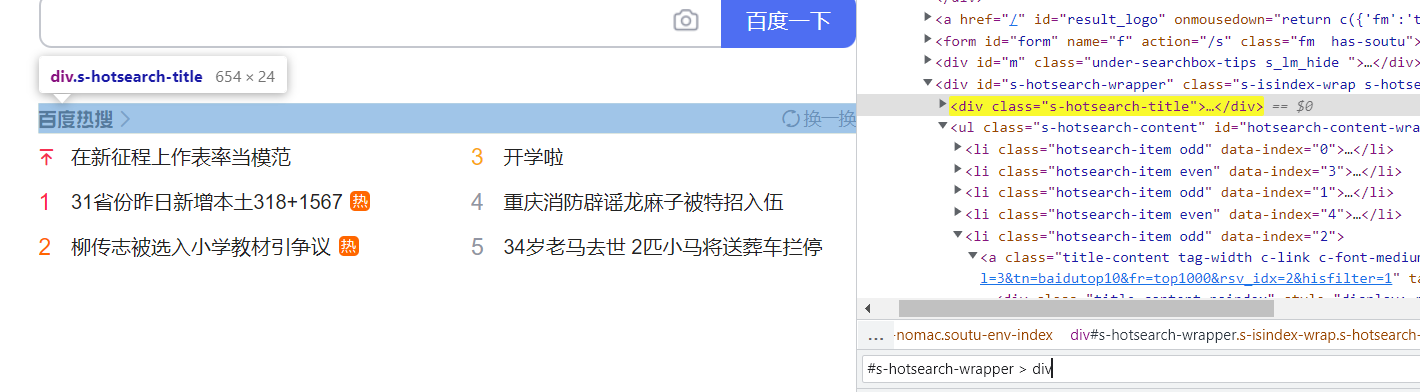
1.1.1 基础选择器
| 选择器类型 | 语法 | 示例 | 说明 |
|---|---|---|---|
| ID 选择器 | #id值 |
#kw |
定位 id 为 "kw" 的元素(如百度搜索框) |
| Class 选择器 | .class值 |
.s_ipt |
定位 class 为 "s_ipt" 的元素 |
| 标签选择器 | 标签名 |
input |
定位所有 input 标签的元素 |
| 子类选择器 | 父元素 > 子元素 |
#s-hotsearch-wrapper > div |
定位 id 为 "s-hotsearch-wrapper" 下的直接子 div 元素 |
1.1.2 实战案例:定位百度核心元素
python
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
# 初始化浏览器
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
driver.get("https://www.baidu.com")
# 1. 定位百度搜索框(id=kw)
search_input = driver.find_element(By.CSS_SELECTOR, "#kw")
print("成功定位搜索框")
# 2. 定位"百度一下"按钮(id=su)
search_btn = driver.find_element(By.CSS_SELECTOR, "#su")
print("成功定位百度一下按钮")
# 3. 定位百度热搜标题(class=s-hotsearch-title)
hotsearch_title = driver.find_element(By.CSS_SELECTOR, ".s-hotsearch-title")
print(f"百度热搜标题:{hotsearch_title.text}")
driver.quit()1.1.3 避坑指南
- 优先使用 ID 选择器:ID 在页面中通常是唯一的,定位最精准、最稳定;
- Class 选择器注意重复 :如果多个元素有相同的 class 值,
find_element会返回第一个匹配的元素,此时需要结合其他选择器优化;- 子类选择器只匹配直接子元素 :如果需要匹配子孙元素,用空格代替
>(如#s-hotsearch-wrapper div)。
1.2 万能定位方式:XPath(覆盖所有场景)
XPath 是 XML 路径语言,不仅能定位 HTML 元素,还能通过路径、属性、层级等多种方式定位,堪称 "万能定位器"。当 CSS Selector 无法满足需求时,XPath 总能派上用场。
1.2.1 核心语法(必背)
| 语法 | 功能 | 示例 |
|---|---|---|
| //* | 获取页面所有节点 | //* 定位页面所有元素 |
| //标签名 | 获取指定标签的所有节点 | //ul 定位所有 ul 标签元素 |
| / | 匹配直接子节点 | //span/input 定位 span 标签下的直接子 input 元素 |
| .. | 匹配父节点 | //input/.. 定位 input 元素的父节点 |
| [@属性名='属性值'] | 按属性匹配节点 | //*[@id='kw'] 定位 id 为 kw 的元素 |
| [索引] | 按索引匹配节点 | //div/ul/li[3] 定位第 3 个 li 元素(索引从 1 开始) |
1.2.2 实战案例:百度热搜元素定位
python
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
driver.get("https://www.baidu.com")
# 1. 按ID定位搜索框
search_input = driver.find_element(By.XPATH, "//*[@id='kw']")
search_input.send_keys("自动化测试常用函数")
# 2. 按索引定位第2个热搜词条
second_hotsearch = driver.find_element(By.XPATH, "//div[@id='hotsearch-content-wrapper']/li[2]/a/span[2]")
print(f"第2个热搜词条:{second_hotsearch.text}")
# 3. 定位父节点(搜索框的父div)
search_input_parent = driver.find_element(By.XPATH, "//*[@id='kw']/..")
print(f"搜索框父节点标签名:{search_input_parent.tag_name}")
driver.quit()1.2.3 高效技巧:复制 Selector/XPath
新手不用死记硬背语法,Chrome 浏览器提供了快速复制功能:
- 打开页面,按 F12 打开开发者工具;
- 在 Elements 面板中找到目标元素,右键点击;
- 选择 "Copy" -> "Copy selector"(复制 CSS 选择器)或 "Copy XPath"(复制 XPath)。
1.2.4 避坑指南
- 复制的表达式可能不唯一:自动复制的 Selector/XPath 可能会包含动态属性(如随机生成的 class 值),或匹配多个元素,需要手动优化;
- 索引从 1 开始:XPath 的索引是 1-based,而不是 Python 的 0-based,避免因索引错误导致定位失败;
- 避免过度使用 XPath:XPath 定位速度比 CSS Selector 慢,优先用 CSS Selector,XPath 作为补充。
1.3 定位方法总结
| 定位方式 | 语法 | 优点 | 缺点 |
|---|---|---|---|
| CSS Selector | By.CSS_SELECTOR, "选择器" |
速度快、语法简洁、稳定 | 部分复杂场景支持不足 |
| XPath | By.XPATH, "路径表达式" |
功能强大、覆盖所有场景 | 速度较慢、语法复杂 |
实战建议:90% 的场景用 CSS Selector,10% 的复杂场景(如定位父节点、按文本匹配)用 XPath。
二、操作测试对象:对元素 "为所欲为"
找到元素后,下一步就是对元素进行操作 ------ 输入文本、点击按钮、获取信息等。这部分函数是自动化脚本的核心,必须熟练掌握。
2.1 点击操作:click()(最常用)
模拟用户点击元素,适用于按钮、链接、复选框等可点击元素。
功能说明
- 语法 :element.click()
- 适用场景:按钮点击、链接跳转、复选框勾选等。
实战代码
python
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
driver.get("https://www.baidu.com")
# 定位并点击"百度一下"按钮
search_btn = driver.find_element(By.CSS_SELECTOR, "#su")
search_btn.click()
print("成功点击百度一下按钮")
driver.quit()避坑指南
- 元素必须可见且可点击 :如果元素被遮挡、隐藏或禁用,调用
click()会报错;- 先等待元素加载完成:页面未加载完时,元素可能未渲染,需结合等待机制(后续讲解)。
2.2 输入文本:send_keys()(核心输入函数)
模拟用户在输入框中输入文本,支持字符串、键盘按键(如回车、空格)。
功能说明
- 语法 :element.send_keys("文本内容")
- 适用场景:输入框、文本域等可输入元素。
实战代码
python
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
driver.get("https://www.baidu.com")
# 定位搜索框并输入文本
search_input = driver.find_element(By.CSS_SELECTOR, "#kw")
search_input.send_keys("Selenium常用函数")
print("成功输入搜索关键词")
driver.quit()进阶用法:输入键盘按键
python
# 导入键盘按键模块
from selenium.webdriver.common.keys import Keys
# 输入文本后按回车(替代点击搜索按钮)
search_input.send_keys("Selenium常用函数", Keys.ENTER)2.3 清除文本:clear()(输入前必做)
清除输入框中的已有文本,避免旧文本影响测试结果。
功能说明
- 语法 :element.clear()
- 适用场景:重新输入文本前,清除输入框原有内容。
实战代码
python
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
import time
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
driver.get("https://www.baidu.com")
search_input = driver.find_element(By.CSS_SELECTOR, "#kw")
# 输入第一个关键词
search_input.send_keys("迪丽热巴")
time.sleep(1) # 等待1秒,便于观察
print("第一次输入:迪丽热巴")
# 清除文本
search_input.clear()
time.sleep(1)
print("已清除文本")
# 输入第二个关键词
search_input.send_keys("古力娜扎")
print("第二次输入:古力娜扎")
driver.quit()避坑指南
- 只适用于可输入元素 :对按钮、链接等元素调用
clear()会报错;- 清除不彻底时的解决方案 :如果
clear()未清除干净,可先按Ctrl+A全选再删除。
2.4 获取文本:text(验证结果核心)
获取元素的文本内容,用于验证测试结果是否符合预期。
功能说明
- 语法 :
element.text(注意:是属性,不是方法,无需加括号)- 适用场景:获取标签内的文本(如标题、词条、提示信息)。
实战代码
python
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
driver.get("https://www.baidu.com")
# 获取百度热搜第一个词条的文本
first_hotsearch = driver.find_element(By.XPATH, "//*[@id='hotsearch-content-wrapper']/li[1]/a/span[2]")
hotsearch_text = first_hotsearch.text
print(f"百度热搜第一名:{hotsearch_text}")
# 验证结果(断言)
assert "热搜" in hotsearch_text, "测试失败:热搜词条不包含关键词"
print("测试通过:热搜词条符合预期")
driver.quit()关键问题:为什么text拿不到 "百度一下" 按钮的文字?
很多新手会疑惑:"百度一下" 按钮上明明有文字,为什么用element.text获取到的是空字符串?
答案 :text方法只能获取元素 "标签内的文本",而 "百度一下" 按钮的文字是通过value属性设置的(HTML 代码:<input type="submit" id="su" value="百度一下">),并非标签内的文本。
解决方案:获取属性值get_attribute()
要获取元素的属性值(如value、href、src),需要使用**get_attribute("属性名")**方法。
python
# 获取"百度一下"按钮的value属性值
search_btn = driver.find_element(By.CSS_SELECTOR, "#su")
btn_text = search_btn.get_attribute("value")
print(f"按钮文字:{btn_text}") # 输出:百度一下常见属性获取示例
python
# 获取链接的href属性(跳转地址)
link = driver.find_element(By.XPATH, "//a[text()='新闻']")
link_url = link.get_attribute("href")
print(f"新闻链接:{link_url}")
# 获取图片的src属性(图片地址)
img = driver.find_element(By.CSS_SELECTOR, ".index-logo-src")
img_src = img.get_attribute("src")
print(f"百度Logo地址:{img_src}")2.5 获取页面信息:title和current_url
在自动化测试中,经常需要验证是否跳转到了正确的页面,此时就需要获取当前页面的标题和 URL。
2.5.1 获取页面标题:driver.title
- 语法 :driver.title(属性,无需括号)
- 功能 :获取当前页面的标题(
<title>标签内容)。
2.5.2 获取当前 URL:driver.current_url
- 语法 :driver.current_url(属性,无需括号)
- 功能:获取当前页面的 URL 地址。
实战代码:验证页面跳转
python
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
driver.get("https://www.baidu.com")
# 1. 获取首页标题和URL
home_title = driver.title
home_url = driver.current_url
print(f"首页标题:{home_title}")
print(f"首页URL:{home_url}")
# 2. 搜索后验证跳转
search_input = driver.find_element(By.CSS_SELECTOR, "#kw")
search_input.send_keys("Selenium")
driver.find_element(By.CSS_SELECTOR, "#su").click()
# 3. 获取搜索结果页的标题和URL
result_title = driver.title
result_url = driver.current_url
print(f"搜索结果页标题:{result_title}")
print(f"搜索结果页URL:{result_url}")
# 4. 断言验证
assert "Selenium" in result_title, "测试失败:页面标题不包含关键词"
assert "wd=Selenium" in result_url, "测试失败:URL不包含搜索关键词"
print("测试通过:页面跳转符合预期")
driver.quit()2.6 操作测试对象函数总结
| 函数 / 属性 | 语法 | 功能 | 适用场景 |
|---|---|---|---|
| 点击 | element.click() | 模拟用户点击 | 按钮、链接、复选框 |
| 输入文本 | element.send_keys("文本") | 模拟输入文本 | 输入框、文本域 |
| 清除文本 | element.clear() | 清除输入框内容 | 输入框重新输入时 |
| 获取文本 | element.text | 获取元素标签内文本 | 标题、词条、提示信息 |
| 获取属性 | element.get_attribute("属性名") | 获取元素属性值 | value、href、src 等 |
| 获取页面标题 | driver.title | 获取当前页面标题 | 验证页面跳转 |
| 获取当前 URL | driver.current_url | 获取当前页面 URL | 验证页面跳转 |
三、窗口控制:玩转浏览器的 "多窗口"
在自动化测试中,经常会遇到打开新窗口的场景(如点击链接弹出新页面)。此时脚本会默认停留在原窗口,导致无法操作新窗口的元素,这就需要通过 "窗口句柄" 来切换窗口。
3.1 核心概念:窗口句柄(handle)
每个浏览器窗口都有一个唯一的标识符,称为**"窗口句柄"(handle)**。Selenium 通过句柄来区分不同的窗口,实现窗口切换。
- 当前窗口句柄 :driver.current_window_handle(返回当前聚焦窗口的句柄)
- 所有窗口句柄 :driver.window_handles(返回所有已打开窗口的句柄列表,顺序为窗口打开顺序)
3.2 切换窗口:switch_to.window()
功能说明
- 语法 :driver.switch_to.window(目标窗口句柄)
- 功能:将脚本的聚焦切换到指定句柄的窗口。
实战代码:切换到新打开的窗口
python
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
driver.get("https://www.baidu.com")
# 1. 获取原窗口句柄
original_handle = driver.current_window_handle
print(f"原窗口句柄:{original_handle}")
# 2. 点击"新闻"链接,打开新窗口
news_link = driver.find_element(By.XPATH, "//a[text()='新闻']")
news_link.click()
# 3. 获取所有窗口句柄
all_handles = driver.window_handles
print(f"所有窗口句柄:{all_handles}")
# 4. 切换到新窗口(遍历所有句柄,找到非原窗口的句柄)
for handle in all_handles:
if handle != original_handle:
driver.switch_to.window(handle)
break
# 5. 操作新窗口(验证新闻页面标题)
news_title = driver.title
print(f"新窗口(新闻页)标题:{news_title}")
assert "百度新闻" in news_title, "测试失败:未成功切换到新闻窗口"
print("测试通过:成功切换到新窗口")
# 6. 切换回原窗口(可选)
driver.switch_to.window(original_handle)
print(f"切换回原窗口,标题:{driver.title}")
driver.quit()避坑指南
- 切换窗口前先等待新窗口打开:点击链接后,新窗口可能需要时间加载,需结合等待机制;
- 关闭窗口前切换句柄:如果要关闭某个窗口,需先切换到该窗口,否则可能关闭错误的窗口;
- 句柄是动态的:每次运行脚本,窗口句柄都会变化,不能硬编码句柄值。
3.3 窗口大小设置:自定义浏览器窗口
Selenium 提供了多种窗口大小控制函数,满足不同测试场景需求。
3.3.1 常用函数
| 函数 | 语法 | 功能 |
|---|---|---|
| 窗口最大化 | driver.maximize_window() | 模拟用户点击窗口最大化按钮 |
| 窗口最小化 | driver.minimize_window() | 模拟用户点击窗口最小化按钮 |
| 窗口全屏 | driver.fullscreen_window() | 模拟用户按 F11 进入全屏模式 |
| 自定义窗口大小 | driver.set_window_size(宽度, 高度) | 设置窗口为指定尺寸(像素) |
实战代码
python
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
import time
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
driver.get("https://www.baidu.com")
# 1. 窗口最大化
driver.maximize_window()
print("窗口已最大化")
time.sleep(2)
# 2. 自定义窗口大小(1024x768)
driver.set_window_size(1024, 768)
print("窗口大小设置为1024x768")
time.sleep(2)
# 3. 窗口全屏
driver.fullscreen_window()
print("窗口已全屏")
time.sleep(2)
# 4. 窗口最小化
driver.minimize_window()
print("窗口已最小化")
time.sleep(2)
driver.quit()实战建议
- 测试开始时最大化窗口:避免元素因窗口尺寸过小被遮挡,提高脚本稳定性;
- 移动端测试用自定义尺寸 :模拟手机屏幕尺寸(如
set_window_size(375, 667)模拟 iPhone 8)。
3.4 屏幕截图:save_screenshot()(调试 / 报错必备)
自动化脚本通常在后台运行,当脚本报错时,无法直接看到当时的页面状态。屏幕截图功能可以记录报错瞬间的页面,帮助快速定位问题。
功能说明
- 语法 :driver.save_screenshot("截图路径")
- 功能:对当前窗口进行截图,保存为图片文件(支持 png 格式)。
实战代码:基础版截图
python
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
driver.get("https://www.baidu.com")
# 截图并保存到指定路径(相对路径或绝对路径均可)
driver.save_screenshot("./screenshots/baidu_home.png")
print("截图已保存到 ./screenshots/baidu_home.png")
driver.quit()进阶版:按时间命名截图(避免覆盖)
python
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
import datetime
import os
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
driver.get("https://www.baidu.com")
# 1. 创建截图目录(如果不存在)
screenshot_dir = "./screenshots"
if not os.path.exists(screenshot_dir):
os.makedirs(screenshot_dir)
# 2. 按时间生成截图文件名(格式:年-月-日-时-分-秒.png)
current_time = datetime.datetime.now().strftime("%Y-%m-%d-%H%M%S")
screenshot_path = f"{screenshot_dir}/autotest-{current_time}.png"
# 3. 截图并保存
driver.save_screenshot(screenshot_path)
print(f"截图已保存到:{screenshot_path}")
driver.quit()实战建议
- 报错时自动截图 :在try-except异常捕获中添加截图代码,报错时自动记录状态;
- 合理命名截图:包含时间、模块、场景等信息,便于后续查找。
3.5 关闭窗口:close() vs quit()
很多新手会混淆这两个关闭函数,其实它们的功能差异很大:
| 函数 | 语法 | 功能 | 适用场景 |
|---|---|---|---|
| close() | driver.close() | 关闭当前聚焦的窗口 | 只关闭单个窗口,其他窗口保持打开 |
| quit() | driver.quit() | 关闭所有浏览器窗口,终止驱动进程 | 脚本执行完毕,彻底退出浏览器 |
实战代码:关闭窗口示例
python
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
driver.get("https://www.baidu.com")
# 打开新窗口
driver.find_element(By.XPATH, "//a[text()='新闻']").click()
all_handles = driver.window_handles
# 切换到新窗口并关闭
driver.switch_to.window(all_handles[1])
driver.close()
print("已关闭新闻窗口")
# 切换回原窗口,继续操作
driver.switch_to.window(all_handles[0])
print(f"当前窗口标题:{driver.title}")
# 脚本结束,关闭所有窗口
driver.quit()避坑指南
- 关闭窗口后需切换句柄:如果关闭的是当前聚焦窗口,后续操作前需切换到其他已打开的窗口;
- 脚本结束必用
quit():quit()会释放驱动进程,避免占用系统资源;如果只用close(),驱动进程可能残留。
四、弹窗处理:搞定 "难缠" 的系统弹窗
Web 页面中常见的弹窗有 3 种:警告弹窗、确认弹窗、提示弹窗。这些弹窗是浏览器自带的,并非 HTML 元素,无法通过常规元素定位方式操作,需要使用 Selenium 的Alert接口处理。
4.1 核心方法:switch_to.alert
首先需要将脚本聚焦到弹窗上,语法:alert = driver.switch_to.alert(Python 中是switch_to.alert,注意大小写)。
获取到alert对象后,可使用以下方法操作弹窗:
| 方法 | 功能 | 适用弹窗类型 |
|---|---|---|
| accept() | 点击 "确定" 按钮 | 所有弹窗 |
| dismiss() | 点击 "取消" 按钮 | 确认弹窗、提示弹窗 |
| send_keys("文本") | 输入文本 | 提示弹窗(带输入框的弹窗) |
4.2 警告弹窗(Alert)

特点
- 只有 "确定" 按钮,无取消按钮,无法输入文本;
- 示例:页面弹出 "操作成功!" 提示,需点击确定关闭。
实战代码
python
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
# 本地HTML文件(含警告弹窗)
html_path = "file:///D:/test/alert_test.html"
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
driver.get(html_path)
# 点击按钮触发警告弹窗
driver.find_element(By.CSS_SELECTOR, "#alertBtn").click()
# 切换到弹窗并点击确定
alert = driver.switch_to.alert
print(f"弹窗提示内容:{alert.text}") # 获取弹窗文本
alert.accept()
print("已关闭警告弹窗")
driver.quit()4.3 确认弹窗(Confirm)
特点
- 有 "确定" 和 "取消" 两个按钮,无法输入文本;
- 示例:删除数据时弹出 "确定要删除吗?",需选择确定或取消。
实战代码
python
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
html_path = "file:///D:/test/confirm_test.html"
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
driver.get(html_path)
# 点击按钮触发确认弹窗
driver.find_element(By.CSS_SELECTOR, "#confirmBtn").click()
# 切换到弹窗
alert = driver.switch_to.alert
print(f"弹窗提示内容:{alert.text}")
# 点击取消按钮(点击确定用 alert.accept())
alert.dismiss()
print("已点击取消按钮")
driver.quit()4.4 提示弹窗(Prompt)
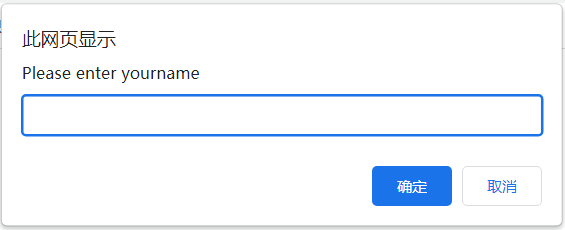
特点
- 有 "确定" 和 "取消" 按钮,且带有输入框,可输入文本;
- 示例:弹出 "请输入您的姓名",需输入文本后点击确定。
实战代码
python
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
html_path = "file:///D:/test/prompt_test.html"
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
driver.get(html_path)
# 点击按钮触发提示弹窗
driver.find_element(By.CSS_SELECTOR, "#promptBtn").click()
# 切换到弹窗
alert = driver.switch_to.alert
print(f"弹窗提示内容:{alert.text}")
# 输入文本并点击确定
alert.send_keys("自动化测试工程师")
alert.accept()
print("已输入文本并点击确定")
driver.quit()4.5 避坑指南
- 先触发弹窗再切换 :必须先通过操作触发弹窗,再调用
switch_to.alert,否则会报错;- 弹窗处理后需切换回页面:处理完弹窗后,脚本会自动聚焦回原页面,无需额外切换;
- 避免多个弹窗叠加:如果页面连续弹出多个弹窗,需逐个处理,避免混淆。
五、等待机制:解决 "页面加载慢" 的核心方案
自动化脚本执行速度远快于页面渲染速度 ------ 如果脚本执行到某个步骤时,页面元素还未加载完成,就会导致元素定位失败,脚本报错。等待机制就是为了解决这个问题,让脚本 "等待" 页面加载完成后再执行下一步。
Selenium 提供 3 种等待方式:强制等待、隐式等待、显式等待。
5.1 强制等待:time.sleep(秒数)(最简单)
功能说明
- 语法:import time; time.sleep(5)
- 功能:让脚本暂停指定秒数,无论页面是否加载完成,时间到后继续执行。
实战代码
python
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
import time
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
driver.get("https://www.baidu.com")
# 强制等待3秒(模拟页面加载)
time.sleep(3)
# 定位元素
search_input = driver.find_element(By.CSS_SELECTOR, "#kw")
search_input.send_keys("强制等待")
print("输入成功")
driver.quit()优缺点
- 优点:语法简单,调试时使用方便;
- 缺点:浪费时间(即使页面提前加载完成,也需等待指定时间)、不稳定(网络波动时,等待时间可能不足或过长)。
适用场景
- 脚本调试阶段:快速验证代码逻辑;
- 短时间等待:如输入文本后等待 1 秒观察效果。
5.2 隐式等待:implicitly_wait(秒数)(全局智能等待)
功能说明
- 语法:driver.implicitly_wait(10)
- 功能:设置全局等待时间,在指定时间内,脚本会不断尝试定位元素;如果在超时前找到元素,立即继续执行;如果超时未找到,报错。
实战代码
python
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
# 设置隐式等待10秒(作用于整个脚本)
driver.implicitly_wait(10)
driver.get("https://www.baidu.com")
# 无需额外等待,脚本会自动等待元素加载完成
search_input = driver.find_element(By.CSS_SELECTOR, "#kw")
search_input.send_keys("隐式等待")
print("输入成功")
driver.quit()核心特点
- 全局生效:只要
driver对象未被quit(),隐式等待就对所有元素定位生效;- 智能等待:只等待元素加载完成,不浪费额外时间;
- 只等待元素存在:只要元素在 DOM 中存在,就认为加载完成,不关心元素是否可见或可点击。
优缺点
- 优点:使用简单、智能高效、全局生效;
- 缺点:无法精确控制单个元素的等待条件(如等待元素可见、可点击)。
适用场景
- 大部分基础测试场景:页面元素加载稳定,无需复杂条件判断。
5.3 显式等待:WebDriverWait(精准智能等待)
功能说明
- 语法:WebDriverWait(driver, 超时时间).until(等待条件)
- 功能:针对单个元素,设置自定义等待条件和超时时间;在超时时间内,每隔一定时间(默认 0.5 秒)检查一次条件是否满足;满足则继续执行,超时未满足则报错。
核心依赖
需要导入以下模块:
python
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC常用等待条件(expected_conditions)
| 条件 | 说明 | 示例 |
|---|---|---|
| EC.presence_of_element_located((定位方式, 定位值)) | 元素存在于 DOM 中 | 等待搜索框存在 |
| EC.visibility_of_element_located((定位方式, 定位值)) | 元素可见(存在且未隐藏) | 等待按钮可见 |
| EC.element_to_be_clickable((定位方式, 定位值)) | 元素可点击 | 等待按钮可点击 |
| EC.title_contains("关键词") | 页面标题包含关键词 | 等待页面标题包含 "百度" |
| EC.alert_is_present() | 弹窗出现 | 等待弹窗弹出 |
实战代码
python
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
driver.get("https://www.baidu.com")
# 显式等待:等待搜索框可见(最多等待10秒,每0.5秒检查一次)
wait = WebDriverWait(driver, 10)
search_input = wait.until(
EC.visibility_of_element_located((By.CSS_SELECTOR, "#kw"))
)
# 输入文本
search_input.send_keys("显式等待")
print("输入成功")
# 显式等待:等待"百度一下"按钮可点击,并点击
search_btn = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, "#su"))
)
search_btn.click()
driver.quit()优缺点
- 优点:精准控制、条件灵活、稳定性最高;
- 缺点:语法复杂、需要导入额外模块、代码量增加。
适用场景
- 复杂测试场景:如动态加载元素、需要等待元素可点击 / 可见;
- 稳定性要求高的脚本:如自动化回归测试脚本。
5.4 关键结论:不要混合使用隐式等待和显式等待
很多新人或许会觉得 "多等总比少等好",同时设置隐式等待和显式等待,但这样会导致等待时间不可预测。
实验验证
python
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
# 隐式等待10秒
driver.implicitly_wait(10)
# 显式等待15秒
wait = WebDriverWait(driver, 15)
start_time = time.time()
try:
# 定位一个不存在的元素
wait.until(EC.presence_of_element_located((By.ID, "nonexistent-element")))
except Exception as e:
end_time = time.time()
print(f"报错时间:{end_time - start_time:.2f}秒") # 输出约20秒(10+15)
driver.quit()原因
隐式等待和显式等待的等待时间会叠加,导致实际等待时间远超预期,影响脚本执行效率。
实战建议
- 调试阶段:用强制等待(
time.sleep);- 简单场景:用隐式等待(
implicitly_wait);- 复杂场景:用显式等待(
WebDriverWait);- 禁止同时使用隐式等待和显式等待。
六、浏览器导航:模拟用户的 "前进后退"
Selenium 提供了模拟浏览器导航栏操作的函数,如打开网页、前进、后退、刷新等,完美复刻用户的浏览器操作。
6.1 打开网页:driver.get("URL")(最基础)
- 语法:driver.get("https://www.baidu.com")
- 功能:打开指定 URL 的网页,等待页面加载完成后继续执行。
6.2 前进:driver.forward()
- 语法:driver.forward()
- 功能:模拟浏览器的 "前进" 按钮,跳转到下一个页面(需先执行过后退操作)。
6.3 后退:driver.back()
- 语法:driver.back()
- 功能:模拟浏览器的 "后退" 按钮,返回上一个页面。
6.4 刷新:driver.refresh()
- 语法:driver.refresh()
- 功能:模拟浏览器的 "刷新" 按钮,重新加载当前页面。
实战代码:导航操作组合
python
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
import time
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
# 1. 打开百度首页
driver.get("https://www.baidu.com")
print(f"当前页面:{driver.title}")
time.sleep(2)
# 2. 搜索关键词,跳转到结果页
driver.find_element(By.CSS_SELECTOR, "#kw").send_keys("浏览器导航")
driver.find_element(By.CSS_SELECTOR, "#su").click()
print(f"搜索后页面:{driver.title}")
time.sleep(2)
# 3. 后退到百度首页
driver.back()
print(f"后退后页面:{driver.title}")
time.sleep(2)
# 4. 前进到搜索结果页
driver.forward()
print(f"前进后页面:{driver.title}")
time.sleep(2)
# 5. 刷新当前页面
driver.refresh()
print("页面已刷新")
time.sleep(2)
driver.quit()避坑指南
- 前进后退依赖浏览历史:只有当浏览器有前进 / 后退的历史记录时,
forward()和back()才有效;- 刷新后元素需重新定位:页面刷新后,之前定位的元素对象会失效,需重新定位。
七、文件上传:绕开 "系统窗口" 的陷阱
文件上传是自动化测试中的常见场景,但上传文件时会弹出系统自带的文件选择窗口 ------Selenium 无法识别系统窗口,此时需要用**send_keys()**函数绕开系统窗口,直接上传文件。
7.1 核心原理
文件上传的本质是向**类型的元素传递文件路径。Selenium 的send_keys()**函数可以直接向该元素传入文件的绝对路径,从而实现文件上传,无需操作系统窗口。
7.2 实战代码
python
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
# 打开本地文件上传测试页面
driver.get("file:///D:/test/upload.html")
# 定位<input type="file">元素
upload_input = driver.find_element(By.CSS_SELECTOR, "input[type='file']")
# 传入文件绝对路径(注意:Windows系统用双反斜杠\\,Linux/Mac用斜杠/)
file_path = "D:\\test\\test_file.txt"
upload_input.send_keys(file_path)
print(f"已上传文件:{file_path}")
driver.quit()7.3 避坑指南
- 必须定位到
<input type="file">元素 :该元素可能被隐藏(通过 CSS 设置display:none),需先让元素可见(如通过 JS 修改样式);- 传入绝对路径:必须使用文件的绝对路径,相对路径可能导致上传失败;
- 路径分隔符 :Windows 系统用
\\(避免转义),Linux/Mac 系统用/。
进阶:处理隐藏的上传元素
如果上传元素被隐藏,可通过执行 JavaScript 代码让元素可见:
python
# 定位隐藏的上传元素
upload_input = driver.find_element(By.CSS_SELECTOR, "input[type='file']")
# 执行JS代码,让元素可见
driver.execute_script("arguments[0].style.display = 'block';", upload_input)
# 上传文件
upload_input.send_keys("D:\\test\\test_file.txt")八、浏览器参数设置:定制化你的测试环境
Selenium 支持通过ChromeOptions(Chrome 浏览器)设置浏览器启动参数,如无头模式、页面加载策略、禁用缓存等,满足不同测试场景需求。
8.1 核心用法
python
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
# 创建ChromeOptions对象
options = webdriver.ChromeOptions()
# 添加启动参数
options.add_argument("参数名")
# 初始化浏览器时传入options
driver = webdriver.Chrome(
service=ChromeService(ChromeDriverManager().install()),
options=options
)8.2 常用参数详解
8.2.1 无头模式(Headless):无界面运行浏览器
- 参数:options.add_argument("--headless=new")(Chrome 112 + 版本推荐)
- 功能:浏览器在后台无界面运行,不显示窗口,节省系统资源。
实战代码
python
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
options = webdriver.ChromeOptions()
# 启用无头模式
options.add_argument("--headless=new")
driver = webdriver.Chrome(
service=ChromeService(ChromeDriverManager().install()),
options=options
)
driver.get("https://www.baidu.com")
print(f"页面标题:{driver.title}") # 正常输出标题,无浏览器窗口显示
driver.quit()适用场景
- 服务器端运行脚本(如 Jenkins、Linux 服务器,无图形界面);
- 批量执行脚本,无需观察执行过程。
8.2.2 页面加载策略:控制页面加载完成的条件
- 语法:options.page_load_strategy = "策略名称"
- 三种策略:
| 策略 | 说明 | 适用场景 |
|---|---|---|
| normal | 默认值,等待所有资源(图片、JS、CSS)加载完成 | 需要完整页面交互 |
| eager | DOM 加载完成后即可执行脚本,无需等待图片等资源 | 只操作 DOM 元素,不关心图片 |
| none | 不等待页面加载完成,立即执行后续脚本 | 快速获取页面信息,无需交互 |
实战代码
python
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
options = webdriver.ChromeOptions()
# 设置页面加载策略为eager(DOM就绪即可)
options.page_load_strategy = "eager"
driver = webdriver.Chrome(
service=ChromeService(ChromeDriverManager().install()),
options=options
)
driver.get("https://www.baidu.com")
print(f"页面标题:{driver.title}")
driver.quit()8.2.3 其他常用参数
| 参数 | 功能 | 代码示例 |
|---|---|---|
| 禁用缓存 | 禁止浏览器缓存,避免缓存影响测试 | options.add_argument("--disable-cache") |
| 禁用 JavaScript | 禁用页面 JS 执行 | options.add_argument("--disable-javascript") |
| 模拟手机设备 | 模拟指定手机型号(如 iPhone 12) | options.add_experimental_option("mobileEmulation", {"deviceName": "iPhone 12"}) |
| 忽略证书错误 | 忽略 HTTPS 证书错误 | options.add_argument("--ignore-certificate-errors") |
8.3 实战案例:模拟手机访问百度
python
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
options = webdriver.ChromeOptions()
# 模拟iPhone 12访问
options.add_experimental_option(
"mobileEmulation",
{"deviceName": "iPhone 12"}
)
driver = webdriver.Chrome(
service=ChromeService(ChromeDriverManager().install()),
options=options
)
driver.get("https://www.baidu.com")
print(f"手机端页面标题:{driver.title}")
driver.save_screenshot("./mobile_baidu.png")
print("手机端截图已保存")
driver.quit()总结
掌握 Selenium 常用函数的关键,不是死记硬背,而是理解 "什么时候用、怎么用、怎么避坑"。
自动化测试的本质是 "用代码解决重复工作",而常用函数就是实现这个目标的 "工具库"。希望这篇文章能帮你彻底吃透 Selenium 常用函数,让你在自动化测试的路上少走弯路,快速从新手进阶为高手!
如果在实际使用中遇到具体问题(如元素定位失败、弹窗处理不了、文件上传报错),欢迎在评论区留言,我们一起交流探讨!