1 算法简介
BERT的全称为Bidirectional Encoder Representation from Transformers,是一个预训练的语言表征模型。它强调了不再像以往一样采用传统的单向语言模型或者把两个单向语言模型进行浅层拼接的方法进行预训练,而是采用新的masked language model(MLM),以致能生成深度的双向语言表征。
该模型有以下主要特点:
1)采用MLM对双向的Transformers进行预训练,以生成深层的双向语言表征。
2)预训练后,只需要添加一个额外的输出层进行fine-tune,就可以在各种各样的下游任务中取得state-of-the-art的表现。在这过程中并不需要对BERT进行任务特定的结构修改。
2 算法原理
BERT的输入为每一个token对应的表征*(图中的粉红色块就是token,黄色块就是token对应的表征)*,并且单词字典是采用WordPiece算法来进行构建的。为了完成具体的分类任务,除了单词的token之外,作者还在输入的每一个序列开头都插入特定的分类token(CLS),该分类token对应的最后一个Transformer层输出被用来起到聚集整个序列表征信息的作用。
由于BERT是一个预训练模型,其必须要适应各种各样的自然语言任务,因此模型所输入的序列必须有能力包含一句话*(文本情感分类,序列标注任务)* 或者两句话以上*(文本摘要,自然语言推断,问答任务)*。那么如何令模型有能力去分辨哪个范围是属于句子A,哪个范围是属于句子B呢?BERT采用了两种方法去解决:
1)在序列tokens中把分割token(SEP)插入到每个句子后,以分开不同的句子tokens。
2)为每一个token表征都添加一个可学习的分割embedding来指示其属于句子A还是句子B。
因此最后模型的输入序列tokens为下图*(如果输入序列只包含一个句子的话,则没有SEP及之后的token)*:
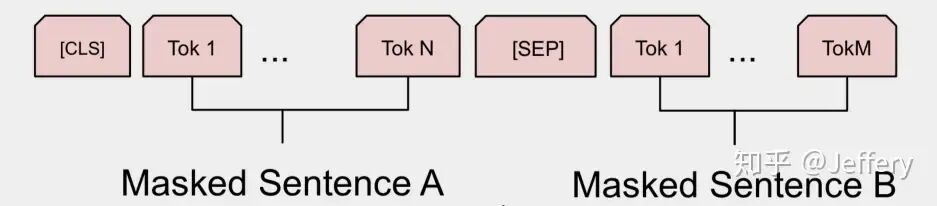
模型的输入序列
上面提到了BERT的输入为每一个token对应的表征,实际上该表征是由三部分组成的,分别是对应的token,分割和位置 embeddings,如下图:
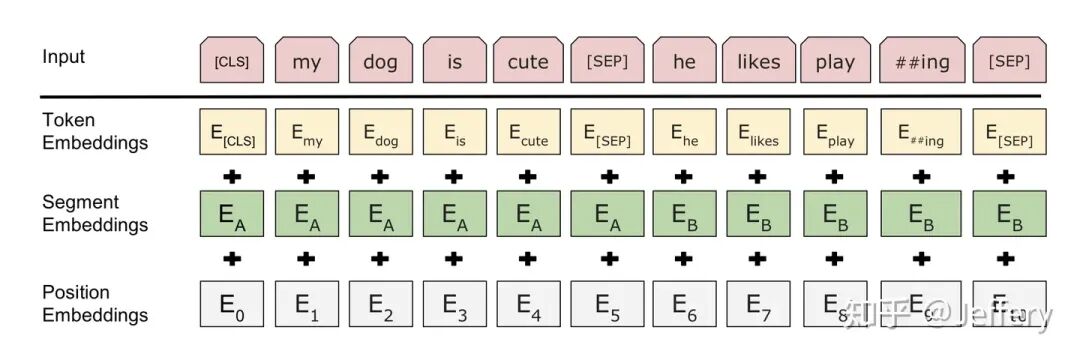
token表征的组成
到此为止,BERT的输入已经介绍完毕,可以看到其设计的思路十分简洁而且有效。
介绍完BERT的输入,实际上BERT的输出也就呼之欲出了,因为Transformer的特点就是有多少个输入就有多少个对应的输出,如下图:

BERT的输出
C为分类token(CLS)对应最后一个Transformer的输出,Ti则代表其他token对应最后一个Transformer的输出。对于一些token级别的任务(如,序列标注和问答任务),就把Ti输入到额外的输出层中进行预测。对于一些句子级别的任务(如,自然语言推断和情感分类任务),就把C输入到额外的输出层中,这里也就解释了为什么要在每一个token序列前都要插入特定的分类token。
3 算法应用
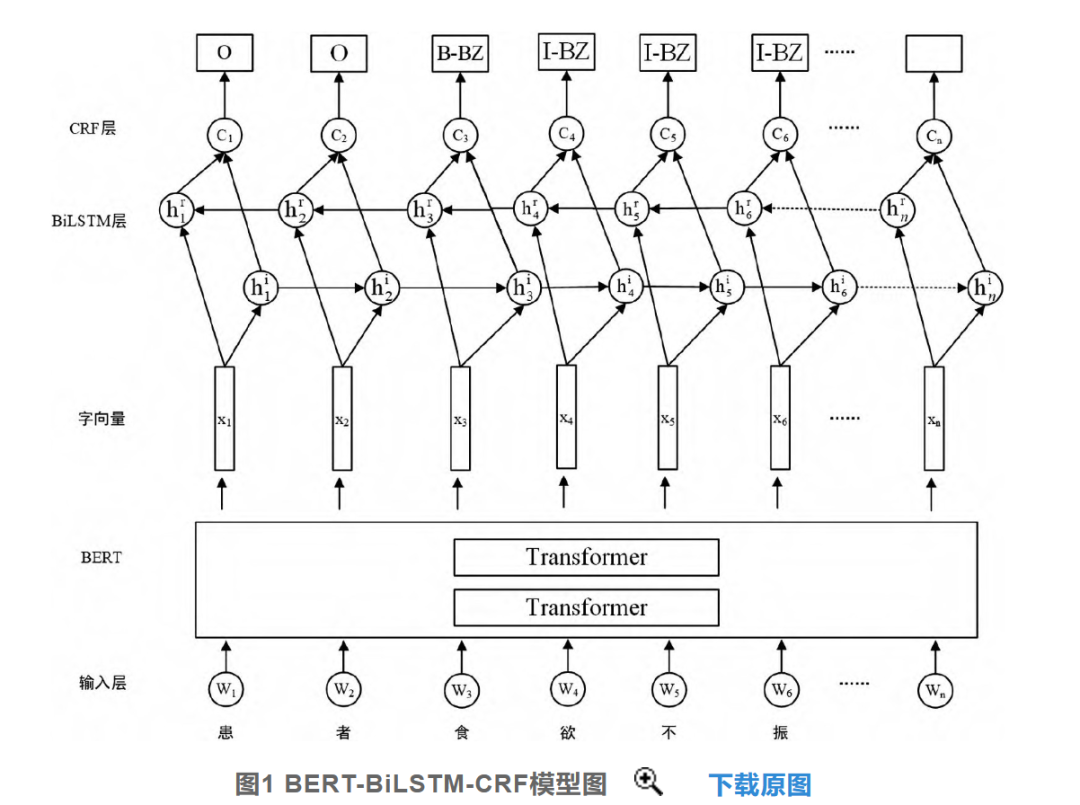
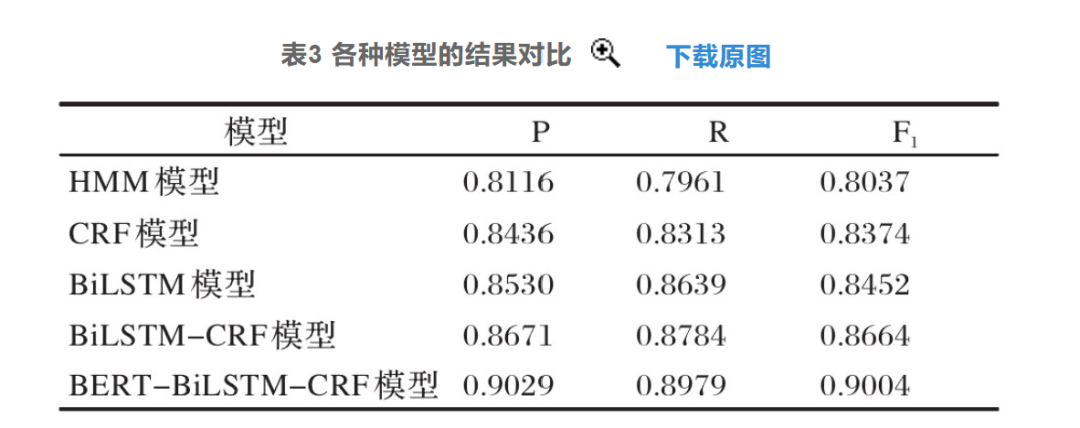
BERT模型是一个强大的预训练模型,通过采用Transformer训练出一个强大的预训练模型,并可以将预训练的模型进行迁移学习。例如在基于中医医案的命名实体识别研究中,研究者提出在BiLSTM-CRF算法上加入BERT语言模型来提高中医医案命名实体识别效果。该模型采用双向Transformer编码器,生成的字向量可以充分融合字词左右的上下文信息,与传统语言模型相比,该模型可以更充分地表征字的多义性。该实验结果也可以说明,BERT模型对于文本数据字符间的关系特征提取及其性能提升有明显效果,此模型在中医医案的命名实体识别相比于其他模型优势较明显。
4 小结
BERT 相较于原来的 RNN、LSTM 可以做到并发执行,同时提取词在句子中的关系特征,并且能在多个不同层次提取关系特征,进而更全面反映句子语义。相较于 word2vec,其又能根据句子上下文获取词义,从而避免歧义出现。但同时BERT模型也存在参数太多,模型太大,少量数据训练时容易过拟合以及对生成式任务和长序列建模支持不好等缺点。