本文主要记录一些学习过程中的笔记
一、文字的表示
1.1 One-hot 读热编码
One-hot编码 是一种非常方便且容易理解的表示方法,
**原理如下:**对于N个不同的字,生成一个长度为N的向量,每个向量中只有一位是1,其余位全是0,以此来表示N个不同的字
虽然 One-hot编码原理简单,但也存在很多问题。
第一个问题:占用的存储空间大,
设想一下这样的的场景,如果我需要表示所有中文汉字,需要编码几千上万位,每一个汉字都需要几千上万位,会导致计算量巨大、存储空间占用巨大。
第二个问题:不表示字的含义,
所有编码是独立存在的,互相不干扰,字意义相近的字和相反的字在这套编码看来,是没有任何区别的,机器无法理解诸如"你"、"我"、"他"、"她"、"它"这类在词性、用法上相似的字的内在联系。
1.2 Word Embedding 词嵌入
为了解决独热编码的缺陷,产生了一种更加高效、适用的编码方式, Word Embedding,它将每个字词映射到一个低纬度的稠密向量中,而且,对于相似的字词,在空间上的距离也是会更近的。
二、 RNN循环神经网络 与 LSTM长短期记忆网络
我们知道,我们输入的句子序列,句子本身是存在内在联系的,对于每一个字、词,需要联系上下文才能知道它的确切含义。
为了捕捉上下文信息,提出了 RNN 和 LSTM模型
2.1 RNN 循环神经网络
在这个模型中,引入了一个重要概念,记忆单元
机器按照序列顺序依次处理每一个字词,不仅会得到这个字词本身的输出,还会产生一个记忆单元,作为下一个字词的输入的一部分一起进入模型。这样,机器就可以顺利记住前文的信息,从而理解上下文。
但是 RNN 存在非常重大的缺陷,当序列长度很长时,怎么能确保记忆单元里的信息是真的有用的?
对于任务有用的信息,可能早就在这一次次的传递中丢失、消失,而那些干扰信息反而有可能被保存在记忆单元内作为输入。
故此, RNN不适合长序列处理。
2.2 LSTM 长短期记忆网络
为了解决RNN 的缺陷, LSTM 模型在 RNN 的基础上,提出了三个"门" ,即 输入门、遗忘门、输出门,用来选择性的保存那些有用的信息。
但同时,LSTM 任然存在缺陷,这个缺陷在RNN中也同样存在:
只能一个字一个字顺序计算,没办法做到并行计算,这将直接导致训练时间过长。
三、 Self-Attention 自注意力机制
为了解决只能顺序执行的问题, Self-Attention模型应运而生,
为了让模型可以并行执行序列,需要解决的问题是:怎么让每一个字都能独立的了解上下文内容对自己的影响?
Self-Attention 模型提出了注意力 这一概念,用来表示每一个字词对自身的联系程度。
首先, 每个字词都会被表示为一个嵌入向量(1.2的那个方法),同时模型引入了 Positional Encoding位置编码,用来表示每个字在序列中的具体位置。
之后进行一系列矩阵运算,概括为以下公式:
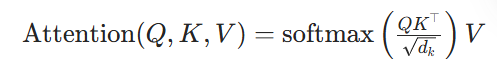
其中,
Q 为查询向量,有输入线性变换 Wq 得到
K 为键向量,由有输入线性变换 Wk 得到
V 为值向量,有输入线性变换 Wv 得到
指的是 注意力分数 的原始矩阵,通过 softmax 归一化,得到每一行和是1的权重矩阵,最后,用该权重和 V 进行 加权求和,以得到融合了上下文信息的内容。
Self-Attention模型有强大的功能,首先它可以并行计算,大大提升了速度,同时它还可以双向得知上下文信息,不仅是之前的,还可以一举得知之后的。
四、BERT
BRET 是基于 transformer 编码器的预训练模型,我这里主要记录它的结构
BERT 的结构主要有以下三层:
4.1 embedding 层
将每个文字转化为嵌入向量,这个向量同时包含以下三种信息:
**① Token Embedding :**即的语义表示,用词嵌入来表示
以下为特殊的表示:
CLS : 用于记录分类任务的重要信息,位于句首(4.3会解释)
SEP:表示停顿(如逗号和句号)
**② Segment Embedding :**句子编码,用来表示不同的句子
**③ Position Embedding :**位置编码,告诉模型字词的位置顺序
4.2 bert layers 层
一般由12层 transformer 编码器层堆叠而形成,每一层都包含多头注意力,同时还有残差连接,以确保模型可以足够深。
4.3 pooler 层
4.1提到的 CLS,即句子中的第一个加入的词,单独作为整个模型的特征表示,这个特征向量可以直接用于下游的分类任务,而这一层需要做的便是:
把 Transformer 层输出的 CLS原始特征,转换成更适合作为整个句子 "语义摘要" 的固定维度向量
五、总结
这里学到了很多东西,从 One-hot 到 Bert ,包括 Self-Attention模型的计算过程、transformer结构的强大知处,为我接下来的学习提供理论基础。
继续加油!