文章目录
- 摘要
- abstract
- 一、论文-2023生成式推荐模型-基于生成式检索的推荐系统
-
- [1.1 生成语义ID部分](#1.1 生成语义ID部分)
- [1.2 训练部分](#1.2 训练部分)
- [1.3 细节](#1.3 细节)
- [1.3.1 论文具有'新能力'](#1.3.1 论文具有’新能力‘)
- [1.4 总结](#1.4 总结)
- 二、推荐算法总结
- 总结
摘要
研读了生成式推荐模型TIGER框架。其核心是将推荐转化为生成式检索:先为物品生成具有语义的ID(使用RQ-VAE量化内容特征),再用Transformer模型根据用户历史语义ID序列自回归预测下一个。该框架不仅能提升推荐性能,还展现出优秀的新项目冷启动能力和通过温度采样调控推荐多样性的新可能。同时,这几周的推荐算法方面进行了总结。
abstract
I studied the TIGER framework, a generative recommendation model. Its core is to transform recommendation into generative retrieval: first, semantic IDs are generated for items (using RQ-VAE to quantify content features), then a Transformer model is used to autoregressively predict the next item based on the user's historical semantic ID sequence. This framework not only improves recommendation performance but also demonstrates excellent cold-start capabilities for new items and new possibilities for controlling recommendation diversity through temperature sampling. Meanwhile, I summarized my experience with recommendation algorithms over the past few weeks.
一、论文-2023生成式推荐模型-基于生成式检索的推荐系统
个人总结 TIGER框架
提出了一种新的生成式检索方法,检索模型自回归地解码目标候选项目的标识符。为了实现,创建了语义上有意义的码字元组,作为每个项目的语义ID。给定用户会话中项目的语义ID,基于Transformer的序列到序列模型被训练来预测用户将与之交互的下一个项目的语义ID。
框架包含两个阶段:
1.使用内容特征生成语义ID。涉及将项目内容特征编码为嵌入向量,并将嵌入量化为语义码字元组。由此产生的码字元组被称为项目的语义ID。
- 在语义ID上训练生成式推荐系统。在顺序推荐任务上使用语义ID序列训练Transformer模型。
1.1 生成语义ID部分

推荐语料库中项目的语义ID生成过程。假设每个项目都有相关的捕获有用语义信息的内容特征(如标题、描述或图像)。
假设可以访问预训练的内容编码器来生成语义嵌入。如,使用通用预训练文本编码器如Sentence-T527和BERT7将项目的文本特征转换为获得语义嵌入。然后对语义嵌入进行量化,为每个项目生成语义ID。
论文使用的是Sentence-T5将项目的文本特征转换为获得语义嵌入。
Google 于 2022 年提出的高性能文本语义编码器,它在 T5(Text-to-Text Transfer Transformer)架构基础上,针对性优化句子/段落级表示改进。
ST5 的升级方向:
ST6 (2025):引入稀疏 MoE 架构,激活参数仅 3.2B(总参 12B),在保持速度下提升多语言能力。
量子化 ST5:Google 内部使用 4-bit 量化 + 硬件感知训练,在 Pixel 8 上实现 3,400 QPS。
因果 ST5:结合 RNN 结构,支持流式文本编码(适用于实时聊天机器人)。
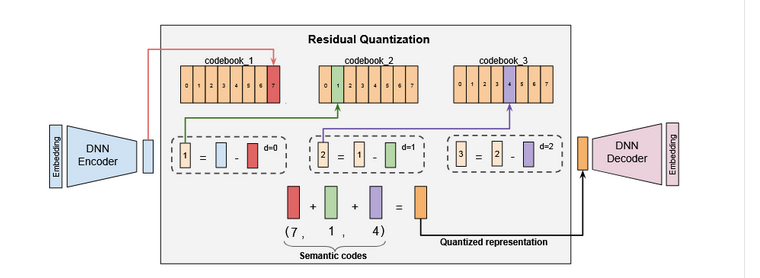
论文使用的是多级向量量化器RQ-VAE(残差量化变分自编码器),对残差应用量化来生成码字元组(即语义ID)。
RQ-VAE核心思想是将连续隐空间分解为层次化的离散表示,适合高保真生成任务和高效信息压缩。
人类感知具有层次性(如先识别物体轮廓,再关注纹理细节)。RQ-VAE 通过多级量化模拟这一过程:
高层码本 → 捕获语义信息(如物体类别)
底层码本 → 捕获细节信息(如纹理、边缘)。
首先通过编码器对输入进行编码z_e,学习潜在表示。
从码本1选最接近 z_e 的向量 q₁(捕获主要结构),计算残差 r₁ = z_e - q₁,从码本2选最接近 r₁ 的向量 q₂(捕获中级细节),计算残差 r₂ = r₁ - q₂,...捕获精细细节...。最后z_q = q₁ + q₂ + q₃+...。一般2-4级。
高层可以使用小码本,然后逐级加大。梯度下降时,反向传播时跳过量化,直接传梯度。每级损失 = 码本更新损失 + 编码器承诺损失,每级独立优化。
解码器尝试使用ẑ重新创建输入x。
防止RQ-VAE出现码本崩溃(即大多数输入仅映射到少数码本向量),使用基于k-means聚类的初始化用于码本。
生成语义ID的一个简单替代方案是使用局部敏感哈希(LSH)。
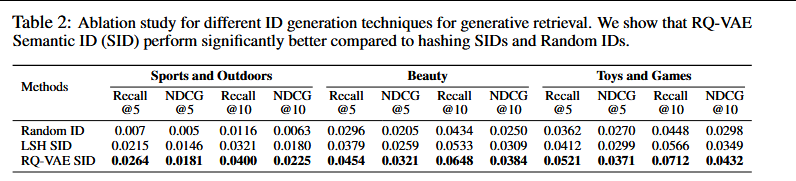
论文进行了一项消融研究,发现RQ-VAE确实比LSH效果更好。另一个选项是分层使用k-means聚类,但它失去了不同聚类之间的语义意义。
语义嵌入的分布、码本大小的选择和码字的长度,可能会发生语义冲突--多个项目可能映射到相同的语义ID,为了消除冲突,在有序语义码的末尾附加一个额外令牌,使它们唯一。
就需要维护一个将语义ID映射到相应项目的查找表,检测冲突。
1.2 训练部分
训练部分:
数据集:Amazon产品评论数据集10的三个公共真实世界基准上评估所提出的框架,该数据集包含1996年5月至2014年7月的用户评论和项目元数据。使用Amazon产品评论数据集的三个类别进行顺序推荐任务:"美容"、"体育和户外"和"玩具和游戏"。
评估指标:top-k召回率(Recall@K)和归一化折扣累积增益(NDCG@K)
流程:
1.使用预训练的Sentence-T527模型获取数据集中每个项目的语义嵌入,使用项目的内容特征,如标题、价格、品牌和类别来构建句子,然后将其传递给预训练的Sentence-T5模型,以获得768维的项目语义嵌入。
2.RQ-VAE用于量化项目的语义嵌入,将输入语义嵌入编码为潜在表示的DNN编码器;输出量化表示的残差量化器,3级量化,分别为512、256和128维度,ReLU激活;以及将量化表示解码回语义输入嵌入空间的DNN解码器。避免多个项目映射到相同的语义ID,为共享相同前三个码字的项目添加唯一的第4个代码。
3.序列到序列模型实现细节:使用开源的T5X框架实现基于Transformer的编码器-解码器架构。基于Transformer的编码器和解码器模型各使用4层,每层有6个维度为64的自注意力头。使用ReLU激活函数。
为了使模型能够处理顺序推荐任务的输入,序列到序列模型的词汇表包含每个语义码字的令牌。词汇表包含1024(256×4)个令牌来表示语料库中的项目。
除了项目的语义码字,还向词汇表添加用户特定的令牌。为了保持词汇表大小有限,仅为用户ID添加2000个令牌。使用哈希技巧将原始用户ID映射到2000个用户ID令牌之一。构建输入序列为用户ID令牌,后跟给定用户项目交互历史的语义ID令牌序列。
发现将用户ID添加到输入中,使模型能够个性化检索的项目。
1.3 细节
将RQ-VAE与局部敏感哈希用于语义ID生成进行比较:
序列构建:将用户历史(items₁,...,itemsₙ)转换为语义ID序列;
序列编码:Transformer编码器处理输入序列,生成上下文表示;
自回归解码:解码器以开头,逐个预测语义ID的码字,使用束搜索(beam search)生成最可能的语义ID。
1.3.1 论文具有'新能力'
提出的生成式检索框架的两种新能力,即冷启动推荐和推荐多样性。:
冷启动推荐。由于现实世界推荐语料库的快速变化性质,新项目不断被引入。新添加的项目在训练语料库中缺乏用户印象,使用随机原子ID进行项目表示的现有推荐模型无法检索新项目作为潜在候选项目。
TIGER框架可以轻松执行冷启动推荐,因为在预测下一个项目时利用项目语义。
从训练数据拆分中移除5%的测试项目。这些移除的项目称为未见项目。确保了关于未见项目的无数据泄漏。训练RQ-VAE量化器和序列到序列模型。训练完成后,使用RQ-VAE模型为数据集中的所有项目(包括项目语料库中的任何未见项目)生成语义ID。
给定模型预测的语义ID(c₁,c₂,c₃,c₄),检索具有相同对应ID的已见项目。模型预测的每个语义ID最多匹配训练数据集中的一个项目。具有相同前三个语义令牌的未见项目,即(c₁,c₂,c₃)被包含在检索候选列表中,第4个令牌用于确保所有已见项目存在唯一ID。
引入一个超参数ε,指定我们框架选择的未见项目的最大比例。
比较了TIGER与k-最近邻(KNN)方法在冷启动推荐设置中的性能:
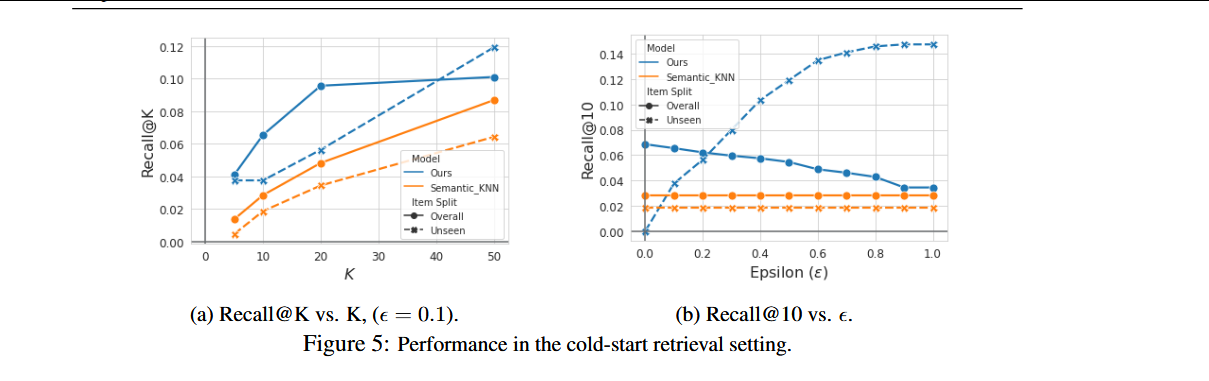
图a中,框架(ε=0.1)在所有Recall@K指标上始终优于Semantic_KNN。在5b中,提供了各种ε值下我们的方法与Semantic_KNN的比较。对于所有ε≥0.1的设置,我们的方法优于基线。
推荐多样性:具有较差多样性的推荐系统可能对用户的长期参与有害。在解码过程中基于温度的采样可以有效地用于控制模型预测的多样性。
基于温度的采样:通过调节概率分布平滑度来精确控制推荐结果多样性的关键技术。
假设模型对3个物品的原始打分:视频A: 3.0, 视频B: 2.0, 视频C: 1.0
经过Softmax得到基础概率:P(i) = exp(score_i) / Σexp(score_j); 基础概率 ≈ 0.67, 0.24, 0.09 (T=1.0,即标准Softmax),引入温度参数T,P_T(i) = exp(score_i / T) / Σexp(score_j / T)。T<1,只推荐最高分物品,T=1,主要推A,偶尔推B.T>1,ABC三者都有合理曝光机会。
信息熵调控(理论基础):信息熵 H§ = -Σ P(i) log P(i) 量化分布的不确定性
温度 T 与熵的严格正相关:
T↑ → H§↑ → 推荐不确定性↑ → 多样性↑
T↓ → H§↓ → 推荐确定性↑ → 精准性↑
基于温度的采样可以应用于任何现有推荐模型,而TIGER允许在RQ-VAE语义ID属性的不同层次上进行采样。如,对语义ID的第一个令牌进行采样允许从粗粒度类别检索项目,而对第二/第三个令牌进行采样允许在类别内采样项目。
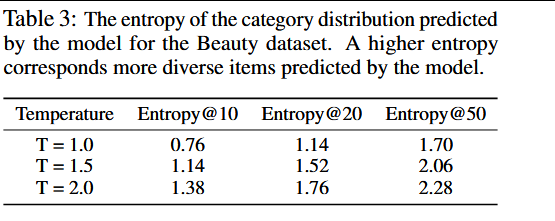
论文使用Entropy@K指标定量测量预测的多样性,其中熵是根据模型预测的top-K项目的真实类别的分布计算的。表3中报告了各种温度值的Entropy@K。证明解码阶段的温度采样可以有效地用于增加项目地面真实类别的多样性。表4做了定性分析。

1.4 总结
TIGER通过将推荐任务转化为生成式检索问题,并引入语义ID作为项目表示,实现性能与能力的突破。核心价值在于将Transformer内存作为端到端索引(语义ID推荐项目ID),同时保持对新项目的泛化能力--冷启动+推荐多样性。
二、推荐算法总结
个人理解:从最开始的协方差,矩阵分解,到大模型后引入的深度神经网络,序列推荐,再到现在的生成式推荐算法,都是围绕着,物品特征和用户特征两个方面进行改进,如:通过物品分类,用户分组推荐、将物品特征总结成文本后推荐、根据用户的行为特征进行序列建模、以及最新的生成式根据物品特征进行划分语义,这些都是围绕两个方面进行的推荐,只不过技术方面慢慢在改进,计算也更快。就目前我的理解下,推荐算法可能会在这两样综合的情况下更好(物品进行特征总结,不是一般的总结甚至可以紧跟时事(用户为什么会搜,以及喜爱的原因)进行总结;用户的话除了序列行为+生成语义外,可以加上情感以及时事潮流方面的内容)。
总结
就目前看的论文而言,推荐算法方面会简单看几篇有特点的论文,把重点目标放在多模态,智能体上面,然后就是需要对代码复现,以及一些基础的内容去深究。