摘要:亲和传播算法是一种无需预设聚类数量的无监督学习方法,通过消息传递机制自动识别数据中的"范例点"作为聚类中心。该算法通过交替更新责任矩阵(反映样本适配度)和可用性矩阵(反映中心认可度)实现聚类,适用于中小规模数据集。其优势在于自动确定聚类数量和处理复杂形状数据,但存在计算成本高、对参数敏感等局限。Python中可通过scikit-learn的AffinityPropagation类实现,需重点调整preference和damping参数。该算法在生物信息学、图像处理等领域有广泛应用,但大数据场景建议选用更高效的替代算法。
目录
[机器学习 - 亲和传播算法](#机器学习 - 亲和传播算法)
[二、Python 实现](#二、Python 实现)
[1. 核心参数调优](#1. 核心参数调优)
[2. 相似度矩阵优化](#2. 相似度矩阵优化)
[3. 大规模数据处理方案](#3. 大规模数据处理方案)
机器学习 - 亲和传播算法
一、算法概述
亲和传播(Affinity Propagation)是一种聚类算法,其核心功能是在数据集中识别出 "范例点"(exemplars),并将每个数据点分配给其中一个范例点。作为一类无需预先指定聚类数量的算法,它成为探索性数据分析的实用工具。该算法由弗雷(Frey)和杜克(Dueck)于 2007 年提出,此后广泛应用于生物学、计算机视觉、社交网络分析等多个领域。
亲和传播算法的核心思想是迭代更新两个矩阵:责任矩阵 (responsibility matrix)和可用性矩阵(availability matrix)。责任矩阵记录了每个数据点作为其他数据点范例点的适宜程度;可用性矩阵则反映了每个数据点选择其他数据点作为自身范例点的意愿程度。算法通过交替更新这两个矩阵,直至达到收敛状态,最终依据责任矩阵中的最大值确定范例点。
核心原理
- 基本思想:视每个样本为潜在聚类中心,通过 N×N 相似度矩阵描述样本间关联,迭代更新两类消息以收敛到稳定聚类结构。
- 核心消息
- 吸引度(Responsibility, r (i,k)):样本 i 对样本 k 作为其聚类中心的 "推荐强度",反映 k 相比其他候选对 i 的适配性。
- 归属度(Availability, a (i,k)):样本 k 接受样本 i 将其作为中心的 "认可强度",反映 k 适合作为 i 中心的程度。
- 聚类中心判定:收敛后,r (i,k)+a (i,k) 最大的 k 即为 i 的聚类中心;若 k=i,则 i 自身为中心。
算法流程
- 初始化
- 计算相似度矩阵 S:常用负欧氏距离,S (i,i) 为偏向参数 preference,控制聚类数量(值越大,中心越多)。
- 初始化吸引度矩阵 R 和归属度矩阵 A 为全零矩阵。
- 迭代更新(阻尼系数 damping∈[0.5,1) 防止振荡)
- 更新吸引度:r (i,k) = S (i,k) - max_{k'≠k} a (i,k') + S (i,k')。
- 更新归属度:a (i,k) = min {0, r (k,k) + sum_{i'∉{i,k}} max {0, r (i',k)}};a (k,k)=sum_{i'≠k} max {0, r (i',k)}。
- 收敛判定:连续 convergence_iter 次迭代聚类中心不变或达 max_iter,停止迭代。
- 输出结果:聚类中心索引及各样本聚类标签。
关键参数(sklearn)
| 参数 | 作用 | 默认值 |
|---|---|---|
| preference | 样本自身作为中心的偏向,控制聚类数量 | None(常用 S 中位数) |
| damping | 阻尼系数,防止数值振荡 | [0.5,1),默认 0.5 |
| convergence_iter | 收敛判定阈值 | 15 |
| max_iter | 最大迭代次数 | 200 |
二、Python 实现
在 Python 中,Scikit-learn 库提供了AffinityPropagation类,用于实现亲和传播算法。该类包含多个参数,其中:
- 偏好参数(preference):控制范例点的数量,值越高则范例点越多,值越低则范例点越少;
- 阻尼系数(damping factor):控制算法的收敛速度,系数越大,收敛速度越慢。
示例代码
python
from sklearn.cluster import AffinityPropagation
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
# 生成数据集
X, _ = make_blobs(n_samples=100, centers=4, random_state=0)
# 创建亲和传播算法实例
af = AffinityPropagation(preference=-50)
# 拟合模型
af.fit(X)
# 打印聚类标签和范例点
print("聚类标签:", af.labels_)
print("范例点索引:", af.cluster_centers_indices_)
# 绘制结果
plt.figure(figsize=(7.5, 3.5))
# 绘制数据点(按聚类标签着色)
plt.scatter(X[:, 0], X[:, 1], c=af.labels_, cmap='viridis')
# 绘制范例点(红色"×"标记)
plt.scatter(af.cluster_centers_[:, 0], af.cluster_centers_[:, 1], marker='x', color='red')
plt.show()代码说明
- 首先使用 Scikit-learn 的
make_blobs()函数生成一个合成数据集; - 创建
AffinityPropagation类实例,设置偏好参数为 - 50; - 通过
fit()方法将模型拟合到数据集; - 输出聚类标签(每个数据点所属的聚类)和范例点索引(被选为范例点的数据点在数据集中的位置);
- 利用
matplotlib绘制聚类结果,其中普通数据点按聚类标签着色,范例点用红色 "×" 标记。
输出结果
- 可视化输出:运行代码后会生成一个散点图,展示数据点的聚类分布及范例点位置(横坐标范围 0-3,纵坐标范围 0-10);
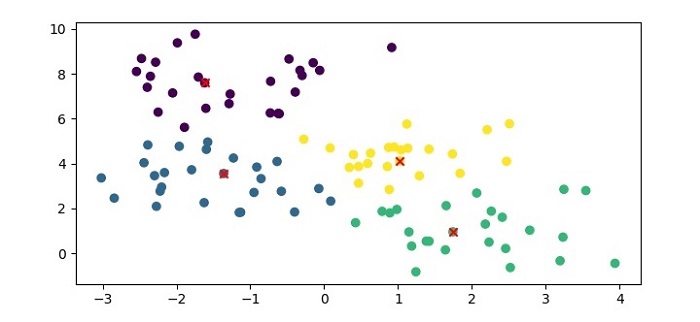
- 终端输出:
python
聚类标签:[3 0 3 3 3 3 1 0 0 0 0 0 0 0 0 2 3 3 1 2 2 0 1 2 3 1 3 3 2 2 2 0 2 2 1 3 0 2 0 1 3 1 0 1 1 0 2 1 3 1 3 2 1 1 1 0 0 2 2 0 0 2 2 3 2 0 1 1 2 3 0 2 3 0 3 3 3 1 2 2 2 0 1 1 2 1 2 2 3 3 3 1 1 1 1 0 0 1 0 1]
范例点索引:[9 41 51 74]三、算法优缺点
优点
- 无需预先指定聚类数量,可自动识别聚类个数;
- 能够处理任意形状和大小的聚类;
- 可应对含噪声或不完整的数据;
- 对初始参数的选择相对不敏感;
- 在特定类型的数据集上,表现优于其他聚类算法。
缺点
- 对于大型数据集或高维数据集,计算成本较高;
- 可能收敛到次优解,尤其当数据变异性强或噪声较多时;
- 对控制收敛速度的阻尼系数较为敏感;
- 可能产生多个小型聚类(仅含一个或少数几个数据点),这类聚类可能缺乏实际意义;
- 聚类结果的可解释性较差,算法未提供关于聚类含义或特征的明确信息。
四、亲和传播算法参数调优指南
1. 核心参数调优
| 参数 | 调优思路 | 取值建议 | 注意事项 |
|---|---|---|---|
| preference(偏向参数) | 控制聚类中心数量,值越大 → 中心越多默认取相似度矩阵 S 的中位数 | 1. 数据分布密集:取 S 的下四分位数 (减少中心)2. 数据分布稀疏:取 S 的上四分位数(增加中心)3. 已知大致簇数:逐步调整直到簇数匹配 | 避免设置为极端值(如远大于 S 最大值),否则每个样本都会成为中心 |
| damping(阻尼系数) | 防止迭代过程中数值振荡,平衡新旧消息权重 | 1. 无振荡:0.5~0.72. 轻微振荡:0.7~0.93. 严重振荡:0.9~0.99 | 取值越接近 1,收敛越慢,但稳定性越强 |
| convergence_iter(收敛阈值) | 连续 n 次迭代中心不变则收敛 | 10~50(默认 15) | 取值太小易提前收敛(聚类效果差);取值太大增加计算成本 |
| max_iter(最大迭代次数) | 防止算法无限迭代 | 200~1000(默认 200) | 复杂数据集可适当增大,结合收敛阈值使用 |
2. 相似度矩阵优化
AP 算法的性能高度依赖相似度矩阵 ,常用优化方式:
- 基础相似度:负欧氏距离(适用于连续型数据)
- 缺点:对高维数据敏感,需先降维
- 高维数据适配 :
- 先通过 PCA、t-SNE 降维到低维空间,再计算相似度
- 改用余弦相似度(适用于文本 / 向量数据):
- 稀疏相似度矩阵:对大规模数据,只保留每个样本的 Top-K 近邻相似度,其余置为 -∞,可大幅降低空间复杂度
3. 大规模数据处理方案
AP 算法 O(N2) 的复杂度不适合大数据集,可通过以下方式优化:
- 数据抽样:抽取部分样本训练 AP,得到中心后,用 K 近邻将剩余样本分配到对应簇
- 结合降维:先用 PCA/FA 降维,减少特征维度,降低相似度计算成本
- 改用近似算法:如 FastAP(快速亲和传播),通过剪枝非核心样本提升效率
五、应用场景
适用于中小规模、需自动确定聚类数量的场景,如文本聚类、图像分割、基因表达分析等;大规模数据建议用 MiniBatchKMeans、DBSCAN 等替代。
六、总结
亲和传播通过消息传递机制实现无监督聚类,核心在于 preference 和 damping 参数调优。中小数据集且聚类数量未知时表现出色,大数据集需权衡计算与内存成本。