李沐课程中,讲解了LeNex,AlexNet,VGG,Inception和ResNet
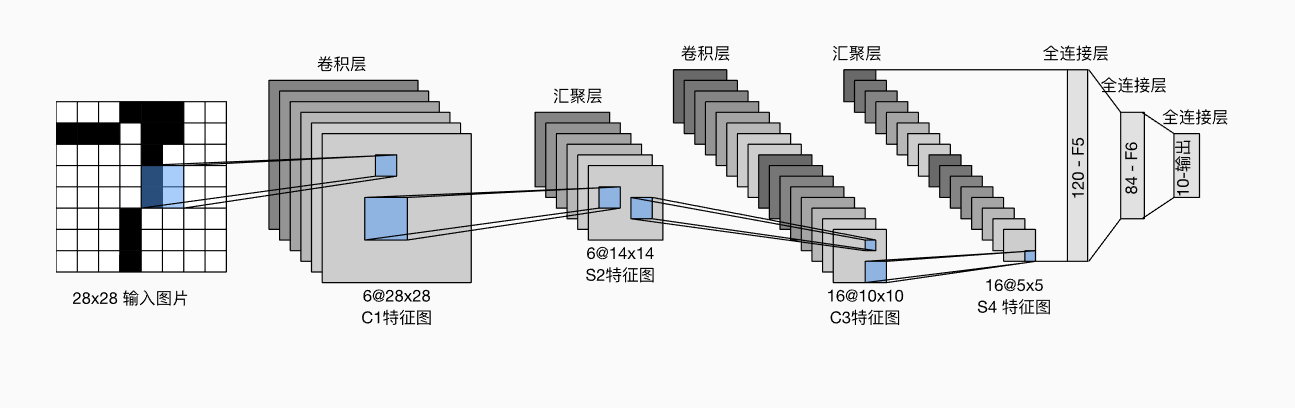
一、LeNex
层数:7层(2卷积+2池化+3全连接)
net = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Flatten(),
nn.Linear(16 * 5 * 5, 120), nn.Sigmoid(),
nn.Linear(120, 84), nn.Sigmoid(),
nn.Linear(84, 10))主要应用于手写数字识别(MNIST数据集)
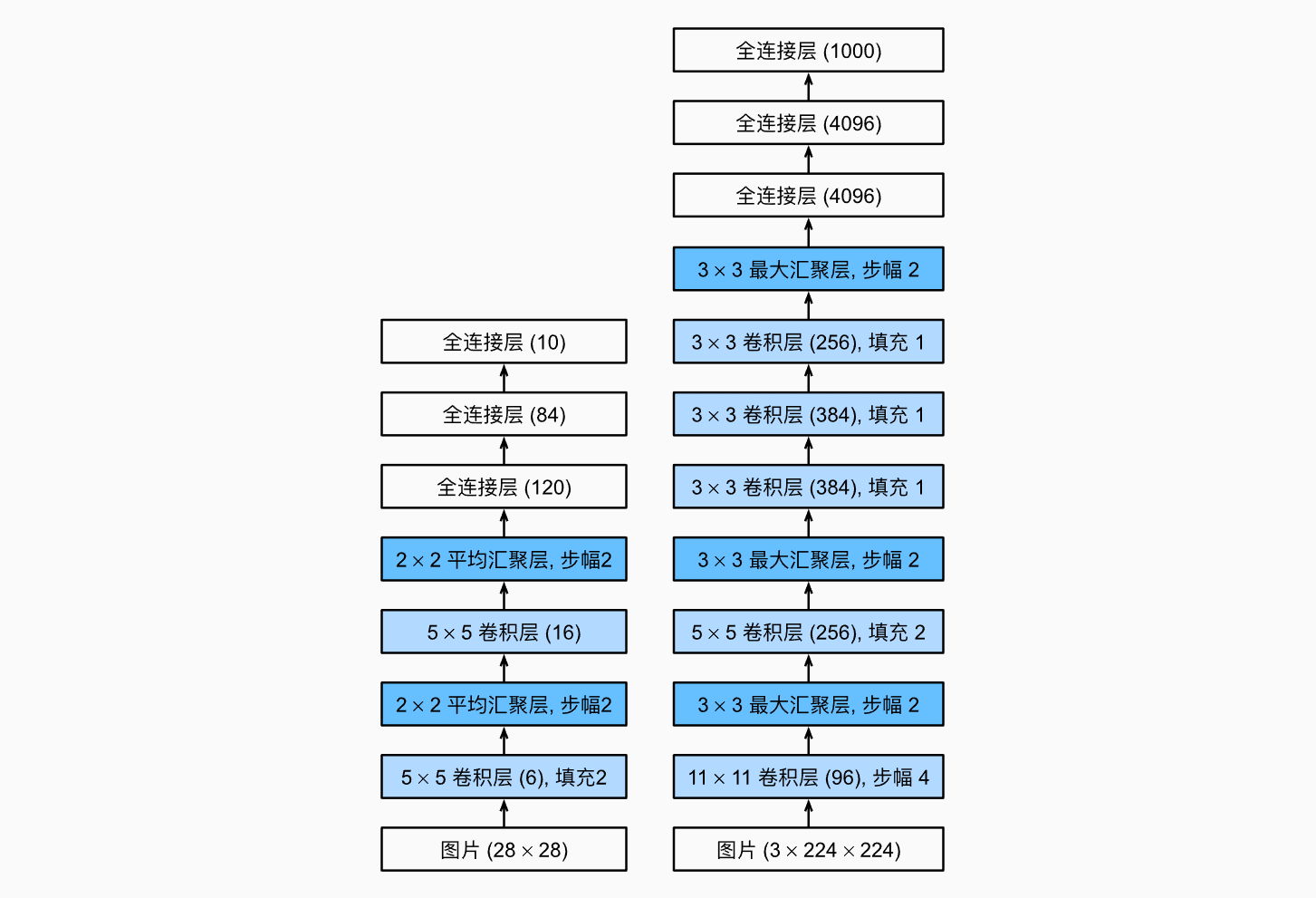
二、AlexNex
在LeNex进行优化,使用Dropout,RELU和MaxPool
层数:13层(5卷积+3池化+3全连接)
net = nn.Sequential(
nn.Conv2d(1, 96, kernel_size=11, stride=4, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(96, 256, kernel_size=5, padding=2), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(256, 384, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(384, 384, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(384, 256, kernel_size=3, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Flatten(),
# 这里,全连接层的输出数量是LeNet中的好几倍。使用dropout层来减轻过拟合
nn.Linear(6400, 4096), nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096), nn.ReLU(),
nn.Dropout(p=0.5),
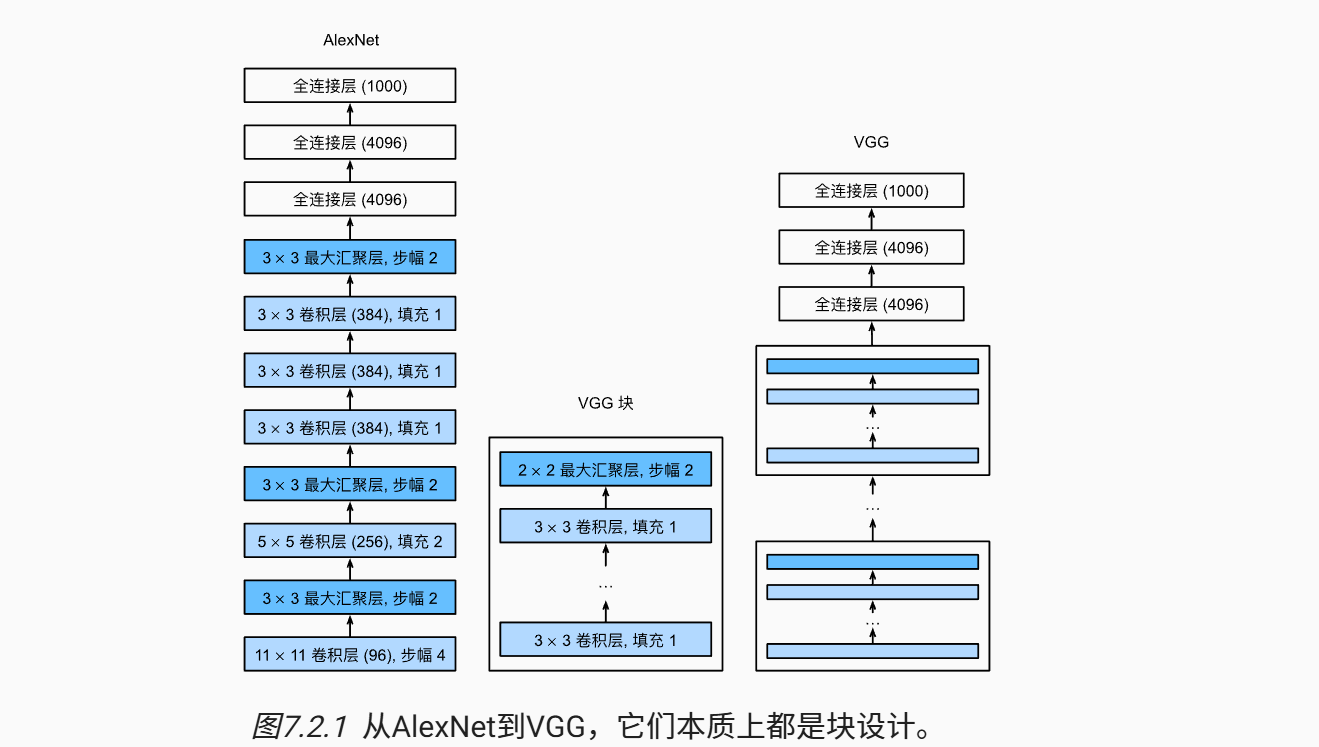
nn.Linear(4096, 10))三、VGG
封装成块,块堆叠
def vgg(conv_arch):
conv_blks = []
in_channels = 1
# 卷积层部分
for (num_convs, out_channels) in conv_arch:
conv_blks.append(vgg_block(num_convs, in_channels, out_channels))
in_channels = out_channels
return nn.Sequential(
*conv_blks, nn.Flatten(),
# 全连接层部分
nn.Linear(out_channels * 7 * 7, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(0.5),
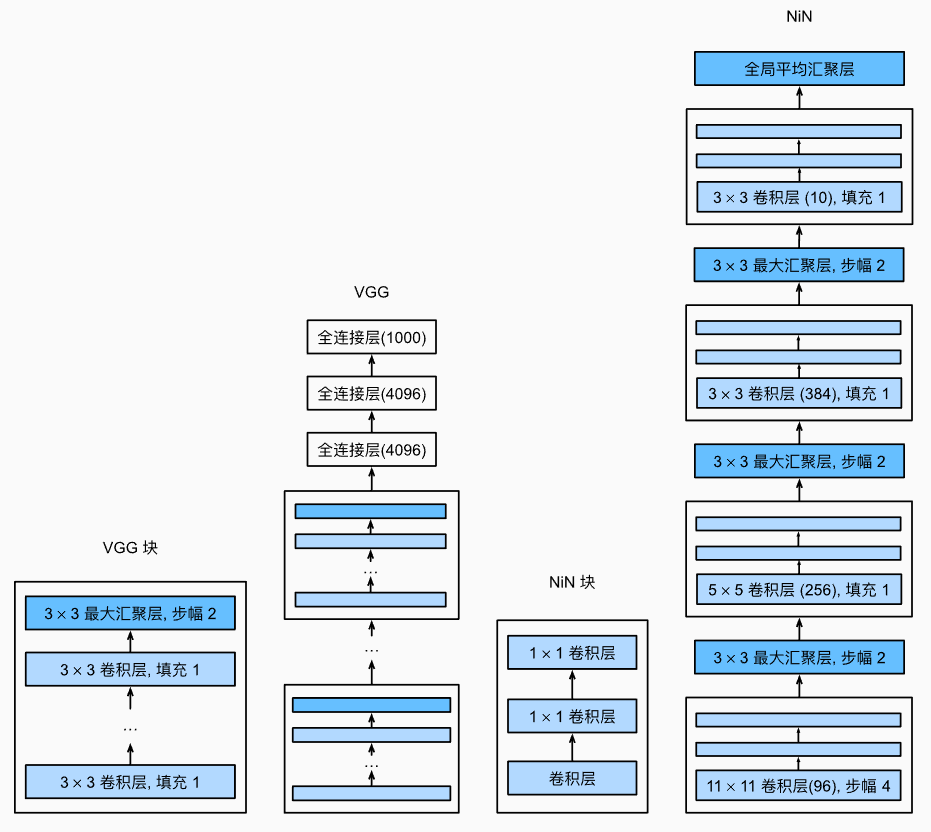
nn.Linear(4096, 10))四、NiN
NiN块以一个普通卷积层开始,后面是两个的卷积层。
def nin_block(in_channels, out_channels, kernel_size, strides, padding):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size, strides, padding),
nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU())
net = nn.Sequential(
nin_block(1, 96, kernel_size=11, strides=4, padding=0),
nn.MaxPool2d(3, stride=2),
nin_block(96, 256, kernel_size=5, strides=1, padding=2),
nn.MaxPool2d(3, stride=2),
nin_block(256, 384, kernel_size=3, strides=1, padding=1),
nn.MaxPool2d(3, stride=2),
nn.Dropout(0.5),
# 标签类别数是10
nin_block(384, 10, kernel_size=3, strides=1, padding=1),
nn.AdaptiveAvgPool2d((1, 1)),
# 将四维的输出转成二维的输出,其形状为(批量大小,10)
nn.Flatten())五、GoogLeNet
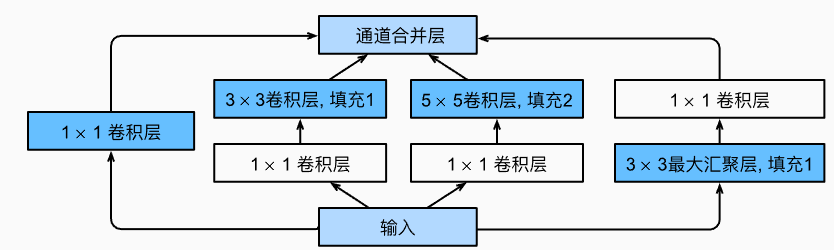
class Inception(nn.Block):
# c1--c4是每条路径的输出通道数
def __init__(self, c1, c2, c3, c4, **kwargs):
super(Inception, self).__init__(**kwargs)
# 线路1,单1x1卷积层
self.p1_1 = nn.Conv2D(c1, kernel_size=1, activation='relu')
# 线路2,1x1卷积层后接3x3卷积层
self.p2_1 = nn.Conv2D(c2[0], kernel_size=1, activation='relu')
self.p2_2 = nn.Conv2D(c2[1], kernel_size=3, padding=1,
activation='relu')
# 线路3,1x1卷积层后接5x5卷积层
self.p3_1 = nn.Conv2D(c3[0], kernel_size=1, activation='relu')
self.p3_2 = nn.Conv2D(c3[1], kernel_size=5, padding=2,
activation='relu')
# 线路4,3x3最大汇聚层后接1x1卷积层
self.p4_1 = nn.MaxPool2D(pool_size=3, strides=1, padding=1)
self.p4_2 = nn.Conv2D(c4, kernel_size=1, activation='relu')
def forward(self, x):
p1 = self.p1_1(x)
p2 = self.p2_2(self.p2_1(x))
p3 = self.p3_2(self.p3_1(x))
p4 = self.p4_2(self.p4_1(x))
# 在通道维度上连结输出
return np.concatenate((p1, p2, p3, p4), axis=1)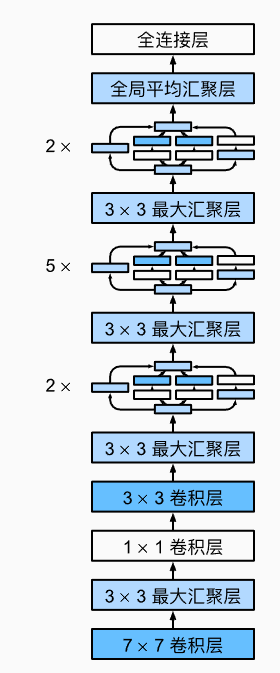
b1 = nn.Sequential()
b1.add(nn.Conv2D(64, kernel_size=7, strides=2, padding=3, activation='relu'),
nn.MaxPool2D(pool_size=3, strides=2, padding=1))b2 = nn.Sequential()
b2.add(nn.Conv2D(64, kernel_size=1, activation='relu'),
nn.Conv2D(192, kernel_size=3, padding=1, activation='relu'),
nn.MaxPool2D(pool_size=3, strides=2, padding=1))b3 = nn.Sequential()
b3.add(Inception(64, (96, 128), (16, 32), 32),
Inception(128, (128, 192), (32, 96), 64),
nn.MaxPool2D(pool_size=3, strides=2, padding=1))b4 = nn.Sequential()
b4.add(Inception(192, (96, 208), (16, 48), 64),
Inception(160, (112, 224), (24, 64), 64),
Inception(128, (128, 256), (24, 64), 64),
Inception(112, (144, 288), (32, 64), 64),
Inception(256, (160, 320), (32, 128), 128),
nn.MaxPool2D(pool_size=3, strides=2, padding=1))b5 = nn.Sequential()
b5.add(Inception(256, (160, 320), (32, 128), 128),
Inception(384, (192, 384), (48, 128), 128),
nn.GlobalAvgPool2D())
net = nn.Sequential()
net.add(b1, b2, b3, b4, b5, nn.Dense(10))X = np.random.uniform(size=(1, 1, 96, 96))
net.initialize()
for layer in net:
X = layer(X)
print(layer.name, 'output shape:\t', X.shape)六、ResNet
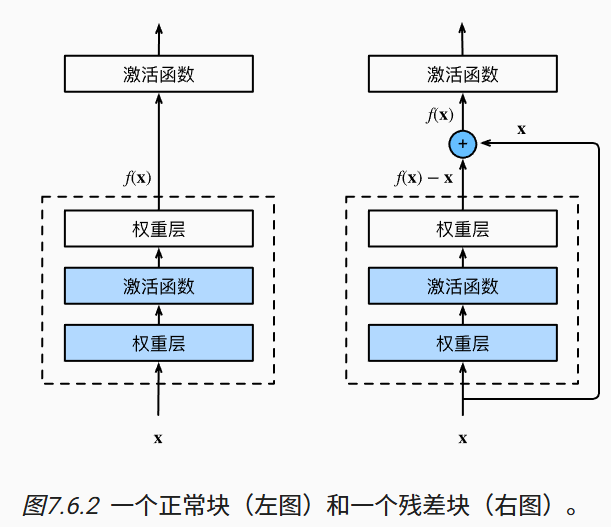
class Residual(nn.Module):
def __init__(self, input_channels, num_channels,
use_1x1conv=False, strides=1):
super().__init__()
self.conv1 = nn.Conv2d(input_channels, num_channels,
kernel_size=3, padding=1, stride=strides)
self.conv2 = nn.Conv2d(num_channels, num_channels,
kernel_size=3, padding=1)
if use_1x1conv:
self.conv3 = nn.Conv2d(input_channels, num_channels,
kernel_size=1, stride=strides)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(num_channels)
self.bn2 = nn.BatchNorm2d(num_channels)
def forward(self, X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
Y += X
return F.relu(Y)