Hadoop的安装分为Standalone Operation、Pseudo-Distributed Operation、Fully-Distributed Operation,为了我们方便在本地搭建Hadoop集群和学习,我们来聊聊Hadoop的单机伪分布模式的搭建,并希望程序能在yarn上运行。
一、下载安装包
官方部署地址,可以参考
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html#Download
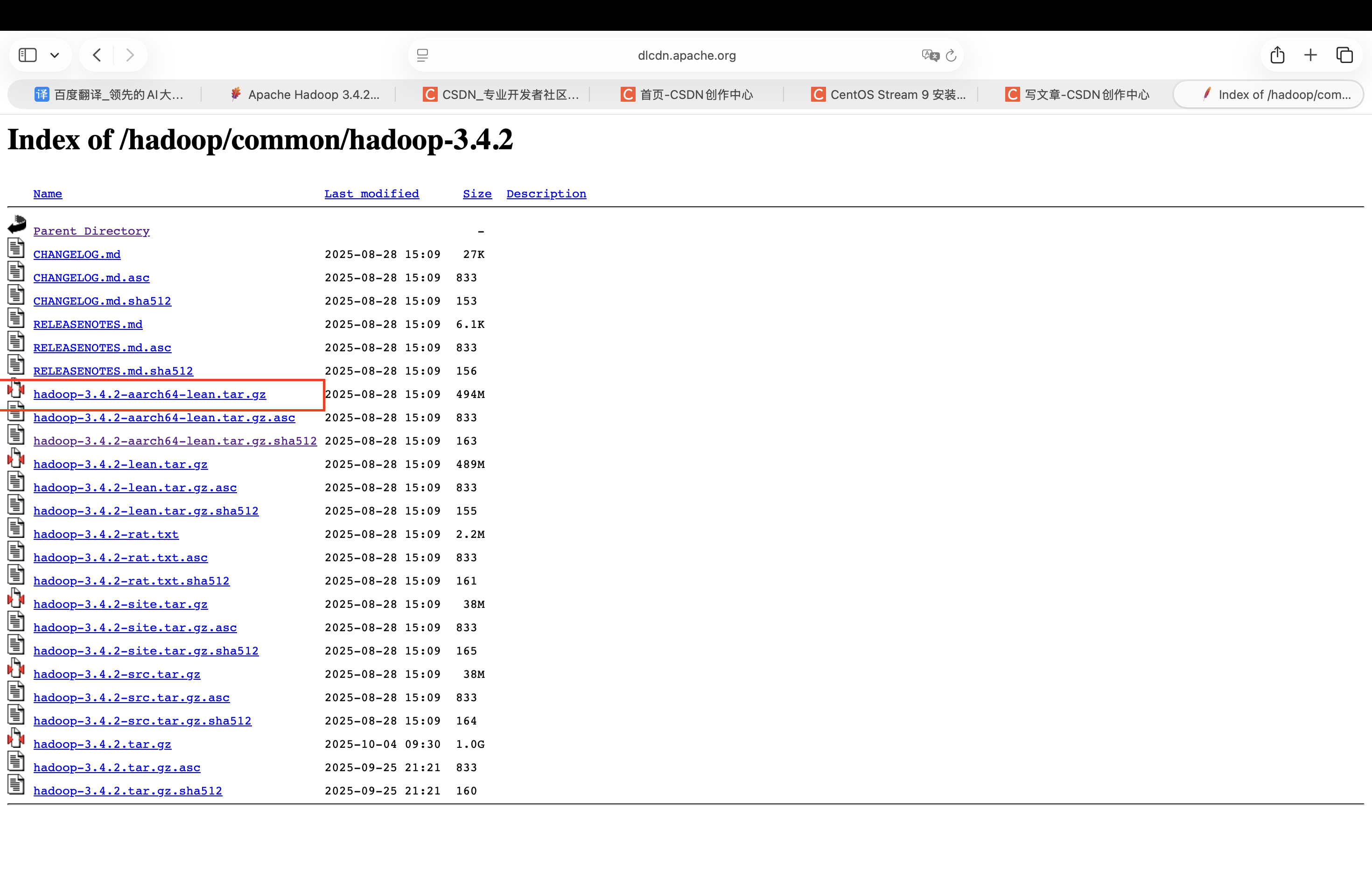
安装包官网下载地址:
https://dlcdn.apache.org/hadoop/common/hadoop-3.4.2/
大家可以根据自己的电脑系统下载相应的安装包,我的是M芯片的,所以下载这个安装包
二、准备一台虚拟机,我这里起名为centos01。
三、永久关闭防火墙
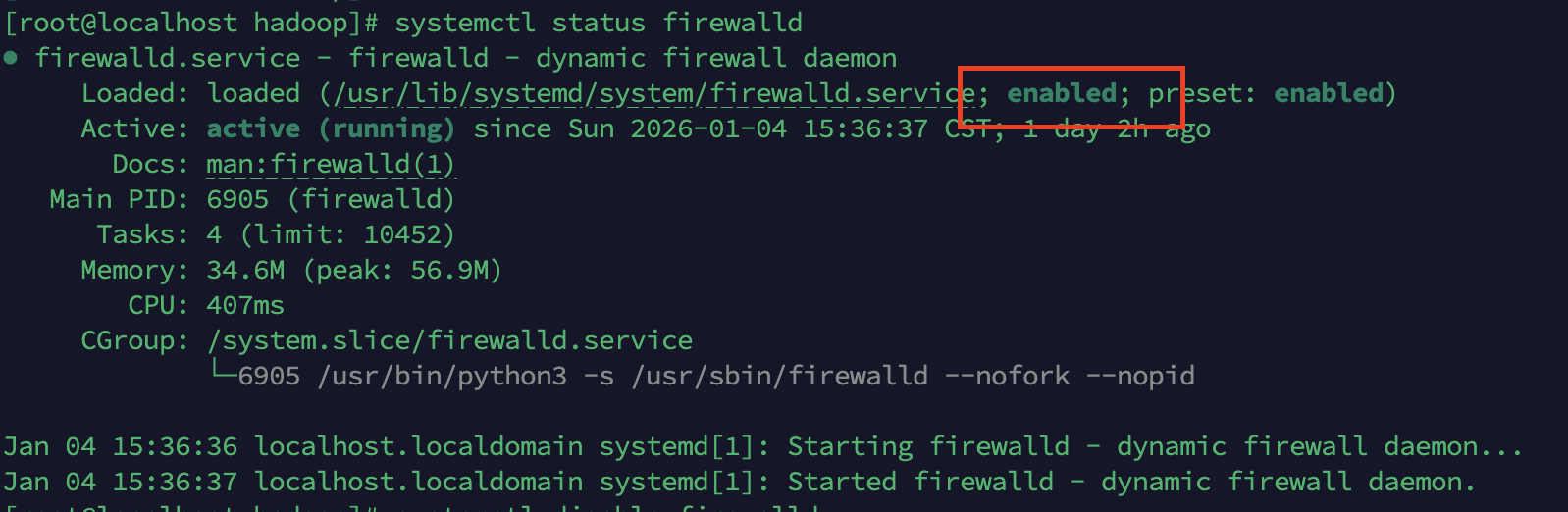
首先查看防火墙状态
systemctl status firewalld出现一下状态视为激活状态
关闭防火墙
systemctl disable firewalld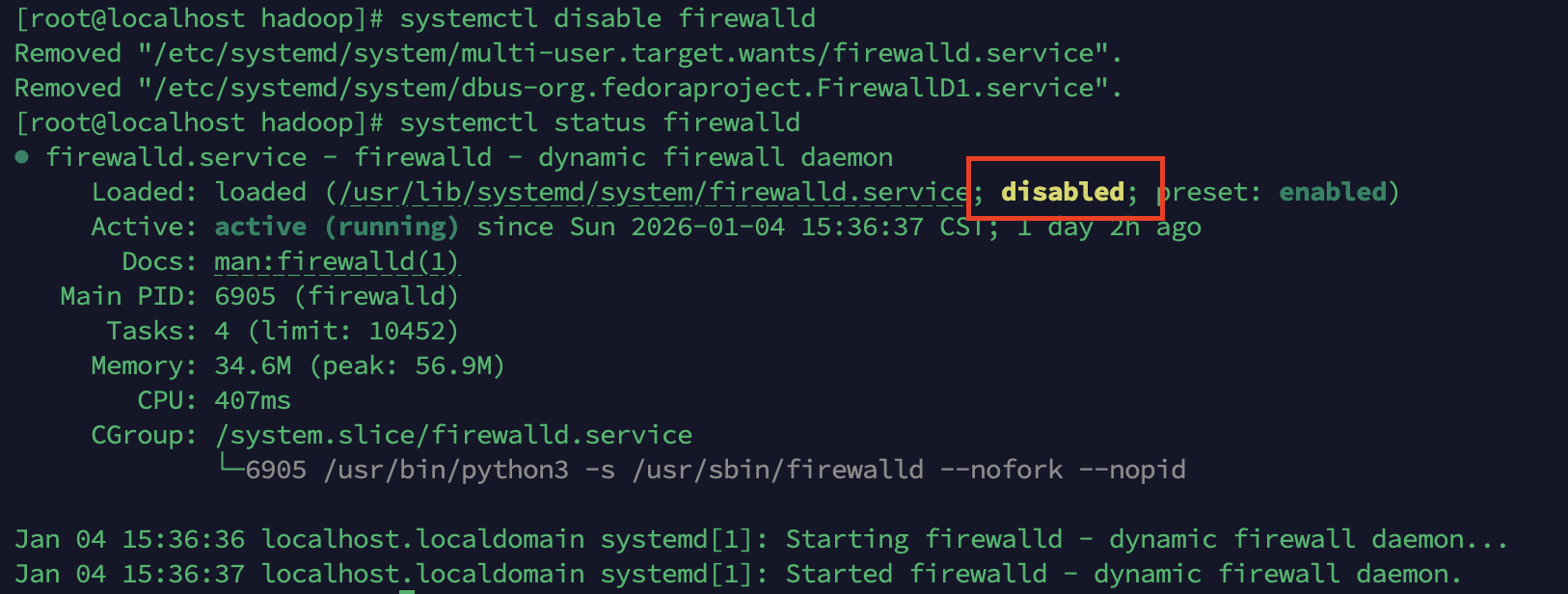
注意:当然根据你的实际需要,开启防火墙状态的命令为
systemctl enable firewalld
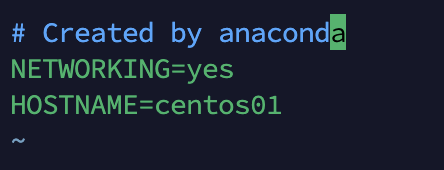
systemctl start firewalld四、配置主机名
vim /etc/sysconfig/network添加以下内容
五、修改hosts文件
vim /etc/hosts添加以下内容,其中ip是我本地ip,可以替换成自己的ip。

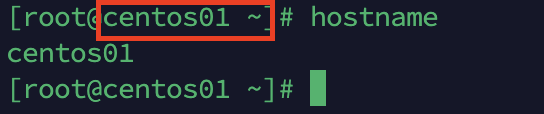
重启系统,执行reboot命令,可以看到主机名已经修改过来了。
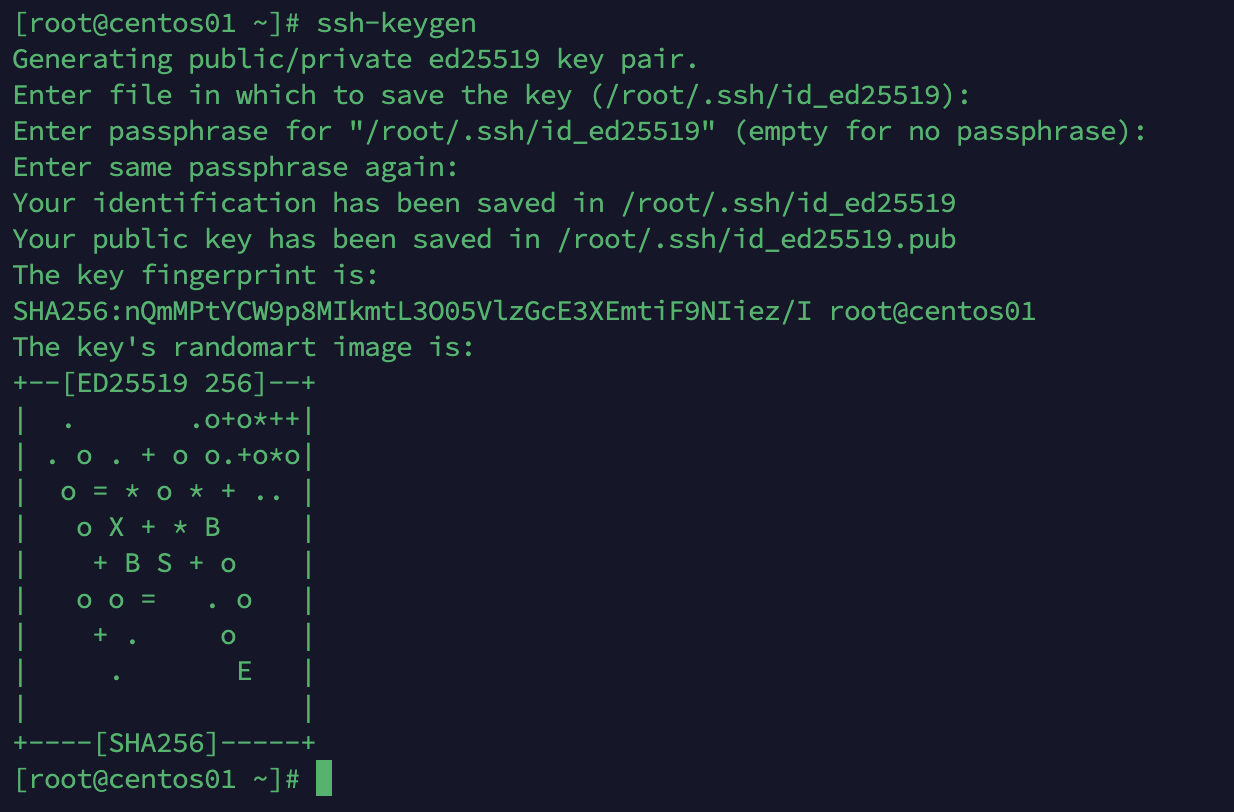
六、配置免密码登录
在centos01节点执行ssh-keygen,然后一直回车
如果是单机的伪分布环境,节点需要登录自己节点,就需要配置自己节点的免密码登录
ssh-copy-id -i /root/.ssh/id_ed25519.pub root@centos01七、安装和配置JDK
就不在这里叙述了,可以参考网上的其他文章,或者我之前的文章
八、上传和解压hadoop
将之前下载的安装包上传到/usr/local/hadoop目录下,并进行解压
tar -xvf hadoop-3.4.2-aarch64-lean.tar九、配置hadoop文件配置,配置文件在/usr/local/hadoop/hadoop-3.4.2/etc/hadoop
主要是修改java路径和hadoop路径
cd /usr/local/hadoop/hadoop-3.4.2/etc/hadoop
vim hadoop-env.sh 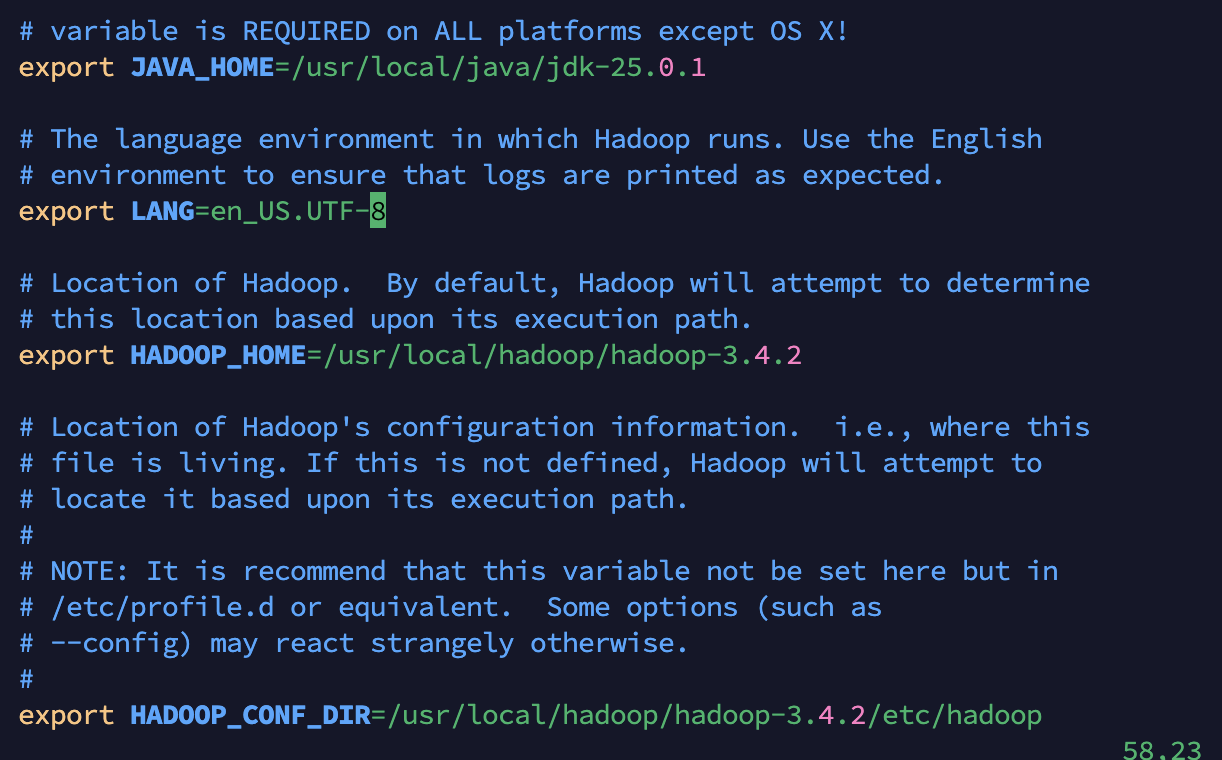 执行 source hadoop-env.sh 让配置立即生效。
执行 source hadoop-env.sh 让配置立即生效。
2)修改 core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://centos01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/hadoop-3.4.2/tmp</value>
</property>
</configuration>需要创建tmp目录。
3)修改 hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>4)修改 mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>5)修改 yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>centos01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>十、配置 slaves 文件,集群所有datanode的主机名


十一、配置hadoop环境变量
export HADOOP_HOME=/usr/local/hadoop/hadoop-3.4.2
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
source /etc/profile 是配置文件生效
十二、格式化namenode
hadoop namenode -format运行中出现以下错误
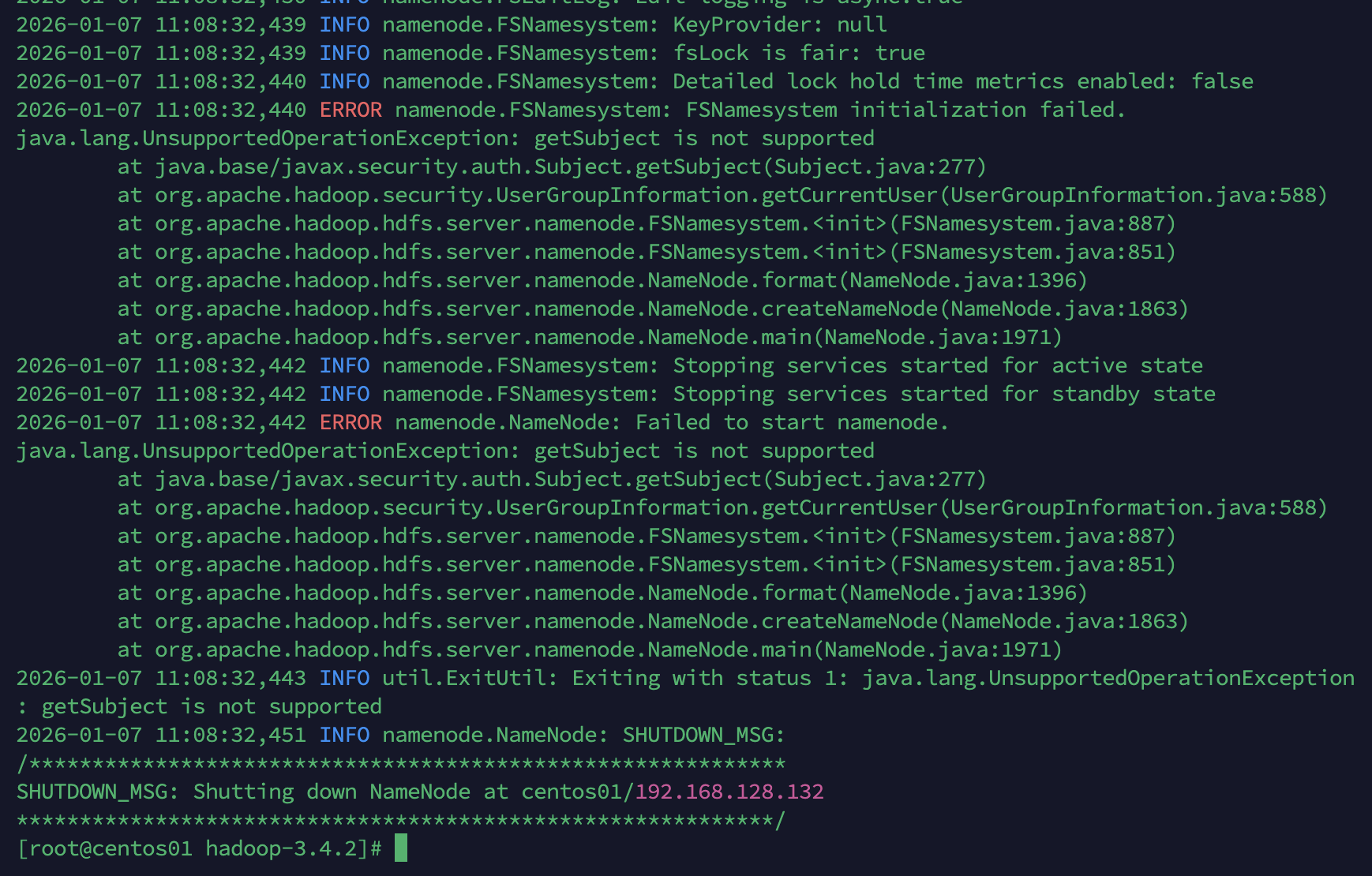
查看问题原因及官方文档,估计是jdk版本匹配不一致。

切换jdk版本,并重新配置hadoop-env.sh
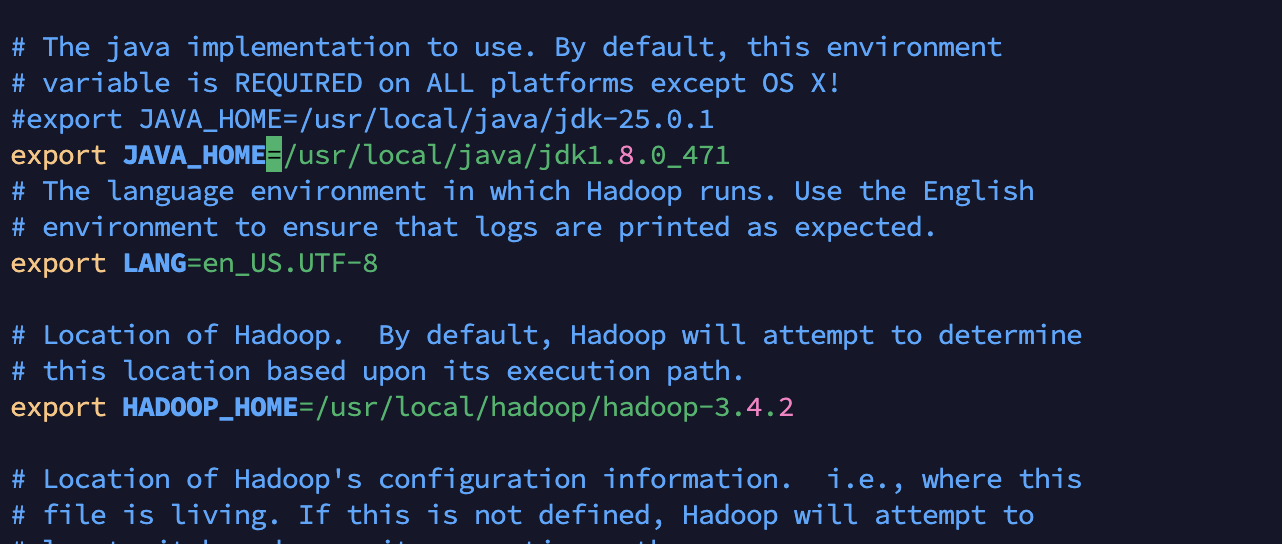
再次执行hadoop namenode -format

格式化成功,说明配置没有问题。
十三、启动hadoop
在sbin目录,执行./start-all.sh
出现以下问题
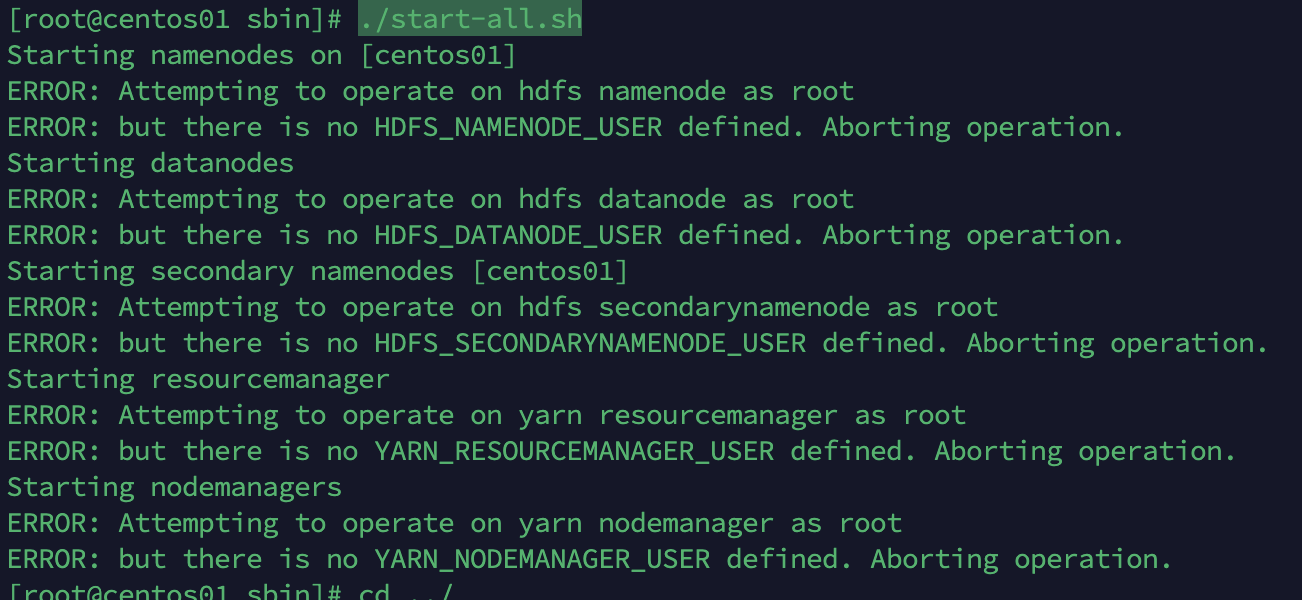
以root用户启动hadoop,出现用户权限问题。
我们可以找一下官方配置,查看和权限有关的选项

我们选择hdfs-default.xml看一下,可以找到以下有关权限的一些描述。

将hdfs-site.xml重新配置
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration>再次执行,发现还是出现以上问题。
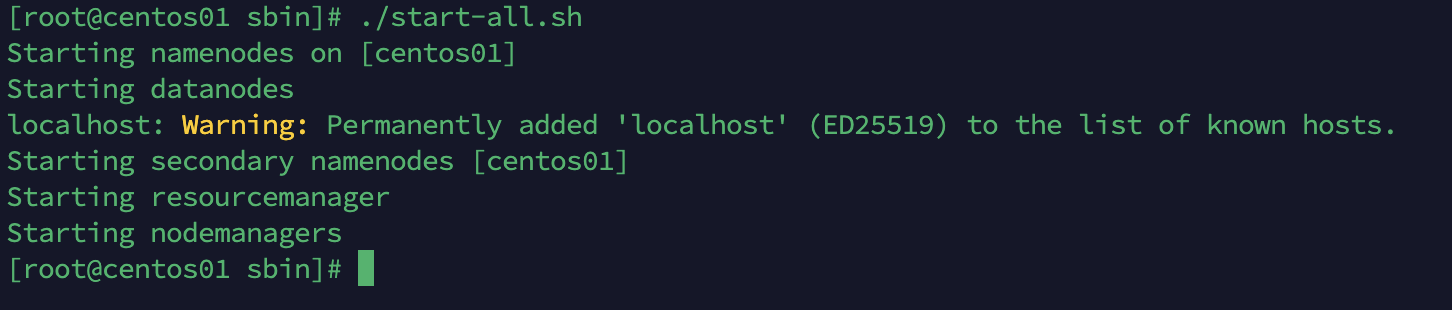
通过网友们发布的帖子,在hadoop-env.sh中设置环境变量,解决了问题。
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root再次执行,启动成功。
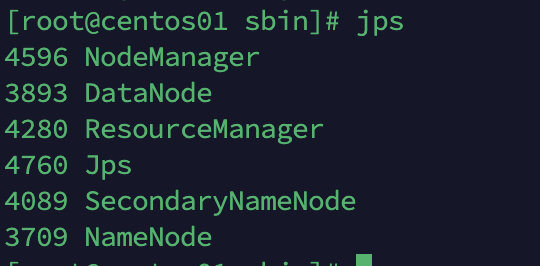
执行jps
通过网址进行访问http://192.168.128.132:8088/
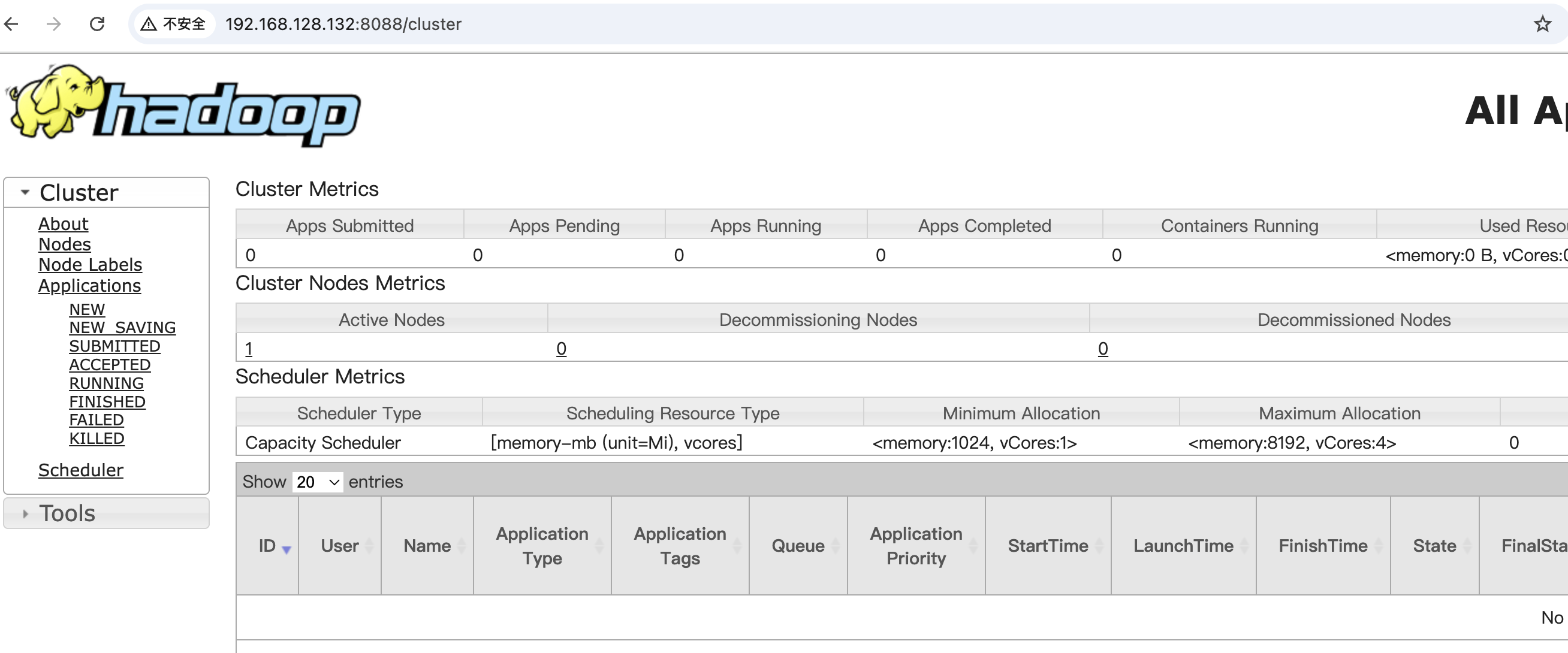
正常访问,单机伪分布模式部署成功。