**摘要:**本文探讨了在云原生环境中,传统 APM(应用性能管理)分布式追踪方案因依赖代码插桩而面临的观测盲点和实施难题,如基础设施组件插桩困难、客户端与服务端响应时间差异大等。针对这些痛点,文章介绍了基于 eBPF 技术的零侵扰分布式追踪解决方案 DeepFlow。该方案通过 eBPF Agent 自动采集全栈调用链数据,无需修改或重启应用,有效解决了 NIO 机制、跨线程处理等复杂场景下的追踪挑战,并借助网关的 X-Request-ID、消息队列的 Correlation ID 等行业规范实现调用链串联。文中还分享了腾讯 IEG 的落地案例,展示了 eBPF 在提升运维效率和可观测性方面的实际价值,并展望了 eBPF 在日志采集、API 拓扑生成等领域的创新探索。
**关键词:**分布式追踪、eBPF、云原生、零侵扰可观测性、DeepFlow、APM、跨线程追踪
一、分布式追踪在云环境下的痛点
首先,这幅图展示了在云原生环境下分布式追踪的一个痛点。APM 的分布式追踪解决方案依靠 Code Instrumentation(代码插桩),比如利用 Java Agent 或引入插桩的 SDK 等。插桩之后,APM 能够回答一次调用的响应时间(Response Time,RT),比如图中客户端 RT 为 500ms,服务端的 RT 是 10ms。真实环境中,有可能服务端不是一个 Java 应用,插桩困难导致无法得知它的响应时间;也有可能服务端是 MySQL 等数据库、Redis 或 Kafka 等中间件,这种情况下一般是无法插桩的。
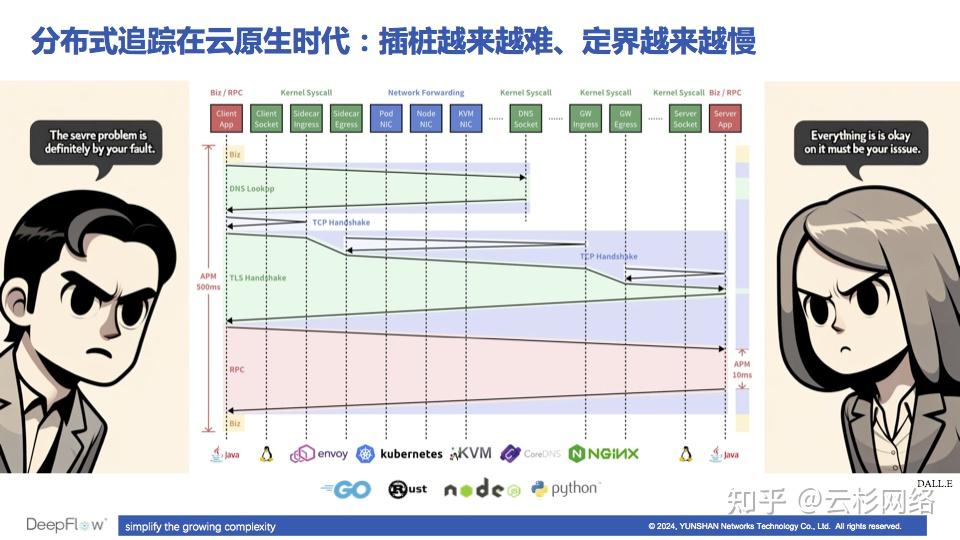 APM 插桩难、定界难的痛点
APM 插桩难、定界难的痛点
即使在最理想的情况下,APM 能回答客户端和服务端的响应时间,也通常会发现类似上图中的情况:客户端看到的响应时间和服务端差距太大。那到底图中的小哥哥、小姐姐谁能说服谁呢?这中间其实有很多交互过程,除了业务逻辑以外,还有 DNS Lookup(K8s 环境下一次 DNS 查询可能涉及到七八次递归查询)、TCP 三次握手、TLS 四次握手,因此我们可以发现在云原生环境下 APM 的分布式追踪其实会有很多观测盲点存在。实际上即使没有上面这些复杂的非业务流程,仅仅是 RPC 调用过程本身,也会因为经过中间繁多的系统调用、容器网络、K8s 网络、网关等环节而一步步引入或大或小的时延,最终导致客户端和服务端观测到的调用时延差距越来越大。
应用插桩困难、基础设施无法插桩所引发的问题,正是 eBPF 技术可以大展拳脚之地。
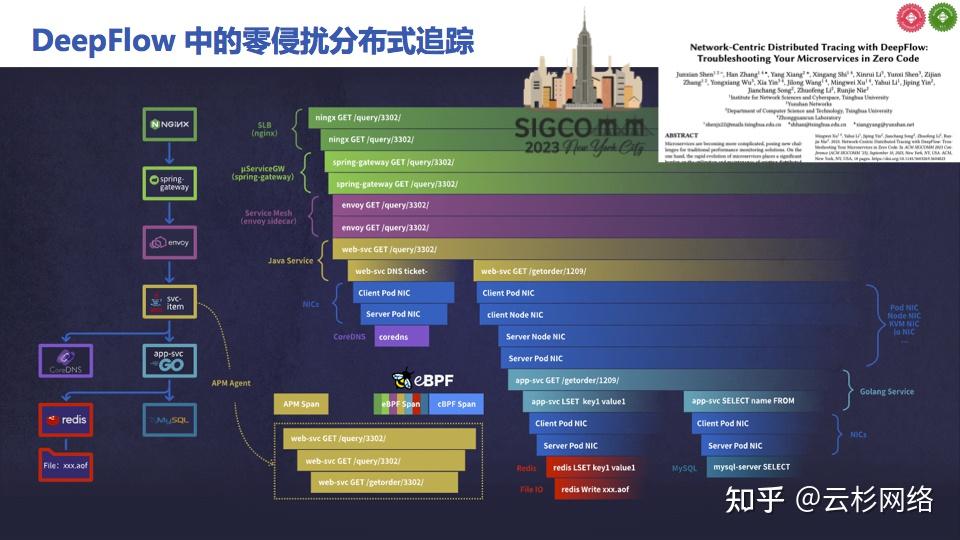 DeepFlow 中的零侵扰分布式追踪能力
DeepFlow 中的零侵扰分布式追踪能力
上图左侧是一个简单的应用拓扑,它的入口是一个 Nginx 网关,接下来是 Spring Cloud Gateway 作为微服务网关,然后进入到 K8s Pod 中的 Envoy Sidecar 中,进而到达一个 Java 业务进程;这个 Java 服务继续请求上游 Golang 服务之前会先做 DNS 解析,上游 Golang 服务继续依赖于 Redis 缓存和 MySQL 数据库,而后者在提供服务时可能会进行一些文件读写。如果只用 Java Agent 这种最便利的 APM 插桩方式的话,看到的分布式追踪可能只有图中黄色部分这么两三个 Span,就是说只能把 Java 应用入口、内部、出口的调用链展现出来。
而 eBPF 在理想的情况下能做到什么样程度呢?只要在每个主机上部署一个独立的 eBPF Agent,不需要对任何业务进程和基础设施进程做修改或重启,就能得到图右侧的完整调用链,它包含了所有业务进程的调用,也包括了与 DNS、缓存、数据库、文件系统之间的调用链。图中除了彩色部分的 eBPF Span 以外,DeepFlow 还通过 cBPF 获取到了每个网卡上的 Span(容器网卡、主机网卡等),并将他们关联到整个 Trace 中,呈现出一个全栈的分布式追踪火焰图。
在真实的业务场景中,调用行为实际上是复杂多样的,可能有异步 调用,也可能出现进程内部的调用链跨线程的情况,如果不对他们做处理会导致零插桩调用链断开,那 DeepFlow 是如何一步步解决其中的问题呢?
二、eBPF 零侵扰分布式追踪的进展
eBPF 的颠覆之处在于它给了一种非常安全的方式,你不止不需要修改或重启进程,还不用担心不同版本 Linux 内核之间的差异,也不用担心会引发内核的内存泄漏或崩溃。eBPF 通过自身的 Verifier 机制保证了代码的内存安全性以及不会进入到死循环中。
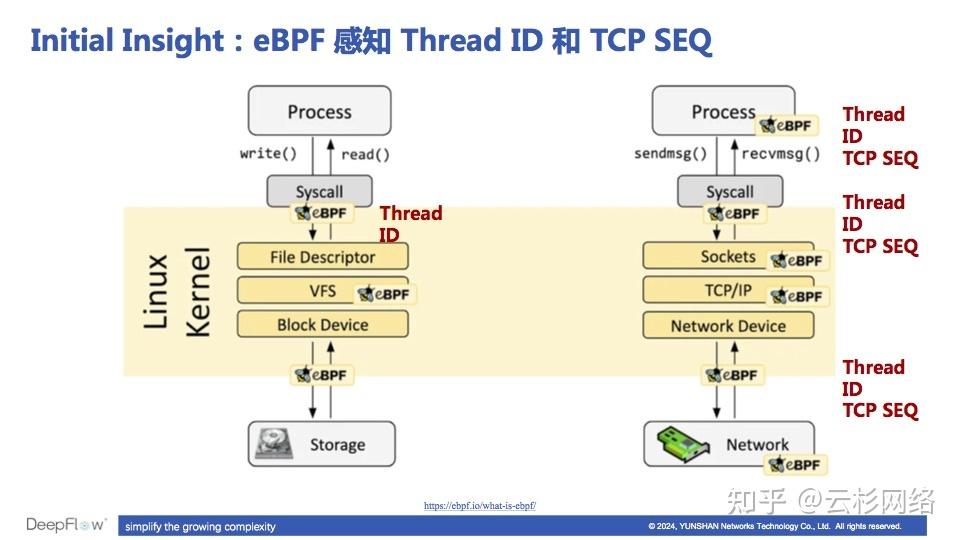 使用 eBPF 实现分布式追踪的关键洞察
使用 eBPF 实现分布式追踪的关键洞察
由于**eBPF 能轻松获知每一个调用在系统中各个位置的 Thread ID 和 TCP SEQ,**我们才能用 eBPF 来实现分布式追踪。例如,可以使用 eBPF uprobe 获取用户态函数的这两个信息,用 kprobe/tracepoint 获取内核系统调用的这两个信息,用 AF_PACKET 获取网卡收发流量时的 TCP SEQ。在这些信息中,DeepFlow 利用 Thread ID 将一个进程入向和出向的调用关联到一个 Trace 中(我们称之为 System Span),同时利用 TCP SEQ 将两个服务之间的调用关联到一个 Trace 中(我们称之为 Network Span)。除此之外,DeepFlow 也会利用 eBPF Hook 文件读写的系统调用,将文件 IO 事件与应用调用之间进行关联,从而构建更加全栈的调用链。
2.1 挑战一:NIO(Non-blocking IO,非阻塞 IO)机制下的追踪
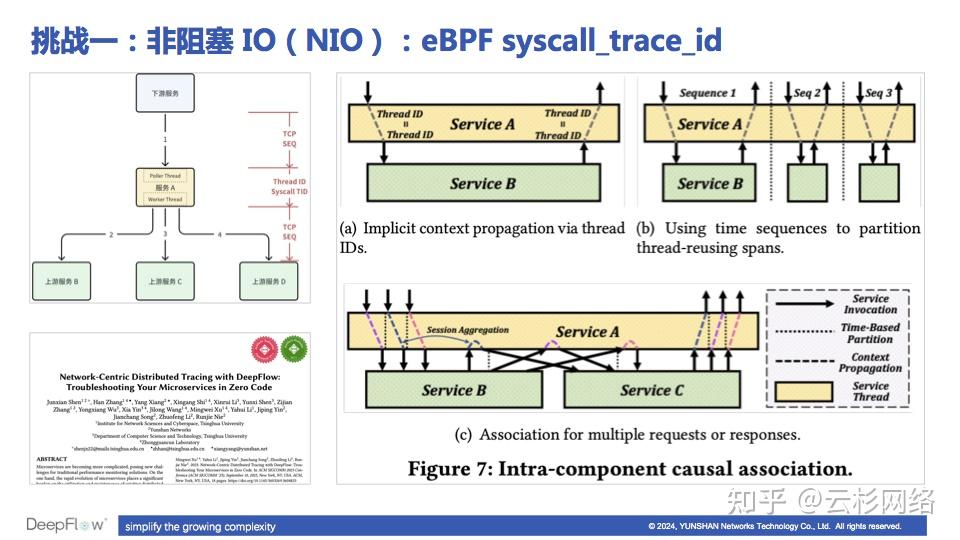 如何解决 NIO 带来的追踪挑战
如何解决 NIO 带来的追踪挑战
想要获取到完整的分布式调用链,仅仅依靠 eBPF 是有很多挑战的,我们遇到的第一个挑战是 NIO(Non-blocking IO,非阻塞 IO)机制下的追踪。
- 图中 (a) 是比较简单的情况,从 Service A 接收调用到向 Service B 发起调用,全部在一个线程内完成,所以我们使用 eBPF 获取调用的 Thread ID 就能关联这个调用链。
- 图中 (b) 展示了更为复杂但更接近真实的情况,Service A 中的线程在被持续复用,此时必须将 Trace 的边界识别出来,使得追踪结果中不要包含多余的调用,很显然我们可以根据时间特征和调用的闭环序列来进行分割,实现对 Trace 的切分。
- 图中 (c) 又更复杂了一些,同时也更贴近真实场景,我们看到 Service A 的线程使用了 NIO 机制,这是一种常见的高性能网络 IO 机制,在 NIO 机制下 Service A 可能会交错的处理多个 Trace 中的调用。
那么 eBPF 能解决 NIO 的场景吗?答案是肯定的,DeepFlow 在 eBPF 程序利用了同一个 Trace 的相邻两次系统调用之间几乎不会有其他 Trace 的调用打断进来 的观察,为每个调用生成了一个无需注入到消息内容中的 syscall_trace_id,利用一系列 syscall_trace_id 就可以将图中紫、蓝、粉三个颜色的 Trace 区分开。这张图片是整个追踪逻辑的一个简化示意图,大家可以阅读 GitHub 代码来了解更多的细节。
2.2 挑战二:业务逻辑跨线程处理
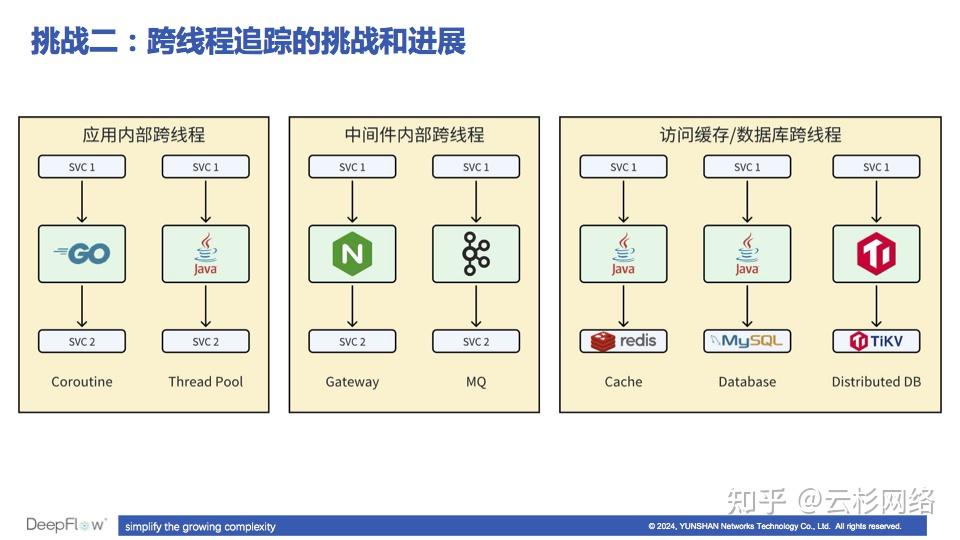 eBPF 分布式追踪面临的跨线程挑战
eBPF 分布式追踪面临的跨线程挑战
面临第二个挑战 ------ 业务逻辑跨线程处理。跨线程的场景很多,例如:
- 应用程序内部跨线程,应用接收和应答调用与处理业务逻辑的线程不一样;
- 中间件内部跨线程,网关和消息队列等中间件与客户端(下游)通信的线程和与服务端(上游)通信的线程不一样;
- 访问缓存和数据库时跨线程,应用访问 Redis 缓存、数据库,以及分布式数据库进程内部处理一个 SQL 命令时跨线程。
第一个思路是利用协程、Socket 的「生命周期」来进行追踪。
 利用「生命周期」解决跨线程追踪问题
利用「生命周期」解决跨线程追踪问题
比如对于 Golang 语言的应用而言,由于 Golang 是一个原生的协程语言,不能通过 Thread ID 来进行调用链追踪。但我们知道一个 Golang 应用为了处理它所提供的 API,会将所有阻塞调用使用 Goroutine 运行,稍加分析就会发现,这种在协程 A 内接收 API 请求、在协程 B/C/D/... 内继续请求上游依赖服务 的场景,可以使用 eBPF uprobe 观测协程的生命周期,例如当关注到协程 B/C/D/... 是由协程 A 创建的,此时可以将 A/B/C/D/... 等协程标记上同样的 Pseudo Thread ID,从而将这个问题转化为一个线程语言的调用链追踪问题。
比如对于一些网关服务而言,可以跟踪 Socket 的生命周期来实现跨线程追踪。例如在 Nginx 中,一个与 upstream 之间建立的 Socket 通常是在线程 A 中创建的、在另一个线程 B 中使用的,我们会在 eBPF 程序中跟踪这个 Socket 的创建和读写,从而利用 Socket 的生命周期关联在一段时间内有业务联系的两个线程中的 Socket。
再比如说 Tomcat,它的 Acceptor Thread 是接收请求的,除此之外还有个 Poller Thread 是去监听请求的读写就绪事件,监听对应的 FD 上是不是读写就绪了。但是它见听到可读或可写时,不会直接进行读写,而是将事件发送给 Worker Thread 进行处理。也就是说,实际上 Socket 的读写动作已经在同一个线程中了。Dubbo 也是类似的,当它使用 DirectDispather 时 IO 线程也会承担业务处理的职责,因此在 IO 线程中可以直接将调用链追踪出来。
第二个思路是利用网关、消息队列的一些「事实标准」进行追踪。
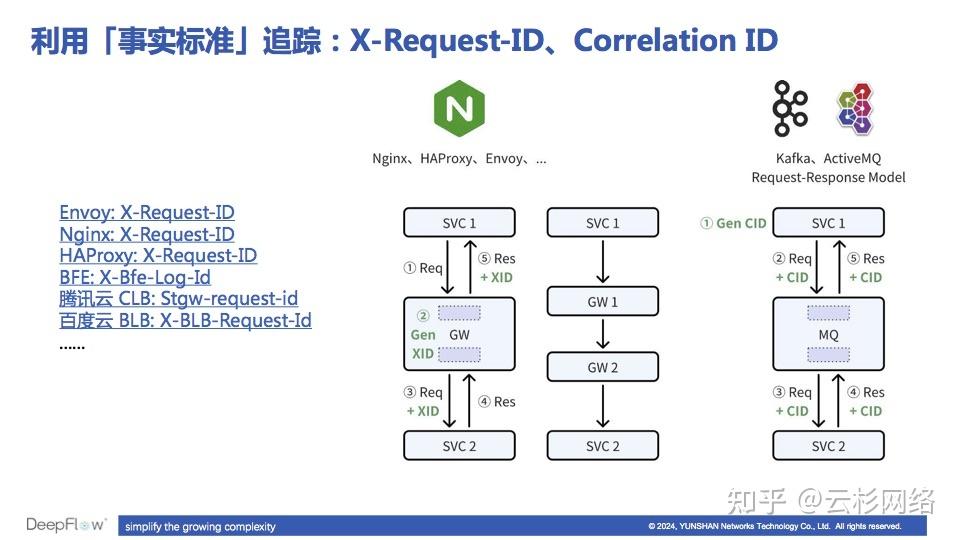 利用「事实标准」解决跨线程追踪问题
利用「事实标准」解决跨线程追踪问题
同样不需要应用做任何的改造,只需要对基础设施或中间件做一些配置调整,即可将中间件前后的调用链自动串联起来。比如几乎对于所有应用层网关 而言,Nginx、HAProxy、BFE、Envoy、各家云网关等,都支持向 HTTP 消息中自动注入 X-Request-ID 头字段。当网关接收到一个请求时,它会生成一个随机的 UUID,即 X-Request-ID 并注入到发往 upstream 的请求头中;待接到 upstream 的响应以后,网关会查询为对应的请求生成的 X-Request-ID 并将它注入到对客户端的响应头中。所以,我们通过解析 HTTP Header 中用于表达 X-Request-ID 含义的头字段,就能将网关前后的 HTTP 调用关联起来。不论流量经过了几级网关,只要其中有一级网关开启了 X-Request-ID,整个调用链就都能依靠它完整的追踪出来。
例如消息队列 ,虽然纯异步的消息通信缺少追踪信息可以利用,但如果应用使用消息队列来实现 Request-Response 模式的通信时,一定会有额外特征可提供追踪信息。例如 Kafka 和 ActiveMQ 的协议中就会要求存在一个用于请求、响应关联的 Correlation ID 字段。实际上业务方也是强依赖这个 ID 的,只有客户端能从响应消息中获取到这个 Correlation ID,才能将它和对应的请求关联匹配上来。因为有了这样的关联信息,DeepFlow 能自动将跨越消息队列的调用追踪出来,同样不需要应用做任何改造。
第三个思路是利用「行业规范」来进行追踪。
 利用「行业规范」解决跨线程追踪问题
利用「行业规范」解决跨线程追踪问题
在具体的业务场景中,通常有一些用于跟踪业务流程的唯一标识字段,例如金融行业的交易流水号。DeepFlow Agent 上支持编写 Wasm Plugin,因此即使对于这些业务相关的信息,也可以非常便捷的通过编写一个 Golang 等语言的 Plugin 来实现业务追踪 ID 的提取。
除了提取业务追踪 ID 以外, Wasm Plugin 的能力会更加丰富,例如提取 Json、XML、Protobuf 的消息体中的 User ID、Order ID 等业务字段,以及扩展 DeepFlow Agent 内置的协议解析能力。
三、DeepFlow 用户的典型落地案例
分享一个典型用户的落地案例,腾讯 IEG 对 DeepFlow 的使用显著提高工作效率。
 腾讯 IEG 的使用案例
腾讯 IEG 的使用案例
上图左侧是 DeepFlow 社区版最近发布的一个开箱即用 Dashboard。社区版仅支持 Grafana GUI,在此之前我们已经内置了丰富的 Dashboard,但对于新上手的用户会感到无所适从,而且不同的 Panel 之间无法联动,分析能力较弱。这个开箱即用的 Dashboard 将接口的性能指标、调用日志、分布式追踪在一个 Grafana 面板上展现出来,并且 Panel 之间支持点击联动。
作为一个游戏业务的运维人员,因为有了零侵扰可观测性能力,它不用再去驱动开发者修改代码进行插桩。以腾讯 IEG 为例,除了有自研游戏以外,他们还有很多代理游戏,难以推动这些第三方开发的游戏进行 APM 插桩。即使是自研游戏,通常也是使用 C++ 等编译型语言实现,一方面必须使用 SDK 插桩,另一方面也要求运维团队能构建 C++ 技术栈从而长期维护 SDK。总结来讲就是推动插桩难、维护插桩 SDK 难,eBPF 能很好的解决这两个痛点。
在腾讯 IEG,DeepFlow 已经覆盖了很多游戏业务,不仅用于事后的故障排查,已经融入了业务变更之前的依赖确认、扩缩容过程中的性能监测、业务发版之后的性能对比、基础设施的性能优化等工作,显著提高了研发和运维团队的工作效率。
四、探索 eBPF 可观测性能力的边界
- 如何彻底解决跨线程的调用链串联问题?
除了有之前介绍的各种方法以外,最近我们也在实验一些统计推理的方法。像这张图里面展示的那样,是否可以通过大量数据的统计,来智能的推理出一个应用的 Ingress 调用和 Egress 调用之间的关联关系?目前我们已经做了一些实验,发现推理结果随数据量的增长可以得到非常可观的改善,再结合 eBPF USDT 能力,预期可以得到非常准确的分布式调用链。这个探索能将我们在跨线程场景下的零侵扰追踪能力前进一大步。
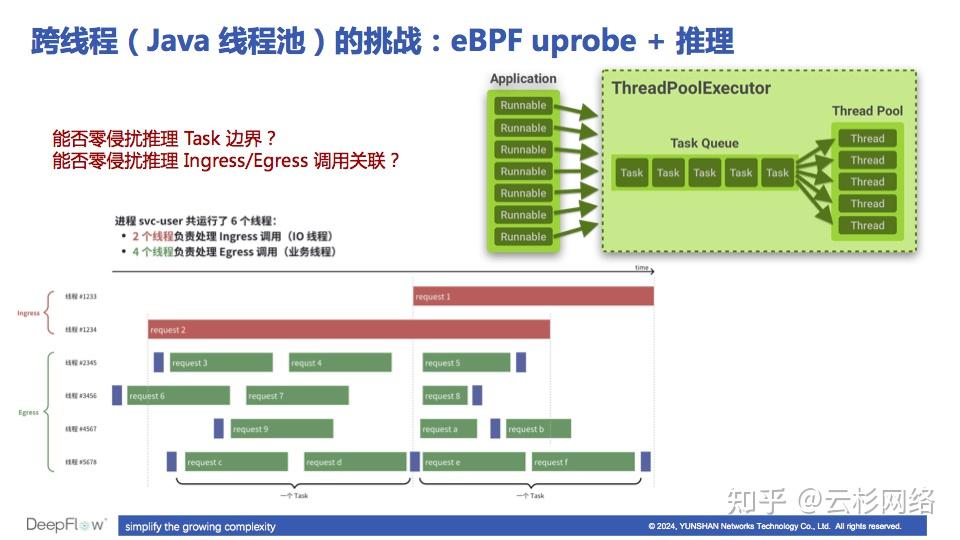 如何利用统计推理的方式解决 Java 应用跨线程追踪问题
如何利用统计推理的方式解决 Java 应用跨线程追踪问题
- 如何基于 eBPF 的调用日志生成 API 拓扑?
这里面的主要挑战在于,直接使用调用日志数据只能生成服务拓扑,这类拓扑会在网关、消息队列处连接上一大片服务,打破业务的边界,不易于业务方使用;而直接使用 Trace 数据时,由于 Span 中缺乏 TraceID(在没有 APM 插桩的情况下),难以将一个 Trace 的所有 Span 发往一台机器上聚合。
在这个问题上我们正在进行两方面的探索:首先通过网关的 X-Request-ID 和消息队列的 Topic 信息,计算这些中间件前后的服务的关联关系,避免服务拓扑的爆炸,提供一个「有业务边界」的服务拓扑;其次利用 Linux 5.10 内核中的 eBPF 新能力,尝试将 DeepFlow 的 syscall_trace_id 注入到 TCP Option 中,从而为一个 Trace 中的每条调用日志标记上唯一的 Trace ID,便于将调用日志聚合为 API 拓扑。
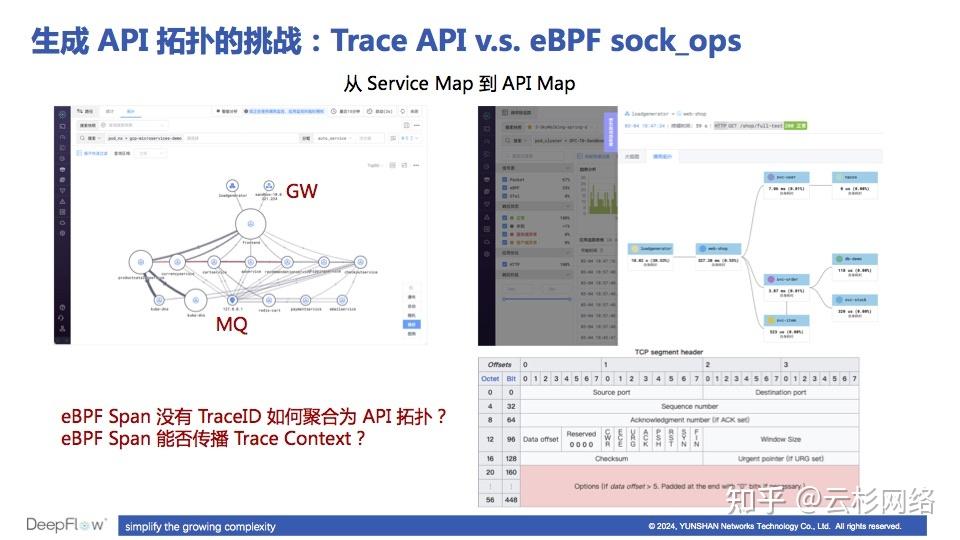 如何基于 eBPF 数据生成 API 拓扑
如何基于 eBPF 数据生成 API 拓扑
- eBPF 在第三大可观测性信号------日志的创新探索
一方面 eBPF 的采集方式无需日志落盘,能够降低日志读写的资源开销;另外 eBPF 采集到的数据可以利用 Thread ID 和追踪数据天然关联起来,天然消除了数据孤岛。
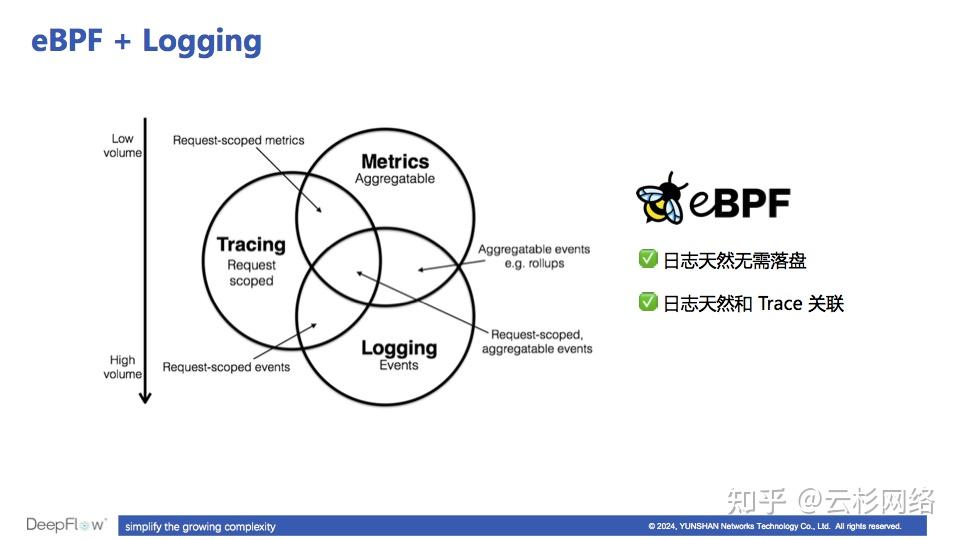 eBPF 采集应用日志的创新点
eBPF 采集应用日志的创新点