1. 支持的服务/产品
| 组件 | 服务 | 状态 | 说明 |
|---|---|---|---|
| 主数据库 | PostgreSQL | ✅ 支持 | 12+ 版本,推荐 15+ |
| 缓存 | Redis | ✅ 支持 | 6.0+,支持单机/哨兵/集群 |
| ORM | SQLAlchemy | ✅ 支持 | 2.x 版本 |
| 迁移 | Flask-Migrate/Alembic | ✅ 支持 | 数据库版本管理 |
2. 架构与组件交互
Dify 采用 PostgreSQL + Redis + Celery 的经典架构。PostgreSQL 作为主数据库提供持久化,Redis 提供缓存与消息队列支持,Celery 负责异步任务处理。
2.1 核心交互图
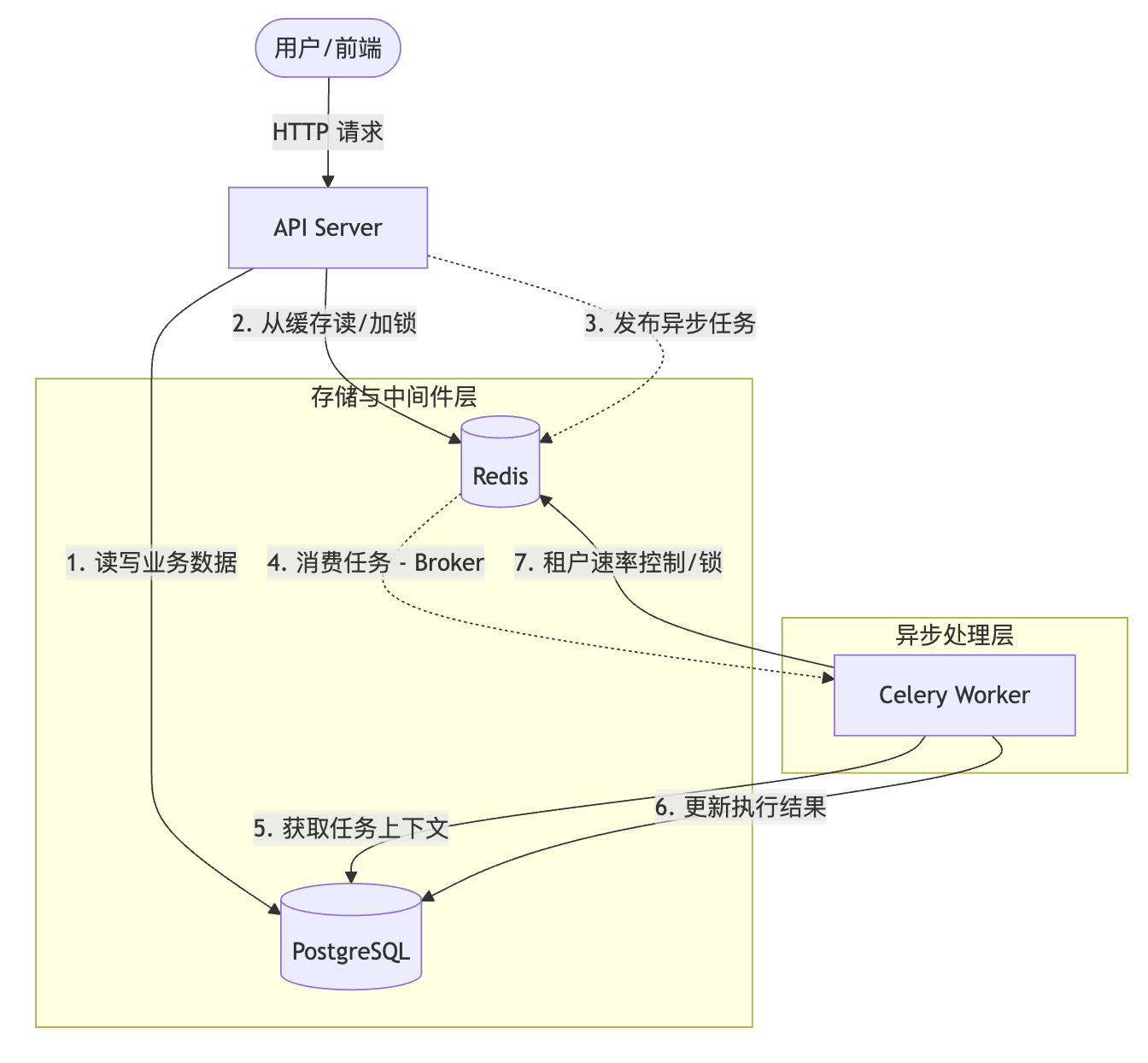
2.2 组件职责与使用场景
| 组件 | 角色 | 在 Dify 中的核心场景 | 交互关系 |
|---|---|---|---|
| PostgreSQL | Source of Truth | • 配置存储 : App, Dataset, Document 等核心实体 • 业务记录 : Message, Conversation, Run Logs • 关联映射: 向量库索引 ID 的映射 | 供 API 和 Celery 读写,保证数据一致性。 |
| Redis | 高速枢纽 | • Celery Broker : 异步任务消息队列 • 分布式锁 : 索引构建、应用更新时的并发控制 • 租户队列 : 通过 TenantIsolatedTaskQueue 实现租户级任务限流 • Cache: 接口响应缓存、Session 存储 |
连接 API 与 Worker,协调并发。 |
| Celery | 异步执行器 | • RAG 流程 : 文件解析 (Parsing)、切片 (Chunking)、向量化 (Embedding) • Agent 执行 : 运行耗时较长的工作流节点 • 系统任务: 邮件发送、数据清理 | 消费 Redis 中的任务,处理后更新 PG 状态。 |
2.3 关键交互流程:文档索引
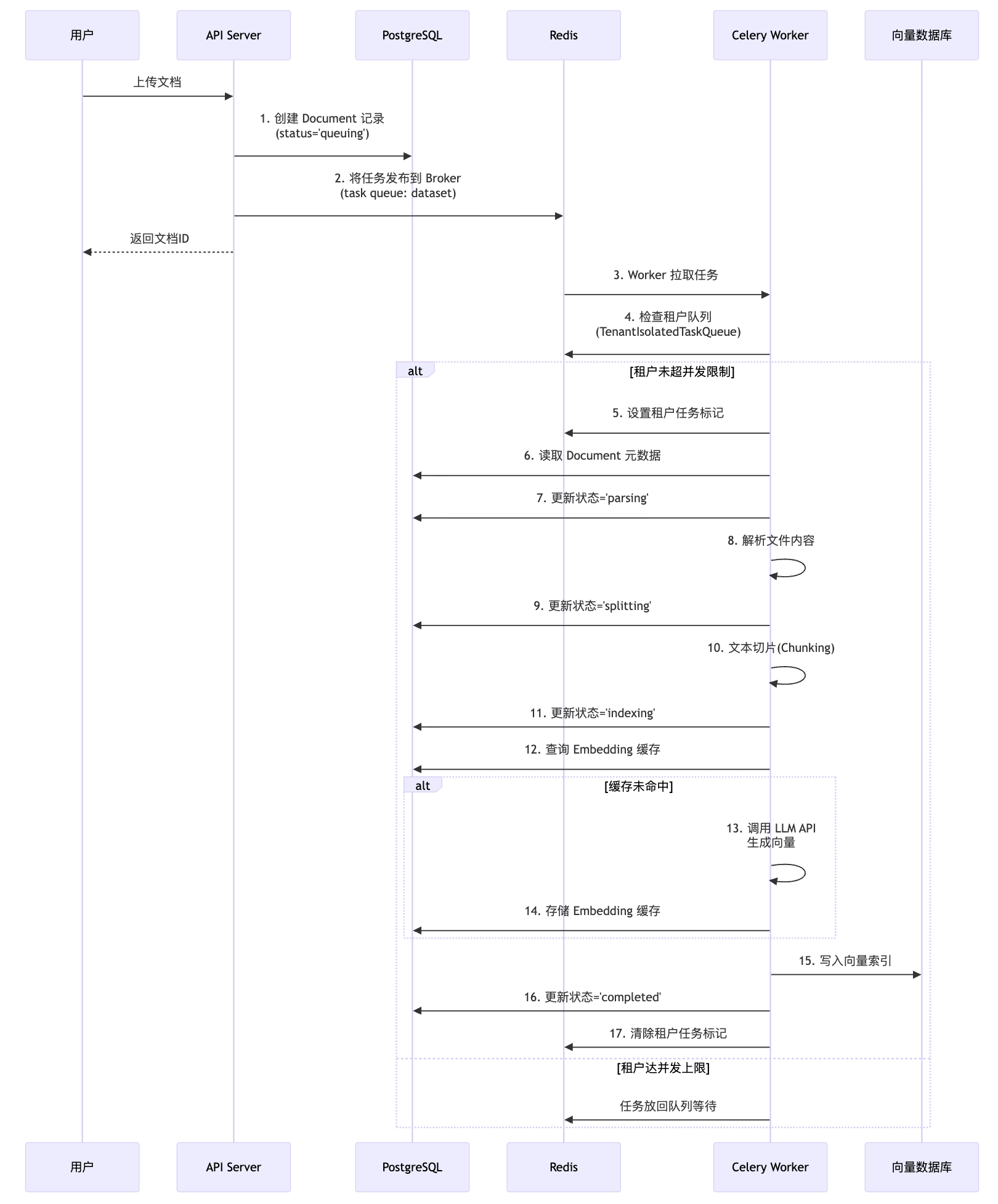
流程说明:
-
API 层 (步骤 1-2):
- 将文档元数据写入 PostgreSQL,初始状态为
queuing。 - 通过
shared_task.delay()将任务发布到 Redis (Celery Broker)。
- 将文档元数据写入 PostgreSQL,初始状态为
-
任务调度 (步骤 3-5):
- Worker 从 Redis 获取任务。
- 检查
TenantIsolatedTaskQueue(Redis 中的 List + TTL Key),确保该租户的并发任务数未超过限制 (TENANT_ISOLATED_TASK_CONCURRENCY)。
-
文档处理 (步骤 6-16):
- Worker 从 PostgreSQL 读取完整的文档上下文。
- 依次执行 解析 (Parsing) → 切片 (Splitting) → 向量化 (Indexing)。
- 关键优化 : Embedding 结果直接缓存在 PostgreSQL 的
embeddings表中(而非 Redis),避免重复调用 LLM API。 - 最终将向量写入外部向量数据库,并更新 PostgreSQL 中的文档状态。
2.4 PostgreSQL 在 Dify 中的使用场景
📌 源代码引用 : api/models/, api/core/rag/embedding/cached_embedding.py
| 场景分类 | 具体表/模型 | 用途 | 关键特性 |
|---|---|---|---|
| 核心实体 | accounts, tenants |
用户与租户信息 | 提供身份认证与多租户隔离 |
datasets, documents, document_segments |
知识库与文档数据 | 存储 RAG 流程的元数据与切片 | |
apps, workflows |
应用与工作流配置 | 存储 Agent 编排逻辑 | |
| 运行记录 | messages, conversations |
对话历史 | 支持上下文管理与追溯 |
workflow_runs, workflow_node_executions |
工作流执行日志 | 记录每个节点的输入输出 | |
| 索引映射 | dataset_keyword_tables |
全文索引关联 | 关联向量数据库中的索引 ID |
| 缓存优化 | embeddings |
Embedding 缓存 | 缓存文本向量,避免重复调用 LLM |
关键设计:
- Embedding 缓存使用 PostgreSQL 而非 Redis :因为向量数据体积较大,存储在数据库中便于持久化和定期清理(通过 Celery 定时任务
clean_embedding_cache_task)。 - 事务保证 :通过 SQLAlchemy 的
db.session确保文档状态更新的原子性。
2.5 Redis 在 Dify 中的使用场景
📌 源代码引用 : api/extensions/ext_redis.py, api/core/rag/pipeline/queue.py
| 场景分类 | Redis 数据结构 | 用途 | 代码实现 |
|---|---|---|---|
| Celery Broker | String/List | 存储异步任务消息 | CELERY_BROKER_URL=redis://... |
| 租户任务队列 | List + Key | 实现 TenantIsolatedTaskQueue,限制单租户并发索引数 |
redis_client.lpush() + redis_client.setex() |
| 分布式锁 | String (SET NX) | 防止并发操作(如同时更新同一应用) | redis_client.lock() |
| 会话存储 | Hash | 存储用户 Session(如有配置) | Flask-Session 集成 |
| Pub/Sub | Pub/Sub | 实时消息推送(如工作流状态变更通知) | redis_client.publish() |
关键设计:
- 租户隔离机制 :每个租户有独立的队列
tenant_self_document_indexing_task_queue:{tenant_id},配合 TTL Keytenant_document_indexing_task:{tenant_id}实现并发控制。 - 支持多种部署模式 :单机、哨兵 (Sentinel)、集群 (Cluster),通过
RedisClientWrapper统一封装。
2.6 Celery 在 Dify 中的使用场景
📌 源代码引用 : api/tasks/, api/extensions/ext_celery.py
| 任务类别 | 典型任务 | 队列名称 | 触发方式 |
|---|---|---|---|
| RAG 索引 | normal_document_indexing_task |
dataset |
API 调用 .delay() |
priority_document_indexing_task |
priority_dataset |
付费用户优先处理 | |
| 工作流执行 | async_workflow_tasks |
workflow |
异步工作流节点 |
| 邮件通知 | send_invite_member_mail_task |
mail |
用户邀请、密码重置等 |
| 定时清理 | clean_embedding_cache_task |
dataset |
Celery Beat 定时 (每月 2 日凌晨 2 点) |
clean_unused_datasets_task |
dataset |
清理未使用的知识库 |
队列设计:
- 优先级队列 :
priority_dataset队列用于付费用户,Worker 优先消费该队列。 - 隔离策略 :
mail队列独立运行,避免大量邮件任务阻塞核心业务。
定时任务 (Celery Beat):
- 通过
crontab配置周期性任务,如每月清理过期的 Embedding 缓存。 - 所有定时任务的开关在
dify_config中控制(如ENABLE_CLEAN_EMBEDDING_CACHE_TASK)。
3. PostgreSQL 集成
3.1 配置
⚠️ 配置示例: 以下为环境变量配置示例
bash
# 数据库连接配置
DB_USERNAME=postgres
DB_PASSWORD=your_password
DB_HOST=db
DB_PORT=5432
DB_DATABASE=dify
# 连接池配置
SQLALCHEMY_POOL_SIZE=30
SQLALCHEMY_POOL_RECYCLE=3600
SQLALCHEMY_ECHO=false3.2 连接管理
📌 源代码引用:
- api/models/engine.py -
db对象定义- api/extensions/ext_database.py - 数据库初始化
python
# api/models/engine.py - 源代码引用
from sqlalchemy.orm import DeclarativeBase, MappedAsDataclass
class Base(MappedAsDataclass, DeclarativeBase):
pass
db = SQLAlchemy(model_class=Base)
# api/extensions/ext_database.py - 概念性示例
def init_app(app):
db.init_app(app)
# 配置连接池
app.config['SQLALCHEMY_ENGINE_OPTIONS'] = {
'pool_size': 30,
'pool_recycle': 3600,
'pool_pre_ping': True,
}3.3 模型定义
⚠️ 概念性示例: 以下代码为演示 SQLAlchemy 模型定义的概念性示例
📌 实际项目模型可参考: api/models/
python
from models.engine import db
class Account(db.Model):
__tablename__ = 'accounts'
id = db.Column(db.String(255), primary_key=True)
name = db.Column(db.String(255), nullable=False)
email = db.Column(db.String(255), unique=True, nullable=False)
created_at = db.Column(db.DateTime, default=db.func.now())3.4 查询操作
⚠️ 概念性示例: 以下代码为演示 SQLAlchemy 查询操作的概念性示例
python
# 查询
account = db.session.query(Account).filter_by(email=email).first()
# 插入
new_account = Account(id=id, name=name, email=email)
db.session.add(new_account)
db.session.commit()
# 更新
account.name = new_name
db.session.commit()
# 删除
db.session.delete(account)
db.session.commit()4. Redis 集成
4.1 配置
⚠️ 配置示例: 以下为环境变量配置示例
bash
# Redis 单机模式
REDIS_HOST=redis
REDIS_PORT=6379
REDIS_DB=0
REDIS_PASSWORD=your_password
REDIS_USE_SSL=false
# Redis 哨兵模式
REDIS_USE_SENTINEL=true
REDIS_SENTINELS=sentinel1:26379,sentinel2:26379
REDIS_SENTINEL_SERVICE_NAME=mymaster
REDIS_SENTINEL_USERNAME=sentinel_user
REDIS_SENTINEL_PASSWORD=sentinel_password
# Redis 集群模式
REDIS_USE_CLUSTER=true
REDIS_CLUSTER_NODES=node1:6379,node2:6379,node3:63794.2 连接管理
📌 源代码引用 : api/extensions/ext_redis.py
python
# api/extensions/ext_redis.py - 源代码引用(简化版)
import redis
from redis.sentinel import Sentinel
from redis.cluster import RedisCluster
class RedisClientWrapper:
"""Redis client wrapper supporting multiple connection modes"""
def __init__(self) -> None:
self._client = None
def initialize(self, client: Union[redis.Redis, RedisCluster]) -> None:
"""Initialize the Redis client"""
if self._client is not None:
raise RuntimeError("Redis client has already been initialized")
self._client = client
def __getattr__(self, item):
if self._client is None:
raise RuntimeError("Redis client is not initialized")
return getattr(self._client, item)
redis_client = RedisClientWrapper()4.3 使用示例
⚠️ 概念性示例: 以下代码为演示 Redis 操作的概念性示例
python
from extensions.ext_redis import redis_client
# 字符串操作
redis_client.set('key', 'value')
value = redis_client.get('key')
# 设置过期时间
redis_client.setex('key', 3600, 'value') # 1小时过期
# Hash 操作
redis_client.hset('user:123', 'name', 'John')
redis_client.hget('user:123', 'name')
# List 操作
redis_client.lpush('queue', 'task1')
task = redis_client.rpop('queue')
# Set 操作
redis_client.sadd('tags', 'python', 'flask')
members = redis_client.smembers('tags')
# 分布式锁
lock = redis_client.lock('my_lock', timeout=10)
if lock.acquire(blocking=False):
try:
# 执行需要加锁的操作
pass
finally:
lock.release()5. Celery 集成
5.1 配置
⚠️ 配置示例: 以下为环境变量配置示例
bash
# Celery Broker (Redis)
CELERY_BROKER_URL=redis://redis:6379/1
# Celery Backend (可选)
CELERY_RESULT_BACKEND=redis://redis:6379/25.2 任务定义
📌 源代码引用 : api/extensions/ext_celery.py - Celery 实例定义
⚠️ 概念性示例 : 以下任务定义为概念性示例,实际任务定义见各模块的
tasks.py文件
python
# api/extensions/ext_celery.py - 源代码引用
from celery import Celery
celery = Celery(__name__)
# 概念性示例:异步任务定义
@celery.task
def process_document(document_id):
"""异步处理文档"""
# 处理逻辑
pass
# 调用任务
process_document.delay(document_id='doc_123')6. 数据迁移
📌 实际命令: 以下为项目中实际使用的迁移命令
6.1 创建迁移
bash
# 创建新迁移
uv run --project api flask db migrate -m "Add new column"
# 应用迁移
uv run --project api flask db upgrade
# 回滚迁移
uv run --project api flask db downgrade6.2 迁移文件
⚠️ 概念性示例: 以下代码为演示迁移文件结构的概念性示例
📌 实际迁移文件见: api/migrations/versions/
python
# api/migrations/versions/xxx_add_column.py
def upgrade():
op.add_column('accounts',
sa.Column('phone', sa.String(20), nullable=True)
)
def downgrade():
op.drop_column('accounts', 'phone')7. 性能优化
⚠️ 概念性示例: 本节所有代码为演示性能优化模式的概念性示例
7.1 数据库优化
python
# 使用索引
class Account(db.Model):
email = db.Column(db.String(255), index=True)
created_at = db.Column(db.DateTime, index=True)
# 批量查询
accounts = db.session.query(Account).filter(
Account.id.in_(account_ids)
).all()
# 预加载关联对象
from sqlalchemy.orm import joinedload
accounts = db.session.query(Account).options(
joinedload(Account.tenant)
).all()7.2 Redis 缓存模式
python
def get_user_with_cache(user_id):
"""带缓存的用户查询"""
cache_key = f"user:{user_id}"
# 尝试从缓存获取
cached = redis_client.get(cache_key)
if cached:
return json.loads(cached)
# 从数据库查询
user = db.session.query(User).get(user_id)
# 写入缓存
redis_client.setex(cache_key, 3600, json.dumps(user.to_dict()))
return user8. 监控与日志
⚠️ 概念性示例: 以下代码为演示监控与日志模式的概念性示例
python
# 数据库慢查询日志
import logging
from sqlalchemy import event
from sqlalchemy.engine import Engine
logger = logging.getLogger(__name__)
@event.listens_for(Engine, "before_cursor_execute")
def before_cursor_execute(conn, cursor, statement, parameters, context, executemany):
conn.info.setdefault('query_start_time', []).append(time.time())
@event.listens_for(Engine, "after_cursor_execute")
def after_cursor_execute(conn, cursor, statement, parameters, context, executemany):
total = time.time() - conn.info['query_start_time'].pop(-1)
if total > 1.0: # 慢查询阈值 1 秒
logger.warning(f"Slow query ({total:.2f}s): {statement}")