提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 一、简介
- 二、数据集构建与处理
-
- [2.1 数据集概况](#2.1 数据集概况)
- [2.2 数据集结构](#2.2 数据集结构)
- [2.3 数据集示例分布](#2.3 数据集示例分布)
- 三、环境搭建、验证
-
- [3.1 环境搭建](#3.1 环境搭建)
- [3.2 验证](#3.2 验证)
- 四、模型训练、评估及推理
- [4.1 配置文件dataset.yaml](#4.1 配置文件dataset.yaml)
- [4.2 模型训练](#4.2 模型训练)
- [4.3 性能评估](#4.3 性能评估)
- [4.4 模型推理](#4.4 模型推理)
- 五、模型部署
- [5.1 onnx模型](#5.1 onnx模型)
- [5.2 安卓模型部署](#5.2 安卓模型部署)
一、简介
在"明厨亮灶"食品安全监管体系下,后厨环境的实时监控已成为行业标准。然而,传统人工巡检方式存在检测效率低、实时性差、易漏检等痛点。对于厨师安全着装,以及老鼠,蟑螂等害虫,实现快速精准检测,以保证食品安全至关重要。
本文基于最新的YOLOv11算法,结合大规模高质量标注数据集,提供一套完整的厨房鼠患智能检测解决方案。
二、数据集构建与处理
2.1 数据集概况
数据规模:35953张高质量图像
标注格式:YOLO TXT
类别设置:14类别 'cockroach','hairnet', 'no_gloves', 'no_hat','rat','with_mask','without_mask','smoke','phone','overflow','garbage','garbage_bin','chef_uniform','chef_hat'
场景覆盖:监控视角、手机摄像头视角、多光照条件
数据划分:训练集/验证集/测试集 = 7:2:1
2.2 数据集结构
text
kitchen_dataset/
├── train/
│ ├── images/ # 训练集图像
│ └── labels/ # YOLO格式标注
├── val/
│ ├── images/ # 验证集图像
│ └── labels/ # YOLO格式标注
├── test/
│ ├── images/ # 测试集图像
│ └── labels/ # YOLO格式标注
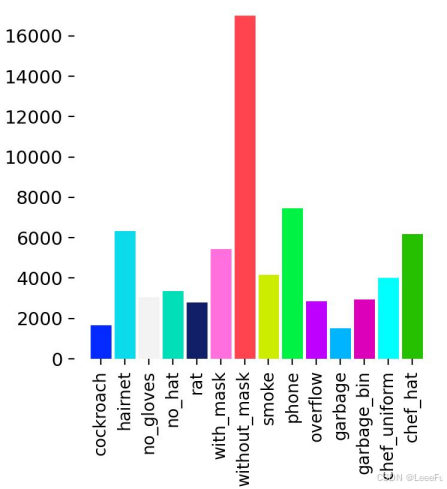
└── dataset.yaml # 数据集配置文件2.3 数据集示例分布
根据统计本数据集共包含14个目标检测类别,总计超6W个标注实例。各类别实例分布呈现出显著的不均衡特征
三、环境搭建、验证
3.1 环境搭建
bash
#1. 安装Anaconda Prompt、Pycharm
#2. 创建python环境
conda create -n YOLOv11 python=3.8.20 -y
#3. 激活环境
conda activate YOLOv11
#4. 安装ultralytics和pytorch
pip install torch==1.13.1+cu116 torchvision==0.14.1+cu116 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu116 -i https://pypi.tuna.tsinghua.edu.cn/simple/
pip install ultralytics -i https://pypi.tuna.tsinghua.edu.cn/simple
#5. 预训练权重下载
wget https://github.com/ultralytics/assets/releases/download/v8.3.0/yolo11s.pt3.2 验证
使用指令或者创建infer.py进行推理
bash
yolo predict model=yolo11s.pt sources="https://ultralytics.com/images/bus.jpg"
python
from ultralytics import YOLO
#加载预训练模型(会自动下载 yolov8n.pt)
model = YOLO("yolov8s.pt")
#预测图片
results = model.predict(
source="bus.jpg", # 输入源:图片/视频/目录/摄像头(0)
conf=0.5, # 置信度阈值
save=True, # 保存结果
show=True, # 显示结果(适用于Jupyter Notebook)
device="cuda:0" # 使用GPU(改为 "cpu" 则用CPU))
#打印结果
for result in results:
print(result.boxes) # 检测到的边界框信息以下结果确认环境是没有问题
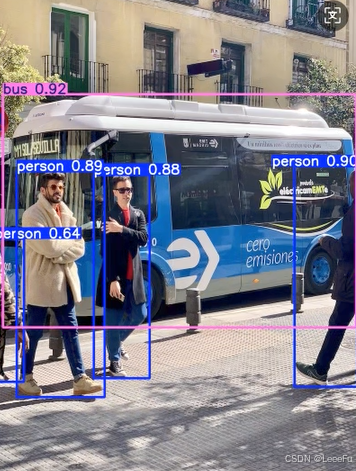
四、模型训练、评估及推理
4.1 配置文件dataset.yaml
yaml
path: /path/kitchen_dataset
train: train/images
val: val/images
test: test/images
nc: 14 # 类别数量
# 类别名称
names: ['cockroach','hairnet', 'no_gloves', 'no_hat','rat','with_mask','without_mask','smoke','phone','overflow','garbage','garbage_bin','chef_uniform','chef_hat'] # 类别名称4.2 模型训练
数据准备完成后,通过一下指令或者创建train.py文件进行模型训练,data参数用于加载数据集的配置文件,epochs参数用于调整训练的轮数,batch参数用于调整训练的批次大小(根据个人配置,进行调整)
bash
yolo train model=yolo11s.pt data=dataset.yaml epochs=300 imgsz=640 batch=32
python
from ultralytics import YOLO
# 加载模型
model = YOLO('yolo11s.pt') # 从头开始或使用预训练权重
# 训练
results = model.train(
data='dataset.yaml', # 数据集配置文件
epochs=300, # 训练轮数
imgsz=640, # 图像大小
batch=32, # 批量大小
device=0, # GPU设备 (0,1,2,3 或 'cpu')
workers=8, # 数据加载线程数
optimizer='AdamW', # 优化器 (SGD, Adam, AdamW, etc.)
lr0=0.01, # 初始学习率
lrf=0.01, # 最终学习率系数
momentum=0.937, # SGD动量
weight_decay=0.0005, # 权重衰减
warmup_epochs=3.0, # 热身轮数
warmup_momentum=0.8, # 热身动量
box=7.5, # 框损失权重
cls=0.5, # 分类损失权重
dfl=1.5, # DFL损失权重
pose=12.0, # 姿态损失权重(仅姿态模型)
kobj=1.0, # 关键点对象损失权重
label_smoothing=0.0, # 标签平滑
dropout=0.0, # Dropout(分类任务)
verbose=True, # 打印详细信息
seed=0, # 随机种子
deterministic=True, # 确定性训练
single_cls=False, # 单类别训练
rect=False, # 矩形训练
cos_lr=False, # 余弦学习率调度
close_mosaic=10, # 最后N轮关闭马赛克增强
resume=False, # 恢复训练
amp=True, # 自动混合精度
fraction=1.0 # 数据集比例
)4.3 性能评估
在深度学习中,我们通常用损失函数下降的曲线来观察模型训练的情况,避免过拟合和欠拟合现象。在训练结束后我们可以在run/detect中进行查看,结果如下所示:
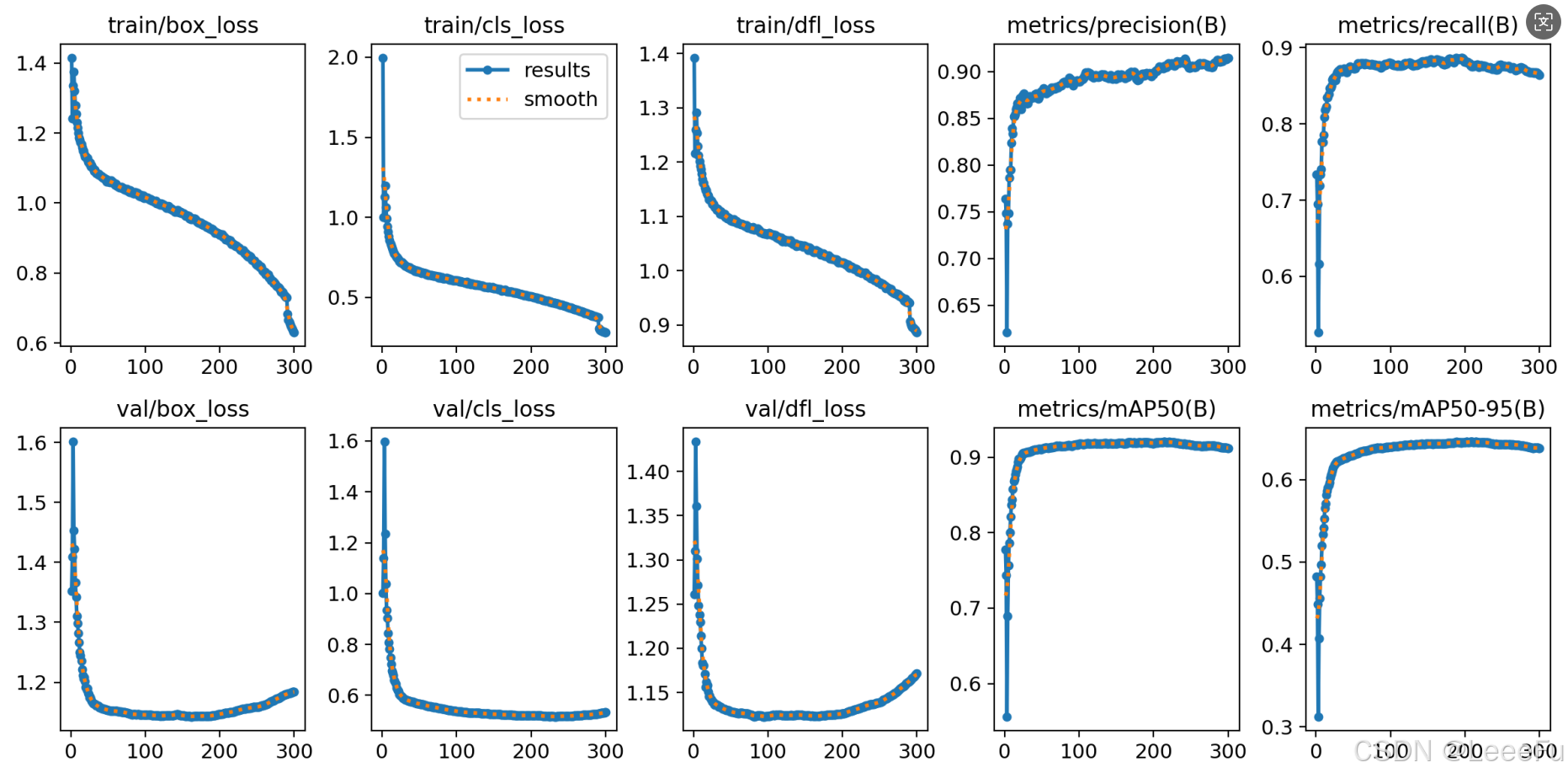
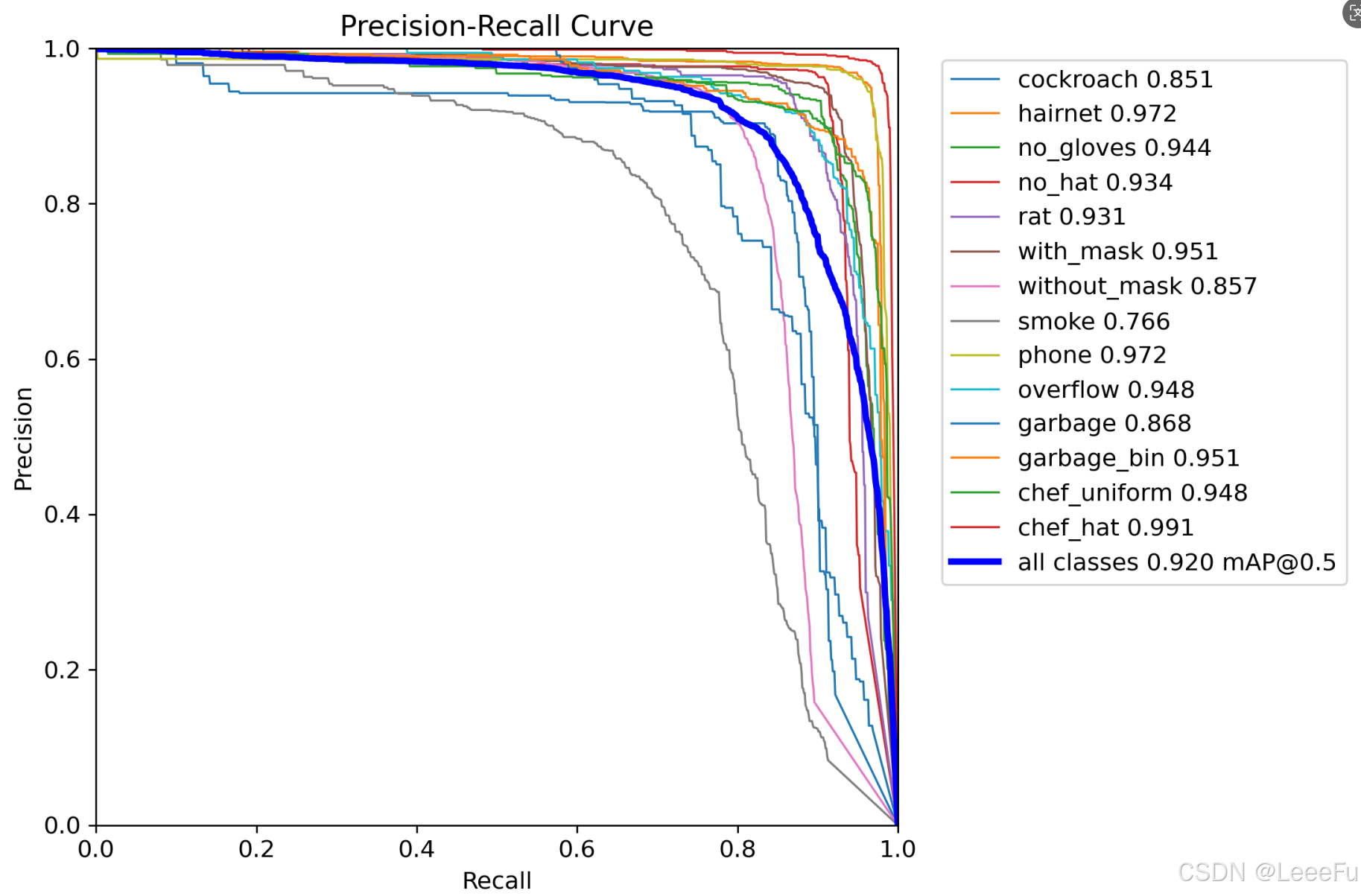
4.4 模型推理
我们可以利用以上3.2 章节创建的infer.py来进行推理,更换两个地方,将model="我们训练好的模型",通常在run/detect/exp/weights/best.pt,以及 source="需要推理的图片路径",source可以指定单张图片/图片文件夹
例如:
bash
yolo predict model=run/detect/exp1/weights/best.pt sources=/data/Imgs


五、模型部署
5.1 onnx模型
- onnx模型量化
python
from ultralytics import YOLO
import onnx
# 加载预训练模型
model = YOLO('yolo11s.pt') # 可以是 yolov8s.pt, yolov8m.pt 等
# 导出为ONNX格式
success = model.export(
format='onnx',
imgsz=640, # 输入图像尺寸
dynamic=True, # 支持动态batch size
simplify=True, # 简化模型
opset=12, # ONNX opset版本
half=False, # 是否导出FP16,量化时建议False
)- onnx模型推理
python
import cv2
import numpy as np
import onnxruntime as ort
#1. 加载ONNX模型
model_path = "yolo11s.onnx"
session = ort.InferenceSession(model_path)
#2. 加载并预处理图像
img_path = "test.jpg" # 改为你的测试图片路径
img = cv2.imread(img_path)
# 调整到640x640
input_img = cv2.resize(img, (640, 640))
input_img = input_img.transpose(2, 0, 1) # HWC -> CHW
input_img = input_img.astype(np.float32) / 255.0 # 归一化
input_img = np.expand_dims(input_img, axis=0) # 添加batch维度
# 3. 执行推理
input_name = session.get_inputs()[0].name
outputs = session.run(None, {input_name: input_img})[0] # 获取第一个输出
# 4. 解析检测结果
detections = outputs[0] # shape: (84, 8400)
boxes = []
confidences = []
class_ids = []
# 遍历所有8400个预测
for i in range(detections.shape[1]):
# 获取类别分数
scores = detections[4:, i]
class_id = np.argmax(scores)
confidence = scores[class_id]
# 过滤低置信度
if confidence > 0.5:
# 获取边界框 (cx, cy, w, h 格式)
cx, cy, w, h = detections[0:4, i]
# 转换为角点格式
x1 = int((cx - w/2) * img.shape[1] / 640) # 缩放回原始尺寸
y1 = int((cy - h/2) * img.shape[0] / 640)
x2 = int((cx + w/2) * img.shape[1] / 640)
y2 = int((cy + h/2) * img.shape[0] / 640)
boxes.append([x1, y1, x2, y2])
confidences.append(float(confidence))
class_ids.append(class_id)
# 5. 应用NMS (简化版)
indices = cv2.dnn.NMSBoxes(boxes, confidences, 0.5, 0.4)
# 6. 绘制检测框
for i in indices:
if hasattr(i, '__len__'): # 处理不同版本的返回格式
i = i[0]
box = boxes[i]
conf = confidences[i]
class_id = class_ids[i]
# 绘制矩形框
cv2.rectangle(img, (box[0], box[1]), (box[2], box[3]), (0, 255, 0), 2)
# 添加标签
label = f"{class_id}: {conf:.2f}"
cv2.putText(img, label, (box[0], box[1]-10),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
# 7. 保存并显示结果
cv2.imwrite("result.jpg", img)
print(f"检测到 {len(indices)} 个目标")
# 显示图像(可选)
cv2.imshow("Detection Result", img)
cv2.waitKey(0)
cv2.destroyAllWindows()5.2 安卓模型部署
可参考一下博客,完成yolo11安卓部署
【ultralytics最新版本】Android部署算法(含yolo11)万字完结篇
送你们一条美丽的--分割线--
🌷🌷🍀🍀🌾🌾🍓🍓🍂🍂🙋🙋🐸🐸🙋🙋💖💖🍌🍌🔔🔔🍉🍉🍭🍭🍋🍋🍇🍇🏆🏆📸📸⛵⛵⭐⭐🍎🍎👍👍🌷🌷