大数据与云计算
- 并行分布式计算定义:将大任务拆解成多个子任务,由多处理单元并行执行,强调协同与任务划分。
- 云计算定义:通过网络按需获取可弹性伸缩的计算、存储与服务资源,通常以计量付费方式提供。
- 服务模型:
- IaaS(基础设施即服务):提供计算、存储、网络等基础资源。
- PaaS(平台即服务):提供应用运行环境与开发平台。
- SaaS(软件即服务):提供可直接使用的软件能力。
- 摩尔定律与新摩尔定律
a.摩尔定律:每18个月,集成电路芯片上的电路数量翻一番,微处理器性能提升一倍、价格减半,整体计算性能提升约四倍。
b.新摩尔定律:每18个月,全球新增信息量约等于计算机有史以来全部信息量的总和。
-
存储容量单位换算:
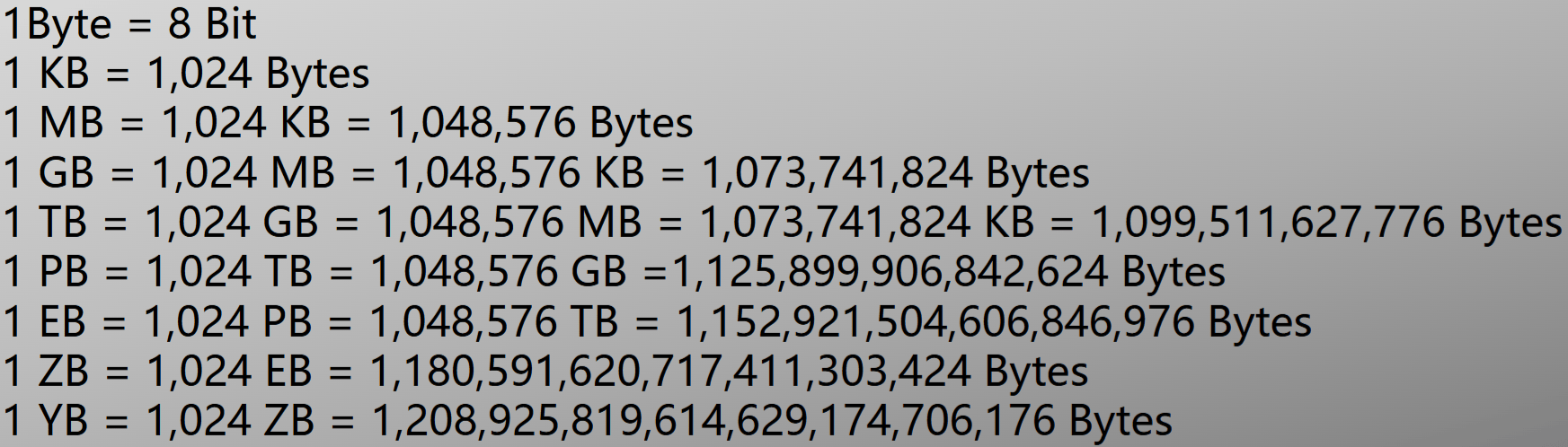
-
大数据的特点(4V+1C)
- Volume:数据量巨大
- Velocity:数据增长与处理速度快
- Variety:数据来源与格式多样
- Value:价值密度低、需要挖掘
- Complexity:处理与分析难度大
-
云计算长定义:一种商业计算模型,将计算任务分布在大量计算机组成的资源池上,使应用系统可按需获取计算力、存储空间和信息服务。
-
云计算短定义:通过网络按需提供可动态伸缩的廉价计算服务。
-
云计算的核心理念:资源池化与按需弹性供给。
-
云计算的7个特点:
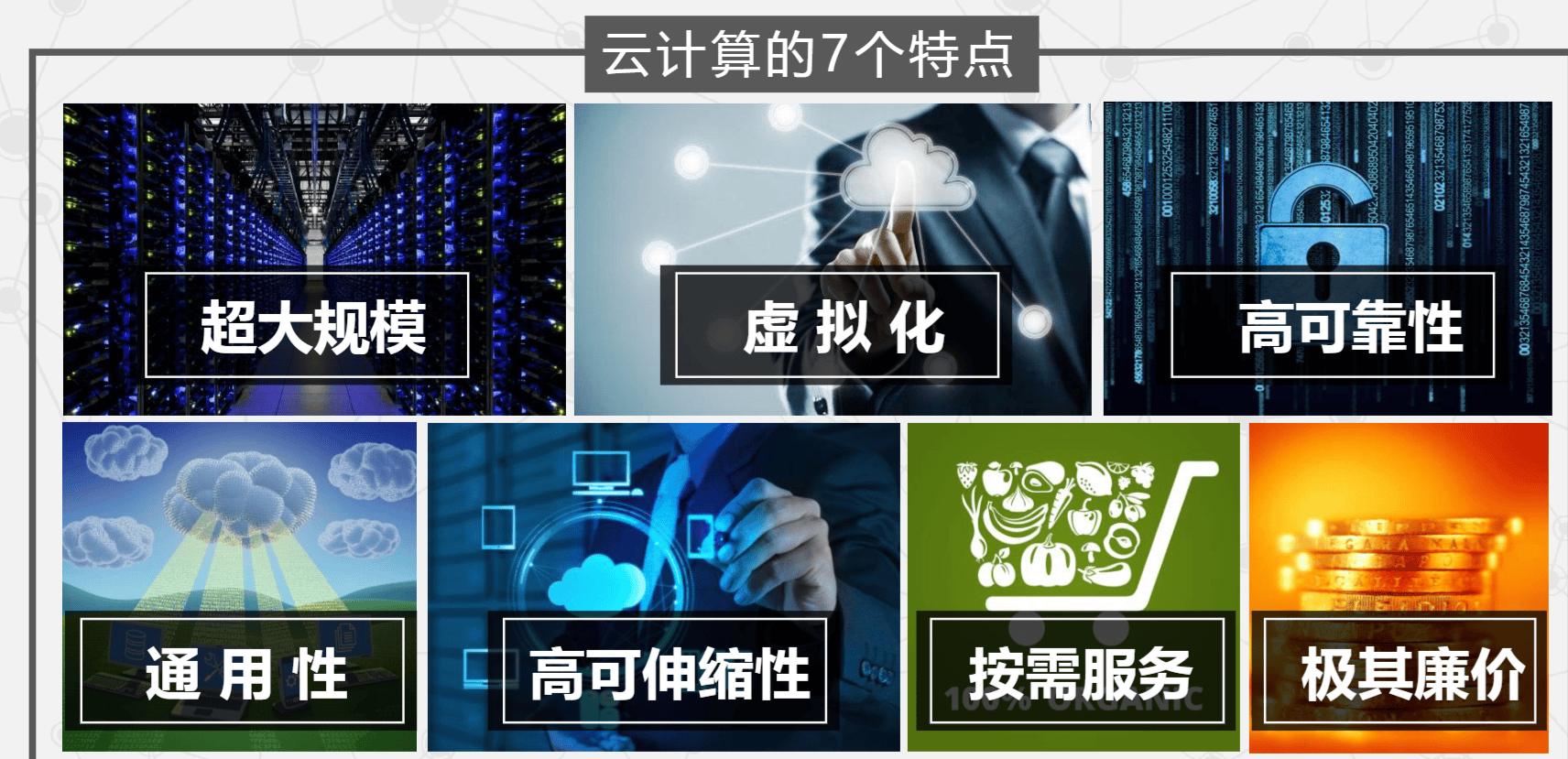
-
云计算的服务类型:
- SaaS:面向终端用户的应用服务,如 Salesforce 的在线 CRM。
- PaaS:提供应用运行环境与开发平台,如 Google App Engine、Microsoft Azure。
- IaaS:提供基础硬件资源服务,如 AWS 的 EC2 和 S3。
将软件作为服务(SaaS):通过 Internet 提供软件,用户无需购买软件,而是租用基于 Web 的应用。
将平台作为服务(PaaS):将服务器平台或开发环境作为服务提供,强调开发、部署与维护的简化。
将基础设施作为服务(IaaS):将多台服务器组成的"云端"资源(内存、I/O、存储、计算能力等)按计量提供给用户。
容器即服务(CaaS):以容器为资源分割与调度单位,封装运行时环境,为开发者与运维提供构建、发布与运行分布式应用的平台。

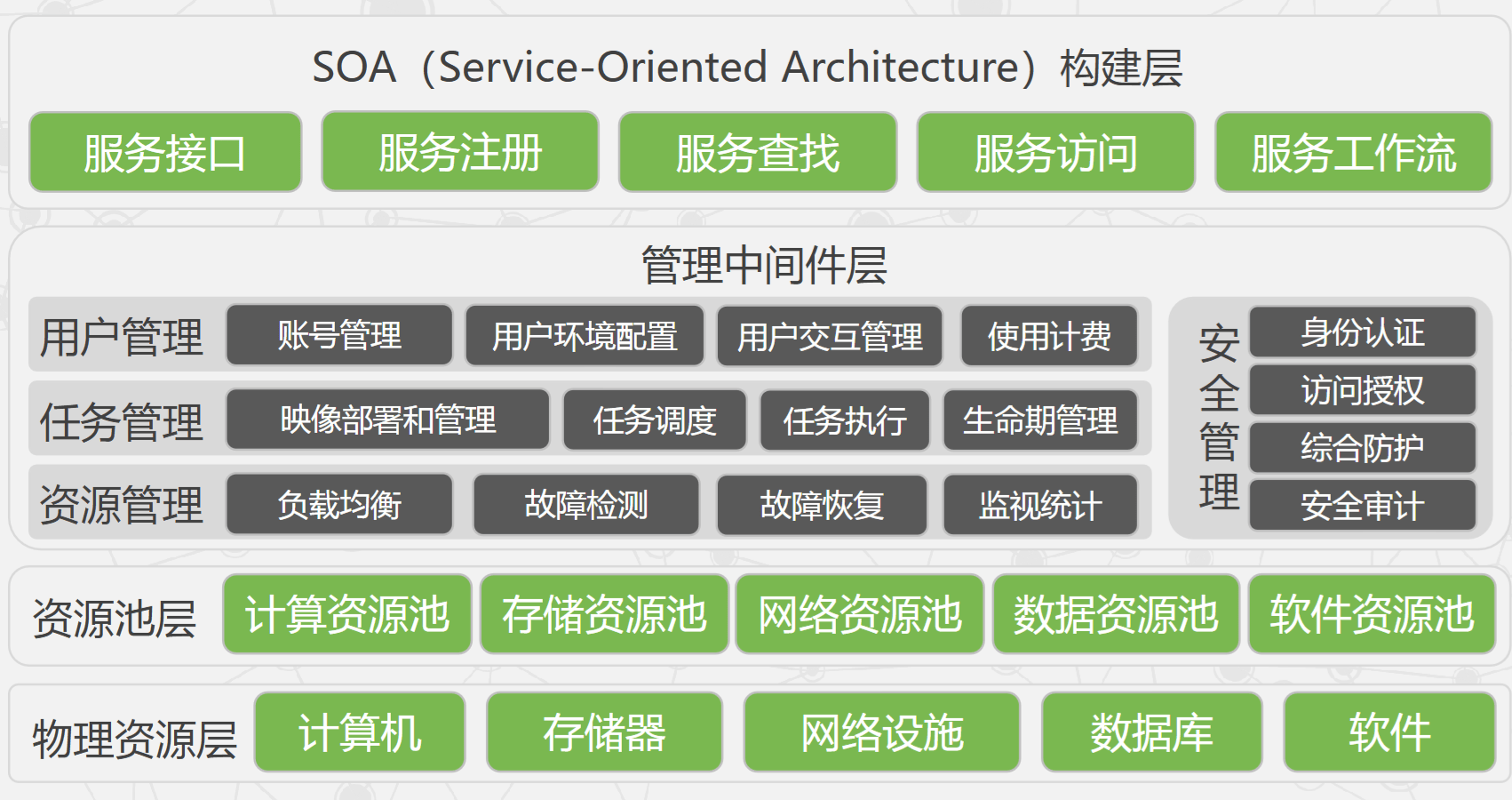
- 云计算实现机制:
- SOA构建层:封装云计算能力为标准的 Web Services,并纳入 SOA 体系。
- 管理中间件层:负责云资源管理与任务调度,保障资源高效、安全地服务应用。
- 物理资源层:计算机、存储器、网络设施、数据库与软件等。
- 资源池层:将大量同类资源组成同构或近似同构的资源池,负责物理资源的集成与管理。
管理中间件层和资源池层是云计算技术的关键部分,SOA构建层的功能更多依靠外部设施提供。
- 数据中心应该建在什么地方?
人烟稀少、气候寒冷、水电资源丰富的地区。
- 偏远地区的数据传输成本呢?
由于密集波分复用技术(DWDM)的应用,单根光纤的传输容量已超过 10 Tbit/s。开挖并铺设光纤的传输成本远低于将电力通过高压输电线路引入城市,且传输衰减小。谷歌的观点是:"传输光子比传输电子要容易得多。"
- 云计算压倒性的成本优势:
- 在超大规模资源池中按需分配与释放资源,弹性强。
- 平台规模大,整体负载更容易平滑与优化。
- 资源利用率可达 80% 左右,显著高于传统模式(约 5~7 倍)。
总结:硬件成本、能耗与管理费用被规模化摊薄,资源利用率提升是关键因素。
GFS
-
GFS:Google File System(谷歌文件系统)
- GFS 是大型分布式文件系统,为 Google 云计算提供海量存储,与 Chubby、MapReduce、Bigtable 等技术结合紧密,处于核心技术底层。
- GFS 不是开源系统。
- 主流分布式文件系统有:Red Hat 的 GFS、IBM 的 GPFS、Sun 的 Lustre、Alibaba 的 TFS(Taobao File System)。
- 通常用于高性能计算中心或大型数据中心,对硬件设施要求较高。

-
GFS 的系统架构
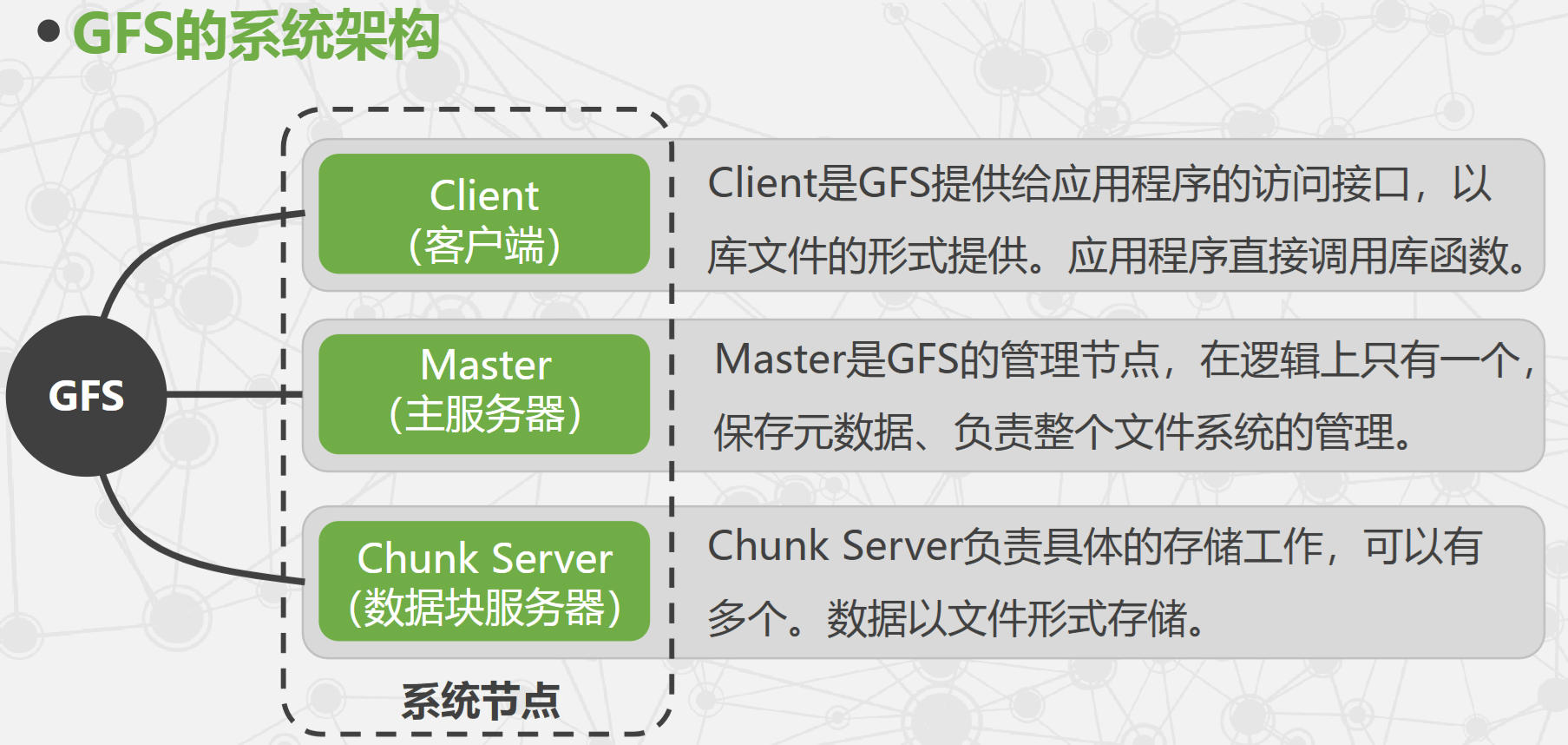
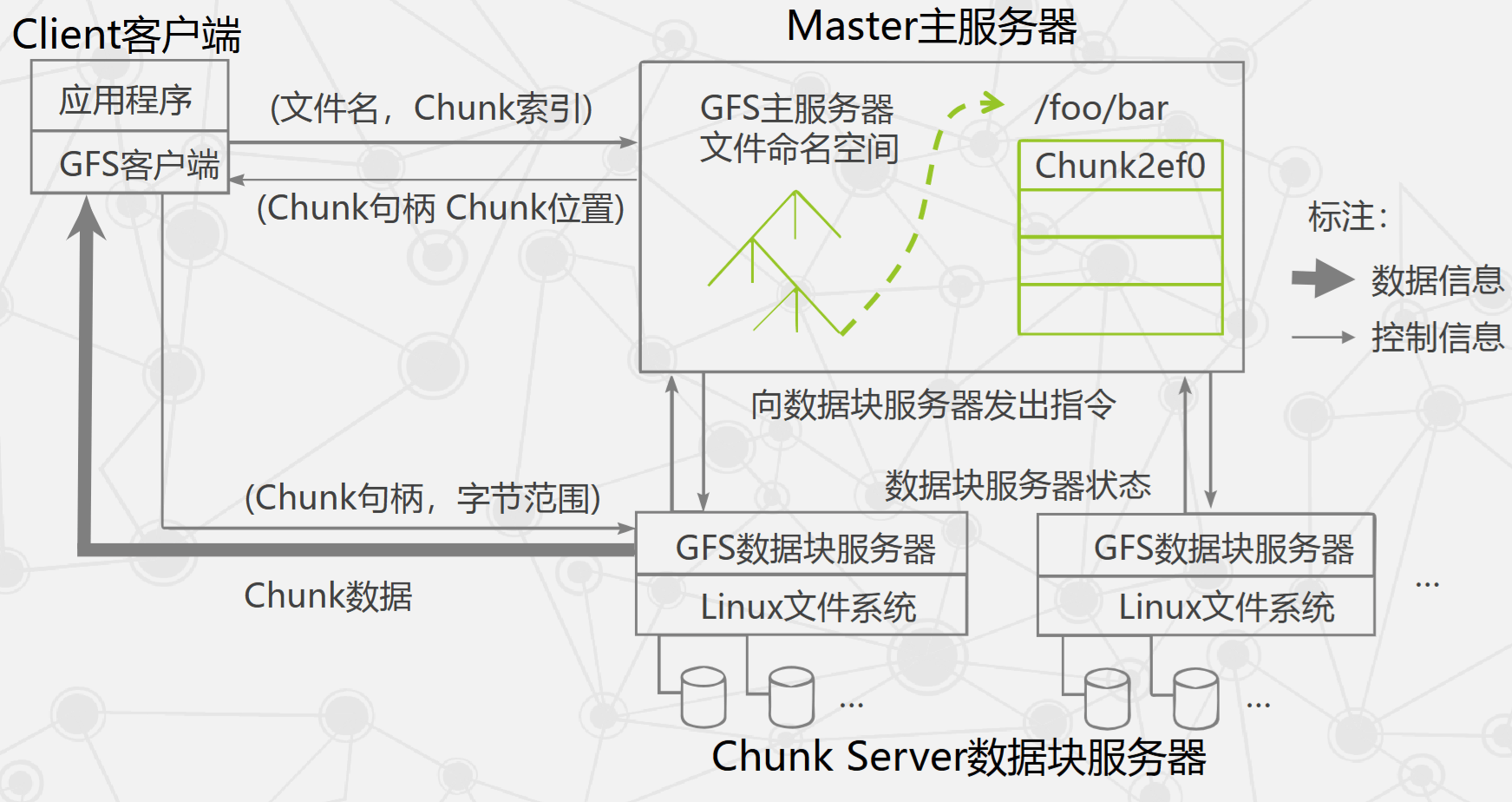
- GFS 将文件按固定大小分块,默认 64 MB,每一块称为 Chunk,每个 Chunk 有对应的索引号(Index)。
- 客户端先访问 Master 获取 Chunk Server 信息,再与 Chunk Server 交互完成数据存取,实现控制流与数据流分离。
- Client 与 Master 之间只有控制流,没有数据流,显著降低 Master 负载。
- Client 与 Chunk Server 直接传输数据流,且可并行访问多个 Chunk Server,提升整体 I/O 性能。
-
GFS 的四个特点
- 采用中心服务器模式
- Master 管理分布式系统中的所有元数据。
- 文件被划分为 Chunk 存储,对 Master 而言每个 Chunk Server 只是存储空间。
- Client 操作需先经由 Master,新增 Chunk Server 只需注册到 Master。
- Chunk Server 之间无直接关系,易于扩展。
- 无中心模式难以保证一致性且扩展性差(更新通知困难)。
- Master 维护统一命名空间与全局 Chunk Server 状态,实现系统内负载均衡。
- 单中心易成瓶颈,GFS 通过控制元数据规模、远程备份、控制流与数据流分离等机制降低影响。
- 不缓存数据
- 业务以流式读写为主,重复读写少,Cache 性能收益有限。
- 数据在 Chunk Server 以文件形式存储,频繁读取的数据可由本地文件系统缓存。
- Cache 一致性维护复杂,Chunk Server 与网络不稳定。
- 数据量巨大,内存容量不足以承载大规模缓存。
- Master 侧元数据采用缓存,常驻内存并配合压缩机制提高效率。
- 在用户态下实现
- 利用 POSIX 接口存取数据,降低实现难度并提高通用性。
- 用户态调试工具丰富,较内核态易于排错。
- Master 与 Chunk Server 均为进程,单进程故障不影响操作系统。
- GFS 与操作系统解耦,便于独立升级。
- 只提供专用接口
- GFS 通过库文件提供专用 API,应用程序调用库函数访问系统。
- 优点:实现难度低;可为应用特性提供特殊支持(如并发追加);减少上下文切换,提高效率。
- 采用中心服务器模式
-
Master 容错

- Master 发生故障时,在磁盘元数据完好情况下可快速恢复。
- 为防止 Master 彻底失效,GFS 提供远程实时备份。
- Chunk Server 容错采用副本机制:
- 每个 Chunk 默认保存 3 份副本,分布在不同 Chunk Server。
- 所有副本写入成功后才视为写入成功。
- 副本丢失或不可恢复时,Master 自动在其他 Chunk Server 上补副本。
- Chunk 默认大小 64 MB,每个 Chunk 以 Block 划分,Block 大小 64 KB,每个 Block 对应 32-bit 校验和。
-
系统管理技术
- 故障检测技术:集群运行在不可靠廉价硬件上,需依赖监控技术快速定位故障。
- 节能技术:能耗成本高于采购成本,Google 通过修改主板、采用蓄电池替代 UPS 降低能耗。
- 大规模集群安装技术:节点数量多,需要自动化安装与部署能力。
- 节点动态加入技术:新 Chunk Server 裸机加入后可自动获取系统并安装运行。
- UPS:uninterruptable power system,不间断供电系统。
-
Global File System 与 Google File System 的区别?
- Global File System(GFS):开源、产品化的集群文件系统,又名"红帽全球文件系统"。Red Hat 按服务器数量收费(约 2200 美元/台/年),原理性文档少,技术细节未公开。
- Google File System(GFS):Google 内部使用的分布式文件系统,部分技术细节在论文中公开。
-
HDFS 与 GFS 的区别?
- HDFS(Hadoop Distributed File System)隶属于 Hadoop 开源分布式计算框架,与 MapReduce 模型配套。
- 设计目标相似,但在文件块大小与副本策略等方面存在差异:GFS 块大小 64 MB,HDFS 常见块大小 128 MB。
- GFS 元数据由 Master 维护;HDFS 由主节点与从节点共同维护。
TFS
-
淘宝分布式文件系统 TFS
- Taobao File System(TFS)是高可扩展、高可用、高性能、面向互联网服务的分布式文件系统,主要针对海量非结构化数据。
- 构建在普通 Linux 机器集群上,可对外提供高可靠与高并发的存储访问。
- 淘宝提供海量小文件存储:与 GFS 不同(64 MB),TFS 通常单文件不超过 1 MB,满足小文件存储需求并广泛应用于淘宝业务。
- 采用高容错架构和平滑扩容,保证系统可用性与扩展性。
- 扁平化数据组织结构:将文件名映射到物理地址,简化访问流程,提升读写性能。
-
TFS 总体架构
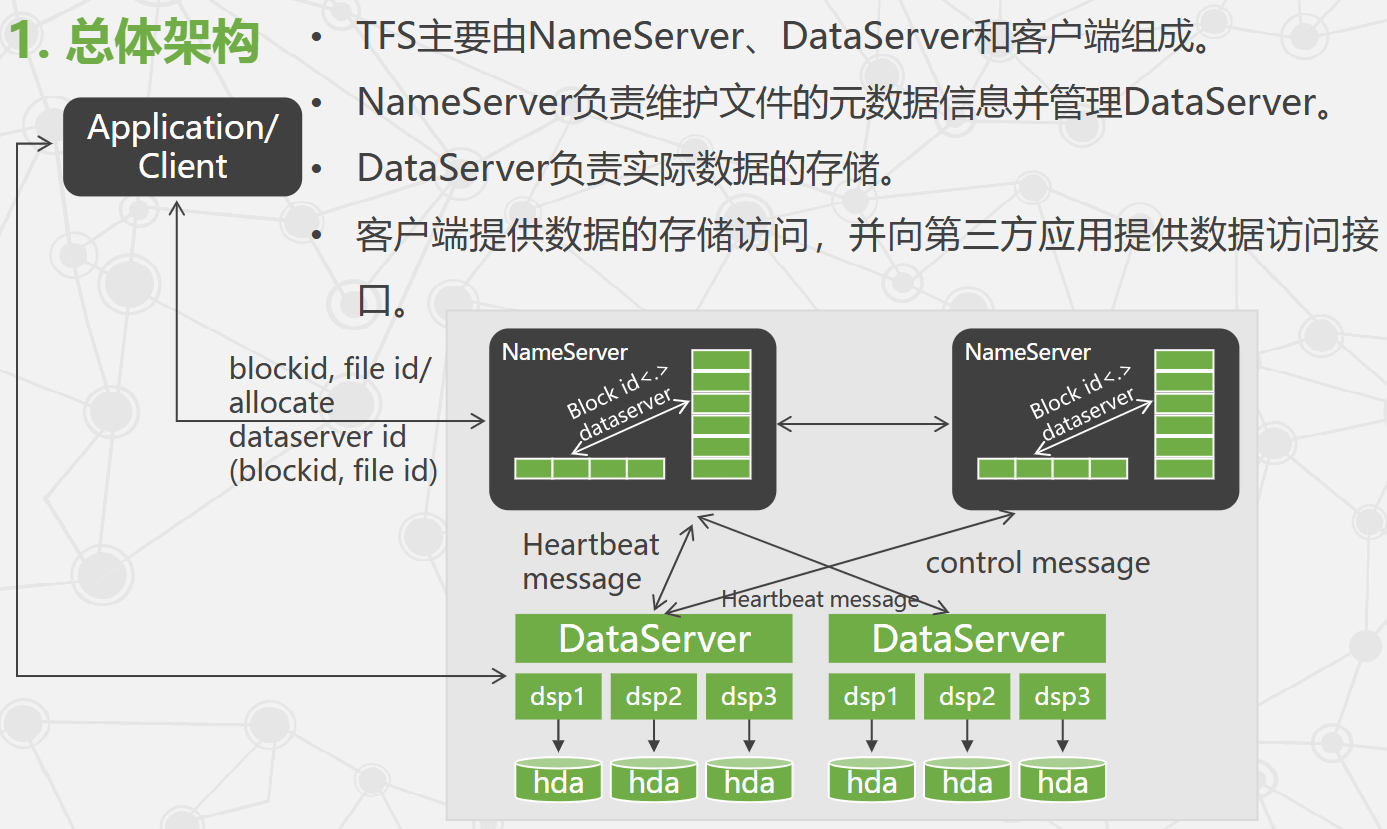
- NameServer 采用双机热备互为容错。
- 多个 DataServer 组成数据存储集群。
- TFS 主要针对海量小文件,为提高读写性能,将小文件合并为大文件,类似 GFS 的 Chunk。
- 定位 Chunk 的信息称为一级索引;Chunk 内部的文件定位信息称为二级索引。
- TFS 文件名包含索引信息,用户写入前向 TFS 申请文件名,以便后续解析索引定位。
<namespace>_<block_id>_<file_id> - TFS 命名方式 vs 传统文件系统 POSIX 接口
- 灵活性不如 POSIX 接口。
- 扁平化组织可显著降低元数据规模,使 NameServer 支持 PB 级一级索引,提高扩展性。
- 二级索引仅针对单台 DataServer 的数据量,避免数据膨胀导致索引膨胀。
-
TFS 存储机制
- 大量小文件合并为大文件,该大文件称为 Block 块。
- TFS 以 Block 组织文件存储。
- 每个 Block 在集群内有唯一编号,由 NameServer 分配,但实际存储在 DataServer。
- NameServer 维护 Block 信息列表以及 Block 与 DataServer 的映射关系。
- 每个 Block 存储多份副本,分布在不同 DataServer 上以保证冗余。
- 客户端读写请求由 NameServer 选择合适 DataServer 返回;客户端直接与 DataServer 进行读写。
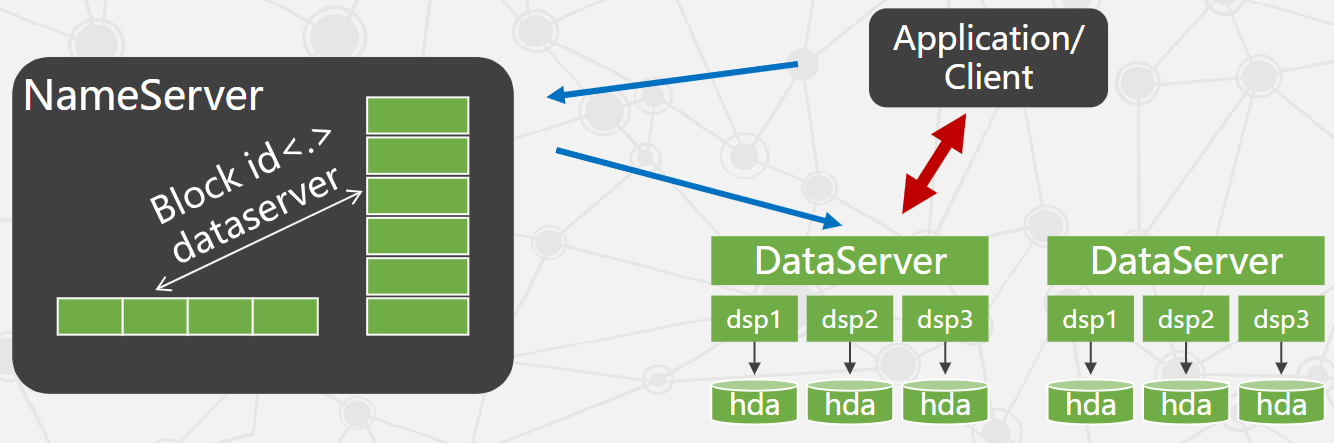

- 一个 DataServer 上有多个物理块,物理块以文件形式存放磁盘。
- DataServer 部署前预分配物理块,保证访问速度并减少碎片。
- 为满足该特性,DataServer 一般运行在 EXT4 文件系统上。
-
容错机制
- 集群容错:
- GFS 没有集群容错机制。
- TFS 可配置主辅集群,通常位于不同机房。
- 主集群提供全部功能,辅集群仅提供读。
- 主集群将操作重放到辅集群,既做负载均衡,又在主集群异常时保证服务不中断、数据不丢失。
- NameServer 容错:
- NameServer 采用 HA 主备模式,主节点操作重放到备节点,主节点故障可实时切换。
- NameServer 与 DataServer 有定时 heartbeat,DataServer 上报自身 Block;DataServer 故障时,NameServer 可重建 DataServer 与 Block 关系。
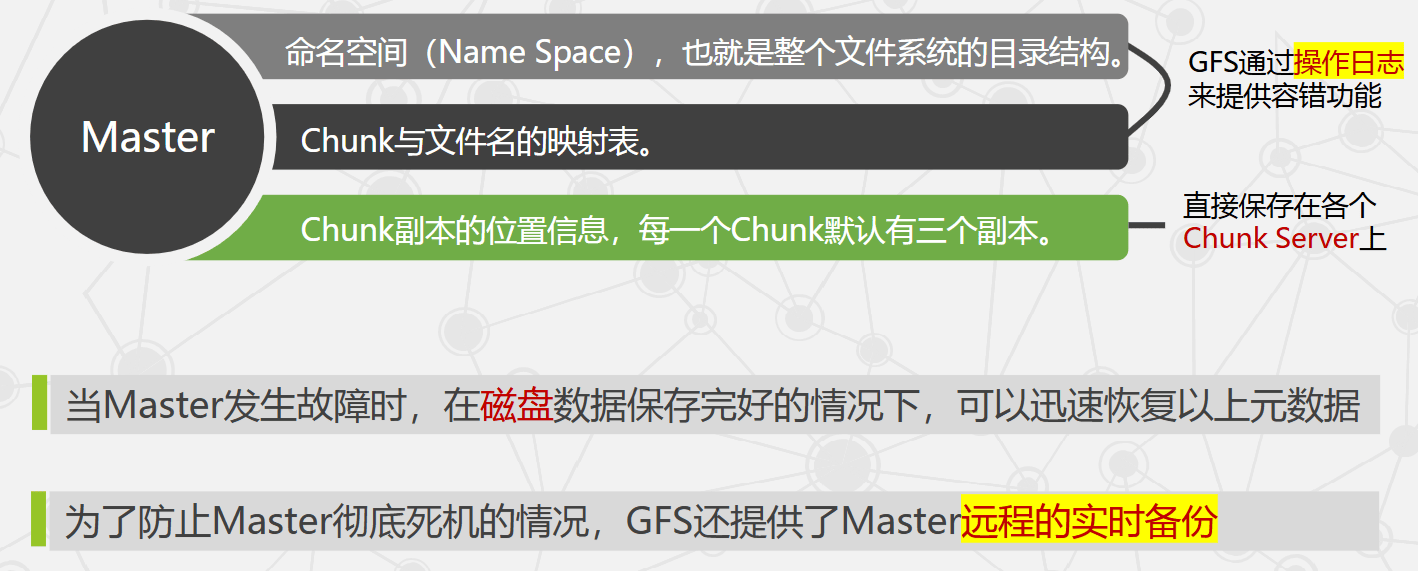
- DataServer 容错:
- Block 默认多副本(一般 3 份),分布在不同网段的不同 DataServer。
- 写入请求需所有副本写入成功才算成功。
- 磁盘损坏或 DataServer 宕机时,TFS 启动复制流程,将副本数不足的 Block 复制到其他 DataServer。
- TFS 对每个文件记录 CRC 校验,客户端发现 CRC 与内容不匹配时自动切换到可用 Block,并自动修复单文件损坏。

- 集群容错:
-
平滑扩容
- TFS 集群容量不足时,只需新增 DataServer,部署应用后启动即可;这些 DataServer 会向 NameServer 心跳汇报。
- 用户写入数据时,NameServer 根据 DataServer 容量比率与负载情况选择合适节点存储。
- 集群负载较轻时,NameServer 对 Block 进行均衡:
- 先计算每台 DataServer 的 Block 平均数量。
- 将节点分为两堆:超过平均的作为移动源,低于平均的作为移动目的。
MapReduce
-
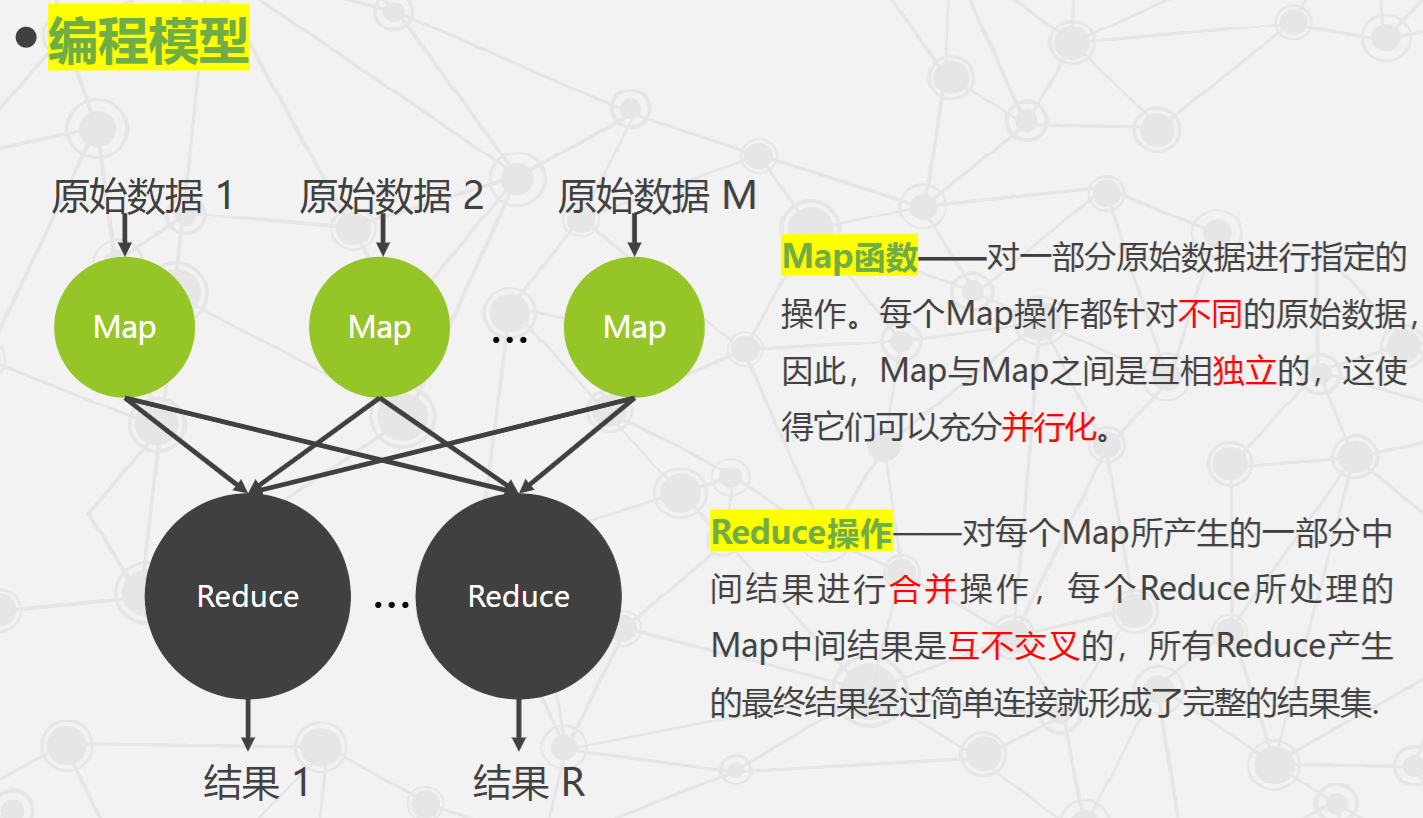
MapReduce 定义与特点
- 将对大规模数据集的操作分发给主节点管理下的各工作节点共同完成,实现可靠执行与容错。
- 相比传统分布式程序设计,MapReduce 封装并行处理、容错处理、本地化计算、负载均衡等细节,提供简单而强大的接口。
-
MapReduce 的实现机制
- 分割输入文件:将输入文件划分为 M 个块,每块约 16 MB~64 MB(可由参数配置),并在集群中分派处理。
- 分派程序:一个进程作为 Master,负责调度;其余进程作为 Worker 执行任务。
- 读取并处理文件块:Map Worker 读取并处理分配到的输入块。
- 本地写入:中间结果缓存在内存并定时写入本地磁盘,通过分区函数划分为 R 个分区。
- 远程读取缓存:Master 通知 Reduce Worker 中间 <key, value> 的位置后,Reduce Worker 通过远程过程从 Map Worker 本地磁盘读取。
- 写入结果:Reduce Worker 按 key 遍历排序后的中间数据,将 key 与对应 value 集合传递给用户定义的 Reduce 函数。
- 返回:所有 Map 与 Reduce 任务完成后,Master 激活用户程序,MapReduce 返回到调用点。
-
MapReduce 的容错机制
- MapReduce 在大规模集群上运行,容错通过重新执行失效任务实现。
- Master 失效:
- Master 周期性设置检查点(checkpoint)并导出状态。
- 任务失效时从最近检查点恢复并重新执行。
- 由于只有一个 Master,若 Master 失效通常只能终止程序并重新开始。
- Worker 失效:
- Master 周期性向 Worker 发送 ping,未响应则判定失效。
- 失效 Worker 上的任务会被调度到其他 Worker 重新执行。
-
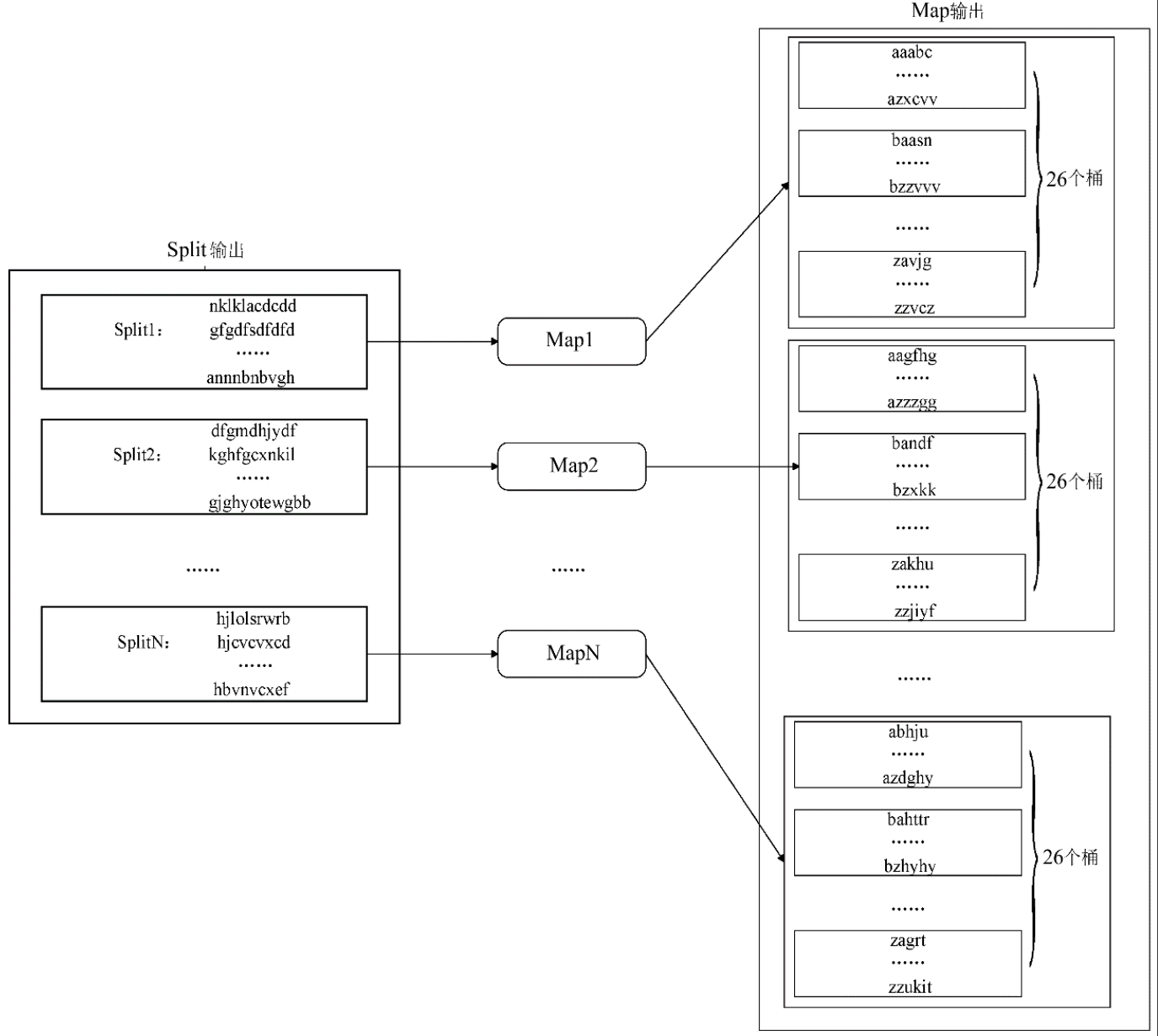
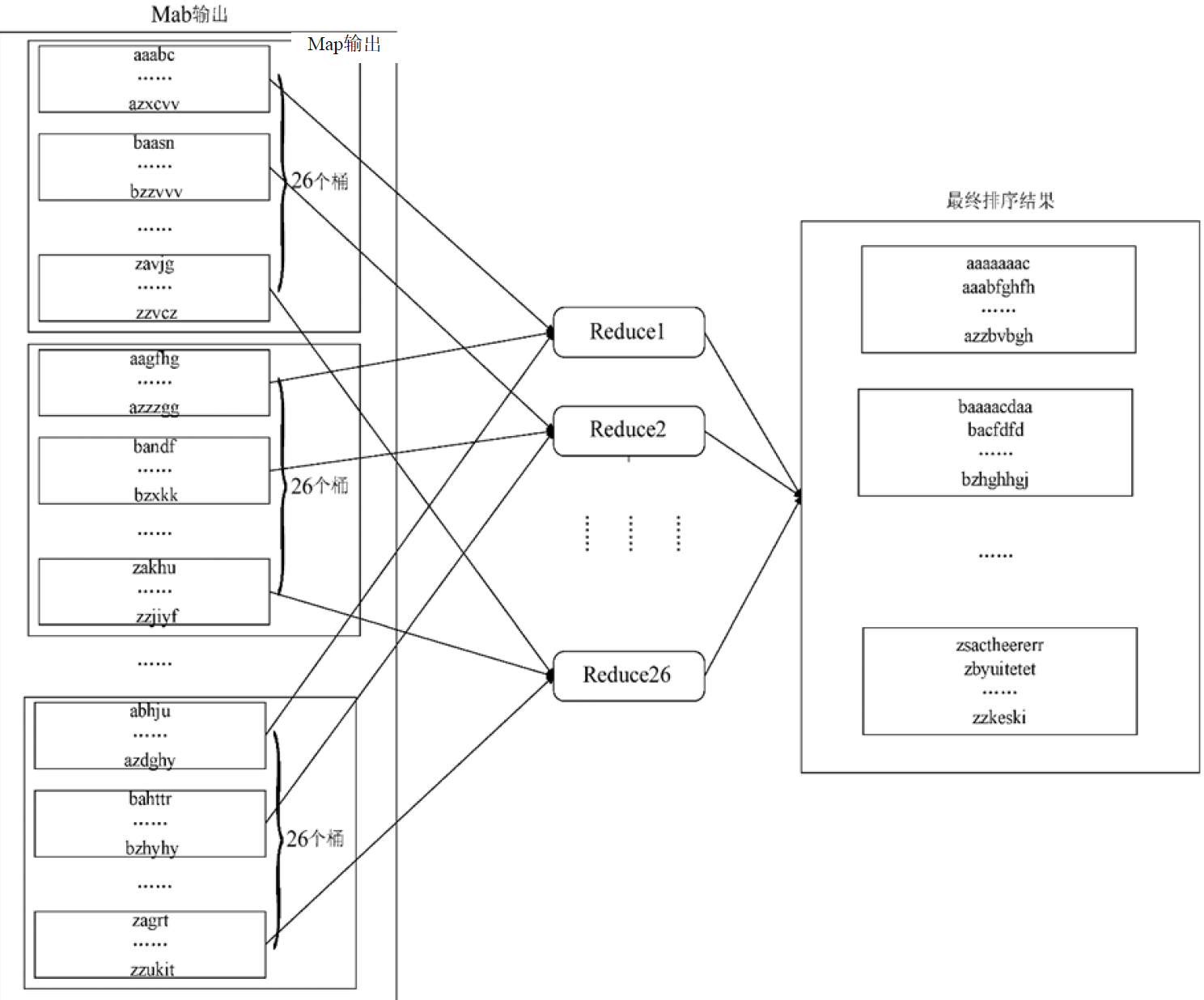
MapReduce 流程示意
- 原始数据进行分割(Split),得到 N 个数据分块。
- 为每个数据分块启动一个 Map 任务处理。
- Map 后得到中间结果,按规则分配到多个 Reduce 任务处理。

-
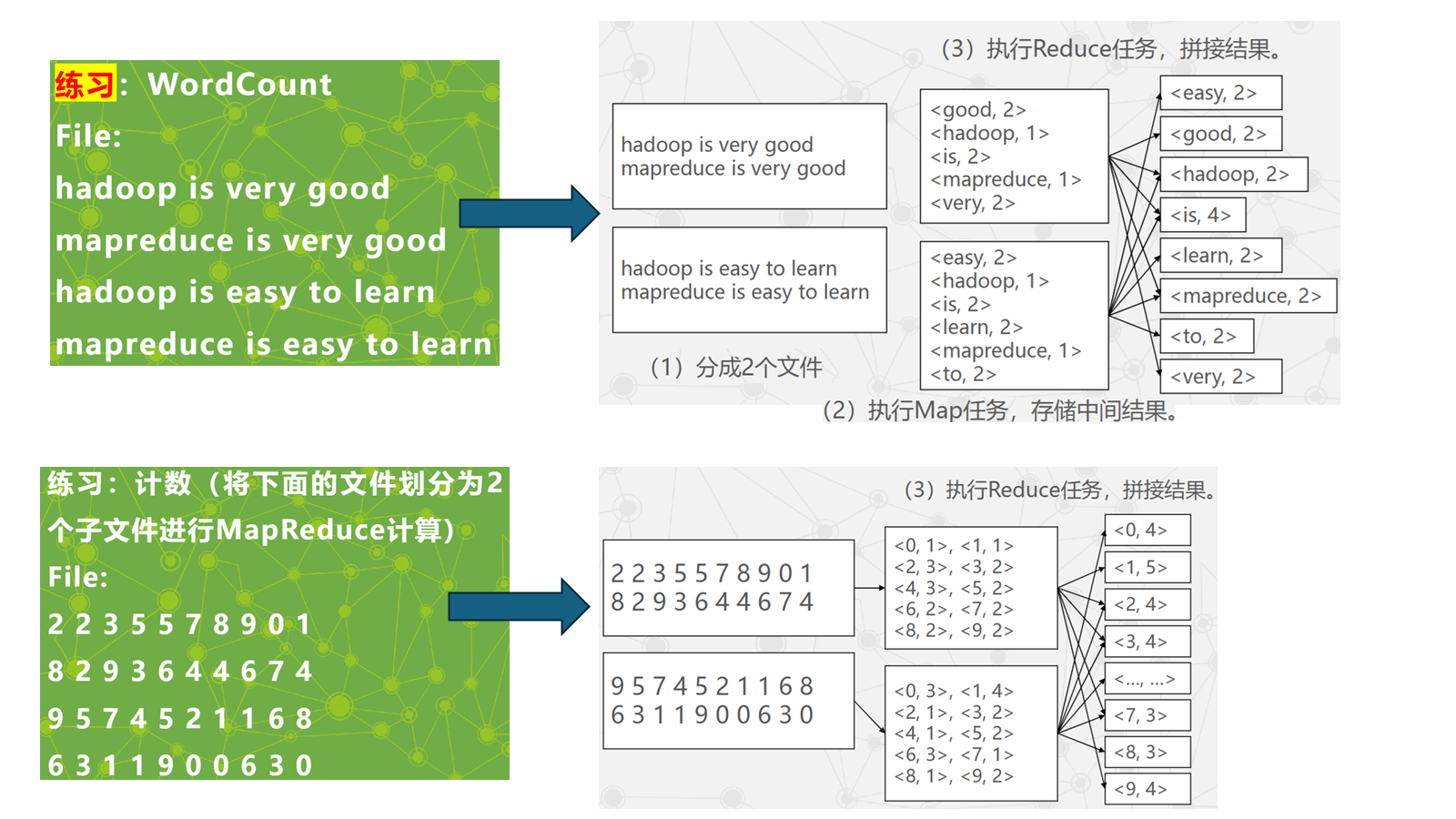
练习
Chubby
-
Chubby 初步了解
- Chubby 是 Google 设计的、提供粗粒度锁服务的分布式文件系统,基于松耦合分布式系统解决一致性问题。
- Chubby 提供的是建议性锁(advisory lock),而非强制锁,使系统更灵活。
- GFS 使用 Chubby 选取 GFS 主服务器;Bigtable 使用 Chubby 指定主服务器并发现/控制子表服务器。
- 使用示例:
- 使用锁服务保证数据操作一致性。
- 作为稳定存储系统保存小数据(含元数据)。
- 作为名字服务(Name Server)。
-
Paxos 算法
- Paxos 是基于消息传递的一致性算法,用于解决分布式系统一致性问题。
- 一致性核心:保证多个节点在相同初始状态与操作序列下看到一致的指令序列,并得到一致结果。
- 直观方案:设置专门节点接受并裁决操作顺序。
- 缺陷:单点失效导致不一致,因此需要多个节点共同决定操作序列。
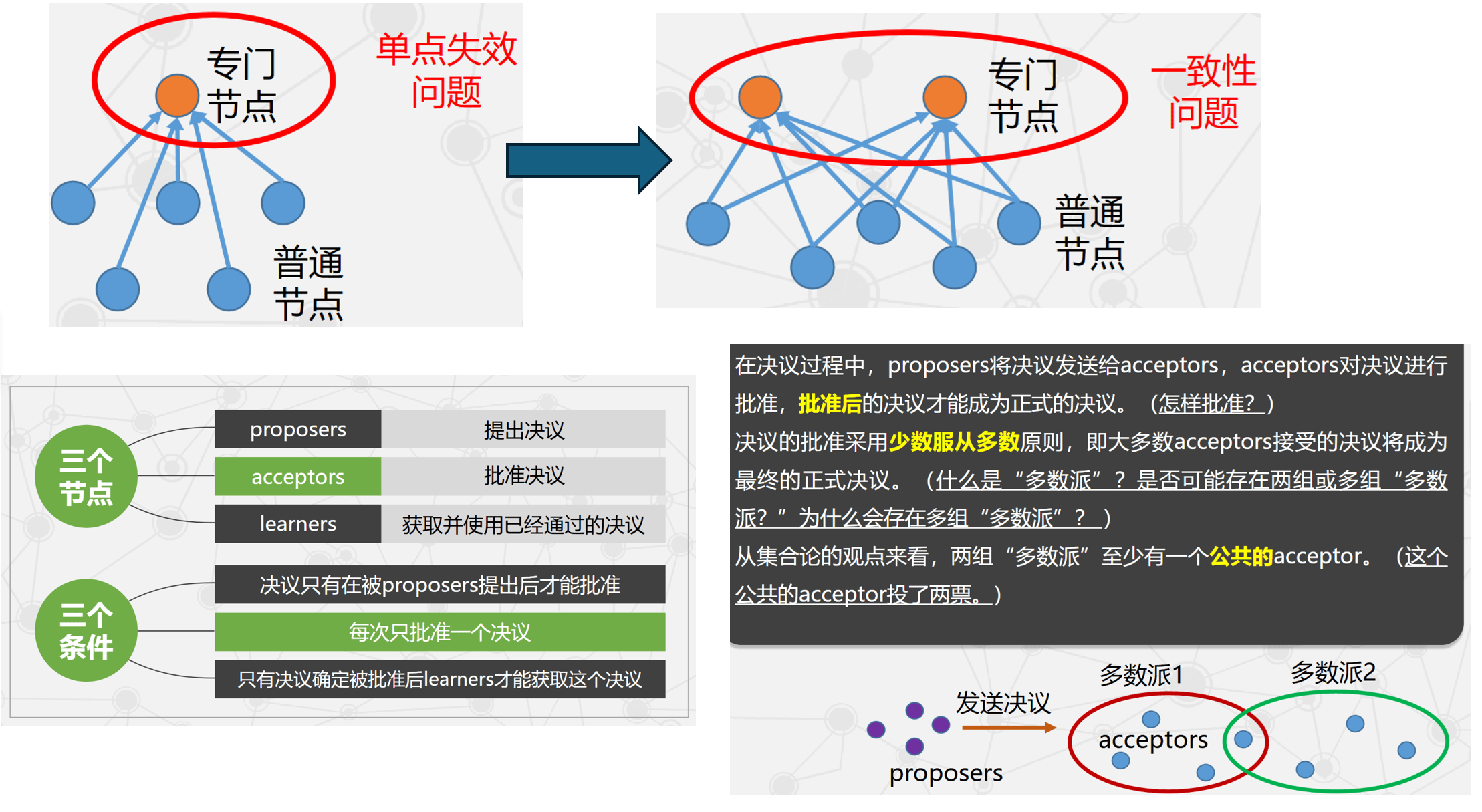
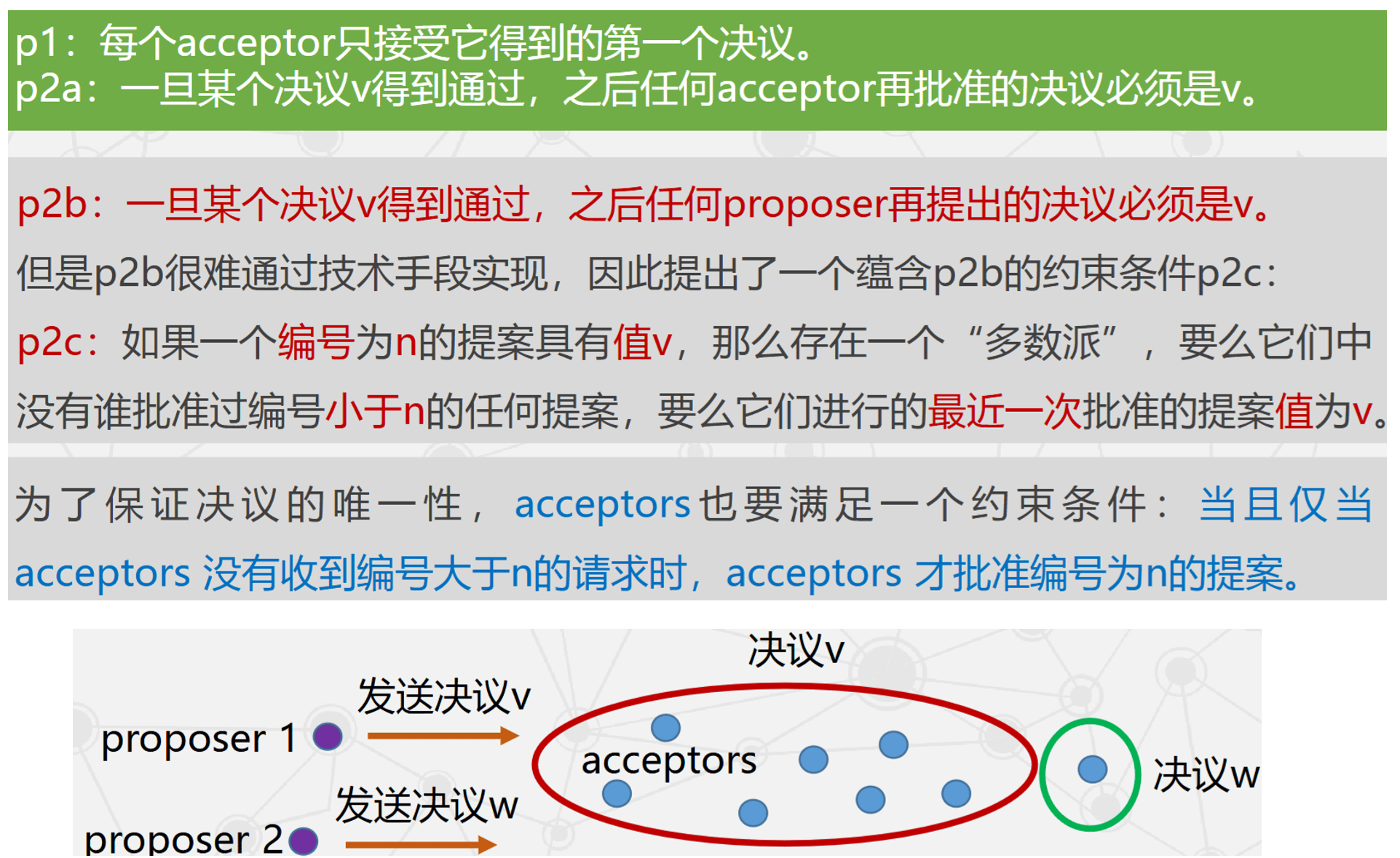



-
Chubby 的设计目标
- 高可用性和高可靠性:系统设计首要目标,其次再考虑吞吐量与存储能力。
- 高扩展性:数据存储在较廉价 RAM 中,支持大规模用户访问。
- 支持粗粒度建议性锁服务:提高系统性能。
- 服务信息直接存储:可直接存储元数据与系统参数,不再维护额外服务。
- 支持通报机制:客户端及时获知事件发生。
- 支持缓存机制:一致性缓存常用信息,减少访问主服务器。
-
为什么不直接实现 Paxos 函数库,而设计 Chubby 锁服务
- 独立锁服务不改变原有系统架构,而函数库需要侵入式修改。
- 基于文件系统的锁服务可将系统变动写入文件,减少大量组件间通信带来的性能损耗。
- 基于锁的开发接口更易被开发者接受。


-
元数据的四类单调递增编号
- 实例号:新节点实例号必定大于旧节点实例号。
- 内容生成号:文件内容修改时递增。
- 锁生成号:锁被用户持有时递增。
- ACL 生成号:ACL 名被覆写时递增。
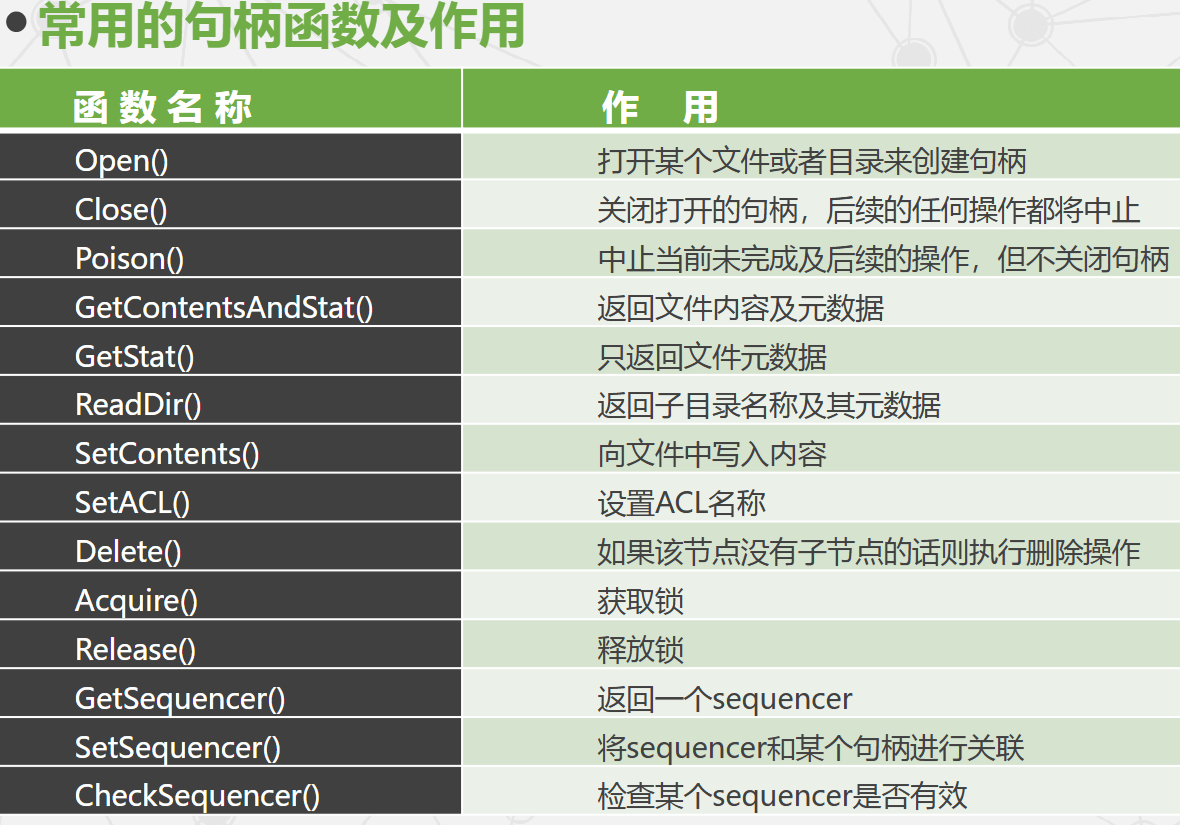
-
Chubby 客户端与服务器通信过程
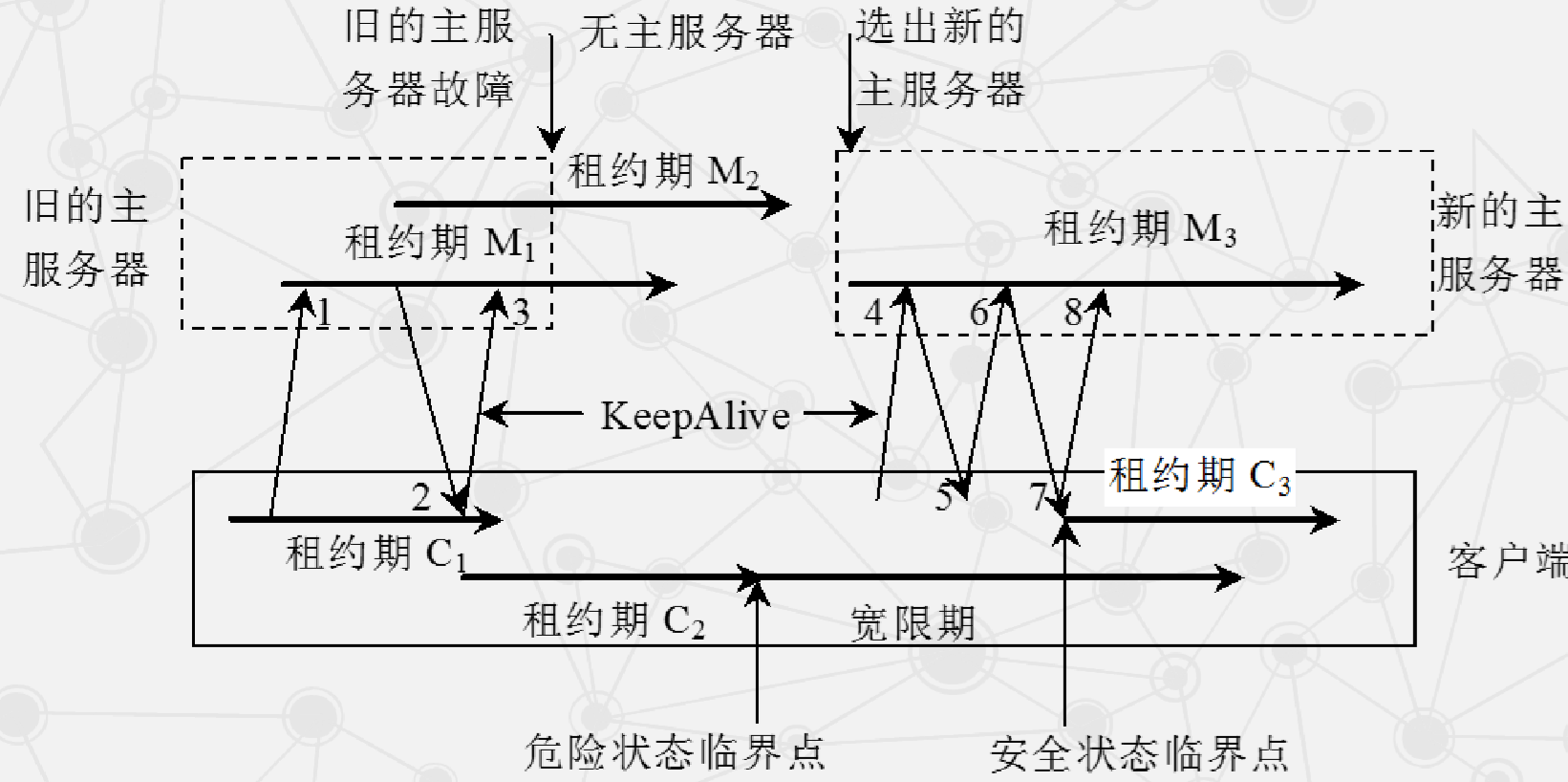
- 客户端与主服务器通过 KeepAlive 握手协议维持通信。
- 斜向上箭头表示一次 KeepAlive 请求,斜向下箭头表示主服务器回应。
- KeepAlive 周期性发送,用于延长租约有效期并携带事件更新。
- 主要事件包括:
- 文件内容被修改
- 子节点增加、删除、修改
- 主服务器出错
- 句柄失效
- 可能出现的两类故障:客户端租约过期、主服务器出错。
-
客户端租约过期
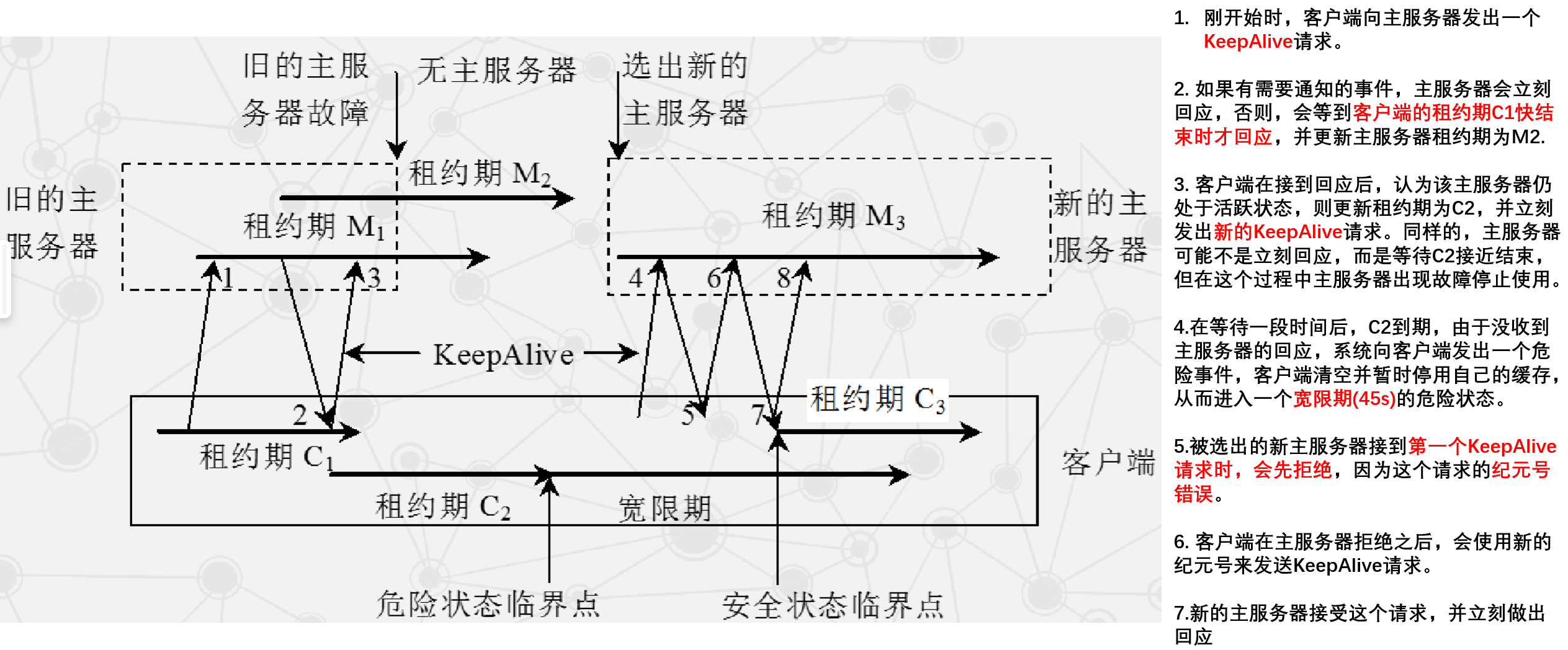
-
主服务器出错

Bigtable
-
Bigtable 概述
- Bigtable 是 Google 基于 GFS 和 Chubby 的分布式存储系统。
- Google 的 Web 索引、卫星图像等海量结构化与半结构化数据存储在 Bigtable 中。
-
Bigtable 的设计动机
- 需要存储的数据种类繁多。
- 服务请求量巨大。
- 商用数据库无法满足需求。
-
Bigtable 的基本目标
- 广泛适用性:面向一系列 Google 产品,而非单一产品。
- 强可扩展性:可随时加入或撤销服务器。
- 高可用性:尽可能保证系统持续可用,减少服务中断。
- 简单性:底层简单降低出错概率,并便于上层应用开发。
-
Bigtable 的数据模型
- Bigtable 是分布式多维映射表,通过行键(Row Key)、列键(Column Key)和时间戳(Time Stamp)索引。
- 数据不做解析,统一视为字符串,具体结构由用户定义。
- 逻辑表示:
(row:string, column:string, time:int64) -> string - 数据存储格式如下图:
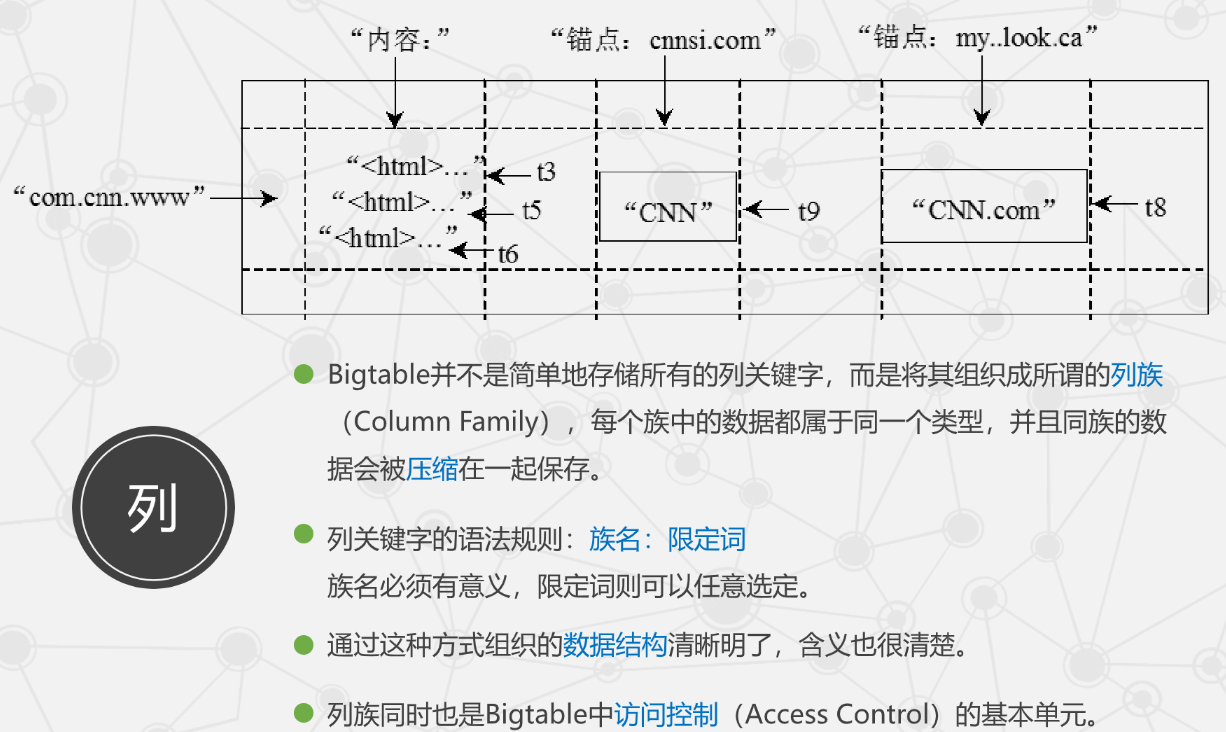
-
Bigtable 依赖组件
- Chubby
- WorkQueue
- GFS
-
Chubby 在 Bigtable 中的作用
- 选取并保证同一时间内只有一个主服务器(Master Server)。
- 获取子表服务器的位置信息。
- 保存 Bigtable 的模式信息与访问控制列表。
-
Bigtable 的系统组成
- 由客户端程序、一个主服务器和多个子表服务器构成。
- 客户端主要与子表服务器通信,几乎不与主服务器直接通信,降低主服务器负载。
- 主服务器负责元数据操作与负载调度,实际数据存储在子表服务器上。
-
主服务器的主要作用
- 新子表分配。
- 子表服务器状态监控。
- 子表服务器之间的负载均衡。
-
SSTable 与子表基本结构
- SSTable 是 Bigtable 的内部存储格式,文件存储在 GFS 上,可通过键查询值。
- SSTable 数据划分为块(Block),块大小可变,通常为 64 KB;文件末尾有索引记录块位置。
- SSTable 打开时索引加载到内存,可快速定位磁盘块。
- 子表地址查询采用类似 B+ 树的三层查询体系。
- 为减少开销,提高访问效率,Bigtable 使用缓存(Cache)与预取(Prefetch)。
-
Bigtable 的数据压缩
- 内存表达到阈值后停止使用并压缩成 SSTable。
- 三种压缩形式:
- 次压缩:旧内存表停止使用时执行,生成一个 SSTable。
- 合并压缩:定期将已有 SSTable 与内存表一起压缩。
- 主压缩:合并压缩的一种,将所有 SSTable 压缩成一个大 SSTable,并彻底删除被压缩数据以回收空间与保护敏感数据。
- 三个重要的优化措施
- 局部性群组:按列族将数据组织到同一 SSTable,提高访问局部性。
- 压缩:
- Bentley & McIlroy(BMDiff)在大扫描窗口压缩常见长串。
- Zippy 快速压缩,在 16 KB 扫描窗口内寻找重复数据。
- 布隆过滤器:长二进制向量与随机映射函数,用于读操作中判断子表位置。
Megastore
-
Megastore 提供的三种读
- current:在单个实体组内完成。开始前确保所有已提交写操作生效,然后从最后一个成功提交的事务时间戳读取。
- snapshot:在单个实体组内完成。读取已知的最后一个完整提交事务时间戳处的数据;此时可能有事务已提交但未生效。
- inconsistent:忽略日志状态,直接读取最新值,适用于低延迟且可容忍数据过期或不完整的读操作。
-
Megastore 事务的写操作
- 采用预写式日志(Write-ahead Log):所有操作先写日志,日志记录完成后才对数据执行修改。
- 使用乐观并发(Optimistic Concurrency):多个写操作竞争同一日志位置时,仅一个成功;失败者观察成功写入后中止并重试。
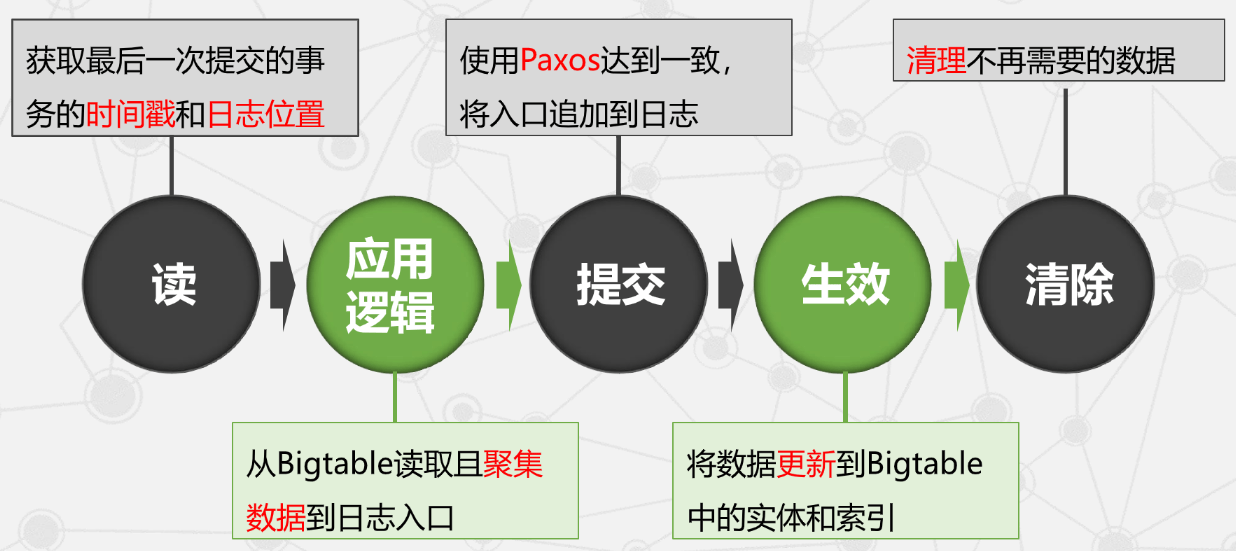
-
Megastore 的三种副本
- 完整副本:Bigtable 存储完整日志与数据。
- 见证者副本:参与 Paxos 投票,记录日志但不存储数据。
- 只读副本:不参与投票,仅读取过去某时间点的数据。
-
Megastore 的核心技术:复制
- 复制的日志
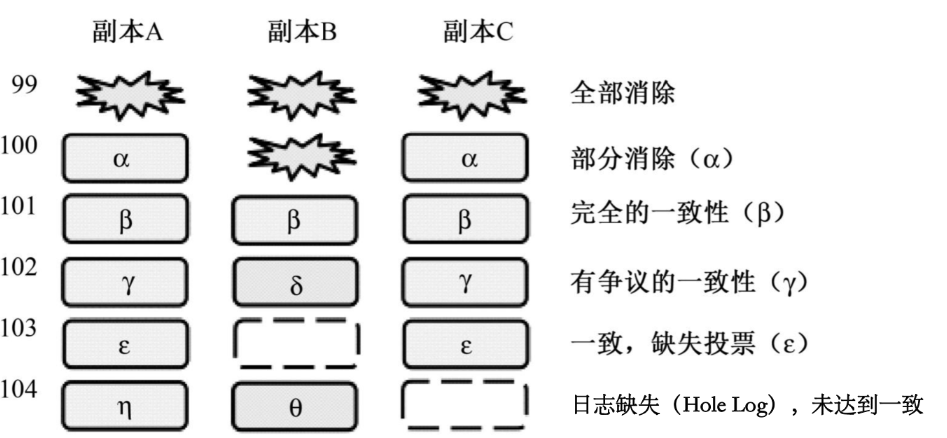
- 数据读取
- 进行一次 current 读之前,至少保证一个副本数据最新;即之前提交到日志的更新已复制并在该副本生效。
- 该过程称为追赶(Catchup)。
- 一次数据读取过程要经历五个步骤。
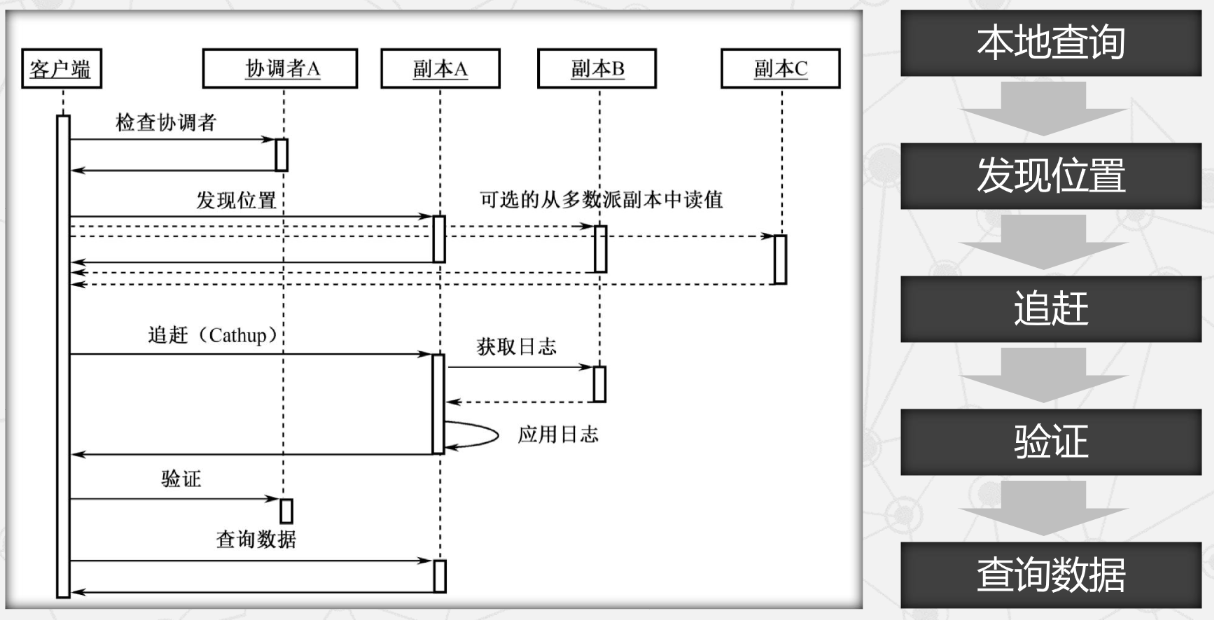
- 数据写入
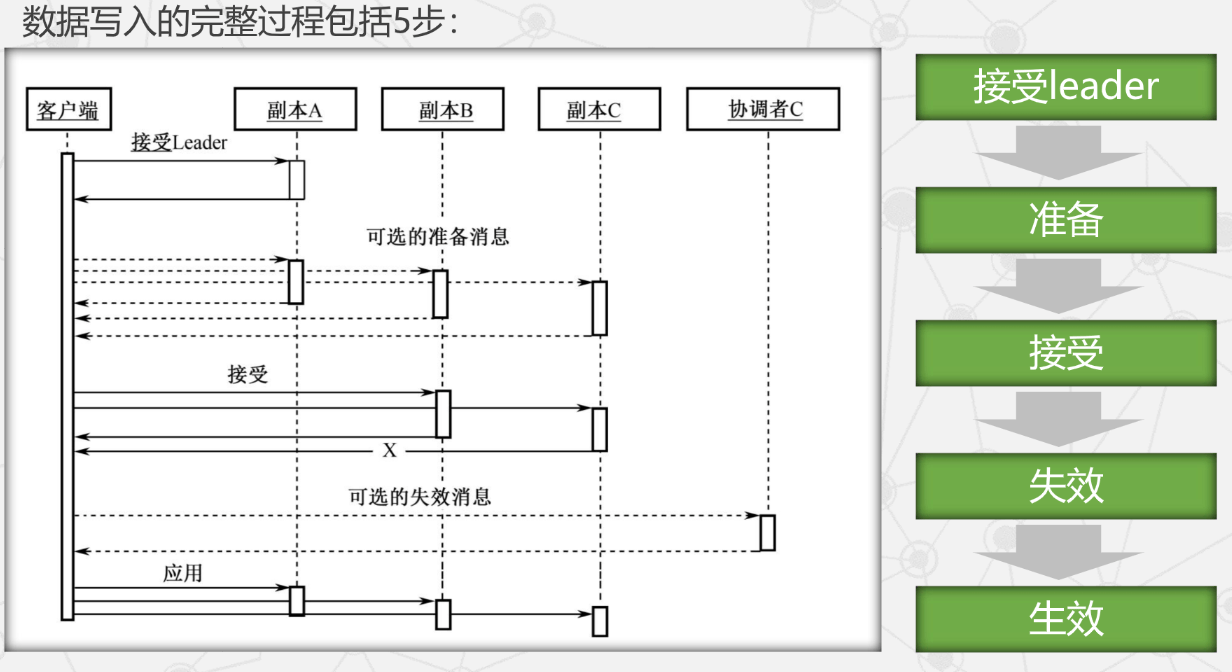
- 协调者的可用性
- 除了可用性问题,协调者的读写协议还需满足一系列竞争条件。
- 失效的信息总是安全的,但生效的信息必须谨慎处理。
- 复制的日志
OceanBase
-
OceanBase 的开发背景
- 为解决淘宝网大规模数据需求而产生。
- 高性能分布式数据库系统,支持海量数据管理(数千亿条记录)。
- 支持在数百 TB 数据上进行跨行、跨表事务,并支持 SQL 操作。
-
OceanBase 的系统架构
- 主要由五部分构成:
- 客户端
- 主备配置服务器 RootServer
- 双机热备,负载较轻,常与 UpdateServer 共用物理机。
- 更新服务器 UpdateServer
- 存储增量更新数据,通常一主一备。
- 基准数据服务器 ChunkServer
- 存储基准数据,通常为多台。
- 合并服务器 MergeServer
- 接收并解析用户 SQL 请求。
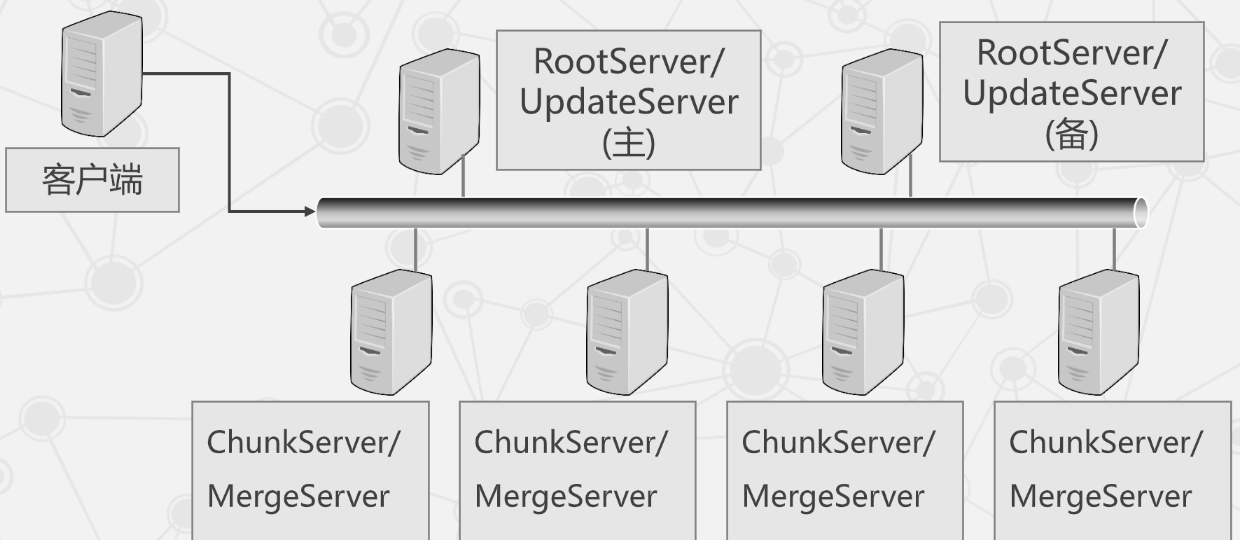
- 主要由五部分构成:
-
增量更新数据 vs 基准数据
- 增量更新数据:在初始数据基础上新增、修改或删除的动态部分,体现状态变化,通常较小。
- 基准数据:主体数据,在特定时间点或条件下被视为准确完整版本,用于对比、评估或测试。
-
基准数据 vs 全量数据
- 全量数据:某特定时刻系统内完整记录与字段的集合,数据量大、更新频率高。
- 基准数据:从全量数据中选取或按规则生成,代表系统典型特征,时间内相对稳定,数据量更小。
Dapper
-
Dapper 的两个基本要求
- 广泛可部署性:监控系统应覆盖尽可能多的 Google 服务。
- 不间断的监控:Google 服务全天候运行,需要 24/7 持续监控以捕捉难以复现的故障。
-
Dapper 的三个基本设计目标
- 低开销:降低对原系统影响,便于部署。
- 对应用层透明:不要求业务代码做额外调整。
- 可扩展性:满足服务与集群规模的持续增长。
-
监控系统的两种方案
- 黑盒(Black Box):轻便、基于统计推断消息关系,但精度不足。
- 基于注释的监控(Annotation-based Monitoring):给每条记录赋全局标识符,串联相关消息。
- Google 选择了基于注释的方案,并实现轻量级核心功能库以降低性能影响。
-
Dapper 的三个基本概念
- 监控树(Trace Tree):与特定事件相关的所有消息以树形组织。
- 区间(Span):树中的节点,一条记录;所有记录构成完整事件。
- 注释(Annotation):辅助推断区间关系,可包含自定义内容。
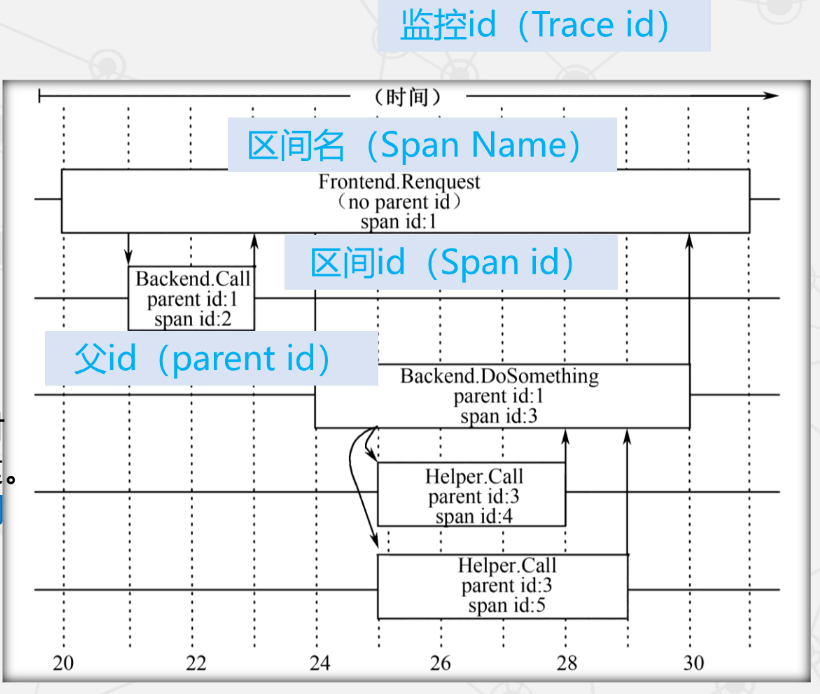
- 监控 ID 对每棵树的所有区间相同,随机分配且全局唯一,用于区分不同监控。
-
设计目标与关键技术总结
- 三个设计目标:低开销、对应用层透明(难度最大)、可扩展性。
- 两个关键技术:轻量级核心功能库、二次抽样技术。
-
Dapper 的使用场景

Dremmel
-
Dremel 的产生背景
- MapReduce 面向批处理,便携但效率低、延迟高。
- 实时交互式查询需求增强,Google 借鉴搜索引擎与并行数据库,开发了交互式查询系统 Dremel。
-
Dremel 的技术支撑
- 统一的存储平台:底层数据存储平台为 GFS。
- 统一的数据存储格式:数据可被不同平台复用。
-
Dremel 的列存储与嵌套数据模型
- Dremel 是第一个在嵌套数据模型基础上实现列存储的系统。
- 列存储的好处:
- 查询仅需访问涉及的列。
- 更利于数据压缩。
- 记录型数据包括三种类型:
- Required:必须出现且仅出现一次。
- Repeated:可重复出现。
- Optional:可选出现。
-
嵌套结构模式需要解决的问题
- 数据结构的无损表示:
- 重复深度 r 关注 repeated 类型。
- 定义深度 d 同时关注 repeated 与 optional 类型。
- 高效的数据编码:
- 核心思想是仅在字段 writer 有数据时更新,非必要不向下传递父节点状态。
- 数据重组:
- 为每个字段创建有限状态机(FSM),读取字段值与重复深度,顺序重建输出结果。
- 数据结构的无损表示:
PowerDrill
-
数据探索(data exploration)
- 在完成任务前反复试探查询:根据结果修正查询条件并再次提交,循环多次。
-
Ad hoc 查询(即席查询)
- 用户按需选择查询条件,系统据此生成统计结果。
-
PowerDrill 团队的两个假设
- 绝大多数查询是相似且一致的。
- 表中只有一小部分经常被使用,绝大部分使用频率低。
- 因此重点在于:
- 在查询中尽可能跳过不需要的数据分块。
- 减少内存占用,使更多数据可被加载到内存中处理。
-
PowerDrill 与 Dremel 的差异
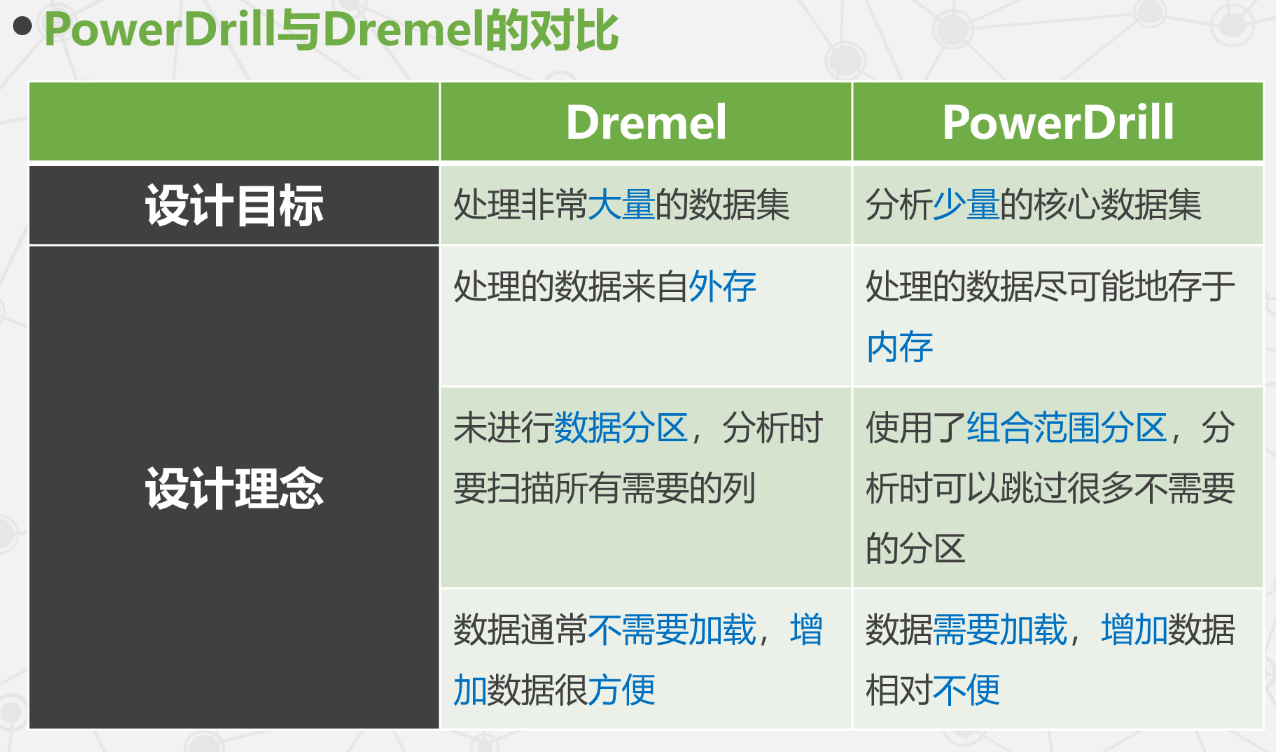
- PowerDrill 尽可能将数据加载到内存,计算方式更接近内存计算。
-
PowerDrill 的数据结构
- 使用双层数据字典结构。
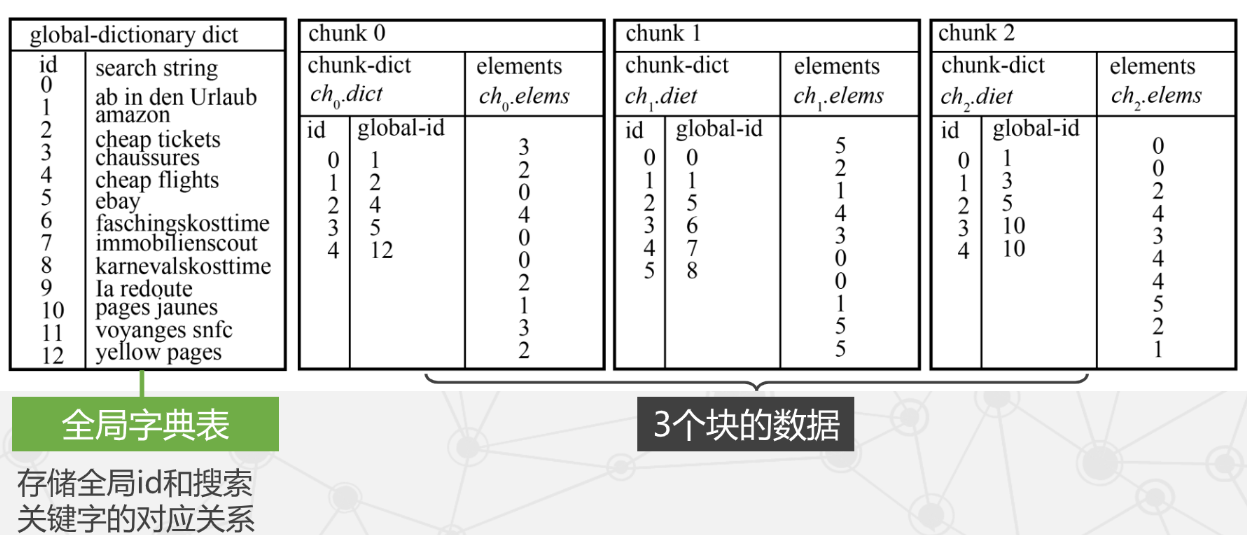
- 使用双层数据字典结构。
-
冷热数据分离策略
- 冷数据:访问频率低的数据。
- 热数据:访问频率高的数据。
-
游程编码(Run-Length Encoding)
- 将连续重复的数据用"值 + 连续次数"表示,例如
AAAAABBB可编码为A5B3。 - 适合重复度高的数据列,减少存储与内存占用,提高扫描效率。
- 将连续重复的数据用"值 + 连续次数"表示,例如
-
汉明距离
- 在信息论中,两个等长字符串之间的汉明距离是对应位置不同字符的个数。
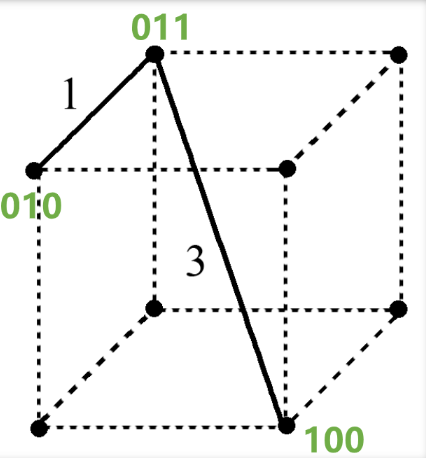
- 在信息论中,两个等长字符串之间的汉明距离是对应位置不同字符的个数。
-
Dremel 与 PowerDrill 对比
GAE
-
GAE 概述
- Google App Engine 是由 Python 应用服务器群、Bigtable 数据库与 GFS 存储服务组成的平台。
- 为开发者提供一体化、可自动扩展与升级的在线应用服务,是典型的 PaaS 平台。
-
GAE 的整体架构(四部分)
- 前端与静态文件:负责请求转发、负载均衡与静态文件传输。
- 应用服务器:提供可同时运行多个应用的运行时(Runtime)。
- 应用管理节点:负责应用的启停、资源管理与计费。
- 服务器群:提供基础服务,如 Memcache、Images、URLfetch、E-mail、Datastore 等。
AWS-Dynamo
-
Dynamo 概况
- Amazon 为保证稳定性采用完全分布式、去中心化架构,Dynamo 作为底层存储同样无中心。
- 仅支持简单的键/值(key/value)存储,不支持复杂查询。
- 存储数据为原始值(按位存储),不解析数据内容。
-
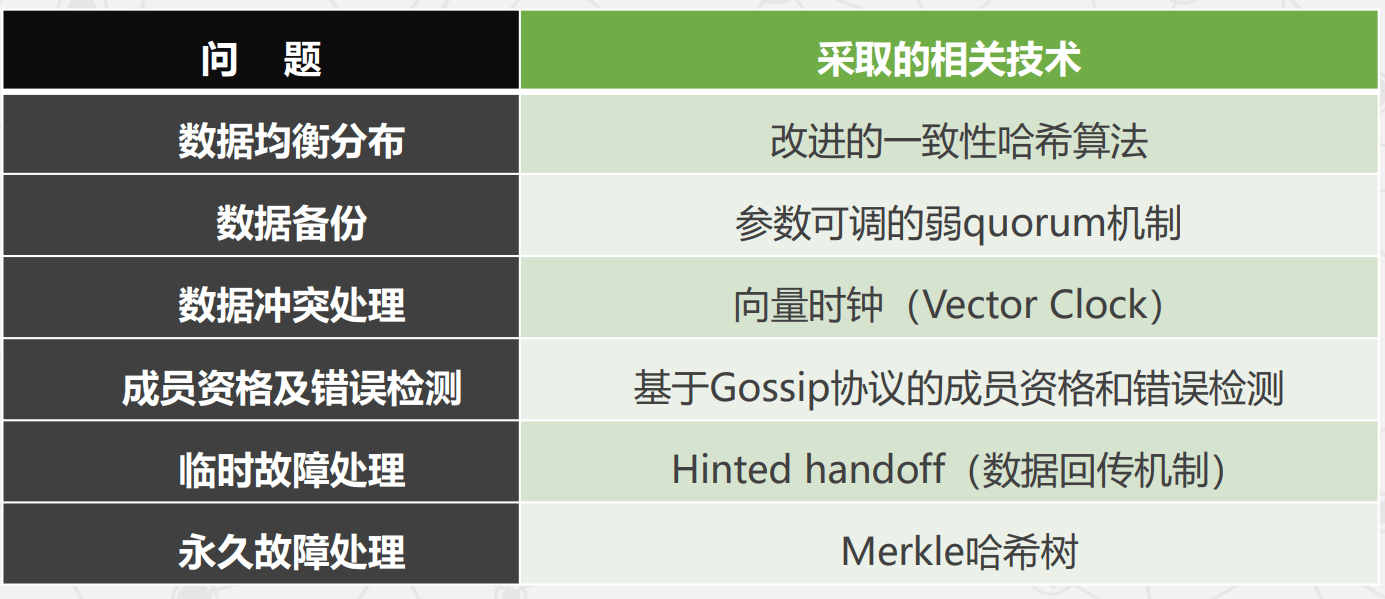
Dynamo 需要解决的主要问题及解决方案
-
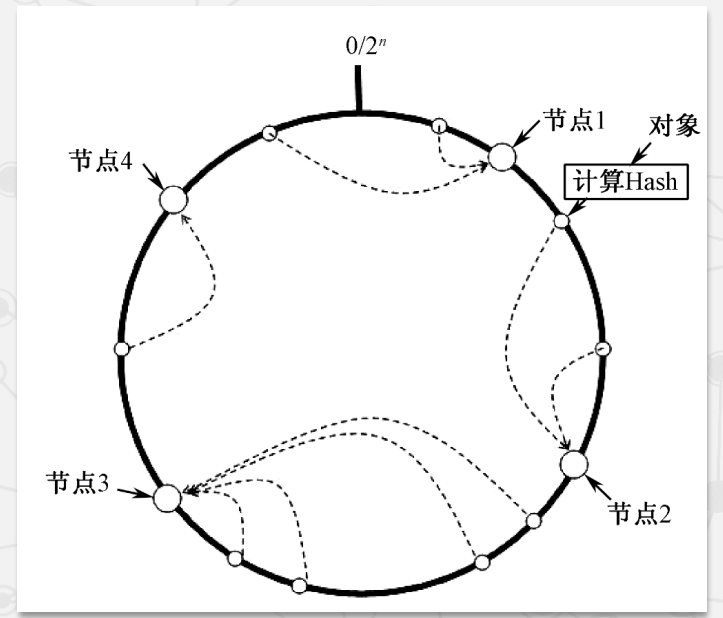
一致性哈希算法
- 数据存放到顺时针方向的第一个节点。
- 优点:新增/删除节点仅影响其前驱节点,其他节点不受影响,数据迁移开销小。
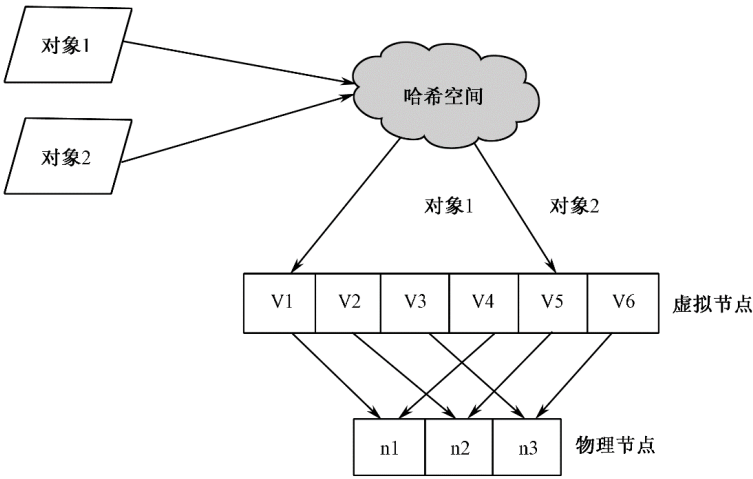
- 引入虚拟节点与数据分区后:
- 降低数据分布不均衡的概率。
- 节点变更时数据迁移进一步减少。
AWS-EC2-S3
-
EC2(Elastic Compute Cloud)概述
- AWS 重要组成部分,用于提供弹性可调的计算容量。
- 具备低成本、灵活性、安全性、易用性与容错性。
- 用户无需硬件投入即可快速开发、部署与管理应用。
-
EC2 基本架构
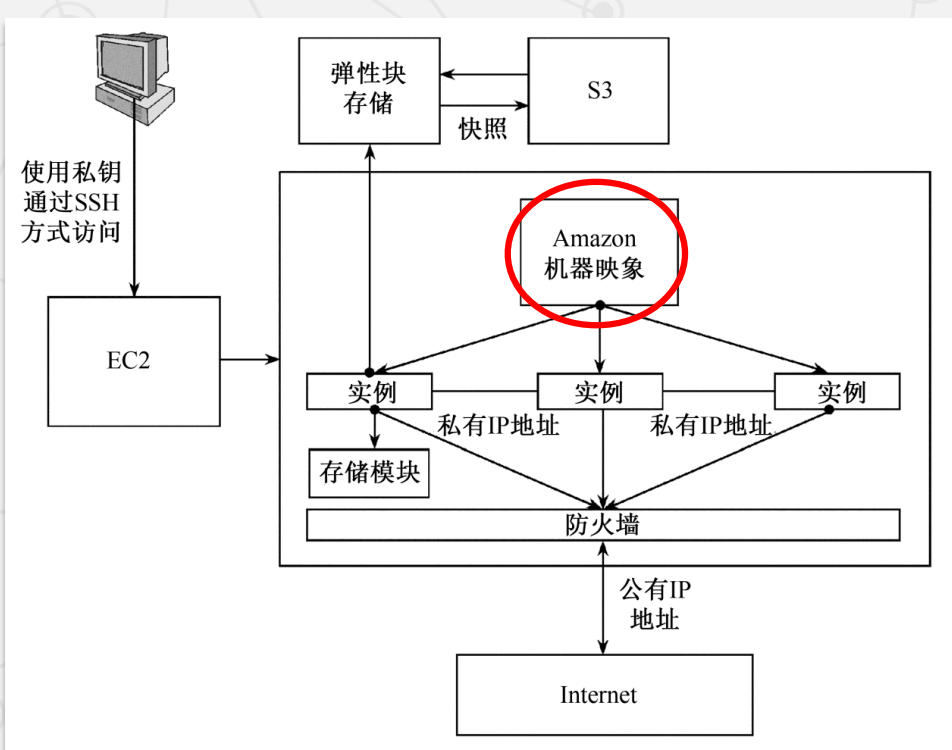
-
AMI(Amazon Machine Image)
- 包含操作系统、服务器程序、应用程序等配置的模板。
- 可启动不同实例,像传统主机一样提供服务。
- 分为 EBS(弹性块存储)支持与实例存储支持两类。
-
EBS 存储卷
- 适合细粒度高频访问且需持久保存的数据。
- 常用作文件系统或数据库主存储。
-
EC2 的关键技术
- 地理区域与可用区:EC2 包含多个地理区域,每个区域包含多个可用区。
- EC2 通信机制:
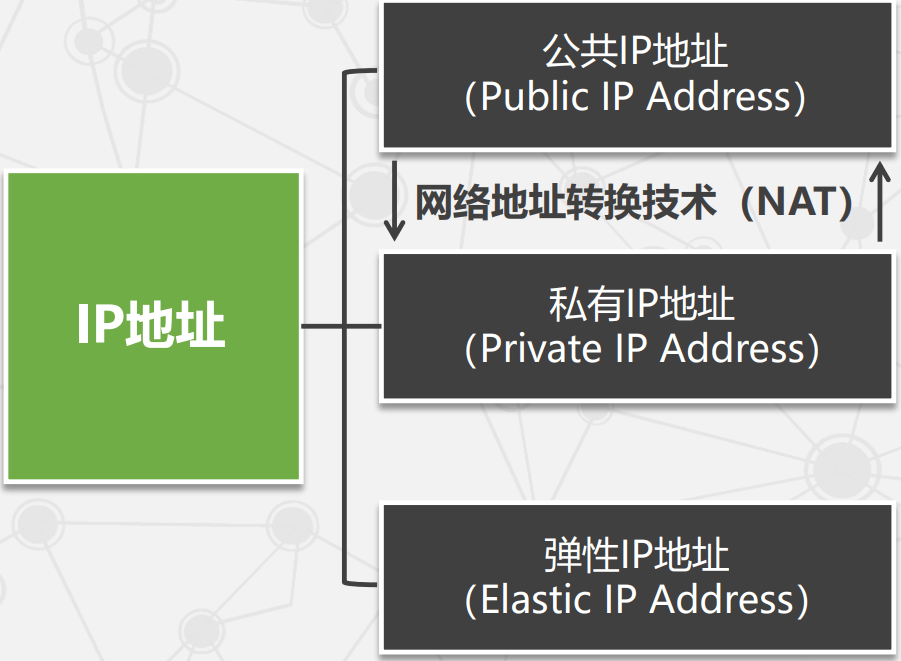
- 弹性负载均衡(Elastic Load Balancing):自动分发流量,平衡负载并提升容错能力。
- 监控服务 CloudWatch:提供 AWS 资源可视化监控。
- 自动伸缩(Auto Scaling):适合负载周期性变化的应用,基于 CloudWatch 自动伸缩。
- 服务管理控制台(AWS Management Console)。
-
EC2 的安全与容错机制
- 安全组:定义实例可接受的网络流量规则。
- SSH 密钥对(Secure Shell Key Pair):用于登录访问。
-
S3(Simple Storage Service)概述
- 构建在 Dynamo 之上,提供任意类型文件的临时或永久存储。
- 设计目标:可靠、易用、低成本。
- 两个基本概念:
- 桶(Bucket):用于存储对象,类似文件夹但不嵌套。
- 对象(Object):S3 基本存储单元,由数据和元数据组成。
-
S3 的安全措施
- 身份认证:加密 Hash 函数(HMAC-SHA1)。
- 访问控制列表(ACL)。
AWS-SimpleDB
-
CAP 原则
- 一致性(Consistency)、可用性(Availability)、分区容错性(Partition Tolerance)。
- 传统关系型数据库:更偏重 C 和 A,在 P 方面较弱。
- 非关系型数据库:更偏重 A 和 P,在 C 方面较弱。
-
SimpleDB 与 DynamoDB 的比较
- 二者都是 Amazon 提供的非关系型数据库服务。
- SimpleDB:
- 限制单表大小,更适合小规模、复杂查询的工作负载。
- 自动对所有属性建立索引,查询能力较强。
- DynamoDB:
- 自动将数据与负载分布到多台服务器。
- 不限制单表数据量,适合大规模负载。
AWS-RDS
-
Amazon RDS 概述
- 将 MySQL 等关系型数据库托管到集群中,在一定范围内提升可扩展性。
-
MySQL 集群架构
- 采用 Share-Nothing 架构:每台数据库服务器相互独立,通过网络互联,不共享资源。
-
SQS 的消息格式
- 消息 ID:系统返回,用于标识队列中的不同消息。
- 接收句柄:从队列接收消息时获得,用于删除等操作。
- 消息体:消息正文,文本数据,不能是 URL 编码方式。
- 消息体 MD5 摘要:消息体字符串的 MD5 校验和。
-
CDN
- 将网站内容发布到靠近用户的边缘节点,使不同地域用户就近获取内容。
AWS-其他
- 其他 Amazon 云计算服务
- 快速应用部署:Elastic Beanstalk
- DNS 服务:Route 53
- 虚拟私有云:VPC
- 消息与邮件:Simple Notification Service(SNS)、Simple Email Service(SES)
- 弹性 MapReduce 服务:Elastic MapReduce(EMR)
- 电子商务服务:DevPay、FPS、Simple Pay
- 内容分发网络:Amazon CloudFront
- 众包平台:Amazon Mechanical Turk
- 数据仓库服务:Redshift
- 应用流服务:AppStream
- 数据流分析服务:Kinesis