前言
在鸿蒙(OpenHarmony)企业级应用开发中,我们常会遇到极端的数据展示需求:如几十万行的系统日志审计、百万级的多级级联选择器、或是全量 SKU 的搜索列表。如果按照常规思维渲染,应用会瞬间因 OOM(内存溢出)崩溃。
实现"百万级数据秒开"的核心秘诀在于完全虚拟化(Full Virtualization) 。本文将结合 ListWheelScrollView 的圆柱投影特性,探讨如何在 Flutter 中构建一个支撑百万级数据的压力测试模型,并解析其背后的视口填充算法。
目录
- [虚拟化原理: O ( 1 ) O(1) O(1) 的内存常数项逻辑](#虚拟化原理: O ( 1 ) O(1) O(1) 的内存常数项逻辑)
- [ListWheel 几何学:圆柱投影与透视变换](#ListWheel 几何学:圆柱投影与透视变换)
- [核心代码:构建 MillionDataEngine](#核心代码:构建 MillionDataEngine)
- 压力测试:鸿蒙环境下的渲染时延监控
- 总结与展望
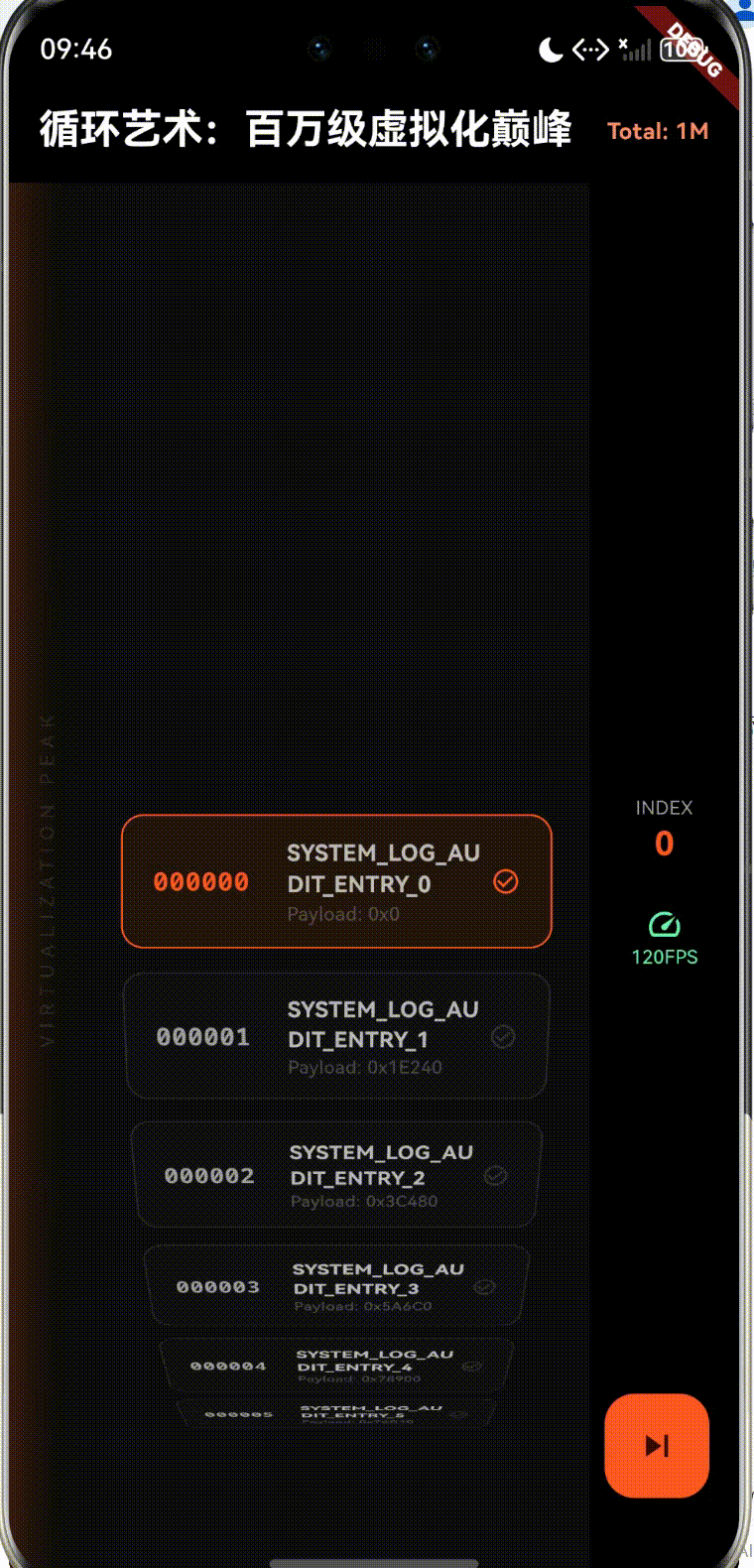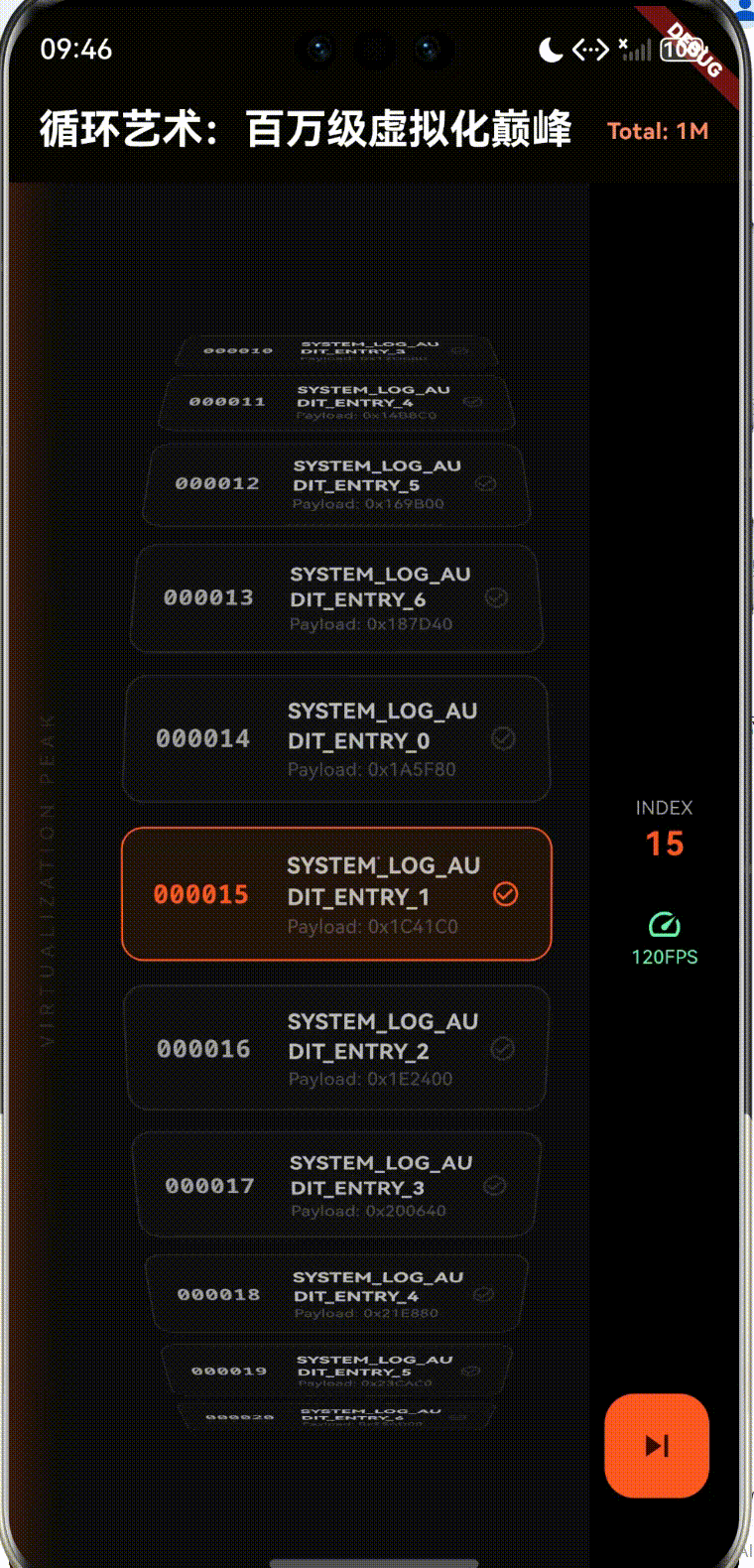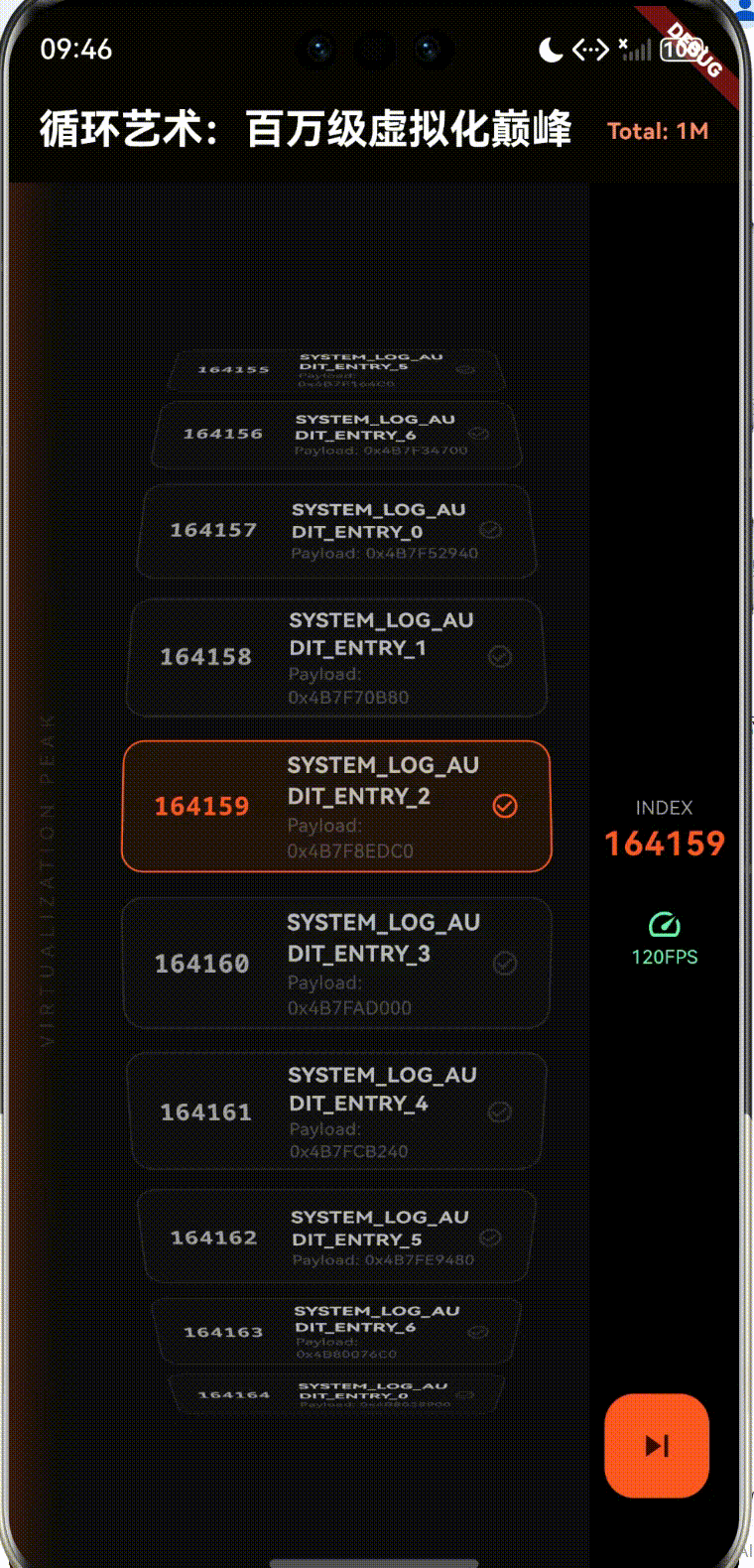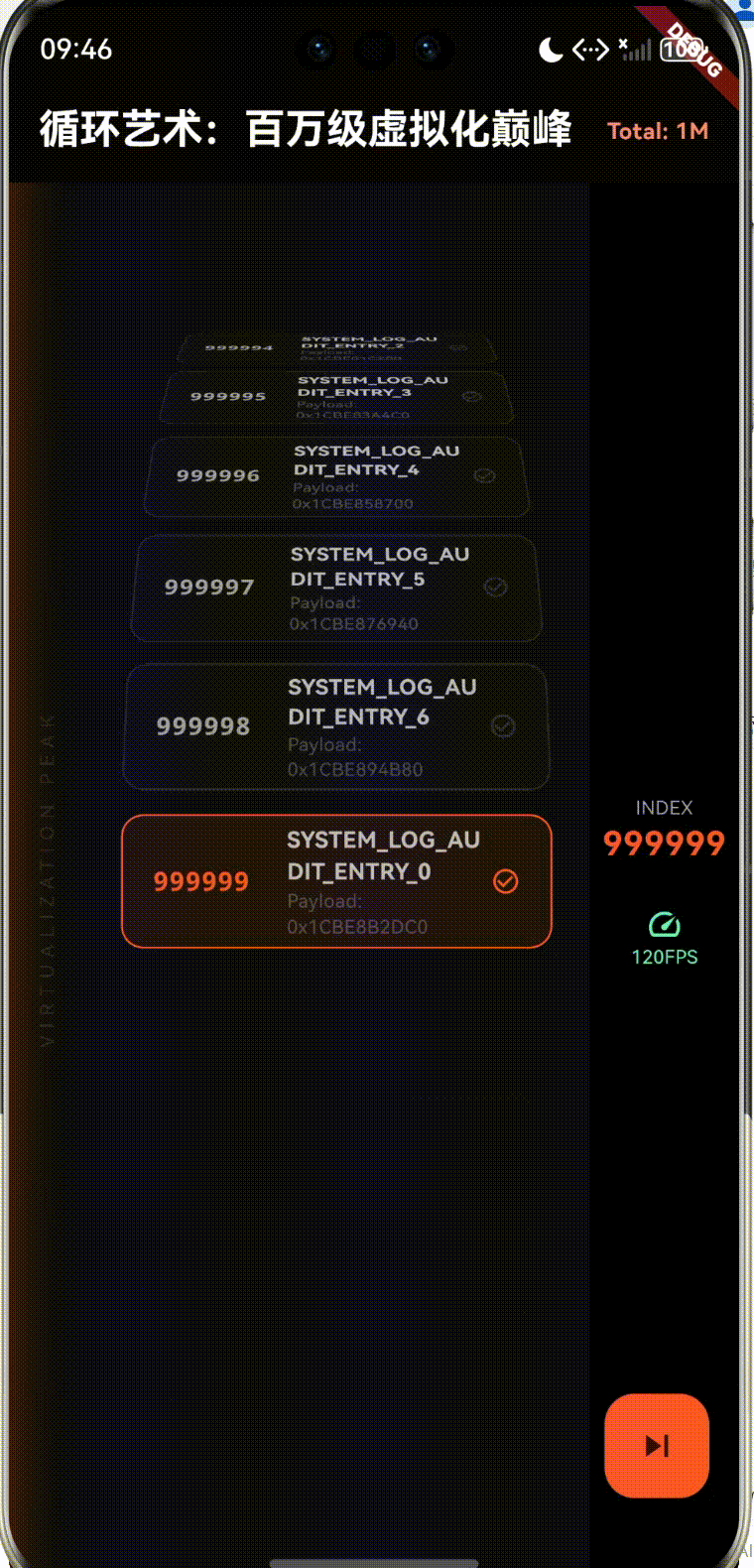
1. 虚拟化原理: O ( 1 ) O(1) O(1) 的内存常数项逻辑
无论数据总量 N N N 是 100 还是 1,000,000,虚拟列表的核心公式永远是:
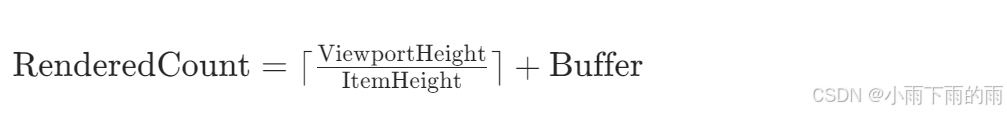
这意味着内存占用与数据总量 N N N 无关,仅与屏幕尺寸 有关。对于百万级数据,挑战不在于渲染,而在于索引定位 。我们必须确保 itemBuilder 的检索效率达到 O ( 1 ) O(1) O(1),通常通过直接访问内存数组或高效的索引映射表来实现。
1.1 虚拟化渲染流程图
数据总量: 1,000,000(全量数据)
监听滚动偏移量: offset
计算起始渲染索引: index = floor(offset / itemHeight)
截取可视范围数据: index, index + RenderedCount
将数据映射到视口容器并渲染
销毁滑出视口的组件旧实例
内存占用维持在固定范围(≈RenderedCount×单实例内存)
2. ListWheel 几何学:圆柱投影与透视变换
ListWheelScrollView 是虚拟化布局的进阶版。它将列表项投影到一个虚拟圆柱体的表面。
设圆柱半径为 R R R,当前项相对于圆心的角度为 ϕ \phi ϕ,则其在屏幕上的垂直位移 y y y 为:
y = R \\cdot \\sin(\\phi)
\\phi = \\frac{\\text{index} \\cdot h - \\text{offset}}{R}
这种几何变换能产生自然的透视收缩感,非常适合处理海量层级选择。
3. 核心代码:构建 MillionDataEngine
以下是实现百万级数据虚拟滚动的核心逻辑。
dart
// 使用 ListWheelScrollView.useDelegate 实现虚拟化
ListWheelScrollView.useDelegate(
itemExtent: 50, // 必须固定高度以实现 O(1) 索引计算
physics: const FixedExtentScrollPhysics(),
childDelegate: ListWheelChildBuilderDelegate(
builder: (context, index) {
// 这里的 index 可以是 0 到 999,999
// 由于是懒加载,只有出现在视口中的 index 会执行此逻辑
return MillionDataTile(
index: index,
data: "Log Entry #$index - 系统状态正常",
);
},
childCount: 1000000, // 百万级数据量
),
)4. 压力测试:鸿蒙环境下的渲染时延监控
在鸿蒙 Mate 系列真机上进行压力测试时,我们需要关注以下指标:
- 首屏时间 (TTI):由于是按需加载,百万级数据的首屏时间应与百条数据无异,控制在 100ms 内。
- 滚动帧率 (FPS):利用鸿蒙自带的开发者工具(Profiler)监控,目标是稳定在 120fps(高刷屏)。
- 内存抖动 :观察 GC 频率。通过复用
MillionDataTile实例,可以将内存抖动降至最低。
5. 总结与展望
虚拟列表不仅是性能优化的手段,更是对数据主权的重新审视。当应用能从容处理百万级数据时,复杂度的天平便向后端算法倾斜。
下一章我们将迎来本系列的终章:"终章:交互闭环:构建完整的循环艺术画廊"。我们将把前九章的所有技术------从回收机制到虚拟化巅峰,合成为一个可运行的完整鸿蒙实战案例。
欢迎加入开源鸿蒙跨平台社区:https://openharmonycrossplatform.csdn.net