数据预处理是一个机器学习项目最核心的步骤,我认为甚至要高于模型搭建,它决定着项目是否能够成功。
pandas教程
这里非常不建议大家先去看很多的函数再来写。写到哪不会了再去看函数用法会比较好。python的很多库函数内容非常多,看起来很费时间而且收获不大。
DataFrame
参数说明
DataFrame 是 Pandas 中的一个核心数据结构,类似于一个二维的表格。其不同的列可以包含不同的数据类型。
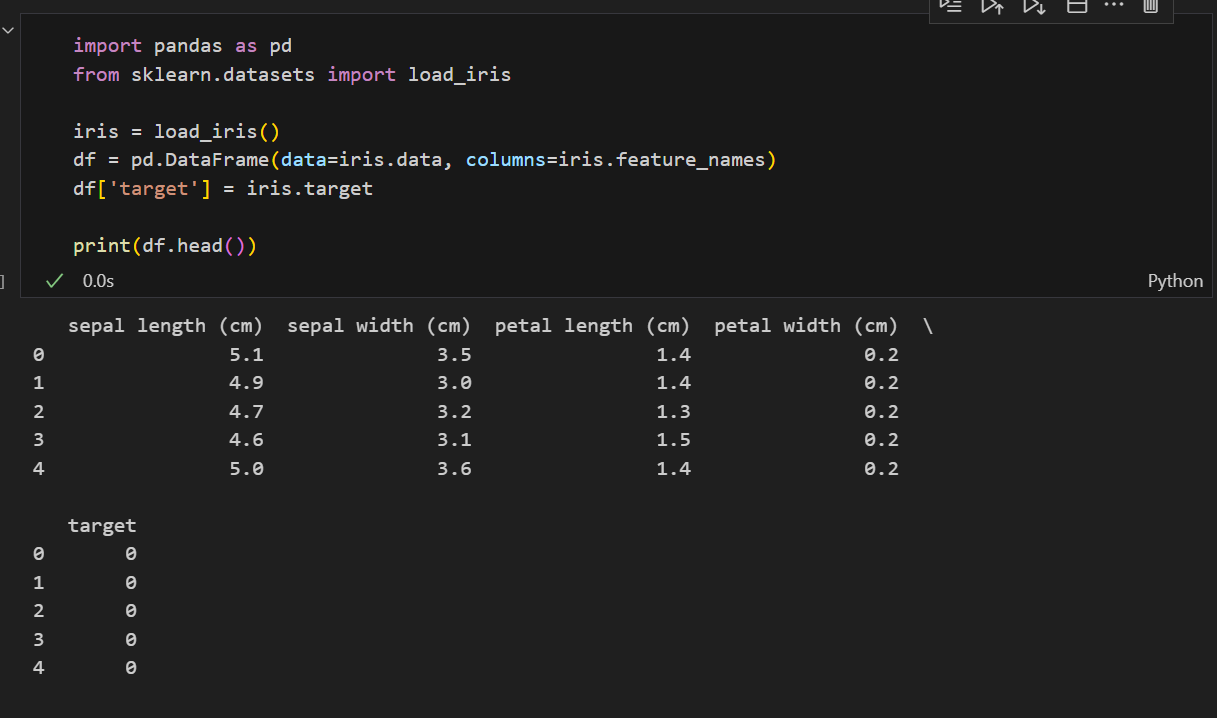
上面代码加载了鸢尾花数据集为DataFrame,并展示了其结构(注意为了展示,df'target' = iris.target是必须的,DataFrame默认不会加载target标签)
演示:修改行索引
python
iris = load_iris()
# DataFrame 参数说明
# data: 用于构建 DataFrame 的数据,可以是 ndarray、series、list 等
# columns: 列名
# index: 行索引
# dtype: 数据类型
# copy: 是否复制数据,默认为 False(True = 创建副本,False = 尽可能复用原数据)
col_index = [f"样本{i+1}" for i in range(len(iris.data))]
df = pd.DataFrame(data=iris.data, columns=iris.feature_names, index=col_index)此时再次打印df
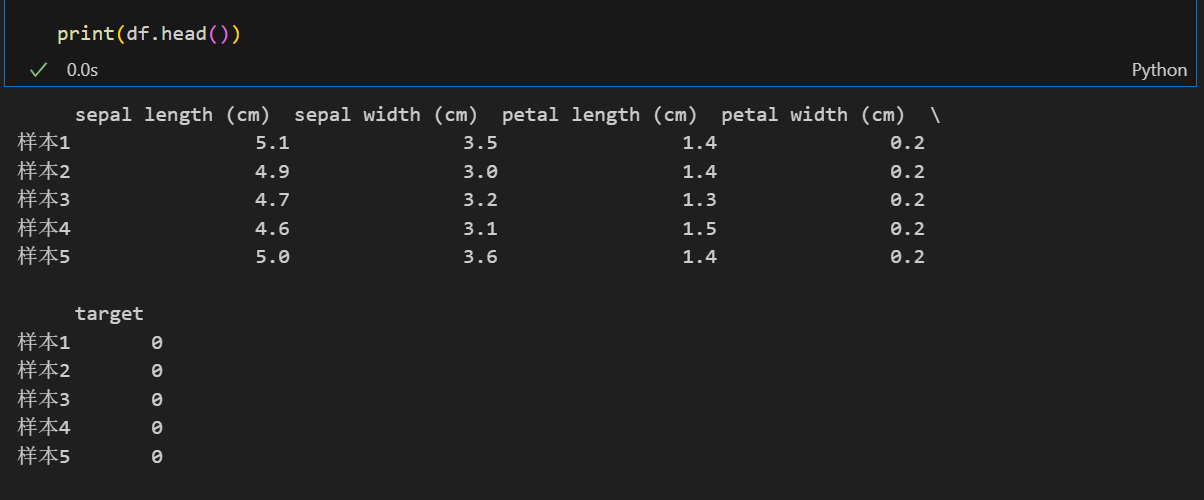
可以看到行索引已经从默认的0、1、2、3......改为了我们自己的规定
方法
1、查看
DataFrame有多种方法来查看数据,常用如下
python
print(df.head()) # 显示前五行数据
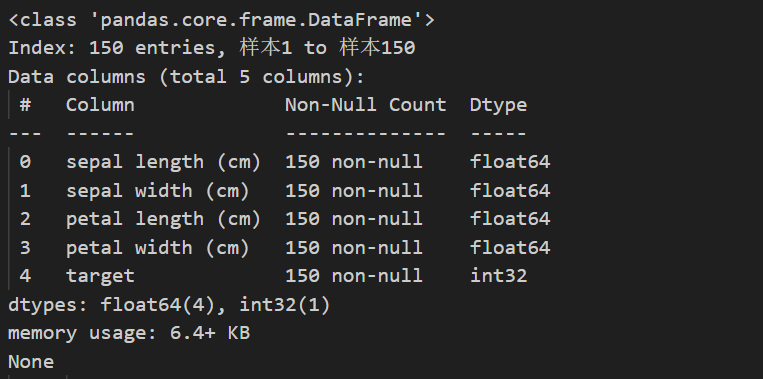
print(df.info()) # 显示 DataFrame 的简要信息
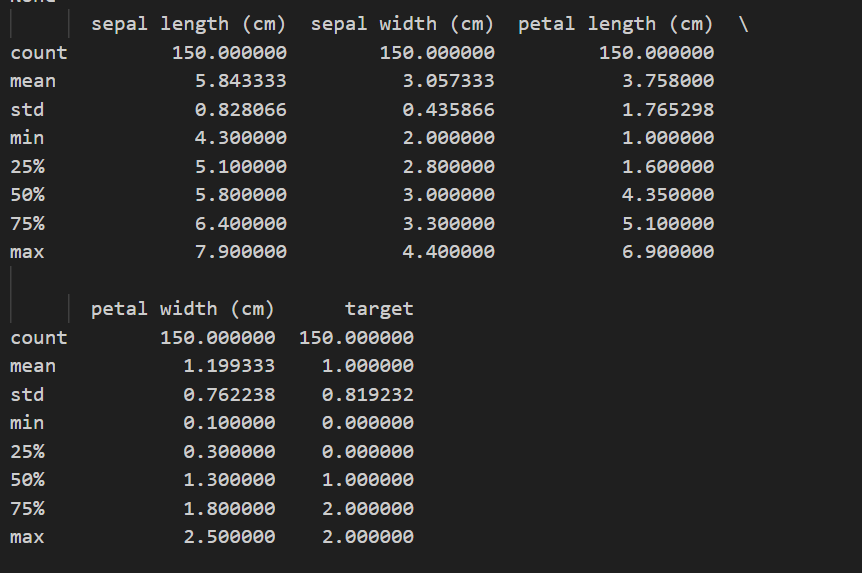
print(df.describe()) # 显示数值型列的统计信息输出如下
head(默认返回前五行、tail可以返回后五行)
info(列名、数据类型、非空值数量等)
describe(计数、均值、标准差等)
2、缺失值处理
鸢尾花数据集是一个非常规范简单的数据集,格式化且没有任何缺失值,但项目中遇到的绝大部分数据集中都会有缺失,因此缺省值处理是非常重要的
|--------------------------|-------------------------------------|-------------------------------------------------------------------------------------------------|
| 缺失率 > 80% 的字段 | 直接删除列 | df = df.drop(columns=["高缺失字段名"]) |
| 数值型字段(无明显偏态、无异常值) | 均值填充(保留数据集中趋势) | df["年龄"].fillna(df["年龄"].mean(), inplace=True) |
| 数值型字段(有异常值 / 偏态分布) | 中位数填充(抗异常值影响,更稳健) | df["收入"].fillna(df["收入"].median(), inplace=True) |
| 数值型字段(有时间趋势,如销量 / 股价) | 前值填充(ffill)/ 后值填充(bfill)/ 线性插值(更平滑) | df["日销量"].fillna(method="ffill", inplace=True)``# 线性插值更优``df["日销量"] = df["日销量"].interpolate() |
| 类别型字段(低缺失率,如性别 / 城市) | 众数填充(符合多数样本特征) | df["性别"].fillna(df["性别"].mode()[0], inplace=True) |
| 类别型字段(缺失率高 / 无明显众数) | 新增 "未知" 类别填充(更贴合实际,避免误导) | df["职业"].fillna("未知", inplace=True) |
| 关键字段(用户 ID / 订单号 / 核心指标) | 删除行(无法填充,缺失则样本无分析价值) | df = df.dropna(subset="用户ID", "订单号", axis=0) |
| 时序数据(按分组填充,如门店日销量) | 按分组(门店)填充该组的均值 / 中位数 | df["销量"] = df.groupby("门店ID")["销量"].fillna(df.groupby("门店ID")["销量"].median()) |
下一篇文章会用一个更复杂的数据集进行缺失值处理,此外还有异常值处理和重复值处理,也会在下篇文章一并讲解。
类别特征编码
对不同标签进行编码是非常重要的,因为数据集中通常包含字符串,但一般的模型不允许字符串作为输入。(鸢尾花数据集中,target标签已经进行过编码了,为了演示说明,下面例子中新加了一列species,用于表示不同鸢尾花的名字)
鸢尾花数据集中,三种不同类型的鸢尾花的target(即最后一列)分别被设置为0、1、2,我们可以修改这一表示
python
# 添加一列用于演示
species_mapping = {0: "setosa", 1: "versicolor", 2: "virginica"}
df["species"] = [species_mapping[target] for target in iris.target]
print(df.head())输出如下
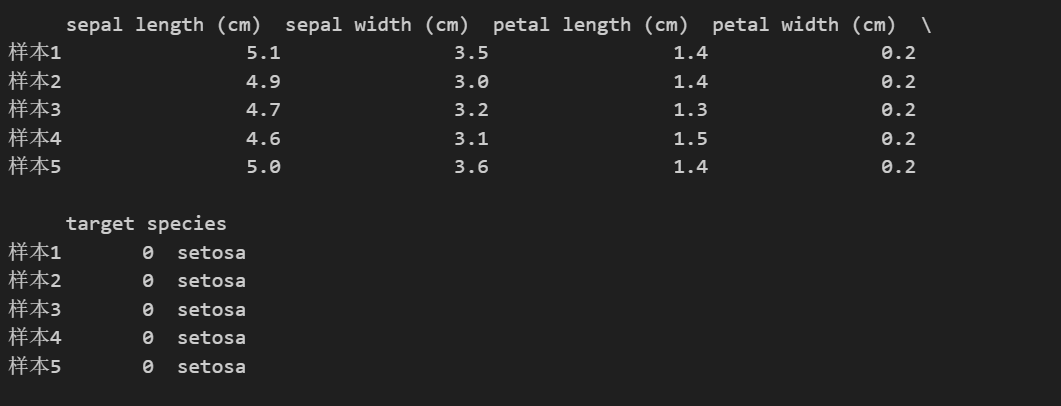
可以看到已经添加了一列species
手动编码
下面对species进行编码
python
# 对species进行手动编码
species_mapping = {"setosa": 0, "versicolor": 1, "virginica": 2}
species_encoded = df["species"].map(species_mapping)
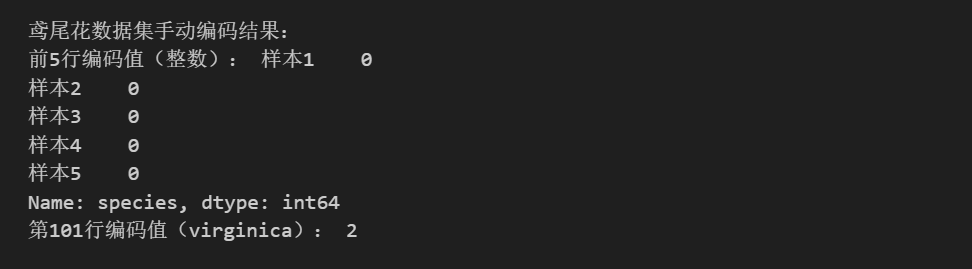
print("\n鸢尾花数据集手动编码结果:")
print("前5行编码值(整数):", species_encoded[:5])
print("第101行编码值(virginica):", species_encoded.iloc[100]) 输出如下
factorize () 自动编码
factorize() 是 pandas 专为类别特征设计的自动编码工具,核心规则很简单:
- 遍历目标列的所有值,先提取出唯一的类别值;
- 按照这些唯一类别第一次出现在数据中的顺序 ,为每个类别分配一个从
0开始的连续整数; - 返回一个元组:
(编码后的整数数组, 唯一类别列表),你可以通过索引提取编码结果。
简单说:它无需手动定义映射关系,完全根据类别首次出现的顺序分配编码。
python
# 对species列自动编码
target_encoded, target_cats = df["species"].factorize()
print("\n鸢尾花数据集自动编码结果:")
print("唯一类别列表(字符串):", target_cats)
print("前5行编码值(整数):", target_encoded[:5]) # 改为打印编码值
print("第101行编码值(virginica):", target_encoded[100]) # 改为打印编码值这里不使用iloc是因为factorize返回的第一个元素是编码数组,因此不需要使用DataFrame提供发访问方式。
输出如下

factorize () 自动编码虽然方便,但有时候会出现自己不知道编码是什么的情况,所以初学者可以先通过手动编码来熟悉几个简单项目,再用factorize () 来提高效率。
此外,一定要注意 factorize() 返回的是元组 ,第一个元素才是编码数组,第二个是类别列表;factorize()也不会改变DateFrame,因此在之后的训练中,需进行替换
python
# 假设 X 是特征矩阵(例如 df.drop('species', axis=1))
X = df.drop('species', axis=1) # 移除字符串列
y = target_encoded # 直接用编码后的整数标签独热编码
- 原理:将每个类别转为一个独立的二进制列(1 表示属于该类别,0 表示不属于),彻底消除「类别有序」的误导。
- 适用场景:无序类别(如鸢尾花品种、性别、城市),是分类任务中最常用的编码方式。
python
do_one_hot = pd.get_dummies(df["target"], prefix="species")
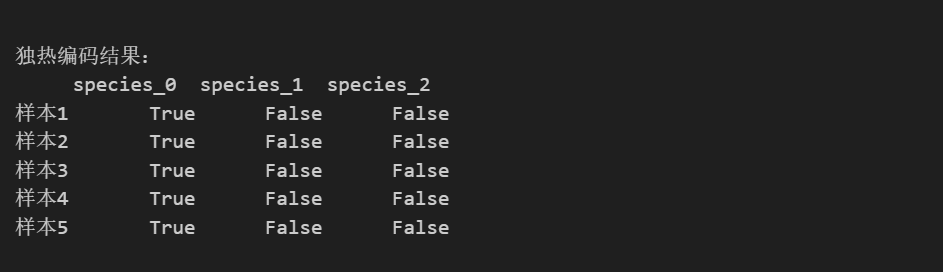
print("\n独热编码结果:")
print(do_one_hot.head())输出如下
如果不填写参数prefix,结果如下
对于分类问题(是或者不是)独热编码更好一些,如果是评分或者多分类,标签编码还是更常用一些,当然还有其它更多的编码方式,等遇到的时候在进行讨论。