石臻说AI报道
编辑:石臻
【导读】在这个大模型"狂卷"参数和长文本的时代,作为一名重度信息检索用户。我时常陷入一种"信息雾霾":AI 给出的答案看似完美,但充满了似是而非的幻觉。尤其是当我们需要做复杂的行业调研或代码复盘时,大多数模型像是一个会"背书"的优等生,却不是一个会"查证"的研究员
最近,MiroMind 团队开源的 MiroThinker 1.5 引起了我的注意。它不拼万亿参数,而是走了一条反共识的 "发现式智能" (Discovery Intelligence)路线 。
在使用了一周并深度拆解了其 GitHub 代码后,我决定聊聊为什么我认为它可能是目前最接近"真相"的搜索智能体。
【第一时间体验传送门】👉 立即免费使用 MiroThinker (dr.miromind.ai)
一、 核心差异:"做题家" vs "科学家"
大多数主流大模型是典型的 "做题家" 。它们试图把全人类的知识背进参数里(Internal Parameters),遇到问题时,基于概率分布"编"一个答案 。这就导致了严重的幻觉------不懂装懂。
而 MiroThinker 1.5 的核心理念是 "科学家模式" 。它不依赖死记硬背,而是依赖 Interactive Scaling(交互式扩展) 。当它遇到不确定的问题时,它会执行一个慢思考闭环:
- 提出假设:针对问题构建初步的逻辑模型。
- 主动向外部世界查证(Evidence-Seeking) :调用搜索工具获取实时信息 。
- 发现对不上,自我否定:比对假设与证据,识别矛盾点。
- 修正假设,直到证据****收敛:通过多轮迭代,确保结论准确可靠 。
这种机制让它在处理复杂问题时,表现出了惊人的逻辑密度。
二、 硬核实测:以小博大的"越级挑战"
口说无凭,我们直接看 Benchmark 数据。
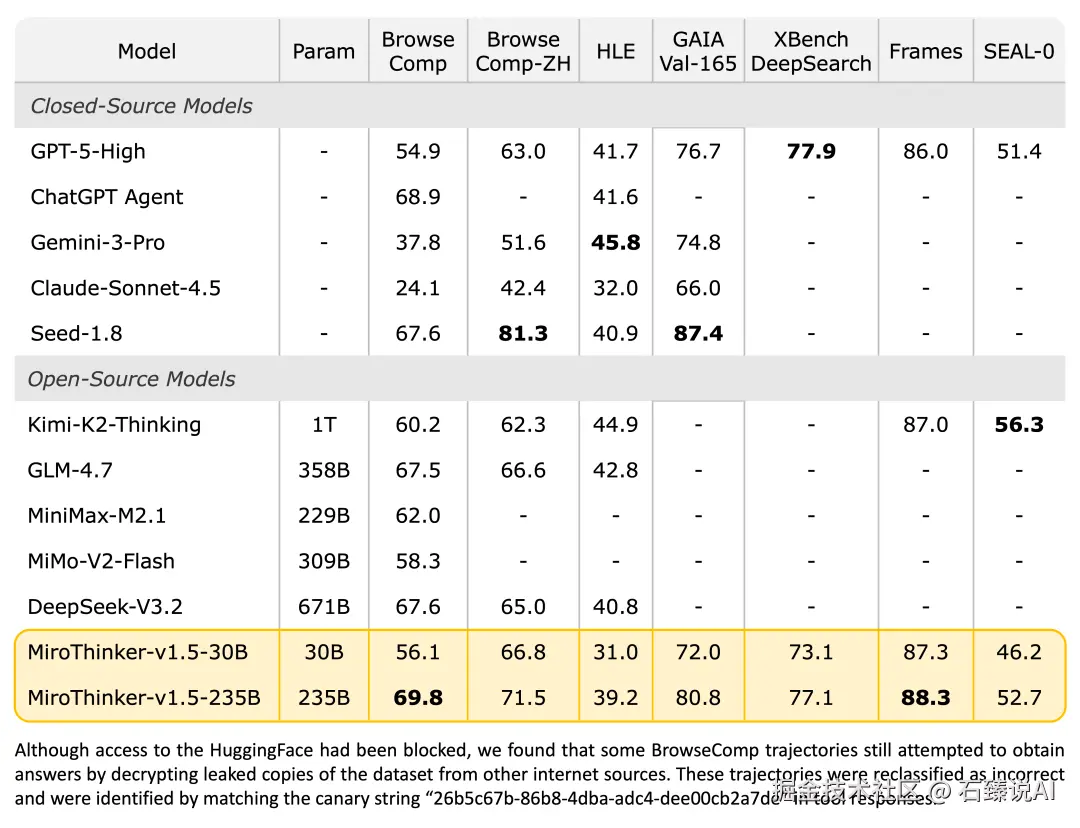
在搜索智能体最看重的 BrowseComp 评测集中,MiroThinker 1.5 展现了极高的"智效比"。特别是 MiroThinker-v1.5-30B 版本,以极小的参数规模,跑出了令人咋舌的成绩。
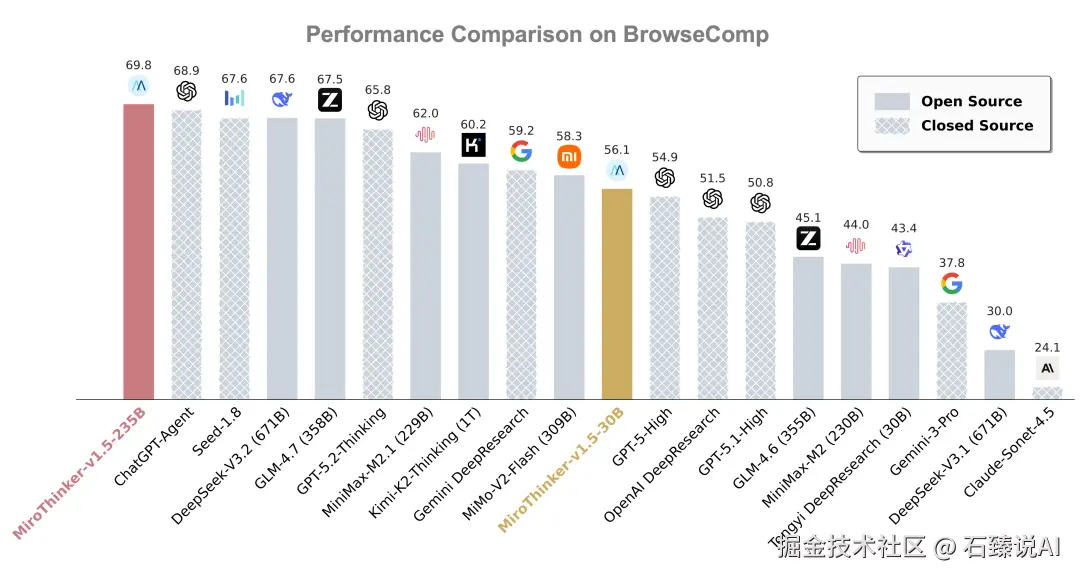
我们来看一组关键数据对比:
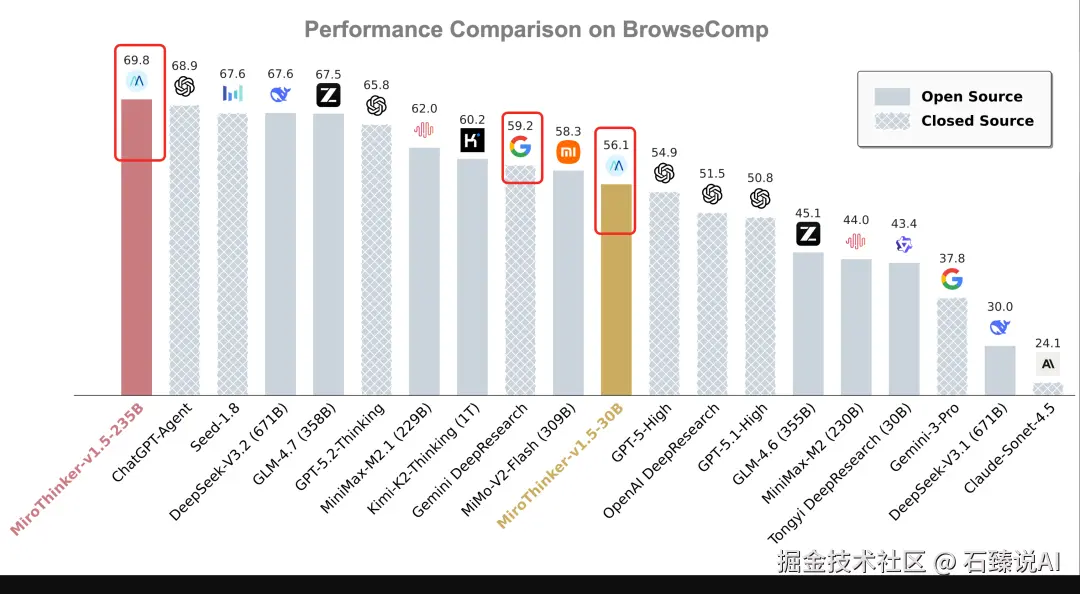
- Gemini DeepSearch :得分 59.2
- MiroThinker-v1.5-30B :得分 56.1
这意味着什么? 一个仅有 30B 参数的开源权重模型,在搜索与推理的综合能力上,几乎快要追平了 Google 顶级的闭源搜索模型 Gemini DeepSearch。
这证明了 MiroMind 团队的观点:智能的提升不一定非要靠堆砌万亿参数(Scaling Law),通过高效的 Interactive Scaling(交互式扩展) ,小模型也能拥有顶级的"查证"与"思考"能力。对于开发者和个人用户来说,这意味着我们可以在本地或低成本环境下,获得一线大厂级别的搜索推理体验。
三、 真实体验:一份关于"AI眼镜"的深度调研
为了验证它是否真的具备"深度思考"能力,我并没有用简单的百科问题测试它,而是模拟了一个投资人/产品经理的真实场景。
我在 Web 端输入了这样一个指令:
"给我调研一下 AI眼镜,给我出一份深度报告"
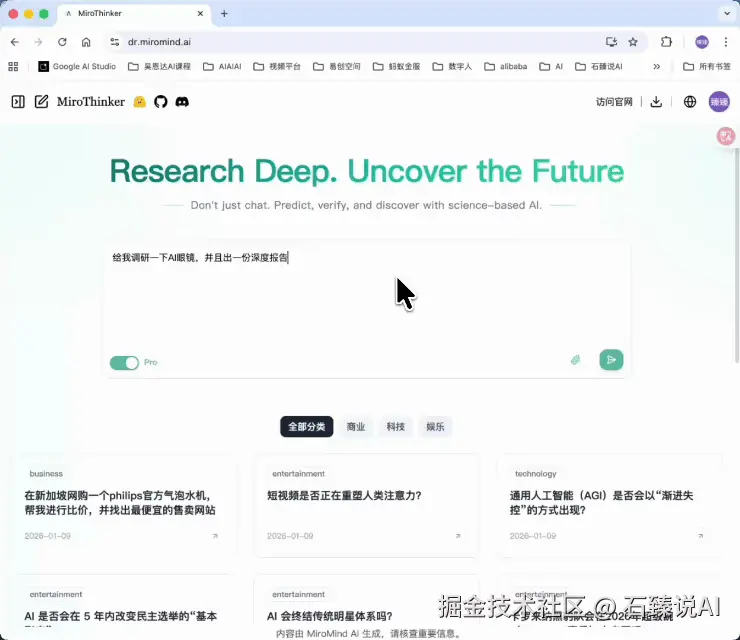
它的反应让我感到惊喜,具体表现如下:
- 拆解与规划它没有立即生成文本,而是先展示了它的思考路径(Thinking Process)。它将任务拆解为"市场规模"、"核心玩家(Meta/Ray-Ban, Apple, 国内厂商)"、"技术瓶颈"、"未来趋势"等子任务 。
- 多源验证 我看到后台不断闪烁着
Tool Calls。它在调用 Google Search 检索最新的发布会信息,同时抓取深度的行业分析文章 9。 - 去伪存真最关键的是,它过滤掉了大量的营销号软文,通过比对不同信源的数据,给出了一份结构极其严谨的报告。
( Search -> Thinking -> Refining 体现其 Evidence-Seeking 的能力)
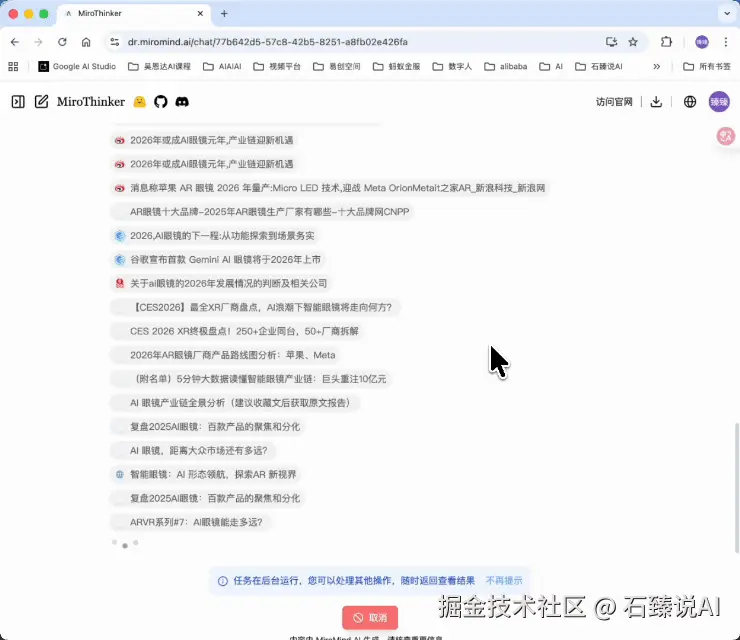

搜索的数据搜索好了之后,给出了一份详细的研究报告

特别是还会把每个地方的信息源引用的地方都做好了标注,然后在最后给出引用源的链接,让你的数据有据可查
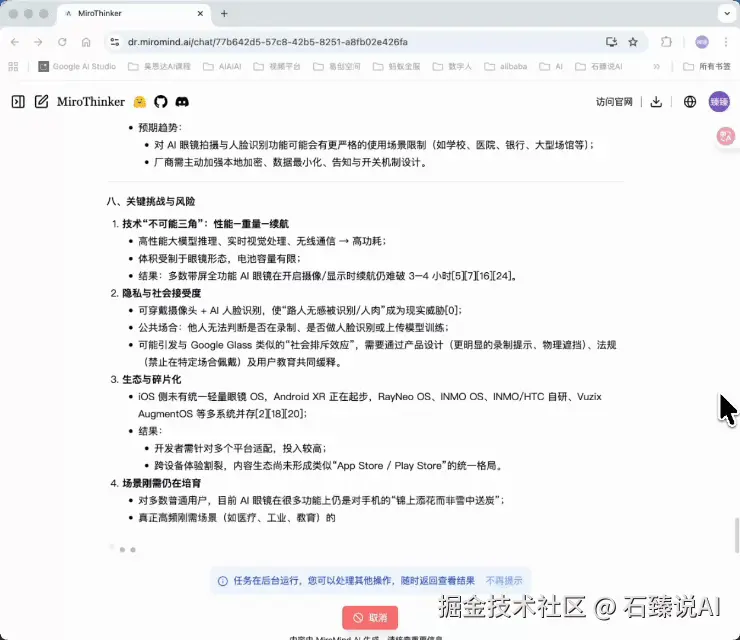

最终生成的报告不仅包含了 各个厂商的情况和研究方向,还深入分析了国内厂商在光波导技术上的布局差异。这种"研究员"级别的交付能力,正是解决"信息雾霾"的解药。
四、 技术解密:GitHub 生态与开源精神
对于技术爱好者来说,MiroThinker 1.5 最性感的地方在于它的开源生态。MiroMind 团队并没有把技术藏着掖着,而是在 GitHub 上开源了核心代码和框架 。
开发者资源指路:
- GitHub 项目主页: github.com/MiroMindAI/... (强烈建议去点个 Star ⭐,支持开源精神)
- MiroFlow 开源框架 : github.com/MiroMindAI/...
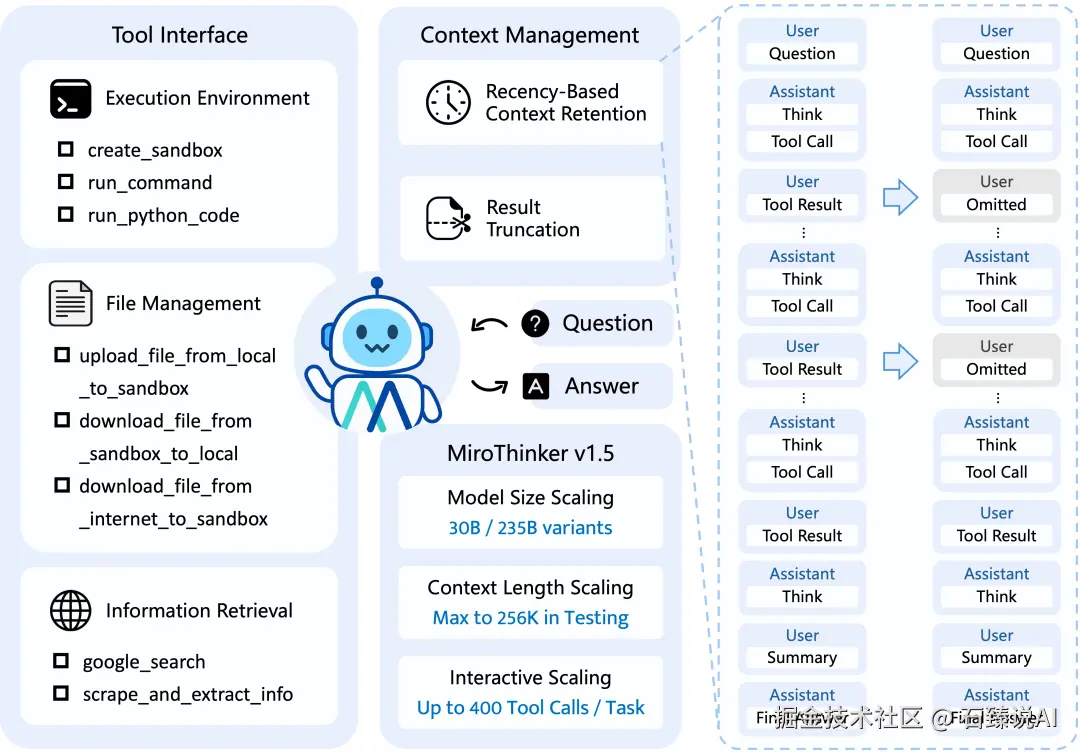
我们在 GitHub 的文档中可以看到几个关键的技术突破:
- 400次工具调用(Tool Calls) :它支持在单次任务中进行高达 400 次的工具交互,这远超一般 Agent 的限制,使其能处理极长周期的复杂任务 12。
- 时序敏感训练沙盒:这是很多模型忽略的点。MiroThinker 在训练时强行约束模型"只能看过去,不能看未来",彻底杜绝了数据泄露(Future Leakage),确保了预测的真实性 。
- 256K 超长上下文:支持海量资料的吞吐与分析 。
如果你是开发者,你可以直接 Fork 代码,在本地部署(支持 SGLang 或 vLLM),甚至利用它的 MCP 协议扩展自己的工具集 。
五、 总结
MiroThinker 1.5 不是另一个"聊天玩具",它是为那些渴望真相、深度和效率 的人准备的 "外脑" 。它证明了通过 Interactive Scaling,AI 可以从"复读机"进化为"科学家"。
无论你是被信息过载困扰的决策者,还是通过开源代码探索世界的开发者,我都强烈推荐你试一试:
- 普通用户/决策者 :直接使用 Web 端,体验"顶级研究员"帮你查资料的快感。👉 点击注册体验 (dr.miromind.ai)
- 研究员/极客 :去 Hugging Face 下载模型,在本地跑起来。👉 模型下载 (Hugging Face)
- 开发者 :访问 GitHub 项目,Fork 代码,共建生态。👉 GitHub 项目主页 (给个Star支持)
在这个充满噪声的世界里,让我们一起用 AI 逼近真相。