LLaMA-Factory微调多模态大模型Qwen3-VL
目录
[1. 显卡驱动](#1. 显卡驱动)
[2. 模型微调](#2. 模型微调)
[3. 模型导出](#3. 模型导出)
[4. 模型部署:vLLM服务](#4. 模型部署:vLLM服务)
[5. 测试效果](#5. 测试效果)
1. 显卡驱动
- 显卡型号:NVIDIA GeForce RTX 3090 24G
- 显卡驱动:NVIDIA-SMI 535.171.04
- CUDA: 12.2 ,Driver Version: 535.171.04
微调Qwen3-VL-2B模型,至少需要12G显存
2. 模型微调
项目采用大型语言模型工厂(LLaMA-Factory)对大模型微调,目前可支持Qwen3 / Qwen2.5-VL / Gemma 3 / GLM-4.1V / InternLM 3 / MiniCPM-o-2.6等大模型。下面以微调Qwen3-VL-2B-Instruct作为例子进行说明。
微调之前,请先下载Qwen3-VL基础模型。下载方法可以选择modelscope和huggingface,国内建议选择modelscope,避免翻墙问题。
modelscope下载Qwen3-VL-2B-Instruct方法,模型默认保存在~/.cache/modelscope/hub/models/
bash
# 使用modelscope下载模型Qwen3-VL-2B-Instruct
# 模型保持在 ~/.cache/modelscope/hub/models/
modelscope download --model Qwen/Qwen3-VL-2B-Instruct 微调其他Qwen3-VL版本,请参考地址:
- https://www.modelscope.cn/models/Qwen/Qwen3-VL-2B-Instruct
- https://www.modelscope.cn/models/Qwen/Qwen3-VL-4B-Instruct
- https://www.modelscope.cn/models/Qwen/Qwen3-VL-8B-Instruct
LLaMA-Factory安装教程,请参考官方文档:
安装好LLaMA-Factory后,激活环境,然后终端输入(默认端口是7860):
bash
export CUDA_VISIBLE_DEVICES=0 # 指定运行GPU
export GRADIO_SERVER_PORT=30000 # 指定gradio的端口(默认是7860,这里修改为30000)
export GRADIO_TEMP_DIR="~/.cache/gradio" # 指定gradio临时缓存路径,解决上传图片权限的问题
llamafactory-cli webui # 启动llamafactory web服务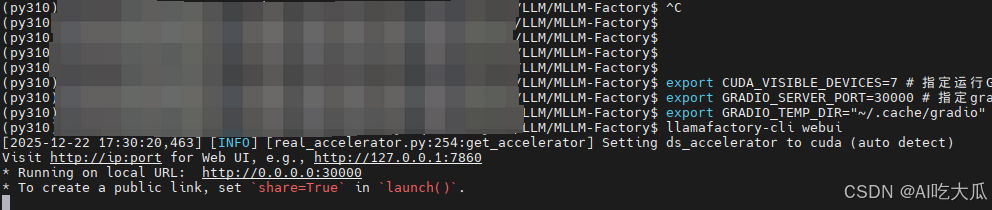
浏览器打开url http://0.0.0.0:30000/ (http://ip:port,默认端口是7860,为避免端口冲突,可以通过export GRADIO_SERVER_PORT=30000修改端口),并按照配置如下信息:
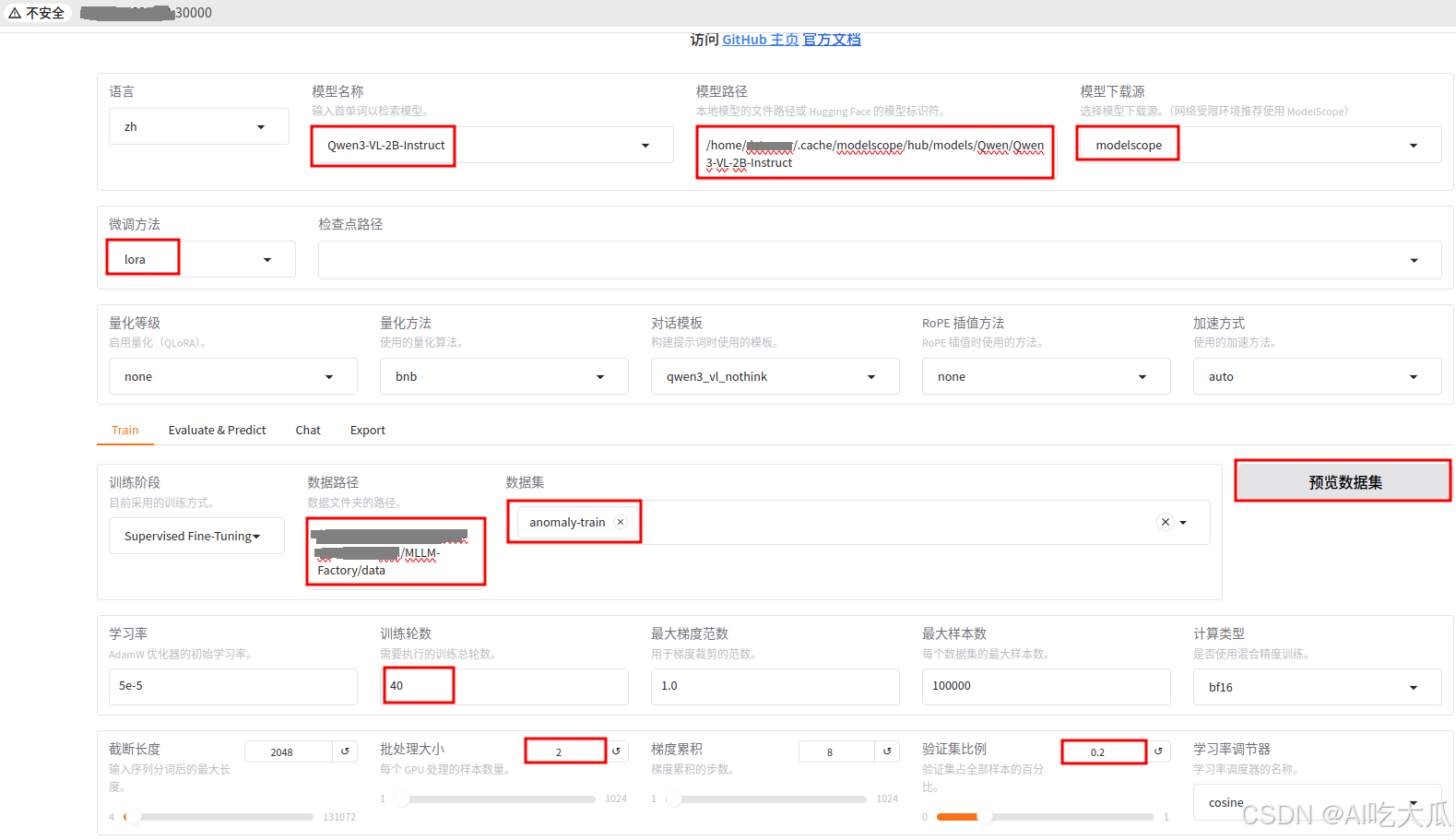
- 模型名称:选择"Qwen3-VL-2B-Instruct",你也可以使用Qwen3-VL更大参数量的模型,如7B
- 模型路径:请填写服务器Qwen3-VL-2B-Instruct模型文件路径绝对地址
- 模型下载源:可以选择"modelscope"和"huggingface",国内建议选择"modelscope"避免翻墙。注意:选择"modelscope"时,模型路径必须填写绝对地址,否则不能正常加载模型。
- 微调方法:建议选择"lora"
- 数据路径:数据路径必须包含dataset_info.json ,默认是LLaMA-Factory项目的./data路径,由于我们使用外部数据训练,因此数据路径设置为**我个人的项目(MLLM-Factory)根目录./**data绝对路径。MLLM-Factory/data已经存在了dataset_info.json数据集。
- 数据集: 数据集采样sharegpt格式,项目已经构建了一个多模态数据集anomaly-train 这是一个异常行为的视频数据集,详细说明请参考https://panjinquan.blog.csdn.net/article/details/156240847
- 预览数据集: 如果数据路径正常,点击"预览数据集",可以正常查看数据的,反之数据路径错误。
- 预览命令:可以查看训练的命令行
- 开始: 一切准备好后,点击开始训练
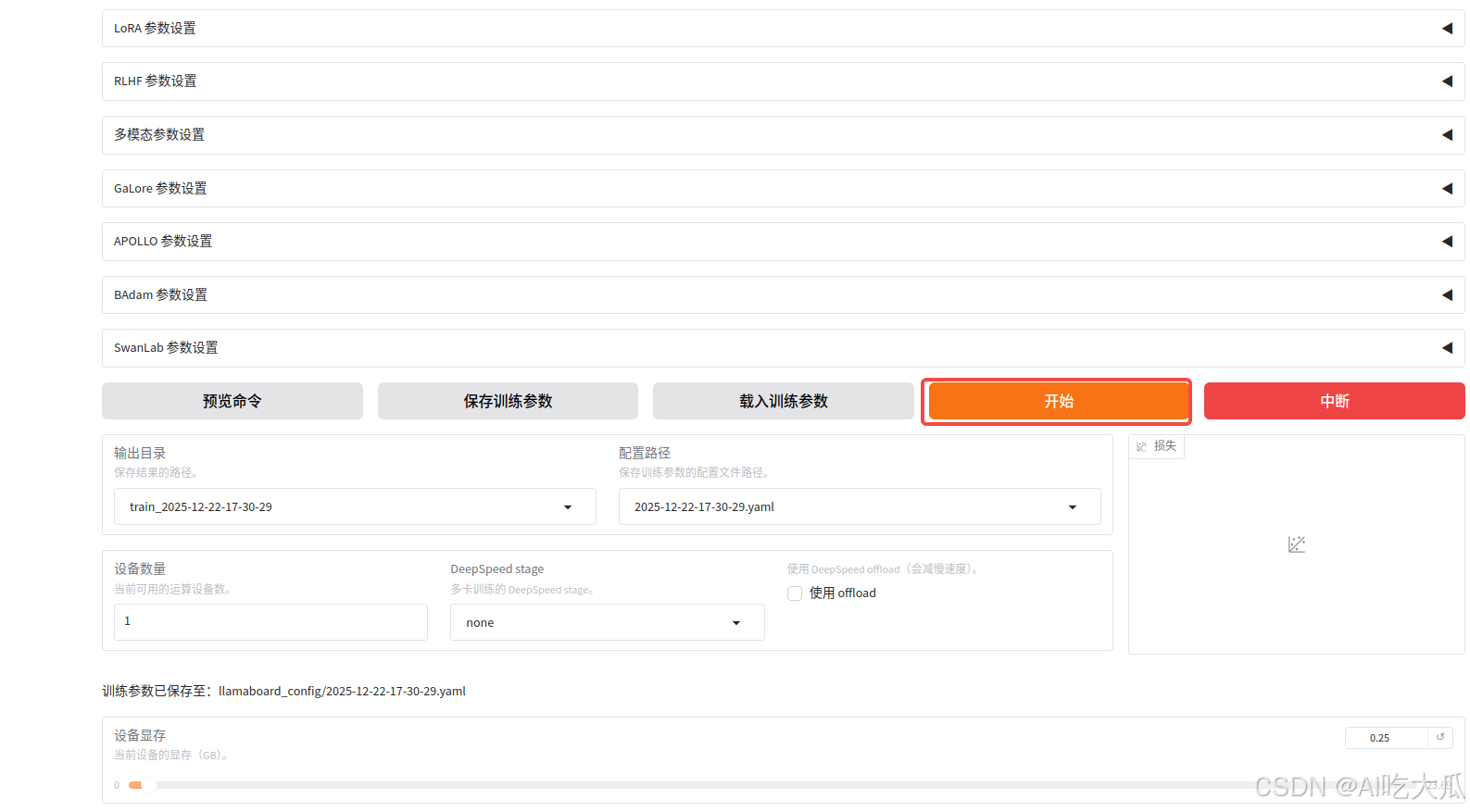
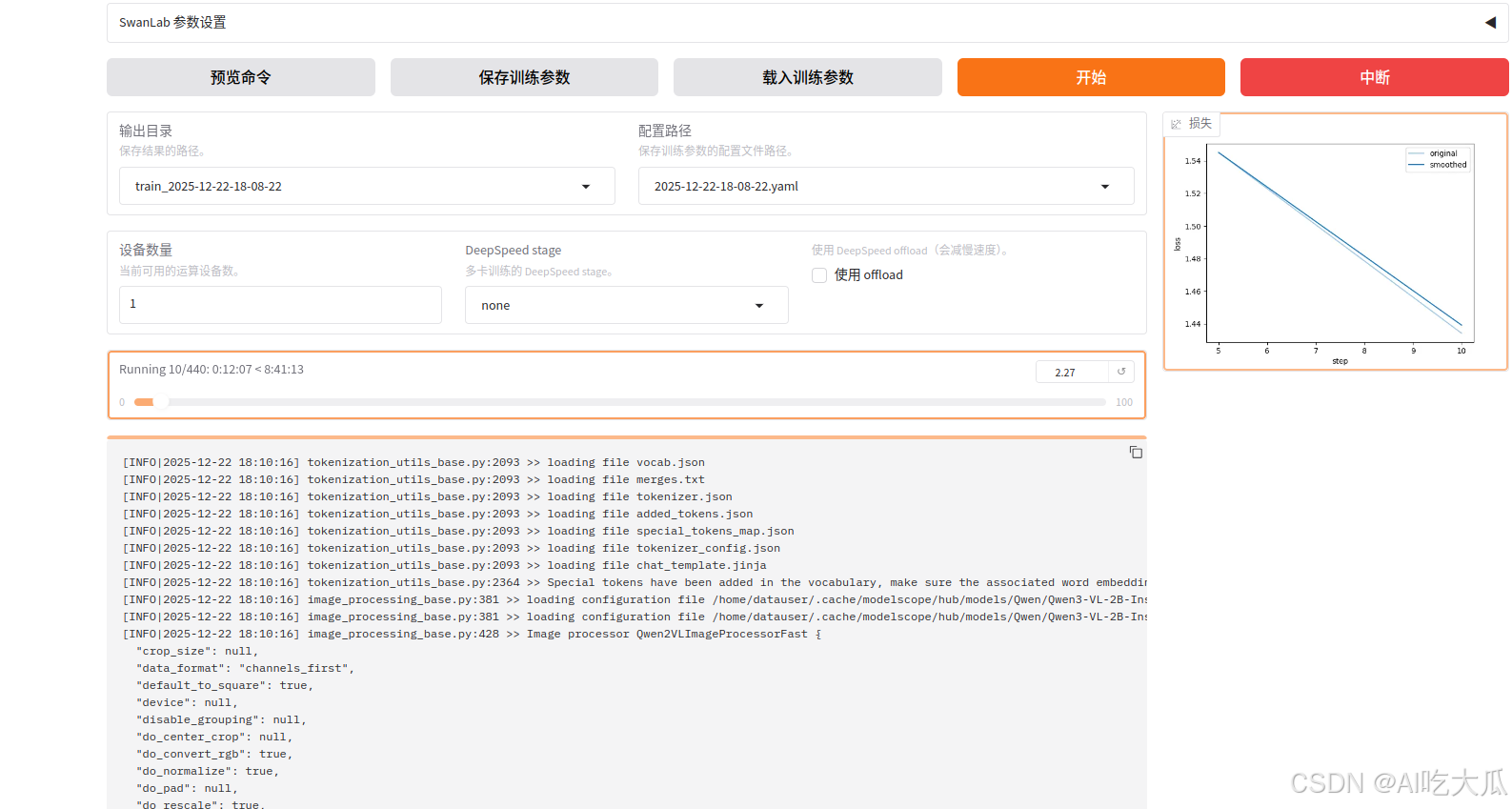
- 如果训练正常的,可以出现如下信息:
3. 模型导出
基于LoRA训练的模型,默认情况下,输出目录只保存了增量的训练参数;你还需要将原始基础模型(--model_name_or_path)和LoRA适配器参数(--adapter_name_or_path)进行合并,生成一个独立的、无需额外加载适配器即可运行的完整模型,便于后续部署或分享。
bash
#!/usr/bin/env bash
# TODO Lora+model合并,参数说明:
#--model_name_or_path:原始基础模型路径,可使用modelscope download --model Qwen/Qwen3-VL-2B-Instruct下载
#--adapter_name_or_path:LoRA适配器路径(即训练输出目录)
#--export_dir:合并后模型的保存路径
#--template default:Qwen3-VL 可使用 default,也可尝试qwen_vl(但通常自动识别)
#--trust_remote_code True:Qwen系列模型必需
export CUDA_VISIBLE_DEVICES=0
model_name_or_path=~/.cache/modelscope/hub/models/Qwen/Qwen3-VL-2B-Instruct
adapter_name_or_path=saves/Qwen3-VL-2B-Instruct/lora/train_2025-12-22-18-08-22/checkpoint-440
export_dir=saves/Qwen3-VL-2B-Instruct/lora/train_2025-12-22-18-08-22/Qwen3-VL-2B-Instruct
llamafactory-cli export \
--model_name_or_path $model_name_or_path \
--adapter_name_or_path $adapter_name_or_path \
--template default \
--finetuning_type lora \
--export_dir $export_dir \
--trust_remote_code Truellamafactory-cli export调用 LLaMA-Factory 的命令行接口(CLI),执行export操作,即导出合并后的模型。model_name_or_path $model_name_or_path指定基础模型(base model)的路径或 Hugging Face 模型 ID。例如:Qwen/Qwen3-VL-2B-Instruct或本地路径~/.cache/modelscope/hub/models/Qwen/Qwen3-VL-2B-Instruct。adapter_name_or_path $adapter_name_or_path指定微调后保存的 LoRA 适配器(adapter)的路径。通常是通过 LLaMA-Factory 微调后生成的包含adapter_model.safetensors或adapter_model.bin的目录。template default指定对话模板(chat template)名称。default表示使用 LLaMA-Factory 中预设的默认模板(通常适用于无特殊对话格式的模型)。其他值如llama3、chatglm3等会根据模型格式自动选择对应的输入格式。finetuning_type lora指定微调方法类型。此处为lora,表示使用的是 LoRA(Low-Rank Adaptation)微调。LLaMA-Factory 也支持full(全参数微调)或pissa等类型。- **
export_dir $export_dir**指定合并后模型的输出目录。导出的模型将保存在此路径下,包含 tokenizer、config、权重等完整结构,可直接用于推理或部署。 trust_remote_code True允许加载远程自定义代码(如某些 Hugging Face 模型需要modeling_xxx.py等自定义文件)。对于需要自定义建模逻辑的模型(如 ChatGLM、Qwen 等)必须启用该选项。
4. 模型部署:vLLM服务
模型训练好后,项目推荐使用vLLM部署模型
- 源码:https://github.com/vllm-project/vllm
- 文档:https://vllm.hyper.ai/docs/
- 安装:pip install vllm
bash
#!/usr/bin/env bash
# TODO 启动vllm服务
export CUDA_VISIBLE_DEVICES=0
# http://0.0.0.0:8000/v1
# model_path=~/.cache/modelscope/hub/models/Qwen/Qwen3-VL-2B-Instruct # 原始基础模型路径
model_path=saves/Qwen3-VL-2B-Instruct/lora/train_2025-12-22-18-08-22/Qwen3-VL-2B-Instruct # Lora微调(合并)后的模型路径
vllm serve $model_path --dtype auto --max-model-len 7680 --max_num_seqs 32 --api-key token-abc123 --gpu_memory_utilization 0.95 --trust-remote-code- api-key是自定义的服务接口的API访问密钥,后面接口调用需要使用。户端请求需包含:Authorization: Bearer token-abc123,保护服务器免受未授权访问
- model_path 请填写Lora微调(合并)后的模型路径
- dtype auto自动选择模型加载的数据类型,优先使用模型配置文件指定的 dtype。如果没有指定,会根据模型大小和可用 GPU 内存自动选择。常见选择:float16、bfloat16、float32
- max-model-len 设置模型支持的最大上下文长度(token 数),通常是 2048 或 4096
- max_num_seqs 设置批处理的最大序列数,控制同时处理的最大请求
- gpu_memory_utilization 设置 GPU 内存利用率目标,0.95 的含义:尝试使用 95% 的可用 GPU 内存
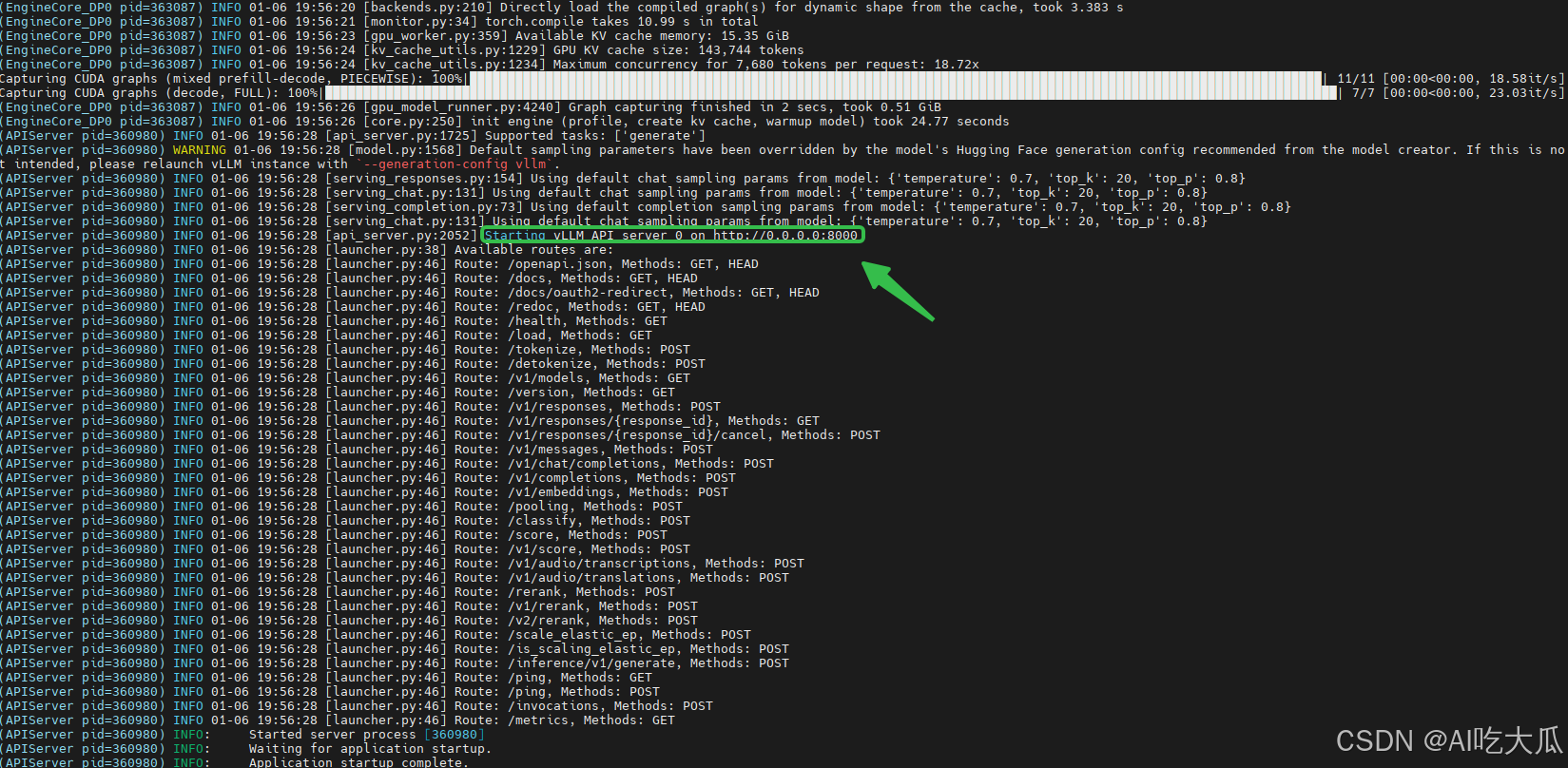
启动成功后,可以看到 Starting vLLM API server 0 on http://0.0.0.0:8000等信息,这是就是vLLM服务接口,后续可以基于该接口实现聊天对话功能。关于接口说明,请参考https://vllm.hyper.ai/docs/
5. 测试效果
调用vLLM API进行多模态对话,测试脚本如下:
python
# -*- coding: utf-8 -*-
import os
import traceback
from openai import OpenAI
from pybaseutils import image_utils, base64_utils
url = "http://0.0.0.0:8000/v1" # vLLM地址 url + /chat/completions
key = "token-abc123" # API密钥,需与启动服务时设置的(--api-key)保持一致
class Client():
"""调用vLLM API进行多模态对话"""
def __init__(self, url, key, model=None):
"""
初始化Client类
:param url: vLLM API地址
:param key: API密钥
:param model: 模型名称
"""
self.url = url
self.key = key
self.model = model
self.services = OpenAI(api_key=self.key, base_url=self.url)
print(f"url:{self.url}, key:{self.key}, model:{self.model}")
def chat(self, messages, T=0.0):
"""
:param messages: 多模态消息列表
:param T: 温度参数
:return: 模型回复内容
"""
result = None
try:
response = self.services.chat.completions.create(model=self.model, messages=messages, seed=2024,
temperature=T)
contents = response.choices[0].message.content
result = contents if isinstance(contents, str) else contents[0]['text']
except Exception as e:
traceback.print_exc()
return result
if __name__ == "__main__":
image_file = "./data/test.jpg"
assert os.path.exists(image_file), f"{image_file} not exists"
image = image_utils.read_image(image_file, use_rgb=True)
messages = [{
"role": "user",
"content": [
{"type": "text", "text": "请详细描述这张图片"},
{"type": "image_url", "image_url": {"url": image}},
]
}]
messages = base64_utils.serialization(messages, prefix="data:image/jpeg;base64,", use_rgb=True)
client = Client(url=url, key=key)
output = client.chat(messages)
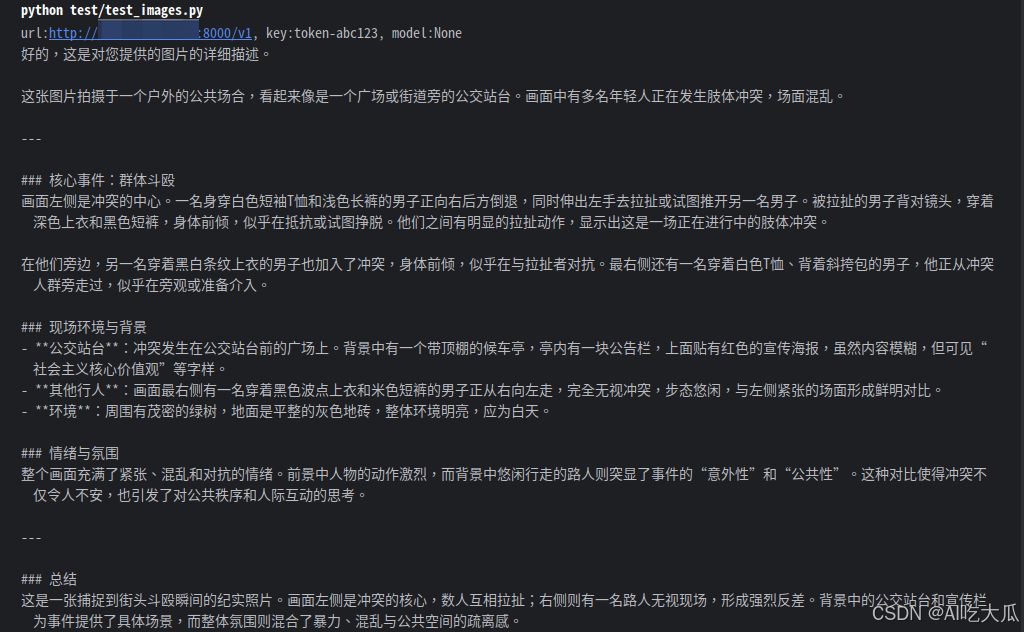
print(output)这次测试图片:

这是输出结果: