目录
- [1. 概述](#1. 概述)
-
- [1.1 图像检索的现状与难点](#1.1 图像检索的现状与难点)
- [1.2 本文任务目标](#1.2 本文任务目标)
- [1.3 Qwen3-VL-Embedding-2B 的优势](#1.3 Qwen3-VL-Embedding-2B 的优势)
- [1.4 技术原理简析](#1.4 技术原理简析)
- [2. 基础环境搭建:WSL2与Ubuntu 24.04](#2. 基础环境搭建:WSL2与Ubuntu 24.04)
- [3. GPU计算环境配置](#3. GPU计算环境配置)
- [4. 部署Qwen3-VL-Embedding-2B微服务](#4. 部署Qwen3-VL-Embedding-2B微服务)
-
- [4.1 准备工作](#4.1 准备工作)
- [4.2 启动vLLM容器](#4.2 启动vLLM容器)
- [5. 业务应用层开发](#5. 业务应用层开发)
-
- [5.1 项目结构设计](#5.1 项目结构设计)
- [5.2 封装 vLLM 客户端工具](#5.2 封装 vLLM 客户端工具)
- [5.3 核心应用逻辑实现 (FastAPI + SQLite)](#5.3 核心应用逻辑实现 (FastAPI + SQLite))
- [5.4 前端交互界面 (Jinja2 Template)](#5.4 前端交互界面 (Jinja2 Template))
- [6. 部署与测试](#6. 部署与测试)
-
- [6.1 启动服务](#6.1 启动服务)
- [6.2 效果验证](#6.2 效果验证)
- [7. 总结](#7. 总结)
1. 概述
在多模态人工智能迅速发展的今天,图像检索技术已从传统的基于元数据匹配,演进为基于内容的深度语义检索。构建高效、精准且具备语义理解能力的图像检索系统,是当前计算机视觉与自然语言处理交叉领域的重要课题。本文档旨在详细阐述如何利用最新的Qwen3-VL-Embedding-2B模型,结合vLLM推理框架与微服务架构,构建一个工业级的图像检索系统。
1.1 图像检索的现状与难点
传统的图像检索系统主要依赖于人工标注的标签或文件名,这种方式不仅耗时耗力,且难以捕捉图像的丰富语义信息。随着CLIP(Contrastive Language-Image Pre-training)等模型的出现,基于向量(Embedding)的检索成为主流。通过将图像和文本映射到同一个高维向量空间,计算向量间的余弦相似度即可实现"以文搜图"或"以图搜图"。
然而,现有的通用检索模型仍面临以下核心难点:
- 细粒度理解不足:传统CLIP模型往往关注图像的主体概貌,难以精确捕捉图像中的细节、位置关系或数量特征。
- 文字识别(OCR)能力弱:对于包含密集文本的图像(如海报、文档、图表),普通模型往往无法理解其中的文字含义,导致检索失效。
- 多语言与指令遵循差:多数模型仅支持英文或简单的中文关键词,难以理解复杂的自然语言描述或特定的检索指令(如"检索一张包含红色汽车且背景为雪山的图片")。
1.2 本文任务目标
本文档的核心任务是构建一个私有化、高性能的多模态图像检索系统。系统架构设计遵循微服务解耦原则,具体包含以下技术链路:
- 基础设施层:基于Windows WSL2 Ubuntu 24.04环境,配置NVIDIA GPU驱动与Docker容器运行时。
- 模型推理层:利用vLLM高性能推理框架,部署Qwen3-VL-Embedding-2B模型,通过HTTP接口对外提供标准化的向量计算服务。
- 业务应用层:基于FastAPI与SQLite,实现图像的上传、特征向量存储(入库)以及基于向量相似度的实时检索。
1.3 Qwen3-VL-Embedding-2B 的优势
Qwen3-VL-Embedding-2B 是阿里通义千问团队推出的专门用于多模态表征学习的轻量级模型。相较于传统模型,该模型在图像检索任务中展现出显著优势:
- 强大的OCR与细节理解:继承了Qwen-VL系列在视觉理解上的强项,能够精准识别图像中的文字内容和细微物体,显著提升了对文档、标牌及复杂场景的检索准确率。
- 指令遵循能力(Instruction Following):支持通过Prompt(提示词)引导模型生成特定侧重的向量。例如,可以指示模型"关注图像中的颜色信息"或"关注图像中的文字内容",从而实现可控的特征提取。
- 高效的轻量级架构:2B(20亿)参数量在保持高性能的同时,大幅降低了显存需求和推理延迟,非常适合在T4、3090/4090等消费级或入门级服务器显卡上部署。
- 动态分辨率支持:不同于传统模型将图像强制缩放至固定尺寸(如224x224或336x336),Qwen3-VL支持动态分辨率输入,有效保留了高分辨率图像的特征信息。
1.4 技术原理简析
Qwen3-VL-Embedding-2B 的核心原理是将视觉编码器(Visual Encoder)与大语言模型(LLM)进行深度融合,并通过对比学习与掩码建模等任务进行微调,使其具备生成高质量多模态向量的能力。
其工作流程如下:
- 视觉编码:输入的图像经过视觉编码器(基于ViT架构)处理,被转换为一系列视觉Token。该过程保留了图像的空间结构与语义特征。
- 多模态融合:视觉Token与文本Token(用户的查询或指令)被拼接后输入到Qwen语言模型中。通过自注意力机制(Self-Attention),模型实现了文本与图像信息的深度交互与对齐。
- 池化与向量化(Pooling) :不同于生成式任务输出文本,Embedding任务通过特定的池化策略(通常是提取最后一个有效Token的隐藏状态或对所有Token进行加权平均),将变长的多模态序列压缩为一个固定维度(通常为2048维)的稠密向量。
- 相似度计算:在检索阶段,系统计算"查询向量"与"库中图像向量"的点积或余弦相似度。由于模型在训练阶段已拉近了语义相关样本的距离,相似度越高的向量,其代表的图像与查询内容的关联度就越强。
本文将演示如何利用 vLLM 的 pooling 运行模式(Runner),高效地执行上述流程,实现从图像到向量的快速转换。
2. 基础环境搭建:WSL2与Ubuntu 24.04
构建系统的第一步是在Windows平台上配置Linux运行环境。
- 安装WSL2 :
在Windows PowerShell(管理员模式)中执行命令启用WSL子系统,并设置默认版本为2。 - 安装Ubuntu 24.04 :
通过Microsoft Store或命令行安装Ubuntu 24.04 LTS分发版。 - 系统初始化 :
完成Linux用户创建与基础包更新。
关于WSL2及Ubuntu的详细安装步骤,请参考:CSDN博客:Windows安装WSL及Ubuntu。
3. GPU计算环境配置
在WSL环境内,需配置NVIDIA驱动与容器化运行时以支持GPU加速。
- 安装NVIDIA显卡驱动 :
确保Windows主机已安装最新的NVIDIA Game Ready或Studio驱动。WSL2会自动映射Windows的GPU驱动,无需在Linux内部重新安装内核驱动,但需验证nvidia-smi能否正常输出。 - 安装Docker :
在Ubuntu中安装Docker,并配置当前用户权限。 - 安装NVIDIA Container Toolkit :
这是实现Docker容器调用GPU的关键组件。安装完成后,需配置Docker守护进程以使用nvidia-container-runtime。
具体的手工安装与配置方法,请参考:项目实践13---全球证件智能识别系统(内网离线部署大模型并调用)。
需要注意,对于WSL2系统来说,需要安装最新版的nvidia-container-toolkit,否则后续在docker中调用GPU会出问题。安装方法详见英伟达官网。
4. 部署Qwen3-VL-Embedding-2B微服务
本节通过Docker容器部署模型推理服务。该服务独立运行,对外提供标准化的API接口。
4.1 准备工作
首先需要下载Qwen3-VL-Embedding-2B模型,本文推荐使用modelscope来下载。
下载方法如下:
bash
pip install modelscope -i https://pypi.tuna.tsinghua.edu.cn/simple
modelscope download --model Qwen/Qwen3-VL-Embedding-2B --local_dir ./Qwen3-VL-Embedding-2B4.2 启动vLLM容器
为了适配T4等显卡(需禁用P2P与IB以避免通信错误)并优化显存使用,使用以下命令启动服务。该命令将启动一个OpenAI兼容的API服务,专门用于Embedding任务。
bash
sudo docker run -d \
--name qwen3-vl-embedding-server \
--restart unless-stopped \
--gpus all \
--ipc=host \
-p 8002:8000 \
-v "/home/qb/copy/Qwen3-VL-Embedding-2B:/models/Qwen3-VL-Embedding-2B" \
-e NCCL_P2P_DISABLE=1 \
-e NCCL_IB_DISABLE=1 \
hub.rat.dev/vllm/vllm-openai:latest \
--model "/models/Qwen3-VL-Embedding-2B" \
--served-model-name Qwen3-VL-Embedding-2B \
--tensor-parallel-size 1 \
--gpu-memory-utilization 0.60 \
--max-model-len 8192 \
--runner pooling \
--dtype float16 \
--trust-remote-code参数说明:
--dtype float16: 针对T4显卡使用FP16精度(若使用A100/4090可改为bfloat16)。-e NCCL_...: 针对部分消费级或旧款服务器显卡的通信库兼容性设置。-v: 挂载模型路径,容器内路径需与--model参数一致。
启动后,可通过查看日志确认服务状态:
bash
sudo docker logs -f qwen3-vl-embedding-server当看到 Uvicorn running on http://0.0.0.0:8000 时,表示推理微服务已就绪。
5. 业务应用层开发
在完成模型推理微服务的部署后,下一阶段是构建业务应用层。本节将实现一个轻量级的Web服务,该服务负责以下功能:
- 图像入库:接收用户上传的图像,调用推理服务生成向量,并存储至SQLite数据库。
- 多模态检索:支持"以文搜图"和"以图搜图",实时计算查询向量并在库中进行相似度匹配。
- 可视化交互:提供基于Web的用户界面。
5.1 项目结构设计
为保持架构简洁,项目采用单体微服务结构。推荐目录结构如下:
text
image_retrieval_app/
├── static/
│ ├── uploads/ # 存放上传的原始图像文件
│ └── css/ # 样式文件(可选)
├── templates/
│ └── index.html # 前端交互页面
├── app.py # FastAPI后端核心逻辑
├── vllm_client.py # 封装与vLLM交互的客户端代码
└── requirements.txt # 依赖列表5.2 封装 vLLM 客户端工具
为了严格遵循Qwen3-VL-Embedding-2B的调用规范,我们将封装独立的特征计算模块 vllm_client.py。该模块负责处理Base64编码、构建Chat协议消息体以及解析返回的Embedding向量。
新建 vllm_client.py,代码如下:
python
# vllm_client.py
import base64
from typing import Literal, Optional, List
from openai import OpenAI
from openai._types import NOT_GIVEN, NotGiven
from openai.types.chat import ChatCompletionMessageParam
from openai.types.create_embedding_response import CreateEmbeddingResponse
# 配置vLLM服务的地址
OPENAI_API_KEY = "EMPTY"
OPENAI_API_BASE = "http://127.0.0.1:8002/v1" # 请根据实际部署IP修改,如宿主机IP
client = OpenAI(
api_key=OPENAI_API_KEY,
base_url=OPENAI_API_BASE,
)
def encode_image_from_bytes(image_bytes: bytes) -> str:
"""将图像字节流转换为Base64字符串"""
return base64.b64encode(image_bytes).decode("utf-8")
def create_chat_embeddings(
messages: list[ChatCompletionMessageParam],
model: str,
encoding_format: Literal["base64", "float"] | NotGiven = NOT_GIVEN,
continue_final_message: bool = False,
add_special_tokens: bool = False,
) -> CreateEmbeddingResponse:
"""
访问vLLM Chat Embeddings API的便捷函数,
这是OpenAI现有Embeddings API的扩展。
"""
return client.post(
"/embeddings",
cast_to=CreateEmbeddingResponse,
body={
"messages": messages,
"model": model,
"encoding_format": encoding_format,
"continue_final_message": continue_final_message,
"add_special_tokens": add_special_tokens,
},
)
def get_qwen_embedding(input_type: str, data: bytes = None, text_query: str = "") -> List[float]:
"""
调用Qwen3-VL生成向量。
:param input_type: 'image' 或 'text'
:param data: 图像的二进制数据 (当 input_type='image' 时必填)
:param text_query: 文本查询内容 (当 input_type='text' 时必填)
"""
# 获取模型ID (假设只有一个模型)
models = client.models.list()
model_id = models.data[0].id
default_instruction = "Represent the user's input."
messages = []
# 系统提示词
messages.append({
"role": "system",
"content": [{"type": "text", "text": default_instruction}],
})
# 构建用户消息
user_content = []
if input_type == 'image':
# 图像模式:Image + Empty Text
base64_image = encode_image_from_bytes(data)
user_content.append({"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{base64_image}"}})
user_content.append({"type": "text", "text": ""})
elif input_type == 'text':
# 文本模式:Text only
user_content.append({"type": "text", "text": text_query})
messages.append({
"role": "user",
"content": user_content,
})
# 助手消息占位
messages.append({
"role": "assistant",
"content": [{"type": "text", "text": ""}],
})
response = create_chat_embeddings(
client=client,
messages=messages,
model=model_id,
encoding_format="float",
continue_final_message=True,
add_special_tokens=True,
)
return response.data[0].embedding5.3 核心应用逻辑实现 (FastAPI + SQLite)
接下来编写 app.py。该文件集成了数据库操作、相似度计算以及API路由。系统启动时会自动创建SQLite数据库表 images。
核心功能点:
- 入库 :上传图像 -> 保存文件 -> 调用
vllm_client-> 存入SQLite。 - 检索 :接收请求 -> 调用
vllm_client生成查询向量 -> 遍历数据库计算余弦相似度 -> 排序返回。
python
# app.py
import os
import json
import sqlite3
import uvicorn
import shutil
from typing import List
from fastapi import FastAPI, Request, UploadFile, File, Form
from fastapi.templating import Jinja2Templates
from fastapi.staticfiles import StaticFiles
from fastapi.responses import HTMLResponse
from vllm_client import get_qwen_embedding
app = FastAPI()
# 路径配置
UPLOAD_DIR = "static/uploads"
DB_PATH = "images.db"
os.makedirs(UPLOAD_DIR, exist_ok=True)
# 挂载静态资源和模板
app.mount("/static", StaticFiles(directory="static"), name="static")
templates = Jinja2Templates(directory="templates")
# --- 数据库操作 ---
def init_db():
"""初始化SQLite数据库"""
conn = sqlite3.connect(DB_PATH)
cursor = conn.cursor()
# 创建表:存储文件路径、文件名、以及JSON格式序列化的向量
cursor.execute('''
CREATE TABLE IF NOT EXISTS images (
id INTEGER PRIMARY KEY AUTOINCREMENT,
filename TEXT,
filepath TEXT,
embedding TEXT
)
''')
conn.commit()
conn.close()
def save_to_db(filename, filepath, embedding):
conn = sqlite3.connect(DB_PATH)
cursor = conn.cursor()
# 将列表格式的向量转换为JSON字符串存储
embedding_json = json.dumps(embedding)
cursor.execute('INSERT INTO images (filename, filepath, embedding) VALUES (?, ?, ?)',
(filename, filepath, embedding_json))
conn.commit()
conn.close()
def fetch_all_embeddings():
"""获取库中所有向量"""
conn = sqlite3.connect(DB_PATH)
cursor = conn.cursor()
cursor.execute('SELECT id, filename, filepath, embedding FROM images')
rows = cursor.fetchall()
conn.close()
results = []
for row in rows:
results.append({
"id": row[0],
"filename": row[1],
"filepath": row[2],
"embedding": json.loads(row[3]) # 反序列化
})
return results
# --- 算法工具 ---
def calculate_cosine_similarity(vec1, vec2):
"""余弦相似度计算 (严格参照提供的参考代码)"""
dot_product = sum(a * b for a, b in zip(vec1, vec2))
magnitude_vec1 = sum(a ** 2 for a in vec1) ** 0.5
magnitude_vec2 = sum(b ** 2 for b in vec2) ** 0.5
if magnitude_vec1 == 0 or magnitude_vec2 == 0:
return 0.0
return dot_product / (magnitude_vec1 * magnitude_vec2)
# --- 路由定义 ---
@app.on_event("startup")
async def startup_event():
init_db()
@app.get("/", response_class=HTMLResponse)
async def home(request: Request):
return templates.TemplateResponse("index.html", {"request": request})
@app.post("/upload")
async def upload_image(request: Request, file: UploadFile = File(...)):
"""处理图像上传与入库"""
file_location = os.path.join(UPLOAD_DIR, file.filename)
# 1. 保存文件到本地
with open(file_location, "wb") as buffer:
shutil.copyfileobj(file.file, buffer)
# 2. 读取文件字节流用于计算向量
with open(file_location, "rb") as f:
image_bytes = f.read()
# 3. 调用微服务计算向量
try:
embedding = get_qwen_embedding(input_type='image', data=image_bytes)
# 4. 存入数据库
save_to_db(file.filename, file_location, embedding)
message = f"成功入库: {file.filename}"
except Exception as e:
message = f"处理失败: {str(e)}"
return templates.TemplateResponse("index.html", {"request": request, "message": message})
@app.post("/search")
async def search(
request: Request,
search_type: str = Form(...), # 'text' or 'image'
text_query: str = Form(None),
image_file: UploadFile = File(None)
):
"""执行检索逻辑"""
query_embedding = []
try:
# 1. 获取查询向量
if search_type == "text" and text_query:
query_embedding = get_qwen_embedding(input_type='text', text_query=text_query)
elif search_type == "image" and image_file:
image_bytes = await image_file.read()
query_embedding = get_qwen_embedding(input_type='image', data=image_bytes)
else:
return templates.TemplateResponse("index.html", {"request": request, "error": "输入无效"})
# 2. 从数据库获取所有向量并计算相似度
db_records = fetch_all_embeddings()
scored_results = []
for record in db_records:
score = calculate_cosine_similarity(query_embedding, record['embedding'])
record['score'] = round(score, 4)
scored_results.append(record)
# 3. 排序并取Top N (例如 Top 5)
scored_results.sort(key=lambda x: x['score'], reverse=True)
top_results = scored_results[:5]
return templates.TemplateResponse("index.html", {
"request": request,
"results": top_results,
"search_type": search_type,
"query_preview": text_query if search_type == 'text' else "Uploaded Image"
})
except Exception as e:
return templates.TemplateResponse("index.html", {"request": request, "error": f"检索出错: {str(e)}"})
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)5.4 前端交互界面 (Jinja2 Template)
创建 templates/index.html,实现一个包含上传和检索功能的简单Tab页。
html
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<title>Qwen3-VL 图像检索系统</title>
<style>
body { font-family: 'Segoe UI', sans-serif; max-width: 900px; margin: 0 auto; padding: 20px; background-color: #f4f4f9; }
.container { background: white; padding: 30px; border-radius: 8px; box-shadow: 0 2px 5px rgba(0,0,0,0.1); }
h1 { text-align: center; color: #333; }
.tabs { display: flex; border-bottom: 2px solid #ddd; margin-bottom: 20px; }
.tab { padding: 10px 20px; cursor: pointer; border: 1px solid transparent; border-bottom: none; }
.tab.active { background: #fff; border-color: #ddd; border-bottom-color: #fff; font-weight: bold; color: #007bff; }
.form-section { display: none; }
.form-section.active { display: block; }
input[type="text"], input[type="file"] { width: 100%; padding: 10px; margin: 10px 0; box-sizing: border-box; }
button { background-color: #007bff; color: white; padding: 10px 20px; border: none; cursor: pointer; width: 100%; }
button:hover { background-color: #0056b3; }
.results { margin-top: 30px; }
.result-card { display: flex; align-items: center; border: 1px solid #eee; padding: 10px; margin-bottom: 10px; background: #fff; }
.result-card img { width: 100px; height: 100px; object-fit: cover; margin-right: 20px; border-radius: 4px; }
.score { color: #d9534f; font-weight: bold; }
.message { padding: 10px; background-color: #d4edda; color: #155724; border-radius: 4px; margin-bottom: 15px; }
.error { padding: 10px; background-color: #f8d7da; color: #721c24; border-radius: 4px; margin-bottom: 15px; }
</style>
<script>
function switchTab(tabId) {
document.querySelectorAll('.tab').forEach(t => t.classList.remove('active'));
document.querySelectorAll('.form-section').forEach(f => f.classList.remove('active'));
document.getElementById(tabId + '-tab').classList.add('active');
document.getElementById(tabId + '-section').classList.add('active');
}
</script>
</head>
<body>
<div class="container">
<h1>Qwen3-VL 智能图像检索</h1>
{% if message %} <div class="message">{{ message }}</div> {% endif %}
{% if error %} <div class="error">{{ error }}</div> {% endif %}
<div class="tabs">
<div id="upload-tab" class="tab active" onclick="switchTab('upload')">图像入库</div>
<div id="text-search-tab" class="tab" onclick="switchTab('text-search')">以文搜图</div>
<div id="img-search-tab" class="tab" onclick="switchTab('img-search')">以图搜图</div>
</div>
<!-- 图像入库表单 -->
<div id="upload-section" class="form-section active">
<form action="/upload" method="post" enctype="multipart/form-data">
<h3>上传图像至特征库</h3>
<input type="file" name="file" accept="image/*" required>
<button type="submit">上传并向量化</button>
</form>
</div>
<!-- 以文搜图表单 -->
<div id="text-search-section" class="form-section">
<form action="/search" method="post">
<h3>输入描述进行检索</h3>
<input type="hidden" name="search_type" value="text">
<input type="text" name="text_query" placeholder="例如:一张红色的跑车,背景是雪山..." required>
<button type="submit">检索</button>
</form>
</div>
<!-- 以图搜图表单 -->
<div id="img-search-section" class="form-section">
<form action="/search" method="post" enctype="multipart/form-data">
<h3>上传图像进行相似度检索</h3>
<input type="hidden" name="search_type" value="image">
<input type="file" name="image_file" accept="image/*" required>
<button type="submit">检索</button>
</form>
</div>
<!-- 检索结果展示 -->
{% if results %}
<div class="results">
<h2>检索结果 (Top 5)</h2>
<p>查询类型: {{ search_type }} | 内容: {{ query_preview }}</p>
{% for item in results %}
<div class="result-card">
<a href="{{ item.filepath }}" target="_blank">
<img src="{{ item.filepath }}" alt="{{ item.filename }}">
</a>
<div>
<div><strong>文件名:</strong> {{ item.filename }}</div>
<div><strong>相似度:</strong> <span class="score">{{ item.score }}</span></div>
</div>
</div>
{% endfor %}
</div>
{% endif %}
</div>
</body>
</html>6. 部署与测试
6.1 启动服务
-
确认vLLM服务运行中 :确保第3节中的Docker容器
qwen3-vl-embedding-server正在运行并监听 8002 端口。 -
安装依赖 :
bashpip install fastapi uvicorn python-multipart openai jinja2 pillow -i https://pypi.tuna.tsinghua.edu.cn/simple -
启动FastAPI服务 :
在image_retrieval_app目录下运行:bashpython app.py终端应输出
Uvicorn running on http://0.0.0.0:8000。
6.2 效果验证
-
浏览器访问 :打开
http://localhost:8000(若在WSL2中,通过Windows浏览器访问WSL IP或localhost)。
-
构建库:
- 在"图像入库"标签页,上传若干张测试图片(例如:猫、汽车、文档截图等)。
- 系统会自动调用Qwen3-VL计算向量并存入SQLite。
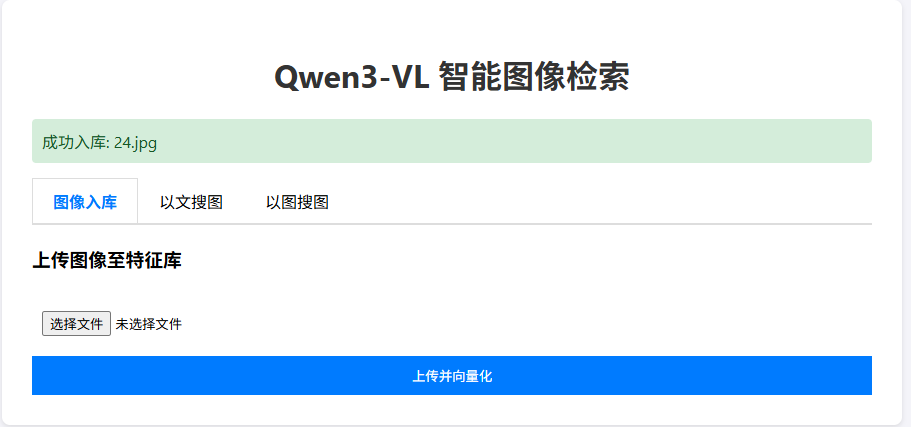
上传的图像如下:
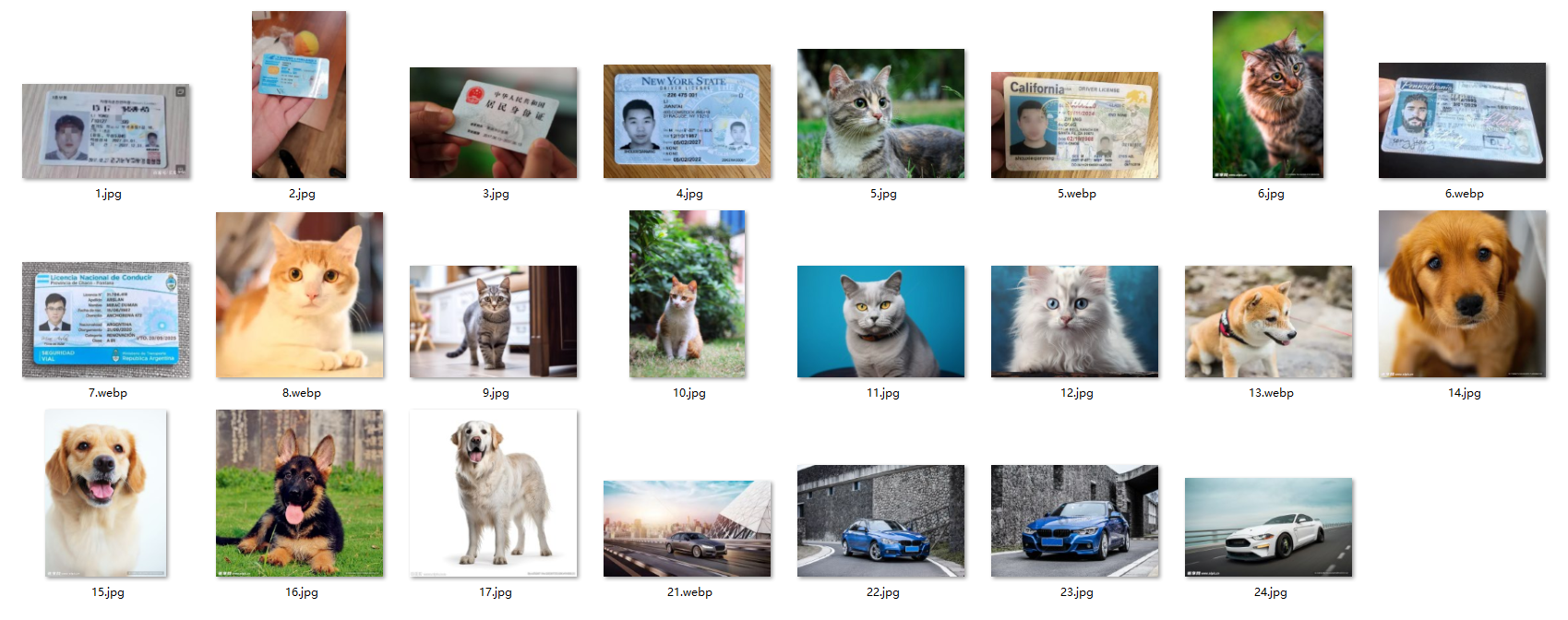
-
以文搜图:
- 切换至"以文搜图"。
- 输入自然语言,例如"一只白色的猫"或"纽约驾驶证"。
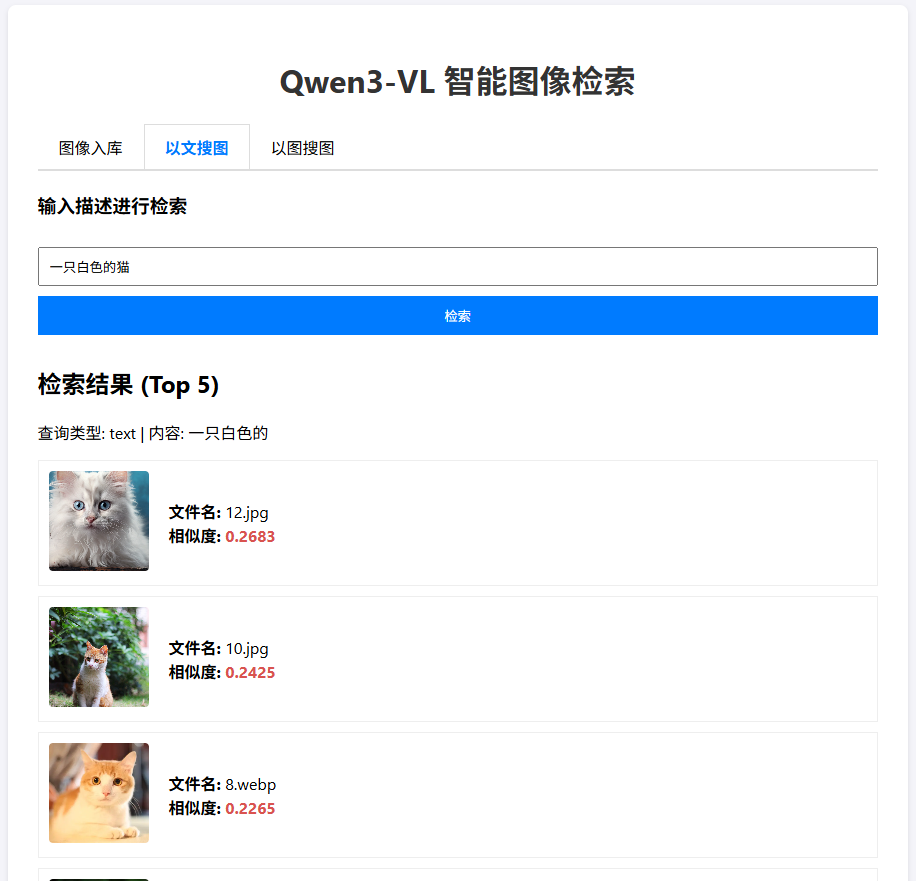
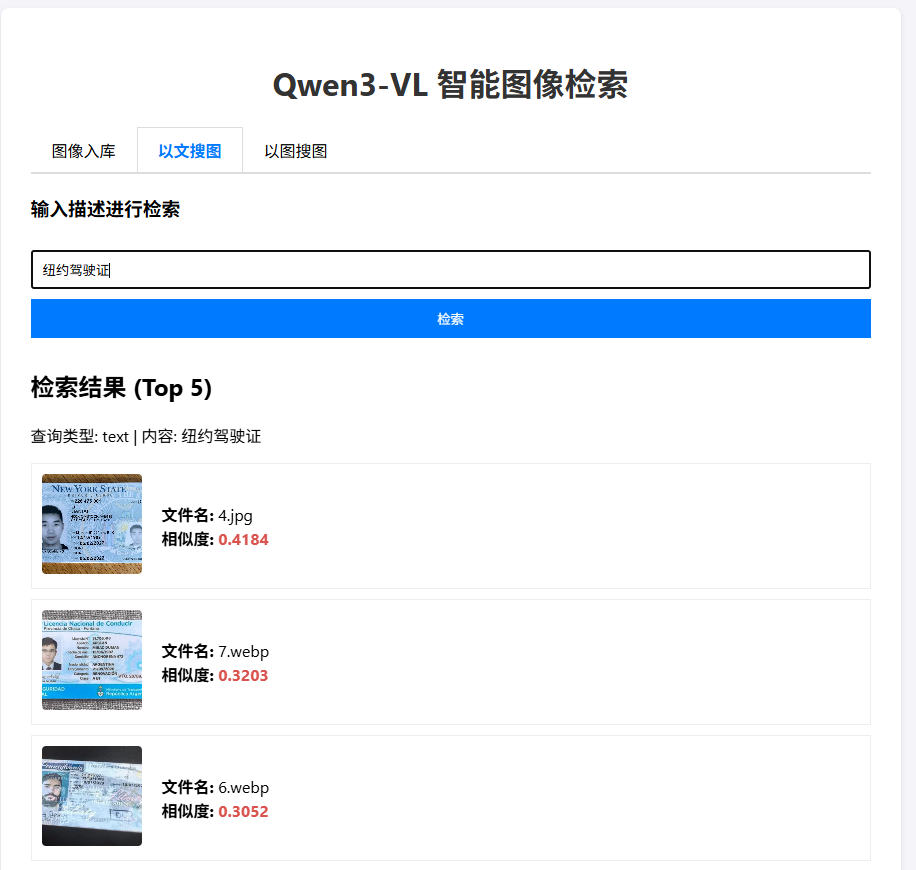
* 验证返回的图像是否符合描述。得益于Qwen3-VL强大的指令遵循和OCR能力,即使是复杂的文字描述也能精准匹配。- 以图搜图 :
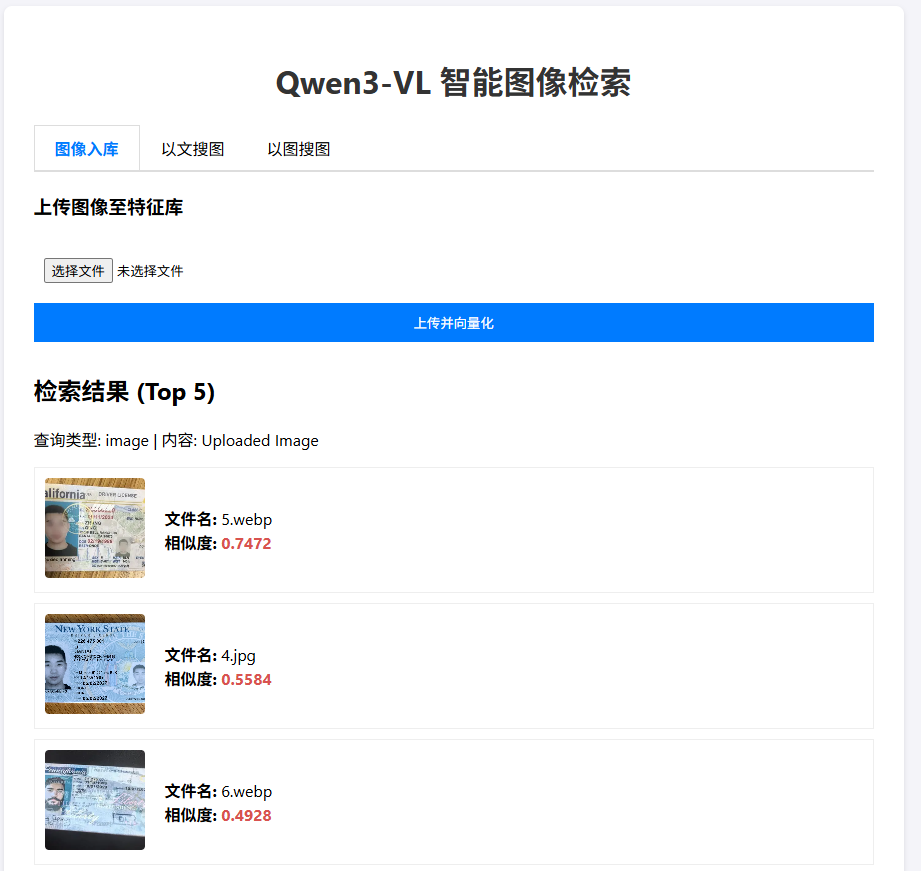
- 切换至"以图搜图"。
- 上传一张本地图片。
- 系统将返回库中视觉特征最相似的图片。
上传图片如下:

返回结果:
7. 总结
本文档展示了如何利用 Qwen3-VL-Embedding-2B 构建一个具备工业级潜力的多模态检索系统。该系统架构清晰:
- 底层使用 Docker + vLLM 提供高性能的向量推理服务,充分利用GPU资源。
- 应用层使用 FastAPI + SQLite 实现轻量级的业务逻辑,将繁重的模型计算与业务流程解耦。
- 通过 Prompt Engineering(如 "Represent the user's input"),系统能够灵活处理纯文本和图像输入,实现了语义空间的高度对齐。
对于更大规模的场景(如百万级图片库),仅需将SQLite替换为专业的向量数据库(如Milvus或Faiss),即可实现毫秒级的大规模检索。Qwen3-VL的出现,使得在消费级显卡上部署高精度的多模态检索成为可能,极大地降低了技术落地门槛。