🍂 枫言枫语 :我是予枫,一名行走在 Java 后端与多模态 AI 交叉路口的研二学生。
"予一人以深耕,观万木之成枫。"
在这里,我记录从底层源码到算法前沿的每一次思考。希望能与你一起,在逻辑的丛林中寻找技术的微光。

在处理海量数据时,我们经常会遇到一个经典问题:如何快速判断一个元素是否在一个集合中?
如果集合有 1000 万个数据,你可能会想到 HashSet。但如果有 10 亿个、100 亿个数据呢?内存会瞬间爆满。这时候,布隆过滤器(Bloom Filter)就像一位身轻如燕的"守门员",以极小的空间代价,帮我们挡住海量的无效请求。
今天,予枫带大家深度剥开布隆过滤器的内核。
一、 核心思想:空间换时间的极致艺术
布隆过滤器由 Burton Howard Bloom 在 1970 年提出。它的核心本质是:利用位数组(Bit Array)和多个哈希函数(Hash Function)来表示一个集合。
1. 结构组成
-
位数组: 一个长度为 m 的二进制向量,每一位初始值都是
0。 -
哈希函数: k个相互独立的随机哈希函数,它们能将输入数据均匀地映射到位数组的不同位置。
2. 运作流程
-
添加元素: 将元素经过 k 个哈希函数计算,得到 k 个索引位置,把位数组中这些位置的值全部设为
1。 -
查询元素: 将要查询的元素再次经过那 k个哈希函数。
-
如果 k 个位置中有一个为 0 ,那么该元素一定不在集合中。
-
如果 k 个位置全为 1 ,那么该元素可能在集合中(存在误判)。
-
二、 灵魂拷问:为什么会存在"误判"?
这是布隆过滤器最著名的特性:宁可错杀一千(误判存在),绝不放过一个(绝无漏报)。
1. 为什么会有误判?
由于位数组的长度有限,而数据量可能是无限的。当多个不同的元素经过哈希计算后,它们映射到的位置可能会产生重叠。
想象一下,元素 A 把第 1, 3, 5 位涂黑了,元素 B 把第 2, 4, 6 位涂黑了。这时来了一个元素 C,它的哈希位置恰好是 1, 4, 6。虽然 C 从未被加入过,但系统会认为它"已存在"。
2. 为什么不能删除?
这是布隆过滤器最大的痛点。
因为位数组中的某一位 1 可能同时代表了多个元素。如果你为了删除元素 A 而把某一位改回 0,那么同时也可能"误删"了元素 B。
进阶知识: 如果非要删除,可以使用 Counting Bloom Filter (计数布隆过滤器),它将每一位从
1 bit换成了Counter计数器,但空间成本会成倍增加。
三、 数学之美:如何降低误判率?
误判率(False Positive Rate)受三个因素影响:
-
位数组长度 m
-
哈希函数个数 k
-
插入元素个数 n
误判率 P 的近似公式如下:
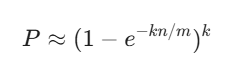
结论:
-
位数组越长,误判率越低。
-
哈希函数越多(在一定范围内),误判率越低。
-
工程经验: 当哈希函数个数
时,误判率最低。
四、 Java 工程实战
在 Java 后端开发中,我们不需要手写哈希函数,通常有两种主流实现方案:
1. Guava 实现(本地内存)
适用于单机环境,数据量在百万到千万级别。
java
// 创建一个布隆过滤器(预计插入100万数据,期望误判率0.01)
BloomFilter<String> filter = BloomFilter.create(
Funnels.stringFunnel(Charset.forName("UTF-8")),
1000000,
0.01
);
filter.put("YF_Java");
System.out.println(filter.mightContain("YF_Java")); // true2. Redisson 实现(分布式环境)
利用 Redis 的 BitMap 实现,适用于分布式架构,多个微服务共享同一个过滤器。
java
RBloomFilter<String> bloomFilter = redisson.getBloomFilter("user-whitelist");
bloomFilter.tryInit(100000000L, 0.03); // 1亿数据,3%误判五、 布隆过滤器的顶级应用场景
-
解决缓存穿透(最经典): 在查询 Redis 之前,先过一遍布隆过滤器。如果过滤器说没有,直接返回,保护数据库。
-
垃圾邮件过滤: 记录数亿个邮件地址,判断发件人是否在黑名单中。
-
网页爬虫去重: 避免重复爬取已经抓取过的 URL。
-
数据库索引优化: 在 BigTable 或 Cassandra 中,利用布隆过滤器快速判断行键(Row Key)是否存在,减少磁盘 I/O。
六、 予枫的面试小贴士
如果面试官问:"布隆过滤器满了怎么办?"
-
重建: 定时从数据库拉取数据,重新创建一个更大的布隆过滤器。
-
分段存储: 类似 ConcurrentHashMap 的思想,使用多个布隆过滤器串联。
-
可伸缩布隆过滤器 (Scalable Bloom Filter): 自动增加长度的变种实现。
结语
布隆过滤器体现了计算机科学中一种深刻的权衡(Trade-off):用不完美的精确度,换取近乎完美的性能和空间效率。 在处理大规模分布式系统时,这种"模糊的智慧"往往比"绝对的精确"更有用。
关于作者 : 💡 予枫 ,某高校在读研究生,专注于 Java 后端开发与多模态情感计算。💬 欢迎点赞、收藏、评论,你的反馈是我持续输出的最大动力!
我的博客即将同步至腾讯云开发者社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan?invite_code=9wrxwtlju1l
当前加入还有惊喜相送!