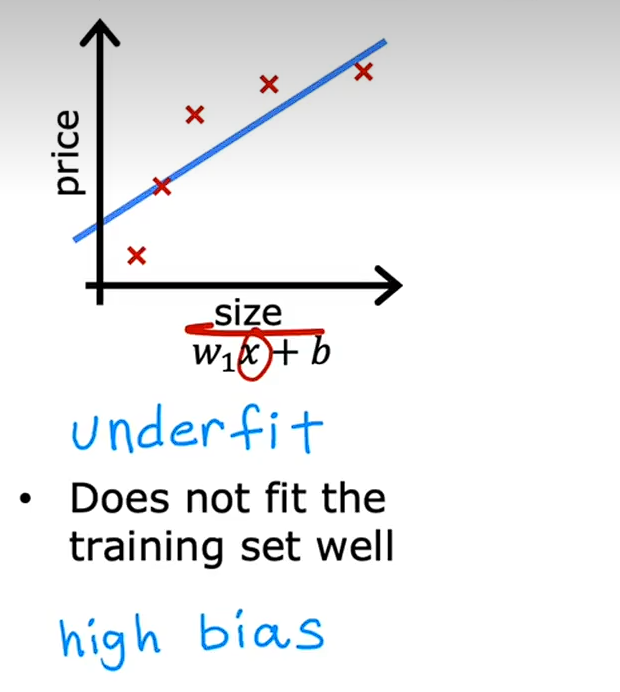
欠拟合
还是回到线性回归欠拟合的例子,如下图,我们得到的模型是房屋的大小和模型,可以看到随着房屋面积的表达,模型并没有,所以模型并没有很好的拟合训练数据,这个技术数据就是欠拟合另一个数据就是算法具有高偏差,
欠拟合意味着算法无法很好的拟合训练集,训练数据中有一个明显的模式,但是算法无法捕捉到
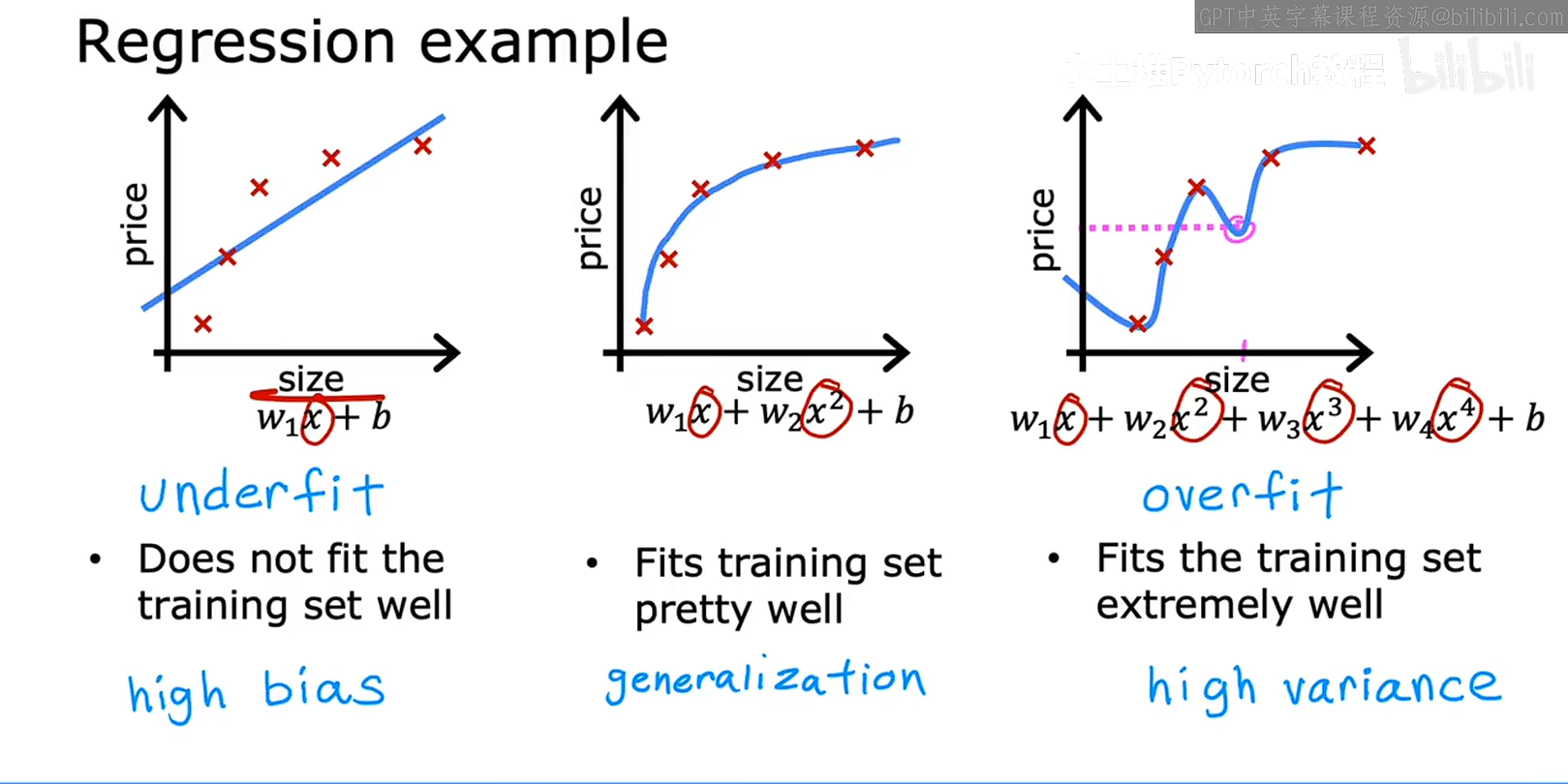 在上图中,第二个数据集合的刚刚好,泛化能力也不错,如果说在训和练测试的数据集之外的其他数据集中,模型拟合这些数据的能力也不错,这叫做泛化,我们说希望你的学习算法可以更好的泛化,这意味着,即使在他从未见过的数据集上也能做错良好的预测,对新样本有很好的泛化能力。
在上图中,第二个数据集合的刚刚好,泛化能力也不错,如果说在训和练测试的数据集之外的其他数据集中,模型拟合这些数据的能力也不错,这叫做泛化,我们说希望你的学习算法可以更好的泛化,这意味着,即使在他从未见过的数据集上也能做错良好的预测,对新样本有很好的泛化能力。
看一下上图同的第三个图,这条曲线非常完美的拟合了训练数据,因为他恰好通过了所有的训练数据,可以通过选择参数,使得这个模型的代价函数刚好等于使他这五个样本中的误差刚好等于0,
这是一条非常曲折的曲线,在各处上下波动,在某些地方,房子相比面积很小,但是房价更贵,所以可以认为这不是一个很好的房价预测模型。技术术语会说这个模型过拟合了这些数据,或者说模型存在过拟合问题,虽然他拟合了所有的数据,但是拟合的太好了,属于死记硬背,看起来也不具备非常好的泛化能力,另一个属于就是算法具有高方差,
中间的是模型刚刚好,他既不过拟合,也不欠拟合,几部高偏差,也不高方差,目前为止还没有也定的术语,我们也可以看到,机器学习就是在寻找一个既不过拟合也不欠拟合的模型,
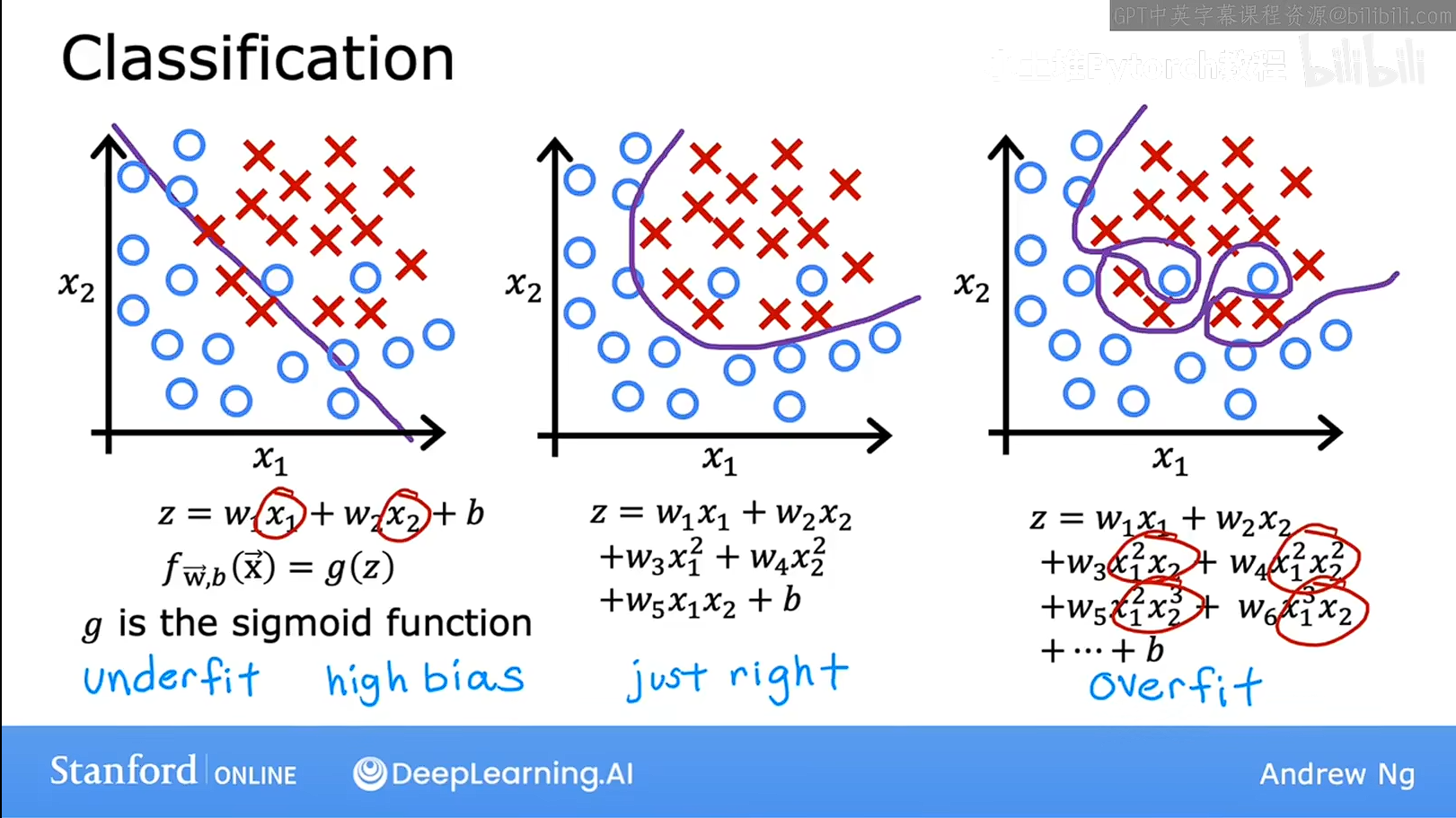
如上图我们可以看到,第一个数据拟合的不太好,属于欠拟合,第二个,数据拟合的刚刚好,第三个数据是过拟合也叫高方不一定有很好的泛化能力