在我之前的文章已经对 AI 相关的一些核心概念做了系统性的介绍。相信读者在阅读完之后,已经对人工智能有了一个初步而整体的认知。
在正式进入 AI 底层算法与数学原理之前,我个人更建议大家先在本地部署并运行一个大模型 。通过实际操作获得直观体验,可以显著降低后续学习过程中的理解成本,也有助于把抽象概念与真实行为建立联系。本文所使用的系统环境为 Windows ,并且完全基于 CPU 进行计算 。需要特别说明的是,作者本人使用的是 AMD 显卡(A 卡)。然而,就目前的实际情况来看,AMD 在 Windows 平台上对大模型推理与训练的支持仍然不够成熟。为了充分利用硬件,我曾尝试过多种方案,包括 WSL2、DirectML 等,但在实际使用过程中,由于兼容性、稳定性以及环境配置等问题,最终都未能顺利运行模型,反而消耗了大量时间成本。
权衡之后,我最终选择直接使用 CPU 运行模型。虽然性能上有所牺牲,但在稳定性、可控性以及排错成本方面都要友好得多,也几乎不会遇到各种"非预期问题"。回过头来看,我个人非常后悔没有在一开始就选择 CPU 方案------对于学习阶段而言,稳定性远比性能更重要。
如果把 AI 技术本身类比为羽毛球技术 ,那么用于实现 AI 的各种编程语言(如 Python、C++)以及相关框架和库(如 PyTorch、TensorFlow)更像是羽毛球拍的选择 。在学习羽毛球技术的初期,最快的提升方式并不是一味追求最专业、最昂贵的球拍,而是选择当下最容易获取、最顺手、最稳定的工具 。同理,在 AI 学习的早期阶段,更重要的是理解原理、动手实践和建立整体认知 ,而不是纠结于某种特定语言或框架。随着经验的积累,更换编程语言或底层库所需的成本,远远低于从零学习 AI 技术本身的成本。因此,我个人非常建议初学者在入门阶段减少技术选型上的执念 ,优先关注理论理解与实践过程。具体工具会不断演进,某些技术甚至会被淘汰,但解决问题的思维方式与方法论是长期有效的。
本地模型推理
为了让大家能看到自己运行的模型来源于哪里,我会先显式地把模型的代码,参数拉取到本地,然后再读取他完成推理。避免使用过于高层级的API。推理得不明不白。模型上,我选用阿里千问开源模型Qwen3-4B
这个模型比较新,不算大,但也绝对不小,而且支持推理模式,CPU也完全跑得动(虽然略慢了点),所以很适合用于学习
huggingface地址:https://huggingface.co/Qwen/Qwen3-4B
第一步 通过git命令把代码拉取到本地
git lfs install
git clone https://huggingface.co/Qwen/Qwen3-4B
这一步可能需要科学上网,也需要等挺长的一段时间,需要有耐心
第二步 拉下来的查看代码
拉下来后目录结构应该是这样的
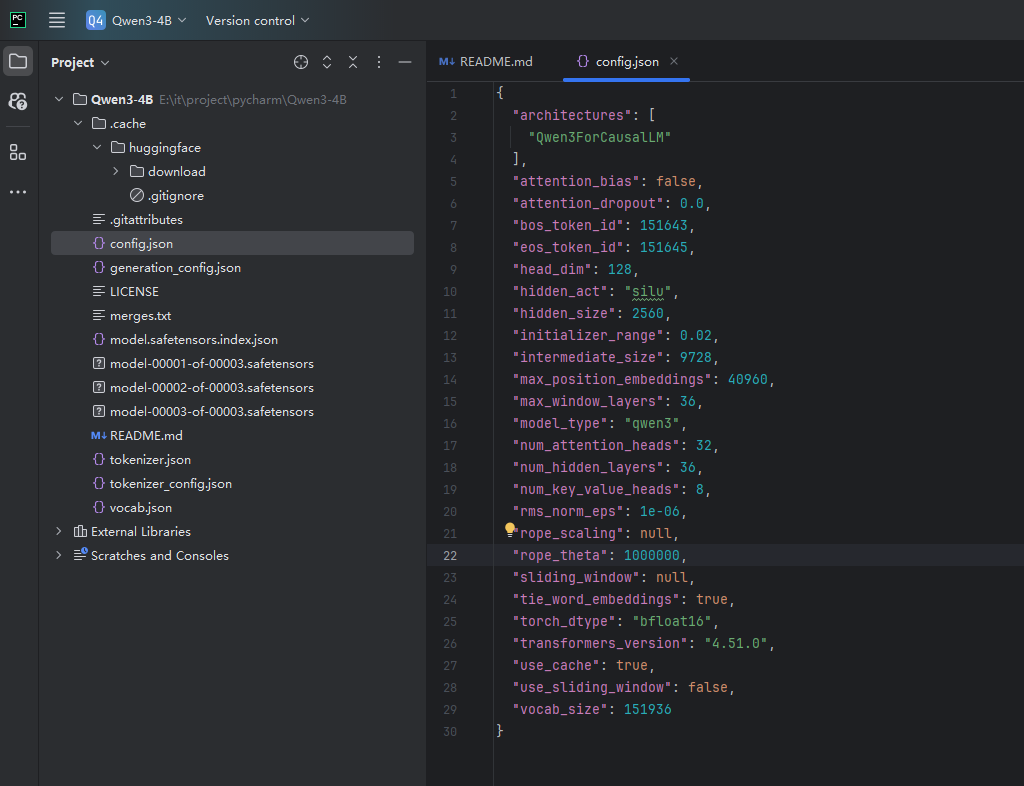
目录重要文件解释
config.json:描述模型结构与超参数。比如字段有 model_type(模型类型)、hidden_size(隐藏层维度)、num_hidden_layers(层数)、num_attention_heads(注意力头数)、vocab_size、max_position_embeddings、torch_dtype、bos_token_id、eos_token_id 等,用于恢复网络结构与推理/训练时的数值类型和位置编码长度。
safetensors文件:大模型参数(weights)的分片文件(sharded weights),它们合在一起,就是完整的模型权重
tokenizer.json:保存分词器的完整可复现状态,通常包含 BPE 模型(vocab 与 merges)、normalizer、pre_tokenizer、post_processor、decoder 以及特殊符号的处理规则。你仓库中同时存在 vocab.json 与 merges.txt,说明分词器是 BPE;tokenizer.json 是它们的合并序列化版本,AutoTokenizer.from_pretrained 会优先读它。
tokenizer_config.json:为 Transformers 提供分词器的高层默认行为与元信息,尤其是特殊符号、最大长度、类名等
generation_config.json:为 model.generate 提供默认的采样与终止参数,未在调用时显式覆盖则使用这里的值,比如do_sample:true,启用随机采样。temperature:0.6,控制分布平滑度;top_k:20、top_p:0.95,限制采样空间,影响多样性与稳定性
第三步 编码加载和运行模型
我使用PyCharm新开一个新python项目。
首先通过pip下载pytorch
pip install torch transformers peft sentencepiece safetensors
导入必要的包
import time import torch from transformers import AutoTokenizer, AutoModelForCausalLM
写个简单的计时方法,打印每个步骤的时间
def tic(): return time.perf_counter() def toc(t0, msg): print(f"⏱ {msg}: {time.perf_counter() - t0:.3f} s")
开始计时,并且设置torch 12线程并发计算
t0 = tic() # ===== 基础设置 ===== torch.set_num_threads(12)
加载刚才拉下来的模型并记录时间
model_path = r"E:\你刚才拉下来的项目地址\Qwen3-4B" # ===== tokenizer ===== tokenizer = AutoTokenizer.from_pretrained( model_path, trust_remote_code=True ) # ===== 加载 基础模型 模型 ===== base_model = AutoModelForCausalLM.from_pretrained( model_path, device_map="cpu", dtype=torch.float32, trust_remote_code=True, # 启用分块加载 + 就地绑定, 在加载模型权重时,避免“权重在内存里被复制一遍”,把“加载峰值内存”降到最低。 low_cpu_mem_usage=True ) toc(t0, "加载模型") t0 = tic()
设置模型进行推理模式
base_model.eval()
这行代码相当于告诉模型:"现在是推理,不是训练,关闭训练专用行为,让模型进入确定性、稳定的推理模式,本质上是设置了model.training = False
构建给大模型的输入并且使用tokenizer编码
messages = [ { "role": "system", "content": "你是一个简洁的助手。" }, {"role": "user", "content": "到底什么是光"} ] input_ids = tokenizer.apply_chat_template( messages, return_tensors="pt", add_generation_prompt=True ) # 构造 attention_mask attention_mask = torch.ones_like(input_ids) inputs = { "input_ids": input_ids.to(base_model.device), "attention_mask": attention_mask.to(base_model.device) }
开始推理,这里限制最多输出96个token,不然等太久了
with torch.no_grad(): outputs = base_model.generate( # **inputs, **inputs, max_new_tokens=96, temperature=0.7, top_p=0.9, do_sample=True, use_cache=True ) toc(t0, "模型推理") print("模型回答: \n") print(tokenizer.decode(outputs[0], skip_special_tokens=True))
自此我们的代码就写好了,总代码如下
python
import time
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# ================= 计时工具 =================
def tic():
return time.perf_counter()
def toc(t0, msg):
print(f"⏱ {msg}: {time.perf_counter() - t0:.3f} s")
# ================= 基础设置 =================
t0 = tic()
# ===== 基础设置 =====
torch.set_num_threads(12)
model_path = r"E:\it\project\pycharm\Qwen3-4B"
# ===== tokenizer =====
tokenizer = AutoTokenizer.from_pretrained(
model_path,
trust_remote_code=True
)
# ===== 加载 基础模型 模型 =====
base_model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map="cpu",
dtype=torch.float32,
trust_remote_code=True,
# 启用分块加载 + 就地绑定, 在加载模型权重时,避免"权重在内存里被复制一遍",把"加载峰值内存"降到最低。
low_cpu_mem_usage=True
)
toc(t0, "加载模型")
t0 = tic()
# 告诉模型:"现在是推理,不是训练,关闭训练专用行为,让模型进入确定性、稳定的推理模式,本质上是设置了model.training = False
base_model.eval()
messages = [
{
"role": "system",
"content": "你是一个简洁的助手。"
},
{"role": "user",
"content": "到底什么是光"}
]
input_ids = tokenizer.apply_chat_template(
messages,
return_tensors="pt",
add_generation_prompt=True
)
# 构造 attention_mask
attention_mask = torch.ones_like(input_ids)
inputs = {
"input_ids": input_ids.to(base_model.device),
"attention_mask": attention_mask.to(base_model.device)
}
#接下来的代码只做推理,不需要梯度,不要构建计算图
with torch.no_grad():
outputs = base_model.generate(
# **inputs,
**inputs,
max_new_tokens=96,
temperature=0.7,
top_p=0.9,
do_sample=True,
use_cache=True
)
toc(t0, "模型推理")
print("模型回答: \n")
print(tokenizer.decode(outputs[0], skip_special_tokens=True))推理过程
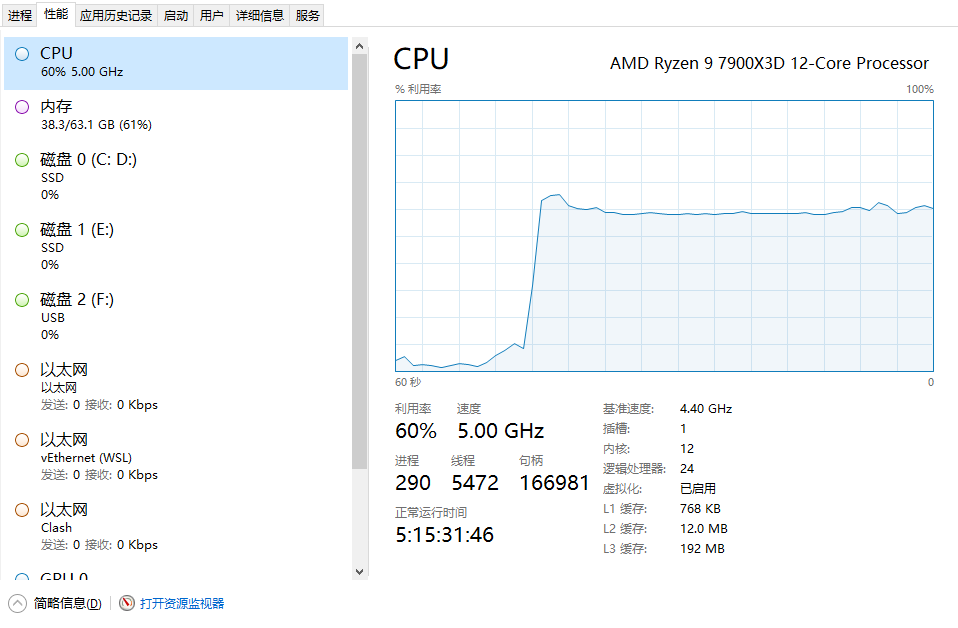
可以看见cpu消耗突然到了百分之60
推理结果
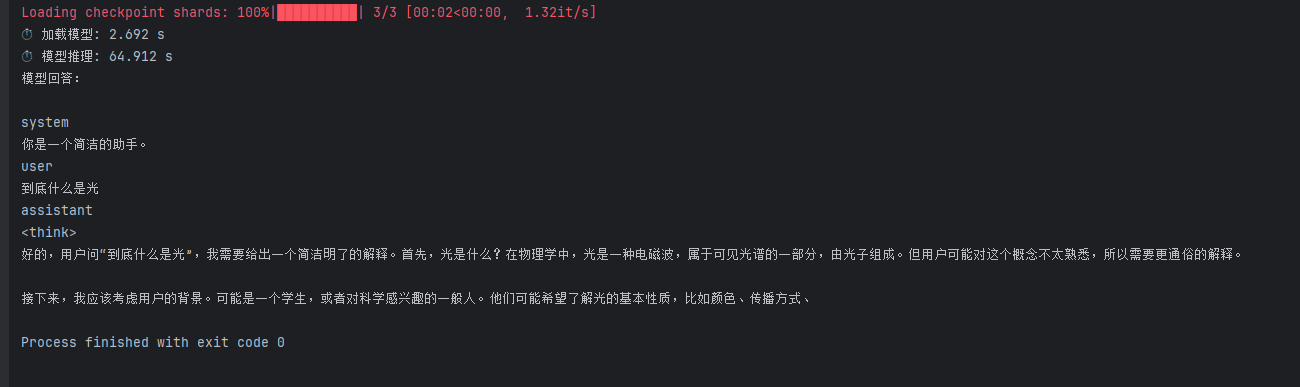
可以看见推理完成了,但是因为我设置max_new_tokens=96,输出不太完整,有条件的可以设置大一点。根据这个代码我们完全可以自己改装一下,变成一个web应用,给其他人提供chat gpt的功能,但是因为这部分和文章核心内容无关,就不做了。