大学院-筆記試験練習:数据库(データベース問題訓練) と 软件工程(ソフトウェア)(7)
- 1-前言
- 2-数据库データベース
- 3-数据库データベース-答案解析
- [一、問3(正規化)------❌ 核心概念性错误(必须纠正)](#一、問3(正規化)——❌ 核心概念性错误(必须纠正))
- [二、問4(SQL)------❌ 结构性错误(但可修)](#二、問4(SQL)——❌ 结构性错误(但可修))
- 4-软件工程(ソフトウェア)
- 5-软件工程(ソフトウェア)答案解析
-
- [問題1 评阅(要求定义为什么难)](#問題1 评阅(要求定义为什么难))
-
- [你的原意(✔ 对)](#你的原意(✔ 对))
- [✅ 本番满分修正版(推荐背)](#✅ 本番满分修正版(推荐背))
- [問題2 评阅(开发模型对比)](#問題2 评阅(开发模型对比))
-
- [理解(✔ 对)](#理解(✔ 对))
- 致命扣分点(⚠⚠)
- [✅ 本番满分修正版](#✅ 本番满分修正版)
- [問題3 评阅(是正保守 vs 適応保守)](#問題3 评阅(是正保守 vs 適応保守))
-
- [你的理解(✔ 非常好)](#你的理解(✔ 非常好))
- 小扣分点(⚠)
- [✅ 本番满分修正版](#✅ 本番满分修正版)
- [問題4 评阅(模块化 / 低耦合)](#問題4 评阅(模块化 / 低耦合))
-
- [你的理解(✔ 对)](#你的理解(✔ 对))
- [✅ 本番满分修正版](#✅ 本番满分修正版)
- 6-总结
1-前言
为了考上大学院,做了日语版本练习,边学边看边记录

2-数据库データベース
問1【データベース・B木操作|相似①】
次に示す 2 次の B 木 に対して,以下の操作を この順に 行った後の B 木を,
与えられた図と同様の箱・●ポインタ形式 で描け。
(1) キー値 18 のレコードを挿入する。
(2) (1) の結果に対して,キー値 26 のレコードを挿入する。
(3) (2) の結果に対して,キー値 7 のレコードを挿入する。
(4) (3) の結果に対して,キー値 21 のレコードを挿入する。
ただし,ノードの分割が発生する場合は,
分割の過程および昇格するキーが分かるように 図示すること。
(注意)
- 2 次 B 木における 1 ノードあたりのキー数 に注意せよ。
- 境界条件(<,≦)の扱いを誤らないこと。
問2【データベース・B木操作|相似②】
次に示す B+ 木 (内部ノードと葉ノードを区別する)に対して,
キー値 30 を削除する操作を行った。
(1) 削除後の B+ 木を図示せよ。
(2) 再配分または併合が発生するか否かを判定し,
発生する場合はその理由を説明せよ。
ただし,
- すべての葉ノードは 同一深さ にあるものとする。
- 再配分が可能な場合は,併合は行わない ものとする。
問3【データベース・正規化|予測①】
次の関係 ( R ) が与えられている。
R(\\underline{A}, B, C, D, E)
また,以下の関数従属が成り立つものとする。
- ( A \rightarrow B )
- ( B \rightarrow C )
- ( AD \rightarrow E )
(1) 候補キーをすべて求めよ。
(2) 関係 ( R ) が 第 2 正規形 であるか判定し,理由を述べよ。
(3) ( R ) を 第 3 正規形 に分解せよ。
(注意)
- 部分関数従属と推移的関数従属を混同しないこと。
- 不要な分解は減点対象とする。
問4【データベース・SQL|予測②】
次の表を考える。下線は主キーを表す。
- 学生( 学生番号 , 学生名, 学科番号, 生年月日)
- 履修( 学生番号, 科目番号 , 成績)
- 科目( 科目番号 , 科目名, 学期)
次の問い合わせを SQL を用いて記述せよ。
(1)
「すべての学期において 1 科目以上を履修している学生」の
学生番号と学生名を求めよ。
(2)
生年月日が 1995 年 1 月 1 日以降 の学生のうち,
その学生の成績が 同一学科内で最高点である学生 の全情報を求めよ。
(注意)
- WHERE と HAVING の使い分けに注意せよ。
- 同点が複数存在する場合は すべて出力 すること。
- 集合の包含関係を正しく表現すること。
3-数据库データベース-答案解析
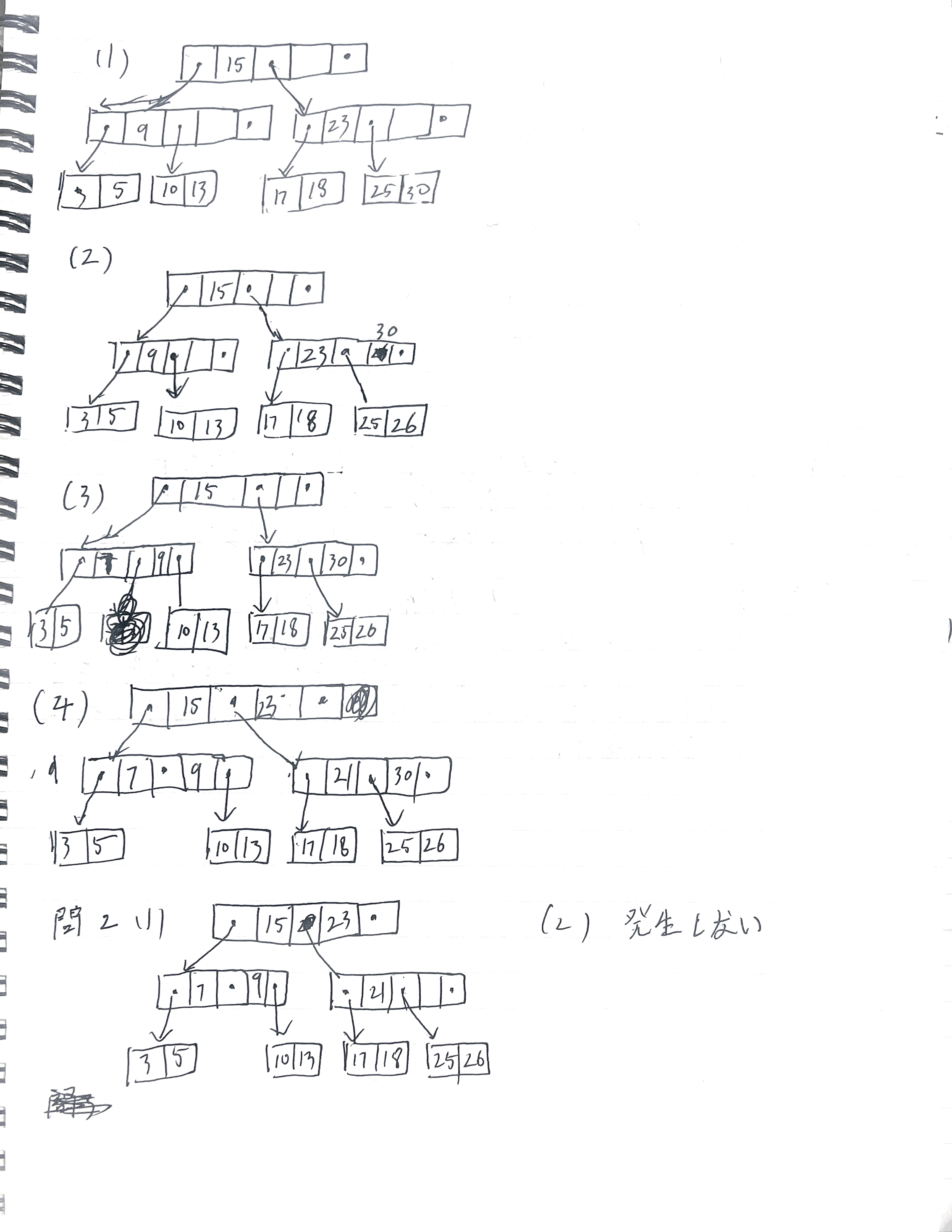

一、問3(正規化)------❌ 核心概念性错误(必须纠正)
这是今天最重要的一点。
题目回顾(问3)
关系:
R(\\underline{A}, B, C, D, E)
函数依赖:
- ( A \rightarrow B )
- ( B \rightarrow C )
- ( AD \rightarrow E )
你写的答案
(1)
候補キーは B と D
❌ 错误(致命)
正确分析(一步一步)
① 先做闭包
- ( A^+ = {A, B, C} )
- ( (A,D)^+ = {A, B, C, D, E} )
👉 只有 AD 能决定所有属性
✅ 正确结论
候補キー:AD(唯一)
❌ B 不是键(B 推不出 A、D、E)
(2)
第2正規形ではない
理由:非主属性的部分依赖没有消除
❌ 判断对,理由写错一半
正确逻辑是:
- 主键是 AD
- 非主属性 B、C
- 存在
A \\rightarrow B,\\ C
- A 是主键的一部分
→ 部分関数従属
👉 所以 不满足第2正規形
⚠️ 你没有明确点出「AD 是主键」,
(3) 你给的分解
R1(A, B, C)
R2(A, D, E)❌ 错误(不满足 3NF)
为什么错?
在 R1(A,B,C) 中:
- 有 ( A → B )
- 有 ( B → C )
👉 仍然存在推移的函数従属
不是第3正規形
✅ 标准满分分解
\\begin{aligned} R_1(A, B) R_2(B, C) R_3(A, D, E) \\end{aligned}
这三个表:
- 无部分依赖
- 无推移依赖
- 无信息丢失
📌 問3 採点评价
| 小问 | 评价 |
|---|---|
| (1) 候補キー | ❌ |
| (2) 正規形判断 | ⚠️(结论对,论证不严) |
| (3) 分解 | ❌ |
👉 本番:几乎整题失分
⚠️ 这是「概念没完全站稳」的典型信号
好消息是:这是最好补的那种错误
二、問4(SQL)------❌ 结构性错误(但可修)
問4(1)
「すべての学期において1科目以上履修している学生」
正确思路(考试要你这样想)
这是经典的:
不存在某个学期,该学生没有修任何课
👉 用 NOT EXISTS + 二重否定
✅ 满分结构(示意)
sql
SELECT S.学生番号, S.学生名
FROM 学生 S
WHERE NOT EXISTS (
SELECT *
FROM 科目 K
WHERE NOT EXISTS (
SELECT *
FROM 履修 R
WHERE R.学生番号 = S.学生番号
AND R.科目番号 = K.科目番号
)
);問4(2)
「学科内で最高点(同点含む)」
当前的问题
- ❌ 把 子查询最大值 写成了结构混乱的 HAVING
- ❌ 没有按 学科分组比较
- ❌ MAX 的作用域不清晰
正确逻辑
- 对每个学科算 MAX
- 与学生成绩比较
- 同点全部输出
正确结构(示意)
sql
SELECT *
FROM 学生 S
JOIN 履修 R ON S.学生番号 = R.学生番号
WHERE R.成績 = (
SELECT MAX(R2.成績)
FROM 学生 S2
JOIN 履修 R2 ON S2.学生番号 = R2.学生番号
WHERE S2.学科番号 = S.学科番号
);📌 問4 採点评价
| 小问 | 评价 |
|---|---|
| (1) | ❌ |
| (2) | ❌ |
4-软件工程(ソフトウェア)
【問題1】(软件工程・相似母题)
問1.
ソフトウェア開発において,要件定義の段階で問題が十分に解決されないまま設計・実装に進むことの問題点を,1つ挙げて説明せよ。
陷阱提示(你自己注意)
- ❌ 不要写「バグが増える」这种结果
- ✅ 要写「なぜ工程後半で致命化するか」
【問題2】(软件工程・相似母题)
問2.
ウォーターフォールモデルと比較した場合の,反復型(イテレーティブ)開発プロセスの特徴を1つ述べ,その理由を説明せよ。
陷阱提示
- ❌ 只写「柔軟」会被判不充分
- ✅ 必须出现「フィードバック 」「要求変更」中的至少一个
【問題3】(软件工程・预测题)
问3.
ソフトウェアの保守作業において,**是正保守(corrective maintenance)と適応保守(adaptive maintenance)**の目的がどのように異なるかを説明せよ。
陷阱提示
- ❌ 把「機能追加」写进去是常见扣分点
- ✅ 抓住「原因来源不同」
【問題4】(软件工程・预测题)
問4.
モジュール分割を行う際に,結合度を低く保つことが重要とされる理由を,ソフトウェアの品質の観点から説明せよ。
陷阱提示
- ❌ 不要只写「わかりやすい」
- ✅ 必须连接到「変更」「影響範囲」「保守性」
5-软件工程(ソフトウェア)答案解析

問題1 评阅(要求定义为什么难)
你的原意(✔ 对)
-
用户懂业务,不懂系统
-
要求没说清 → 后期问题多 → 返工、重做
-
「专业知识不足」写得有点泛
-
没明确点出 "解釈のズレ" 这个关键词
✅ 本番满分修正版(推荐背)
text
顧客は自らの業務に関する知識を豊富に持っている一方で,
システム開発に関する専門知識が十分でない場合が多い。
そのため,要件定義の段階で要求の解釈にずれが生じ,
曖昧な要求が残ったまま開発が進むと,
工程後半で多くの問題が発生し,手戻りや再構築が必要となる。📌 这一题:现在 ≈ 70% → 修正后 ≈ 95%
問題2 评阅(开发模型对比)
理解(✔ 对)
- 瀑布:前期固定,不灵活
- 迭代:能应对需求变化
致命扣分点(⚠⚠)
- 问题问的是「反復型の利点」
- 你写成了「ウォーターフォールの欠点」
「方向对,但答题焦点偏了」= 会被扣分
✅ 本番满分修正版
text
反復型開発プロセスでは,開発の途中で顧客からの
フィードバックを取り入れながら,
要求の変更や修正に柔軟に対応することができる。
そのため,要求の曖昧さを早期に発見し,
完成度の高いソフトウェアを開発しやすい。📌 这一题:现在 ≈ 50~60% → 修正后 ≈ 100%
問題3 评阅(是正保守 vs 適応保守)
你的理解(✔ 非常好)
- 是正保守:修正错误、保证正确性
- 適応保守:适应环境变化
小扣分点(⚠)
- 「使用方法」有点模糊
- 少了一个环境变化的具体来源
✅ 本番满分修正版
text
是正保守の目的は,ソフトウェアに内在する欠陥を修正し,
正しい動作を維持することである。
一方,適応保守の目的は,
ハードウェアやOSなどの実行環境の変化に対応し,
ソフトウェアを適応させることである。📌 这一题:你已经 ≈ 85~90%
問題4 评阅(模块化 / 低耦合)
你的理解(✔ 对)
-
影响范围小
-
修改不影响其他模块
-
保守性
-
変更容易性
✅ 本番满分修正版
text
モジュール分割の目的は,
各モジュールの影響範囲を限定することである。
結合度を低く保つことで,
あるモジュールを変更しても他のモジュールに
影響を与えにくくなり,
ソフトウェア全体の保守性や変更容易性が向上する。📌 这一题:现在 ≈ 75% → 修正后 ≈ 95%
6-总结
用日语的方式来直接训练,我认为是提示能力的好办法吧,希望从今天开始,每天坚持到考试那天,一直训练。