大家好我是小明,redis面试题
文章目录
- [1. 主从复制](#1. 主从复制)
-
- [1.1 主从数据同步原理](#1.1 主从数据同步原理)
- [2. 哨兵模式](#2. 哨兵模式)
- [3. 分片模式](#3. 分片模式)
- [4. redis其他面试题](#4. redis其他面试题)
开始之前先看一下主要的面试题

1. 主从复制
主从复制的特点:单节点的并发能力是有上线的,要进一步提高redis的并发能力,就需要搭建主从集群,实现读写分离。
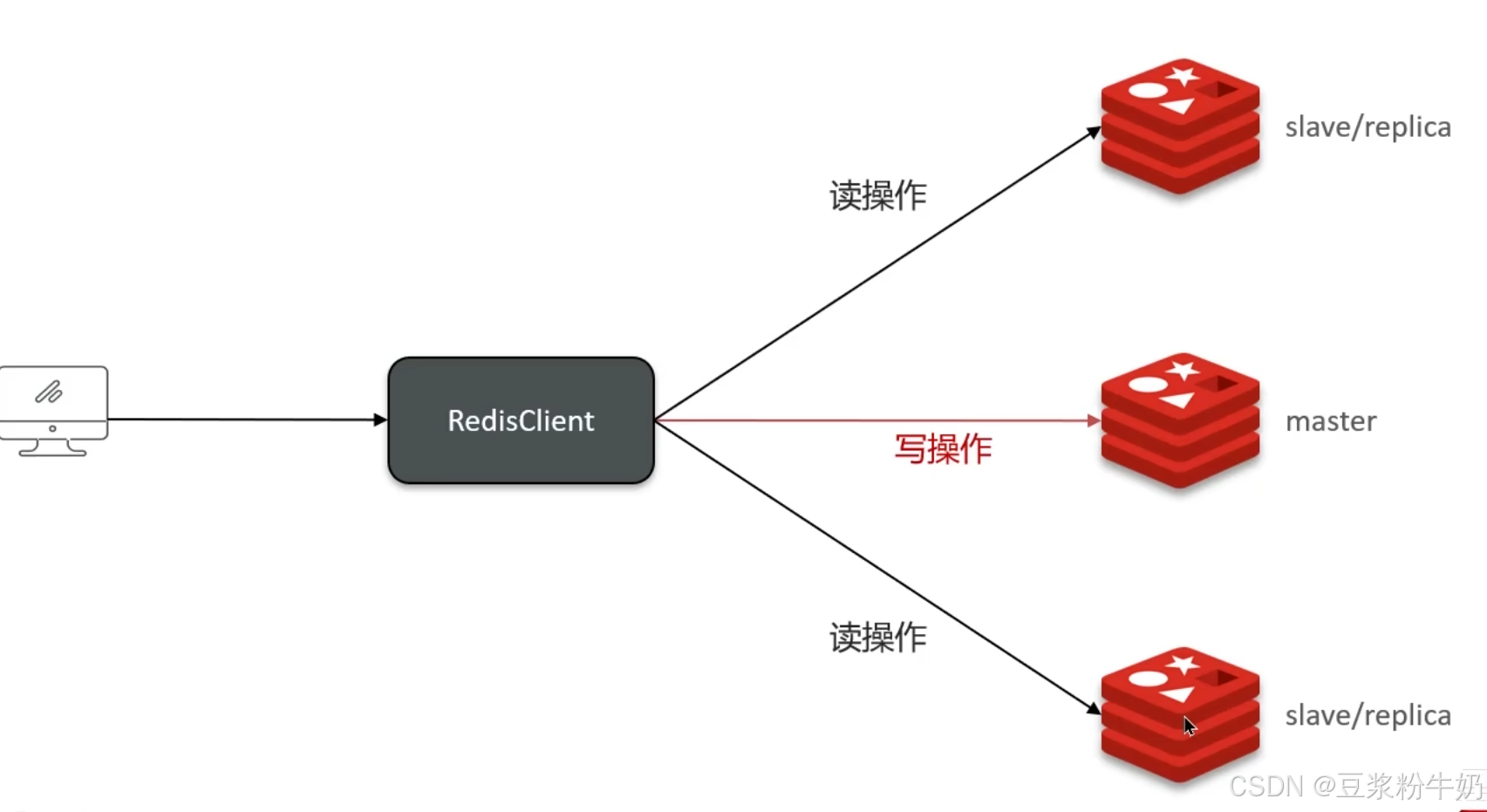
实现读写分离要保证主从数据同步。
1.1 主从数据同步原理
这个面试题是重点
全量同步:
- 从节点发起同步请求,携带复制标识(replication id)和偏移量(offset);
- 主节点判断请求类型,首次请求时同步版本信息(replication id、offset);
- 主节点执行后台持久化(bgsave)生成 RDB 文件,并发送给从节点加载;
- RDB 生成期间,主节点将新执行的命令暂存到缓冲区(命令日志);
- RDB 同步完成后,主节点将缓冲区的命令日志发送给从节点,完成增量同步。

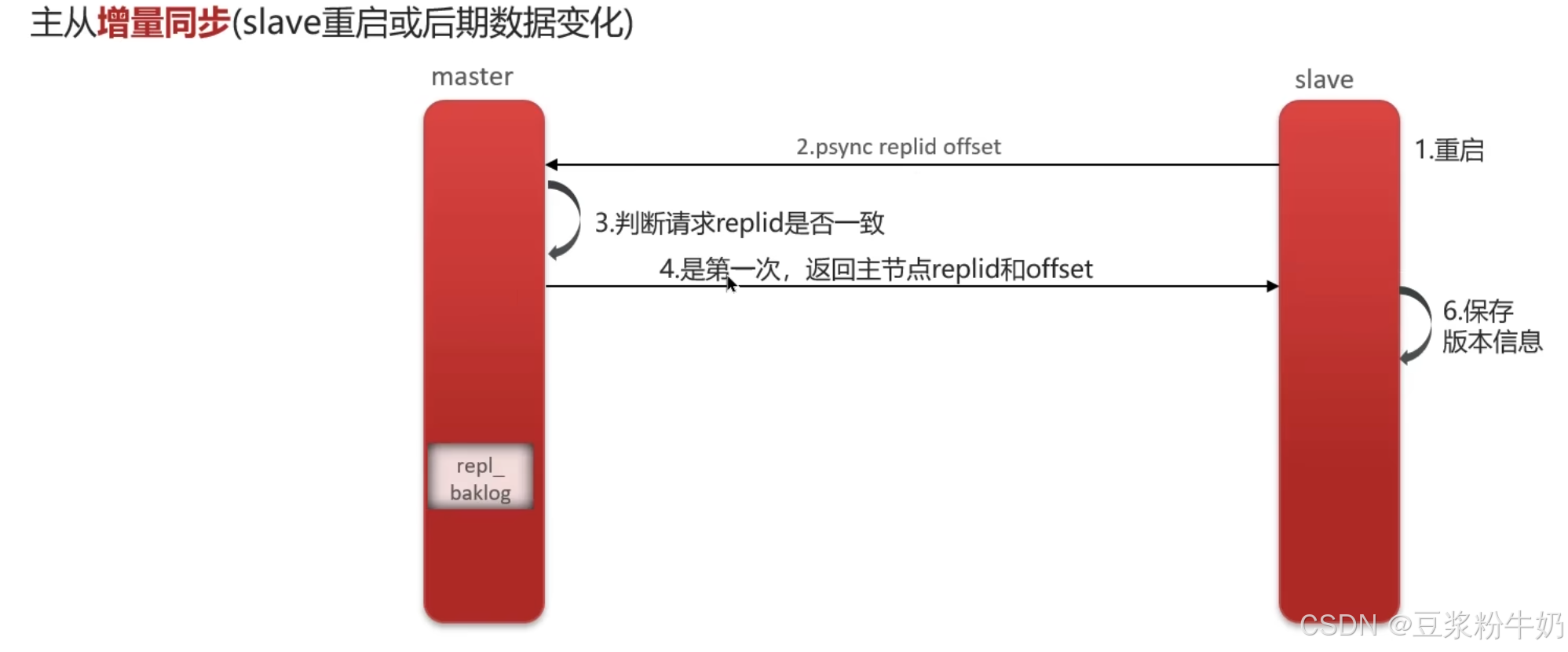
增量同步
- 从节点请求主节点同步数据,主节点判断该请求并非首次请求,进而获取从节点当前的偏移量(offset)值;
- 主节点从命令日志中,提取偏移量(offset)对应位置之后的命令数据,发送给从节点以完成数据同步。
解释:
"全量同步" 和 "增量同步" 是 Redis 主从复制中不同阶段的同步方式,并非二选一的配置,而是主从复制流程中自动结合使用的机制:
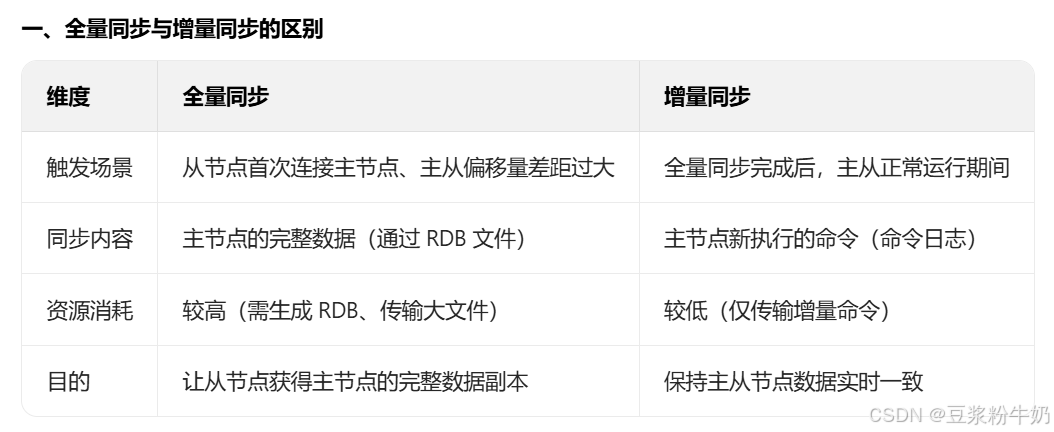
两者之间的关系:
全量同步和增量同步不是二选一的配置,而是主从复制流程中先后结合的步骤:
- 从节点首次同步时,先执行全量同步(获取主节点完整数据);
- 全量同步完成后,主从进入增量同步阶段(主节点持续将新命令同步给从节点);
- 若后续从节点断开重连,主节点会先检查偏移量:若偏移量在主节点的缓冲区范围内,则直接用增量同步;若偏移量超出缓冲区(数据已被覆盖),则重新触发全量同步。
主节点宕机服务器会丧失写的能力,这时候出现哨兵模式
2. 哨兵模式
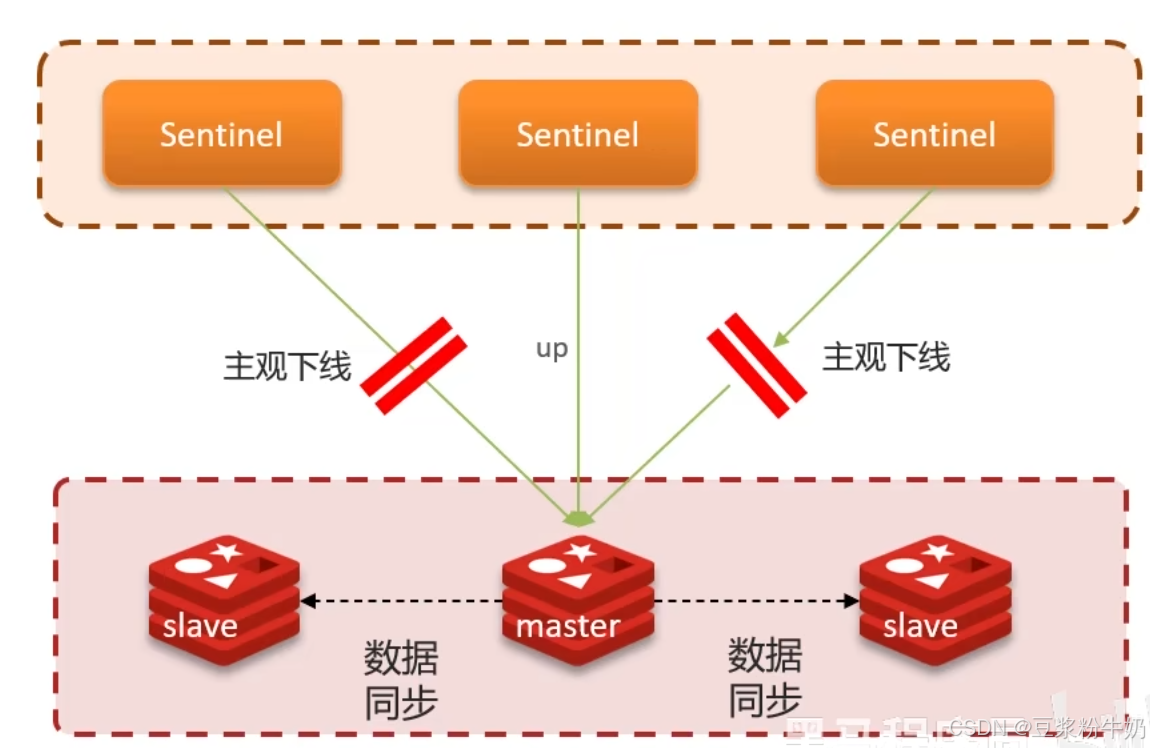
redis哨兵模式,机制来实现主从集群的自动故障恢复,哨兵结构模式如下:

哨兵的作用
- 监控:sentinel会不断的检查你的master和slave是否按照预期工作;
- 自动故障恢复: 如果master故障,sentinel会将一个slave提升为master,当故障实力恢复后也以新的master为主。
- 通知:当redis集群发生故障转移时,会将最新消息退送给redis客户端。
Sentinel 的服务状态监测(基于心跳机制)
Sentinel 每隔 1 秒向集群的每个实例发送 ping 命令,通过 "主观下线" 和 "客观下线" 两个阶段判断实例状态:
- 主观下线:若某 Sentinel 节点发现某实例未在规定时间内响应 ping 命令,则判定该实例为主观下线。
- 客观下线:若超过指定数量(quorum)的 Sentinel 节点均判定该实例为主观下线,则该实例被认定为客观下线。其中,quorum 值建议设置为超过 Sentinel 实例数量的一半。
哨兵选主规则
- 首先判断主与从节点断开时间长短,如超过指定值就排除该节点
- 然后判断从节点的 slave-priority 值,越小优先级越高
- 如果 slave-priority 一样,则判断 slave 节点的 offset 值,越大优先级越高
- 最后是判断 slave 节点的运行 id 大小,越小优先级越高。
哨兵脑裂问题
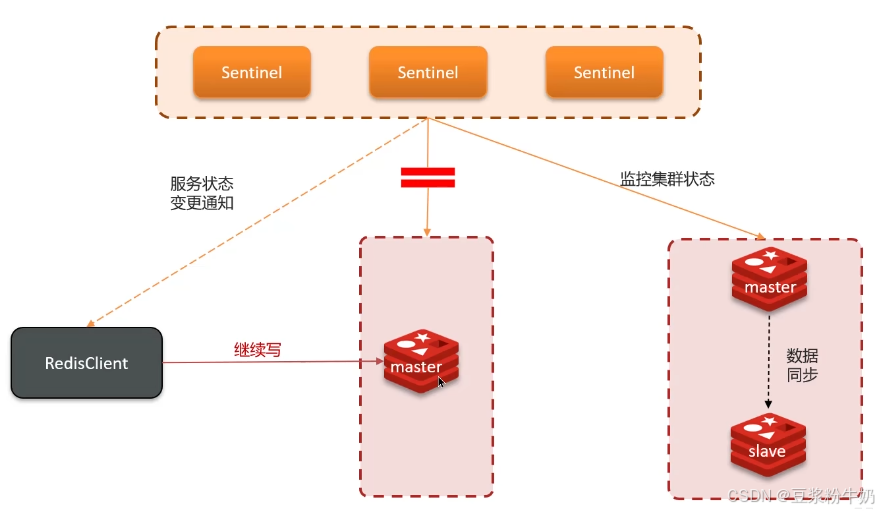
假如说出现网络问题,哨兵以为master下线,出现两个master的时候,服务还是往旧的master写数据,网络好的以后,旧的master强行降为slave。写入旧的master的数据就丢失了。
解决办法:
可以修改redis配置
java
redis 中有两个配置参数:
min-replicas-to-write 1 表示最少的 salve 节点为 1 个
min-replicas-max-lag 5 表示数据复制和同步的延迟不能超过 5 秒master达不到这两个要求就拒绝客户端的请求就好,以免数据丢失。
3. 分片模式
主从和哨兵可以解决高可用,高并发读的问题,但是依然有两个问题没有解决:
- 海量数据存储问题
- 高并发写的问题
使用分片集群可以解决上述问题,分片集群特征:
- 集群中有多个master,每个master保存不同数据
- 每个master都可以有多个slave节点
- master之间通过ping监控彼此健康状态
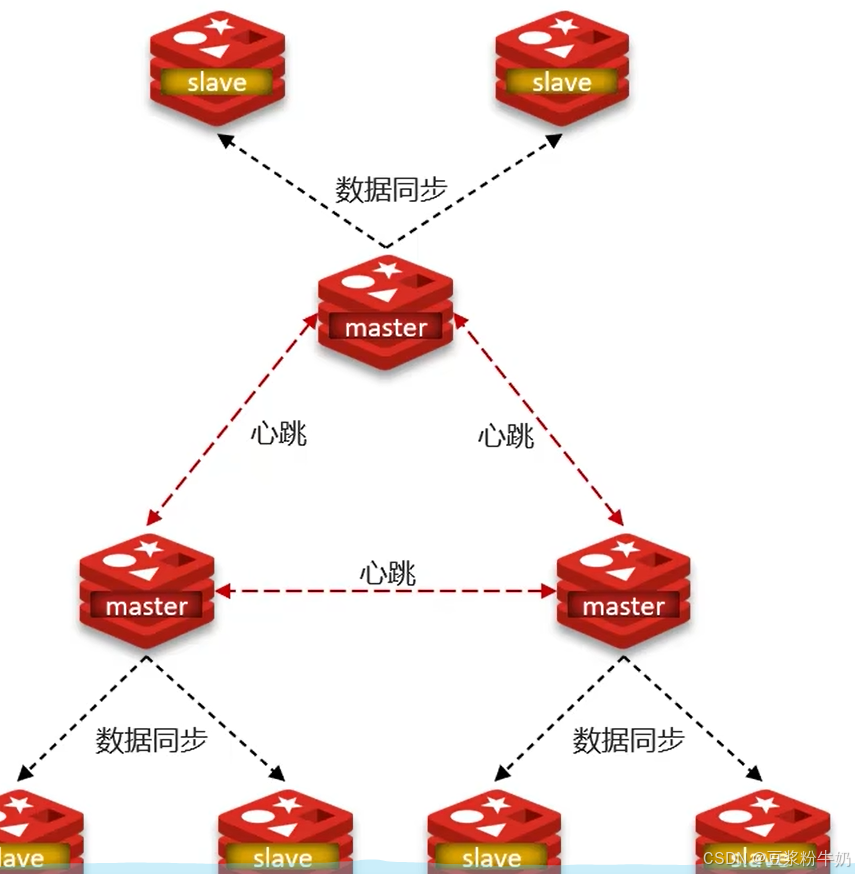
分片集群结构-数据的读写
redis集群引入了哈希槽的概念,redis集群有16384个哈希槽,每个可key通过CRC16校验后对16384取模来决定放置哪个槽,集群的每一个节点负责一部分hash槽。
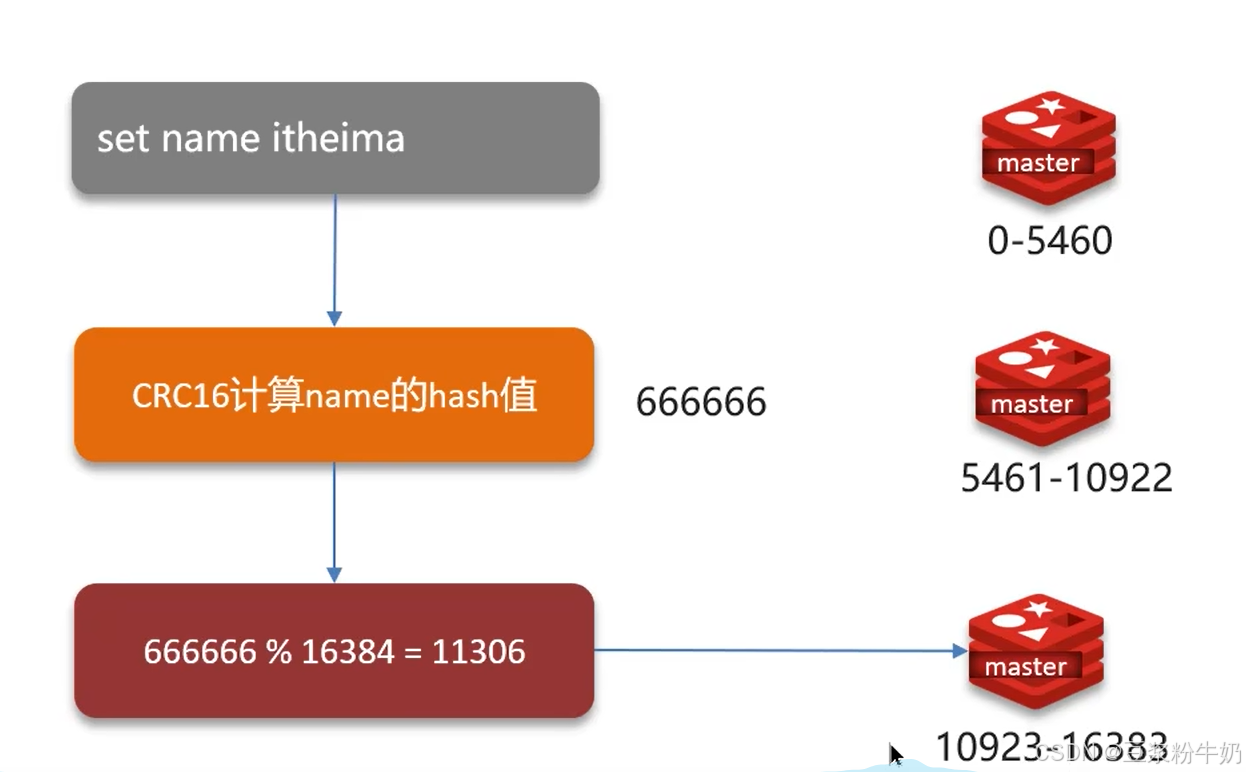
读写数据:根据 key 的有效部分计算哈希值,对 16384 取余(有效部分,如果 key 前面有大括号,大括号的内容就是有效部分,如果没有,则以 key 本身做为有效部分)余数做为插槽,寻找插槽所在的实例。
4. redis其他面试题
redis是单线程的,但是为什么还是那么快
- redis是存内存操作,执行速度非常快。
- 采用单线程,避免使用多线程对cpu资源竞争,多线程还要考虑线程安全问题
- 使用I/O多路复用模型,非阻塞IO
解释一下,I/O多路复用模型
redis是纯内存操作,执行速度非常的快,他的性能瓶颈是网络延时而不是执行速度,I/O多路复用模型主要就是实现了高效的网络请求。
I/O多路复用是相比于阻塞I/O,和非阻塞I/O快,分析:
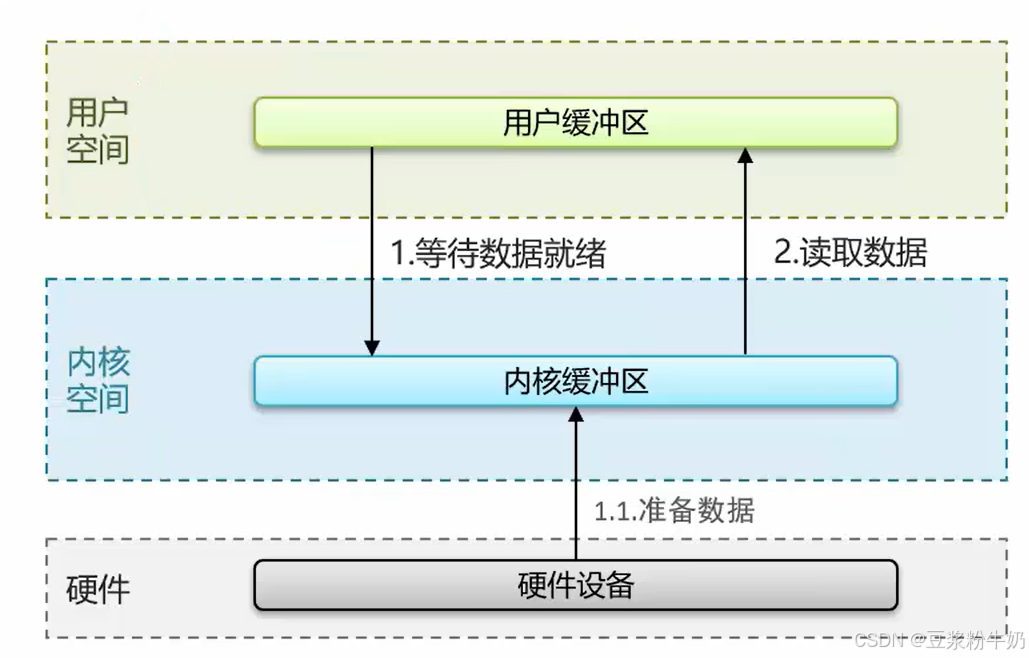
软件的读写数据都需要在用户缓冲区获取,内核是操作硬件的,比如说:网卡,网络请求获取到的数据,经过网卡,内核空间,在经过用户空间,最后到达该软件。

阻塞io模型缺点 :一直在等待内核返回的的数据,性能比较低。
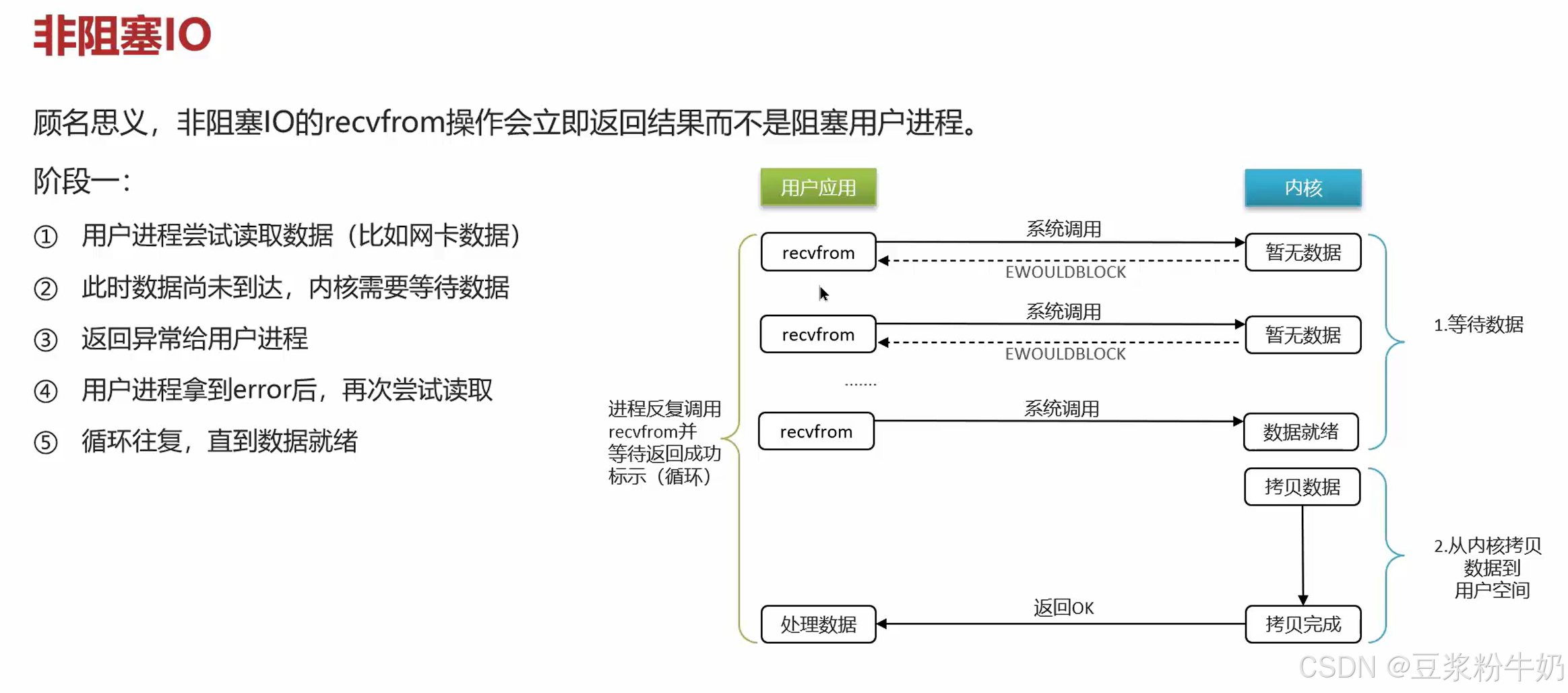
非阻塞io模型 :用户空间没有获取到数据,就会一直循环请求到内核,一直到拿到数据为止,性能没有得到提高,并且一直循环调用请求内核,cpu使用率暴增,还有cpu空转。
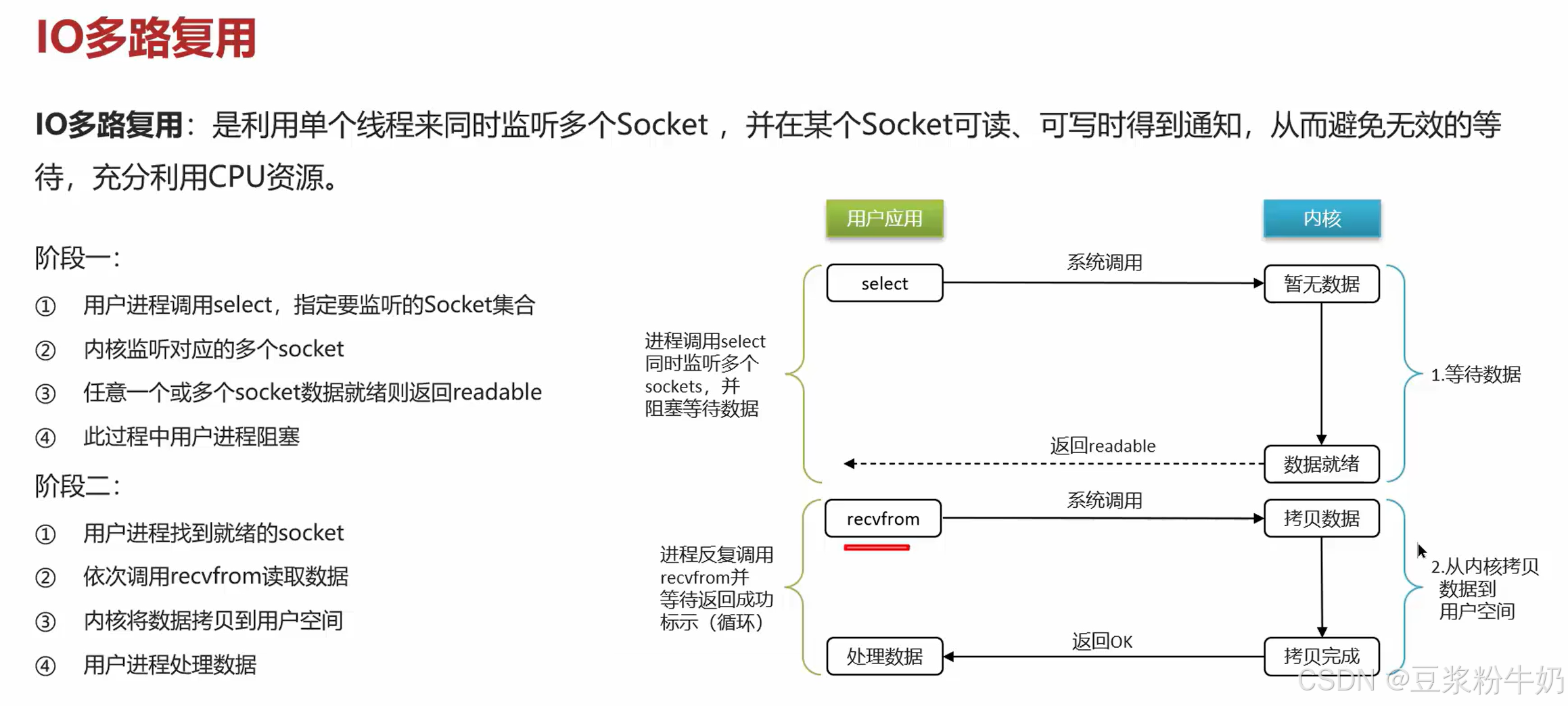
IO多路复用:就是使用一个单线程同时监听多个Socket,Socket是属于内核空间的,如果哪个Socket可读,可写就通知用户空间,用户空间再来获取内核数据。
相比于前面两种模型,减少了cpu使用率,cpu空转。
redis使用的io多路复用有三种模式
- select
- poll
- epoll
差异:
- select 和 poll 只会通知用户进程有 Socket 就绪,但不确定具体是哪个 Socket,需要用户进程逐个遍历 Socket 来确认。
- epoll 则会在通知用户进程 Socket 就绪的同时,把已就绪的 Socket 写入用户空间。