⑴
Now, it turns out here we are talking about how to represent information, like numbers, but we could also use bits, 0's and 1's, light bulbs to represent instructions as well. Because, at the end of day, that's all computers do. They process data, information of some sort, wether it's files, or numbers, or images, or videos, or the like. And you do things with those files. You open them, you print them, you edit them and the like. So there's this notion of instructions, what the computer can actually do.
⑵
No matter how fancy today's hardware or software is, it really just boils down to representing, information and instructions. And computers, and phones, and the like really are, just, operating on those same pieces of information, whether implemented in 0's and 1's or with anything else. So where can we take this, once we have this agree-upon system for representing information ? Well, it turns out that using three bits, three 0's and 1's, at a time, isn't actually all that useful. And you and I even, in conversation, don't often say the word "bit", we say word "byte". And what is a byte, if familiar ?

So, it's just eight bits. It's just more useful unit of measure. And it happens to be a power of 2, 2 to third, which just makes math work out cleanly. But it's just a convention, to have more interesting units of measure than individual bits. So a byte is eight bits.

So, for instance, this represents, using eight bits, eight light bulbs, the number you and I know is 0.
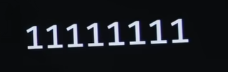
And this byte of all 1 bits, now you've got to do some quick math - - represents what number, instead ? So, it's, indeed, 255.

This is the one's place, two's, four's, eight's, 16's, 32's, 64's, 128's. And because they're all 1, you just have to add up all of those column's values. And you get 255. But a little mental trick, too, is that, if you're got eight bits and each of them can be two possible values, 0 or 1, that's like 2 possibilities here times 2, times 2, times 2, times 2, eight times. So that's 2 to the eight, so that is maybe a little easier to do. That's 256, or easier, in the sense that you get used to seeing these numbers in CS, that's 256.
⑶
So how do you represent letters, because, obviously, this makes our devices more useful, whether it's in English or any other human language. How could we go about representing the letter A, for instance ? If, at the end of the day, all our computers, all our phones have access to is electricity, or equivalently switches, or metaphorically tiny little bulbs, inside of them that can be on and off -- that's it. There's no more building blocks to give you. How could we represent something like the letter A ? So we could just assign every letter a number. And we could do this super simply. Maybe 0 is A, and 1 is B, or maybe 1 is A, and 2 is B. It doesn't really matter, so long as we all agree and we all use the same types of computers, in some sense, ultimately, well, for various reasons, the human's that designed this system, they went with the number 65. So nowdays, anything your computer is showing you the capital letter A on the screen, underneath the hood, so to speak, it's actually storing a pattern of 0's and 1's that represents the number 65. And it tends to use seven bits or, typically, eight bits, total, even if it doesn't need all of those bits in total. So how do we get there ?

Here is that pattern of bits that represents 65. This is the one's place, two's, four's, eight's, 16's, 32's, 64's place. OK, so 64 plus 1 give me 65. So that is to say here's how a computer, using some light switches, so to speak, would represent the number 65. And our Macs, our PCs, our phones just all know this. So whenever they see that in their memory, so to speak, they show a capital letter A on the screen. That's the system known as ASCII.(the American Standard Code for Information Interchange)
⑷
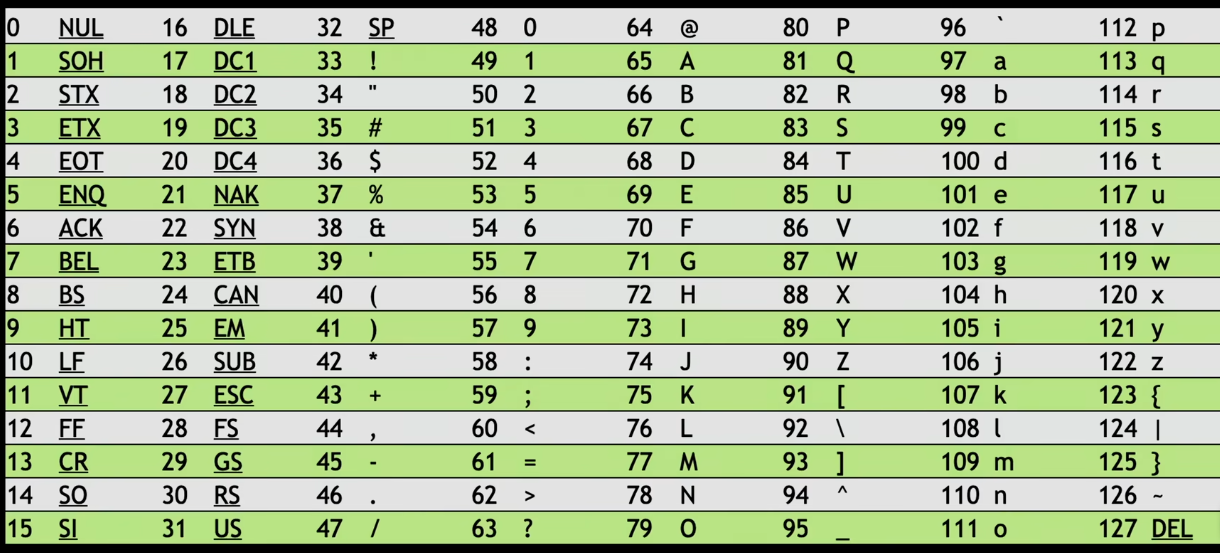
And the A is actually operative there because we're only talking, thus far, about English letters in our alphabet. So just to come back to you, if I may, how many possible letters of the alphabet could - - how many possible letters of any alphabet could we represent with eight bits ? 256, the numbers 0 through 255. Now, that's more than enough for English because we've got A throug Z, uppercase, lowercase, a bunch of numbers, a bunch of punctuation symbols. But in a lot of languages, with accented characters, a lot of Asian characters, this is not nearly enough memory or bits with which to represent all of those possible values, so we need to do a little better than ASCII, but we can build on top of what they did years ago.So here is a chart of ASCII codes.
It's just a bunch of columns showing us the mapping between letters.
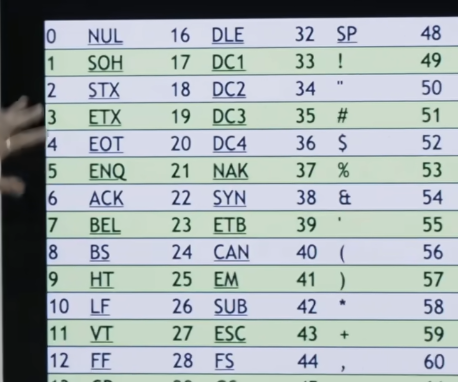
There's some weird things over here like special symbols, that we'll learn about over time . But there's mapping between every English letter of the alphabet and some number, just as you had propose, both for uppercase and lowercase.
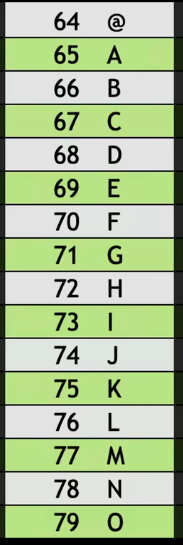
So, for instance, if we highlight just a few of these for now and I say that I've just received a text message or an email that, underneath the hood, so to speak, if I have the ability to look at what switches are on and off,

I receive this message here. Well, first - - and this is not what CS is about, but just fun fact.

Does anyone know what number this would represent in decimal, if this is the binary pattern, like one's place, two's place ?
72 is correct. And again, not, intellectually, all that interesting and this is not the kind of math that we spend all day as CS - - a computer scientist doing. But it's just following the same darn pattern, which is to say it might look cryptic, but conceptually, intellectually, it ultimately is exactly as we did before.

So, yes, I'll spoil the rest of the math. It's 72, 73, 33. Now, anyone remember, in your mind's eye, that message we just spelled ? Yeah, so it is in fact, "HI!". What's the 33, if you noticed ?

Yes, it's an exclamation point.
And that's, indeed, noticeable right here. 33 is the exclamation point. And that's just something, eventually, that might sink in. But, for the most part, if you remember capital A is 65, you can figure out at least 25 other answers to these kinds of questions because they're all contiguous like that. But at the end of the day, we might just have this mapping known as ASCII. And it's how our phones, and computers, and devices, more generally, actually store information.
⑸
So, let's see, then, if we've solved, now, the problem of representing English letters of the alphabet, being able to spell out words like " bow ", B - O - W, what if we do have other glyphs that we want to represent ?

Well, here, of course, is a standard US English keyboard, which a lot of you might have.
But there's also characters that you can type much more easily if you have a foreign keyboard, relative to the US, or with certain keystrokes on your own Mac, PC and phone. But nowadays, too, there's this menu that probably, you've used in the past hour or two to actually send some emoji.
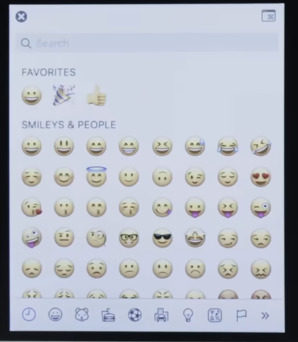
And emoji, even though look like pictures and they actually are pictures on the screen they're, technically, just characters, characters of an emoji alphabet that happened to use a certain pattern of 0's and 1's to represent, each of these faces, each of these people and places, and things. And it turns out that one of the reasons that we have just so many such characters nowadays is because we now use Unicode instead of ASCII.
⑹
So, Unicode is a superset, so to speak, of ASCII, which is to say that we, humans, realized, some time ago, that just using eight bits to represent letters of the alphabet, certainly isn't very good when we want to represent other non-English languages. So Unicode doesn't just use eight bits. It sometimes use 16 bits per character, sometimes 24 bits per character, and sometimes even 32 bits per character. Now, why those number ? That's just one byte, two bytes, three bytes, or four bytes. And that gives us the ability to represent as many as 4 billion possible characters. Because if the longest one is 32 bits, that's 2 to the 32, which, if you do out the math, trust me, is roughly 4 billion. So that's a lot of characters. And we've got a lot of room, then, for these emoji. But it's not just about having fun, pictorically, on the screen Unicode's mission really is to represent and to preserve all human languages digitally both past, present, and future. So it is really about capturing the entirety of human knowledge as we've expressed it in language, but also giving this newfound ability that's been used centuries ago, too - - in writings on walls, and the like - - pictograms via which. We can still communicate, even independently of our own human language. So, we'll reduce it, today, to just patterns of 0's and 1's, but the problem being solved is much greater and well-beyond CS, itself, there.
⑺
Unicode, so more than eight bits, that represents a very popular emoji, which might be a bit of a hint.

This is the most popular emoji, as of last year, at least, statistically, internationally.

Does this help ? It's, roughly, this number here. No ?

It's this one here. So this is the most popular emoji, by most measures, as of last year. But it doesn't always look like this. Those of you who have a Mac or an iPhone recognize this symbol, perhaps immediately.

Those of you with Android devices or other platforms, might notice that it's the same idea, but it's a little bit different. And this is because, too, emojis, at the end of days, just represent character, but those characters can be drawn, can be painted in different ways. And reasonable people will interpret differently this emoji, whose official name is " face with tears of joy ". And, indeed, Google interprets it a little differently from Apple, versus Microsoft, versus Meta, versus other companies, as well. So you can almost think of those different companies as having different fonrs for emoji. And that really starts to connect things to the world of text and characters.

So, just as you've seen it. More on this, another time. It turns out that emoji and, really, characters, in general, we don't use binary 0's and 1's to represent them because no one, myself included, is going to recognize what's that. It's just too much math. It's not interesting. And even decimal - - that was 4 billion or some - - I don't remember which number is which. So we represent things a little more compactly. And this, too, admittedly, still looks cryptic, but this is a Unicode code point that uses another system, mathematically called base-16 or hexadecimal. More than that, another time.
⑻
But it's just way of representing numbers even more succinctly writing less on the screen, because you're using not just 0 through 9, as in decimal. But you're using A through F, as well, so a few letters of English alphabet come into play. But, for now, that's just a little easier to remember, too, for people who care that is the number that represents " face with tears of joy ". But what if we want a customized emoji ? And this, increasingly, is the case.

Here, for instance, are the five skin tones that phones, and laptops, and desktops, nowadays, support. It's based on something called the " Fitzpatrick scale " which essentially categorizes human skin tone six, or, in this case, five different categories, from lighter to darker. But this suggests that, wow, if we want to represent people with five different skin tones, like this, that could significantly increase how many unique patterns of 0's and 1's we need for every possible face. But if we think about it from an engineering perspective, we can actually just think of skin tone as modifying some default color, for better or for worse. And yellow is the de facto default, Simpson style. But to modify it to look more genuinely human-like from lighter to darker, well, maybe we just use the same pattern of bits to represent a human thumb, for instance, thumbs up or thumbs down. And we just, then, modify that character to be displayed with a different skin tone.

So, for instance, here, then, is the " thumbs up " that you might use on various platforms.
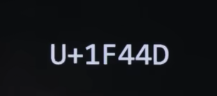
And let me just stipulate that this is the Unicode code point. That is the number that Macs, PCs, and phones use underneath the hood to represent the default yellow " thumbs up ". But if you want to give it a medium skin tone you still use that same number that same pattern of 0's and 1's, or switches, underneath the hood. But you use a few more switches that the computer or phone will interpret as, " Oh, you don't want to see the default in yellow "

Because of this second number that's in the computer's memory somewhere. You want me to adjust it to be the medium skin tone or any of the other values, instead." So that's the engineering solution to this problem of just trying to represent different ranges of emoji here.

Well, what about something like this ? There's a lot more combinatorics, nowadays, on your keyboard for relationships, for instance. So here is a " couple with heart ". But if you want to be more specific - - like man and woman, or man-man, woman-woman - - it's the same idea but we just need to express ourselves a little - - with a little more information.

So, for instance, the way the Unicode folks came up with years ago, to represent, for instance, a woman with a heart and a man from left to right, would be using these values. So things just escalated quickly, but only in the sense that we're using more bits, more 0's and 1's, to represent more expressively, this particular combination.

So this happens to be the number in Unicode that represents the woman at left,

This is the number that's represents the man at right.

And this is the pair of numbers that represents the heart in the middle, sometimes red, sometimes pink, displayed here as pink. But if we want change the combination to be woman-woman.

notice that, now, the left and rightmost number match. Or if we flip it back to man-man.

It's just using different numbers on the tail end again.
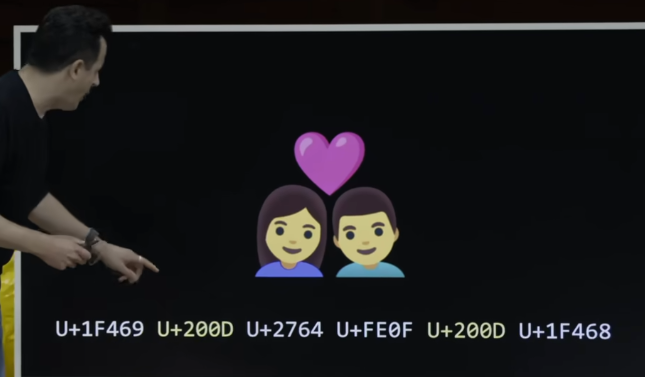
And meanwhile, if I rewind, there's these two identical values here. These are called Zero-Width Joiners or ZWNJ characters. It just is a special number that humans reserve to say glue the emoji at the left to the emoji on the right and so forth. So it connects ideas in this way. So there's actually a lot of emojis, nowadays, that are a combination of different things. " heart on fire " is one's that, technically the combination of a heart emoji, the fire emoji joined together, numerically, in this way. So computer scientists who come up with these thing are just reducing things to representations. All we have at our disposal are 0's and 1's. So we all just need to agree, ultimately, whether we're Google, Microsoft, or the like - - how we're going to standardize these kinds of things as information.