在数据库开发中,我们经常听到一句话:"尽量把字段设置为 NOT NULL"。这不仅仅是为了节省存储空间或优化索引,更重要的是为了规避 NULL 带来的逻辑混乱。
NULL 在 SQL 标准中并不等于 0,也不等于空字符串 ''。它代表的是 "Unknown"(未知)。
正是这个"未知"属性,打破了编程语言中常见的二值逻辑(True/False),引入了复杂的三值逻辑 (Three-Valued Logic)。
一、 底层逻辑:为什么 NULL != NULL ?
在 Java 或 Python 中,null == null 通常为真。但在 SQL 中,这是一个经典的陷阱。
请看以下 SQL 的执行结果:
SELECT 1 = 1; -- 结果: 1 (True)
SELECT 1 = 0; -- 结果: 0 (False)
SELECT 1 = NULL; -- 结果: NULL (Unknown)
SELECT NULL = NULL; -- 结果: NULL (Unknown)原理分析:
因为 NULL 代表"未知"。
"一个未知的值"等于"另一个未知的值"吗?数据库无法确定,所以结果依然是"未知"。
在 SQL 的 WHERE 子句中,只有当表达式结果为 True 时,数据才会被返回。False 和 Unknown 都会被丢弃。
这就是为什么 SELECT * FROM users WHERE age != 20 永远查不到 age 为 NULL 的用户。因为 NULL != 20 的结果是 Unknown。
✅ 正确写法:
必须使用专门的操作符 IS NULL 或 IS NOT NULL,或者使用 COALESCE 函数处理默认值。
SELECT * FROM users WHERE age != 20 OR age IS NULL;
-- 或者
SELECT * FROM users WHERE COALESCE(age, 0) != 20;二、 致命陷阱:为什么 NOT IN 查不到数据?
这是 NULL 导致的最严重、也最难排查的 Bug。
场景复现:
我们需要查询"没有下单记录的用户"。
表 A (users) 有用户 ID:1, 2, 3。
表 B (orders) 有下单用户 ID:1, NULL (脏数据)。
错误的写法:
SELECT * FROM users
WHERE id NOT IN (SELECT user_id FROM orders);预期结果: 用户 2, 3。
实际结果: 空集 (Empty Set)。一条数据都查不到。
逻辑推演:
NOT IN 本质上是一组 AND 条件的简写。
上述 SQL 等价于:
SELECT * FROM users
WHERE id != 1
AND id != NULL; -- 问题出在这里当判断用户 2 时:
-
2 != 1-> True -
2 != NULL-> Unknown -
True AND Unknown-> Unknown
由于最终结果不是 True,该行被过滤。只要子查询中包含任何一个 NULL 值,整个 NOT IN 查询就会彻底失效,返回空结果。
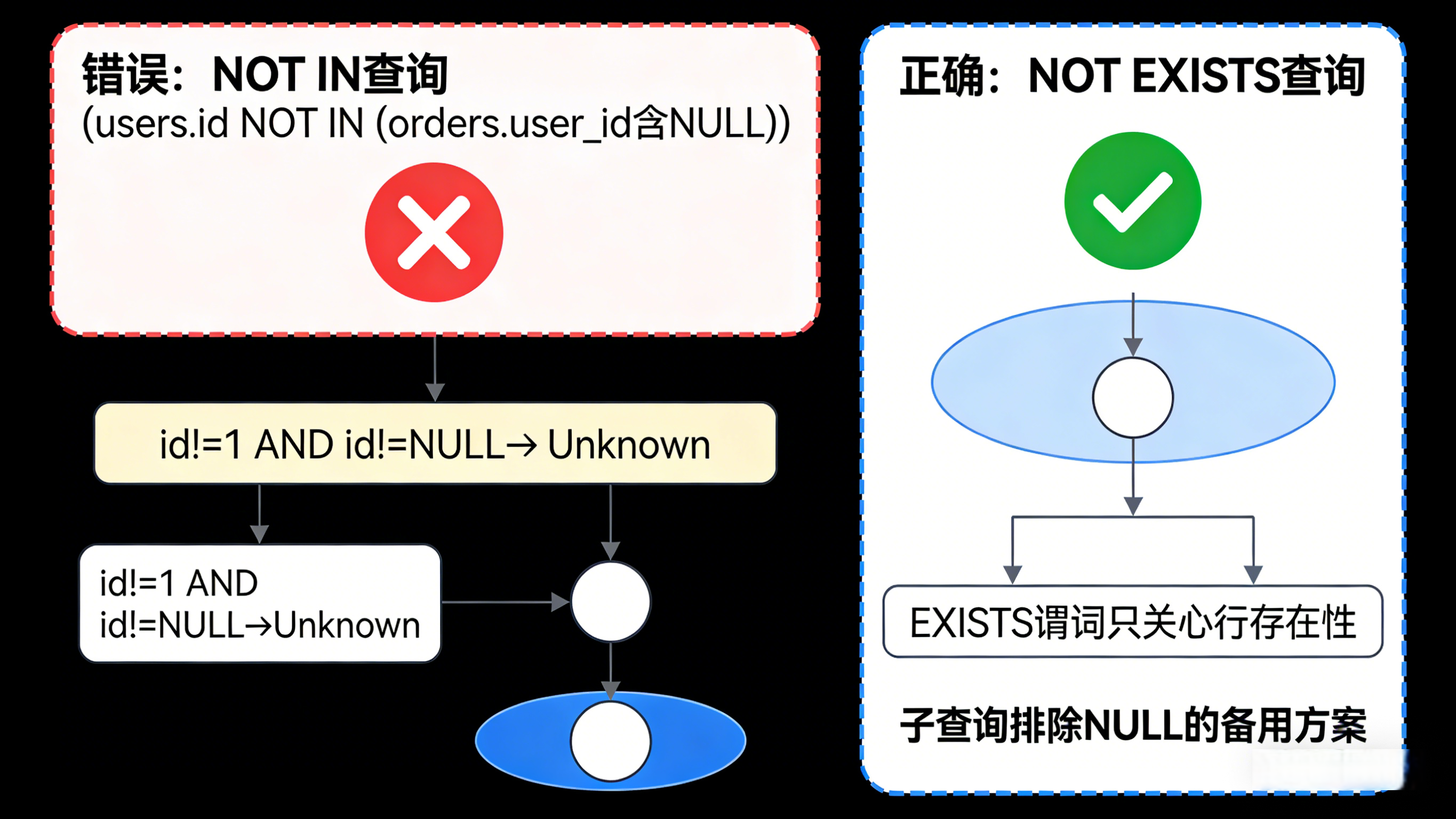
✅ 正确解法:使用 NOT EXISTS
EXISTS 谓词只关心"有没有行",它不受 NULL 的三值逻辑影响。
SELECT * FROM users u
WHERE NOT EXISTS (
SELECT 1 FROM orders o WHERE o.user_id = u.id
);或者,如果你非要用 NOT IN,必须在子查询中显式排除 NULL:
WHERE id NOT IN (SELECT user_id FROM orders WHERE user_id IS NOT NULL)但从性能和语义稳健性角度,推荐始终使用 NOT EXISTS。
三、 统计偏差:COUNT(*) 与 AVG() 的数学游戏
在使用聚合函数时,NULL 的处理方式同样存在不一致性,极易导致报表数据对不上。
1. 计数的差异
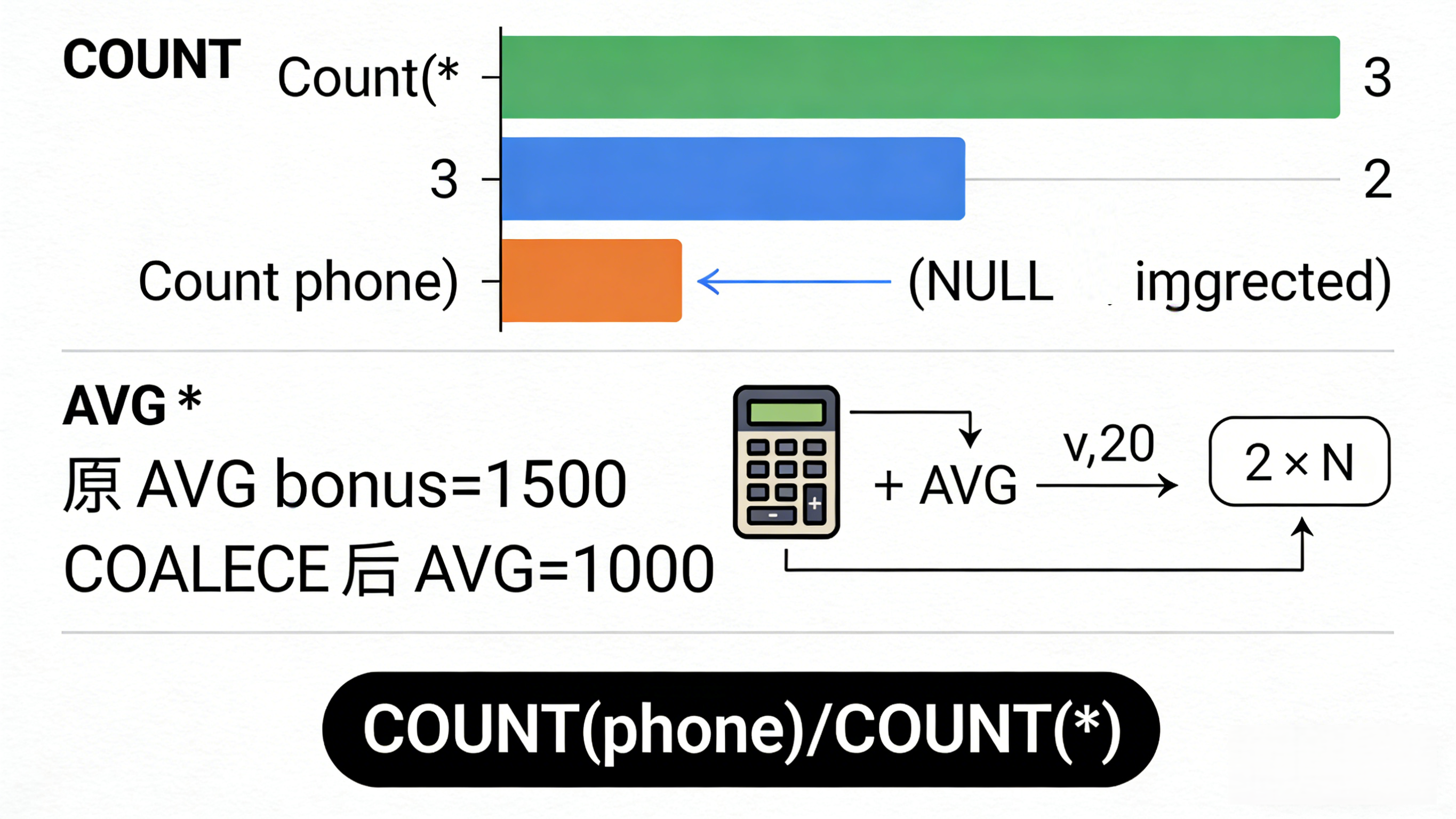
-
COUNT(*):统计物理行数。无论列值是否为 NULL,都算一行。 -
COUNT(col):统计有效值。如果该列为 NULL,则不计数。
实战场景: 计算"用户手机号填写的覆盖率"。
应使用 COUNT(phone) / COUNT(*),而不是直接看行数。
2. 平均值的陷阱
AVG()、SUM()、MAX() 等聚合函数在计算时,会自动忽略 NULL 值。
场景复现:
某部门 3 个人,奖金分别是:1000, 2000, NULL(未发)。
老板问:平均奖金是多少?
SELECT AVG(bonus) FROM employee;-
计算逻辑: (1000 + 2000) / 2 = 1500。
-
业务逻辑: 可能要把 NULL 当作 0 处理,即 (1000 + 2000 + 0) / 3 = 1000。
✅ 正确写法:
如果业务要求 NULL 视为 0,必须先处理值:
SELECT AVG(COALESCE(bonus, 0)) FROM employee;四、 排序的诡异:NULL 在前还是在后?
当你对包含 NULL 的列进行 ORDER BY 时,不同的数据库行为不一致:
-
MySQL: 默认认为 NULL 是最小值(ASC 时排在最前)。
-
Oracle/PostgreSQL: 默认认为 NULL 是最大值(ASC 时排在最后)。
这会导致 API 返回给前端的列表顺序在不同环境下表现不一致。
✅ 通用解法:
使用标准语法控制 NULL 的位置:
ORDER BY sort_no ASC NULLS LAST; -- 强制 NULL 排在最后注:MySQL 原生暂不支持 NULLS LAST 语法,可以使用 ORDER BY -sort_no DESC (针对数字) 或 ORDER BY ISNULL(sort_no), sort_no 来模拟。
总结
SQL 中的 NULL 不是"空",它是"未知"。在处理 NULL 时,请遵循以下三条铁律:
-
比较原则: 永远不要用
=或!=去比较 NULL,只能用IS NULL。 -
集合原则: 严禁在
NOT IN的子查询中引入 NULL 值,首选NOT EXISTS。 -
计算原则: 聚合计算前,根据业务需求使用
COALESCE(col, 0)填充默认值,防止分母计算错误。