⭐ 深度学习入门体系(第 18 篇): Batch Size:为什么它能影响训练速度与泛化能力?
------深度学习中的"每次端上几盘菜"问题
如果说学习率是训练中的"油门",
那么 Batch Size(批大小) 就是训练中的"上菜节奏"。
- Batch 大:每次端上很多"样本菜",厨师(模型)更新得更稳定
- Batch 小:每次端几道菜,厨师(模型)根据小样本更频繁调整
你可能看到很多人讨论:
- 批量越大越好吗?
- 为什么大 batch 训练会掉精度?
- 为什么小 batch 会更"稳"?
- batch 与学习率之间有什么关系?
- 为什么现在大模型都用巨大的 batch(甚至几万)?
这一篇,我们用"人话 + 工程逻辑"讲清楚 batch size 的全部关键性。
文章目录
- [⭐ 深度学习入门体系(第 18 篇): Batch Size:为什么它能影响训练速度与泛化能力?](#⭐ 深度学习入门体系(第 18 篇): Batch Size:为什么它能影响训练速度与泛化能力?)
- [🍱 一、Batch Size 是什么?](#🍱 一、Batch Size 是什么?)
- [🍱 二、小 Batch 和大 Batch 的本质差异](#🍱 二、小 Batch 和大 Batch 的本质差异)
-
- [1)小 Batch:一次端几盘菜,主厨反应灵敏](#1)小 Batch:一次端几盘菜,主厨反应灵敏)
- [2)大 Batch:一次端一大车菜,主厨更新稳定](#2)大 Batch:一次端一大车菜,主厨更新稳定)
- [🎯 三、Batch Size 和"泛化能力"的关系](#🎯 三、Batch Size 和“泛化能力”的关系)
- [🚀 四、Batch Size 与学习率的关系](#🚀 四、Batch Size 与学习率的关系)
- [🔧 五、工程实践:如何选择 Batch Size?](#🔧 五、工程实践:如何选择 Batch Size?)
-
- [情况 1:显存有限(3GB~8GB)](#情况 1:显存有限(3GB~8GB))
- [情况 2:中等显卡(8GB~24GB)](#情况 2:中等显卡(8GB~24GB))
- [情况 3:多 GPU(单机多卡)](#情况 3:多 GPU(单机多卡))
- [情况 4:大模型(Transformers、ViT)](#情况 4:大模型(Transformers、ViT))
- [🔍 六、PyTorch:直接可用的代码示例](#🔍 六、PyTorch:直接可用的代码示例)
-
- [① 梯度累积实现大 batch](#① 梯度累积实现大 batch)
- [② 查 GPU 最佳 batch size(常用小技巧)](#② 查 GPU 最佳 batch size(常用小技巧))
- [📌 七、Batch Size 的"最佳总结"](#📌 七、Batch Size 的“最佳总结”)
- [🔜 下一篇](#🔜 下一篇)
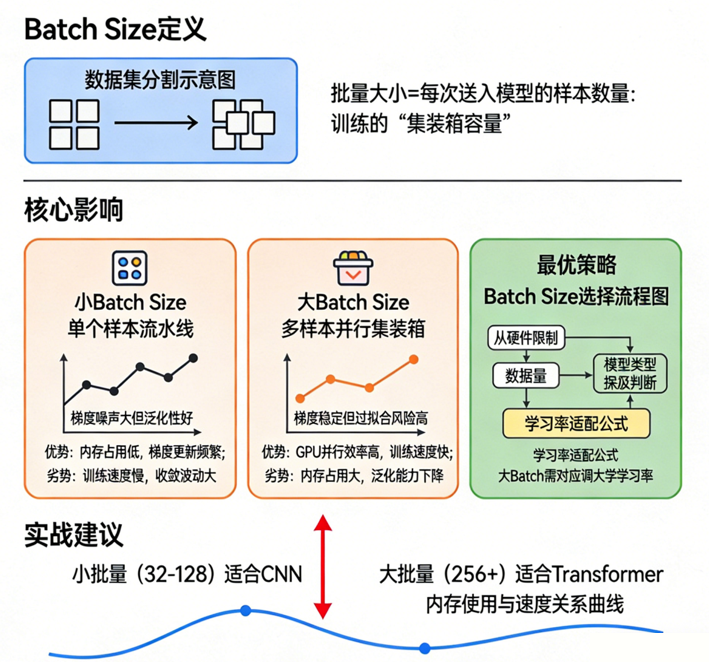
🍱 一、Batch Size 是什么?
一句话:
每次计算梯度时使用的样本数量。
如果你的 batch size = 32,意思是:
- 一次 forward pass 用 32 张图
- 一次 backward pass 用 32 张图的平均梯度
- 然后更新一次参数
只更新一次,就是一个 iteration 。
一整轮跑完整个 dataset = 一次 epoch。
我们可以把训练想象成"餐厅后厨":
- 数据集是食材
- 模型是主厨
- batch 是每次端进后厨的"原料一盘盘"
🍱 二、小 Batch 和大 Batch 的本质差异
为了让概念更直观,我们继续用餐厅的比喻。
1)小 Batch:一次端几盘菜,主厨反应灵敏
特点:
- 噪声大,每批菜的味道(样本分布)不稳定
- 主厨因此调整更频繁、更敏感
- 更容易走到更"自然"的解决方案
- 常常带来更好的泛化能力
现实场景类比:
厨房每次只送两三种原料,主厨边做边调整,很接地气。
小 batch 的模型训练过程:
- loss 波动较大
- 训练路径不稳定,但可能找到更好的谷底
- 收敛较慢
- 对学习率敏感
这是很多论文提到的:
小 batch 更容易找到更"尖锐但泛化好"的最优
当然代价是:速度慢。
2)大 Batch:一次端一大车菜,主厨更新稳定
特点:
- 梯度更干净、更"均值化"
- 每一次更新更"正确"
- 可以使用更大的学习率
- 并行效率更高
现实类比:
厨房准备一个巨大餐车,一次全送过来,非常规范、完整。
大 batch 的行为:
- loss 曲线更平滑
- 可以用更大的 LR(线性缩放)
- 训练更快
- 但更容易卡在"坏的谷底"
- 泛化能力可能下降
这也带来一个重要现象:
大 batch 训练想让模型表现不变,必须再加"正则手段"补偿。
例如:
L2 正则、数据增强、更长 warmup、梯度噪声等。
🎯 三、Batch Size 和"泛化能力"的关系
最经典的研究来自 Facebook AI(SGD Generalization)。
简化一下:
- 小 batch 的噪声帮助模型跳出糟糕的局部极小
- 大 batch 更像"确定性梯度",容易陷入尖锐 minima
- 尖锐 minima 泛化能力差
- 平坦 minima 泛化能力好
举个生活化类比:
学习一种技能时,如果你每次练习都遇到一点"波动",
你会更全面理解技能本质;
如果你的练习环境完全稳定,反而可能理解不到位。
深度学习模型也是一样。
🚀 四、Batch Size 与学习率的关系
这一条是工程上必须掌握的黄金法则:
Batch size 越大,学习率越大。
已有理论(LARS、LAMB)证明:
- 当 batch × k
- 学习率理论上可以乘 k
举例:
batch = 256 时 LR = 0.1
batch = 1024 时 LR ≈ 0.4
batch = 4096 时 LR ≈ 1.6
这就是为什么:
- ViT 训练用 batch 4096
- GPT 训练 batch=数万
- 但是学习率超大,且一定要 warmup
如果不调整学习率,大 batch 会变得"训练不动"。
🔧 五、工程实践:如何选择 Batch Size?
这里给你一套"深度学习工程师通用策略"。
情况 1:显存有限(3GB~8GB)
建议:
- batch 8 / 16
- 用 Gradient Accumulation(梯度累积)
- 学习率从 1e-3 开始调
如果显存紧张,小 batch 没问题,性能不会损失很多。
情况 2:中等显卡(8GB~24GB)
一般 CNN 分类训练:
- batch 32~128 区间
- 更大的 batch 用 AMP (自动混合精度)
情况 3:多 GPU(单机多卡)
建议:
- 单卡 batch 固定,例如 64
- 总 batch = 单卡 batch × GPU 数量
- 学习率按线性规则扩大
例如 8 卡 × 64 = 总 batch 512
则 LR = base_lr × 8
情况 4:大模型(Transformers、ViT)
标配:
- batch 至少 512~4096
- 使用 Warmup + Cosine
- 使用 AdamW
- 学习率线性提升
- 必须 AMP
🔍 六、PyTorch:直接可用的代码示例
① 梯度累积实现大 batch
python
accum_steps = 4 # 等效 batch 扩大 4 倍
for i, (x, y) in enumerate(dataloader):
pred = model(x)
loss = criterion(pred, y)
loss = loss / accum_steps
loss.backward()
if (i + 1) % accum_steps == 0:
optimizer.step()
optimizer.zero_grad()② 查 GPU 最佳 batch size(常用小技巧)
python
for b in [8, 16, 32, 64, 128, 256]:
try:
x = torch.randn(b, 3, 224, 224).cuda()
model(x)
print("OK batch", b)
except:
print("Failed batch", b)非常实用,用来快速确定显存极限。
📌 七、Batch Size 的"最佳总结"
最后用一句话总结这一篇:
小 batch 泛化好但慢;大 batch 高效但可能掉点。
最佳做法是在显存允许情况下尽量大 batch,然后用正则和学习率技巧补偿。
具体来说:
- 不要盲信"大 batch 一定更好"
- 小 batch 对泛化更友好
- batch 与 LR 一定要联调
- batch 越大,学习率越大
- batch 太小会导致训练不稳定
- batch 太大会导致模型过度拟合数据分布
- AMP + 梯度累积是常用组合拳
如果你能灵活掌握 batch size,那么你真正掌握了训练稳定性的半壁江山。
🔜 下一篇
我们将继续进入训练工程重点话题:
《第 19 篇:过拟合、本质、诊断与解决手段(dropout、正则化、早停)》