大模型只是通用推理引擎,私有知识库才是垂直场景 AI 应用的护城河。这句话我在之前的文章里也提过,这个隐患识别项目很好地验证了这个观点。
起因是半个月前知识星球里收到一个成员的提问。对方在开发安全巡查类的小程序,核心功能是巡查人员拍照现场隐患后,系统自动识别隐患内容、给出整改建议、并引用对应的法律法规。他已经封装了大模型 API 在后端做识别,Prompt 也调了很多版,但测试下来识别的效果和速度都达不到预期。但注意到市面上某款 AI 隐患排查小程序,速度快、精准度高,不知道人家是怎么做到的。

我搜了这个小程序试了下,给的判断是大概率不是靠纯 Prompt 或者 YOLO 目标检测,而是"轻量多模态模型 + 私有知识库 + 模板填充"的组合拳。从商业化的角度,这类应用的核心壁垒不在使用了什么特殊的大模型,而是一套覆盖面足够广的隐患分类体系,以及一个整理好的"法规条款-整改建议"知识库。
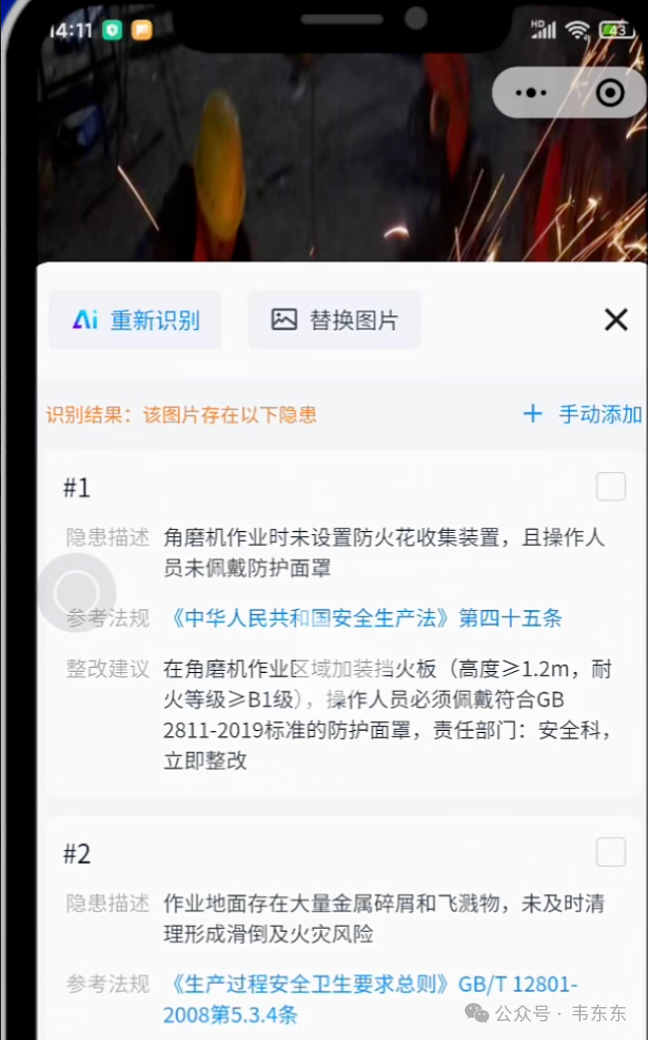
后来星球这位盆友提供了一些历史巡查记录文档和隐患照片样本,我花了半天时间做了下 POC 验证,这其中有些小的工程经验,拿出来和各位说道说道。
这篇试图说清楚:
如何从非结构化的 Word 巡检报告中提取结构化数据、如何构建"隐患描述-法规条款-整改建议"三元组的私有知识库、如何用向量检索让隐患描述精准匹配知识库、如何在 Mac 本地和云端 GPU 两种环境下做性能调优,以及这套"小模型 + 大知识"的技术路线在垂直场景落地的可行性边界。
以下,enjoy:
1、数据工程:非结构化文档的结构化改造
做知识库类的项目,70% 的工作量在数据治理,而不是模型的各种调参,这个项目也不例外。不过在动手之前,有个问题值得先想清楚:这套系统的知识库数据应该从哪里来?
从应用场景来看,目标是开发一个安全巡查小程序,用户现场拍照后系统自动给出隐患分析和法规引用。未来新增的数据当然是用户上传的照片,但系统冷启动阶段必须要有一套种子知识库,包含常见隐患类型、对应的法规条款、标准整改建议。这些内容不可能凭空生成,只能从历史数据里提炼。
那历史数据会以什么形式存在?大致有几种情况:
第一种是现成的结构化数据库或 Excel 表格。这是最理想的情况,字段清晰、格式统一,直接导入就能用。但实际上,大多数中小企业的安全巡检场景还没走到这一步,数据治理的基础设施压根不存在。
第二种是第三方平台的数据导出。如果客户之前用过某款巡检 SaaS,可能有历史记录可以导出。但这类数据通常只有基础字段(时间、地点、描述),法规引用和整改建议往往缺失或不规范。
第三种是散落在各处的非结构化文档。这是最常见的情况------Word 报告、PDF 扫描件、甚至纸质记录的照片。格式五花八门,但信息密度最高,因为这些是真正经过专业工程师审核输出的正式材料。
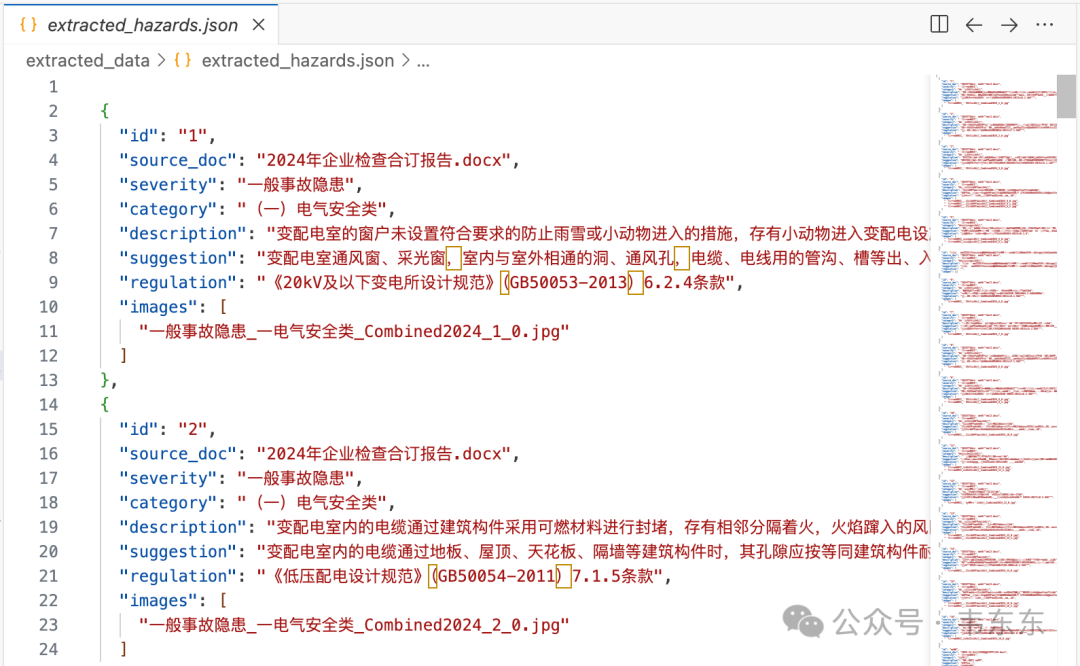
这个项目做 poc 拿到的就是第三种。对方提供了几份 Word 格式的《企业生产现场检查记录》,记录了巡检人员在现场发现的各类隐患。文档本身的结构看似规整:标准的表格、清晰的列定义(序号/隐患描述/现场照片/整改建议/法规依据),但实际上手解析才发现坑不少。

1.1、 原始文档的复杂性
这类巡检报告在视觉上是层级化的树形结构:最外层是**"严重程度"** (一般事故隐患 / 重大事故隐患),第二层是**"隐患分类"(电气安全类 / 危险化学品安全类 / 机械安全类等),最内层才是具体的隐患条目**。但在 Word 的数据结构里,这些层级被压缩成了一个二维表格,分类标题用合并单元格横跨整行来表示。
除了层级嵌套,还有几个技术难点:
**1、合并单元格。**分类标题(如"(一)电气安全类")会横跨整行,用 python-docx 遍历时会产生大量空单元格和重复数据。
**2、表格内嵌图片。**每条隐患都附带现场照片,直接嵌入在单元格里。这是 Word 解析的经典难题,高层 API 支持很弱。
**3、法规引用不完整。**依据列只有"书名号+条款号",比如《低压配电设计规范》6.2.4 条,但没有法规的具体内容------这个问题后面知识库增补环节会专门处理。
1.2、 智能层级识别
第一个要解决的问题是如何从扁平的表格行里还原出"严重程度 → 分类 → 隐患"的三层树形结构?
我的做法是用一个简单的状态机。脚本在逐行扫描表格时,维护两个状态指针:current_severity(当前严重程度)和 current_category(当前分类)。
python
# 状态机:维护当前层级
current_severity = "一般事故隐患"
current_category = "未分类"
for row in table.rows:
row_text = "".join(c.text for c in row.cells)
# 严重程度切换
if "重大事故隐患" in row_text:
current_severity = "重大事故隐患"
continue
if "一般事故隐患" in row_text:
current_severity = "一般事故隐患"
continue
# 分类识别:正则 + 启发式 Fallback
cat_match = re.search(r'^[(\(][一二三四五六七八九十]+[)\)].*类', text_c0)
if not cat_match and "安全类" in text_c0 and len(text_c0) < 20:
current_category = text_c0 # 启发式匹配
continue严重程度的切换比较简单,只需要检测行文本里是否包含"一般事故隐患"或"重大事故隐患"这类关键词。一旦命中,就更新 current_severity 指针,后续所有隐患条目都会继承这个值,直到遇到下一个切换点。
分类的识别稍微复杂一些。规范的文档会用"(一)电气安全类"这种带序号的格式,可以用正则 ^(\\(一二三四五六七八九十+)\\).*类 精确匹配。但实际文档里有些分类标题没有序号,只有"消防安全类"这样的纯文本。对于这种情况,我加了一个启发式的 Fallback:如果某一行文本长度小于 20 个字符,且包含"安全类"关键词,就判定为分类标题。
这个逻辑的核心思想其实也是模拟人眼阅读报告的认知过程,看到大标题就知道后面的内容属于这个类别,直到遇到下一个大标题。
1.3、 数据行清洗与排噪
层级识别解决了内容归属问题,但表格里还有大量噪音需要过滤。
python
# 数据行判定逻辑
description = cells[1].text.strip()
# 跳过表头
if "现场隐患描述" in description:
continue
# 跳过合并单元格导致的重复(分类标题穿透)
if description == current_category:
continue
# 跳过空行
if not description:
continue
# 通过以上检查的才是有效数据行**1、表头过滤。**表格第一行通常是"序号 / 现场隐患描述 / 现场隐患照片 / 整改建议 / 依据"这样的静态表头,需要自动识别并跳过。
**2、合并单元格穿透。**由于分类标题用合并单元格横跨整行,遍历时这一行的每个单元格都会返回相同的文本。如果不处理,同一个分类标题会被当成多条"隐患"重复入库。解决方法是对比"当前行描述文本"和"当前分类标题",如果完全一致就跳过。
**3、空行和脏数据。**有些行只有序号没有实际内容,或者全是空白,这些都要过滤掉。
1.4、 图片深度提取
图片提取算是整个数据工程里技术含量最高的部分。
python-docx 提供了 run.inline_shapes 来访问图片,但这个 API 在表格嵌套场景下极不稳定,经常漏图或者返回错误的引用。更麻烦的是,Word 里的图片其实是以"关系引用"的方式存储的,文档 XML 里只有一个 ID,真正的图片二进制数据藏在 .docx 压缩包的 media 目录里。
最终的解决方案是绕过高层封装,直接操作 OpenXML 底层:
python
# OpenXML 命名空间
NS = {
'a': 'http://schemas.openxmlformats.org/drawingml/2006/main',
'r': 'http://schemas.openxmlformats.org/officeDocument/2006/relationships',
}
def get_images_from_cell(cell, doc):
images = []
# XPath 定位图片引用节点
blips = cell._element.xpath('.//a:blip')
for blip in blips:
# 获取 Relation ID
rId = blip.get(f"{{{NS['r']}}}embed")
if rId and rId in doc.part.related_parts:
# 通过 Relation ID 反查图片 Part,读取二进制流
images.append(doc.part.related_parts[rId].blob)
return images用 lxml 的 XPath 语法在单元格的 XML 子树里定位图片引用节点(.//a:blip)。这个节点的 r:embed 属性值是一个 Relation ID,指向文档包内部的真实图片资源。
通过 document.part.related_parts 字典,用 Relation ID 反查到对应的图片 Part 对象,然后直接读取 .blob 属性拿到原始二进制流。
这种方法的好处是导出的图片和 Word 里嵌入的原图完全一致,没有任何压缩损失。
1.5、 输出规范与设计考量
数据清洗完成后,输出分为两部分:结构化 JSON 和现场照片。
图片的命名采用语义化策略:{严重程度}{隐患分类}{来源文档脱敏标识}{隐患 ID}{索引}.jpg。比如 一般事故隐患 _ 电气安全类 _AnhuiXX2025_1_0.jpg。这样设计的好处是,脱离 JSON 数据后,单看文件名也能快速判断这张图属于什么类型的隐患,方便人工抽检核查。
JSON 的结构则是为后续知识库构建服务的。每条隐患记录包含:
python
{
"id": "hzd_01",
"severity": "一般事故隐患",
"category": "电气安全类",
"description": "变配电室的窗户未设置符合要求的防止雨雪或小动物进入的措施...",
"regulation_ref": "《低压配电设计规范》(GB50053-2011) 6.2.4条",
"suggestion": "变配电室窗户应设置防止雨雪和小动物进入的设施...",
"images": ["一般事故隐患_电气安全类_AnhuiXX2025_1_0.jpg"]
}这个结构里,description + category 后续会拼接成 embedding_source_text,用于构建向量索引;regulation_ref 会在知识库增补环节联网查询法规全文;suggestion 独立存储,支持模板化输出。
1.6、 数据成果
最终从几份原始 Word 文档中,提取出几十条高价值的结构化隐患数据,覆盖电气、消防、机械、危化、特种设备等十几个细分领域。同步导出的现场照片全部采用语义化命名,存放在 extracted_data/images/ 目录下。这一步也是给后续构建"视觉理解 Prompt"和"知识库检索"打下了数据基础。
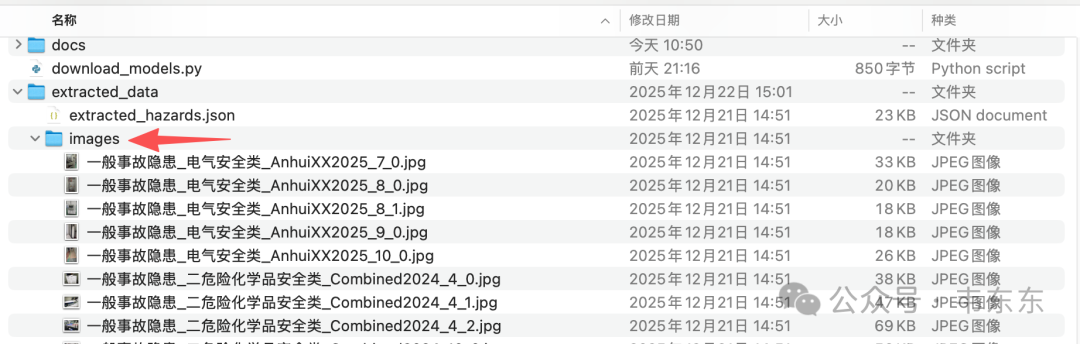
2、知识库构建:从宽表到星型模式
数据清洗完成后,拿到了一份"宽表"(可以理解为一个 Excel 表格,每一行是一条隐患记录,每一列是一个字段:描述、法规引用、整改建议等,所有信息都塞在同一张表里)。看起来已经可以直接用了,但如果仔细想一下后续的 RAG 流程,会发现这个结构有问题。
2.1、 为什么不能直接用宽表?
假设用户上传一张配电柜的照片,VLM 识别出"柜门没接地"。接下来系统需要做两件事:1)找到知识库里语义最接近的标准隐患描述;2)返回对应的法规条款和整改建议。
如果用宽表做向量检索,会遇到几个问题。
首先是数据冗余。同一条法规(比如 GB50054-2011 第 7.1.5 条)可能被多条隐患引用。如果每条隐患都存一份法规全文,同样的内容会重复存储很多遍,后续想更新某条法规的内容,还得找出所有引用它的记录逐个修改,维护成本很高。
其次是检索精度受影响。向量检索的原理是把文本转成向量,然后计算语义相似度。如果每条记录又是描述、又是法规、又是建议,内容混杂在一起,向量检索时噪音很大,很容易"答非所问"。理想情况是:检索的输入只包含"隐患特征描述"这一个干净的语义单元。
最后是可扩展性差。宽表结构很难支持复杂查询。比如未来想实现"按法规标准号检索所有相关隐患"或"按分类筛选",就得遍历整张表逐行匹配,效率很低。
2.2、 星型模式设计
解决方案是把"一张大宽表"拆成"多张小表",各司其职,用 ID 关联。这种设计在数据仓库领域叫做星型模式 (Star Schema),中心是一张事实表(记录核心业务数据),周围是多张维度表(存储可复用的参考信息)。
具体到这个项目,我拆成了三张表:
| 表名 | 角色 | 核心字段 | 说明 |
|---|---|---|---|
| hazard_index.json | 事实表(核心索引) | hazard_id, category, description, embedding_text | 每条隐患一条记录,是向量检索的"路标" |
| regulations.json | 维度表(法规库) | id, standard_code, full_text, content | 去重后的法规条款,被多条隐患共享引用 |
| suggestions.json | 维度表(建议库) | id, content | 去重后的整改建议话术 |
核心索引表里不直接存法规和建议的全文,只存引用 ID(比如 regulation_ref: "reg_3")。需要完整信息时,再根据 ID 去法规表和建议表里查。

这样设计的好处是:
**1、去重:**同一条法规只存一份,几十条隐患共用 GB50054-2011 的内容,实际只存一条记录
**2、易维护:**法规内容更新了,只需要改法规表里的一条记录,所有引用它的隐患自动生效
3、检索干净: 向量化只针对 embedding_source_text字段,不会被法规、建议的文本干扰
2.3、 核心代码逻辑
构建知识库的脚本核心逻辑如下:
python
def build_knowledge_base():
# 1. 法规去重:用 MD5 哈希作为去重键
regulations_map = {} # key: hash(full_text), value: {id, content, ...}
for item in raw_hazards:
reg_text = item.get("regulation", "")
if reg_text:
reg_hash = hashlib.md5(reg_text.encode()).hexdigest()
if reg_hash not in regulations_map:
# 正则提取标准号,如 GB50054-2011
standard_code = extract_regulation_code(reg_text)
regulations_map[reg_hash] = {
"id": f"reg_{len(regulations_map) + 1}",
"full_text": reg_text,
"standard_code": standard_code
}
# 2. 构建隐患索引,只存引用 ID
hazard_index.append({
"hazard_id": f"hzd_{n}",
"category": item["category"],
"standard_description": item["description"],
"regulation_ref": regulations_map[reg_hash]["id"], # 只存ID
"suggestion_ref": suggestions_map[sugg_hash]["id"],
# 这个字段是后续向量化的输入源
"embedding_source_text": f"{category}: {description}"
})关键点在于 embedding_source_text 字段的设计。它把"分类"和"描述"拼接在一起,形成一个语义完整的短文本。比如:电气安全类: 配电柜柜门应做防静电跨接保护这个文本后续会被 Embedding 模型转成向量,用于语义检索。把分类信息加进去,是为了在检索时能区分"电气类的漏电"和"消防类的漏电"这种不同场景。
2.4、 最终产出的数据结构
隐患索引 (hazard_index.json):
python
{
"hazard_id": "hzd_1",
"category": "电气安全类",
"standard_description": "装有电器的配电柜的箱门与柜体之间无导线连接保护...",
"regulation_ref": "reg_3",
"suggestion_ref": "sug_3",
"embedding_source_text": "电气安全类: 装有电器的配电柜的箱门与柜体之间无导线连接保护..."
}法规库 (regulations.json):
python
{
"id": "reg_3",
"full_text": "《建筑电气工程施工质量验收规范》(GB50303-2015) 5.1.1条款",
"standard_code": "GB50303-2015",
"content": "柜、台、箱的金属框架及基础型钢应与保护导体可靠连接;对于装有电器的可开启门,门和金属框架的接地端子间应选用截面积不小于4mm²的黄绿色绝缘铜芯软导线连接,并应有标识。"
}注意 content 字段------这是法规的具体条文内容。原始文档里只有"书名号+条款号"的引用,没有正文。这就引出了下一个问题:法规全文从哪来?
2.5、 法规联网增补
原始数据里的法规字段长这样:《低压配电设计规范》7.1.5 条。只有条款号,没有具体内容。这会导致一个严重问题:当 VLM 识别出"电缆穿墙没封堵"这个隐患时,知识库能匹配到对应的法规条款,但系统给用户的回复只能是"违反了 GB50054 第 7.1.5 条"------用户还是不知道这条法规具体规定了什么。
更深层的问题是:如果法规库里只有条款号,向量检索时语义匹配会非常弱。因为用户描述的是"防火泥"、"封堵"这样的现场特征,而法规文本里根本没出现这些词,只有一个干巴巴的条款编号。
POC 阶段的实际做法
这里需要如实交代一下:POC 阶段为了快速跑通流程,法规增补并没有做成全自动化的流水线。实际的做法是:
**1、大模型辅助检索:**把每条法规的标准号和条款号提取出来,用搜索工具查询"GB50054-2011 7.1.5 条文内容",大模型调用联网搜索工具返回找到的相关内容
**2、人工抽查核验:**搜索结果不一定准确,我又人工抽查核对了部分结果是否真的是这个条款的原文。有些法规是收费标准,网上只有摘要或解读,需要判断是否可用
**3、硬编码填充:**核验通过的内容直接写进脚本里的一个字典,然后批量回填到 JSON 文件
代码里是这样的:
python
# 核验后的法规内容,直接硬编码进脚本
fetched_content = {
"GB50054-2011_7.1.5": "电缆通过地板、屋顶、天花板、隔墙等建筑构件时,其孔隙应按等同建筑构件耐火等级的要求进行封堵。",
"GB50053-2013_6.2.4": "变压器室、配电室...应设置防止雨、雪和蛇、鼠等小动物从采光窗、通风窗、门、电缆沟等处进入室内的设施。",
# ... 更多条目
}这种做法看起来很作坊,但对于 POC 验证来说其实也够用了。
真实场景的大规模增补怎么做?
如果是生产环境需要处理成百上千条法规,这套流程就需要工程化改造:
**1、接入标准库 API:**部分行业标准(如 GB 强制性国标)有官方数据库或第三方 API 可以查询全文,可以直接对接
**2、LLM + RAG 辅助:**对于没有 API 的法规,可以用大模型 + 联网搜索自动检索,然后用另一个大模型做内容提取和格式化
**3、置信度标注:**自动检索的结果附带置信度评分。高置信度的直接入库,低置信度的进入人工复核队列
**4、众包核验:**把待核验的法规条目分发给外部团队,在线标注"正确/错误/需修改"
本质上,法规增补也是一个数据治理的活儿。自动化只能解决"量"的问题,"质"的把控最终还是需要人工介入。POC 阶段选择直接硬编码,就是用最少的工程投入验证端到端流程是否可行。POC 阶段增补了几十条高频法规,覆盖了大部分常见隐患场景。举几个例子:
| 标准号 | 条款 | 增补内容(摘要) |
|---|---|---|
| GB50054 | 7.1.5 | 电缆通过建筑构件时,孔隙应按等同耐火等级进行防火封堵 |
| GB50053 | 6.2.4 | 变配电室窗户应设置防止雨雪和小动物(蛇、鼠)进入的设施 |
| GB50303 | 5.1.1 | 柜门和金属框架间应选用截面积不小于 4mm² 的黄绿色软导线连接 |
| GB50016 | 6.4.11 | 疏散出口不应使用卷帘门、旋转门,应采用平开门 |
这一步显著提升了知识库的含金量。系统不仅知道犯了哪条法,还能展示出对应的具体法律规定,为生成精准的整改建议提供了文本依据。
3、向量检索的实现过程
知识库建好了,下一个问题是怎么检索?
3.1、 为什么不能用关键词匹配?
先看一个例子。知识库里有这么一条标准隐患描述:
"配电柜门与柜体之间无导线连接保护",但实际使用时,VLM 看图后输出的分析不会是这么规范的表述,可能是:"箱门没有跨接线"、 "柜门没接地"、"门和柜子断开了"。
这三种说法和知识库里的标准描述,意思完全一样,但字面上几乎没有重叠。如果用传统的关键词匹配(比如 SQL 的 LIKE '%跨接%'),上面三种变体全都匹配不到。这就是向量检索要解决的问题:不管用户怎么表述,只要语义相近,就能匹配到正确的知识条目。
3.2、 技术栈选型
Embedding 模型选择:BGE-small-zh
选嵌入模型时主要考虑三个因素:中文支持方面,工业隐患场景的描述全是中文术语,需要对中文语义理解足够好;轻量化上,POC 阶段在本地 Mac(m4 pro, 24g) 上跑;检索效果需要在中文语义检索的公开榜单上排名靠前。
BAAI/bge-small-zh-v1.5在 MTEB 中文榜单上表现优异,而且模型文件只有几百 MB,推理速度很快。
向量索引选择:FAISS
索引引擎选了 Facebook 开源的 FAISS,Python 接口友好,几行代码就能构建索引和检索。虽然 POC 只有几十条数据,但 FAISS 支持亿级规模,未来扩展无压力
对于小规模数据,直接用 IndexFlatIP(精确内积检索)就够了。如果数据量上去,可以换成 IndexIVFFlat 加速。
3.3、 核心代码逻辑
向量索引构建的脚本逻辑如下:
python
from sentence_transformers import SentenceTransformer
import faiss
def build_vector_index():
# 1. 加载 Embedding 模型
model = SentenceTransformer("BAAI/bge-small-zh-v1.5")
# 2. 从知识库读取待向量化的文本
sentences = []
for item in hazard_index:
# embedding_source_text = "电气安全类: 配电柜柜门应做防静电跨接保护"
text = item.get("embedding_source_text", "")
sentences.append(text)
# 3. 批量向量化(自动 normalize)
embeddings = model.encode(sentences, normalize_embeddings=True)
# 4. 构建 FAISS 索引
dimension = embeddings.shape[1] # 512维
index = faiss.IndexFlatIP(dimension) # 内积 = 余弦相似度(因为已归一化)
index.add(embeddings)
# 5. 保存索引和 ID 映射
faiss.write_index(index, "vector_index.faiss")
# vector_id_map.json: [hzd_1, hzd_2, ...] 用于反查关键点解释:normalize_embeddings=True:把向量归一化到单位长度,这样内积(Inner Product)就等于余弦相似度,方便后续计算
IndexFlatIP:精确检索,暴力计算所有向量的相似度,适合小数据量
vector_id_map.json:FAISS 返回的是向量在索引中的位置(0, 1, 2...),需要一个映射表反查到实际的 hazard_id
3.4、 踩坑记录:HuggingFace 联网超时
这个坑花了不少时间排查。脚本测试时,偶尔整体耗时高达 30s - 60s,但向量检索本身明明只需要零点几秒。日志显示 SentenceTransformer 加载模型时卡住了很久,输出类似 Retrying (Retry 1/5)... 的警告。
排查下来发现是因为sentence-transformers 底层用的是 HuggingFace 的 transformers 库,默认行为是每次加载模型时尝试连接 HuggingFace Hub 检查是否有更新版本。国内网络环境访问 HuggingFace 不稳定,超时后会自动重试,重试 5 次就是几十秒。
解决方案也很简单,就是强制离线模式,禁止任何联网检查。
python
import os
os.environ["HF_HUB_OFFLINE"] = "1" # 必须在 import transformers 之前设置加上这行之后,模型加载时间从 23s 骤降到 0.1s 以内。
3.5、 检索效果验证
RAG 系统的评测通常分成两个阶段:
**1、检索阶段(Retrieval):**给定一个 query,能否召回正确的 Top-K 文档?常用指标是 Recall@K、MRR 等;
**2、生成阶段(Generation):**给定检索到的上下文,生成的答案是否准确?
这个项目的 RAG 流程中,答案生成是模板填充(直接从知识库提取法规条款和整改建议),不涉及 LLM 自由生成,因此评测只需要关注检索阶段的准确率。为了客观地评估检索效果,我构建了一个包含 24 组测试用例、96 个查询的黄金测试集。每个知识库条目配 4 个不同表述的 query 变体,模拟 VLM 可能输出的各种"白话"描述。
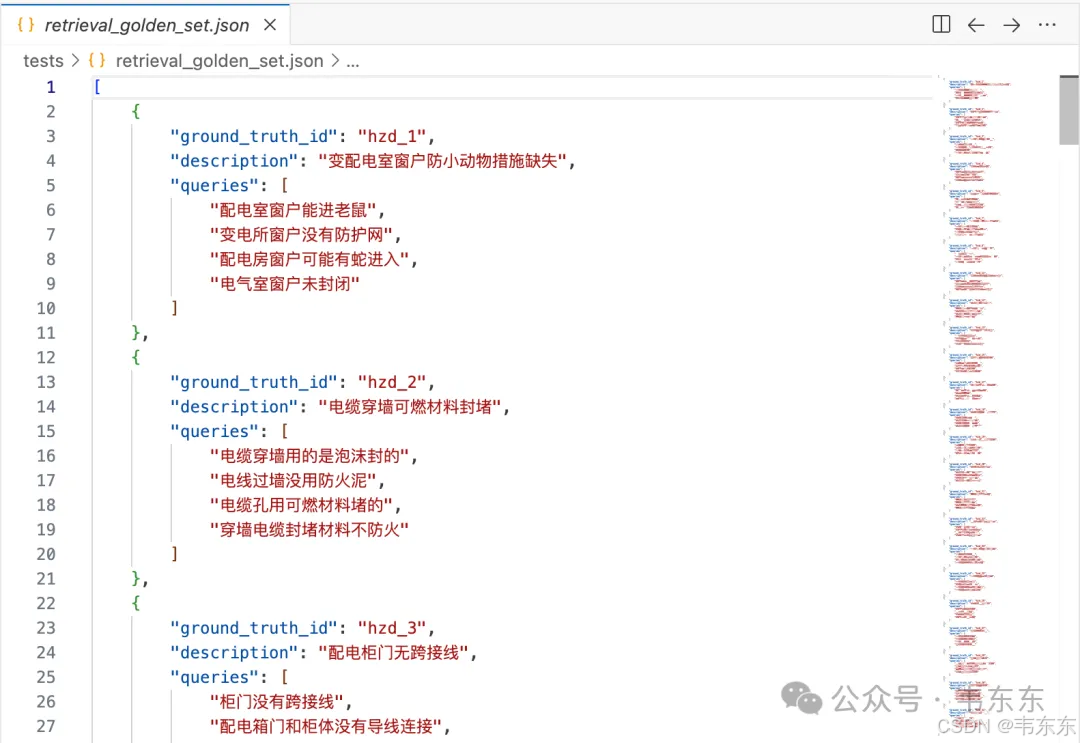
测试集示例:
python
{
"ground_truth_id": "hzd_24",
"description": "配电柜门无跨接保护",
"queries": [
"柜门没有接地线",
"配电柜门缺少跨接",
"电柜门没有接地保护",
"配电箱门静电跨接缺失"
]
}跑了一遍评测脚本,结果如下:
| 指标 | 结果 |
|---|---|
| 总查询数 | 96 |
| Recall@1 | 76.04% (73/96) |
| Recall@3 | 93.75% (90/96) |
| MRR | 0.8420 |
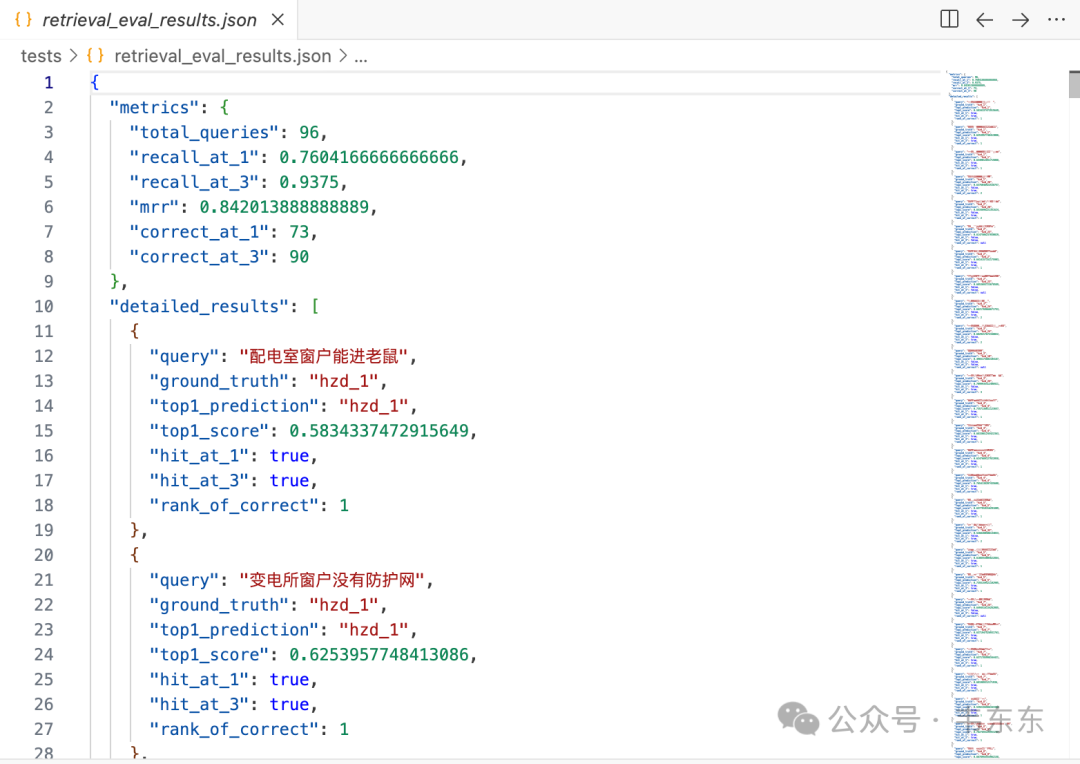
结果解读:
Recall@1 = 76%:大约四分之三的 query 能直接命中正确答案,还不错但有提升空间
Recall@3 = 94%:如果放宽到 Top-3,召回率就非常高了。说明正确答案基本都在前三名
MRR = 0.84:平均倒数排名接近 1,说明即使没命中 Top-1,正确答案也往往在 Top-2
错误分析
仔细看了 23 个 Top-1 未命中的案例,发现几个典型问题:
1、知识库内容相似导致混淆
hzd_3 和 hzd_24 都是关于"配电柜门跨接"的描述:
python
hzd_3:"装有电器的配电柜的箱门与柜体之间无导线连接保护..."
hzd_24:"配电柜柜门应做防静电跨接保护"两者语义高度接近,向量检索容易混淆。实际上这两条说的是同一类问题,合并知识库条目可能是更好的选择。
2、描述角度不同导致漏召回
python
hzd_2(电缆封堵用可燃材料)和 hzd_23(线管桥架穿墙未封堵)被混淆:
query:"电线过墙没用防火泥" → 匹配到 hzd_23(桥架封堵)
期望:hzd_2(电缆封堵可燃材料)两者都涉及"穿墙封堵",但一个强调"材料可燃",一个强调"没封堵"。向量模型捕捉到了"封堵"这个核心语义,但区分不了细微差异。
3、query 过于简短
"箱门没接地" 这种极短描述被匹配到 hzd_18(消火栓箱门),而不是 hzd_3(配电柜箱门)。因为缺乏"配电"这个关键上下文,模型误把"箱门"理解成了消火栓箱。
调优方向
根据错误分析,有几个可能的优化方向:
**1、知识库去重:**把语义高度相似的条目合并,减少"假阴性";
2、丰富检索文本: 在 embedding_source_text 里加入更多区分性关键词;
**3、Rerank:**在 Top-K 结果基础上,用 Cross-Encoder 做精排
不过对于 POC 来说,Recall@3 已经 94% 了,说明向量检索基本可用。后续如果要生产化,再做细粒度调优。
关于评测标准的说明
需要说明的是,这个测试集的评测标准是偏严格的。
测试集里有些 query 故意设计得比较短(如"箱门没接地"只有 5 个字),这是在测试"最差情况"。真实场景中 VLM 输出通常更长、更具体,比如"配电柜柜门和柜体之间没有跨接线"。所以 76% 的 Recall@1 是偏保守的估计,实际使用时应该更高。
另外,这个 POC 只用了纯向量检索,没有加入关键词检索(BM25)做混合。主要考虑是知识库只有 32 条,向量检索的召回已经足够准确;BGE 模型对中文工业术语的语义理解不错,"跨接线"和"接地保护"这种同义表述纯向量就能匹配上;混合检索需要额外维护 BM25 索引和调权重,POC 阶段没必要。
什么时候需要混合检索?如果用户 query 里有明确的标准号(如"GB50054 7.1.5"),关键词精确匹配效果更好;或者知识库规模上去后(比如上千条),纯向量可能出现语义漂移,关键词可以做兜底。目前 POC 验证阶段,纯向量检索已经能满足需求。
4、端到端流程测试
知识库和向量索引都准备好了,接下来要验证整个系统能不能跑通。
4.1、 核心测试逻辑
整个 POC 的工作流程可以大致分为:
**1、VLM:**负责看图描述隐患特征。Prompt 设计成只让它描述物理现象,不引用任何法规。比如看到一张配电室的照片,输出"配电室窗户没有防护网"就够了。
**2、RAG:**负责查阅索引。拿到 VLM 的描述后,把它转成向量,在 FAISS 里找语义最接近的标准隐患条目,然后把关联的法规条款和整改建议一并返回。
**3、最终报告:**把 VLM 的观察、知识库的法规、建议组合成一份专业的隐患报告。
python
用户上传图片
↓
VLM 分析图片 → 输出:"场景: 配电室 | 隐患: 窗户开启"
↓
向量检索 → 匹配到: "变配电室窗户应设置防止小动物进入的设施"
↓
组装报告 → 法规: GB50053-2013 6.2.4 + 整改建议4.2、 解决了什么痛点?
传统 Image-to-Text 方案最大的问题是 LLM 幻觉。你让大模型直接输出法规条款,它很容易编造一个看起来像的但实际不存在的规范。这套方案的优势在于 VLM 只需要当好现场观察员,专业判断交给知识库。
VLM 只负责识别"看到了什么"(窗户开着、气瓶没固定,地垫破损),法规和建议是从知识库精确检索的,不是生成的,准确率接近 100%,即使用小模型(2B),只要能准确描述现象,系统就能输出正确的法规。
这验证了 "Small Model + Big Knowledge" 路线在端侧落地的可行性。
4.3、 本地测试:Ollama 预热
在正式测试之前,需要先预热 Ollama 模型,避免冷启动延迟:
python
# 预热 2B 模型
ollama run qwen3-vl:2b "hi"
# 预热 8B 模型(如果要测试)
ollama run qwen3-vl:8b "hi"预热后模型会常驻内存,后续请求不需要重新加载。
4.4、 本地测试效果对比(Mac M4 Pro 24G)
我在本地用三张测试图片分别测试了 2B 和 8B 模型(均为 Q4 量化版本):
测试图片 1:气瓶存放
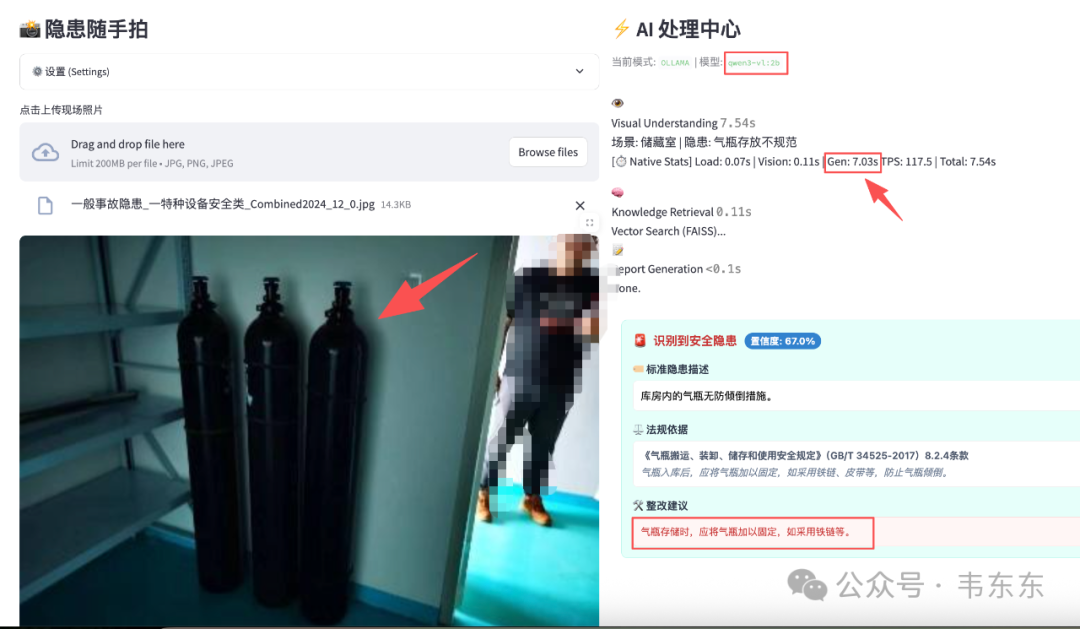
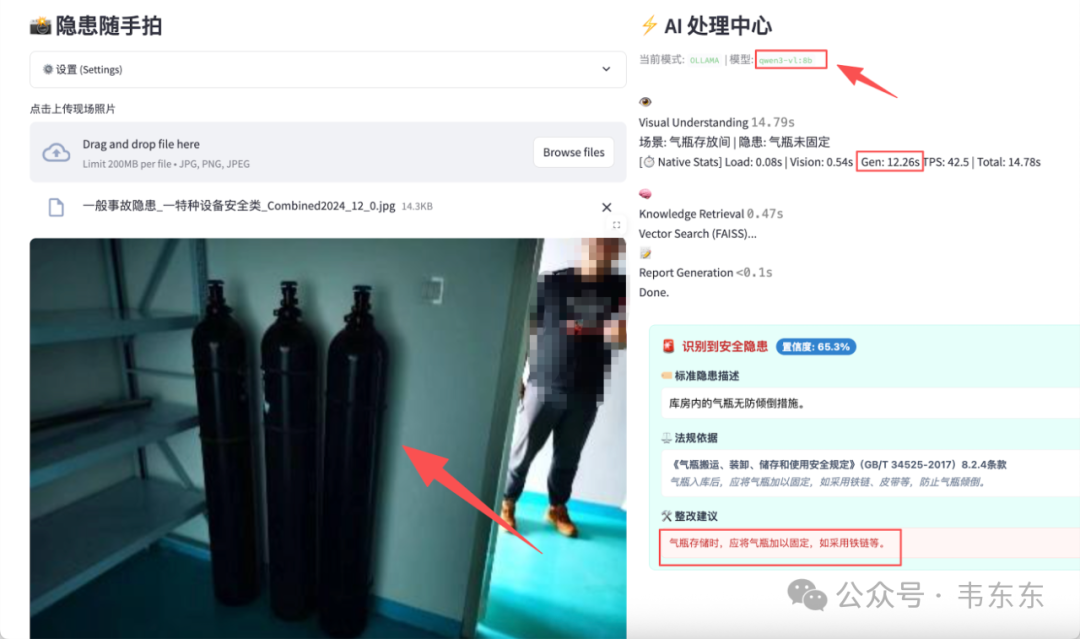
| 模型 | VLM 输出 | Gen 时间 | 总耗时 | 检索结果 |
|---|---|---|---|---|
| qwen3-vl:2b | 场景: 储藏室 | 隐患: 气瓶存放不规范 | 7.03s | 7.54s | ✓ 匹配到气瓶防倾倒条目 |
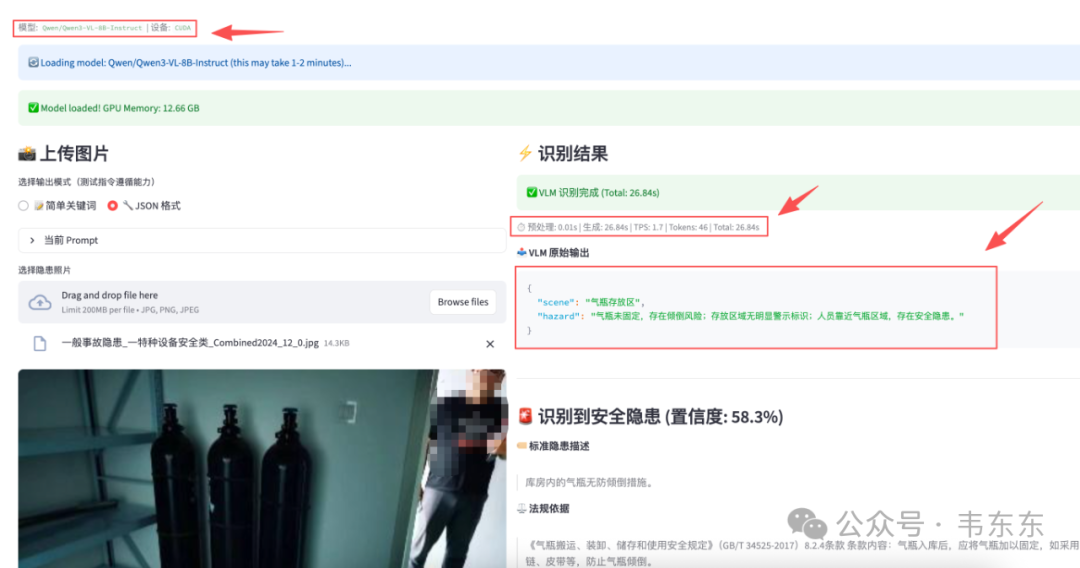
| qwen3-vl:8b | 场景: 气瓶存放间 | 隐患: 气瓶未固定 | 12.26s | 14.78s | ✓ 匹配到气瓶防倾倒条目 |
这一组两者都能识别出"气瓶"相关特征,8B 描述更精准("未固定"比"存放不规范"更具体),但速度慢了近一倍。
测试图片 2:绝缘地垫破损
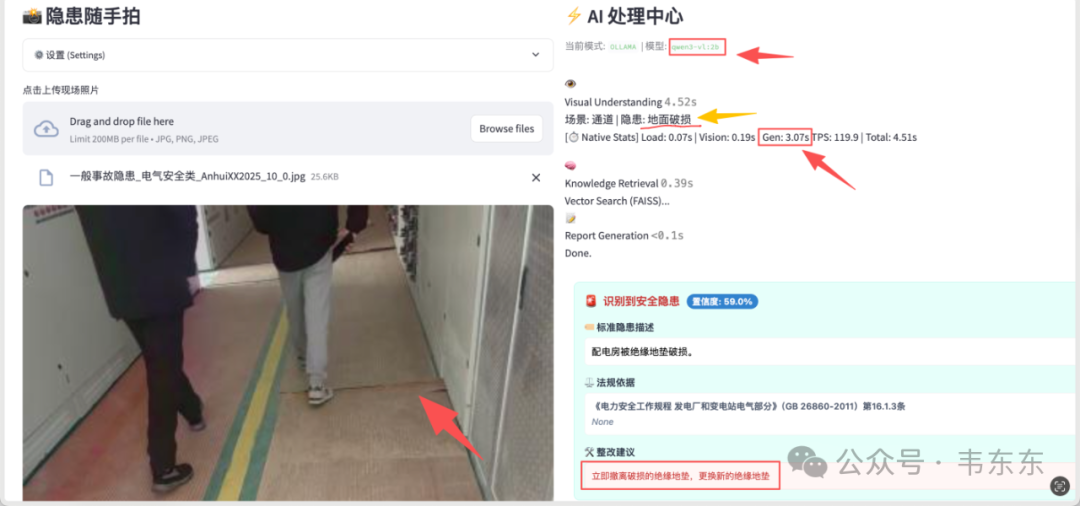
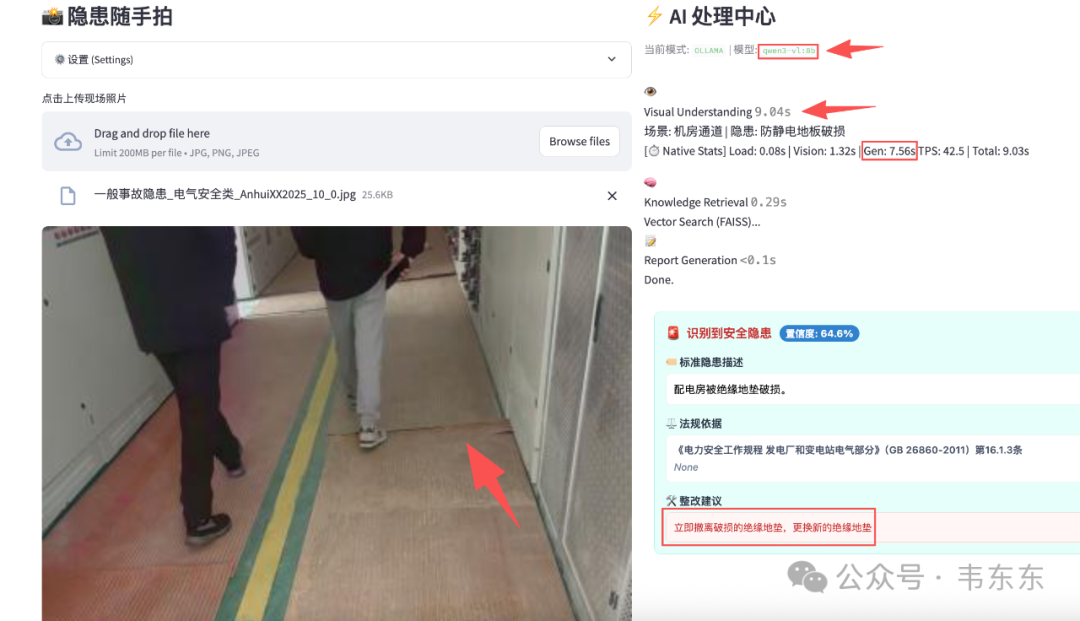
| 模型 | VLM 输出 | Gen 时间 | 总耗时 | 检索结果 |
|---|---|---|---|---|
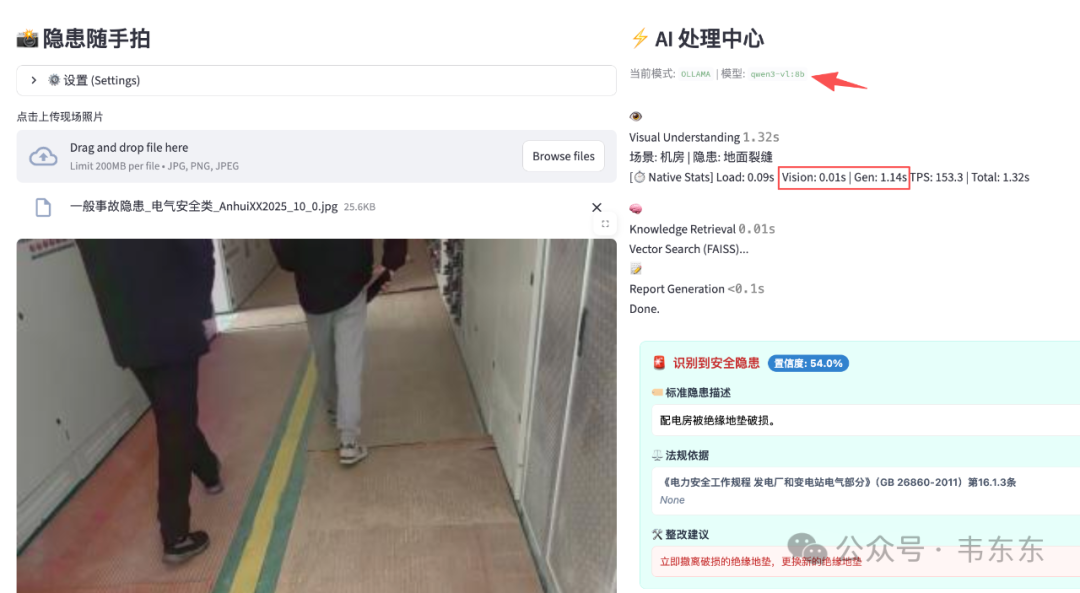
| qwen3-vl:2b | 场景: 通道 | 隐患: 地面破损 | 3.07s | 4.51s | ✓ 匹配到绝缘地垫破损条目 |
| qwen3-vl:8b | 场景: 机房通道 | 隐患: 防静电地板破损 | 7.56s | 9.03s | ✓ 匹配到绝缘地垫破损条目 |
这一组差距开始明显:2B 把"绝缘地垫破损"泛化成了"地面破损",丢失了关键特征;8B 能识别出"防静电地板破损",更接近真实隐患。
测试图片 3:配电室窗户 ⚠️
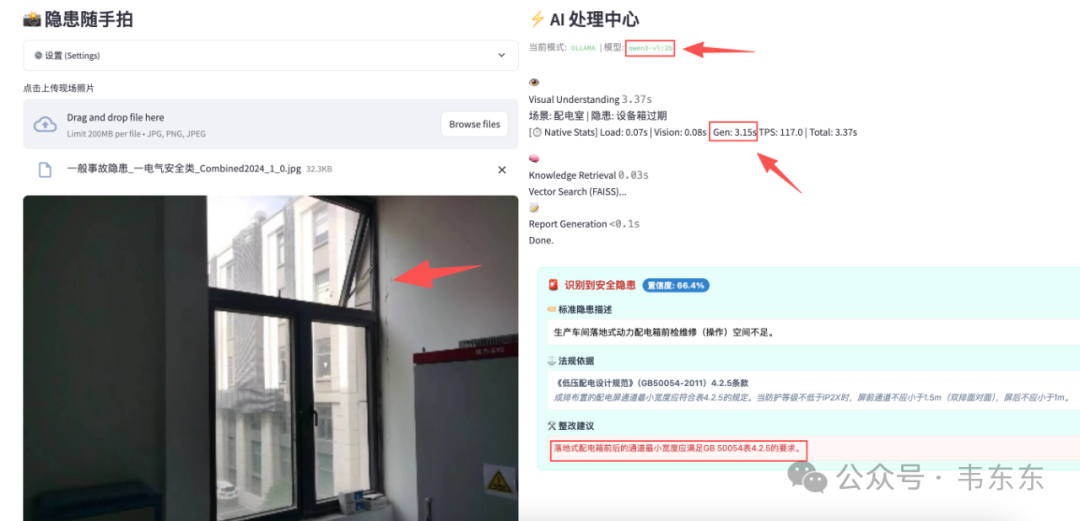
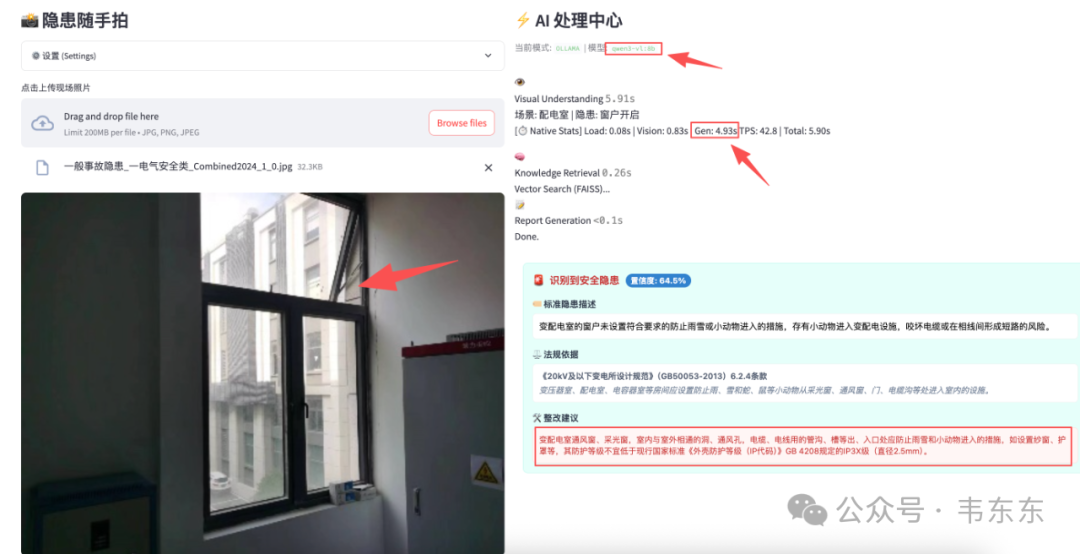
| 模型 | VLM 输出 | Gen 时间 | 总耗时 | 检索结果 |
|---|---|---|---|---|
| qwen3-vl:2b | 场景: 配电室 | 隐患: 设备箱过期 | 3.15s | 3.37s | ✓ 匹配到窗户防护条目 |
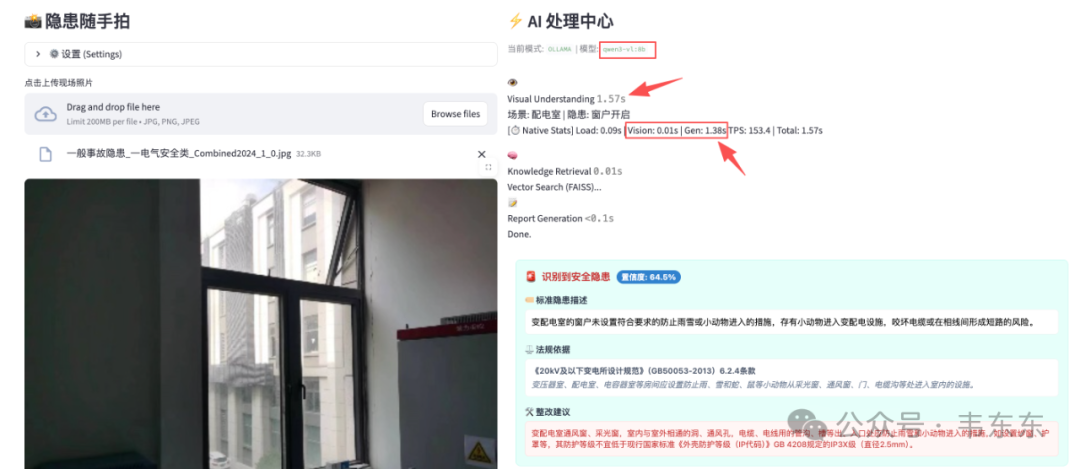
| qwen3-vl:8b | 场景: 配电室 | 隐患: 窗户开启 | 4.93s | 5.90s | ✓ 匹配到窗户防护条目 |
这一组问题最明显:2B 完全识别错了隐患特征,把"窗户没有防护网"识别成了"设备箱过期"。 虽然最终 RAG 检索还是匹配到了正确的知识库条目,但这是因为"配电室"这个场景关键词起了作用,属于**"蒙对了"**。8B 则能正确识别出"窗户开启"这个核心特征。
测试发现的问题:
**1、速度差距明显:**2B 的 Gen 时间在 3-7s,TPS 约 117;8B 的 Gen 时间在 5-12s,TPS 约 42。8B 慢了接近一倍,主要是模型更大(6.1GB vs 1.9GB),Mac 统一内存带宽成为瓶颈。
**2、2B 识别不稳定:**三组测试中,2B 有两次识别出现偏差(绝缘地垫→地面破损,窗户防护→设备箱过期),说明小模型的视觉理解能力确实有限,对于细节特征容易"看走眼"。
**3、量化模型的指令遵循问题:**这是踩过的最大坑。两个模型默认都会输出不必要的思维链内容(Thinking...),而且无法有效关闭。我们尝试过几种优化方案:
方案 1:JSON Mode 强制格式化输出
尝试用 Ollama 的 format="json" 功能,期望模型只输出结构化数据,消除"废话"和思维链。结果:2B 量化模型完全崩溃,返回空字符串或不合法的 JSON;8B 量化模型:同样失效,延迟反而飙到 38s+,且容易输出空结果。
分析下来,低比特量化的小参数 VLM 在指令遵循和 JSON Schema 严格约束之间存在对齐问题,强制 JSON 模式会导致模型在 Decoding 阶段陷入死循环或概率崩塌。
方案 2:Prompt "降维打击"
既然硬约束走不通,改用软引导------回归纯文本模式,通过 Prompt 极度压缩生成空间:
Old Prompt:"请简要描述图中的安全隐患..." → Gen: 9s+
New Prompt:"只输出关键词。格式:场景: A | 隐患: B。不要造句。" → Gen: 2.8s
这个方案在一定程度上有效,但思维链仍然会输出,只是最终输出的关键词部分变短了。
4.5、 小结
本地测试验证了端到端流程是可行的:VLM 识别 → 向量检索 → 知识库匹配 → 生成报告,整个链路跑通了。
但量化小模型的识别精度和指令遵循能力确实有限。2B 模型虽然快,但识别结果不够稳定;8B 模型稍好一些,但在 Mac 上速度还是太慢。
接下来需要在 GPU 服务器上测试,看看用更大的模型(8B 全精度或更大尺寸)能否兼顾速度和精度。
5、GPU 服务器测试:追求速度还是精度?
本以为上了 4090 + 全精度模型就能兼顾速度和精度,结果有些小意外。
5.1、 测试环境
GPU:RTX 4090 (24GB),测试图片:与本地测试相同的三张图片。对比方案:Ollama qwen3-vl:8b(Q4 量化版本)、Transformers Qwen3-VL-8B-Instruct(FP16 全精度)
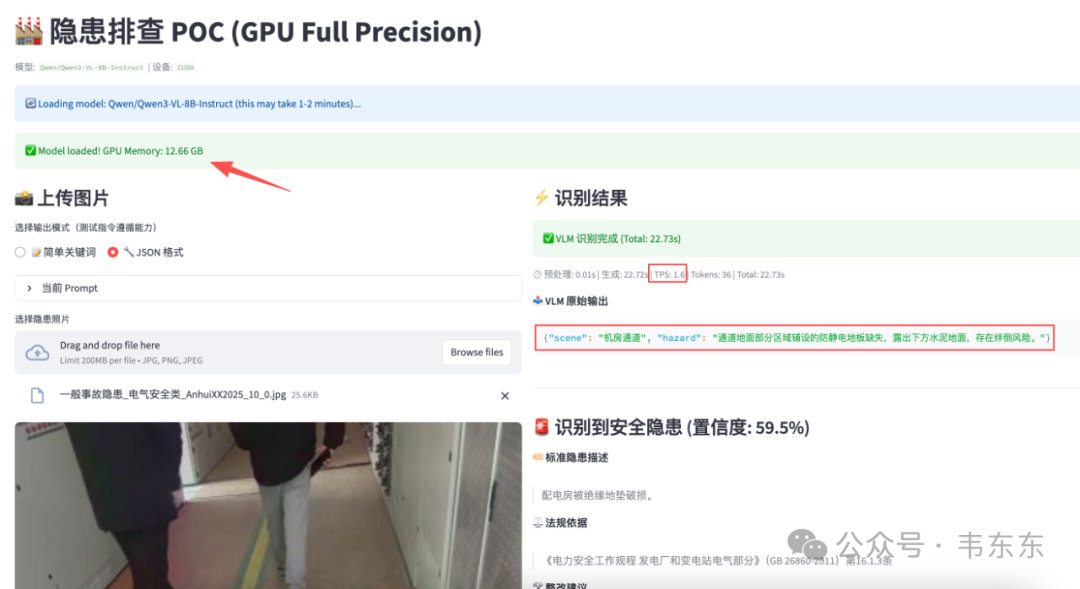
5.2、 全精度模型测试结果
| 测试图片 | Gen 时间 | TPS | Total | JSON 输出 |
|---|---|---|---|---|
| 绝缘地垫破损 | 22.72s | 1.6 | 22.73s | ✅ 成功 |
| 气瓶存放 | 26.84s | 1.7 | 26.84s | ✅ 成功 |
5.3、 Ollama 量化模型测试结果
| 测试图片 | Gen 时间 | TPS | Total | 识别结果 |
|---|---|---|---|---|
| 绝缘地垫破损 | 1.14s | 153.3 | 1.32s | 场景: 机房 | 隐患: 地面裂缝 |
| 配电室窗户 | 1.38s | 153.4 | 1.57s | 场景: 配电室 | 隐患: 窗户开启 ✅ |
| 气瓶存放 | 1.88s | 153.3 | 2.13s | 场景: 气瓶存放区 | 隐患: 气瓶未固定 ✅ |
5.4、 全精度模型为什么这么慢?
4090 理论上应该能跑到 50+ TPS,但实际只有 1.6 TPS,27 秒处理一张图,完全不可用。
猜测最可能的原因是 Qwen3-VL 的思维链机制:Qwen3 系列模型默认开启思维链,模型在输出答案前会先进行大量内部"思考",这些思考过程不会显示在输出中,但会消耗大量时间。46 个 tokens 用了 27 秒 → 说明模型内部可能生成了几千个隐藏 tokens。
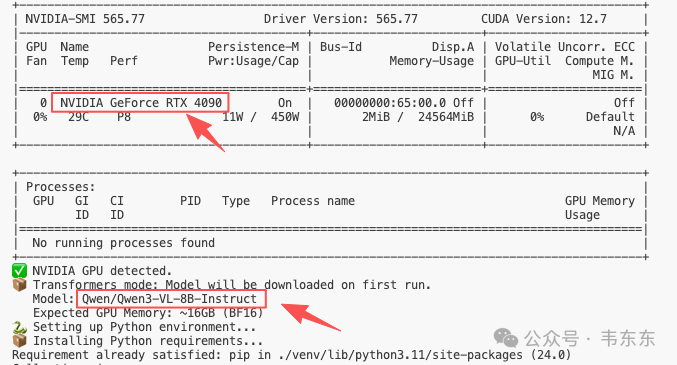
但有一说一,全精度版的 JSON 输出能力确实比量化版本好(能正确遵循格式要求),但代价是 20 倍的延迟,完全无法接受。
5.5、 量化版本反而是赢家
Ollama 量化版在 4090 上的表现很不错:TPS 高达 153(比 Mac 本地的 42 快了 3-4 倍!),总耗时 1-2s,基本符合生产需求。
5.6、 GPU 测试小结
| 维度 | Ollama 量化版 | 全精度版 |
|---|---|---|
| 响应速度 | ✅ 1-2s | ❌ 22-27s |
| TPS | 153 | 1.6 |
| 显存占用 | ~6GB | ~13GB |
| JSON 遵循 | ❓ 有限 | ✅ 优秀 |
| 识别准确度 | 中等 | 高 |
| 生产可用性 | ✅ 可用 | ❌ 不可用 |
结论:8B 量化模型(qwen3-vl:8b)是目前最佳的折中选择。在 4090 上配合 Ollama KEEP_ALIVE 可以实现 2s 内响应,完全满足生产需求。
全精度模型如果要实用,需要专门优化(关闭思维链、使用 vLLM 推理加速等),这是后续可以探索的方向。
6、生产环境:达成极致响应的关键
6.1、 7.1 性能瓶颈深度剖析
为什么 24G 和 64G 显存速度一样?
我用来开发的 Mac M4 Pro 是 24G 内存版本,公司还有一台 Mac Mini 是 64G 版本。这里顺道科普一个知识点,可能会有盆友觉得内存越大速度越快,但实际你去用两台内存大小不同的 Mac 运行 Qwen3-VL-8B 模型时,两台机器的推理速度几乎没有差别。
原因也很简单,这个量化后的模型实际只需要 ~6GB 显存。只要显存够用(能装下模型),再大的显存也不会让模型跑得更快。真正决定速度的是显存带宽------也就是数据在显存和计算单元之间传输的速度。
什么是显存带宽?
显存带宽可以理解为"数据管道的粗细"。M4 Pro(24G)和 M4 Pro(64G)的显存带宽都是 273 GB/s------管道一样粗,数据流通速度自然一样。
为什么 4090 更快?
RTX 4090 虽然同样是 24G 显存,但它的显存带宽高达 1008 GB/s,是 Mac 的 3.7 倍。这意味着数据流通速度快了将近 4 倍。再加上 4090 拥有 16,384 个 CUDA 核心(算力远超 Mac 的 GPU),所以同样的模型在 4090 上能跑出 153 TPS,而 Mac 只有 42 TPS。
对于 Ollama 运行的 Q4 量化版本(模型文件仅 1.9GB),理论吞吐计算:
python
$$\text{Token/s} = \frac{\text{带宽}}{\text{模型大小}} $$Mac (273 GB/s ÷ 1.9GB) ≈ 143 Token/s(理论值)
4090 (1008 GB/s ÷ 1.9GB) ≈ 530 Token/s(理论值)
实际测试中没有达到理论值,说明瓶颈还有其他因素------下面会讲到。
真正的耗时步骤:视觉编码器 (Vision Encoder)
多模态模型的流程是 图片 -> Vision Encoder (ViT) -> 视觉 Tokens -> LLM。虽然 LLM 部分被量化到了 Q4 (1.9GB),但前端的 Vision Encoder 通常保持较高精度 (FP16/FP32) 以确保"看得清"。处理高清图像(如 1024x1024)需要进行海量的矩阵运算,消耗的是 GPU 的 TFLOPS (算力),而非带宽。这也解释了为什么"首字延迟 (Time to First Token)"会这么长------大部分时间花在了"看图"和"理解图"的预处理阶段。
6.2、 硬件升级建议
基于上述分析,升级策略应侧重于 提升核心算力而非单纯的显存容量:
| 升级方向 | 效果 | 推荐 |
|---|---|---|
| Mac M4 Pro 24G → 64G | ❌ 无速度提升 | 不推荐 |
| Mac M4 Pro → M4 Max | ✅ GPU 核心翻倍,Vision 编码时间减半 | 推荐 |
| Mac → RTX 4090 服务器 | ✅ 16,384 CUDA 核心,82 TFLOPS | 最佳性能 |
结论:换用 M4 Max 或 RTX 4090 将比单纯增加内存带来更显著的速度提升,不仅能提升生成速度,更能大幅压缩那 ~5s 的"看图"等待时间。
6.3、 隐藏的耗时:前端图片尺寸
这是达成 < 2s 目标的决定性因素:
现状:现代手机照片通常 5MB+,上传耗时 >2s,直接超标
强制策略:小程序端先压缩再上传,Resize 到长边 ≤1024px,格式 JPEG,质量 80%
结果:图片体积降至 100KB - 200KB,上传耗时 <0.3s
6.4、 最终延迟预算表
| 环节 | 预估耗时 (优化后) | 备注 |
|---|---|---|
| 网络上传 | 0.3s | 100KB 图片, 4G 网络 |
| 应用处理 | 0.1s | 接收请求, 预处理 |
| 视觉推理 | 0.5s | 4090 + 量化模型 |
| RAG 检索 | 0.1s | FAISS 向量检索 |
| 总计 | < 1.5s | ✅ 达成目标 |
7、写在最后
这篇文章有点长,工程细节不用全记住,但以下三点经验值得带走。
7.1、 理解模型的能力边界,比追求更大更强更重要
有些盆友刚上手大模型应用倾向于用最强的模型,觉得参数越大效果越好。但真正做落地项目时你会发现,大模型的全能往往意味着"什么都会一点,什么都不精"。比如这个项目,8B 量化模型会比全精度版本更合适。原因很简单:我需要的是它"看图识别场景"的能力,不需要它深度推理的能力。量化版本恰好保留了前者,砍掉了后者,响应时间从 27s 降到了 1-2s。这不是降级,而是精准匹配需求。
7.2、 用模型的识别能力,不用它的生成能力
这个项目的架构设计有一个核心思路:模型只负责描述隐患现象,输出一段简短的关键词;而知识库负责匹配,根据描述查找标准条目,返回法规和整改建议。模型的输出只是一个"插槽",真正的专业内容由预先录入的知识库提供。这样做的好处是:模型可以换,知识库可以沉淀;模型可能看错,知识库可以兜底;模型不懂行业术语,知识库全都知道。这种"小模型 + 大知识"的组合,比"大模型包打天下"更适合工业场景。
7.3、 边缘侧部署,量化和知识库是标配
如果你的场景对响应延迟有硬性要求(比如 2 秒内),或者需要在手机、边缘盒子上运行,那么全精度大模型基本不可能。这时候,量化模型 + 本地知识库的组合就是唯一解。模型负责意图理解和特征提取,知识库负责专业回复,各取所长,互相补位。这不是妥协,而是在资源约束下的最优解。
如果你也在做类似的项目,欢迎交流。
完整项目脚本已上传至知识星球《企业大模型应用从入门到落地》中,
欢迎加入一起学习共创。
(知识星球成员可1元兑换下方课程)