本文从编译器基础概念开始,逐步深入到 LLVM 的实现细节和实际应用,帮助开发者全面理解 LLVM 的工作原理和使用方法。
目录
- 第一部分:编译器基础
- [第二部分:LLVM 简介](#第二部分:LLVM 简介 "#%E7%AC%AC%E4%BA%8C%E9%83%A8%E5%88%86llvm-%E7%AE%80%E4%BB%8B")
- [第三部分:LLVM 的使用](#第三部分:LLVM 的使用 "#%E7%AC%AC%E4%B8%89%E9%83%A8%E5%88%86llvm-%E7%9A%84%E4%BD%BF%E7%94%A8")
- [第四部分:Jeandle 案例分析](#第四部分:Jeandle 案例分析 "#%E7%AC%AC%E5%9B%9B%E9%83%A8%E5%88%86jeandle-%E6%A1%88%E4%BE%8B%E5%88%86%E6%9E%90")
- 第五部分:深入理解
第一部分:编译器基础
编译器是什么?
编译器本质上是一个翻译官,它的工作是将人类能理解的高级语言代码翻译成计算机能执行的机器码。
类比理解:
- 源代码 = 中文文章
- 编译器 = 翻译官
- 机器码 = 英文文章(计算机能理解)
编译器的三个步骤
编译器的工作可以分为三个核心步骤:
步骤1:词法分析(Lexer)- "拆词"
作用:把源代码拆成一个个有意义的"单词"(Token)
例子:
java
// 源代码
String source = "let x = 5 + 3";
// 词法分析后
List<Token> tokens = Arrays.asList(
new Token(TokenType.LET, "let"),
new Token(TokenType.IDENTIFIER, "x"),
new Token(TokenType.ASSIGN, "="),
new Token(TokenType.NUMBER, "5"),
new Token(TokenType.PLUS, "+"),
new Token(TokenType.NUMBER, "3")
);实际代码(Java 实现):
java
public class Lexer {
private String source;
private int pos = 0;
private List<Token> tokens = new ArrayList<>();
public List<Token> tokenize() {
while (pos < source.length()) {
char ch = source.charAt(pos);
// 跳过空白字符
if (Character.isWhitespace(ch)) {
pos++;
continue;
}
// 数字
if (Character.isDigit(ch)) {
String value = readNumber();
tokens.add(new Token(TokenType.NUMBER, value));
continue;
}
// 标识符或关键字
if (Character.isLetter(ch) || ch == '_') {
String value = readIdentifier();
TokenType type = keywordMap.getOrDefault(value, TokenType.IDENTIFIER);
tokens.add(new Token(type, value));
continue;
}
// 运算符和分隔符
switch (ch) {
case '+':
tokens.add(new Token(TokenType.PLUS));
break;
case '-':
tokens.add(new Token(TokenType.MINUS));
break;
case '=':
if (peekChar() == '=') {
pos++;
tokens.add(new Token(TokenType.EQ));
} else {
tokens.add(new Token(TokenType.ASSIGN));
}
break;
// ... 其他运算符
}
pos++;
}
return tokens;
}
private String readNumber() {
int start = pos;
while (pos < source.length() && Character.isDigit(source.charAt(pos))) {
pos++;
}
return source.substring(start, pos);
}
private String readIdentifier() {
int start = pos;
while (pos < source.length() &&
(Character.isLetterOrDigit(source.charAt(pos)) ||
source.charAt(pos) == '_')) {
pos++;
}
return source.substring(start, pos);
}
}类比:就像把句子"我喜欢苹果"拆成 "我", "喜欢", "苹果"
步骤2:语法分析(Parser)- "理解结构"
作用:把 Token 流转换成抽象语法树(AST),理解代码的结构和含义
例子:
java
// Token 流
List<Token> tokens = Arrays.asList(
new Token(TokenType.LET),
new Token(TokenType.IDENTIFIER, "x"),
new Token(TokenType.ASSIGN),
new Token(TokenType.NUMBER, "5"),
new Token(TokenType.PLUS),
new Token(TokenType.NUMBER, "3")
);
// 语法分析后生成 AST
ASTNode ast = new AssignmentNode(
"x",
new BinaryOpNode(
"+",
new NumberNode(5),
new NumberNode(3)
)
);AST 的树状结构:
markdown
=
/ \
x +
/ \
5 3实际代码(Java 实现):
java
public class Parser {
private List<Token> tokens;
private int current = 0;
public ASTNode parseExpression() {
ASTNode left = parseTerm();
while (current < tokens.size() &&
(currentToken().getType() == TokenType.PLUS ||
currentToken().getType() == TokenType.MINUS)) {
String op = currentToken().getType().getValue();
advance();
ASTNode right = parseTerm();
left = new BinaryOpNode(op, left, right);
}
return left;
}
public ASTNode parseAssignment() {
expect(TokenType.LET);
String name = expect(TokenType.IDENTIFIER).getValue();
expect(TokenType.ASSIGN);
ASTNode value = parseExpression();
return new AssignmentNode(name, value);
}
private ASTNode parseTerm() {
ASTNode left = parseFactor();
while (current < tokens.size() &&
(currentToken().getType() == TokenType.MUL ||
currentToken().getType() == TokenType.DIV)) {
String op = currentToken().getType().getValue();
advance();
ASTNode right = parseFactor();
left = new BinaryOpNode(op, left, right);
}
return left;
}
private ASTNode parseFactor() {
Token token = currentToken();
if (token.getType() == TokenType.NUMBER) {
advance();
return new NumberNode(Integer.parseInt(token.getValue()));
} else if (token.getType() == TokenType.IDENTIFIER) {
advance();
return new IdentifierNode(token.getValue());
} else if (token.getType() == TokenType.LPAREN) {
advance();
ASTNode expr = parseExpression();
expect(TokenType.RPAREN);
return expr;
}
throw new SyntaxError("Unexpected token: " + token);
}
}类比:理解"我喜欢苹果"中,"我"是主语,"喜欢"是动词,"苹果"是宾语
步骤3:代码生成(CodeGen)- "翻译"
作用:把 AST 转换成目标代码(在我们的例子中是 LLVM IR)
例子:
java
// AST
ASTNode ast = new AssignmentNode(
"x",
new BinaryOpNode("+", new NumberNode(5), new NumberNode(3))
);
// 代码生成后
String llvmIR = """
%x = alloca i32 ; 为变量 x 分配内存
%1 = add i32 5, 3 ; 计算 5 + 3,结果存在 %1
store i32 %1, i32* %x ; 把结果存到 x 里
""";实际代码(Java 实现):
java
public class CodeGenerator {
private LLVMModuleRef module;
private LLVMBuilderRef builder;
private Map<String, LLVMValueRef> symbols = new HashMap<>();
private LLVMTypeRef int32Type;
public CodeGenerator() {
module = LLVM.ModuleCreateWithName("calc_module");
int32Type = LLVM.Int32Type();
}
public LLVMValueRef generateAssignment(AssignmentNode node) {
// 生成表达式的值
LLVMValueRef value = generateExpression(node.getValue());
// 分配内存(如果变量不存在)
if (!symbols.containsKey(node.getName())) {
LLVMValueRef alloca = LLVM.BuildAlloca(
builder, int32Type, node.getName());
symbols.put(node.getName(), alloca);
}
// 存储值
LLVM.BuildStore(builder, value, symbols.get(node.getName()));
return value;
}
public LLVMValueRef generateExpression(ASTNode node) {
if (node instanceof BinaryOpNode) {
BinaryOpNode binOp = (BinaryOpNode) node;
LLVMValueRef left = generateExpression(binOp.getLeft());
LLVMValueRef right = generateExpression(binOp.getRight());
switch (binOp.getOp()) {
case "+":
return LLVM.BuildAdd(builder, left, right, "add");
case "-":
return LLVM.BuildSub(builder, left, right, "sub");
case "*":
return LLVM.BuildMul(builder, left, right, "mul");
case "/":
return LLVM.BuildSDiv(builder, left, right, "div");
default:
throw new IllegalArgumentException(
"Unknown operator: " + binOp.getOp());
}
} else if (node instanceof NumberNode) {
NumberNode num = (NumberNode) node;
return LLVM.ConstInt(int32Type, num.getValue(), false);
} else if (node instanceof IdentifierNode) {
IdentifierNode ident = (IdentifierNode) node;
if (!symbols.containsKey(ident.getName())) {
throw new RuntimeException(
"Variable not found: " + ident.getName());
}
return LLVM.BuildLoad(builder,
symbols.get(ident.getName()), ident.getName());
}
throw new IllegalArgumentException(
"Unknown AST node type: " + node.getClass());
}
}类比:把中文翻译成英文
完整流程示例
让我们用一个完整的例子来看整个编译过程:
源代码 (examples/add.calc):
calc
func add(a, b) {
return a + b
}
let result = add(5, 3)
print(result)第1步:词法分析
scss
Token(FUNC, 'func')
Token(IDENTIFIER, 'add')
Token(LPAREN)
Token(IDENTIFIER, 'a')
Token(COMMA)
Token(IDENTIFIER, 'b')
Token(RPAREN)
Token(LBRACE)
Token(RETURN, 'return')
Token(IDENTIFIER, 'a')
Token(PLUS)
Token(IDENTIFIER, 'b')
Token(RBRACE)
Token(LET, 'let')
Token(IDENTIFIER, 'result')
Token(ASSIGN)
Token(IDENTIFIER, 'add')
Token(LPAREN)
Token(NUMBER, '5')
Token(COMMA)
Token(NUMBER, '3')
Token(RPAREN)
Token(PRINT, 'print')
Token(LPAREN)
Token(IDENTIFIER, 'result')
Token(RPAREN)第2步:语法分析(AST)
less
FunctionDef("add", ["a", "b"], [
Return(BinaryOp("+", Identifier("a"), Identifier("b")))
])
Assignment("result", FunctionCall("add", [Number(5), Number(3)]))
FunctionCall("print", [Identifier("result")])第3步:代码生成(LLVM IR)
llvm
; ModuleID = "calc_module"
target triple = "unknown-unknown-unknown"
declare void @"print"(i32 %".1")
define i32 @"main"()
{
entry:
%".2" = call i32 @"add"(i32 5, i32 3)
%"result" = alloca i32
store i32 %".2", i32* %"result"
%"result.1" = load i32, i32* %"result"
call void @"print"(i32 %"result.1")
ret i32 0
}
define i32 @"add"(i32 %"a", i32 %"b")
{
entry:
%"a.1" = alloca i32
store i32 %"a", i32* %"a.1"
%"b.1" = alloca i32
store i32 %"b", i32* %"b.1"
%"a.2" = load i32, i32* %"a.1"
%"b.2" = load i32, i32* %"b.1"
%"add" = add i32 %"a.2", %"b.2"
ret i32 %"add"
}第二部分:LLVM 简介
什么是 LLVM?
LLVM(Low Level Virtual Machine)是一个编译器基础设施,提供了一套模块化的编译器工具链。
重要澄清:
- LLVM 不是一个虚拟机(尽管名字里有 VM)
- LLVM 是一个编译器框架和工具集
- LLVM 的核心是 LLVM IR(中间表示)
为什么选择 LLVM?
传统方式 vs LLVM 方式
传统方式(复杂):
你的语言 → 直接生成机器码
需要了解:x86、ARM、MIPS 等各种 CPU 架构
需要写:每个平台一套代码生成器(至少 6 套!)
开发时间:3-5 年使用 LLVM(简单):
你的语言 → LLVM IR → LLVM自动生成机器码
你只需要:生成 LLVM IR(1 套代码)
LLVM 帮你:优化、跨平台、各种架构(自动支持所有平台)
开发时间:1-2 年实际例子:Swift 为什么用 LLVM?
Swift 需要支持:
- iPhone/iPad(ARM 架构)
- Mac(x86 和 ARM)
- Linux 服务器(x86)
如果不用 LLVM:
- 需要写 3 套代码生成器
- 需要写 3 套优化器
- 至少需要 3-5 年开发时间
- 维护成本巨大
使用 LLVM:
- 只需要生成 LLVM IR(1 套代码)
- LLVM 自动支持所有平台
- LLVM 自动优化代码
- 1-2 年完成开发
- 维护成本低
LLVM 的核心优势
-
一次编写,到处运行
- 生成 LLVM IR 后,自动支持所有平台
- Windows、Linux、Mac、iOS、Android 都能用
-
强大的优化能力
- 死代码消除
- 循环优化
- 内联函数
- 常量折叠
- 几十种优化算法
-
成熟的工具链
- 编译器(clang)
- 调试器(lldb)
- 性能分析工具
- 代码格式化工具
LLVM IR 是什么?
LLVM IR(Intermediate Representation)是 LLVM 的中间代码格式,它是:
- 人类能看懂(不像机器码 01010101)
- 比高级语言低级(不像 Python 那么简单)
- 比机器码高级(不像汇编那么复杂)
- 格式统一(所有语言都能生成这种格式)
类比:
ini
高级语言(Python/Java) = 中文
↓
LLVM IR = 世界语(中间语言)
↓
机器码 = 各种外语(英文、日文...)LLVM IR 基础语法
基本类型
llvm
i32 ; 32位整数
i64 ; 64位整数
i32* ; 指向 i32 的指针
void ; 无类型基本操作
llvm
; 分配内存
%x = alloca i32
; 存储值
store i32 5, i32* %x
; 加载值
%val = load i32, i32* %x
; 算术运算
%sum = add i32 %a, %b
%diff = sub i32 %a, %b
%prod = mul i32 %a, %b
%quot = sdiv i32 %a, %b
; 函数调用
call void @print(i32 %x)
; 返回
ret i32 0函数定义
llvm
define i32 @add(i32 %a, i32 %b) {
entry:
%1 = add i32 %a, %b
ret i32 %1
}关键点:
%开头的变量是局部变量(如%1,%a)@开头的变量是全局变量或函数(如@add,@print)entry:是基本块的标签- 每个函数至少有一个基本块
第三部分:LLVM 的使用
如何调用 LLVM API?
LLVM 提供了多种语言的绑定,最常见的是 C/C++ API,其他语言通过包装库调用。本文以 Java 为例展示如何使用 LLVM API。
Java 使用 LLVM
java
import org.llvm.*;
public class LLVMExample {
public static void main(String[] args) {
// 创建 LLVM 模块
LLVMModuleRef module = LLVM.ModuleCreateWithName("calc_module");
// 创建类型
LLVMTypeRef int32Type = LLVM.Int32Type();
LLVMTypeRef voidType = LLVM.VoidType();
// 创建函数类型
LLVMTypeRef[] paramTypes = {int32Type, int32Type};
LLVMTypeRef funcType = LLVM.FunctionType(int32Type, paramTypes, false);
// 创建函数
LLVMValueRef func = LLVM.AddFunction(module, "add", funcType);
// 创建基本块
LLVMBasicBlockRef entryBlock = LLVM.AppendBasicBlock(func, "entry");
LLVMBuilderRef builder = LLVM.CreateBuilder();
LLVM.PositionBuilderAtEnd(builder, entryBlock);
// 生成代码
LLVMValueRef paramA = LLVM.GetParam(func, 0);
LLVMValueRef paramB = LLVM.GetParam(func, 1);
LLVMValueRef result = LLVM.BuildAdd(builder, paramA, paramB, "sum");
LLVM.BuildRet(builder, result);
// 输出 LLVM IR
String ir = LLVM.PrintModuleToString(module);
System.out.println(ir);
// 清理资源
LLVM.DisposeBuilder(builder);
LLVM.DisposeModule(module);
}
}关键:Java 使用 LLVM 就是调用 LLVM 的库(lib)包里面的 API 函数,通过 JNI 或 Java 绑定库来调用底层的 C/C++ API。
其他语言 :Python 可以使用 llvmlite,Rust 可以使用 llvm-sys,但原理相同,都是调用 LLVM 的库 API。
ModuleCreateWithName 的作用
重要理解 :ModuleCreateWithName("test") 中的 "test" 只是一个模块名称/标识符,不是源代码!
java
// 创建空模块(只是起个名字)
LLVMModuleRef module = LLVM.ModuleCreateWithName("test");
// 此时模块是空的,只有名字
// 实际的代码是通过后续 API 调用添加的
LLVMValueRef func = LLVM.AddFunction(module, "add", funcType); // ← 添加函数
LLVM.BuildAdd(builder, ...); // ← 添加实际的代码逻辑类比:
ModuleCreateWithName= 创建空文件夹(起名字)AddFunction、BuildAdd等 = 添加实际的文件(代码)
LLVM IR 到机器码的流程
重要澄清 :调用 LLVM API 后,生成的是 LLVM IR,还不是机器码!
完整流程(JIT 编译器)
java
// 1. 调用 LLVM API 生成 IR
LLVMModuleRef module = LLVM.ModuleCreateWithName("java_method");
// ... 生成 LLVM IR(还不是机器码!)
// 2. 优化 IR
LLVMPassManagerRef pm = LLVM.CreatePassManager();
LLVM.RunPassManager(pm, module);
// 3. 编译成机器码
byte[] machineCode = LLVM.CompileToMachineCode(module);
// 现在是机器码了!
// 4. 放在 Code Cache
CodeCache cache = getCodeCache();
cache.put(methodName, machineCode);
// 5. 以后直接执行
// 当 Java 方法被调用时,从 cache 中取出机器码直接执行关键点:
- 调用 API 后生成的是 LLVM IR(不是机器码)
- LLVM IR 需要编译成机器码
- 机器码放在 code cache(JIT 编译器)
- 从 cache 中直接执行(快)
Code Cache 的作用
Code Cache 是 JIT 编译器中的代码缓存,用于存储编译好的机器码。
为什么需要 Code Cache?
- JIT 编译器在运行时编译(慢)
- 编译好的机器码放在 cache 中
- 下次直接执行,不用再编译(快)
类比:
- 第一次:翻译文章(编译),放在书架(cache)
- 第二次:直接从书架取(从 cache 执行),不用再翻译
静态编译器 vs JIT 编译器:
| 特性 | 静态编译器 | JIT 编译器 |
|---|---|---|
| 编译时机 | 提前编译 | 运行时编译 |
| 输出 | 可执行文件 | Code Cache |
| Code Cache | 不需要 | 需要 |
| 例子 | Swift、Rust | Jeandle、HotSpot |
第四部分:Jeandle 案例分析
Jeandle 是什么?
Jeandle(筋斗云)是蚂蚁集团开源的基于 LLVM 的 JVM JIT 编译器,它将 LLVM 的强大优化能力引入到 Java 虚拟机中。
重要澄清:
- HotSpot JVM 有自己的 JIT 编译器(C1、C2),不是基于 LLVM
- Jeandle 是新的尝试,用 LLVM 来做 JIT 编译器
- 这样就能享受 LLVM 的强大优化能力
为什么重要?
-
Java 是世界上使用最多的语言之一
- 很多大公司都在用 Java
- 如果能提升 Java 的性能,影响巨大
-
LLVM 是业界最强的编译器工具
- Swift、Rust 等新语言都用它
- 它的优化能力是顶级的
- 但之前没有用在 JVM 上
-
Jeandle 把两者结合
- 让 Java 也能享受 LLVM 的优势
- 就像给 Java 装上了"筋斗云"
Jeandle 的技术流程
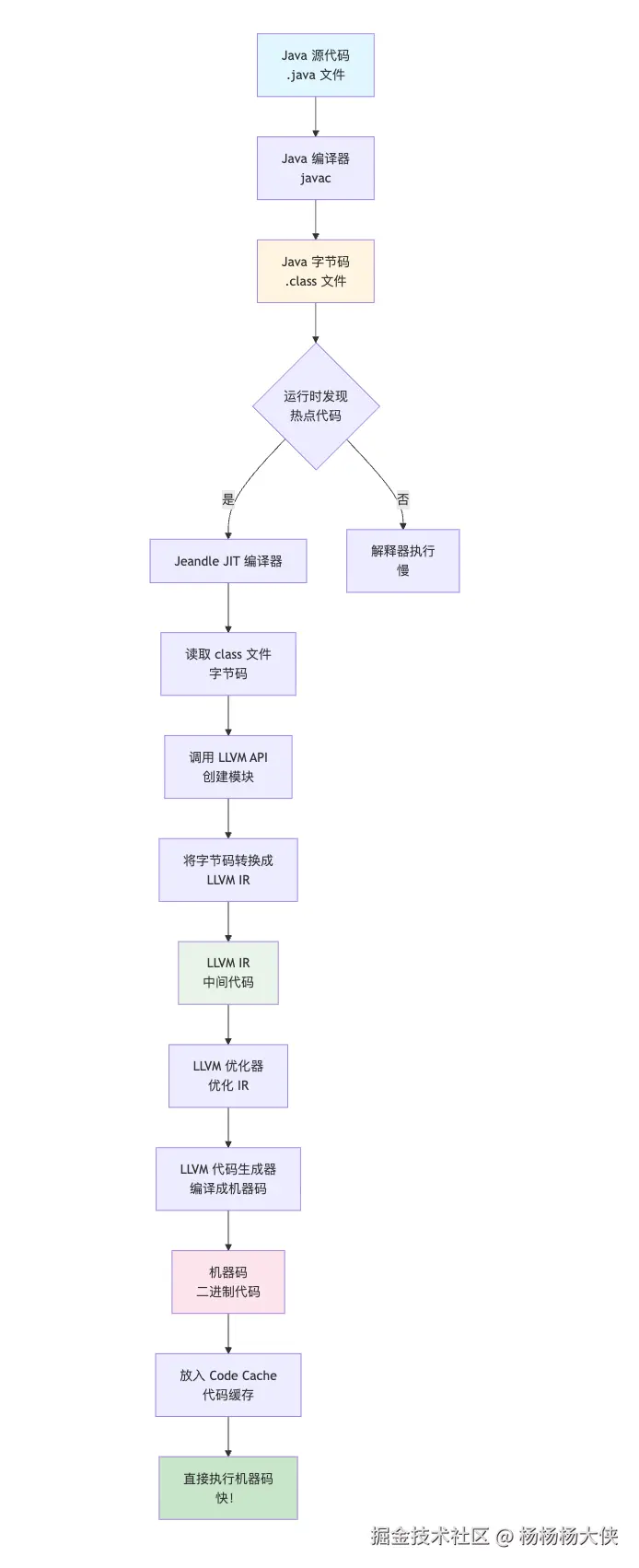
详细步骤
步骤1:读取 Java 字节码
java
// Jeandle 读取 Java 字节码
byte[] bytecode = readClassFile("MyClass.class");
// class 文件内容(字节码):
// - 方法名、参数类型
// - 字节码指令(iload, iadd, ireturn 等)
// - 常量池步骤2:转换成 LLVM IR
java
// Jeandle 的核心工作:将字节码转换成 LLVM IR
LLVMModuleRef module = LLVM.ModuleCreateWithName("MyClass.add");
// 读取字节码指令并转换
for (bytecode instruction : bytecode) {
if (instruction == ILOAD) { // 加载整数
// 转换成 LLVM IR:%1 = load i32, i32* %local_var
LLVM.BuildLoad(builder, ...);
}
else if (instruction == IADD) { // 整数相加
// 转换成 LLVM IR:%2 = add i32 %1, %3
LLVM.BuildAdd(builder, ...);
}
else if (instruction == IRETURN) { // 返回
// 转换成 LLVM IR:ret i32 %2
LLVM.BuildRet(builder, ...);
}
}步骤3:LLVM 编译成机器码
java
// LLVM 将 IR 编译成机器码
byte[] machineCode = LLVM.CompileToMachineCode(module);步骤4:放在 Code Cache
java
// 放在 code cache 中
codeCache.put("MyClass.add", machineCode);
// 以后直接执行
executeFromCache("MyClass.add");技术挑战
Jeandle 需要解决的技术难题:
-
垃圾回收(GC)支持
- Java 有自动内存管理
- 需要让 LLVM 理解 Java 的 GC 机制
-
Java 的动态特性
- 比如
synchronized(同步锁) - 需要定制 LLVM 来支持这些特性
- 比如
-
Java 专用优化
- 针对 Java 语言特点的优化算法
- 比如锁优化、逃逸分析等
与 HotSpot JVM 的对比
对比总结:
| 特性 | HotSpot C1/C2 | Jeandle + LLVM |
|---|---|---|
| 优化能力 | 有限(自己实现) | 强大(LLVM 优化) |
| 开发成本 | 高(需要自己写) | 低(复用 LLVM) |
| 平台支持 | 需要自己支持 | LLVM 自动支持 |
| 维护成本 | 高 | 低 |
第五部分:深入理解
不能直接"增加":为什么需要转换?
常见误解:可以直接把 class 文件内容"增加"到 LLVM IR 中。
实际情况 :不能直接"增加",必须转换!
原因:
-
格式不同
- Java 字节码是 JVM 的格式(iload, iadd 等)
- LLVM IR 是 LLVM 的格式(load, add 等)
- 格式完全不同,必须转换
-
LLVM 不会自动理解
- LLVM 不会自动理解 Java 语法或字节码
- LLVM 只能理解 LLVM IR 格式
- 需要编译器前端来做转换
正确流程:
arduino
class 文件(Java 字节码)
↓
Jeandle 转换器(读取字节码)
↓
转换成 LLVM IR(格式转换)
↓
添加到 LLVM 模块中错误流程:
arduino
class 文件内容
↓
直接放到 LLVM 模块中 ❌
↓
LLVM:我看不懂这是什么!字节码到 LLVM IR 的转换
指令映射关系:
| Java 字节码 | LLVM IR | 说明 |
|---|---|---|
iload_1 |
%1 = load i32, i32* %local_var |
加载局部变量 |
iadd |
%2 = add i32 %1, %3 |
整数相加 |
ireturn |
ret i32 %2 |
返回整数 |
invokevirtual |
call i32 @method(...) |
调用方法 |
getfield |
%obj = load %Class, %Class* %ptr %field = getelementptr ... |
访问字段 |
实际转换示例:
Java 字节码:
arduino
public int add(int a, int b) {
return a + b;
}字节码指令:
arduino
iload_1 // 加载参数 a
iload_2 // 加载参数 b
iadd // 相加
ireturn // 返回转换后的 LLVM IR:
llvm
define i32 @add(i32 %a, i32 %b) {
entry:
%1 = add i32 %a, %b
ret i32 %1
}LLVM 优化器
LLVM 优化器包含几十种优化算法:
常见优化:
- 死代码消除:删除永远不会执行的代码
- 循环优化:优化循环结构,减少循环开销
- 内联函数:将小函数直接展开到调用处
- 常量折叠:在编译时计算常量表达式
- 公共子表达式消除:避免重复计算相同的表达式
优化流程:
使用示例:
java
// 创建优化器
LLVMPassManagerRef pm = LLVM.CreatePassManager();
// 添加优化 Pass
LLVM.AddInstructionCombiningPass(pm); // 指令合并
LLVM.AddReassociatePass(pm); // 重新关联
LLVM.AddGVNPass(pm); // 全局值编号
LLVM.AddCFGSimplificationPass(pm); // CFG 简化
// 运行优化
LLVM.RunPassManager(pm, module);实际应用场景
使用 LLVM 的著名系统:
| 系统/语言 | 为什么选择 LLVM | 实际好处 |
|---|---|---|
| Swift (Apple) | 需要支持 iOS、macOS、Linux | 一次编写,到处运行 |
| Rust | 需要高性能和跨平台 | LLVM 的优化能力很强 |
| Julia | 科学计算需要高性能 | LLVM 的数学优化很厉害 |
| Clang (C/C++) | 替代 GCC,更好的错误信息 | LLVM 的模块化设计 |
| Kotlin Native | 需要编译成原生代码 | 不需要 JVM,直接运行 |
| Jeandle | 将 LLVM 优势引入 Java | 强大的优化能力 |
参考资料
记住:编译器就是翻译官,LLVM 是专业的翻译工具!🚀