在无外网访问权限的内网环境中,IP离线数据库是实现设备定位、安全监控、合规审计等核心能力的关键基础设施。本方案针对内网"无外网依赖、数据安全可控、运维自主闭环"的核心需求,从前期规划、搭建实施、维护优化、应急处置四个维度,提供全生命周期的部署维护指南,适配不同规模企业的内网系统架构。

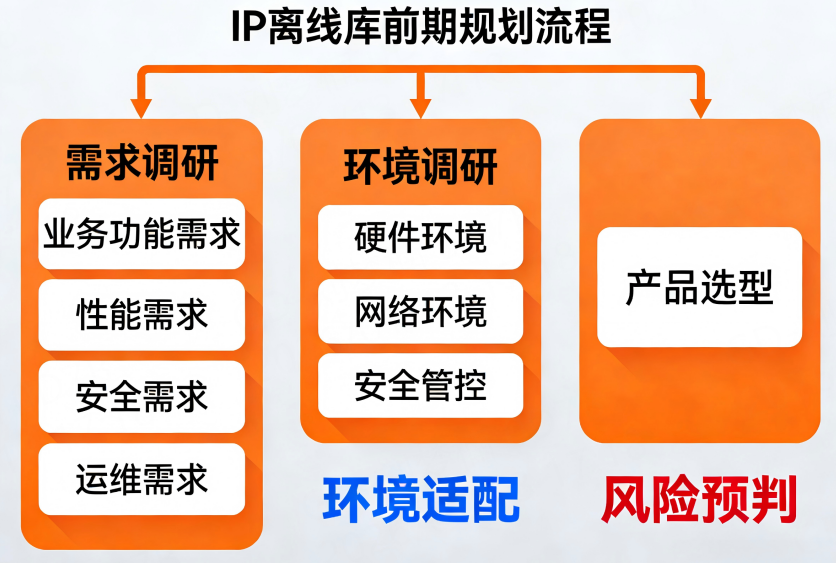
一、前期规划:适配内网环境的核心准备
内网环境的特殊性(无外网、安全管控严格、系统封闭)决定了前期规划需重点解决"环境适配、产品选型、风险预判"三大问题,避免后期返工。
1. 核心需求与环境调研
(1)需求梳理(精准匹配业务场景)
| 需求类型 | 具体内容 | 对离线库的核心要求 |
|---|---|---|
| 业务功能需求 | ① 内网设备IP归属定位(部门/工位/负责人);② 公网访问IP溯源(如员工外网访问审计);③ 恶意IP识别(如内网入侵检测) | 支持内网IP自定义映射;公网IP数据全量覆盖;含恶意IP标签库 |
| 性能需求 | ① 并发查询量(如单节点支持100QPS/1000QPS);② 查询延迟(如≤10ms);③ 支持设备规模(如500台/5000台/10万+台) | 适配内网服务器硬件配置;支持高并发优化;本地查询无延迟 |
| 安全需求 | ① 数据不外泄(禁止向公网传输任何数据);② 访问权限管控(仅授权角色可查询);③ 操作日志留存(合规审计) | 纯内网部署,无外网通信模块;支持细粒度权限控制;自带操作日志功能 |
| 运维需求 | ① 数据更新便捷(无外网下的更新方案);② 低运维成本(少人工干预);③ 故障可快速自愈 | 支持离线增量/全量更新;提供自动化运维脚本;具备故障告警机制 |
(2)内网环境调研(避免环境不兼容)
| 调研维度 | 调研内容 | 适配建议 |
|---|---|---|
| 硬件环境 | 服务器CPU、内存、存储容量;是否支持集群部署;存储是否支持加密 | 单机部署:CPU≥4核、内存≥8G、存储≥100G(含数据+日志);集群部署:节点≥3台,支持负载均衡 |
| 软件环境 | 操作系统(Windows Server/Linux CentOS/Ubuntu);现有数据库(MySQL/PostgreSQL);开发语言(Java/Python/Go) | 优先选择支持内网主流系统的离线库;避免引入小众依赖(增加运维成本) |
| 网络环境 | 内网网段规划(如192.168.0.0/16、10.0.0.0/8);服务器网络可达性;是否有机房隔离(如生产网/测试网) | 确保离线库部署服务器与需查询的业务系统网络互通;跨机房部署需打通内网路由 |
| 安全管控 | 是否需要堡垒机访问;文件传输是否需审批(如U盘/内网文件服务器);是否禁用脚本执行 | 提前申请运维权限;规划离线更新包的内网传输路径;脚本需提前通过安全审核 |
2. IP离线数据库选型(内网适配优先级排序)
内网环境选型核心原则:无外网依赖>安全可控>性能适配>运维便捷,优先选择成熟商业离线库(避免开源库的维护风险),主流选型对比如下:
| 选型维度 | IP数据云离线库 | MaxMind GeoIP2离线库 |
|---|---|---|
| 无外网依赖 | 完全离线部署,无任何外网通信模块 | 完全离线部署,支持本地查询 |
| 内网IP支持 | 支持内网IP段自定义映射(部门/负责人/工位),适配企业内网规划 | 仅支持公网IP,内网IP需二次开发适配 |
| 数据更新 | 提供离线增量/全量更新包,支持内网手动/自动同步(无外网依赖) | 需外网下载更新包,内网部署需手动传输,无自动化工具 |
| 安全管控 | 支持数据加密存储(AES-256);细粒度权限控制(读/写/管理);操作日志留存 | 基础权限控制,无数据加密功能,需依赖数据库自身安全策略 |
| 性能适配 | 支持数据库镜像/SDK集成,单机并发≥1000QPS,查询延迟≤10ms | 支持数据库/文件部署,单机并发≥500QPS,查询延迟≤20ms |
| 运维便捷性 | 提供运维手册、自动化脚本(更新/备份/监控);技术支持内网远程协助 | 文档完善,但无针对内网的运维工具,需自主开发 |
| 选型结论:企业级内网系统优先选择【IP数据云离线库】(适配内网自定义需求、安全可控、运维便捷);跨境业务内网系统可补充【MaxMind GeoIP2】(国际IP覆盖广)。 |
|---|
3. 风险预判与规避措施
| 潜在风险 | 规避措施 |
|---|---|
| 环境不兼容(如操作系统/数据库版本不匹配) | 提前获取离线库环境要求,在测试内网搭建模拟环境验证;优先选择支持多环境的离线库 |
| 数据更新困难(无外网无法获取更新包) | 选择提供"离线更新包订阅服务"的厂商(如IP数据云可通过内网文件服务器同步更新包);提前规划更新包内网传输路径 |
| 安全合规风险(数据外泄/权限滥用) | 选择支持数据加密和细粒度权限控制的离线库;禁用所有外网通信功能;留存操作日志至少6个月 |
| 性能瓶颈(高并发下查询延迟过高) | 根据业务并发需求选择部署模式(如高并发场景选集群部署);提前进行压力测试,验证性能指标 |
二、搭建实施:内网环境下的部署落地步骤
以"IP数据云离线库(数据库镜像部署模式)"为例(适配中型企业内网,支持高并发、自定义内网IP),分6个步骤完成搭建,全程无外网依赖。
1. 前置准备(权限与环境配置)
-
权限申请:向内网运维团队申请服务器访问权限(堡垒机/本地登录)、数据库创建权限、文件传输权限(如内网U盘/文件服务器访问权限);
-
环境配置:
○ 操作系统:确认服务器为CentOS 7+/Ubuntu 18.04+/Windows Server 2016+(符合IP数据云离线库要求);
○ 数据库:部署MySQL 8.0+/PostgreSQL 12+(提前创建空数据库,字符集设为utf8mb4);
○ 安全配置:开启服务器防火墙,仅开放内网授权端口(如3306用于数据库访问、8080用于API查询);配置数据库用户权限(仅给离线库分配"读/写"权限,禁止root权限);
- 离线包获取:通过厂商提供的内网传输渠道(如企业内网文件服务器、加密U盘)获取IP数据云离线库全量包(含数据库镜像.sql文件、部署手册、SDK包)。
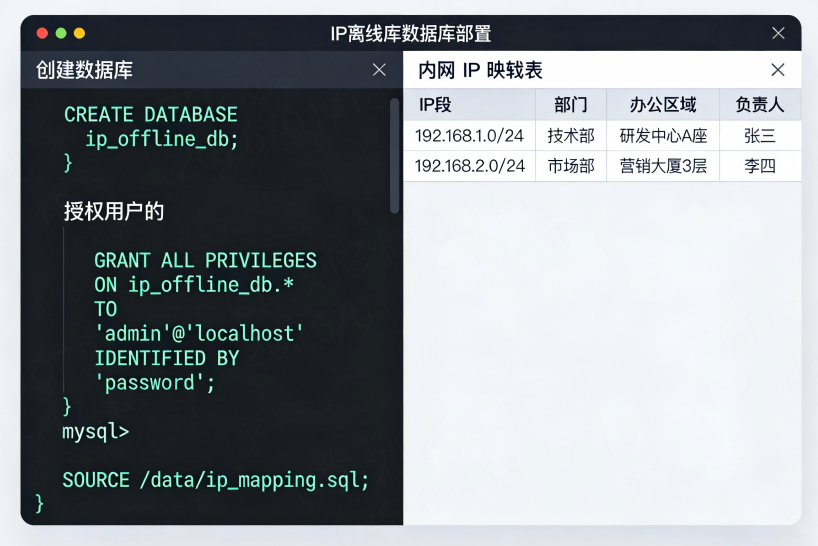
2. 数据库部署(核心步骤)
- 登录内网数据库服务器,执行以下命令创建专用数据库(以MySQL为例):
python
-- 创建数据库
CREATE DATABASE ip_cloud_db CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
-- 创建专用用户并授权
CREATE USER 'ipdb_user'@'%' IDENTIFIED BY 'SecurePassword123!'; -- 强密码,定期更换
GRANT SELECT, INSERT, UPDATE ON ip_cloud_db.* TO 'ipdb_user'@'%';
FLUSH PRIVILEGES;- 导入全量数据:将IP数据云离线库的全量镜像文件(ip_cloud_full.sql)上传至服务器/opt/ipdb目录,执行导入命令:
python
mysql -u ipdb_user -p ip_cloud_db < /opt/ipdb/ip_cloud_full.sql说明:
全量数据导入耗时约30-60分钟(取决于服务器性能),导入过程中避免中断;
导入完成后可通过SELECT COUNT(*) FROM ip_info;
查询数据量(公网IP全量约43亿条,含IPv4/IPv6)。
- 内网IP自定义映射(内网核心配置):
为实现内网设备精准定位,需在数据库中创建内网IP映射表,绑定部门、负责人、工位等信息:
python
-- 创建内网IP映射表
CREATE TABLE internal_ip_map (
id INT AUTO_INCREMENT PRIMARY KEY,
ip_start VARCHAR(15) NOT NULL COMMENT '内网IP段起始(如192.168.1.0)',
ip_end VARCHAR(15) NOT NULL COMMENT '内网IP段结束(如192.168.1.255)',
department VARCHAR(50) NOT NULL COMMENT '归属部门(如研发部-后端组)',
office_area VARCHAR(50) COMMENT '办公区域(如总部3楼302室)',
device_owner VARCHAR(20) COMMENT '设备负责人(姓名/工号)',
mac_bind VARCHAR(20) COMMENT '绑定MAC地址(可选)',
create_time DATETIME DEFAULT CURRENT_TIMESTAMP,
update_time DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
UNIQUE KEY uk_ip_range (ip_start, ip_end)
) COMMENT '内网IP段自定义映射表';导入内网IP规划数据:将企业内网IP规划表(Excel格式)转换为SQL导入脚本,执行导入(示例:192.168.1.0/24段归属研发部):INSERT INTO internal_ip_map (ip_start, ip_end, department, office_area, device_owner)
VALUES ('192.168.1.0', '192.168.1.255', '研发部-后端组', '总部3楼302室', '张三/工号1001');3. 服务集成(与内网业务系统对接)
通过SDK集成或API调用,实现内网业务系统与IP离线库的联动,支持两种集成方式:
(1)SDK集成(高并发场景,如游戏/监控系统)
-
从离线包中获取IP数据云对应开发语言的SDK(如Java/Python/Go),上传至内网代码仓库;
-
在业务系统代码中引入SDK,配置离线库数据库连接信息(内网地址、端口、用户名、密码):// Java SDK示例(查询IP归属信息)
python
import com.ipdatacloud.sdk.OfflineIPQuery;
import com.ipdatacloud.sdk.config.DBConfig;
public class IPQueryDemo {
public static void main(String[] args) {
// 配置内网数据库连接
DBConfig dbConfig = new DBConfig();
dbConfig.setUrl("jdbc:mysql://192.168.0.100:3306/ip_cloud_db");
dbConfig.setUsername("ipdb_user");
dbConfig.setPassword("SecurePassword123!");
// 初始化查询客户端
OfflineIPQuery queryClient = new OfflineIPQuery(dbConfig);
// 查询IP信息(支持内网/公网IP)
String ip = "192.168.1.10"; // 内网IP
String result = queryClient.query(ip);
System.out.println("IP归属信息:" + result);
// 输出示例:{"ip":"192.168.1.10","department":"研发部-后端组","office_area":"总部3楼302室","device_owner":"张三/工号1001"}
}
}- 编译部署业务系统,测试IP查询功能(确保内网/公网IP均能正常返回结果)。
(2)API服务部署(低并发场景,如OA/审计系统)
-
部署IP数据云提供的内网API服务端(基于Spring Boot开发,可直接部署在Tomcat/Jetty中);
-
配置API服务端的数据库连接信息(同SDK集成),并设置访问权限(仅允许内网授权IP访问);
-
业务系统通过内网HTTP请求调用API查询IP信息:# 内网API调用示例(curl命令)
python
curl -X GET "http://192.168.0.101:8080/ip/query?ip=117.136.xx.xx"
# 输出示例:
{"ip":"117.136.xx.xx"
"country":"中国"
"province":"广东省"
"city":"深圳市","isp":"中国电信"
"is_malicious":false}4. 测试验证(确保部署成功)
(1)功能测试
• 内网IP查询:查询已配置的内网IP段(如192.168.1.10),验证部门、负责人等信息是否正确;
• 公网IP查询:查询已知公网IP(如百度IP 180.101.49.12),验证归属地、运营商信息是否准确;
• 恶意IP查询:查询已知恶意IP(如攻击IP 209.141.56.xx),验证是否能正确标记"恶意IP"标签。
(2)性能测试
• 并发测试:使用JMeter模拟1000QPS并发查询,验证查询延迟≤10ms,无请求失败;
• 压力测试:持续30分钟高并发查询,监控服务器CPU、内存、数据库连接数(确保无资源耗尽风险)。
(3)安全测试
• 权限测试:使用未授权账号/IP访问数据库/API,验证是否被拒绝;
• 数据加密测试:检查数据库中敏感字段(如负责人信息)是否加密存储;
• 日志测试:执行查询操作后,验证操作日志是否正常留存(含操作人、IP、时间、查询内容)。
三、维护优化:内网环境下的长期稳定运行保障
内网离线库的维护核心是"数据准确更新、性能稳定、故障快速恢复",需建立标准化运维流程,减少人工干预。
1. 数据更新(核心维护任务,确保数据时效性)
内网无外网,需通过"离线更新包+内网同步"的方式更新数据,推荐两种更新方案:
(1)增量更新(每日执行,仅更新变更数据)
-
获取增量更新包:通过厂商内网渠道(如每日定时推送至企业内网文件服务器)获取IP数据云每日增量更新包(仅含变更IP段,约10-50MB/天);
-
自动化更新脚本:编写Shell脚本(update_ipdb_incremental.sh),实现自动下载更新包并导入数据库:
内网增量更新脚本
1. 从内网文件服务器下载增量更新包
python
wget -O /opt/ipdb/incremental.sql http://192.168.0.200/ipdb/update/$(date +%Y%m%d).sql 2. 导入增量数据
python
mysql -u ipdb_user -p'SecurePassword123!' ip_cloud_db < /opt/ipdb/incremental.sql 3. 记录更新日志
python
echo "$(date +'%Y-%m-%d %H:%M:%S') 增量更新完成" >> /var/log/ipdb_update.log 4. 清理3天前的更新包
python
find /opt/ipdb -name "*.sql" -mtime +3 -delete- 定时任务配置:通过crontab设置每日凌晨2点执行增量更新(避开业务高峰期):
python
0 2 * * * /opt/ipdb/update_ipdb_incremental.sh(2)全量更新(每月执行,避免增量误差累积)
-
获取全量更新包:每月1日从厂商内网渠道获取全量更新包(约5-10GB);
-
手动执行更新:在业务低峰期(如凌晨0点)执行全量更新(先备份旧数据,避免更新失败):
内网全量更新脚本(含备份)
1. 备份旧数据库
python
mysqldump -u ipdb_user -p'SecurePassword123!' ip_cloud_db > /opt/ipdb/backup/ip_cloud_db_$(date +%Y%m%d).sql 2. 导入全量数据(先清空旧表)
python
mysql -u ipdb_user -p'SecurePassword123!' ip_cloud_db -e "TRUNCATE TABLE ip_info;"
mysql -u ipdb_user -p'SecurePassword123!' ip_cloud_db < /opt/ipdb/full_update/ip_cloud_full_$(date +%Y%m).sql 3. 恢复内网IP映射表(全量更新不会覆盖自定义表)
python
mysql -u ipdb_user -p'SecurePassword123!' ip_cloud_db < /opt/ipdb/backup/internal_ip_map_backup.sql 4. 记录更新日志
python
echo "$(date +'%Y-%m-%d %H:%M:%S') 全量更新完成" >> /var/log/ipdb_update.log- 更新后验证:执行查询测试,确保数据正常(若更新失败,可通过备份文件回滚)。
(3)内网IP映射表更新
当企业组织架构调整、工位变动时,需同步更新internal_ip_map表:
• 建立变更申请流程:部门提交IP映射变更申请(含变更IP段、新部门/负责人信息);
• 运维人员审核后执行更新:
-- 示例:更新192.168.1.0/24段的负责人信息
python
UPDATE internal_ip_map
SET device_owner = '李四/工号1002', update_time = NOW()
WHERE ip_start = '192.168.1.0' AND ip_end = '192.168.1.255';2. 日常运维(标准化流程)
| 运维周期 | 运维内容 | 操作方式 |
|---|---|---|
| 每日 | ① 检查增量更新日志(确认更新成功);② 监控数据库查询延迟;③ 清理过期日志(如API访问日志) | 查看/var/log/ipdb_update.log;执行SQL:SELECT NOW() - execution_time FROM query_log LIMIT 10;执行日志清理脚本 |
| 每周 | ① 备份数据库(全量备份);② 检查服务器资源使用情况(CPU/内存/存储);③ 验证内网IP映射表准确性 | 执行mysqldump备份;通过top/df命令查看资源;对比OA部门信息与internal_ip_map表 |
| 每月 | ① 执行全量更新;② 压力测试(验证性能是否达标);③ 权限审计(清理无效账号/IP权限) | 运行全量更新脚本;用JMeter模拟并发;查询数据库用户表/API访问控制列表 |
| 每季度 | ① 服务器系统更新(补丁修复);② 数据库性能优化(如重建索引);③ 全量备份文件归档(异地存储) | 通过内网yum/apt更新系统;执行ALTER TABLE ip_info FORCE重建索引;将备份文件复制至内网异地存储 |
3. 性能优化(提升查询效率)
(1)数据库优化
• 索引优化:确保ip_info表的ip字段、ip_start/ip_end字段创建索引(默认已创建,定期维护);
• 分区表优化:对于超大规模部署(如10万+设备并发),将ip_info表按IP段分区(如按IPv4/IPv6分区、按地域分区),提升查询效率;
• 连接池优化:配置数据库连接池参数(如MySQL的max_connections设为1000,适配高并发查询)。
(2)缓存优化
• 本地缓存:在API服务端/SDK中启用本地缓存(如Caffeine缓存),缓存高频查询IP(如内网常用IP),减少数据库访问;
• 分布式缓存:大型内网系统可部署Redis缓存集群,缓存全量高频IP数据(如热门公网IP、内网IP),查询延迟可降至1ms内。
(3)集群部署优化(高并发场景)
当单机部署无法满足并发需求时,可部署IP离线库集群:
-
数据库主从复制:部署1主2从数据库集群,主库负责数据更新,从库负责查询,通过读写分离提升并发能力;
-
API服务负载均衡:在多台服务器部署API服务端,通过内网负载均衡器(如Nginx/LVS)分发查询请求;
-
缓存集群同步:确保Redis缓存集群数据同步,避免查询结果不一致。
四、应急处置:内网环境下的故障解决预案
针对内网离线库常见故障(查询失败、更新失败、性能下降),制定快速处置流程,确保业务影响最小化。
1. 常见故障处置方案
| 故障现象 | 排查方向 | 处置步骤 |
|---|---|---|
| IP查询无结果/报错 | ① 数据库连接失败;② 数据导入不完整;③ SDK/API配置错误 | 1. 检查数据库服务是否正常(systemctl status mysqld);2. 验证数据库连接信息(用户名/密码/地址);3. 查询ip_info表数据量(确认数据完整);4. 重启API服务/业务系统 |
| 增量更新失败 | ① 更新包损坏/不完整;② 数据库权限不足;③ 表结构不兼容 | 1. 重新从内网文件服务器获取更新包(验证MD5值);2. 检查ipdb_user用户是否有INSERT/UPDATE权限;3. 查看更新日志中的错误信息(如SQL语法错误);4. 若无法修复,跳过当日增量,次日全量更新时修复 |
| 查询延迟突然升高 | ① 数据库索引失效;② 服务器资源耗尽;③ 并发量超出上限 | 1. 重建数据库索引(ALTER TABLE ip_info FORCE);2. 查看服务器资源(top/df,若内存不足则扩容,若存储满则清理日志);3. 临时限制非核心业务查询,优先保障核心业务;4. 若为并发超上限,临时扩容API服务节点 |
| 数据泄露风险(如未授权访问) | ① 权限配置错误;② API访问控制失效;③ 账号密码泄露 | 1. 立即禁用可疑账号,重置数据库/API密码;2. 重新配置访问权限(仅允许授权IP/角色访问);3. 审计操作日志,确认泄露范围;4. 加固安全配置(如开启数据库加密、API访问日志留存) |
2. 灾备方案(数据安全保障)
• 本地备份:每日增量备份+每周全量备份,备份文件存储在本地服务器(加密存储);
• 异地备份:每月将全量备份文件复制至内网异地存储服务器(如不同机房),避免单点故障;
• 灾备切换:若主服务器故障,快速在备用服务器部署离线库,导入最新备份文件,切换API/SDK的数据库连接地址,恢复查询服务。
五、方案优势与选型建议
1. 本方案核心优势
• 完全适配内网环境:全程无外网依赖,所有操作均在内网完成,符合安全管控要求;
• 灵活适配不同规模:支持单机/集群部署,适配小型/中型/大型企业内网架构;
• 安全可控:数据加密存储、细粒度权限控制、操作日志留存,满足合规审计需求;
• 运维便捷:提供自动化更新/备份脚本,标准化运维流程,降低人工成本;
• 内网自定义能力强:支持内网IP段精准映射,适配企业组织架构和工位规划。
2. 选型与部署建议
• 小型企业内网(≤500台设备,低并发):选择IP数据云离线库单机文件部署模式,无需数据库,直接通过脚本查询,降低运维成本;
• 中型企业内网(500-5000台设备,中并发):选择本方案的数据库镜像+API服务部署模式,平衡性能与运维成本;
• 大型企业内网(≥5000台设备,高并发):选择集群部署模式(主从数据库+API负载均衡+Redis缓存),确保高可用性和低延迟;
• 跨境业务内网:主选IP数据云离线库(内网适配),补充MaxMind GeoIP2离线库(国际IP覆盖),通过SDK集成实现双库联动查询。
通过本方案的实施,可在严格管控的内网环境中搭建稳定、安全、精准的IP离线数据库,为内网设备监控、安全审计、业务管理提供核心IP数据支撑,同时实现全生命周期的低成本运维,确保长期稳定运行。