一、介绍
图数据库擅长处理复杂关联关系,而 PostgreSQL 擅长事务型数据管理。Apache AGE 通过扩展方式将图数据库能力引入 PostgreSQL,使其在保持原有稳定性与生态优势的同时,补齐了图数据建模与查询能力的短板。这种"关系型数据库 + 图模型"的融合架构,为需要同时处理强事务与复杂关系的数据场景提供了一种务实且高性价比的技术路径。
二、架构
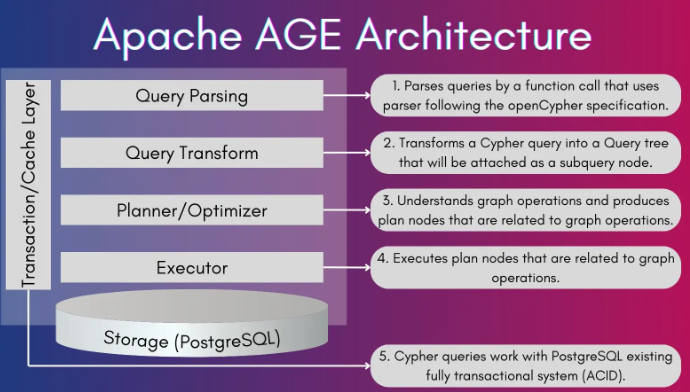
Apache AGE 是一个 PostgreSQL 的扩展,用户能够在现有关系数据库中使用图数据库。AGE 是 A Graph Extension 的缩写。
特点
- 采用符合 OpenCypher 规范的查询解析器,支持标准化的图查询语言;
- 将 Cypher 查询语句 转换为 PostgreSQL 可识别和执行的内部查询表示;
- 能够解析和理解图数据操作语义,并生成对应的 图查询执行计划;
- 按照生成的执行计划高效执行图查询与图计算操作;
- 在执行 Cypher 查询的同时,完整继承 PostgreSQL 的 ACID 事务特性,确保数据一致性与可靠性。
三、配置AGE插件
-
安装Apache AGE图扩展插件
#编译安装插件
yum install gcc glibc glib-common readline readline-devel zlib zlib-devel flex bison
make PG_CONFIG=/usr/local/pgsql17/bin/pg_config install
 加载扩展插件
加载扩展插件
#AGE这个插件与其他插件不同,安装后。为了让数据库能够找到 AGE 的函数,如 create_graph(),还需要设置搜索路径。
create extension age;
LOAD 'age';
SET search_path = ag_catalog, "$user", public;四、图形在PostgreSQL中的存储形态
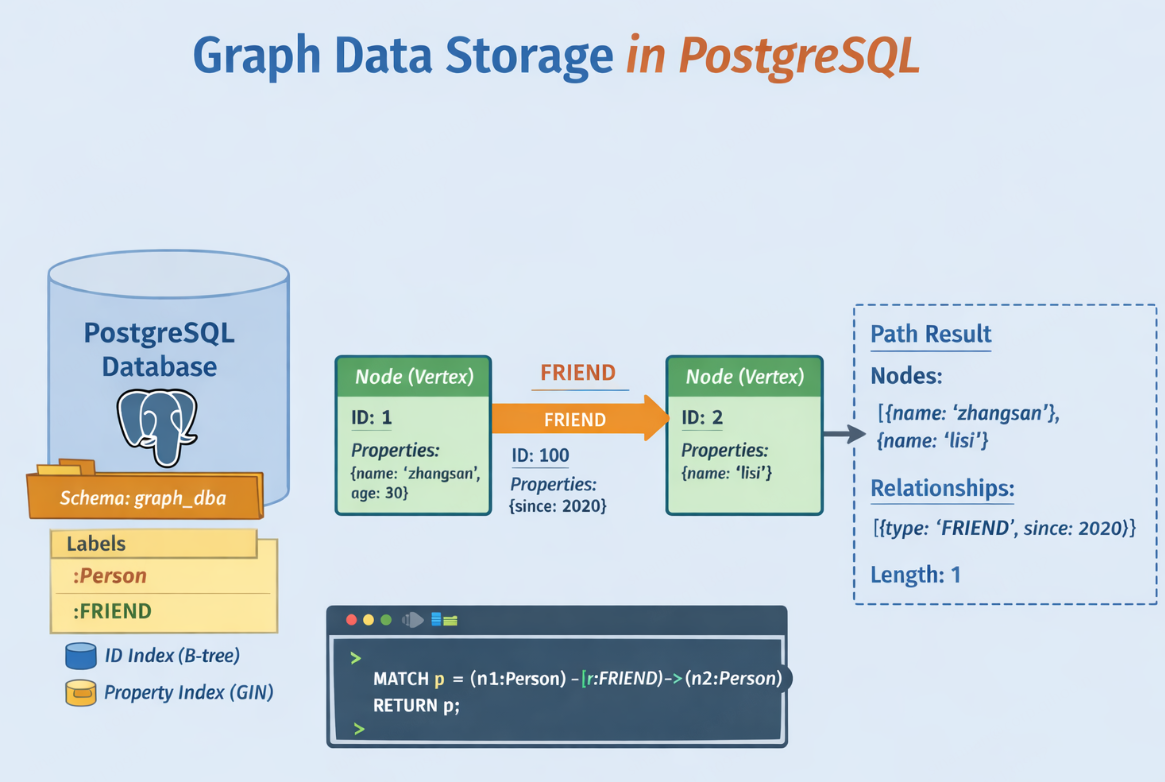
在使用AGE创建图表时,将为每个单独的图生成一个命名空间。 创建的图可以在ag_catalog命名空间的ag_graph表中查看:
graphid | name | namespace
---------+------------+------------
17012 | graph_dba | graph_dba
17034 | graph_test | graph_test创建图表后,在图表的命名空间下将创建两个表来存储顶点和边:_ag_label_vertex 和 _ag_label_edge,这两个表作为点和边表的母表,之后创建任何类型的点表和边表都继承该表。同时,会将_ag_label_vertex和_ag_label_edge作为点和边表的信息插入ag_label中
-
name → 标签名称或内部标签名
-
graph → 图的唯一 ID
-
id → 标签唯一 ID
-
kind → 'v' 节点或 'e' 边
-
relation → 底层 PostgreSQL 表名
-
seq_name → 自增序列名(ID 自增用)
name | graph | id | kind | relation | seq_name------------------+-------+----+------+-----------------------------+-------------------------
_ag_label_vertex | 17012 | 1 | v | graph_dba._ag_label_vertex | _ag_label_vertex_id_seq
_ag_label_edge | 17012 | 2 | e | graph_dba._ag_label_edge | _ag_label_edge_id_seq
Person | 17012 | 3 | v | graph_dba."Person" | Person_id_seq
FRIEND | 17012 | 4 | e | graph_dba."FRIEND" | FATHER_id_seq
节点表记录了节点的属性,关系表则记录了点之间的联系
select * from graph_dba."Person";
id | properties
-----------------+----------------------
844424930131975 | {"name": "Jack"}
844424930131976 | {"name": "Tom"}
select * from graph_dba."FRIEND";
id | start_id | end_id | properties
------------------+-----------------+-----------------+-----------------
1407374883553282 | 844424930131975 | 844424930131976 | {"since": 2015}
1407374883553283 | 844424930131976 | 844424930131975 | {"since": 2015}五、语法解析
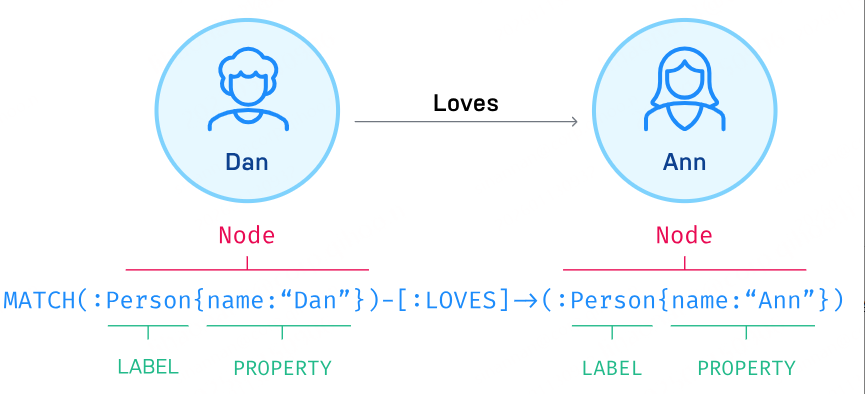
5.1 Cypher语法
- **节点(node) :**图中的实体,可以设置标签(Label)表示类型,设置属性(Property)存储信息
- **关系(Relationship):**连接两个节点,表示二者之间的联系. 拥有方向(单向或者双向),同样可以设置标签及属性
- **核心语法:**MATCH:匹配节点和关系、WHERE:过滤条件。RETURN:返回结果。
5.2 SQL语法与Cypher语法的结合
-
在 Apache AGE 中,所有 Cypher 都必须通过 SQL 函数调用 ,不能直接执行 MATCH,必须显式声明返回列结构。调用的Cypher语法必须使用**$$包裹,**避免SQL Parser冲突
SELECT *
FROM cypher('graph_dba', //SQL调用Cypher函数,查询图graph_dbaMATCH (n) //Cypher匹配所有节点 RETURN n )
AS (n agtype); //返回JSON类型结果 -
图操作
1、创建&&删除
SELECT * FROM ag_catalog.create_graph('graph_dba');
SELECT * FROM ag_catalog.drop_graph('graph_dba', true);
graphid | name | namespace
---------+------------+------------
17012 | graph_dba | graph_dba -
节点操作
#创建多个点
SELECT *
FROM cypher(
'graph_dba',
UNWIND [ {name:'zhang3'}, {name:'li4'} ] AS row CREATE (p:Person { name: row.name }) RETURN p
) AS (p agtype);
p{"id": 844424930131969, "label": "Person", "properties": {"name": "zhang3"}}::vertex
{"id": 844424930131970, "label": "Person", "properties": {"name": "li4"}}::vertex -
关系(边)操作
#创建点之间的关系
SELECT *
FROM cypher(
'graph_dba',
MATCH (a:Person {name:'zhang3'}), (b:Person {name:'li4'}) MERGE (a)-[r:FRIENDS {since:2001}]->(b) RETURN r
) AS (r agtype);
r{"id": 1125899906842625, "label": "FRIENDS", "end_id": 844424930131970, "start_id": 844424930131969, "properties": {"since": 2001}}::edge
-
查询
#根据关系及关系的属性进行匹配查询
SELECT *
FROM cypher(
'graph_dba',
MATCH (a:Person {name:'zhang3'})-[r:FRIENDS]->(b:Person) WHERE r.since = 2001 RETURN b
) AS (b agtype);
b{"id": 844424930131970, "label": "Person", "properties": {"name": "li4"}}::vertex
六、 应用样例
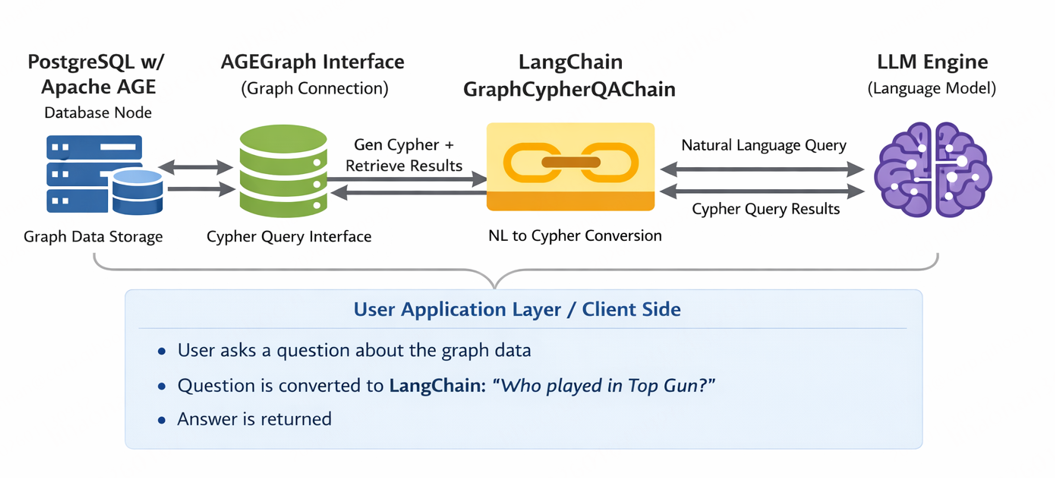
用户在 应用层 提出自然语言查询。该问题首先传入 LangChain 的 GraphCypherQAChain ,链内部调用 LLM 引擎 将自然语言自动转换为 Cypher 查询语句 。生成的 Cypher 查询通过 AGE图实例 (AGEGraph)发送到 PostgreSQL + Apache AGE 图数据库 执行,检索出对应的图结构数据(节点、关系及属性)。数据库返回的结果再次由 LLM 解析和整理,最终以自然语言答案的形式返回给用户。
from langchain_community.graphs.age_graph import AGEGraph
from langchain.chains import GraphCypherQAChain
from langchain_openai import ChatOpenAI
def main():
# 1. 配置并连接 Apache AGE 图数据库
conf = {
"database": "postgresDB",
"user": "postgresUser",
"password": "postgresPW",
"host": "localhost",
"port": 5432,
}
# graph_name 是 AGE 中的具体图名称
graph = AGEGraph(graph_name="age_test", conf=conf)
# 2. 填充一些示例图数据(如果数据库为空)
graph.query(
"""
MERGE (m:Movie {name: 'Top Gun'})
WITH m
UNWIND ['Tom Cruise', 'Val Kilmer', 'Anthony Edwards', 'Meg Ryan'] AS actor
MERGE (a:Actor {name: actor})
MERGE (a)-[:ACTED_IN]->(m)
"""
)
# 3. 使用 ChatOpenAI LLM 创建 LangChain 查询链
llm = ChatOpenAI(temperature=0) # 使用默认模型
chain = GraphCypherQAChain.from_llm(
llm,
graph=graph,
verbose=True,
allow_dangerous_requests=True
)
# 4. 输入自然语言查询
question = "Who played in Top Gun?"
# 5. 执行链并输出结果
response = chain.invoke(question)
print("自然语言查询:", response["query"])
print("生成答案:", response["result"])
if __name__ == "__main__":
main()七、总结
在 PostgreSQL 图数据库化的实践中,Apache AGE 的引入为传统关系型数据库注入了强大的图计算能力。作为 PostgreSQL 的插件,AGE 无需额外独立部署,便可在熟悉的数据库环境中管理节点、关系及属性,实现图数据的存储与查询。其原生支持 Cypher 查询语言,使得图分析与知识图谱构建变得更为简便,同时保留了 PostgreSQL 在事务管理、扩展性和生态兼容性方面的优势。如需启用或试用相关能力,请联系 DBA 进行评估与支持。未来,我们计划在此基础上引入更多 PostgreSQL 插件,进一步拓展数据库的功能边界,为企业数据应用提供更多可能性。
HULK云数据库产品,提供一站式全生命周期数据库服务自助管理能力,产品访问地址请联系人工客服。