一、 List 家族全景图
首先,你要清楚 List 接口的核心特点:有序(存储顺序和插入顺序一致)、可重复、支持索引访问。
主要实现类如下:
ArrayList:动态数组(面试绝对核心,90% 的场景都用它)。
LinkedList:双向链表(作为对比陪跑,但需了解其作为队列/栈的特性)。
Vector:古老的线程安全数组(全同步,性能差,已淘汰)。
CopyOnWriteArrayList:JUC 包下的并发 List(读写分离,读多写少场景)。
二、 核心王者:ArrayList (深度剖析)
- 底层结构
结构:Object\[\] elementData。
特点:内存连续,支持快速随机访问(Random Access)。 - 初始化与懒加载 (JDK 1.8 变化)
JDK 1.7:new ArrayList() 时,直接创建一个长度为 10 的数组。
JDK 1.8:new ArrayList() 时,赋值为一个空数组 (DEFAULTCAPACITY_EMPTY_ELEMENTDATA)。
懒加载:只有当第一次调用 add() 方法时,才真正将数组初始化为默认容量 10。
目的:节省内存。如果创建了 List 但没用,就不占用空间。 - 扩容机制 (Grow)
当 add 元素导致数组满了,会触发扩容:
计算新容量:
java
复制
int newCapacity = oldCapacity + (oldCapacity >> 1);
公式:old + 0.5 * old,即扩容为原来的 1.5 倍。
对比:Vector 是扩容 2 倍。
数据迁移:
创建一个新的大数组。
调用 System.arraycopy(native 方法,极快)将旧数据复制过去。
代价:扩容是高成本操作。
优化建议:如果你知道大概的数据量,请在构造时指定 initialCapacity,避免频繁扩容。 - 删除元素 (Remove)
尾部删除:O(1),非常快。
中间删除:O(n)。因为删除后,需要把后面的所有元素向前移动一位(填补空缺),依然使用 System.arraycopy。
三、 链表实现:LinkedList - 底层结构
结构:双向链表。
节点:Node 对象,包含 prev (前驱)、next (后继)、item (数据)。
java
复制
private static class Node {
E item;
Node next;
Node prev;
} - 特性
内存:不连续。每个节点都需要额外存储两个引用,内存占用比 ArrayList 高。
访问:不支持随机访问。get(i) 需要从头(或尾)遍历,复杂度 O(n)。
优化:JDK 做了微小优化,如果 i < size/2,从头找;否则从尾找。
插入/删除:
理论上:只要拿到了节点,插入/删除只是修改指针,复杂度 O(1)。
实际上:如果你要"删除第 i 个元素",你得先遍历找到它,这步是 O(n)。只有在使用 Iterator (存在游标,记录了当前节点的索引,不需要再次遍历查询)遍历过程中删除才是真正的 O(1)。 - 额外身份
LinkedList 实现了 Deque (双端队列) 接口。
因此它可以用作 栈 (Stack) 或 队列 (Queue)。
四、 巅峰对决:ArrayList vs LinkedList
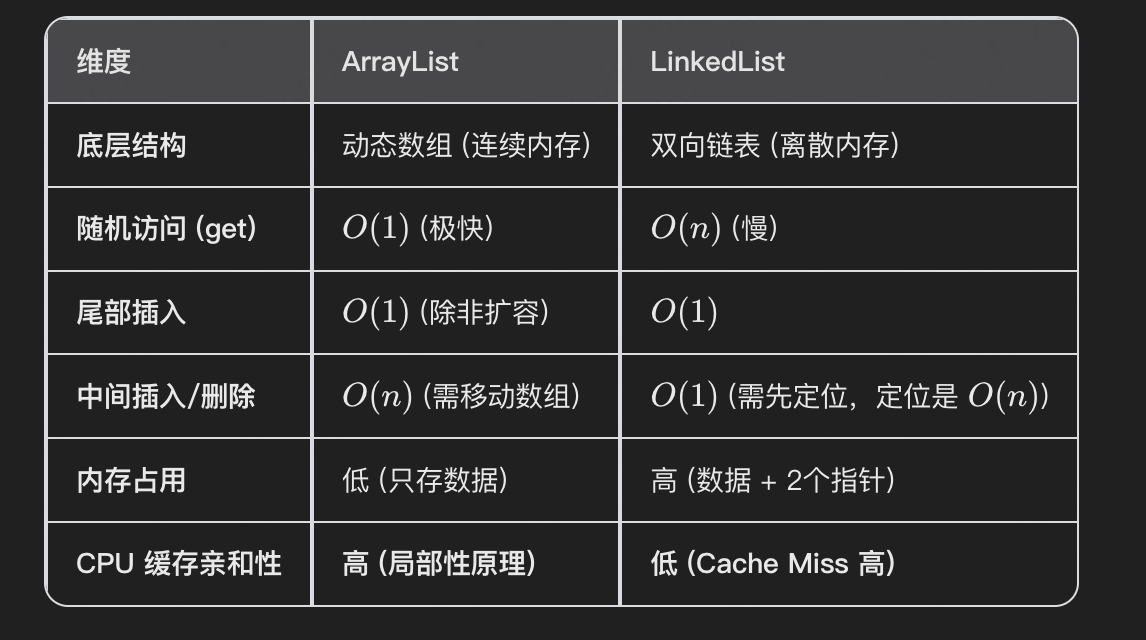
★ 高级回答点:CPU 缓存局部性 (Locality of Reference)
回答:除了随机访问快,还有一个重要原因是 CPU 缓存友好。
ArrayList 的内存是连续的,CPU 读取时会利用预读机制将相邻数据加载到 L1/L2 缓存中,遍历速度极快。
而 LinkedList 内存分散,遍历时频繁发生 Cache Miss(缓存未命中),导致 CPU 必须频繁去主存取数,性能相差巨大。
五、 线程安全 List
- Vector (淘汰)
所有方法加 synchronized。
性能太差,扩容是 2 倍。别用。 - Collections.synchronizedList (不推荐)
包装类,使用 mutex 对象锁。性能一般。 - CopyOnWriteArrayList (JUC 核心)
这是并发场景下的首选 List。
核心原理:写时复制 (COW)
读操作:完全不加锁。直接读取原数组,性能极高。
写操作 (add/set):
加锁 (ReentrantLock)。
复制:将原数组复制一份,长度 +1。
修改:在新数组上执行修改。
替换:将引用指向新数组 (setArray)。
解锁。
优点:读写分离,读性能极佳,适合读多写少(如白名单、配置列表)。
缺点:
内存占用:写的时候内存里会有两份数组。
数据最终一致性:写入的数据,读线程可能不会立马读到(因为没切引用前读的还是旧数组),不适合实时性要求极高的场景。
六、 面试避坑指南 (常见陷阱)
- Arrays.asList() 的坑
java
List<String> list = Arrays.asList("a", "b");
list.add("c"); // 报错!UnsupportedOperationException原因:它返回的不是 java.util.ArrayList,而是 Arrays 内部的一个静态内部类。
特点:它是固定长度的,没有重写 add/remove 方法。
- subList 的坑
java
List<String> sub = list.subList(0, 2);特点:返回的不是新 List,而是原 List 的一个视图 (View)。
坑:
修改 sub 会影响原 list。
修改原 list(结构性修改,如 add/remove),会导致 sub 遍历时抛出 ConcurrentModificationException。
内存泄漏:如果你有一个巨大的 List,截取了一个小的 subList 并且长期持有,那么整个大 List 的数组都无法被 GC 回收(因为 subList 强引用了原数组)。
- 循环删除的坑
错误写法
java
for (String s : list) {
if ("a".equals(s)) list.remove(s); // 抛出 ConcurrentModificationException
}正确写法
java
Iterator<String> it = list.iterator();
while (it.hasNext()) {
if ("a".equals(it.next())) {
it.remove(); // 必须用迭代器的 remove
}
}原理:ArrayList 内部维护了一个 modCount 变量,记录修改次数。迭代器在遍历时会检查 expectedModCount == modCount,如果不一致(外部修改了),就报错(Fail-Fast 机制)。
七、 总结
首选:99% 的情况用 ArrayList。
队列/栈:用 LinkedList 或 ArrayDeque。
并发读多写少:用 CopyOnWriteArrayList。
扩容:ArrayList 扩容 1.5 倍,尽量指定初始容量。
性能:ArrayList 赢在随机访问和 CPU 缓存亲和性。