前言
经过之前文章的学习我们明白了YOLO算法中的V1,V2,V3的三个版本中的层层迭代优化,也分析到了前三个yolo版本的特点。
⭐⭐⭐
YOLOv1 特点:( 单网直出框,七格俩框忙,直回归宽高,小目标易忘)
YOLOv2 特点:( 锚框定机制,骨干强基础,Passthrough 补小目标,多尺度扩场景)
YOLOv3 特点:( 九框三尺度,Darknet-53 加残差,FPN 拼层补小目标,多标签分类更灵活)
接下来我进一步整理关键性版本YOLOv4和YOLOv5这两个具有代表性的yolo版本
YOLOv4的概述
⭐YOLOv4 (2020)
1.简要概述:
核心目的: 「在保证实时性(速度)的前提下,最大限度提升检测精度」
工程化极致优化,工业级标杆
骨干网:CSPDarknet-53(引入 CSPNet,减少计算量,保持精度);
颈部(Neck):SPP(空间金字塔池化,增大感受野)+ PAN(路径聚合网络,加强特征融合);
训练技巧(核心):
Mosaic 数据增强:4 张图拼接,丰富背景,提升小目标鲁棒性;
CIoU Loss:替代 IOU Loss,考虑框的重叠、中心距离、长宽比,回归更精准;
标签平滑、余弦退火学习率、自对抗训练(SAT)等;
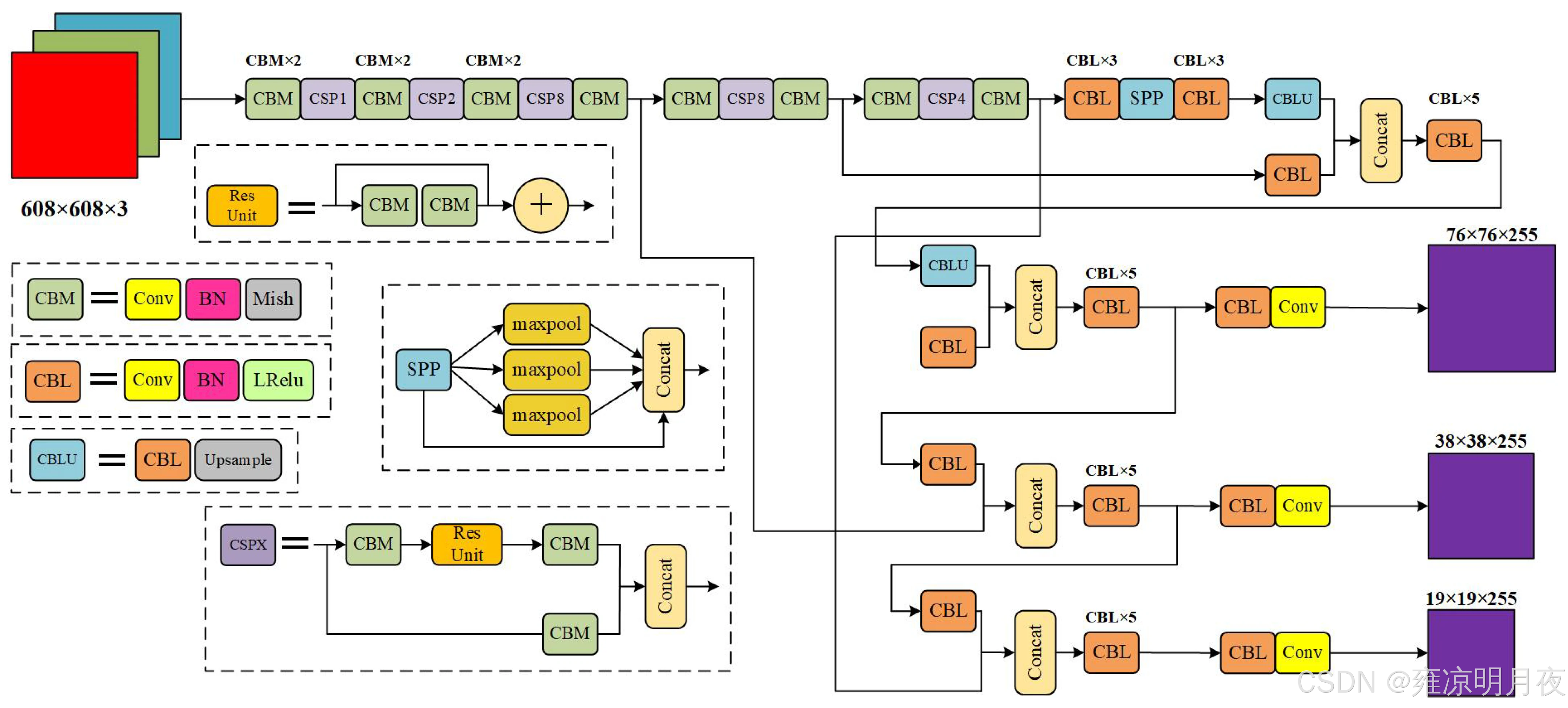
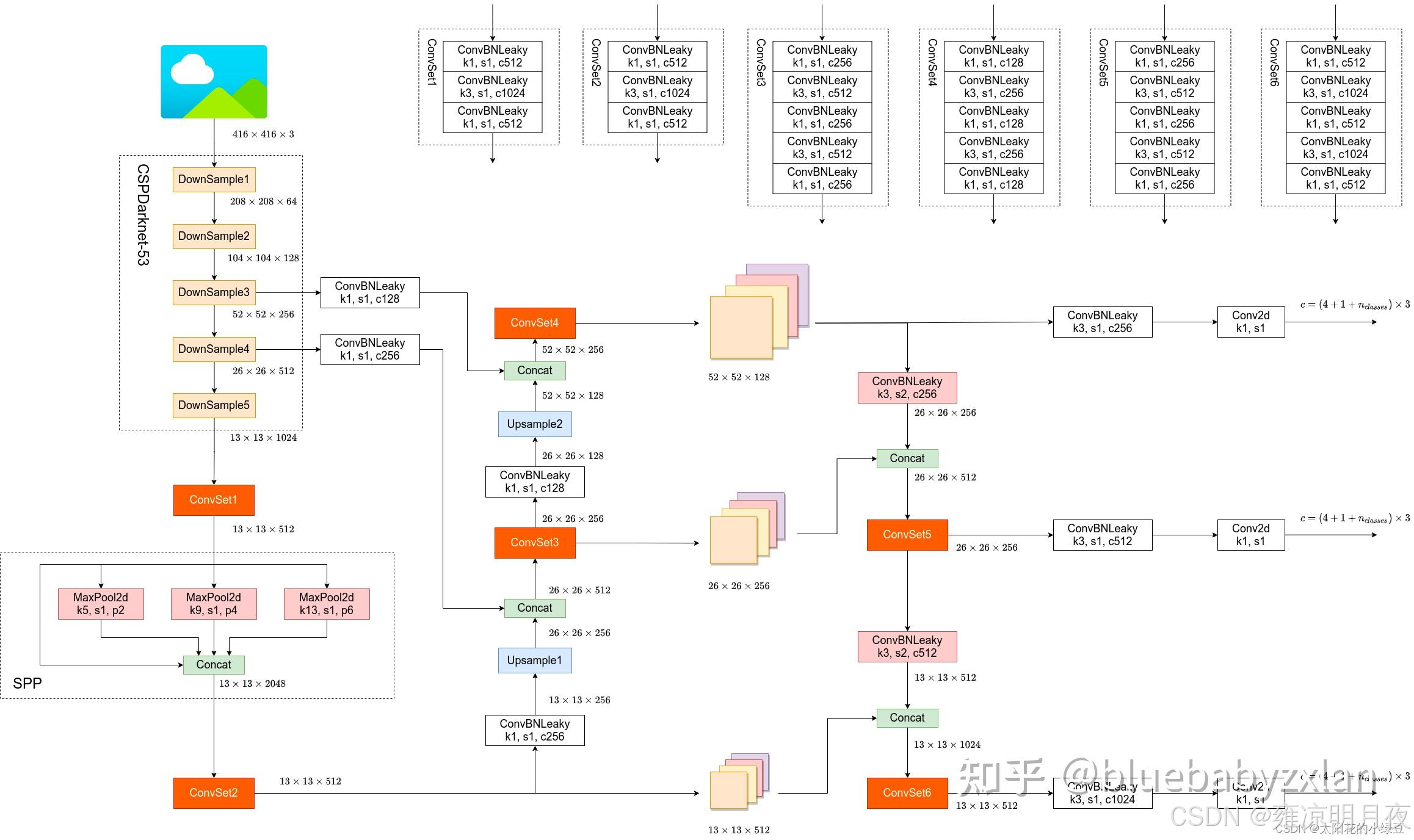
2.认知基础:
yolo系列算法性能有关键评判标准:mAP@0.5
1.IOU@0.5(核心判定条件):IOU是交并比,值越大则越准。
@0.5 的含义 :当
IoU ≥ 0.5时,就判定这个预测框是正确检测 ;反之则判定为错误检测。拓展:这是 COCO 数据集的标准宽松阈值 ,也是行业内对比算法精度的常用基准(如果是
mAP@0.5:0.95,则是从 0.5 到 0.95 每隔 0.05 取一个阈值计算均值,更严格)。AP (单个类别的精度):AP 的全称是 Average Precision ,即平均精度 ,衡量的是单个类别的检测性能,计算逻辑基于两个核心指标:
- Precision(精确率):预测为正样本的结果中,真正是正样本的比例 → 反映 "预测准不准"。
- Recall(召回率):所有真实正样本中,被成功预测出来的比例 → 反映 "漏检多不多"。
AP 的计算方式是:以 Recall 为横轴、Precision 为纵轴绘制 P-R 曲线,曲线下方的面积就是该类别的 AP 值 。AP 取值范围也是
0~1,值越大代表该类别的检测效果越好。

mAP (全类别的平均精度):mean Average Precision ,即平均精度均值 ,是所有类别 AP 值的算术平均值。

mAP@0.5的完整含义在 IoU 阈值为 0.5 的判定标准下,所有类别的平均精度均值。
- 数值范围
0~1,越接近 1 代表算法的整体检测精度越高。- YOLOv4 在 COCO 上
mAP@0.5比 v3 提升约 10%,意味着在 "预测框和真实框重合度≥50% 就算检测正确" 的标准下,v4 对 80 类目标的整体检测准确率提升了 10 个百分点。
YOLOv3的痛点:
1.特征提取能力有限(仅使用 Darknet-53,对小目标、复杂背景目标的特征捕捉不足)
2.训练过程不稳定、收敛慢,且对硬件要求偏高(在普通设备上高效训练出高精度模型难)
YOLO4解决方案:
**「骨干网络优化 + 颈部网络创新 + 头部网络微调 + 训练策略升级」**四位一体
**「精度 - 速度 - 硬件兼容性」**三者间找到最优解。
⭐YOLOv4的精讲
1.理论核心改进:
- 网络结构改进(Backbone+Neck+Head)
- 数据增强策略改进(针对训练集,提升模型泛化能力)
- 训练技巧优化(加速收敛、提升精度,降低硬件门槛)
第一部分:Backbone
骨干网络 ------ CSPDarknet53
核心思想:
为什么要引入CSP?
① 减少计算量(相比 Darknet-53,计算量降低约 50%,保证推理速度)
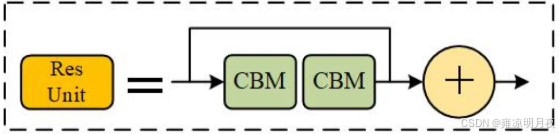
② 缓解梯度消失(残差连接的优化,让深层网络更容易训练,提升特征提取能力)
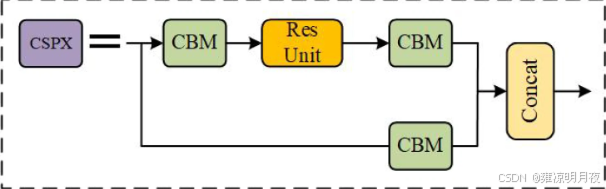
**对比记忆:**CSPDarknet53 = Darknet-53 + 每个残差块中嵌入 CSP 结构,保留了 Darknet-53 的「步长为 2 的卷积下采样(实现特征图尺寸减半、通道数翻倍)」和「残差连接」核心,仅优化了残差块内部结构。
输出的特征图和YOLOv3一样:
- 大尺度特征图:52×52×256(对应小目标,分辨率最高,细节信息最丰富)
- 中尺度特征图:26×26×512(对应中目标,平衡细节和语义信息)
- 小尺度特征图:13×13×1024(对应大目标,分辨率最低,语义信息最丰富)
第二部分:Neck
颈部网络------ SPP + FPN + PANet
YOLOv3的Neck仅使用了FPN(特征金字塔网络),实现【自上而下】的特征融合。
**YOLOv4 的 Neck 是「SPP 模块 + PANet」**大幅提升特征融合效果,这是 YOLOv4 精度提升的核心之一。
1. SPP 模块(Spatial Pyramid Pooling,空间金字塔池化)
作用:进行多尺度池化,解决对大目标检测精度不足的问题。
具体实现:
1.输入:13×13×1024 的特征图
2.操作:对该特征图并行执行 4 种不同尺寸的最大池化(Max Pooling):
① 1×1 池化(无实际池化效果,保留原始特征)'
② 5×5 池化(步长 = 1,填充 = 2,保证输出尺寸不变)
③ 9×9 池化(步长 = 1,填充 = 4,保证输出尺寸不变)
④ 13×13 池化(步长 = 1,填充 = 6,保证输出尺寸不变)
3.输出:将 4 种池化结果在通道维度上拼接(Concatenate)
得到 13×13×(1024×4)=13×13×4096 的特征图,再通过一个 1×1 卷积将通道数压缩回 1024,最终输出 13×13×1024 的特征图(尺寸不变,通道数还原,特征信息更丰富)。
关键注意点:
SPP 模块仅作用于最小尺度特征图(大目标),不改变特征图尺寸,仅增强特征表达能力。
YOLOv5引入的SPPF模块:3个5x5串行的同时进行concat。
SPPF作用:大目标特征融合贡献更多,且比spp快了6ms
2. PANet(Path Aggregation Network,路径聚合网络)
YOLOv3 的 FPN 仅实现「自上而下」(从 13×13→26×26→52×52)的特征融合。
PANet 在 FPN 基础上增加了「自下而上」的特征传递。
形成「自上而下 + 自下而上」的双向特征融合,解决 FPN 中底层特征(大尺度,对应小目标)语义信息不足的问题。
详细步骤:
步骤 1:自上而下融合(继承 FPN,与 YOLOv3 类似)
- 输入:SPP 模块输出的 13×13×1024 特征图
- 操作 1:13×13×1024 → 1×1 卷积(通道数减半为 512)→ 上采样(双线性插值,尺寸翻倍为 26×26)→ 与 CSPDarknet53 输出的 26×26×512 特征图拼接(通道数变为 512+512=1024)→ 经过 2 个 3×3 卷积(通道数还原为 512)→ 输出 26×26×512 特征图。
- 操作 2:26×26×512 特征图 → 1×1 卷积(通道数减半为 256)→ 上采样(尺寸翻倍为 52×52)→ 与 CSPDarknet53 输出的 52×52×256 特征图拼接(通道数变为 256+256=512)→ 经过 2 个 3×3 卷积(通道数还原为 256)→ 输出 52×52×256 特征图。
- FPN:深层上采样与浅层特征concat融合。给浅层补语义为了检出小目标;
步骤 2:自下而上融合(PANet 创新,YOLOv3 无此步骤)
- 操作 1:52×52×256 特征图 → 步长为 2 的 3×3 卷积(尺寸减半为 26×26,通道数翻倍为 512)→ 与步骤 1 中得到的 26×26×512 特征图拼接(通道数变为 512+512=1024)→ 经过 2 个 3×3 卷积(通道数还原为 512)→ 输出 26×26×512 特征图。
- 操作 2:26×26×512 特征图 → 步长为 2 的 3×3 卷积(尺寸减半为 13×13,通道数翻倍为 1024)→ 与步骤 1 中得到的 13×13×1024 特征图拼接(通道数变为 1024+1024=2048)→ 经过 2 个 3×3 卷积(通道数还原为 1024)→ 输出 13×13×1024 特征图。
- PAN:浅 **层下采样与深层特征concat融合。**给深层补定位为了检出大目标;
最终输出:PANet 输出 3 个尺度的特征图(52×52×256、26×26×512、13×13×1024),直接输入到 Head 网络进行检测,这 3 个特征图的特征融合效果远优于 YOLOv3。
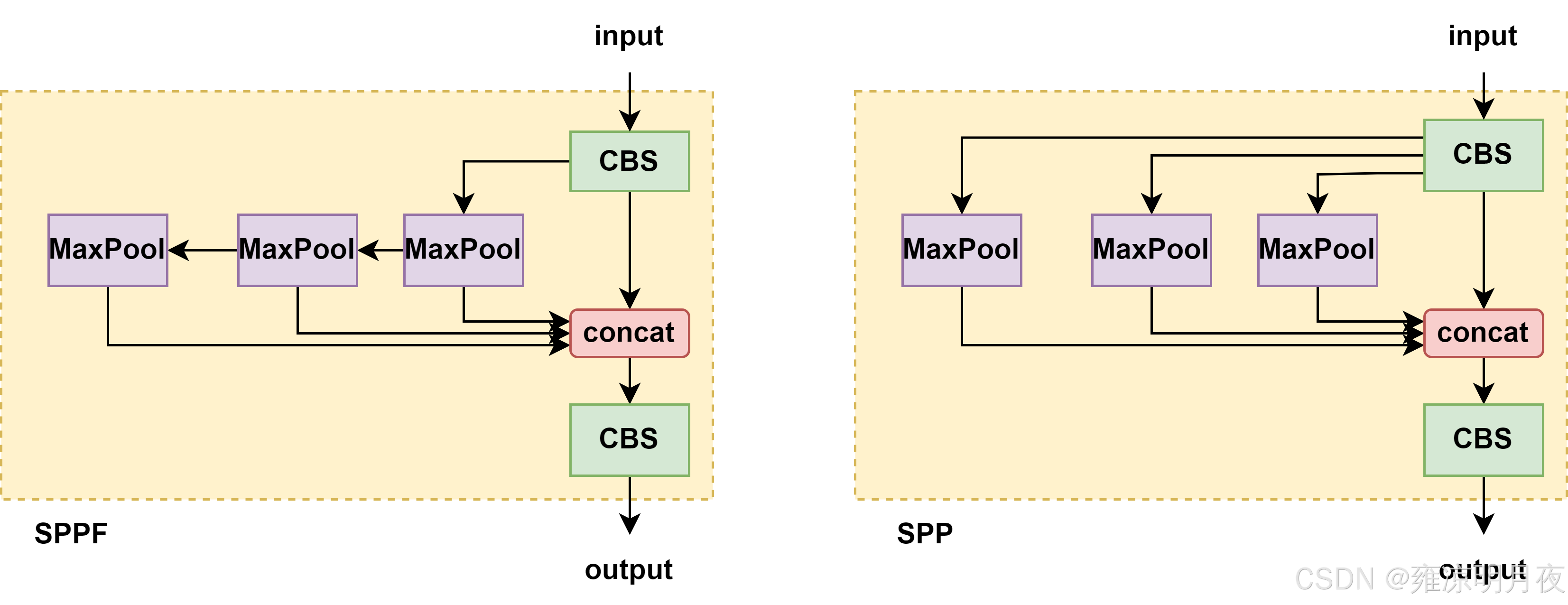
总结:修正后的完整理解
| 模块 | 输入特征图 | 核心作用 | 受益目标 |
|---|---|---|---|
| SPP | 13×13×1024(步幅 32) | 扩大感受野 + 多尺度池化融合 | 大目标 |
| PAN | 52×52、26×26、13×13 三尺度 | 双向特征聚合(语义 + 定位) | 小目标 + 大目标 |
核心亮点:
SPP 是 "单尺度内部的深度挖掘",PAN 是 "多尺度之间的双向联动",两者结合让 Neck 模块的特征融合效果达到 1+1>2 的效果。两个模块的根本目的都是为了增强特征图的表现力。
第三部分:Head
头部网络**------ 沿用 YOLOv3 结构,细节微调**
YOLOv4 的 Head 基本沿用了 YOLOv3 的检测头结构,核心功能是
「将 Neck 输出的特征图转换为检测结果(边界框、类别、置信度)」
核心操作(与 YOLOv3 一致)对 Neck 输出的 3 个尺度特征图,分别进行 3 次 3×3 卷积(增强特征)+ 1 次 1×1 卷积(预测输出),其中 1×1 卷积的输出通道数计算方式如下(假设检测类别数为 C):
- 每个网格预测 B 个边界框(YOLOv4 默认 B=3,与 YOLOv3 一致)
- 每个边界框对应 5 个基础参数(x, y, w, h, confidence)+ C 个类别概率
- 输出通道数 = 3×(5+C),例如 COCO 数据集(C=80),输出通道数 = 3×85=255。
细节微调(YOLOv4 的优化,无遗漏掌握)
- 边界框预测:沿用 YOLOv3 的「锚框(Anchor Box)」机制,锚框尺寸通过 k-means 聚类 COCO 数据集得到(YOLOv4 提供了预定义的 9 个锚框,对应 3 个尺度,每个尺度 3 个),同时保留「坐标归一化」和「宽高指数化」(防止 w、h 为负)。
- 置信度预测:微调了置信度的定义,增加了「对象性得分」的权重,更精准地判断网格内是否存在目标。
- 损失函数:将 YOLOv3 的部分损失项替换为「CIoU Loss」(替代 IoU Loss、GIoU Loss),解决了边界框回归时「重叠度低、目标框尺寸差异大」的收敛慢问题,大幅提升边界框回归精度(这是 YOLOv4 的关键改进之一,后续步骤会详细讲解)。
2.关键训练优化策略
1.数据增强策略
「Mosaic 数据增强 + CutMix 数据增强 + 传统数据增强」的组合策略
Mosaic 数据增强:
- 作用:将 4 张不同的训练图像拼接成 1 张图像进行训练,大幅增加训练数据的多样性,同时提升小目标的检测精度(4 张图像拼接后,小目标数量翻倍),还能减少批量归一化(Batch Normalization)对批量大小(Batch Size)的依赖(即使 Batch Size=1 也能有效训练,降低硬件门槛)。
- 具体实现:① 随机选取 4 张训练图像;② 对每张图像分别进行随机缩放、随机裁剪、随机翻转、随机色域调整等传统增强;③ 按照「左上、右上、左下、右下」的布局,将 4 张图像拼接成 1 张与输入尺寸一致的图像(如 416×416);④ 调整每张图像对应的边界框坐标,生成拼接后图像的标注文件。
CutMix 数据增强(辅助):
- 作用:补充 Mosaic 增强,将一张图像的部分区域裁剪后粘贴到另一张图像上,保留图像的局部上下文信息,提升模型对目标遮挡场景的鲁棒性。
- 与 Mosaic 的区别:Mosaic 是 4 张图像拼接,CutMix 是 2 张图像融合,各有侧重。
传统数据增强(基础):
- 包含随机水平翻转、随机缩放、随机裁剪、随机亮度 / 对比度 / 饱和度调整、HSV 色域调整等,与 YOLOv3 一致,为 Mosaic 和 CutMix 提供基础。
2. 批量归一化优化
(BN+SyncBN+CBN)
- 核心改进:在 CSPDarknet53 和 Neck 的所有卷积层后,都使用了「Batch Normalization(BN)」,并做了两个优化:① SyncBN(同步批量归一化):在多 GPU 训练时,跨 GPU 计算批量统计信息,提升批量归一化的效果,加速收敛;② CBN(跨阶段批量归一化):在 CSP 结构中优化 BN 的计算方式,减少计算量,同时保证归一化效果。
- 关键作用:解决深层网络的梯度消失问题,加速模型训练收敛,提升模型泛化能力,这是 YOLOv4 能在普通 GPU 上高效训练的关键之一。
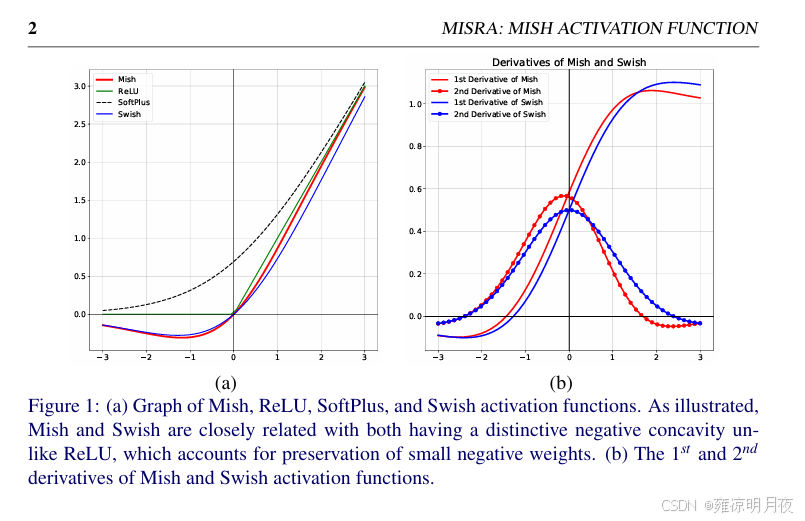
3. 激活函数优化
(Leaky ReLU → Mish)
- YOLOv3 使用的是 Leaky ReLU 激活函数,YOLOv4 在 CSPDarknet53 的骨干网络中,将部分 Leaky ReLU 替换为「Mish 激活函数」,Neck 和 Head 仍使用 Leaky ReLU(平衡速度和精度)。
- Mish 激活函数的优势:具有平滑的非线性特性,能更好地保留梯度信息,提升深层网络的特征提取能力,尤其在小目标检测上效果更优;缺点是计算量略高于 Leaky ReLU,因此仅在骨干网络中使用,保证整体推理速度。
- 公式记忆:Mish (x) = x × tanh (softplus (x)),其中 softplus (x) = ln (1+e^x)。
4. 损失函数优化
(CIoU Loss 替代 IoU Loss)
- 先回顾 YOLOv3 的损失函数不足:使用 IoU Loss 进行边界框回归,当两个边界框无重叠时,IoU=0,梯度为 0,无法进行有效回归;后续的 GIoU Loss 解决了无重叠问题,但对目标框的尺寸和位置敏感性不足。
- YOLOv4 的改进:使用「CIoU Loss」进行边界框回归,全面考虑了边界框的「重叠面积、中心距离、长宽比」三个因素,回归精度更高,收敛速度更快。
- CIoU Loss 的核心组成(无遗漏掌握):CIoU = IoU - (d²/c²) - αv其中:
- ① d:预测框与真实框的中心欧氏距离;
- ② c:包围预测框和真实框的最小外接矩形的对角线长度;
- ③ α:权重系数,用于平衡长宽比项的影响;
- ④ v:衡量预测框与真实框的长宽比差异。损失函数:CIoU Loss = 1 - CIoU,通过最小化该损失,实现边界框的精准回归。
总结:
本章笔者专门总结了YOLOv4的详细内容,由于YOLOv4和v5几乎一样,本来想着连同YOLOv5一起总结了,但是发现知识点有些掺杂,担心搞混了,所以打算分开来整理,同时下一篇中的YOLOv5也在v4的基础上进行代码的实际落地和解析其中的核心代码逻辑,最后归纳几篇论文链接供大家学习参考。
YOLOv4英文原文:《YOLOv4: Optimal Speed and Accuracy of Object Detection》
https://arxiv.org/pdf/2004.10934.pdf
当然也有中英对照版本: