本期内容为自己总结归档,7天学会Redis。其中本人遇到过的面试问题会重点标记。
(若有任何疑问,可在评论区告诉我,看到就回复)
Day 4 - 高可用架构设计与实践
4.1 主从复制全流程解析
4.1.1 Redis主从复制概述
Redis主从复制是Redis高可用架构的基础,它允许将一台Redis服务器的数据复制到多台从服务器上。主从复制不仅提供了数据冗余,还实现了读写分离和故障恢复能力。
核心价值:
-
数据冗余:多副本保证数据安全
-
读写分离:主库写,从库读,提升系统吞吐量
-
故障恢复:主库故障时,从库可提升为主库继续服务
-
负载均衡:多个从库分担读请求压力
4.1.2 主从复制全流程详解
初始化连接建立
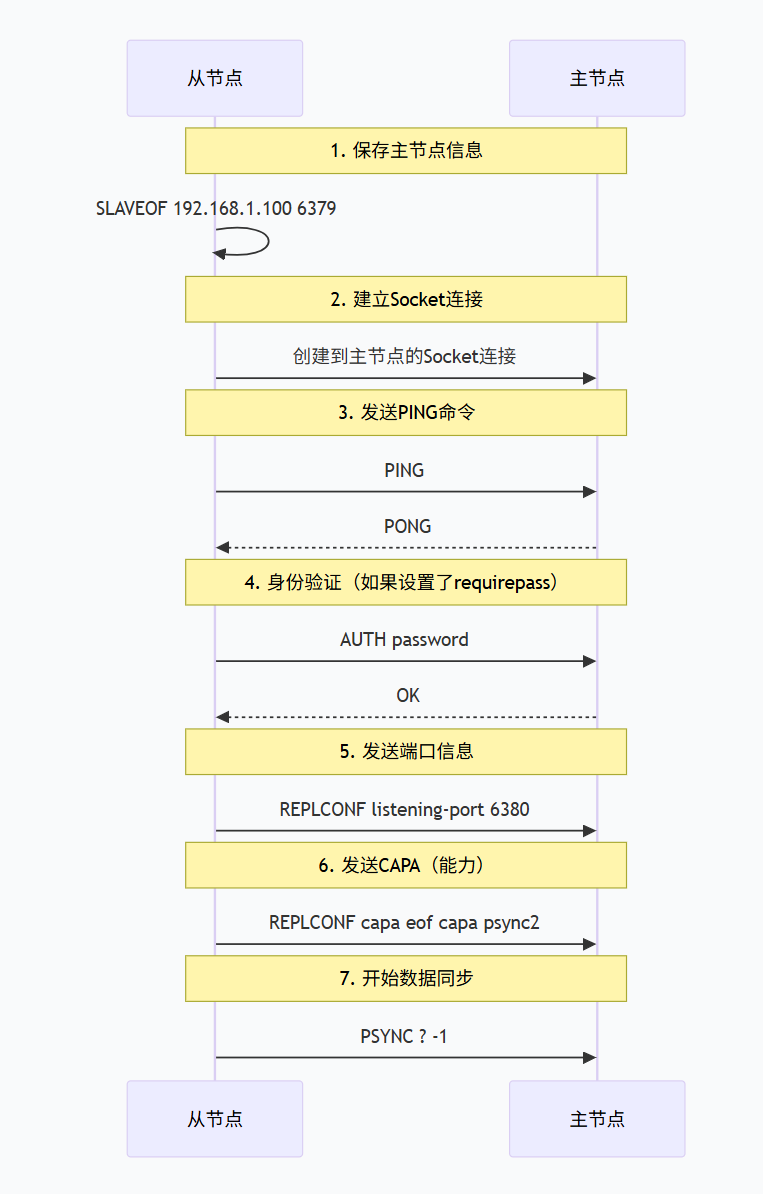
全量复制过程
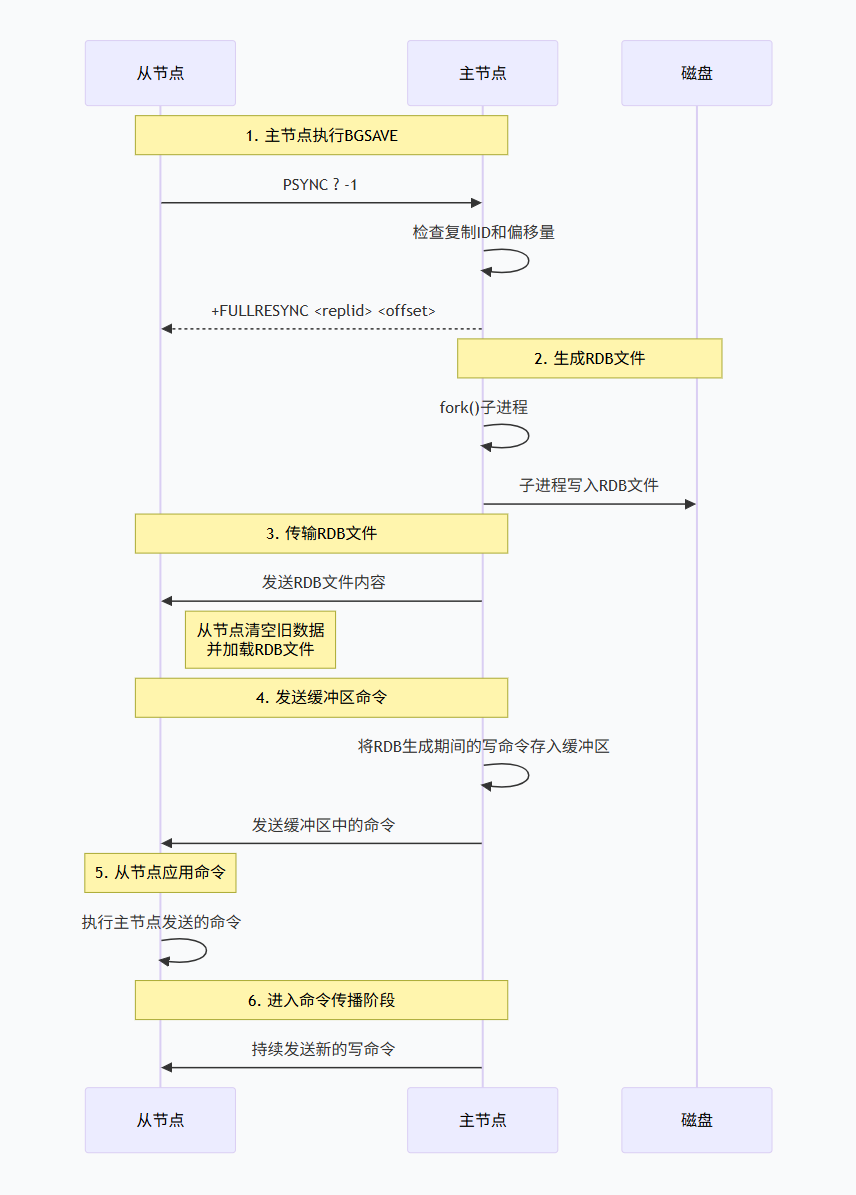
当从节点首次连接主节点,或者主从复制中断时间过长导致复制偏移量不在积压缓冲区中时,会触发全量复制。
部分复制(增量复制)
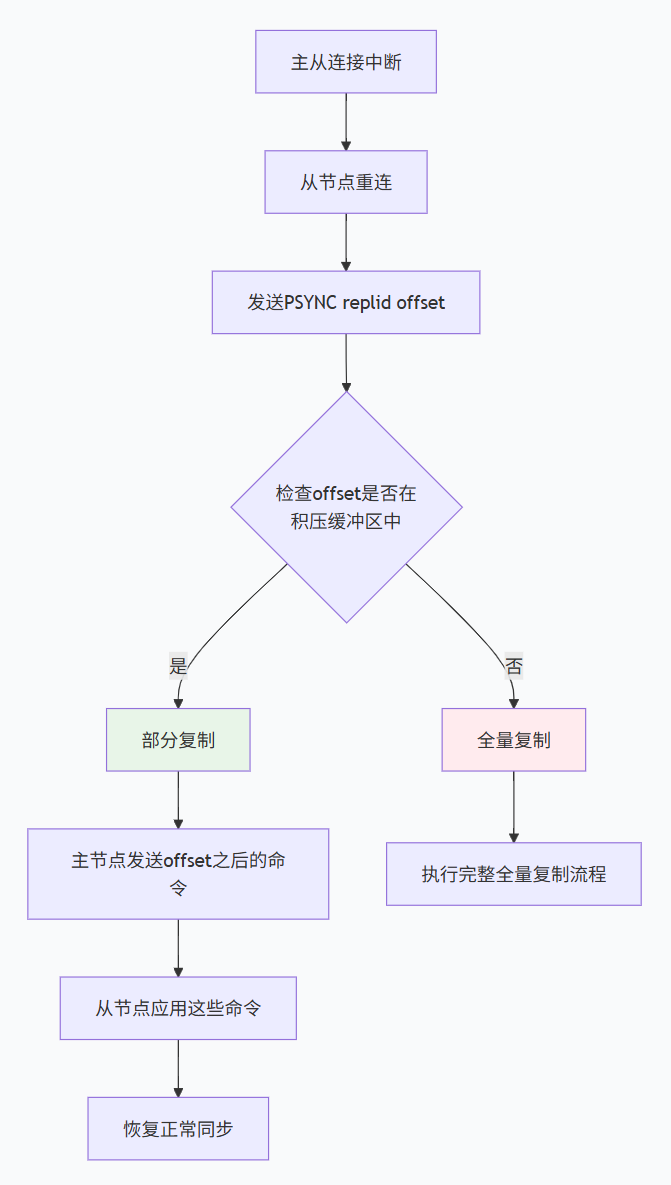
当主从连接短暂中断后重连,如果从节点的复制偏移量仍在主节点的复制积压缓冲区中,则可以只同步中断期间的数据。
复制积压缓冲区详解
复制积压缓冲区是主节点维护的一个固定大小的循环队列,用于保存最近传播的写命令。
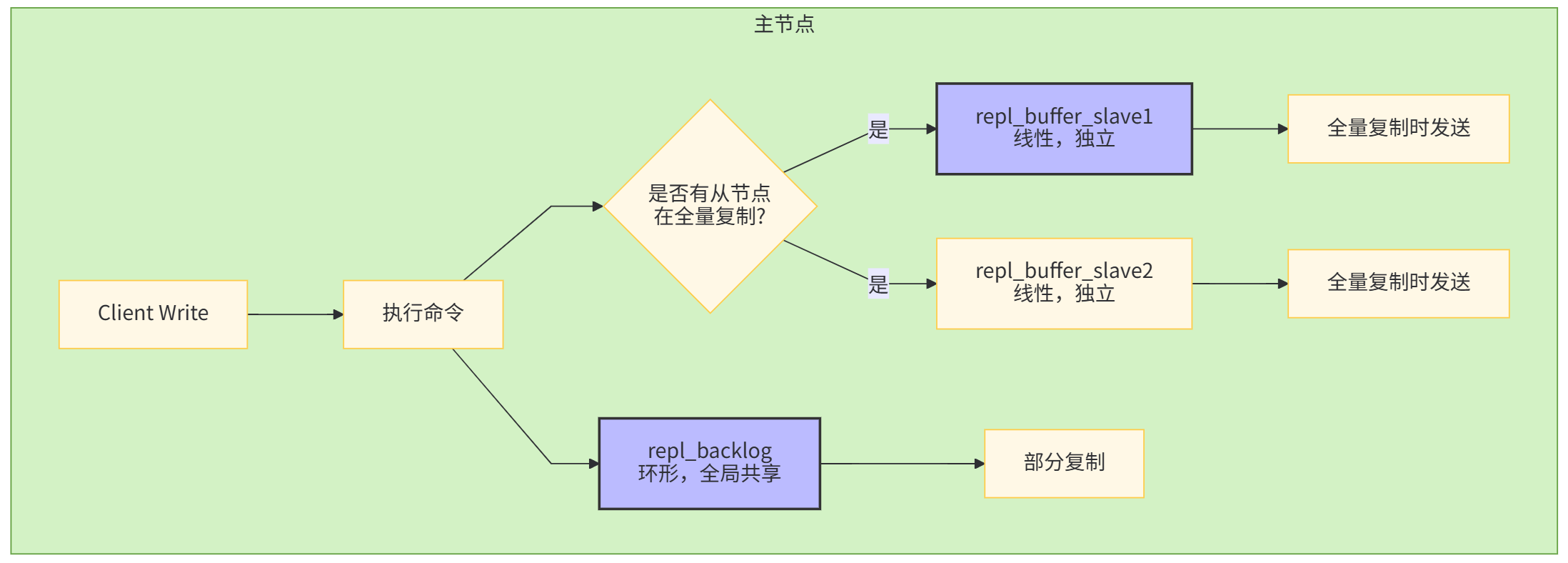
与repl_backlog的区别:
-
repl_backlog:环形,用于部分复制,大小固定
-
repl_buffer:每个从节点独立,线性,存放全量复制期间的增量命令
配置参数:
bash
# redis.conf配置
repl-backlog-size 1mb # 积压缓冲区大小,默认1MB
repl-backlog-ttl 3600 # 主节点无连接时保留时间,默认1小时无盘复制优化
传统的全量复制需要主节点将RDB文件写入磁盘,然后通过网络发送给从节点。无盘复制允许主节点直接将RDB数据通过网络发送给从节点,避免磁盘I/O。
启用无盘复制:
bash
# redis.conf配置
repl-diskless-sync yes # 启用无盘复制
repl-diskless-sync-delay 5 # 延迟秒数,等待更多从节点连接无盘复制适用场景:
-
磁盘I/O瓶颈:主节点磁盘性能较差时
-
网络带宽充足:网络带宽大于磁盘I/O带宽时
-
多个从节点同时同步:避免重复磁盘读写
4.1.3 主从复制状态监控
关键指标监控:
bash
# 查看复制信息
redis-cli info replication
# 关键指标解释:
# role:master/slave # 角色
# connected_slaves:2 # 连接的从节点数
# master_replid:... # 主节点复制ID
# master_repl_offset:123456 # 主节点复制偏移量
# slave_repl_offset:123450 # 从节点复制偏移量
# repl_backlog_active:1 # 积压缓冲区是否激活
# repl_backlog_size:1048576 # 积压缓冲区大小
# repl_backlog_first_byte_offset:123000 # 积压缓冲区起始偏移4.2 Sentinel哨兵机制
4.2.1 Sentinel架构概述
Sentinel(哨兵)是Redis官方提供的高可用解决方案,它监控Redis主从集群,并在主节点故障时自动进行故障转移。
Sentinel核心功能:
-
监控:持续检查主从节点是否正常运行
-
通知:当被监控节点出现问题时,通过API通知管理员
-
自动故障转移:主节点故障时,自动将一个从节点提升为主节点
-
配置提供者:客户端连接时,提供当前主节点的地址
4.2.2 主观下线与客观下线
主观下线(Subjectively Down)
当单个Sentinel实例在配置的down-after-milliseconds时间内没有收到目标节点的有效回复(PING响应),该Sentinel就会将目标节点标记为主观下线。
配置示例:
bash
# sentinel.conf
sentinel monitor mymaster 192.168.1.100 6379 2
sentinel down-after-milliseconds mymaster 5000 # 5秒无响应认为主观下线客观下线(Objectively Down)
当足够数量的Sentinel(由quorum参数决定)都将某个主节点标记为主观下线时,这个主节点就会被标记为客观下线,这时可以触发故障转移流程。
客观下线判定条件:
客观下线 = (标记主节点为主观下线的Sentinel数量) ≥ quorumquorum配置说明:
bash
# sentinel.conf
sentinel monitor mymaster 192.168.1.100 6379 2 # 最后的2就是quorum值-
quorum=1:只要1个Sentinel认为主观下线就触发故障转移(容易误判)
-
quorum=2:需要2个Sentinel都认为主观下线
-
quorum=多数:通常设置为Sentinel数量的多数(如3个Sentinel时quorum=2)
4.2.3 领导者选举算法(Raft协议变种)
当主节点被判定为客观下线后,Sentinel集群需要选举一个领导者来执行故障转移操作。Sentinel使用类似于Raft协议的选举算法。
选举流程:
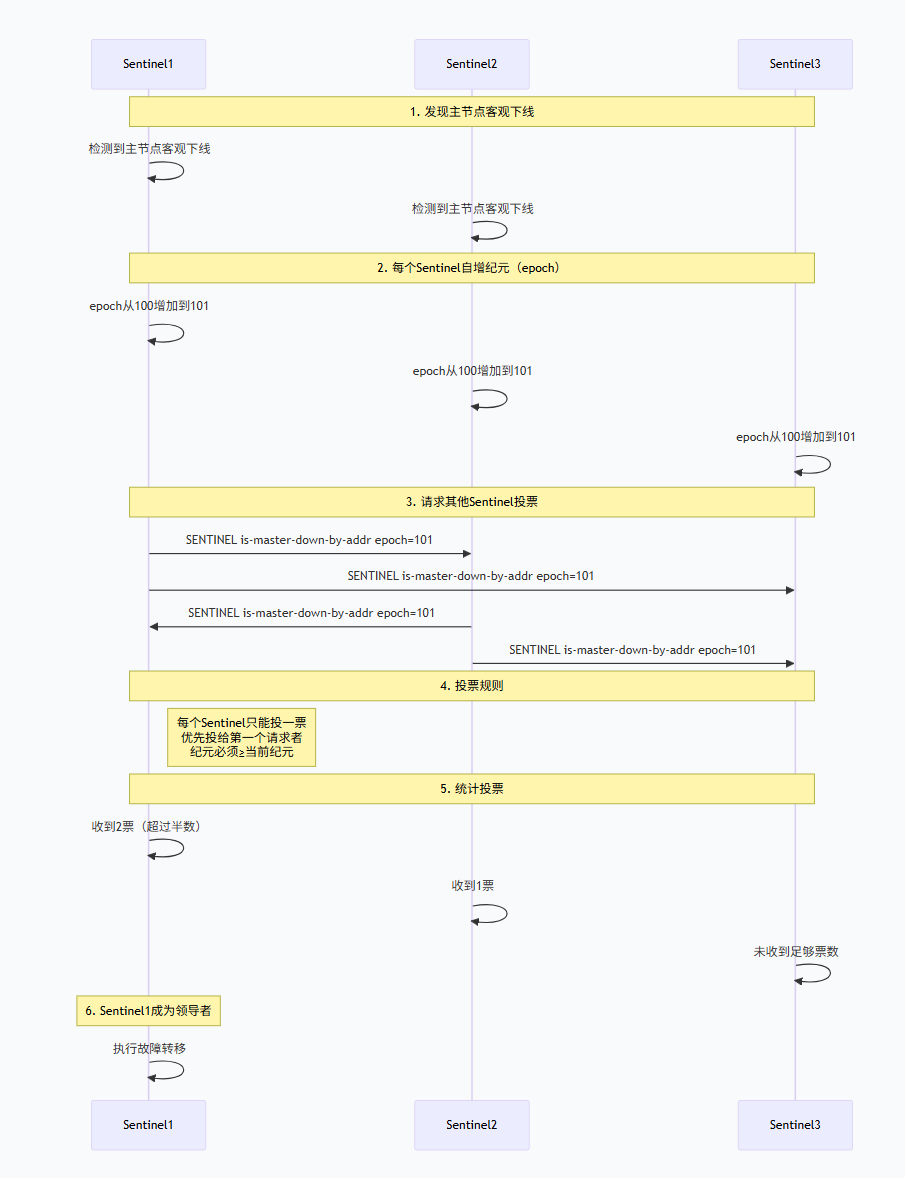
选举算法关键点:
-
纪元(epoch):每个Sentinel维护一个递增的纪元,每次选举尝试都会增加纪元
-
先到先得:每个Sentinel在每个纪元只能投票给第一个请求的候选者
-
多数原则:需要获得超过半数的投票才能成为领导者
-
随机延迟:Sentinel在发现客观下线后,会等待一个随机时间再发起选举,避免多个Sentinel同时发起
选举配置参数:
bash
# sentinel.conf
sentinel failover-timeout mymaster 180000 # 故障转移超时时间,默认3分钟4.2.4 故障转移完整流程
步骤1:选择新的主节点
Sentinel根据以下规则从从节点中选择新的主节点:
-
排除已经下线或断线的从节点
-
排除最近5秒内没有回复过Sentinel INFO命令的从节点
-
排除与已下线主节点连接断开时间超过
down-after-milliseconds * 10的从节点 -
选择优先级最高的从节点(由
slave-priority配置) -
如果优先级相同,选择复制偏移量最大的从节点
-
如果复制偏移量相同,选择runid最小的从节点
步骤2:提升新的主节点
bash
# Sentinel执行的命令序列
1. 向选中的从节点发送:SLAVEOF NO ONE
2. 等待该节点提升为主节点(通过INFO命令确认role:master)
3. 向其他从节点发送:SLAVEOF <new_master_ip> <new_master_port>步骤3:更新Sentinel配置
bash
# Sentinel修改监控配置
# 将旧的主节点从配置中移除,添加新的主节点
sentinel monitor mymaster <new_master_ip> <new_master_port> <quorum>步骤4:客户端通知
Sentinel通过发布/订阅机制通知客户端配置变更:
bash
# 客户端监听Sentinel的频道
SUBSCRIBE +switch-master
# 当故障转移发生时,Sentinel会发布消息:
PUBLISH +switch-master mymaster <old_ip> <old_port> <new_ip> <new_port>4.2.5 Sentinel集群部署最佳实践
Sentinel节点数量建议
| Sentinel数量 | Quorum设置 | 容忍故障数 | 优点 | 缺点 |
|---|---|---|---|---|
| 1 | 1 | 0 | 简单 | 单点故障,不推荐 |
| 3 | 2 | 1 | 推荐配置 | 需要3台服务器 |
| 5 | 3 | 2 | 高可用性 | 资源消耗多 |
| 6 | 4 | 2 | 避免脑裂 | 复杂 |
推荐配置:3个或5个Sentinel节点
部署架构示例
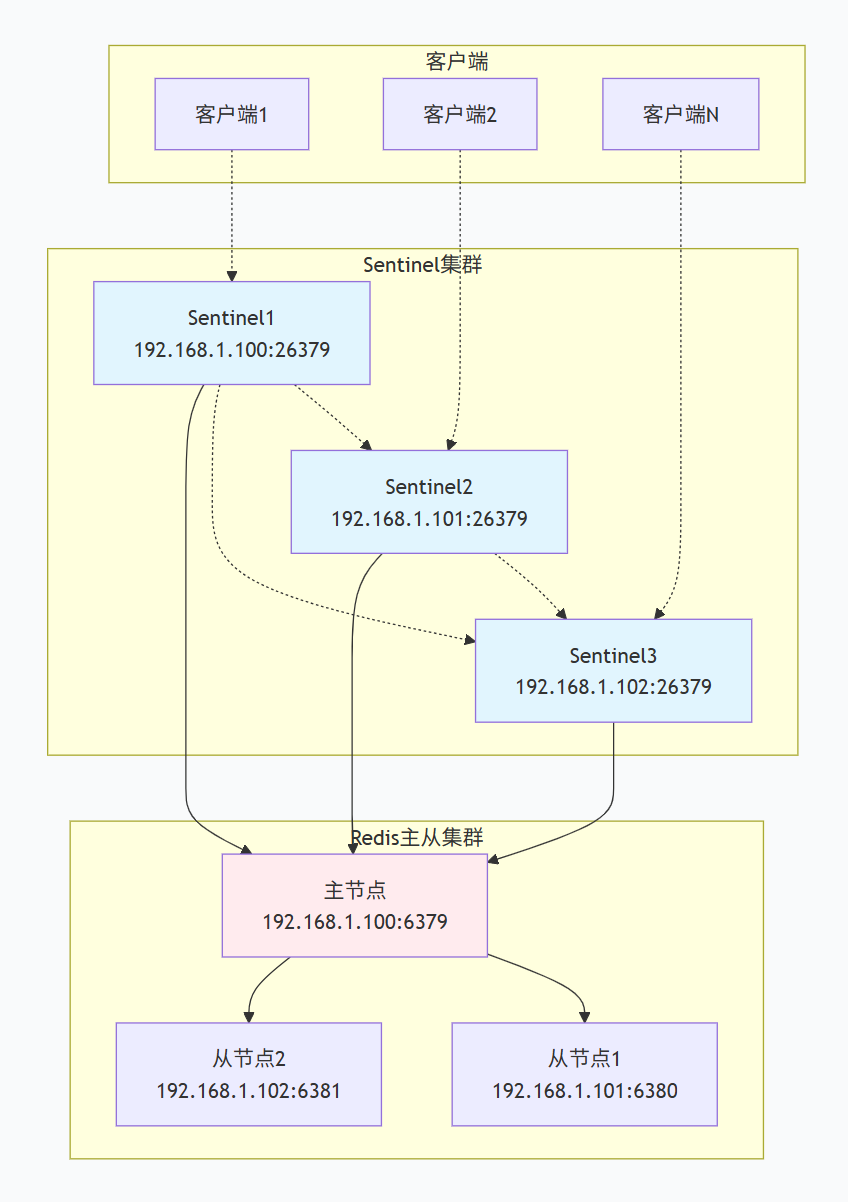
Sentinel配置示例
bash
# sentinel.conf 完整示例
# 监控名为mymaster的主节点
sentinel monitor mymaster 192.168.1.100 6379 2
# 主观下线时间:5秒无响应
sentinel down-after-milliseconds mymaster 5000
# 故障转移超时时间:3分钟
sentinel failover-timeout mymaster 180000
# 故障转移时,最多有多少个从节点同时同步新的主节点
sentinel parallel-syncs mymaster 1
# 设置密码(如果Redis有密码)
sentinel auth-pass mymaster MyPassword
# Sentinel自身端口
port 26379
# 守护进程模式
daemonize yes
# 日志文件
logfile "/var/log/redis/sentinel.log"
# 工作目录
dir "/tmp"4.3 脑裂问题与解决方案
4.3.1 什么是脑裂(Split-Brain)?
定义 :因网络分区,旧主节点未真正宕机,但被哨兵判死,新主节点上线,导致出现两个主节点,数据写入混乱。
脑裂发生场景:
-
网络故障导致主节点与部分从节点、Sentinel断开连接
-
网络分区后,每个分区都选举出自己的主节点
-
网络恢复后,出现两个主节点,数据不一致
4.3.2 脑裂的危害
-
数据不一致:两个主节点同时接受写请求,数据无法自动合并
-
数据丢失:网络恢复后,旧主节点的数据可能被丢弃
-
客户端混乱:客户端可能连接到不同的主节点
-
系统不可用:需要人工干预解决冲突
4.3.2 min-slaves配置策略
核心思想:主节点必须至少有N个从节点连接,才允许写入。
配置:
bash
# redis.conf
min-replicas-to-write 1 # 至少1个从节点连接,否则主节点拒绝写入
min-replicas-max-lag 10 # 从节点延迟<10秒才计入工作原理:
-
当主节点连接的正常从节点数量少于
min-slaves-to-write时,主节点拒绝写操作 -
当所有从节点的复制延迟都超过
min-slaves-max-lag秒时,主节点拒绝写操作 -
这样确保在网络分区时,只有拥有足够从节点的主节点才能接受写请求
4.3.4 客户端连接验证机制
除了服务器端配置,客户端也需要采取措施来应对脑裂问题。
客户端验证策略
-
双重检查机制:客户端在写入前,从多个Sentinel获取当前主节点信息
-
写后验证:写入后立即读取验证,如果不一致则重新获取主节点
-
连接池监控:定期检查连接的主节点是否仍然有效
Sentinel防脑裂配置
bash
# sentinel.conf
# 设置Sentinel的quorum值为Sentinel数量的多数
# 3个Sentinel时设置为2,5个时设置为3
# 增加故障转移的条件
sentinel monitor mymaster 192.168.1.100 6379 2
# 设置从节点晋升条件
sentinel down-after-milliseconds mymaster 5000
sentinel failover-timeout mymaster 180000
sentinel parallel-syncs mymaster 14.3.5 脑裂后的恢复策略
当脑裂确实发生后,需要按照以下步骤恢复:
步骤1:识别脑裂
bash
# 检查所有节点的主从状态
redis-cli -h node1 info replication | grep role
redis-cli -h node2 info replication | grep role
redis-cli -h node3 info replication | grep role如果有多个节点显示role:master,说明发生脑裂
步骤2:选择保留的主节点
-
选择数据更完整的节点(复制偏移量更大)
-
选择客户端连接更多的节点
-
选择与业务系统关联更紧密的节点
步骤3:恢复一致性
bash
# 1. 将其他"主节点"降级为从节点
redis-cli -h old_master_ip SLAVEOF new_master_ip 6379
# 2. 强制同步数据(可能会丢失部分数据)
redis-cli -h old_master_ip SLAVEOF NO ONE
redis-cli -h old_master_ip FLUSHALL
redis-cli -h old_master_ip SLAVEOF new_master_ip 6379
# 3. 检查数据一致性
redis-cli -h new_master_ip info replication4.4 面试高频考点
考点1:Sentinel的客观下线和主观下线是什么?
面试回答:
主观下线和客观下线是Sentinel监控机制中的两个核心概念:
主观下线(Subjectively Down):
-
定义 :单个Sentinel实例在配置的
down-after-milliseconds时间内没有收到目标节点的有效回复(PING响应) -
判断依据:基于单个Sentinel的视角
-
配置 :
sentinel down-after-milliseconds <master-name> <milliseconds> -
特点:主观判断,可能存在误判(如网络抖动)
客观下线(Objectively Down):
-
定义:当足够数量的Sentinel(由quorum参数决定)都将某个主节点标记为主观下线时,这个主节点被标记为客观下线
-
判断依据:基于多个Sentinel的共识
-
配置 :
sentinel monitor <master-name> <ip> <port> <quorum> -
特点:客观判断,需要多个Sentinel达成一致,更可靠
关系:主观下线是客观下线的必要条件。只有先有主观下线,才可能触发客观下线。客观下线是故障转移的前提条件。
考点2:Sentinel领导者选举过程是怎样的?
面试回答:
Sentinel领导者选举使用类似于Raft协议的算法:
-
触发条件:当主节点被判定为客观下线时,Sentinel集群需要选举一个领导者来执行故障转移
-
选举过程:
-
每个发现主节点客观下线的Sentinel都会自增纪元(epoch)
-
每个Sentinel向其他Sentinel发送投票请求
-
每个Sentinel在每个纪元只能投一票,遵循先到先得原则
-
获得超过半数(包括自己)投票的Sentinel成为领导者
-
如果本次选举没有产生领导者,等待一段时间后重新选举
-
-
关键机制:
-
纪元(epoch):递增的计数器,每次选举尝试增加
-
随机延迟:Sentinel在发起选举前等待随机时间,避免多个Sentinel同时发起
-
多数原则:需要获得超过半数的投票
-
-
选举失败处理 :如果选举超时(由
failover-timeout配置),会重新发起选举
考点3:什么是脑裂?如何预防和解决Redis脑裂问题?
面试回答:
脑裂是指在分布式系统中,由于网络分区导致集群被分割成多个独立部分,每个部分都选举出自己的主节点,从而出现多个主节点的情况。
预防措施:
-
合理配置Sentinel:
-
设置适当的quorum值(通常为Sentinel数量的多数)
-
部署足够数量的Sentinel节点(至少3个,推荐5个)
-
-
Redis配置优化:
bash# 主节点配置 min-slaves-to-write 1 # 至少需要1个从节点 min-slaves-max-lag 10 # 从节点延迟不超过10秒 -
网络和部署优化:
-
确保网络稳定性,避免网络分区
-
将Sentinel部署在不同机架或可用区
-
使用高质量的网络设备
-
-
客户端防护:
-
客户端实现双重验证机制
-
写后验证,确保数据一致性
-
解决方案:
一旦发生脑裂:
-
识别脑裂:检查所有节点的role状态
-
选择保留的主节点:基于数据完整性、客户端连接数等因素
-
恢复一致性:
-
将其他"主节点"降级为从节点
-
可能需要手动同步或丢弃部分数据
-
-
修复根本原因:检查网络配置,调整Sentinel参数