- 原来基于LangChain的方式来判断新闻的真假方案不可行。
- 由于大语言模型的弊端无法稳定的通过推理来确定新闻的真假。
- 针对某新闻的相关信息,无法通过训练来获取,可供引用的数据匮乏
- 通过大语言模型的训练,训练后的大语言模型依然无法有效的识别新闻真假
- 大语言模型的不稳定和GPU资源匮乏,无法大规模训练
- 通过训练后的模型对假新闻判断依然不精确。
利用https://colab.research.google.com/上的资源。需要至少V100以上的GPU。
在通过https://github.com/hiyouga/LLaMA-Factory 搭建训练平台。
- 通过LLama2的LlamaForSequenceClassification来对新闻进行判断真假。通过对新闻的训练,提高辨别率。
- 训练LLama2需要用至少A100的GPU(40G)。训练的时候要使用将近31G的GPU的RAM
- 训练LLama2无法输入长的新闻内容。输入超过1000长度的Text,LLama2会崩溃,造成Out Of Memery。所以,目前只能训练短文本,譬如:Twitter相关的假新闻。
- 1600条Twitter数据。1300条数据用来训练,300条数据用来验证。能达到85%左右的准确率。
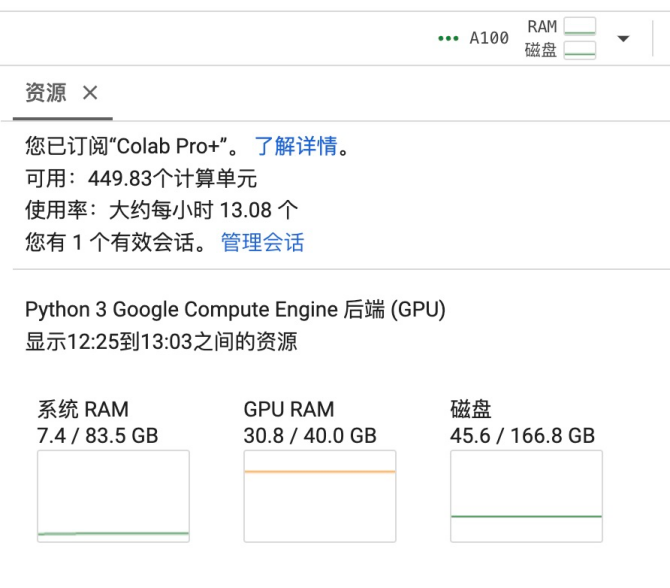
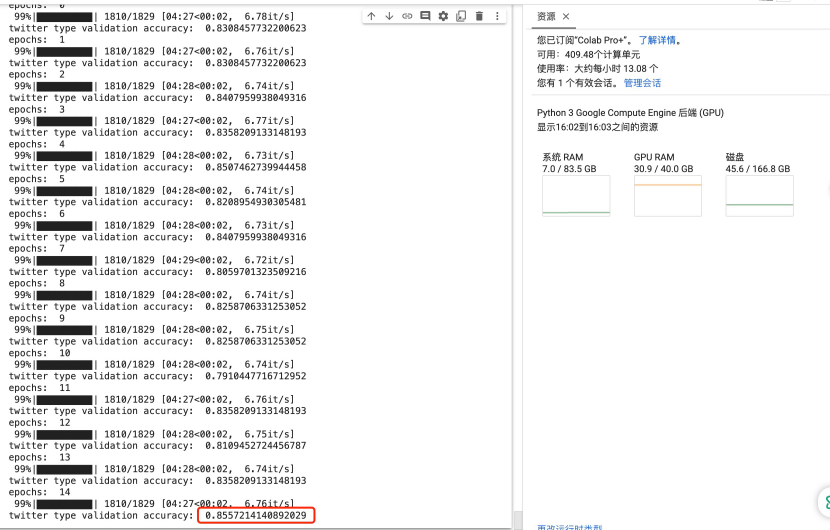
使用的大语言模型如下:
togethercomputer/Llama-2-7B-32K-Instruct
https://huggingface.co/togethercomputer/Llama-2-7B-32K-Instruct