构建智能 PDF 内容提取与处理系统
在数字化转型的浪潮中,PDF 作为最通用的文档交换格式,承载了海量的非结构化数据。然而,如何高效、准确地从 PDF 中提取文本、表格和图像,并进行二次处理(如去水印、注释),一直是技术领域的痛点。本文将详细介绍 skill-pdf-content-extractor 项目的技术实现与开发经验。
1. 项目概述
1.1 项目背景与目标
在企业级应用和数据分析场景中,经常需要处理大量的 PDF 报告、合同和技术文档。传统的 PDF 处理工具往往功能单一,难以同时满足文本提取、表格解析、图像分离以及文档清洗(去水印)等综合需求。
本项目旨在构建一个模块化、高性能且易于扩展的 PDF 内容提取与处理系统。主要目标包括:
- 提供统一的命令行接口(CLI)处理各种 PDF 操作。
- 实现高精度的文本和表格提取,支持 Markdown 格式输出。
- 集成 OCR 能力,处理扫描件或纯图片 PDF。
- 提供文档清洗(去水印)和自动化注释功能。
1.2 技术栈说明
项目基于 Python 生态构建,精选了各领域表现最佳的库:
- 核心处理引擎 :
PyMuPDF (fitz): 提供极速的 PDF 渲染、底层数据访问和图像处理能力。pdfplumber: 专注于高精度的文本布局分析和表格提取。PyPDF2: 处理文档合并、元数据读写等标准操作。
- OCR 引擎 :
pytesseract(Tesseract-OCR 封装),用于识别扫描件内容。 - 数据处理 :
pandas和openpyxl用于表格数据的清洗与导出。 - 图像处理 :
Pillow用于图片格式转换与去重处理。 - 报告生成 :
reportlab用于生成新的 PDF 页面。
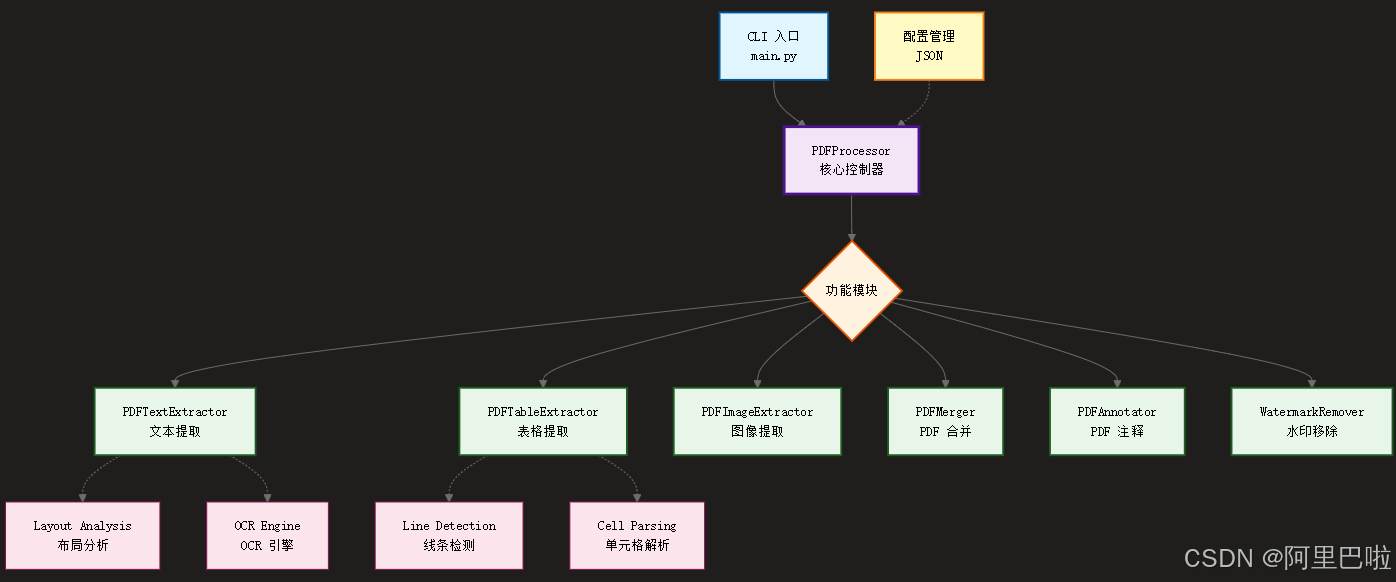
1.3 系统架构图
系统采用分层架构设计,保证了各功能模块的独立性与可维护性。
此技能提供完整的 PDF 处理能力:
- 文本提取:提取所有文本内容,保留格式和结构,支持章节识别与图片在 Markdown 报告中的引用
- 表格提取:识别并提取表格数据为结构化格式(CSV/Excel/JSON)
- 元数据提取:获取作者、创建日期、标题等元信息
- PDF 合并:将多个 PDF 文件合并为一个
- 智能注释:在 PDF 上添加高亮、批注、标记
- 图片提取:提取 PDF 中嵌入图片,输出到目录并生成清单 JSON
- 去水印处理:基于规则与启发式清理文本/注释类型水印
- OCR 兜底:文本密度不足时可启用 Tesseract OCR 进行识别
2. 核心技术实现
2.1 关键模块设计
文本提取引擎 (PDFTextExtractor)
文本提取并非简单的读取流。我们实现了一个智能提取器,支持多种策略:
- 布局保持 : 使用
pdfplumber分析字符坐标,尽可能还原段落结构。 - OCR 自动回退: 系统会自动计算页面的文本密度。如果密度低于阈值(如扫描件),自动调用 Tesseract OCR 进行识别。
- Markdown 转换: 将提取的内容自动转换为 Markdown 格式,保留标题层级和列表格式。
表格识别系统 (PDFTableExtractor)
表格是 PDF 中最难处理的部分。我们结合了 pdfplumber 的线检测和隐式表格识别算法:
- 显式表格: 基于线条交点识别单元格。
- 隐式表格: 基于文本块的垂直对齐和空白间隔进行推断。
- 结构化输出: 支持导出为 CSV、Excel 或 JSON 格式,便于数据分析。
2.2 创新技术应用
智能去水印 (WatermarkRemover)
针对企业文档常见的干扰水印,我们实现了双重去除策略:
- 模式匹配 : 通过
resources/watermark_patterns.json配置特定的文本模式或图像指纹。 - 启发式算法: 分析页面中重复出现、透明度高且位于特定层级(OCG)的对象,自动识别为水印并移除。
图像去重与提取
PDF 中常包含重复的 logo 或背景图。在提取图片时,我们计算图像的感知哈希(Perceptual Hash),自动剔除重复图片,减少冗余存储。
2.3 性能优化方案
- 按需加载: 各个功能模块(Extractor)仅在被调用时初始化,减少内存占用。
- 流式处理: 针对大型 PDF,采用流式读取和分页处理,避免一次性加载整个文件导致内存溢出。
- 并行合并: 在处理多文件合并任务时,优化了文件句柄管理,提升 I/O 效率。
3. 开发经验总结
3.1 遇到的挑战及解决方案
| 挑战 | 解决方案 |
|---|---|
| PDF 编码混乱 | 部分 PDF 字体编码(CMap)缺失,导致乱码。我们引入了 PyMuPDF 的底层字体分析能力,结合 OCR 作为兜底方案,显著提高了识别率。 |
| 表格跨页问题 | 简单的表格提取无法处理跨页表格。我们引入了页眉/页脚检测逻辑,尝试合并相邻页面的同构表格。 |
| 复杂布局解析 | 针对多栏排版,我们利用 pdfplumber 的 lap_params 参数进行微调,根据垂直间距自动判断分栏。 |
3.2 最佳实践分享
- 配置即代码 : 将所有的规则(如水印模式、OCR 语言、图像过滤阈值)抽离到
resources/*.json配置文件中,无需修改代码即可适配新场景。 - 防御性编程 : PDF 格式容错率极低,我们在每个处理环节都增加了异常捕获,并生成详细的
execution_report.md,确保单个页面的失败不会导致整个任务崩溃。 - 中间产物管理: 采用清晰的目录结构管理输出文件(按文件名/操作类型分类),便于追溯。
3.3 未来改进方向
- 深度学习布局分析: 引入 LayoutLM 模型,更精准地识别文档中的标题、段落、图片和表格区域。
- Web 服务化: 基于 FastAPI 将 CLI 工具封装为 RESTful API,提供在线处理能力。
- 流式编辑: 优化大文件处理逻辑,支持在不完全加载的情况下进行增量修改。
4. 部署与运维指南
4.1 环境要求
- 操作系统: Windows / Linux / macOS
- Python 版本: 3.8+
- 系统依赖 :
- Tesseract OCR (如需 OCR 功能)
- GCC (部分 Python 库编译需要)