机器学习基础概念
文章目录
机器学习基础分类
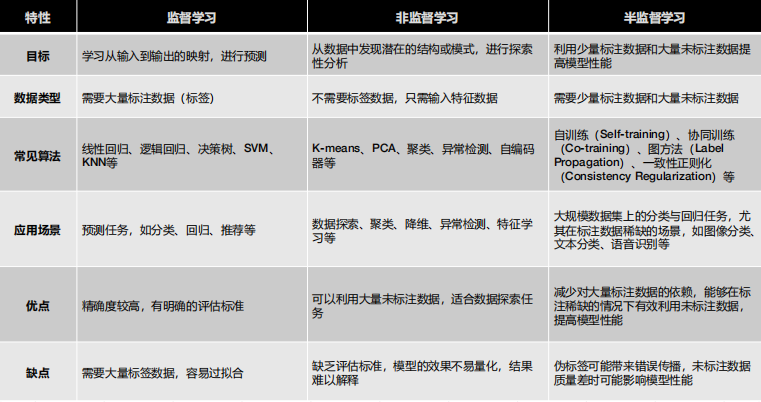
机器学习(Machine Learning, ML)根据学习方式 和是否有标签数据,通常分为以下几大类:
- 监督学习(Supervised Learning)
- 半监督学习(Semi-supervised Learning)
- 非监督学习(Unsupervised Learning)
监督学习
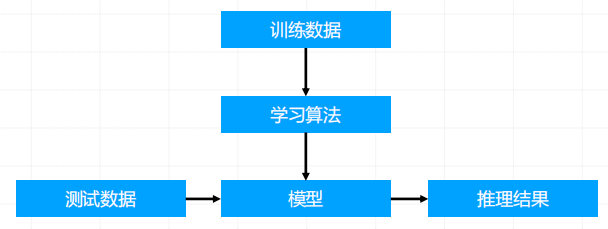
- 训练数据集:输入数据和对应的标签(即目标输出)。
- 目标:学习一个映射函数,将输入映射到正确的输出(标签)。
- 应用:分类 (预测离散类别,如:垃圾邮件识别(是/否)、图像识别(猫/狗/鸟))、回归(预测连续数值,如:房价、股票价格预测)等任务
在监督学习中,训练数据是带标签的,也就是说,每个输入数据都有一个对应的输出标签。模型的目标是从这些输入数据和标签对中学习一个映射函数,使得给定新的输入时,能够预测出正确的输出标签。
- 输入数据(x):由特征组成的样本数据。
- 输出标签(y):与输入数据对应的正确答案(标签),如价格、类别、销售额等。
监督学习常见算法
- 线性回归(Linear Regression)
- 逻辑回归(Logistic Regression)
- 支持向量机(SVM)
- 决策树(Decision Tree)
- 随机森林(Random Forest)
- 梯度提升树(XGBoost, LightGBM)
- 神经网络(Neural Networks)
- 朴素贝叶斯(Naive Bayes)
使用监督学习算法建立多变量房价预测模型时,不同变量在数值上差别会非常大,比如房屋面积 和房间个数 这两个变量(特征)在数值上差了几百上千倍,在这种情况下模型只关注数值大的特征,小尺度特征失去作用 。所以在训练模型时需要注意特征缩放(Scaling),使得所有特征归一化,加速模型收敛。
需要进行特征缩放的模型:
- 基于距离的模型
- K近邻(KNN)
- 支持向量机(SVM)
- 聚类算法(如K-Means)
- 基于梯度下降的模型
- 线性回归/逻辑回归(使用梯度下降优化时)
- 神经网络(MLP、深度学习)
- 带正则化的模型(L1/L2)
- Ridge(L2) / Lasso(L1) 回归
- 带权重衰减的神经网络
监督学习应用场景
监督学习的应用场景非常广泛,主要用于那些数据可以明确标注的任务。常见的应用包括:
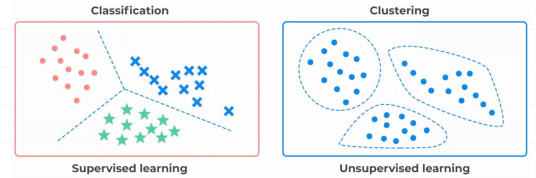
- 分类任务(离散的标签):例如垃圾邮件检测、情感分析(评论打分)、手写数字识别(MNIST数据集)。
- 回归任务(连续的数值):例如房价预测、股票市场预测、天气预测。
优点:
- 训练过程较为清晰、容易理解。
- 在有足够标注数据的情况下,模型可以非常准确地进行预测。
缺点:
- 依赖大量标注数据:标注数据需要人工进行,尤其在某些领域(如医学、法律等)标注成本很高。
- 过拟合风险:模型可能会在训练数据上表现很好,但在新数据上表现不佳,尤其是在训练数据不足或质量不高时。
非监督学习
- 训练数据集:只有输入数据,没有标签信息。
- 目标:从数据中找出隐藏的结构或模式,例如通过聚类或降维来分析数据。
- 应用:聚类、降维、异常检测等任务。例如,顾客分群、PCA降维。
基本原理:
- 非监督学习与监督学习的最大不同之处在于,它不依赖于标注数据 。在非监督学习中,训练数据没有标签,目标是从数据中发现潜在的结构、模式或规律,而不是预测具体的输出标签。
- 非监督学习的关键在于通过不同的算法来揭示数据内部的潜在关系。
训练过程:
- 输入数据(X):仅包含样本的特征数据,没有对应的标签。
- 目标:识别数据中的内在结构或规律,如聚类、降维、异常检测等。
非监督学习常见算法
- K-means聚类(K-means Clustering)
- 层次聚类(Hierachical Clustering)
- 主成分分析(PCA)
- 自编码器(Autoencoders)
- 孤立森林(lsolation Forest)
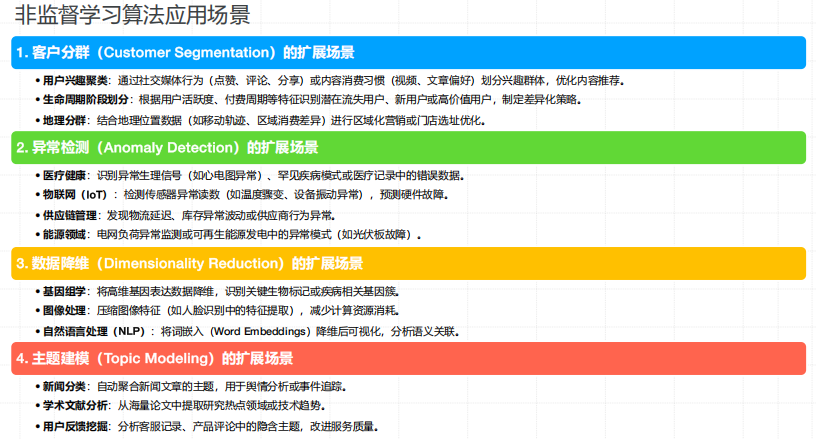
非监督学习应用场景
半监督学习
- 训练数据集:大量没有标签的数据和少量有标签的数据
- 目标:利用少量标签数据来帮助从大量未标注数据中学习,从而提供模型的准确性。
- 应用:大规模数据集的分类任务,在标注成本高的情况下有很大的应用价值。例如,语音识别、图像分类。
核心思想 :半监督学习介于监督学习和非监督学习之间,它利用少量标签 的数据和大量未标签 的数据来进行学习。其动机在于现实世界中,获取未标签数据通常比获取带标签数据容易得多且成本更低。
目标 :通过结合利用这两种数据,达到比仅使用少量带标签数据(监督学习)或仅使用未标签数据(非监督学习)更好的学习效果,特别是提高模型的泛化能力和准确性。
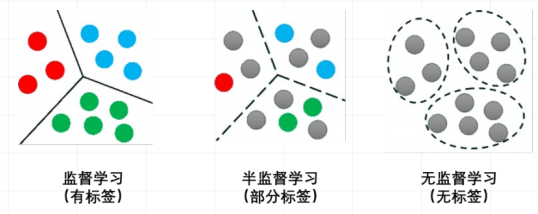
半监督学习常见算法
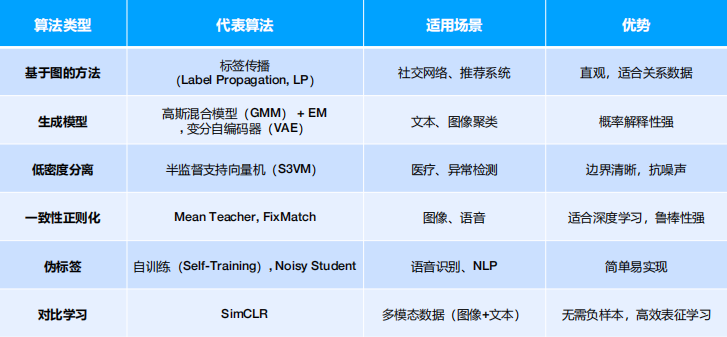
半监督学习应用场景
特别适用于 标注成本高昂 或 标注过程耗时 的领域:
- 图像分类:有少量标注图像和大量未标注图像。(如 自训练 场景)
- 社交网络分析:用户关系和行为数据丰富,但显式标签少。(如 标签传播 场景)
- 文本分类:如网页分类、情感分析,只有部分文本被人工标注。(如 一致性正则化 场景)
- 语音识别:大量的语音数据易于获取,但转录标注费时费力。
- 生物信息学:如蛋白质功能预测、基因序列分析。
- 医学影像分析:标注需要专业医师,成本高。
传统机器学习三大范式对比