目录
[1.1 启动与关闭](#1.1 启动与关闭)
[1.2 数据库的概念](#1.2 数据库的概念)
[1.3 数据库操作](#1.3 数据库操作)
[1.4 数据库的逻辑关系](#1.4 数据库的逻辑关系)
[1.5 SQL分类](#1.5 SQL分类)
[1.6 存储引擎](#1.6 存储引擎)
[2.1 创建数据库](#2.1 创建数据库)
[2.2 查询&&使用&&修改&&删除数据库](#2.2 查询&&使用&&修改&&删除数据库)
[2.3 数据库的备份与还原](#2.3 数据库的备份与还原)
[3.1 创建表](#3.1 创建表)
[3.2 查询&&修改&&删除表](#3.2 查询&&修改&&删除表)
[4.1 数值类型](#4.1 数值类型)
[4.2 字符串类型](#4.2 字符串类型)
[4.3 日期和时间类型](#4.3 日期和时间类型)
[4.4 枚举和集合类型](#4.4 枚举和集合类型)
[5.1 空属性](#5.1 空属性)
[5.2 默认值](#5.2 默认值)
[5.3 列描述](#5.3 列描述)
[5.4 填充0](#5.4 填充0)
[5.5 主键](#5.5 主键)
[5.6 自增长](#5.6 自增长)
[5.7 唯一键](#5.7 唯一键)
[5.8 外键](#5.8 外键)
[6.1 INSERT](#6.1 INSERT)
[6.2 SELECT(重点)](#6.2 SELECT(重点))
[6.3 UPDATE](#6.3 UPDATE)
[6.4 DELETE](#6.4 DELETE)
[7.1 日期函数](#7.1 日期函数)
[7.2 字符串函数](#7.2 字符串函数)
[7.3 数学函数](#7.3 数学函数)
[7.4 其他函数](#7.4 其他函数)
[8.1 索引结构](#8.1 索引结构)
[8.2 创建索引](#8.2 创建索引)
[9.1 事务概念](#9.1 事务概念)
[9.2 事务操作](#9.2 事务操作)
[9.3 隔离性(Isolation)](#9.3 隔离性(Isolation))
1**、** MySQL 数据库基础
- MySQL,关键字,不区分大小写。
- MySQL,''和"",都可以表示字符串,一般使用''。
1.1****启动与关闭
cpp
// MySQL的启动与关闭
启动:mysql -h(主机IP)127.0.0.1 -P(端口号)3306 -u(用户)root -p(密码)
关闭:quit1.2****数据库的概念
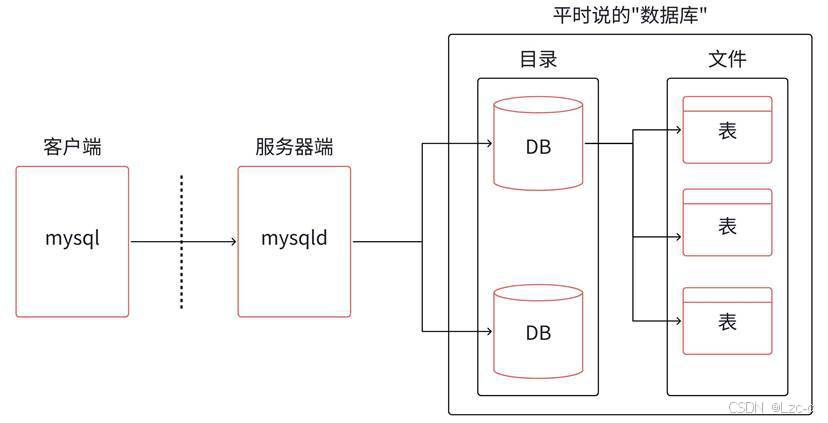
- mysql 是数据库服务 的客户端。
- mysqld 是数据库服务 的服务器端。
- 数据库 MySQL 是一种基于C (mysql )/S (mysqld )模式的网络服务 ,是在磁盘或内存 中进行数据存取 的服务,方便数据的处理。
1.3****数据库操作
- 数据库所在的目录 :datadir=/var/lib/mysql。数据库 是一个目录。
- 创建数据库 :create database helloworld;
- 选择数据库 :use helloworld;
- 创建表 :表 是在数据库目录下的文件。
sql
create table student(
id int,
name varchar(32),
age int,
gender varchar(2)
);- 向表中插入数据 :insert into student(id, name, age, gender) values(1, '张三', 20, '男');
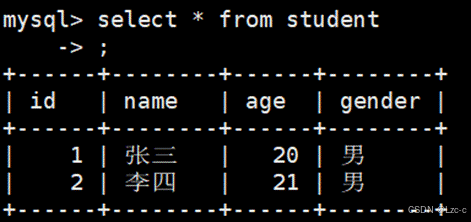
1.4****数据库的逻辑关系
1.5 SQL****分类
- DDL (data definition language):定义数据库和表的结构。
- create ,alter ,drop。
- DML (data manipulation language):实现对表中数据的操作。
- insert , select (DQL ), update , delete。
- DCL (data control language):数据安全性控制。
- grant (授权 ), revoke (撤回 ), deny (拒绝)。
1.6****存储引擎
- MySQ架构:
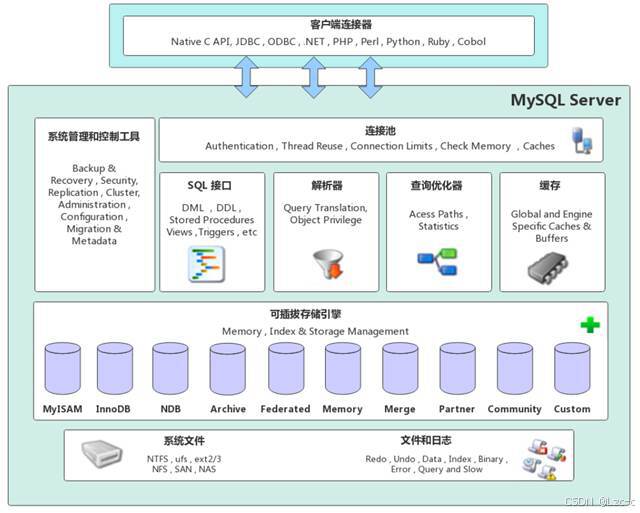
- 查看存储引擎:show engines;
2**、** MySQL 库的操作 (DDL)
2.1****创建数据库
- 数据库所在的目录 :datadir=/var/lib/mysql。数据库 是一个目录。
- 语法:
sql
// 创建数据库的语法:
CREATE DATABASE [IF NOT EXISTS] db_name [create_specification [,create_specification] ...];
create_specification:
[DEFAULT] CHARACTER SET charset_name 或者 CHARSET=charset_name
[DEFAULT] COLLATE collation_name 或者 COLLATE=collation_name- 说明:
- 大写的表示关键字;
- \[\] 是可选项;
- CHARACTER SET:指定数据库采用的字符集;
- 数据库存储数据的格式。本文为utf8。
- show variables like 'character_set_database';查看字符集。
- show charset;查看数据库支持的字符集。
- COLLATE:指定数据库字符集的校验规则。
- 采用什么格式读取数据库中的数据。如:查询时进行比较,是否区分大小写。本文为utf8_general_ci,不区分大小写。
- show variables like 'collation_database';查看校验规则。
- show collation;查看数据库支持的校验规则。
2.2****查询 && 使用 && 修改 && 删除数据库
sql
// 1. 查询数据库
show databases; // 查看有哪些数据库
select database(); // 查看当前在那个数据库
show create database db_name; // 查看创建数据库db_name时的信息
show processlist; // 查看数据库的连接情况
// 2. 使用数据库
use db_name;
// 3. 修改数据库 不建议改
// 与创建数据库相比,就是把CREATE换成了ALTER
ALTER DATABASE db_name [alter_spacification [,alter_spacification]...]
alter_spacification:
[DEFAULT] CHARACTER SET charset_name 或者 CHARSET=charset_name
[DEFAULT] COLLATE collation_name
// 4. 删除数据库 不建议删
DROP DATABASE [IF EXISTS] db_ name;2.3****数据库的备份与还原
sql
// 1. 数据库的备份
mysqldump -uroot -p -B db_name > path/db_new_name.sql // 备份一个数据库
mysqldump -uroot -p db_name table_name1 table_name2 > path/mytest.sql // 数据库中的多个表
mysqldump -uroot -p -B db_name1 db_name2 ... > path/ // 多个数据库
如果备份一个数据库时,没有带上-B参数,
在恢复数据库时,需要先创建(create)空数据库,然后使用(use)数据库,再使用source来还原,
可以达到数据库重命名的效果。当然也可以在db_new_name.sql里面改。
// 2. 数据库的还原
mysql> sourse path/db_new_name.sql3**、** MySQL 表结构的操作 (DDL)
3.1****创建表
sql
CREATE TABLE [IF NOT EXISTS] table_name(
field1 datatype 约束...,
field2 datatype 约束...,
field3 datatype 约束...
) [character set 字符集 collate 校验规则 engine 存储引擎];
或者[charset=字符集 collate=校验规则 engine=存储引擎]
CREATE TABLE table_name1 LIKE table_name2;3.2****查询 && 修改 && 删除表
sql
// 1. 查询表
show tables; // 查看有哪些表
desc table_name; // 查看表的结构
show create table table_name \G // 查看创建表时的信息
// 2. 修改表 不建议改
// 语法
// 新增属性
ALTER TABLE table_name ADD column
datatype [DEFAULT expr] [,column datatype]...;
// 修改属性
ALTER TABLE table_name MODIFY
column datatype [DEFAULT expr] [,column datatype]...;
// 删除属性和数据
ALTER TABLE table_name DROP column;
// 例子
// 在users表添加一个属性,用于保存图片路径,放在birthday属性的后面
mysql> alter table users add
assets varchar(100) comment '图片路径' after birthday;
// 修改表名users为employee
mysql> alter table users rename [to] employee;
// 修改属性名name为xingming。属性也应一并设置。
mysql> alter table employee change name xingming varchar(60);
// 修改name的属性,将其长度改成60。原有的任何数据,会被直接覆盖。
mysql> alter table users modify
name varchar(60);
// 删除password属性。
mysql> alter table users drop password;
// 3. 删除表 不建议删
DROP [TEMPORARY] TABLE [IF EXISTS] table_name [,table_name]...4**、** MySQL 的数据类型
- 数据类型 本质就是约束 ,一旦超出数值范围 ,报错 ,使数据库中的数值都是在指定的范围之内。
4.1****数值类型
sql
// 整数类型
// 1. tinyint 1字节,默认是有符号的。
tinyint -128~127
tinyint unsigned 0~255
// 2. smallint 2字节
// 3. mediumint 3字节
// 4. int 4字节
// 5. bigint 8字节
// 位类型
bit[(M)] // M个比特位,M为1~64,默认为1。按ASCII值显示。
// 浮点数类型
// 1. float[(M,D)] [unsigned] 4字节,默认是有符号的。无符号的,直接去掉负数的部分。
<=M个数字,D是小数位数。
如:float(4,2)是-99.99~99.99,
整数部分<=2(M-D)位数,
小数可以四舍五入后,但整体数值必须在范围之内。
float表示的精度大约是7位。
// 2. double[(M,D)] [unsigned] 8字节
// 3. decimal(M,D) [unsigned]
M<=65位,支持小数最大位数D是30;
如果D被省略,默认为0;如果M被省略,默认是10;
建议:如果希望小数的精度高,推荐使用decimal。4.2****字符串类型
sql
// 1. char(L),固定长度的字符串,
L是字符的长度,最大长度为255个字符,
(2字符,比如:'ab','中国'。注意是2个符号,不是两个字节)。
// 2. varchar(L),可变长的字符串,
L表示字符最大长度,最大为21844个字符,有1~3个字节记录实际字符长度,
当表的编码为utf8时,一个汉字三个字节,
有效存储数据的长度为65532个字节(有3个字节记录长度)。
实际用多少开多少。- char比varchar,一次开好空间,不用维护计数器,更高效;varchar,可以节省内存。
4.3****日期和时间类型
sql
// 1. date,日期'yyyy-mm-dd',
占用三字节。
// 2. datetime 时间日期格式'yyyy-mm-dd HH:ii:ss',
占用八字节。
// 3. timestamp,时间戳,从1970年开始,格式'yyyy-mm-dd HH:ii:ss',和datetime一致,
占用四字节。插入或更新数据时,会自动更新。4.4****枚举和集合类型
sql
// 1. enum('选项1', '选项2', ...),枚举类型,单选,
只能是选项的其中之一,可以用下标索引(从1开始)。
// 2. set('选项1', '选项2', ...),集合类型,多选,
只能是这些选项,可以多选(如:'选项1,选项2')。
可以用数字(位图,如:1就是选项1),0不是NULL,而是''。- find_in_set(a,b),a是b中的一个元素,返回下标(真,从1开始);不是,返回0(假)。
5**、** MySQL 表的约束
- 约束:保证数据的完整性。
- 约束可以在属性类型的后面设置。
5.1****空属性
- 属性默认 为NULL (空,允许插入空);NOT NULL(非空,不允许插入空)。
5.2****默认值
- 默认值 (DEFAULT ):用户没有输入值 ,就使用默认值。
- 属性 的默认值 ,没有指定时 ,默认为NULL 。所以,允许为空是允许插入默认值NULL和用户输入的NULL;非空约束 是为了防止插入默认值 NULL (其实设置为NOT NULL,DEFAULT没有被设置为NULL(因为设置了也插入不了),所以不指定值插入,会报没有默认值的错误。NOT NULL要指定插入或设置非空的默认值。)和用户输入的 NULL。
5.3****列描述
- 列描述 (COMMENT ):用来描述属性。
5.4****填充 0
- 如:age int(10) zerofill ,表示宽度为10位,位数不足 ,用 0 填充。
- 只是输出形式 的改变 ,值不变。
- int unsigned,默认int(10),2^31 -1 ,有10位数;int,默认int(11),多个负号。
5.5****主键
- 主键 (PRIMARY KEY ):一个元组 的非空 的唯一标识 。一个表最多有一个主键。
- 添加主键:
- 可以在属性后面设置 primary key。或者在设置属性的最后一行,primary key(属性集合)。建议创建表的时候,就设置好。
- 也可以创建表后 ,alter table 表名 add primary key (属性集合)。
- 删除主键 :是删除约束 ,不是删除属性。
- alter table 表名 drop primary key;。
5.6****自增长
- 自增长 (auto_increment):默认从1开始,从当前最大值+1开始。插入时,不用输入该值,会自动增长,。
- 自增长的属性 必须是整数类型。
- 自增长的属性 必须是索引类型(索引后续再介绍)。
- 一张表最多有一个自增长类型。
- 一般与主键搭配。
- create table table_name(id int auto_increment) auto_increment=100; 可以指定起始值。
- select last_insert_id();可以查看最后插入时的自增长的值。
5.7****唯一键
- 唯一键 (UNIQUE 或者 UNIQUE KEY ):属性值唯一 ,允许 NULL(NULL认为是未知值,不相等)。
- 主键 是非空唯一键 ,侧重于一个元组的唯一标识 ,一个表最多有一个。
- 唯一键 ,允许为 NULL ,侧重于一个属性的唯一性 ,一个表可以有多个。
5.8****外键
- 外键 (foreign key ):外键 必须是另一张表中 的主键 ,且外键的域包含于该主键的域 (即所有外键的值必须在主键中存在 或者外键为 NULL)。
- foreign key(外键) references 主表(主键)。
6**、** MySQL 表数据的操作 (DML)
- CRUD : Create(创建), Retrieve(读取),Update(更新),Delete(删除)。
6.1 INSERT
sql
// 1. 基本语法
INSERT [INTO] table_name [(column [, column] ...)]
VALUES (value_list) [, (value_list)] ...
value_list: value, [, value] ...
// 2. 使用说明
t1表
id int unsigned auto_increment,
sno char(10) unique key,
name varchar(20),
primary key(id)
// 基本插入(可以多行插入)
// 指定全部属性
insert into t1(id, sno, name) values(1,'01','Lzc');
// 指定部分属性,没有指定的属性使用默认值
insert into t1(sno, name)values('01','Lzc');
// 不指定属性,默认指定全部属性
insert into t1 values(1,'01','Lzc');
或者
insert into t1 values(default(占位符,使用默认值),'01','Lzc');
// 插入或替换1
INSERT ... ON DUPLICATE KEY UPDATE
column = value [, column = value] ...
-- 0 row affected:表中有冲突数据,但冲突数据的值和 update 的值相等
-- 1 row affected:表中没有冲突数据,数据被插入
-- 2 row affected: 表中有冲突数据,并且数据已经被更新(就地更新)
// 插入或替换2
REPLACE INTO table_name(sn, name) VALUES (22, 'dj'); // 在判断冲突前,id已经自增长为3了
-- 1 row affected:表中没有冲突数据,数据被插入
-- 2 row affected:表中有冲突数据,删除后重新插入**6.2 SELECT(**重点 )
- 详细介绍:SELECT的使用-CSDN博客。
- 虽然是SQL SERVER,但用法基本相同。
- MySQL中没有TOP,有LIMIT;MySQL没有全外连接(FULL OUTER JOIN)。
- 对于相关子查询,可以转为下面样例中的构建临时表,形成多表查询。
sql
// 1. 基本语法
SELECT [ALL|DISTINCT] {* | <{column_name | condition_expression} [[as] 重命名]> [,...n] }
[FROM table_name]
[WHERE condition_expression]
[GROUP BY <column_name> [,...n] [HAVING group_condition_expression]
[ORDER BY <column_name [ASC|DESC]> [,...n]
[LIMIT n]
ALL|DISTINCT:默认ALL,结果不去重;DISTINCT,结果去重。
FROM:从一个或多个表(视图)中查询。
WHERE:condition_expression可以是
a. 比较运算符:=、>、<、>=、<=、<>(!=)。NULL=NULL,NULL是未知的,所以为False。
b. 逻辑运算符:AND(与)、OR(或)、NOT(非)。
c. 确定范围运算符:BETWEEN AND(左闭右闭),NOT BETWEEN AND,可以用比较运算符代替。
d. 集合成员运算符:IN、NOT IN。
e. 字符匹配运算符:LIKE,NOT LIKE。
f. 判空运算符:IS NULL、IS NOT NULL。
g. SELECT 子句:SELECT可以嵌套。
h. 谓词:IN、EXISTS、ALL、SOME、ANY。
i. 集合运算符:UNION(并)、INTERSECT(交)、EXCEPT(差)。
GROUP BY:按一个或多个列,分组。
聚合函数:AVG()、MAX()、MIN()、SUM()、COUNT()。
HAVING:在GROUP BY中可选(没有GROUP BY,不能单独写HAVING),给分组加上条件。
ORDER BY:对最终的查询结果进行排序,默认ASC,升序,DESC降序。
LIMIT n:前n行。
LIMIT offset, n:从偏移量offset开始的n行。LIMIT n,默认偏移量offset为0。
LIMIT n OFFSET offset:等价于LIMIT offset, n,只是写法更规范。- SELECT语句的执行顺序:FROM (指定表),WHERE (指定条件),GROUP BY (分组),HAVING (分组条件),SELECT (查询),ORDER BY (排序,可以使用SELECT中的别名),LIMIT(截取指定数量的行返回)。
- 聚合函数 执行的顺序,在GROUP BY后,不能在WHRER中使用,一般在HAVING 或SELECT 中使用 。可以在SELECT 中使用聚合函数 ,后面HAVING 中就可以使用别名 ,少一次计算。
- 查询样例:
sql
MySQL中,一切皆表。
想办法,多表 -> 单表。
// 1. 显示工资最高的员工的名字和工作岗位
select ename, job from EMP where sal = (select max(sal) from EMP);
// 2. 显示每个部门的平均工资和最高工资
select deptno, format(avg(sal), 2) , max(sal) from EMP group by deptno;
// 3. 显示平均工资低于2000的部门号和它的平均工资
select deptno, avg(sal) as avg_sal from EMP group by deptno having avg_sal<2000;
// 4. 查询和SMITH的部门和岗位完全相同的所有雇员,不含SMITH本人
select ename from EMP
where (deptno, job)=(select deptno, job from EMP where ename='SMITH')
and ename != 'SMITH';
// 5. 显示每个高于自己部门平均工资的员工的姓名、部门、工资、平均工资
//获取各个部门的平均工资,将其看作临时表
select ename, deptno, sal, format(asal,2) from EMP inner join
(select avg(sal) asal, deptno dt from EMP group by deptno) tmp on EMP.deptno=tmp.dt
where EMP.sal > tmp.asal;6.3 UPDATE
- 不指定条件,就全部更新。
sql
// 基本语法
UPDATE table_name SET <column = expression> [,...n]
[WHERE ...]
[ORDER BY ...]
[LIMIT ...]6.4 DELETE
- 不指定条件,就全部删除。
sql
// 1. 基本语法
DELETE FROM table_name
[WHERE ...]
[ORDER BY ...]
[LIMIT ...]
// 2. 删除表的全部数据
TRUNCATE [TABLE] table_name;
DELETE FROM table_name;
// 1. TRUNCATE是DDL语句,改变表的结构;DELETE是DML语句,改变表的数据。
// 2. TRUNCATE不支持事务回滚;DELETE支持事务回滚。
// 3. TRUNCATE会重置AUTO_INCREMENT项;DELETE不会重置AUTO_INCREMENT项。
// 4. TRUNCATE比DELETE快。7**、** MySQL 内置函数
7.1****日期函数
sql
// 1. current_date()
当前日期,格式为'yyyy-mm-dd'
// 2. current_time()
当前时间,格式为'HH:ii:ss'
// 3. current_timestamp()
当前时间戳,格式为'yyyy-mm-dd HH:ii:ss'
// 4. date(datetime)
返回datetime中的日期部分
// 5. date_add(date, interval num type)
select date_add('2026-1-8 14:30:25', interval 10 day),
type可以是year,month,day,hour,minute,second。
// 6. date_sub(date, interval num type)
// 7. datediff(date1, date2)
两个日期的差值,单位是天
// 8. now()
当前时间,格式为'yyyy-mm-dd HH:ii:ss' 7.2****字符串函数
sql
// 1. charset(str)
返回字符串的存储格式
// 2. concat(str1,str2,num,...)
返回拼接的字符串
// 3. instr(str, substr)
如果substr在str中,返回起始下标(下标是从1开始的),不在,返回0
// 4. ucase(str)
返回大写的字符串
// 5. lcase(str)
返回小写的字符串
// 6. left(str, length)
返回前面的length个字符
// 7. replace(str, search_str, replace_str)
将str中的searcher全部替换成replace_str
// 8. strcmp(str1, str2)
// 9. length(str)
返回str的字节数
// 10. substring(str, pos [, length])
// 11. ltrim(str),去除左边(开头)的空格
rtrim(str),去除右边(结尾)的空格
trim(str),去除左右两边的空格7.3****数学函数
sql
// 1. abs(num)
返回绝对值
// 2. bin(num),十进制 -> 二进制字符串
hex(num),十进制 -> 十六进制字符串
conv(num, from_base, to_base),from_base原数的进制,to_base目标进制
// 3. ceiling(num),向上取整。
floor(num),向下取整。
// 4. format(num, decimal_places)
保留小数位数(四舍五入)。
// 5. rand()
返回[0.0, 1.0)之间的随机数。
// 6. mod(num1, num2)
等价于num1 % num2,以被除数的符号为准。7.4****其他函数
sql
// 1. user()
显示当前用户
// 2. database()
显示当前使用的数据库
// 3. md5(str)
返回str的摘要,大小为32位字符
// 4. password(str)
MySQL数据库使用该函数对用户密码进行加密
// 5. ifnull(val1, val2)
如果val1 is null,返回val2,否则,返回val18**、** MySQL 索引 ( 重点 )
8.1****索引结构
- MySQL中的数据文件,是以page(16KB)为单位保存在磁盘当中的。为什么是16KB,因为局部性原理。
- MySQL中有Buffer Pool(128M),将page先写到操作系统的内核缓冲区,再写到磁盘中。
- MySQL中有大量的page,需要 先描述,再组织。
- B+树:
- MySQL中的InnoDB的索引结构。
- 叶子节点保存数据+目录项,非叶子节点只保存目录项。
- 叶子节点用链表连接,可以进行范围查找。
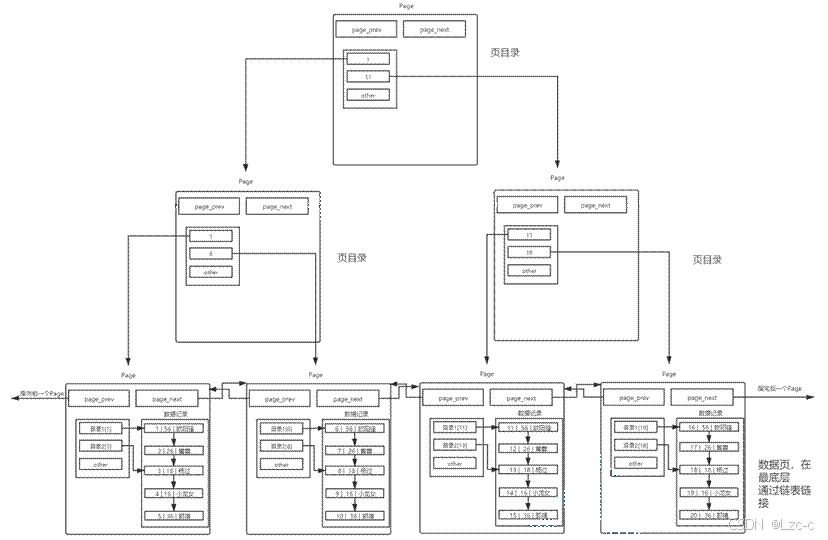
- 查找 时,性能 的决定性因素 :内存与磁盘的 I/O 、线性查找太慢。
- B+ 树 ,向下查找 ,只加载部分的 page ,减少 I/O ;page 里面也有目录 ,支持索引。
- 为什么不用其他数据结构?
- 其他数据结构:链表(线性),AVL、红黑(高度较高),HASH(不支持范围查找)。
- B树:所有节点都保存数据+目录项(高度较高),叶子节点没有用链表连接(不支持范围查找)。
- InnoDB 是将索引和数据一起 ,叶子节点 放目录项和数据 ,称聚簇索引。如果还有一个聚簇索引,对于叶子节点,不放数据,放主键值,然后在主键索引中查询,称为回表查询。
- MyISAM 是将索引与数据分离 ,叶子节点 放目录项和数据指针 ,称非聚簇索引。
8.2****创建索引
sql
// 查看索引
show index from table_name;
// 1. 主键索引 一个表只有一个
// 创建主键索引
-- 在创建表的时候,直接在字段名后指定 primary key
create table user1(id int primary key, name varchar(30));
-- 在创建表的最后,指定某列或某几列为主键索引
create table user2(id int, name varchar(30), primary key(id));
-- 创建表以后再添加主键
create table user3(id int, name varchar(30));
alter table user3 add primary key(id);
// 删除主键索引
alter table table_name drop primary key;
// 2. 唯一索引 一个表可多个,允许为NULL,NULL为未知值,NULL!=NULL;主键是非空唯一索引
// 创建唯一索引
-- 在表定义时,在某列后直接指定unique唯一属性
create table user4(id int primary key, name varchar(30) unique);
-- 创建表时,在表的后面指定某列或某几列为unique
create table user5(id int primary key, name varchar(30), unique(name));
-- 创建表以后再添加唯一索引
create table user6(id int primary key, name varchar(30));
alter table user6 add unique(name);
// 删除唯一索引
alter table table_name drop index index_name;
// 3. 普通索引 一个表可多个
// 创建普通索引
--在表的定义最后,指定某列为索引
create table user7(id int primary key, name varchar(20), email varchar(30), index(name));
--创建完表以后指定某列为普通索引
create table user8(id int primary key, name varchar(20), email varchar(30));
alter table user8 add index(name);
-- 创建一个索引名为 idx_name 的索引
create table user9(id int primary key, name varchar(20), email varchar(30));
create index idx_name on user9(name);
// 删除普通索引
alter table table_name drop index index_name;- 索引创建原则:频繁查询,有多种类别,更新不频繁。
9**、** MySQL 事务 ( 重点 )
9.1****事务概念
- 事务:若干条SQL语句构成的任务。
- 事务的性质:
- 原子性 (A tomicity):事务 是不可分割 的最小单位 ,要么全部执行成功 ,要么全部回滚 。比如转账。
- 一致性 (C onsistency):事务前后数据规则不变 ,比如转账前和转账后 ,加起来的总金额不变。
- 隔离性 (I solation):多个并发事务 之间相互隔离 ,互不干扰。
- 持久性 (D urability):事务提交后数据永久保存 ,哪怕崩溃也不丢 。可以记录日志和备份。
9.2****事务操作
- 查看数据库引擎:show engines;。MySQL中只有使用了Innodb 数据库引擎 的数据库或表才支持事务 ,MyISAM 不支持事务。
sql
// 1. 事务的提交方式
// 查看事务的提交方式
show variables like 'autocommit';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| autocommit | ON |
+---------------+-------+
ON,是自动提交,OFF,是手动提交。
// 设置事务的提交方式
set autocommit=0; // 设置为OFF,手动提交
set autocommit=1; // 设置为ON,自动提交
// 2. 事务的正常操作
// 启动事务
start transaction;
-- 或者
begin;
// 设置标记
savepoint 标记名;
// 回滚事务
rollback 标记名;
如果没有标记名,将全部回滚,然后事务结束,无需commit。
// 提交事务
commit;
a. 手动启动事务,需要手动commit,不受autocommit的影响。
b. 事务,没有commit,会回滚,commit后,无法回滚,数据的修改具有持久性。
c. 单条SQL,本身就是事务,默认autocommit为ON,自动commit。9.3****隔离性 (Isolation)
- 3 个并发问题:
- 脏读 :同一事务内 ,读了其他事务未提交 的修改(数据可能回滚,是 "脏数据");
- 不可重复读 :同一事务内 ,多次读 「同一行数据 」,结果不一样 (被其他事务提交修改了)。数据的值,UPDATE(更新已存在的数据)
- 幻读 :同一事务内 ,多次执行 「同一范围查询 」,结果不一样 (被其他事务提交插入 / 删除了)。数据的行数,INSERT 或 DELETE(新增或删除行)
- 4 种隔离级别(从低到高):
- 读未提交 (Read Uncommitted):同一事务内 ,能读未提交的数据 ,存在脏读 、不可重复读 、幻读,性能最好但最不可靠;
- 读已提交 (Read Committed):同一事务内 ,只能读已提交的 ,解决了脏读 ,但会有不可重复读 和幻读;
- 可重复读 (Repeatable Read):MySQL 默认的隔离级别 。同一事务内 ,读数据,结果不变 (MVCC (多版本并发控制),会生成数据快照 ,解决了脏读 和不可重复读 ,但是新行不在快照里 ,会被直接读到 ,导致行数变化 (幻读 ),如果删除了行 ,要进行先查后改 的操作,也会造成幻读 (行数不对),可以通过InnoDB 的间隙锁 锁住 "数据之间的空隙",阻止其他事务插入 / 删除行)。
- 串行化 (Serializable):事务一个接一个执行 ,没任何并发问题 ,但性能最差,基本不用。
- 隔离级别越高 ,数据越安全 ,但并发性能越差。
sql
// 1. 查看隔离级别
// 查看全局的隔离级别
select @@global.tx_isolation;
// 查看当前会话的隔离级别
select @@session.tx_isolation;
-- 或
select @@tx_isolation;
// 2. 设置隔离级别
SET [SESSION | GLOBAL] TRANSACTION ISOLATION LEVEL {
READ UNCOMMITTED | READ COMMITTED | REPEATABLE READ | SERIALIZABLE};10**、视图**
sql
// 1. 创建试图
create view view_name as select语句;
// 2. 查看视图
show tables;
// 3. 删除视图
drop view view_name;- 修改视图,会修改基表。
- 修改基表,会修改视图。
11**、用户与权限管理**
sql
// 1. 创建用户
create user '用户名'@'登陆主机/ip' identified by '密码';
// 2. 查看用户
use mysql; -- 使用mysql数据库
select * from user \G -- 查看用户信息
select user(); -- 显示当前用户
// 3. 修改用户密码
// 修改自己的密码
set password=password('新的密码');
// root用户修改任意用户的密码
set password for '用户名'@'主机名'=password('新的密码');
// 3. 删除用户
drop user '用户名'@'主机名';- MySQL数据库提供的权限列表:
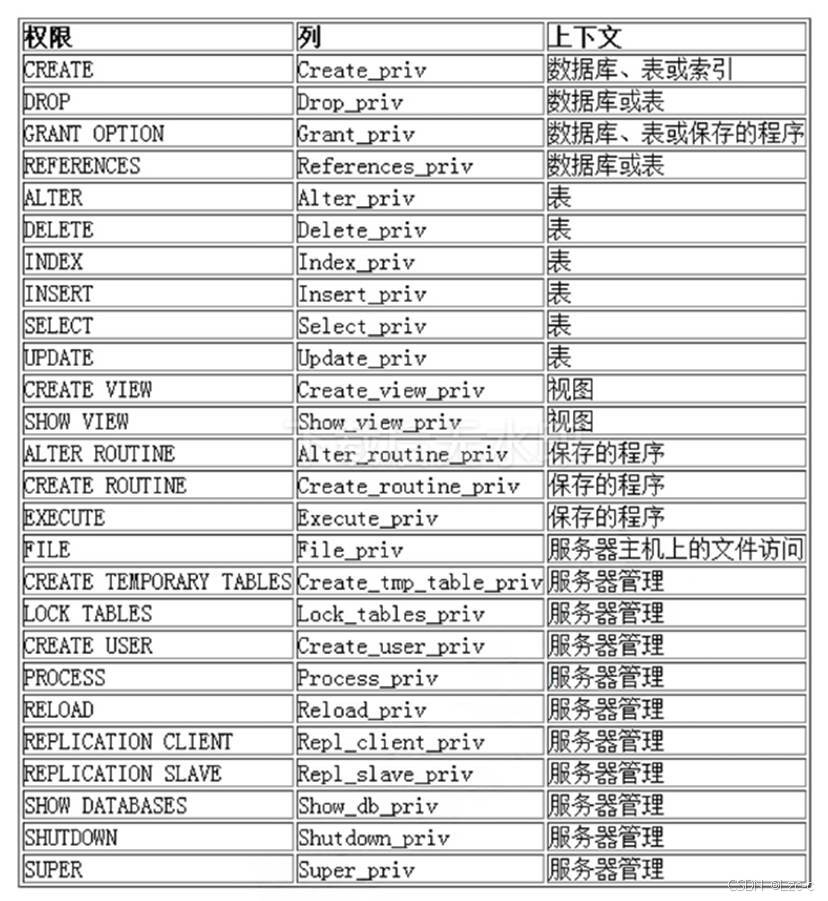
sql
// 1. 授予权限
grant 权限列表 on 库.对象名 to 用户名@IP [identified by '密码'];
权限列表:需要什么权限,就给什么权限,逗号分隔。
*.* : 代表本系统中的所有数据库的所有对象
库.* : 表示某个数据库中的所有数据对象
// 2. 查看权限
show grants for 用户名@IP;
// 3. 撤回权限
revoke 权限列表 on 库.对象名 from 用户名@IP;
// 4. 刷新权限
flush privileges;12**、** C/C++ 访问 MySQL
sql
正常编译
// 1. 下载mysql.h和libmysqlclient.so,
yum install -y mysql-community-devel
-- mysql.h在/usr/include/mysql/mysql.h
-- libmysqlclient.so在/usr/lib64/mysql/libmysqlclient.so
// 2. 编译选项
g++ -o test.cc test -L /usr/lib64/mysql -l mysqlclient- MySQL官网的接口:https://dev.mysql.com/doc/
sql
// MySQL的常用接口
// 1. 初始化MySQL对象
MYSQL *mysql_init(MYSQL *mysql);
// 如:MySQL* mfp = mysql_init(nullptr);
// error,返回nullptr
// 2. 连接MySQL
MYSQL *mysql_real_connect(
MYSQL *mysql, -- MySQL对象
const char *host, // IP 本地连接可以使用 localhost 或者 127.0.0.1
const char *user, // 用户名
const char *passwd, // 密码
const char *db, // 要使用的数据库
unsigned int port, // MySQL的port
const char *unix_socket, // 一般为nullptr
unsigned long clientflag // 一般为0
);
// error,返回nullptr
// 3. 关闭MySQL连接
void mysql_close(MYSQL *sock);
// 4. 设置字符集(存储格式)
int mysql_set_character_set(MYSQL *mysql, const char *csname); // 一般为 "utf8"
// success,返回0,errot,返回非0
// 5. 执行MySQL语句
int mysql_query(MYSQL *mysql, const char *q);
// success,返回0,errot,返回非0
// 6. 显示查询结果
// 首先查询结果,就是一个表,看成二维数组。
// 提取查询结果
MYSQL_RES* mysql_store_result(MYSQL *mysql);
// 如:MYSQL_RES* res= mysql_store_result(mfp);
// 获取行数
my_ulonglong mysql_num_rows(MYSQL_RES *result);
// 如:my_ulonglong row = mysql_num_rows(res);
// 获取列数
unsigned int mysql_num_fields(MYSQL_RES *result);
// 如:unsigned int col = mysql_num_fields(res);
// 获取列属性
MYSQL_FIELD* mysql_fetch_fields(MYSQL_RES *result);
MYSQL_FIELD *fields = mysql_fetch_fields(res);
for(unsigned int i = 0; i < col; ++i) {
std::cout << fields[i].name << " "; // 获取列名
}
std::cout << std::endl;
// 显示查询结果
// 返回查询结果中的一行数据
// 类似迭代器,执行完,内部行指针会自动++。
MYSQL_ROW mysql_fetch_row(MYSQL_RES *result);
for(my_ulonglong i = 0; i < row; ++i) {
MYSQL_ROW line = mysql_fetch_row(res);
for(unsigned int j = 0; j < col; ++j) {
std::cout << line[j] << " ";
}
std::cout << std::endl;
}
// 7. 释放查询结果
void mysql_free_result(MYSQL_RES *result);
// 如:mysql_free_result(res);