大家好我是小明,今天复习mysql
文章目录
- 1.慢查询如何分析
- 2.Mysql索引
- 3.聚簇索引和非聚簇索引(回表查询)
- 4.覆盖索引(MySQL超大分页)
- [5. 索引失效](#5. 索引失效)
- 6.事务
-
- [6.1 事务的特性(ACID)](#6.1 事务的特性(ACID))
- [6.2 并发事务问题,隔离级别](#6.2 并发事务问题,隔离级别)
- [7. uodo log 和redo log 区别](#7. uodo log 和redo log 区别)
1.慢查询如何分析
可以使用EXPLAIN或者DESC命令获取MYSQL如何执行的信息。

这里比较重要的字段是下面几个
- type 这条sql连接类型,性能好到差(NULL, system, const,eq_ref, range, index, all)
- possible_keys 当前可能命中的索引
- key 实际命中的索引
- key_len占用索引大小
- Extre 额外的建议优化


面试回答:

2.Mysql索引
定义:索引是数据库中一种特殊的数据结构,它通过对表中一个或多个字段进行排序存储,来加速查询时的数据定位,本质是用空间换时间的优化手段。
Mysql索引底层默认使用的是B+树,再聊B+树之前,我们先看一下二叉树和B树。
大家都知道二叉搜索树
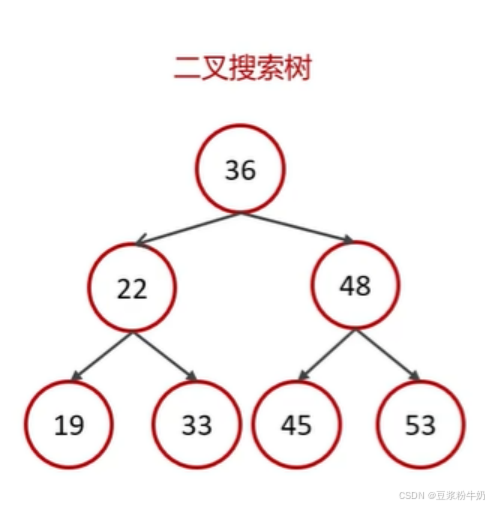
左边的数字一定比右边的大
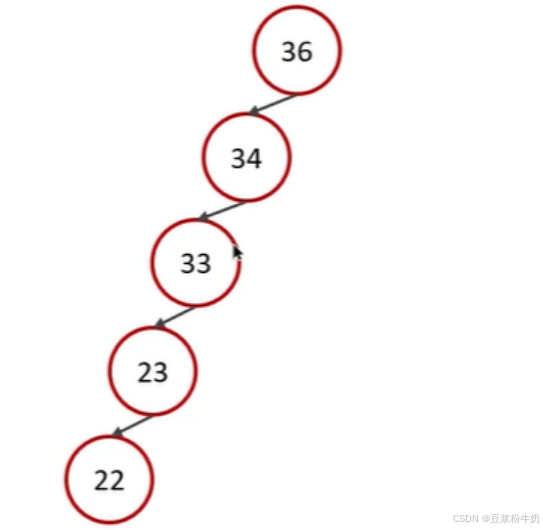
但是最坏的情况是这样的
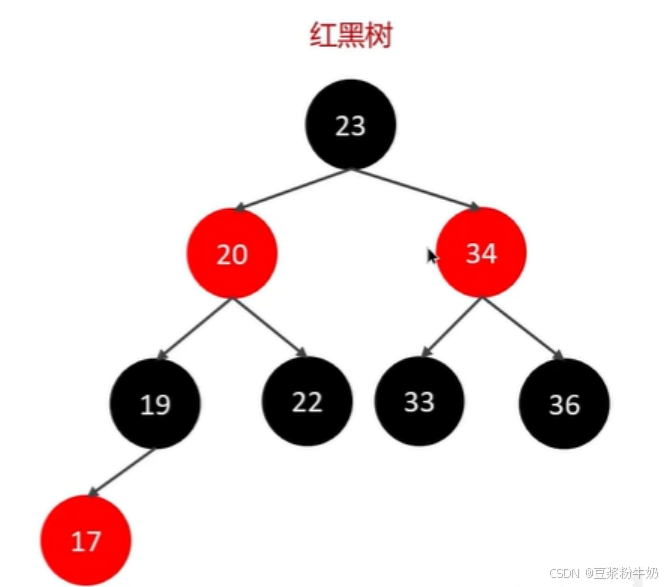
红黑树:可以理解为近似平衡的二叉搜索树,
近似平衡(最长路径 ≤ 2 倍最短路径)
AVL树是高度平衡的树
即:左右子树高度差(平衡因子)的绝对值 ≤ 1
这时候树是平衡了,查找的效率高啦,但是如果拥有海量的数据,树的高度还是非常高
B树
B 树是一种多路平衡查找树,它的节点可以拥有多个子节点(不像二叉树只有 2 个)
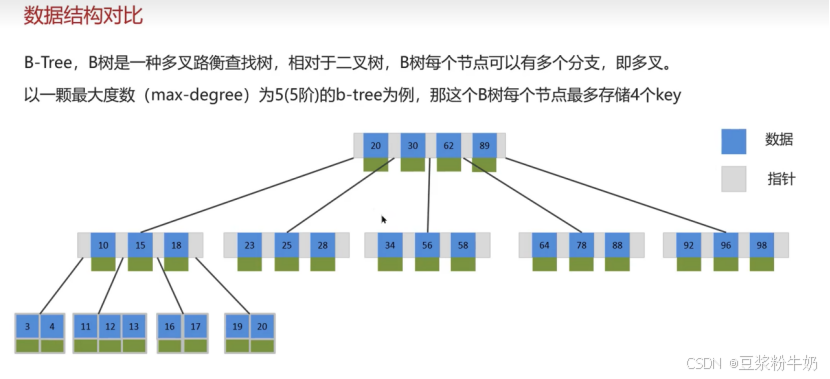
二叉树的问题:如果数据量很大(比如 1000 万条),二叉树的高度会很高(约 20-30 层)。每查一层就要读一次磁盘,查 30 次磁盘太慢了!
B 树的优势:因为一个节点能存很多数据(比如 1KB~16KB),树变得很 "矮胖"。查 1000 万条数据,可能只需要读 3~4 次磁盘。
结论:树的高度越低,磁盘 I/O 次数越少,查询越快。
B+树
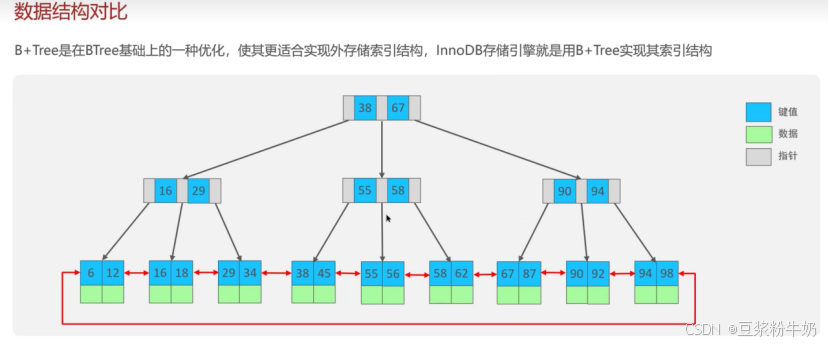
- B+树磁盘读写代价更低: B+树在叶子节点存储数据,非叶子节点存储指针,相比于B树查找节点的时候会缓存路径上的节点,磁盘读写代价大。
- 查询效率B+树更加稳定:B+树只在叶子节点存储数据,非叶子节点存储指针。查询都是logn。
- B+树便于扫盘和区间查询: 原因叶子节点使用双向链表连接。
3.聚簇索引和非聚簇索引(回表查询)
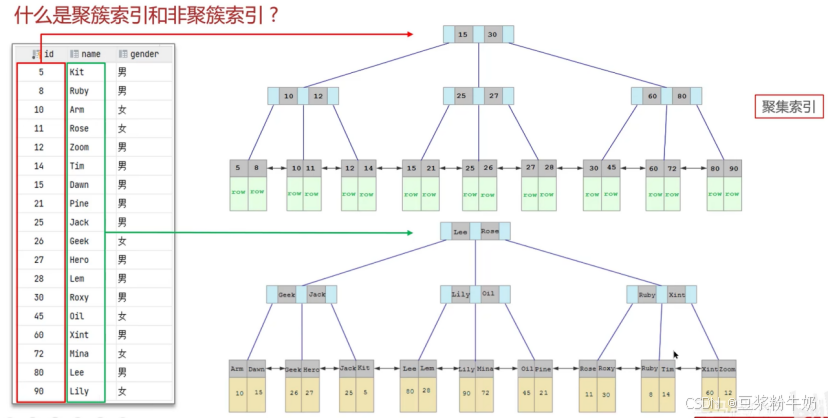
聚簇索引 :一张表只能有 1 个,一般是主键,无主键时会选唯一非空索引,数据和索引存储在一起,叶子节点直接存完整数据行。
非聚簇索引: 索引与数据分开存储,叶子节点存的是主键值(需要回表查询数据)。
回表查询
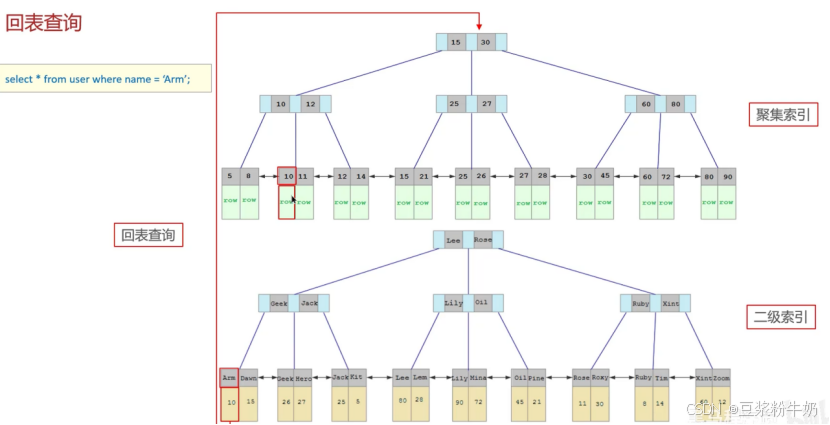
Where name = "Arm"命中非二级索引,在二级中找到Arm,Arm节点存储的是主键,在根据主键查询完整用户。
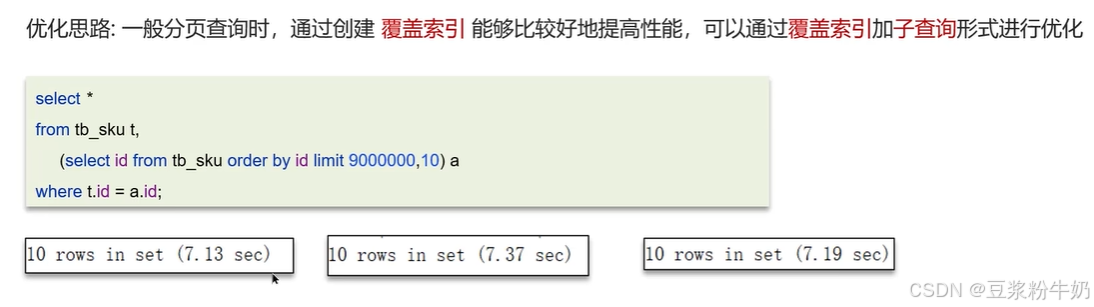
4.覆盖索引(MySQL超大分页)

MySQL超大分页

优化:
5. 索引失效
① 违反最左前缀法则(前提是使用复合索引)
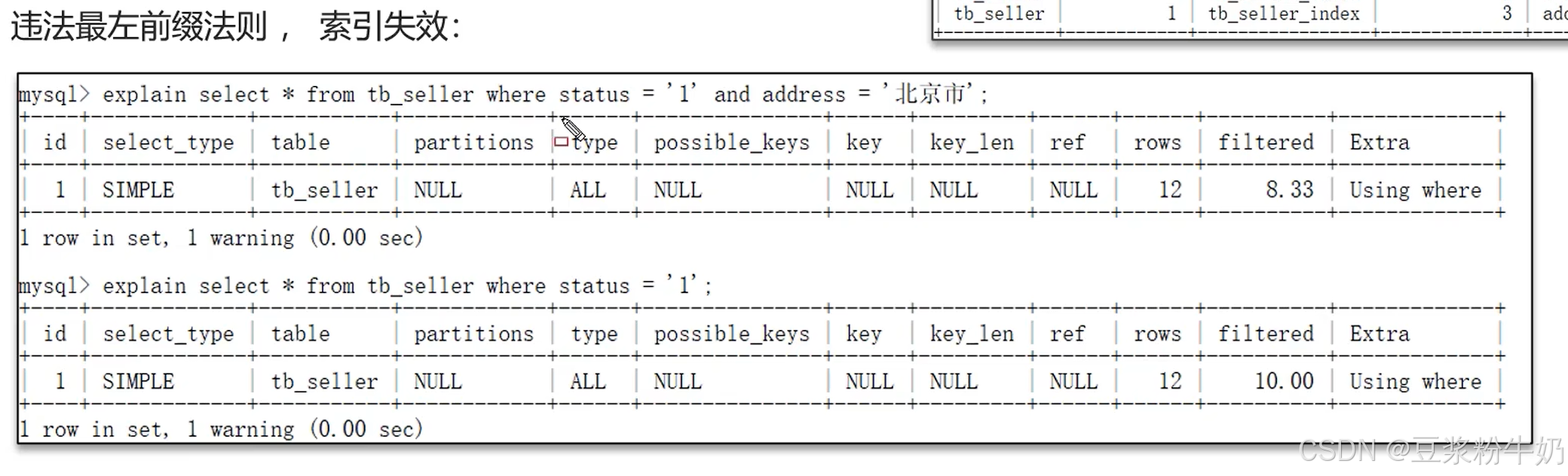

② 范围查询右边的列,不能使用索引

范围查询之后的索引失效
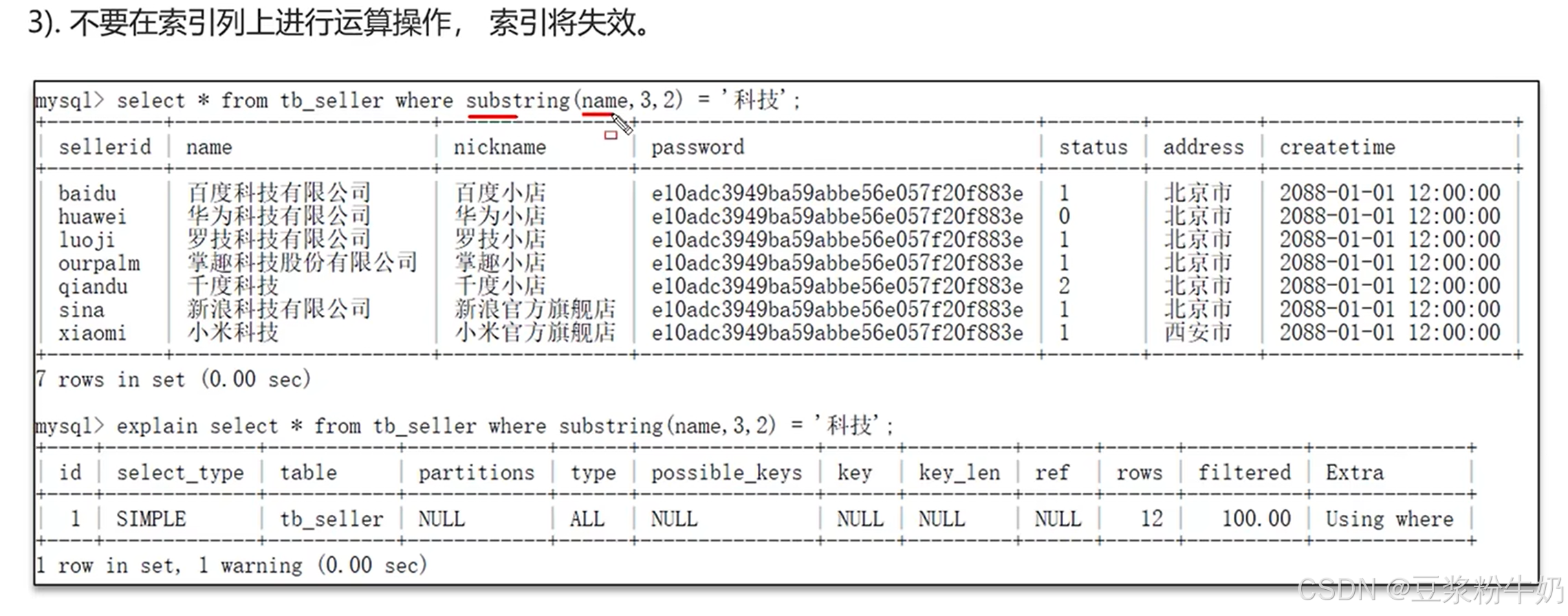
③ 不要在索引列上进行运算操作,索引将失效
④ 字符串不加单引号,造成索引失效。(类型转换)

⑤ 以 % 开头的 Like 模糊查询,索引失效
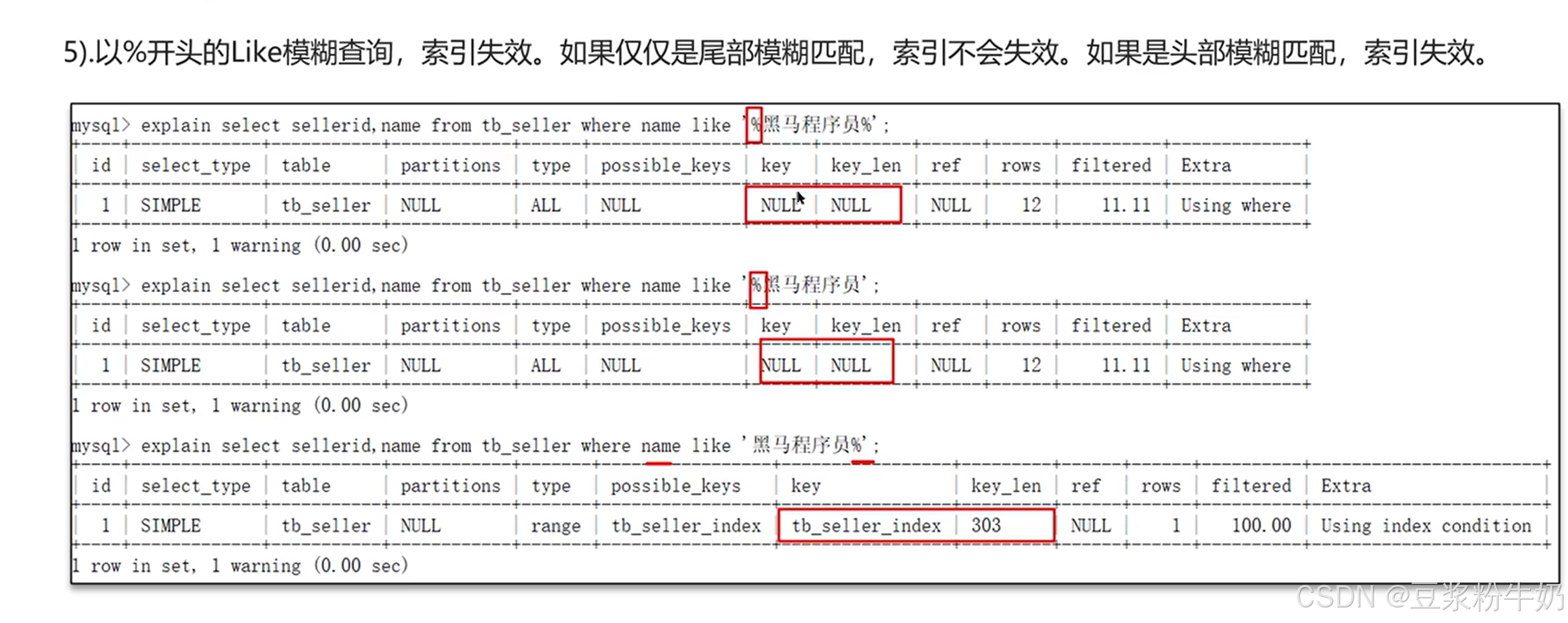
这里直接背就好啦
6.事务
事务:数据库中一组不可分割的数据库操作(SQL 语句集合),这组操作要么全部执行成功,要么全部执行失败回滚,它是数据库保证数据一致性和完整性的核心机制。
6.1 事务的特性(ACID)
- 原子性(Atomicity):事务是不可分割的最小操作单元,要么全部成功,要么全部失败。
- 一致性(Consistency):事务完成时,必须使所有的数据都保持一致状态。
- 隔离性(Isolation):数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行。
- 持久性(Durability):事务一旦提交或回滚,它对数据库中的数据的改变就是永久的。
最好是结合实际场景解释给面试官
- 原子性:转账要么失败要么成功
- 一致性:转账一个人得到钱一个失去钱,保持数据一致性
- 隔离性:转账过程不受第三方打扰
- 持久性:转账成功后数据修改是持久化的
6.2 并发事务问题,隔离级别
== 并发事务问题==

怎么解决呢?
事务的隔离级别
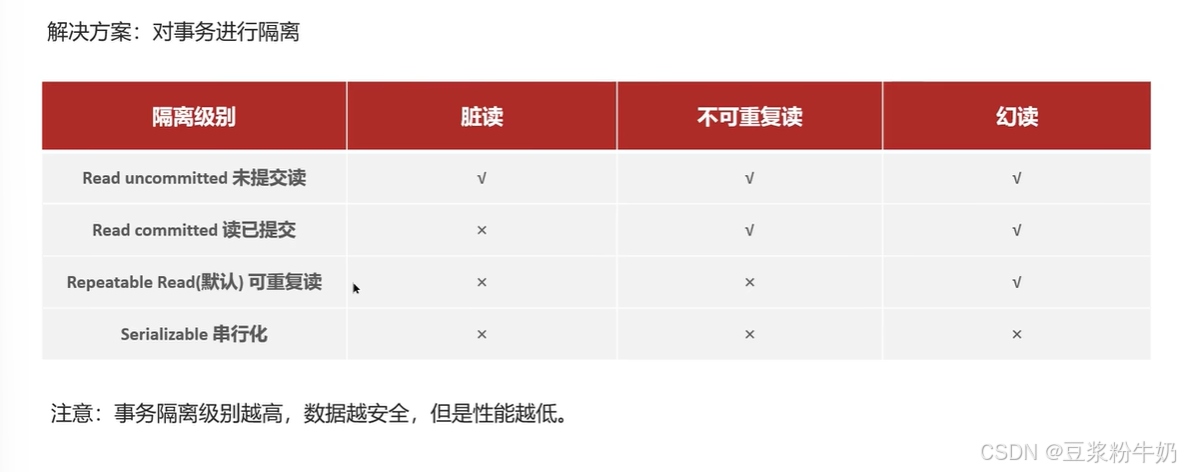
mysql默认的事务级别是可重复读,事务的隔离级别越高,数据越安全,但是性能比较低。
7. uodo log 和redo log 区别
- undo log(回滚日志)
它记录的是数据修改前的状态。
你执行 INSERT / UPDATE / DELETE 时,数据库会先把「修改前的值」写入 undo log。
== 用来支持:==
- 事务回滚时,用 undo log 把数据恢复到修改前的状态
- 多版本并发控制(MVCC)
- redo log(重做日志)
它记录的是数据修改后的状态(物理日志)。
当你修改数据时,数据库会把 "要修改成什么" 写入 redo log,并立即刷盘。
== 用来支持:==
- 录的是数据页的物理变化,服务宕机可用来同步数据
- 保证事务提交后不会丢数据(持久性)