在拟合模型前,需要对已知的数据集(包括特征数据项和目标数据项)作划分。通常我们需要把已知的数据集分成训练数据 (Train
Data)、验证数据 (Validate Data)和测试数据 (Test
Data)三个部分,如图1所示。这三个部分的作用是用训练数据来训练模型,用验证数据调节模型参数,用测试数据来评价模型。训练数据在统计学领域也称为样本数据,一条数据也称为一个样本。评价模型后就可得到模型的各种评价指标的值,从而方便选择合适的模型。这三个部分事先应都已经有目标数据项的值。
要想打好机器学习的数学基础,请参见清华大学出版社的人人可懂系列,包括《人人可懂的微积分》(已上市)、《人人可懂的线性代数》(即将上市)、《人人可懂的概率统计》(即将上市)。
现实应用中,标记目标数据项的值也是一项工作量相当大的工作。在很多工程应用中,会聘请大量的工作人员来做数据标记的工作。
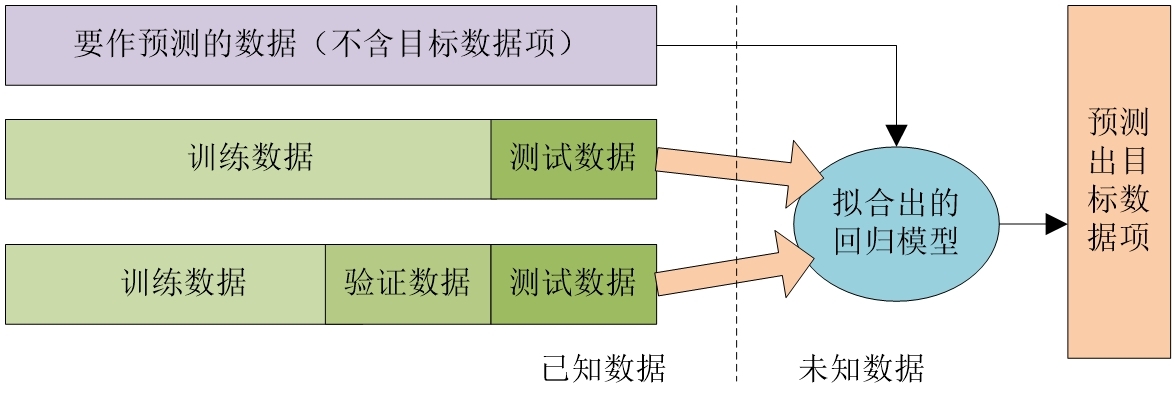
图1 已知数据集的划分
有的模型不需要有验证数据,则可将已知的数据集划分为训练数据和测试数据两个部分。这说明这种模型不需要验证数据来调节模型的参数。测试数据还有一点与验证数据不同的是:对于模型来说,测试数据是从未遇到过的新数据,因而可以测试出模型面对新数据作预测的泛化能力。
所谓泛化能力,就是指的应对广泛的数据(也即模型没有遇到过的数据)的预测能力。"泛"字带有普遍的含义。对于模型来说,自然是泛化能力越强越好。
提示:通常对模型作评价时认为泛化能力越强越好。但是评价泛化能力得靠MAE **、MSE 、RMSE 、R²这些评价指标针对测试数据来判断。这些指标可以用来评价模型对训练数据的拟合程度,评价泛化能力则要用这些指标和模型对测试数据来作出综合评判。
拟合出线性回归模型后,就可以用模型和要作预测的数据(含特征项,不含目标数据)来预测出目标数据项的值。
那么已知的数据集的三个部分应怎么划分比较合适呢?有没有特定的比例讲究?目前对比例还没有准确一致的说法。但是通常认为训练数据要比验证数据、测试数据要多,训练数据应占一半多。Python中已经提供了现成可用的数据集划分工具,一会在实例中再作详细讲解。通常认为,在使用同样的数据集及其划分规则的情况下,对构建出的各种模型之间进行比较才更具意义和实用价值。
要想打好机器学习的数学基础,请参见清华大学出版社的人人可懂系列,包括《人人可懂的微积分》(已上市)、《人人可懂的线性代数》(即将上市)、《人人可懂的概率统计》(即将上市)。