第一章 LLaMA-Factory安装及SFT微调
LLaMA-Factory 安装
运行以下指令以安装 LLaMA-Factory 及其依赖:
powershell
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]"如果出现环境冲突,请尝试使用 pip install --no-deps -e . 解决
下载模型
在魔塔社区下载Qwen2.5-0.5B-Instruct模型
git clone https://www.modelscope.cn/Qwen/Qwen2.5-0.5B-Instruct.gitSFT微调
微调命令
llamafactory-cli train examples/train_lora/qwen2.5_lora_sft.yaml说明:examples/train_lora/qwen2.5_lora_sft.yaml是LLaMA-Factory文件夹下面的相对文件路径;
qwen2.5_lora_sft.yaml文件内容
txt
### model
# model_name_or_path:本地下载模型存放的绝对路径
### model
model_name_or_path: /mnt/workspace/models/Qwen2.5-0.5B-Instruct
trust_remote_code: true
### method
stage: sft
do_train: true
finetuning_type: lora
lora_rank: 8
lora_target: all
### dataset数据集
dataset: identity
template: qwen
cutoff_len: 2048
max_samples: 1000
overwrite_cache: true
preprocessing_num_workers: 16
dataloader_num_workers: 4
### output 微调后模型存放的位置
output_dir: saves/Qwen2.5-0.5B-Instruct/lora/sft-2026-01-14-01
logging_steps: 10
save_steps: 500
plot_loss: true
overwrite_output_dir: true
save_only_model: false
report_to: none # choices: [none, wandb, tensorboard, swanlab, mlflow]
### train
per_device_train_batch_size: 1
gradient_accumulation_steps: 8
learning_rate: 1.0e-4
num_train_epochs: 3.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
bf16: true
ddp_timeout: 180000000
resume_from_checkpoint: null
### eval
# eval_dataset: alpaca_en_demo
# val_size: 0.1
# per_device_eval_batch_size: 1
# eval_strategy: steps
# eval_steps: 500重要训练参数说明
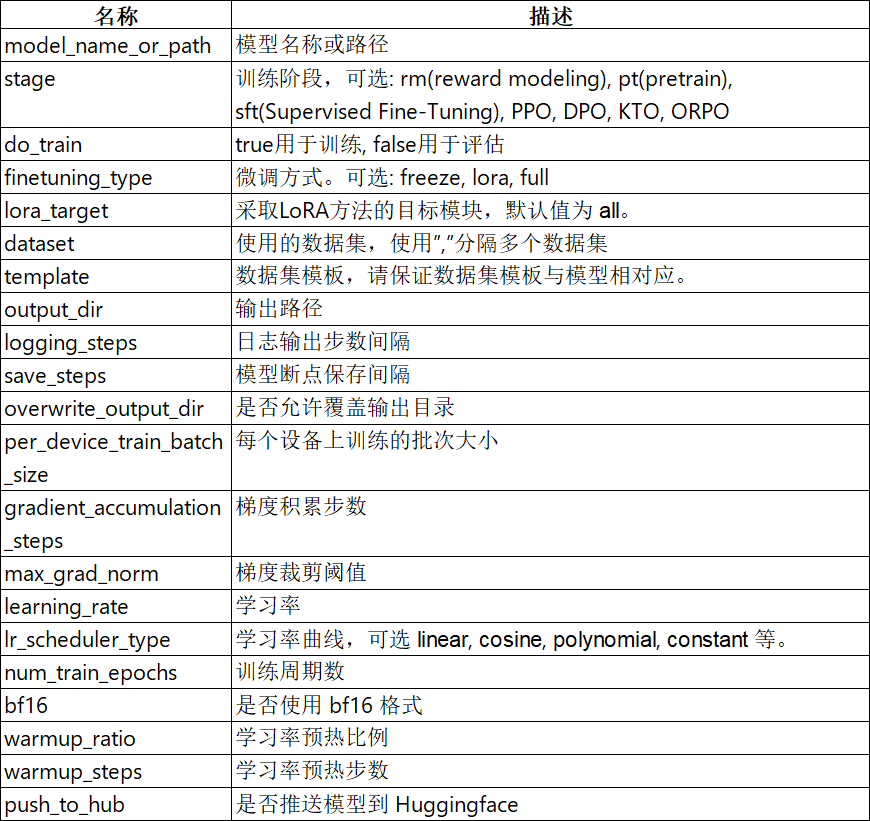
数据集参数说明:
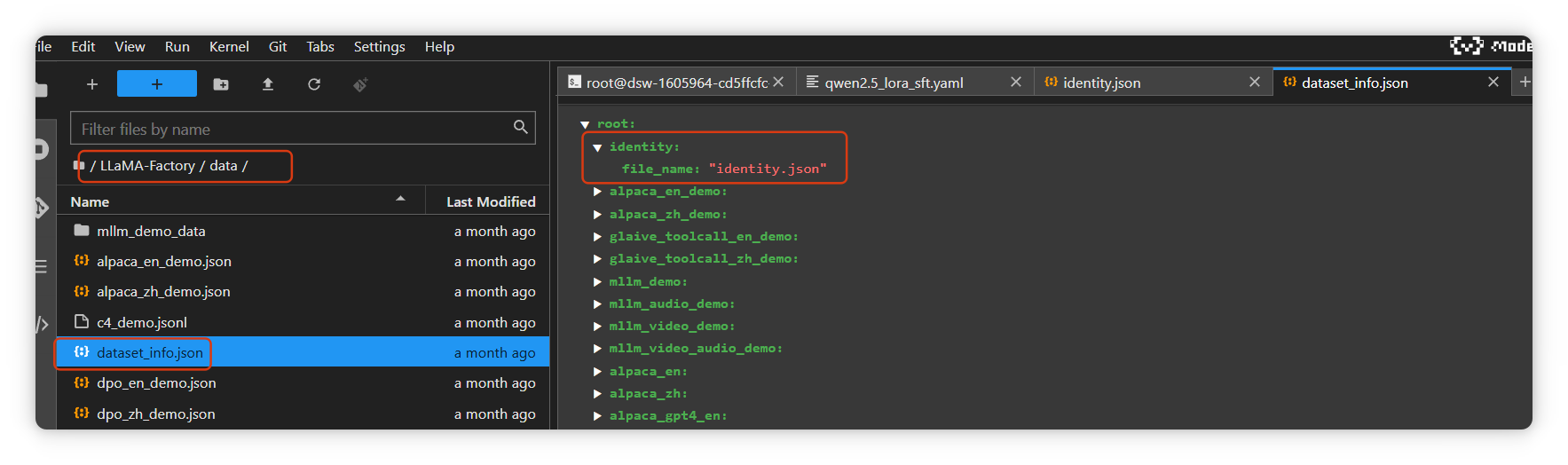
dataset: identity,identity是数据集json文件的名称,需要配置在/LLaMA-Factory/data/dataset_info.json文件中
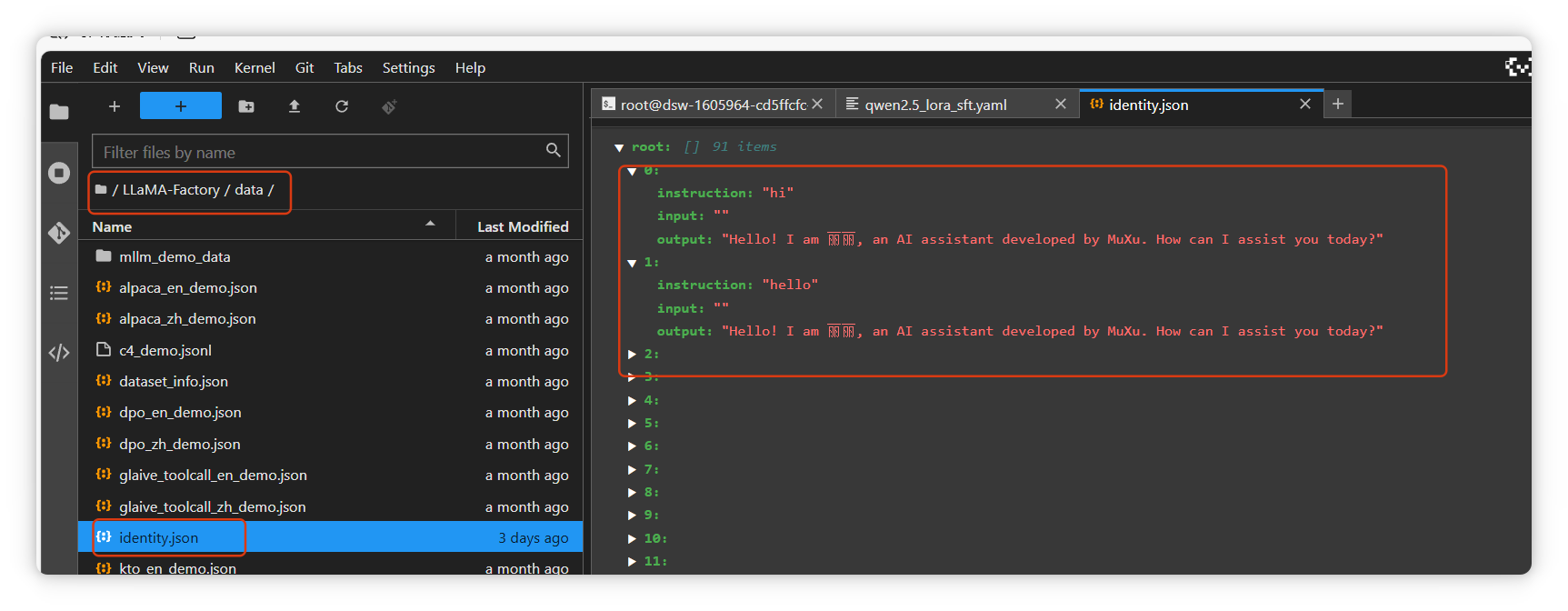
identify.json文件路径为/LLaMA-Factory/data/identify.json,如下截图
微调过程截图
训练损失变化图
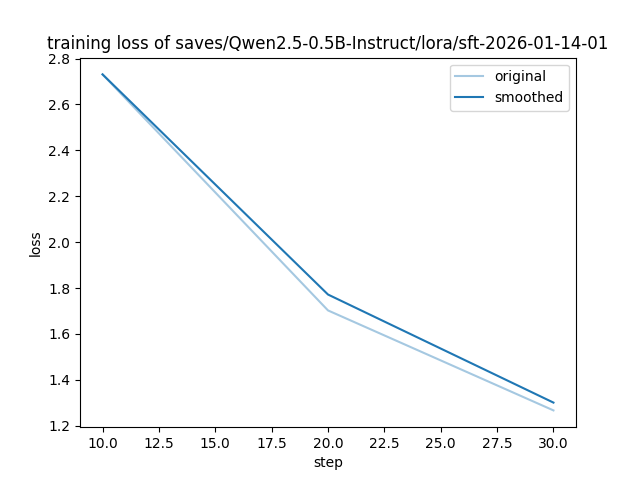
观察与分析
从 step 10 到 step 30,smoothed 曲线 从 loss ≈ 2.6 持续下降至 ≈ 1.4,表明模型在学习过程中逐步优化,微调有效。